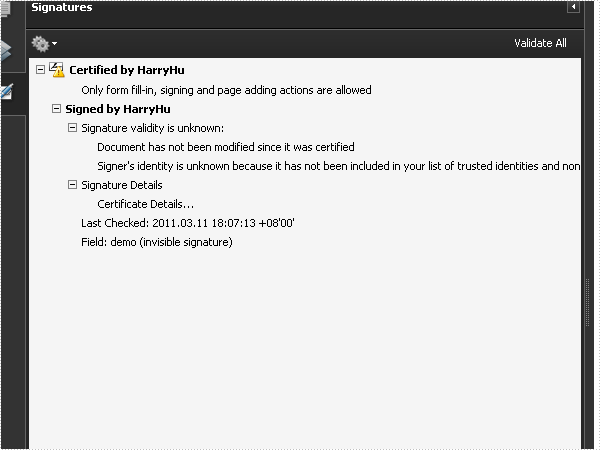
The sample demonstrates how to sign PDF document with digital certificate.
Download DigitalSignature.pdf
using System;
using System.Drawing;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Security;
namespace DigitalSignature
{
class Program
{
static void Main(string[] args)
{
//Create a pdf document.
PdfNewDocument doc = new PdfNewDocument();
// Create one page
PdfPageBase page = doc.Pages.Add();
//Draw the page
DrawPage(page);
String pfxPath = @"Demo.pfx";
PdfCertificate cert = new PdfCertificate(pfxPath, "e-iceblue");
PdfSignature signature = new PdfSignature(doc, page, cert, "demo");
signature.ContactInfo = "Harry Hu";
signature.Certificated = true;
signature.DocumentPermissions = PdfCertificationFlags.AllowFormFill;
//Save pdf file.
doc.Save("DigitalSignature.pdf");
doc.Close();
//Launching the Pdf file.
System.Diagnostics.Process.Start("DigitalSignature.pdf");
}
private static void DrawPage(PdfPageBase page)
{
float pageWidth = page.Canvas.ClientSize.Width;
float y = 0;
//page header
PdfPen pen1 = new PdfPen(Color.LightGray, 1f);
PdfBrush brush1 = new PdfSolidBrush(Color.LightGray);
PdfTrueTypeFont font1 = new PdfTrueTypeFont(new Font("Arial", 8f, FontStyle.Italic));
PdfStringFormat format1 = new PdfStringFormat(PdfTextAlignment.Right);
String text = "Demo of Spire.Pdf";
page.Canvas.DrawString(text, font1, brush1, pageWidth, y, format1);
SizeF size = font1.MeasureString(text, format1);
y = y + size.Height + 1;
page.Canvas.DrawLine(pen1, 0, y, pageWidth, y);
//title
y = y + 5;
PdfBrush brush2 = new PdfSolidBrush(Color.Black);
PdfTrueTypeFont font2 = new PdfTrueTypeFont(new Font("Arial", 16f, FontStyle.Bold));
PdfStringFormat format2 = new PdfStringFormat(PdfTextAlignment.Center);
format2.CharacterSpacing = 1f;
text = "Summary of Science";
page.Canvas.DrawString(text, font2, brush2, pageWidth / 2, y, format2);
size = font2.MeasureString(text, format2);
y = y + size.Height + 6;
//icon
PdfImage image = PdfImage.FromFile(@"Wikipedia_Science.png");
page.Canvas.DrawImage(image, new PointF(pageWidth - image.PhysicalDimension.Width, y));
float imageLeftSpace = pageWidth - image.PhysicalDimension.Width - 2;
float imageBottom = image.PhysicalDimension.Height + y;
//refenrence content
PdfTrueTypeFont font3 = new PdfTrueTypeFont(new Font("Arial", 9f));
PdfStringFormat format3 = new PdfStringFormat();
format3.ParagraphIndent = font3.Size * 2;
format3.MeasureTrailingSpaces = true;
format3.LineSpacing = font3.Size * 1.5f;
String text1 = "(All text and picture from ";
String text2 = "Wikipedia";
String text3 = ", the free encyclopedia)";
page.Canvas.DrawString(text1, font3, brush2, 0, y, format3);
size = font3.MeasureString(text1, format3);
float x1 = size.Width;
format3.ParagraphIndent = 0;
PdfTrueTypeFont font4 = new PdfTrueTypeFont(new Font("Arial", 9f, FontStyle.Underline));
PdfBrush brush3 = PdfBrushes.Blue;
page.Canvas.DrawString(text2, font4, brush3, x1, y, format3);
size = font4.MeasureString(text2, format3);
x1 = x1 + size.Width;
page.Canvas.DrawString(text3, font3, brush2, x1, y, format3);
y = y + size.Height;
//content
PdfStringFormat format4 = new PdfStringFormat();
text = System.IO.File.ReadAllText(@"Summary_of_Science.txt");
PdfTrueTypeFont font5 = new PdfTrueTypeFont(new Font("Arial", 10f));
format4.LineSpacing = font5.Size * 1.5f;
PdfStringLayouter textLayouter = new PdfStringLayouter();
float imageLeftBlockHeight = imageBottom - y;
PdfStringLayoutResult result
= textLayouter.Layout(text, font5, format4, new SizeF(imageLeftSpace, imageLeftBlockHeight));
if (result.ActualSize.Height < imageBottom - y)
{
imageLeftBlockHeight = imageLeftBlockHeight + result.LineHeight;
result = textLayouter.Layout(text, font5, format4, new SizeF(imageLeftSpace, imageLeftBlockHeight));
}
foreach (LineInfo line in result.Lines)
{
page.Canvas.DrawString(line.Text, font5, brush2, 0, y, format4);
y = y + result.LineHeight;
}
PdfTextWidget textWidget = new PdfTextWidget(result.Remainder, font5, brush2);
PdfTextLayout textLayout = new PdfTextLayout();
textLayout.Break = PdfLayoutBreakType.FitPage;
textLayout.Layout = PdfLayoutType.Paginate;
RectangleF bounds = new RectangleF(new PointF(0, y), page.Canvas.ClientSize);
textWidget.StringFormat = format4;
textWidget.Draw(page, bounds, textLayout);
}
}
}
Imports System.Drawing
Imports Spire.Pdf
Imports Spire.Pdf.Graphics
Imports Spire.Pdf.Security
Namespace DigitalSignature
Friend Class Program
Shared Sub Main(ByVal args() As String)
'Create a pdf document.
