Java (485)
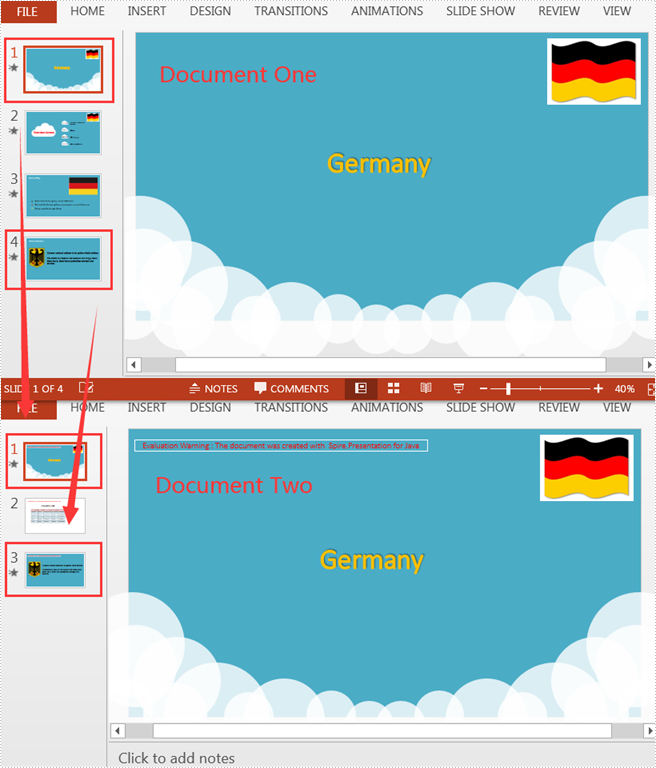
Suppose there are two PowerPoint documents, and you want to copy a certain slide from one document to a specified location of the other. Manual copying and pasting is an option, but the quicker and more efficient way is to use Java codes for automatic operation. This article will show you how to programmatically copy slides between two different PowerPoint documents using Spire.Presentation for Java.
Install Spire.Presentation for Java
First of all, you're required to add the Spire.Presentation.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>11.7.2</version>
</dependency>
</dependencies>
Copy Slides Between Two PowerPoint Documents
The following are detailed steps to copy a slide from one PowerPoint document to a specified position or the end of the other document.
- Create a Presentation object and load one sample document using Presentation.loadFromFile() method.
- Create another Presentation object and load the other sample document using Presentation.loadFromFile() method.
- Get a specific slide of document one using Presentation.getSlides().get() method and insert its copy into the specified position of document two using Presentation.getSlides().insert() method.
- Get another specific slide of document one using Presentation.getSlides().get() method and add its copy to the end of document two using Presentation.getSlides().append() method.
- Save the document two to another file using Presentation.saveToFile() method.
- Java
import com.spire.presentation.FileFormat;
import com.spire.presentation.Presentation;
public class CopySlidesBetweenPPT {
public static void main(String[] args) throws Exception {
//Create a Presentation object to load one sample document
Presentation pptOne= new Presentation();
pptOne.loadFromFile("C:\\Users\\Test1\\Desktop\\sample1.pptx");
//Create another Presentation object to load the other sample document
Presentation pptTwo = new Presentation();
pptTwo.loadFromFile("C:\\Users\\Test1\\Desktop\\sample2.pptx");
//Insert the specific slide from document one into the specified position of document two
pptTwo.getSlides().insert(0,pptOne.getSlides().get(0));
//Append the specific slide of document one to the end of document two
pptTwo.getSlides().append(pptOne.getSlides().get(3));
//Save the document two to another file
pptTwo.saveToFile("output/CopySlidesBetweenPPT.pptx", FileFormat.PPTX_2013);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
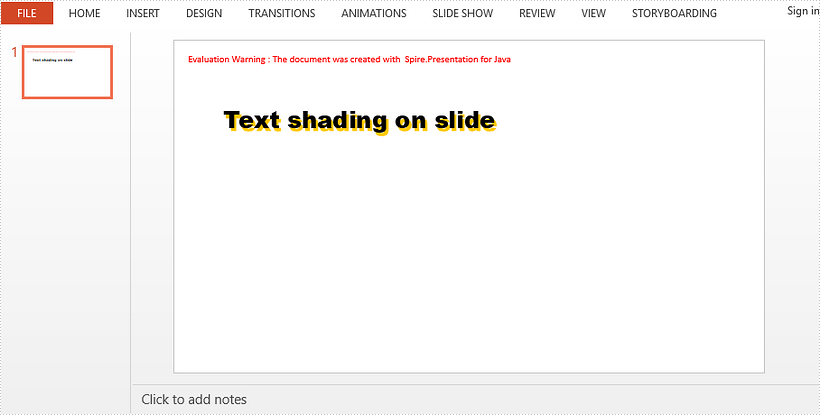
This article demonstrates how to apply a shadow effect to the text in a PowerPoint slide using Spire.Presentation for Java.
