
Knowledgebase (2370)
Children categories
Convert PDF to PDF/A and Vice Versa with JavaScript in React
2026-07-17 02:47:13 Written by Nina TangPDF/A is an ISO-standardized long-term archival format that embeds fonts, color profiles, and metadata into a unified compliance level, ensuring documents remain faithfully reproducible for decades regardless of the PDF reader used. In contrast, standard PDF offers greater flexibility for everyday editing and content extraction. Real-world business often requires switching between these two formats: converting contracts to PDF/A for regulatory compliance during archiving, and restoring them to standard PDF for text extraction during audit review.
Spire.PDF for JavaScript performs bidirectional PDF/PDF/A conversion entirely in the browser via WebAssembly, managing input and output files through a virtual file system (VFS) with no backend server required.
This article covers two core features:
For installation and project setup, refer to Integrating Spire.PDF for JavaScript in a React Project. The examples below assume Spire.PDF is installed and the WebAssembly module is initialized.
Convert PDF to PDF/A
The core of PDF/A archival conversion is to consolidate fonts, color profiles, and metadata in a standard PDF into ISO-compliant levels. Spire.PDF handles this in one step through the PdfStandardsConverter component, supporting multiple compliance levels including PDF/A-1a, PDF/A-1b, PDF/A-2a, PDF/A-2b, PDF/A-3a, and PDF/A-3b.
The conversion standards supported by PdfStandardsConverter and their use cases are as follows:
| Method | Standard | Description |
|---|---|---|
ToPdfA1B |
PDF/A-1b | Based on PDF 1.4, guarantees visual appearance reproducibility only — the most commonly used archival level |
ToPdfA1A |
PDF/A-1a | Requires document tags and structure information on top of 1b, supports accessible reading |
ToPdfA2A |
PDF/A-2a | Based on PDF 1.7, requires tags and structure info, supports layers and transparency |
ToPdfA2B |
PDF/A-2b | PDF/A-2 basic conformance level, allows transparency, layers, and embedded OLE objects |
ToPdfA3A |
PDF/A-3a | Allows embedding XML, Excel, and other arbitrary format files as attachments on top of 2a |
ToPdfA3B |
PDF/A-3b | PDF/A-3 basic conformance level, supports embedding arbitrary format attachments |
ToPdfX1A2001 |
PDF/X-1a:2001 | Print exchange standard, suitable for publishing and printing workflows |
The following example demonstrates converting a PDF to PDF/A-2B using ToPdfA2B:
function App() {
const convertToPDFA = async () => {
// Get the Spire.PDF WASM module
const pdfModule = window.wasmModule?.spirepdf;
// Check if the WASM module is ready
if (!pdfModule) {
alert('Spire.PDF is not ready yet');
return;
}
// Load fonts and PDF file into VFS
await window.spire.FetchFileToVFS('arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/font/`);
const inputFileName = 'MovieCatalog.pdf';
await window.spire.FetchFileToVFS(inputFileName, "", `${process.env.PUBLIC_URL}/data/`);
// Create PdfStandardsConverter
let converter = new pdfModule.PdfStandardsConverter({ filePath: inputFileName });
// Convert to PDF/A-2B format
const outputFileName = 'ToPDFA_result.pdf';
converter.ToPdfA2B({ filePath: outputFileName });
// // Convert to PDF/A-1a
// converter.ToPdfA1A({ filePath: outputFileName });
// // Convert to PDF/A-2a
// converter.ToPdfA2A({ filePath: outputFileName });
// // Convert to PDF/A-2b
// converter.ToPdfA2B({ filePath: outputFileName });
// // Convert to PDF/A-3a
// converter.ToPdfA3A({ filePath: outputFileName });
// // Convert to PDF/A-3b
// converter.ToPdfA3B({ filePath: outputFileName });
// // Convert to PDF/X-1a:2001
// converter.ToPdfX1A2001({ filePath: outputFileName });
// Read the converted file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/pdf' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release resources
converter.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert PDF To PDF/A</h1>
<button onClick={convertToPDFA}>
Generate
</button>
</div>
);
}
export default App;
PDF/A output generated after conversion via PdfStandardsConverter
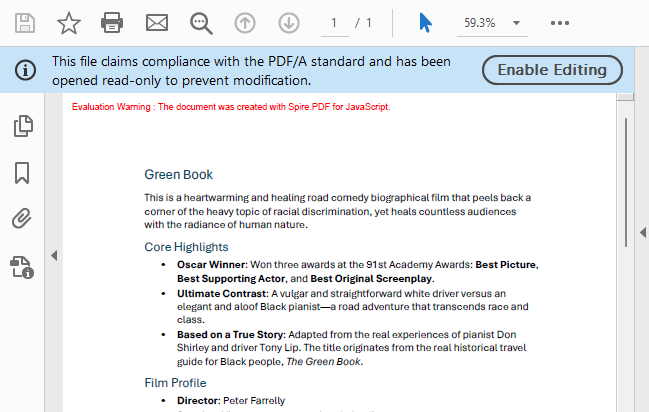
Convert PDF/A to PDF
PDF/A is the standard format for long-term archiving, but in everyday editing and content extraction scenarios, you may need to restore PDF/A back to standard PDF. Spire.PDF for JavaScript achieves this reverse conversion by loading the PDF/A document and copying content page by page into a new document, ensuring the output standard PDF is free of PDF/A compliance constraints.
function App() {
const convertToNormalPDF = async () => {
// Get the Spire.PDF WASM module
const pdfModule = window.wasmModule?.spirepdf;
// Check if the WASM module is ready
if (!pdfModule) {
alert('Spire.PDF is not ready yet');
return;
}
// Load fonts and PDF file into VFS
await window.spire.FetchFileToVFS('arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/font/`);
const inputFileName = 'PDFA_Sample.pdf';
await window.spire.FetchFileToVFS(inputFileName, "", `${process.env.PUBLIC_URL}/data/`);
// Create PdfDocument object
let doc = new pdfModule.PdfDocument();
doc.LoadFromFile(inputFileName);
// Create a new PDF document to draw content onto
let newDoc = new pdfModule.PdfNewDocument();
newDoc.CompressionLevel = pdfModule.PdfCompressionLevel.None;
// Iterate through each page in the original document
for (let i = 0; i < doc.Pages.Count; i++) {
let page = doc.Pages.get_Item(i);
// Get the current page size
let size = page.Size;
// Add a new page with the same size and no margins
let newPage = newDoc.Pages.Add({ size: size, margins: new pdfModule.PdfMargins() });
// Draw the original page content onto the new page
let template = page.CreateTemplate();
let layoutWidget = new pdfModule.PdfLayoutWidget(template.H);
layoutWidget.Draw({ page: newPage, x: 0, y: 0 });
// page.CreateTemplate().Draw({page: newPage, x: 0, y: 0});
}
// Define the output file name
const outputFileName = "PDFAToPdf_result.pdf";
// Save the document to the specified path
newDoc.Save(outputFileName);
// Read the generated file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/pdf' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release resources
newDoc.Dispose();
doc.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert PDF/A To Normal PDF</h1>
<button onClick={convertToNormalPDF}>
Generate
</button>
</div>
);
}
export default App;
Standard PDF output generated by creating a new document and copying pages

FAQ
Converted PDF/A file size is much larger than the original
PDF/A requires all fonts used in the document to be fully embedded to ensure correct rendering on any device. If the original document uses non-embedded system fonts, the font data will be written completely into the output file during conversion, resulting in a larger file size. This is an inherent requirement of PDF/A compliance. To minimize file size, consider using font subsetting (embedding only the characters actually used) or compressing image content before generating the source PDF.
Can encrypted PDFs be converted to PDF/A?
Encrypted PDFs that require a password to open cannot be processed directly by PdfStandardsConverter. The password must be provided when loading the document.
The PdfStandardsConverter constructor supports a password parameter for converting password-protected PDFs to PDF/A:
// Create PdfStandardsConverter with password
let converter = new pdfModule.PdfStandardsConverter({ filePath: inputFileName, password: "123456" });
converter.ToPdfA2A({ filePath: outputFileName });
converter.Dispose();
"File not found" or "Invalid PDF format" error when loading PDF/A
PDF/A documents must first be converted via PdfStandardsConverter, or properly loaded into the virtual file system (VFS) via FetchFileToVFS. Common mistakes include passing the wrong file name or path, or executing subsequent operations before the file has finished loading. Verify that the file has been loaded into VFS via FetchFileToVFS and that the file name (including extension) matches exactly. Use await to ensure the file is ready before proceeding.
Get a Free License
Spire.PDF for JavaScript offers a 30-day full-featured free trial license with no functional limitations. Apply here to evaluate before purchasing.
Get, Replace, Delete Word Bookmark Content and Insert Elements with JavaScript in React
2026-07-17 02:45:00 Written by Nina TangBookmarks are invisible positioning markers in Word documents that act as coordinates, precisely marking a location or a range of text. But the true value of bookmarks goes beyond positioning—by programmatically retrieving content within a bookmark range, replacing placeholder text, removing unwanted content, or inserting text, paragraphs, tables, and images at bookmark positions, developers can implement advanced document processing workflows such as automatic contract template filling, dynamic report data injection, and batch form content cleanup. The combination of "read, write, delete, and insert" operations around bookmark content forms the core of Word automation.
Spire.Doc for JavaScript runs entirely in the browser via WebAssembly, handling bookmark content retrieval, replacement, deletion, and element insertion directly — all managed through a virtual file system (VFS) with no backend server required.
This article covers four core features:
- Get Bookmark Content
- Replace Bookmark Content
- Delete Bookmark Content
- Insert Text, Paragraphs, Tables, and Images at a Bookmark
For installation and project setup, refer to Integrating Spire.Doc for JavaScript in a React Project. The examples below assume Spire.Doc is installed and the WebAssembly module is initialized.
Get Bookmark Content
Getting bookmark content is the prerequisite for any bookmark operation. After locating a bookmark with BookmarksNavigator, the GetBookmarkContent method returns the content within the bookmark range as a TextBodyPart object, which developers can iterate through its BodyItems collection to retrieve elements.
function App() {
const bookmarkContent = async () => {
// Get the Spire.Doc WASM module
const docModule = window.wasmModule?.spiredoc;
// Check if the WASM module is ready
if (!docModule) {
alert('Spire.Doc is not ready yet');
return;
}
// Load the Word file into VFS
const inputFileName = 'ContractTemplate_en.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/data/`);
// Load the Word document
const doc = new docModule.Document();
doc.LoadFromFile(inputFileName);
// Create a BookmarksNavigator and move to the bookmark
let navigator = new docModule.BookmarksNavigator(doc);
navigator.MoveToBookmark("myBookmark");
let textBodyPart = navigator.GetBookmarkContent();
// Iterate through elements in the bookmark content and extract text
let text = "";
for (let i = 0; i < textBodyPart.BodyItems.Count; i++) {
let item = textBodyPart.BodyItems.get_Item(i);
if (item instanceof docModule.Paragraph) {
for (let j = 0; j < item.ChildObjects.Count; j++) {
let childObject = item.ChildObjects.get_Item(j);
if (childObject instanceof docModule.TextRange) {
text += childObject.Text;
}
}
}
}
// Save as a .txt file
const outputFileName = "GetBookmarkContent.txt";
// Write the text file to VFS and trigger download
window.dotnetRuntime.Module.FS.writeFile(outputFileName, text);
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'text/plain' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release resources
doc.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Get Bookmark Content from Word Document</h1>
<button onClick={bookmarkContent}>
Generate
</button>
</div>
);
}
export default App;
Executing the code above extracts the text content from the bookmark "myBookmark" and saves it as a separate .txt file:
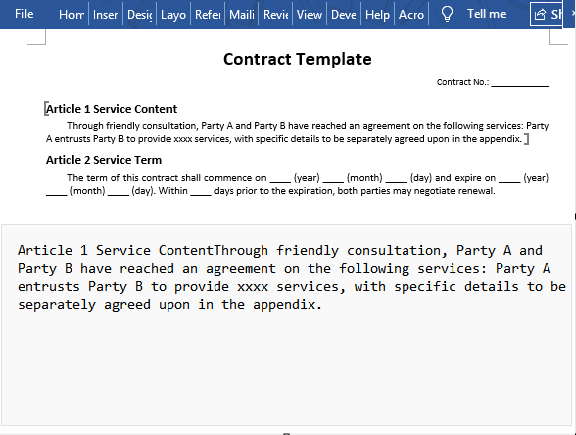
Replace Bookmark Content
Replacing bookmark content is the most common operation in document template filling. After locating a bookmark with BookmarksNavigator, the ReplaceBookmarkContent method supports replacement with both plain text and complex elements like tables, making it ideal for placeholder replacement in contract generation, report filling, and similar scenarios.
function App() {
const replaceBookmarkContent = async () => {
// Get the Spire.Doc WASM module
const docModule = window.wasmModule?.spiredoc;
// Check if the WASM module is ready
if (!docModule) {
alert('Spire.Doc is not ready yet');
return;
}
// Load fonts and Word file into VFS
await window.spire.FetchFileToVFS('ARIAL.TTF', '/Library/Fonts/', `${process.env.PUBLIC_URL}/font/`);
const inputFileName = 'BookmarkSample.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/data/`);
// Load the Word document
const doc = new docModule.Document();
doc.LoadFromFile(inputFileName);
// Create a BookmarksNavigator and move to the bookmark
let navigator = new docModule.BookmarksNavigator(doc);
navigator.MoveToBookmark("Bookmark1");
// Replace the content of "书签1" — with text
navigator.ReplaceBookmarkContent({ text: "This is the text that will replace the bookmark.", saveFormatting: true });
// Continue to replace "书签2" — with a table
navigator.MoveToBookmark("Bookmark2");
// Create a table
let table = new docModule.Table(doc, true);
table.ResetCells(4, 5);
// Create data and fill it into the table
let dt = [
["City", "Province", "Population", "Area (km²)", "Abbrev."],
["Beijing", "Beijing", "21.89M", "16410", "BJ"],
["Shanghai", "Shanghai", "24.75M", "6340", "SH"],
["Guangzhou", "Guangdong", "18.67M", "7434", "GZ"]];
for (let i = 0; i < 4; i++) {
for (let j = 0; j < 5; j++) {
table.Rows.get_Item(i).Cells.get_Item(j).AddParagraph().AppendText(dt[i][j]);
}
}
// Create a TextBodyPart instance and add the table to it
let part = new docModule.TextBodyPart({ doc: doc });
part.BodyItems.Add(table);
// Replace the current bookmark content with the TextBodyPart
navigator.ReplaceBookmarkContent({ bodyPart: part });
// Save as a new .docx file
const outputFileName = "ReplaceBookmark.docx";
doc.SaveToFile({ fileName: outputFileName, fileFormat: docModule.FileFormat.Docx2013 });
// Read the generated file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release resources
doc.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Replace Bookmark Content in Word</h1>
<button onClick={replaceBookmarkContent}>
Generate
</button>
</div>
);
}
export default App;
This method supports replacing bookmark content with plain text or complex elements like tables. The bookmark marker itself is preserved after replacement, making it easy to locate again later. The figure below shows the result:

Delete Bookmark Content
Deleting bookmark content and removing a bookmark marker are two different operations. After locating a bookmark with BookmarksNavigator, calling DeleteBookmarkContent removes the text content within the bookmark range while preserving the bookmark marker itself for later refilling. If you only need to clear the content while keeping the positioning marker, this method is the preferred choice.
function App() {
const deleteBookmarkContent = async () => {
// Get the Spire.Doc WASM module
const docModule = window.wasmModule?.spiredoc;
// Check if the WASM module is ready
if (!docModule) {
alert('Spire.Doc is not ready yet');
return;
}
// Load the Word file into VFS
const inputFileName = 'ContractTemplate_en.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/data/`);
// Load the Word document
const doc = new docModule.Document();
doc.LoadFromFile(inputFileName);
// Create a BookmarksNavigator and move to the bookmark
let navigator = new docModule.BookmarksNavigator(doc);
navigator.MoveToBookmark("myBookmark");
// Delete bookmark content, keep the bookmark marker
navigator.DeleteBookmarkContent(true);
// Save as a new .docx file
const outputFileName = "RemoveBookmark.docx";
doc.SaveToFile({ fileName: outputFileName, fileFormat: docModule.FileFormat.Docx2013 });
// Read the generated file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release resources
doc.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Delete Bookmark Content in Word</h1>
<button onClick={deleteBookmarkContent}>
Generate
</button>
</div>
);
}
export default App;
DeleteBookmarkContentremoves only the text content within the bookmark range — the bookmark marker itself remains.Bookmarks.Remove, on the other hand, removes the bookmark marker, leaving the text within the range unaffected.
After execution, the text within the bookmark "myBookmark" is removed, but the bookmark marker stays in the document:
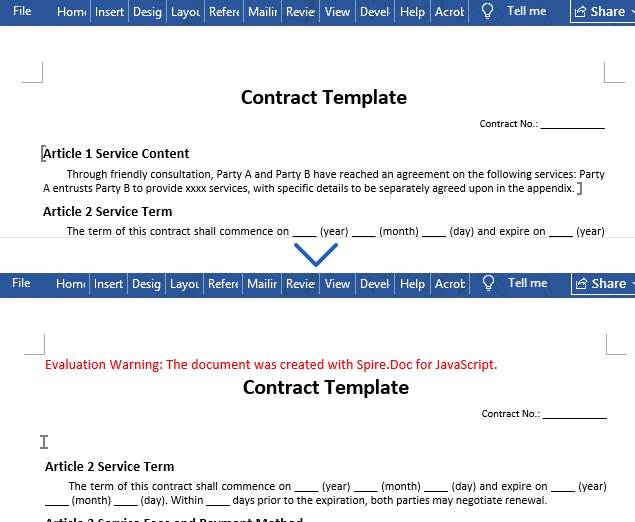
Insert Text, Paragraphs, Tables, and Images at a Bookmark
Spire.Doc supports flexibly inserting various types of document elements at bookmark positions. It provides InsertText, InsertParagraph, and InsertTable methods for inserting text, paragraphs, and tables. Elements can also be inserted based on the index of the bookmark start node within the paragraph's ChildObjects collection.
function App() {
const insertElementsAtBookmark = async () => {
// Get the Spire.Doc WASM module
const docModule = window.wasmModule?.spiredoc;
// Check if the WASM module is ready
if (!docModule) {
alert('Spire.Doc is not ready yet');
return;
}
// Load fonts and Word file into VFS
await window.spire.FetchFileToVFS('ARIAL.TTF', '/Library/Fonts/', `${process.env.PUBLIC_URL}/font/`);
const inputFileName = 'BookmarkSample1.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/data/`);
// Create a Document object and load the file
const doc = new docModule.Document();
doc.LoadFromFile(inputFileName);
// Move to the bookmark position
let navigator = new docModule.BookmarksNavigator(doc);
navigator.MoveToBookmark("Bookmark1");
// 1. Insert text
navigator.InsertText("This is the inserted text content.", true);
// 2. Insert paragraph
let newParagraph = new docModule.Paragraph(doc);
newParagraph.AppendText("This is the inserted paragraph content.")
navigator.MoveToBookmark("Bookmark2");
navigator.InsertParagraph(newParagraph);
// 3. Insert table — 2 rows, 3 columns
let table = new docModule.Table(doc, true);
table.ResetCells(2, 3);
table.Rows.get_Item(0).Cells.get_Item(0).AddParagraph().AppendText("Name");
table.Rows.get_Item(0).Cells.get_Item(1).AddParagraph().AppendText("Quantity");
table.Rows.get_Item(0).Cells.get_Item(2).AddParagraph().AppendText("Note");
table.Rows.get_Item(1).Cells.get_Item(0).AddParagraph().AppendText("Product A");
table.Rows.get_Item(1).Cells.get_Item(1).AddParagraph().AppendText("100");
table.Rows.get_Item(1).Cells.get_Item(2).AddParagraph().AppendText("In Stock");
navigator.MoveToBookmark("Bookmark3");
navigator.InsertTable(table);
// 4. Insert image
const imageFileName = 'pic.png';
await window.spire.FetchFileToVFS(imageFileName, '', `${process.env.PUBLIC_URL}/data/`);
let picture = new docModule.DocPicture(doc);
picture.LoadImage(imageFileName);
picture.Width = 100;
picture.Height = 200;
navigator.MoveToBookmark("Bookmark4");
// Get the bookmark start node
let start = navigator.CurrentBookmark.BookmarkStart;
// Get the paragraph containing the bookmark
let bookmarkPara = start.OwnerParagraph;
// Get the index of the bookmark start node in the paragraph
let startIndex = bookmarkPara.ChildObjects.IndexOf(start);
// Insert the image after the bookmark start node
bookmarkPara.ChildObjects.Insert(startIndex + 1, picture);
// Save as a .docx file
const outputFileName = "InsertToBookmark.docx";
doc.SaveToFile({ fileName: outputFileName, fileFormat: docModule.FileFormat.Docx2013 });
// Read the generated file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release Document resources
doc.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Insert Elements at Bookmark Position</h1>
<button onClick={insertElementsAtBookmark}>
Generate
</button>
</div>
);
}
export default App;
The figure below shows the generated document with text, paragraph, table, and image inserted at bookmark positions:
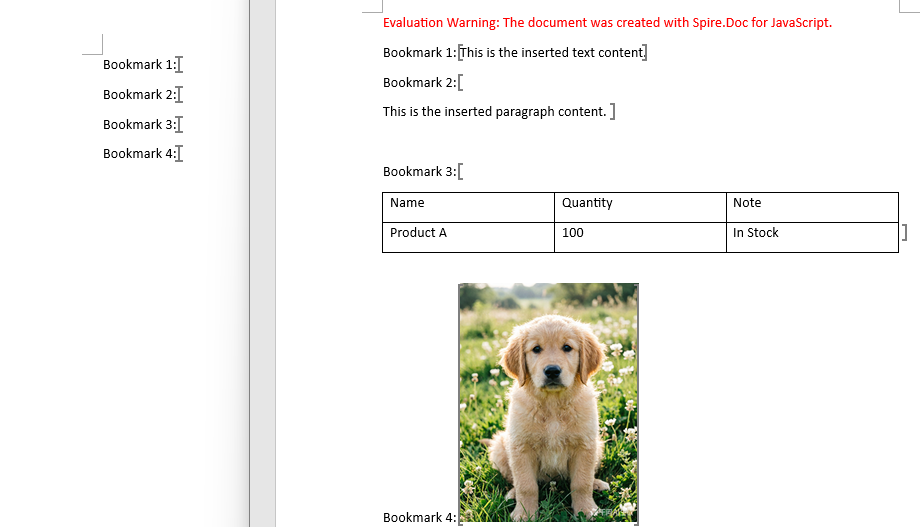
FAQ
Formatting (font, size, color) is lost after replacing bookmark content — how to keep it?
ReplaceBookmarkContent replaces with plain text by default, discarding the original formatting. To preserve the bookmark's existing formatting, pass saveFormatting: true:
navigator.ReplaceBookmarkContent({ text: "New content", saveFormatting: true });
The replacement text will then inherit the original font, size, color, and other formatting from the bookmark.
How to batch process multiple bookmarks in a document?
Iterate through the doc.Bookmarks collection, locating and operating on each bookmark one by one:
for (let i = 0; i < doc.Bookmarks.Count; i++) {
let bookmark = doc.Bookmarks.get_Item(i);
navigator.MoveToBookmark(bookmark.Name);
// Perform replace, delete, or insert operations
}
What's the difference between DeleteBookmarkContent and removing a bookmark marker?
DeleteBookmarkContent: Clears only the content within the bookmark range. The bookmark marker stays in the document, so you can still locate it by name and fill in new content later.Bookmarks.Remove: Removes the bookmark marker itself. The content within the bookmark range is unaffected, but the bookmark name disappears and can no longer be located.
Choose the appropriate operation based on your needs: use DeleteBookmarkContent if you need to keep the "placeholder" capability, or remove the marker if the bookmark is no longer needed.
When inserting multiple elements at the same bookmark, why does only the last one take effect?
Methods like InsertText, InsertParagraph, and InsertTable insert based on the bookmark's current position. When inserting multiple times at the same bookmark, subsequent insertions may overwrite or shift previously inserted content. It is recommended to use separate bookmarks for each insertion, or re-locate the bookmark after each insert before proceeding with the next operation.
Get a Free License
Spire.Doc for JavaScript offers a 30-day full-featured free trial license with no functional limitations. Apply here to evaluate before purchasing.
Bookmarks are invisible positioning markers in Word documents that act as coordinates, precisely marking a location or a range of text. Whether it's a fill-in area in a contract template, a key section to jump to in a long document, or a data insertion point when generating reports in batch, bookmarks are the critical anchor behind these operations. Developers can use bookmarks for dynamic content filling, navigation, content extraction, and other advanced features, making bookmark management one of the most commonly used capabilities in Word automation.
Spire.Doc for JavaScript runs entirely in the browser via WebAssembly, handling bookmark creation, navigation, and deletion directly — all managed through a virtual file system (VFS) with no backend server required.
This article covers three core features:
For installation and project setup, refer to Integrating Spire.Doc for JavaScript in a React Project. The examples below assume Spire.Doc is installed and the WebAssembly module is initialized.
Add a Bookmark to a Paragraph
To add a bookmark in an existing document, use AppendBookmarkStart and AppendBookmarkEnd to mark the bookmark region on a paragraph. You can add bookmark markers to existing paragraphs or append a new paragraph with a bookmark. Spire.Doc also supports nested bookmarks for building hierarchical structures.
function App() {
const createBookmarkInWord = async () => {
// Get the Spire.Doc WASM module
const docModule = window.wasmModule?.spiredoc;
// Check if the module is ready
if (!docModule) {
alert('Spire.Doc is not ready yet');
return;
}
// Load the Word file into VFS
const inputFileName = 'ChinaTravelGuide.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/data/`);
// Load the document
const doc = new docModule.Document();
doc.LoadFromFile(inputFileName);
// Get the first section and add bookmarks
let section = doc.Sections.get_Item(0);
AddBookmark(section);
// Save as a .docx file
const outputFileName = "AddBookmark.docx";
doc.SaveToFile({ fileName: outputFileName, fileFormat: docModule.FileFormat.Docx2013 });
// Read the file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release resources
doc.Dispose();
};
function AddBookmark(section) {
// Bookmark 1: add bookmark markers around existing paragraphs
let paraStart = section.Paragraphs.get_Item(1);
let paraEnd = section.Paragraphs.get_Item(3);
paraStart.AppendBookmarkStart("Bookmark1");
paraEnd.AppendBookmarkEnd("Bookmark1");
// Bookmark 2: add a new paragraph with a bookmark
let paragraph = section.AddParagraph();
paragraph.AppendBookmarkStart("Bookmark2");
paragraph.AppendText("This is a new paragraph");
paragraph.AppendBookmarkEnd("Bookmark2");
}
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Add Bookmark in Word</h1>
<button onClick={createBookmarkInWord}>
Generate
</button>
</div>
);
}
export default App;
Bookmarks added to the generated Word document

Add a Bookmark to Selected Text
To add a bookmark to specific text within an existing paragraph, first locate the text with FindAllString, create bookmark objects using the BookmarkStart and BookmarkEnd constructors, then insert the start marker before and the end marker after the matched TextRange via ChildObjects.Insert.
function App() {
const addBookmarkForMatchedText = async () => {
// Get the Spire.Doc WASM module
const docModule = window.wasmModule?.spiredoc;
// Check if the WASM module is ready
if (!docModule) {
alert('Spire.Doc is not ready yet');
return;
}
// Load the Word file into VFS
const inputFileName = 'ChinaTravelGuide.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/data/`);
// Load the Word document
const doc = new docModule.Document();
doc.LoadFromFile(inputFileName);
// Find all occurrences of "Street" in the document
let textSelections = doc.FindAllString('Street', false, true);
// Iterate over each match and insert bookmark start/end markers
for (let i = 0; i < textSelections.length; i++) {
// Create bookmark start and end objects (named "Bookmark_0", "Bookmark_1", ...)
let start = new docModule.BookmarkStart(doc, "Bookmark_" + i);
let end = new docModule.BookmarkEnd(doc, "Bookmark_" + i);
let selection = textSelections[i];
// Get the TextRange of the matched text
let textRange = selection.GetAsOneRange();
// Get the paragraph containing the matched text
let para = textRange.OwnerParagraph;
// Get the index of the TextRange within the paragraph's child objects
let index = para.ChildObjects.IndexOf(textRange);
// Insert the bookmark start before the TextRange and the bookmark end after it
para.ChildObjects.Insert(index, start);
para.ChildObjects.Insert(index + 2, end);
}
// Save as a new .docx file
const outputFileName = "AddBookmark.docx";
doc.SaveToFile({ fileName: outputFileName, fileFormat: docModule.FileFormat.Docx2013 });
// Read the generated file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release document resources
doc.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Add Bookmarks for Specific Text in Word Documents</h1>
<button onClick={addBookmarkForMatchedText}>
Generate
</button>
</div>
);
}
export default App;
This approach is ideal for scenarios where you need to add positioning markers on top of an existing document, such as marking fill-in areas in a completed contract. The figure below shows the result after execution:
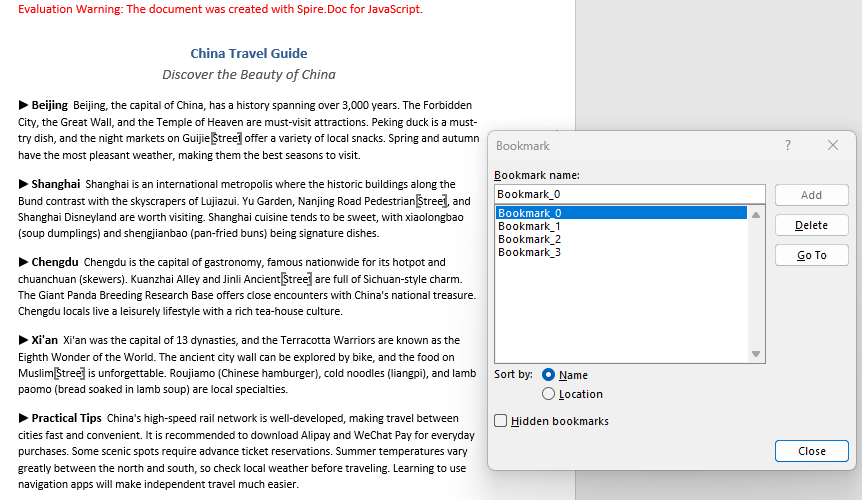
Remove a Bookmark
Removing a bookmark only removes the bookmark markers themselves — the text content within the bookmark range is preserved. Retrieve the bookmark object from the document.Bookmarks collection, then call the Remove method to delete it.
function App() {
const deleteBookmark = async () => {
// Get the Spire.Doc WASM module
const docModule = window.wasmModule?.spiredoc;
// Check if the WASM module is ready
if (!docModule) {
alert('Spire.Doc is not ready yet');
return;
}
// Load the Word file into VFS
const inputFileName = 'AddBookmark.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/data/`);
// Load the Word document
const doc = new docModule.Document();
doc.LoadFromFile(inputFileName);
// Get the bookmark by name
let bookmark = doc.Bookmarks.get_Item("Bookmark_1");
// // Get the bookmark by index
// let bookmark = doc.Bookmarks.get_Item(0);
// Remove the bookmark (keep its content)
doc.Bookmarks.Remove(bookmark);
// Save as a new .docx file
const outputFileName = "DeleteBookmark.docx";
doc.SaveToFile({ fileName: outputFileName, fileFormat: docModule.FileFormat.Docx2013 });
// Read the generated file from VFS and trigger download
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileArray], { type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
a.click();
URL.revokeObjectURL(url);
// Release document resources
doc.Dispose();
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Delete Bookmark in Word Document</h1>
<button onClick={deleteBookmark}>
Generate
</button>
</div>
);
}
export default App;
After the bookmark is removed, its markers disappear from the document, but the text within the bookmark range is preserved.
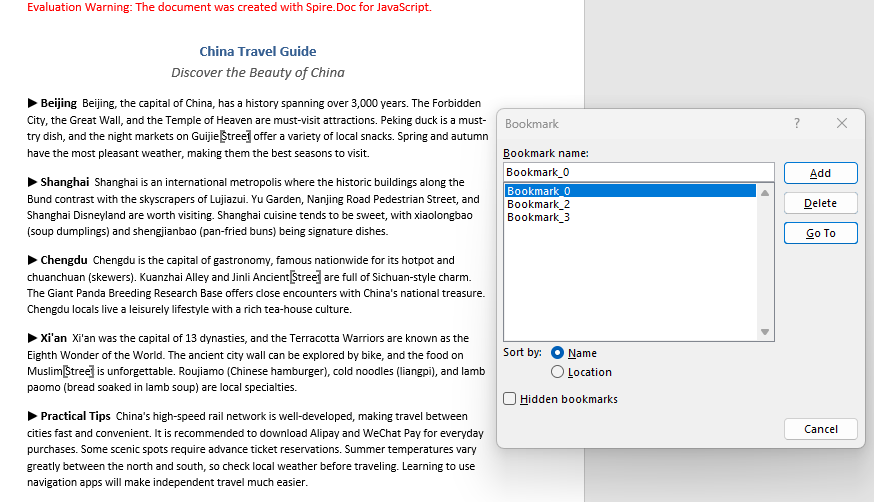
FAQ
Duplicate bookmark name error
Cause: Bookmark names must be unique within a Word document. Adding a bookmark with a duplicate name causes an error.
Solution: Check whether the name already exists before adding the bookmark:
if (document.Bookmarks.FindByName("MyBookmark") === null) {
paragraph.AppendBookmarkStart("MyBookmark");
paragraph.AppendText("Content");
paragraph.AppendBookmarkEnd("MyBookmark");
}
What is the difference between removing a bookmark and deleting its content?
Cause: Spire.Doc's Bookmarks.Remove only removes the bookmark markers (start and end), leaving the text content between them untouched.
Solution: Choose the appropriate operation based on your needs:
// Remove only the bookmark markers, keep the text
document.Bookmarks.Remove(bookmark);
// Remove the bookmark and its content (via BookmarksNavigator)
let navigator = new docModule.BookmarksNavigator(doc);
navigator.MoveToBookmark("MyBookmark");
navigator.DeleteBookmarkContent();
Do AppendBookmarkStart and AppendBookmarkEnd have to be on the same paragraph?
Cause: The start and end markers can be on different paragraphs — the "Bookmark1" example in the code above demonstrates cross-paragraph usage. The key constraint is that the document object structure within the bookmark range must remain intact. Bookmarks cannot span across table cells, since cells are independent containers and doing so may cause the bookmark to be unrecognized.
Solution: If the bookmark range crosses a table cell boundary, adjust the start or end position so that the bookmark closes within the same cell.
Get a Free License
Spire.Doc for JavaScript offers a 30-day full-featured free trial license with no functional limitations. Apply here to evaluate before purchasing.
More...