Dim doc As New PdfNewDocument()
' Create one page
Dim page As PdfPageBase = doc.Pages.Add()
'Draw the page
DrawPage(page)
Dim pfxPath As String = "Demo.pfx"
Dim cert As New PdfCertificate(pfxPath, "e-iceblue")
Dim signature As New PdfSignature(doc, page, cert, "demo")
signature.ContactInfo = "Harry Hu"
signature.Certificated = True
signature.DocumentPermissions = PdfCertificationFlags.AllowFormFill
'Save pdf file.
doc.Save("DigitalSignature.pdf")
doc.Close()
'Launching the Pdf file.
Process.Start("DigitalSignature.pdf")
End Sub
Private Shared Sub DrawPage(ByVal page As PdfPageBase)
Dim pageWidth As Single = page.Canvas.ClientSize.Width
Dim y As Single = 0
'page header
Dim pen1 As New PdfPen(Color.LightGray, 1.0F)
Dim brush1 As PdfBrush = New PdfSolidBrush(Color.LightGray)
Dim font1 As New PdfTrueTypeFont(New Font("Arial", 8.0F, FontStyle.Italic))
Dim format1 As New PdfStringFormat(PdfTextAlignment.Right)
Dim text As String = "Demo of Spire.Pdf"
page.Canvas.DrawString(text, font1, brush1, pageWidth, y, format1)
Dim size As SizeF = font1.MeasureString(text, format1)
y = y + size.Height + 1
page.Canvas.DrawLine(pen1, 0, y, pageWidth, y)
'title
y = y + 5
Dim brush2 As PdfBrush = New PdfSolidBrush(Color.Black)
Dim font2 As New PdfTrueTypeFont(New Font("Arial", 16.0F, FontStyle.Bold))
Dim format2 As New PdfStringFormat(PdfTextAlignment.Center)
format2.CharacterSpacing = 1.0F
text = "Summary of Science"
page.Canvas.DrawString(text, font2, brush2, pageWidth / 2, y, format2)
size = font2.MeasureString(text, format2)
y = y + size.Height + 6
'icon
Dim image As PdfImage = PdfImage.FromFile("Wikipedia_Science.png")
page.Canvas.DrawImage(image, New PointF(pageWidth - image.PhysicalDimension.Width, y))
Dim imageLeftSpace As Single = pageWidth - image.PhysicalDimension.Width - 2
Dim imageBottom As Single = image.PhysicalDimension.Height + y
'refenrence content
Dim font3 As New PdfTrueTypeFont(New Font("Arial", 9.0F))
Dim format3 As New PdfStringFormat()
format3.ParagraphIndent = font3.Size * 2
format3.MeasureTrailingSpaces = True
format3.LineSpacing = font3.Size * 1.5F
Dim text1 As String = "(All text and picture from "
Dim text2 As String = "Wikipedia"
Dim text3 As String = ", the free encyclopedia)"
page.Canvas.DrawString(text1, font3, brush2, 0, y, format3)
size = font3.MeasureString(text1, format3)
Dim x1 As Single = size.Width
format3.ParagraphIndent = 0
Dim font4 As New PdfTrueTypeFont(New Font("Arial", 9.0F, FontStyle.Underline))
Dim brush3 As PdfBrush = PdfBrushes.Blue
page.Canvas.DrawString(text2, font4, brush3, x1, y, format3)
size = font4.MeasureString(text2, format3)
x1 = x1 + size.Width
page.Canvas.DrawString(text3, font3, brush2, x1, y, format3)
y = y + size.Height
'content
Dim format4 As New PdfStringFormat()
text = System.IO.File.ReadAllText("Summary_of_Science.txt")
Dim font5 As New PdfTrueTypeFont(New Font("Arial", 10.0F))
format4.LineSpacing = font5.Size * 1.5F
Dim textLayouter As New PdfStringLayouter()
Dim imageLeftBlockHeight As Single = imageBottom - y
Dim result As PdfStringLayoutResult _
= textLayouter.Layout(text, font5, format4, New SizeF(imageLeftSpace, imageLeftBlockHeight))
If result.ActualSize.Height < imageBottom - y Then
imageLeftBlockHeight = imageLeftBlockHeight + result.LineHeight
result = textLayouter.Layout(text, font5, format4, New SizeF(imageLeftSpace, imageLeftBlockHeight))
End If
For Each line As LineInfo In result.Lines
page.Canvas.DrawString(line.Text, font5, brush2, 0, y, format4)
y = y + result.LineHeight
Next line
Dim textWidget As New PdfTextWidget(result.Remainder, font5, brush2)
Dim textLayout As New PdfTextLayout()
textLayout.Break = PdfLayoutBreakType.FitPage
textLayout.Layout = PdfLayoutType.Paginate
Dim bounds As New RectangleF(New PointF(0, y), page.Canvas.ClientSize)
textWidget.StringFormat = format4
textWidget.Draw(page, bounds, textLayout)
End Sub
End Class
End Namespace