import com.spire.presentation.*;
import com.spire.presentation.drawing.FillFormatType;
import com.spire.presentation.drawing.OuterShadowEffect;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class SetShadowEffect {
public static void main(String[] args) throws Exception {
//Create a Presentation object
Presentation presentation = new Presentation();
presentation.getSlideSize().setType(SlideSizeType.SCREEN_16_X_9);
//Get the first slide
ISlide slide = presentation.getSlides().get(0);
//Add a rectangle to slide
IAutoShape shape = slide.getShapes().appendShape(ShapeType.RECTANGLE,new Rectangle2D.Float(50,80,500,100));
shape.getFill().setFillType(FillFormatType.NONE);
shape.getLine().setFillType(FillFormatType.NONE);
//Set text of the shape
shape.appendTextFrame("Text shading on slide");
//Set font style
shape.getTextFrame().getTextRange().setFontHeight(38f);
shape.getTextFrame().getTextRange().setLatinFont(new TextFont("Arial Black"));
shape.getTextFrame().getTextRange().getFill().setFillType(FillFormatType.SOLID);
shape.getTextFrame().getTextRange().getFill().getSolidColor().setColor(Color.BLACK);
//Create a OuterShadowEffect object
OuterShadowEffect outerShadow= new OuterShadowEffect();
//Set the shadow effect
outerShadow.setBlurRadius(0);
outerShadow.setDirection(50);
outerShadow.setDistance(10);
outerShadow.getColorFormat().setColor(Color.orange);
//Apply shadow effect to text
shape.getTextFrame().getTextRange().getEffectDag().setOuterShadowEffect(outerShadow);
//Save to file
presentation.saveToFile("output/AddShadow.pptx", FileFormat.PPTX_2013);
}
}
Java remove the formulas but keep the values on Excel worksheet
2021-02-20 05:39:06 Written by AdministratorThis article will demonstrate how to use Spire.XLS for Java to remove the formulas but keep the values on the Excel worksheet.
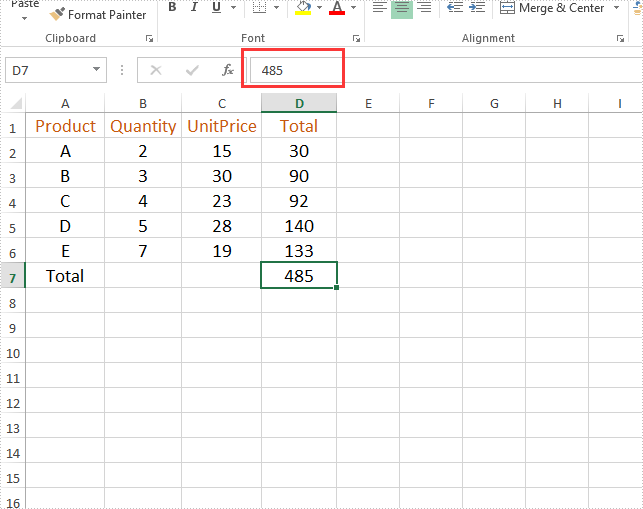
Firstly, view the original Excel:
String inputFile = "Sample.xlsx";
String outputFile="output/removeFormulasButKeepValues_result.xlsx";
//Create a workbook.
Workbook workbook = new Workbook();
//Load the file from disk.
workbook.loadFromFile(inputFile);
//Loop through worksheets.
for (Worksheet sheet : (Iterable<? extends Worksheet>) workbook.getWorksheets())
{
//Loop through cells.
for (CellRange cell : (Iterable<? extends CellRange>) sheet.getRange())
{
//If the cell contains formula, get the formula value, clear cell content, and then fill the formula value into the cell.
if (cell.hasFormula())
{
Object value = cell.getFormulaValue();
cell.clear(ExcelClearOptions.ClearContent);
cell.setValue(value.toString());
}
}
}
//Save to file
workbook.saveToFile(outputFile, ExcelVersion.Version2013);
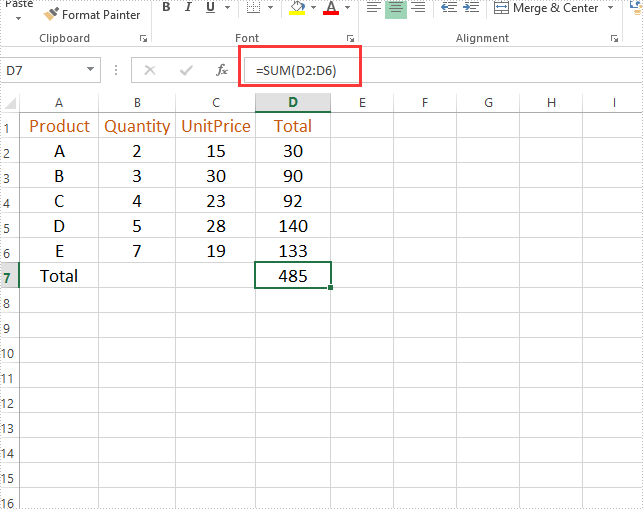
Output: