
Program Guide (123)
Children categories
Generate PDFs from Templates in Java (HTML-to-PDF Explained)
2025-10-17 09:43:21 Written by zaki zou
In many Java applications, you’ll need to generate PDF documents dynamically — for example, invoices, reports, or certificates. Creating PDFs from scratch can be time-consuming and error-prone, especially with complex layouts or changing content. Using templates with placeholders that are replaced at runtime is a more maintainable and flexible approach, ensuring consistent styling while separating layout from data.
In this article, we’ll explore how to generate PDFs from templates in Java using Spire.PDF for Java, including practical examples for both HTML and PDF templates. We’ll also highlight best practices, common challenges, and tips for creating professional, data-driven PDFs efficiently.
Table of Contents
- Why Use Templates for PDF Generation
- Choosing the Right Template Format (HTML, PDF, or Word)
- Setting Up the Environment
- Generating PDFs from Templates in Java
- Best Practices for Template-Based PDF Generation
- Final Thoughts
- FAQs
Why Use Templates for PDF Generation
- Maintainability : Designers or non-developers can edit templates (HTML, PDF, or Word) without touching code.
- Separation of concerns : Your business logic is decoupled from document layout.
- Consistency : Templates enforce consistent styling, branding, and layout across all generated documents.
- Flexibility : You can switch or update templates without major code changes.
Choosing the Right Template Format (HTML, PDF, or Word)
Each template format has strengths and trade-offs. Understanding them helps you pick the best one for your use case.
| Template Format | Pros | Cons / Considerations | Ideal Use Cases |
|---|---|---|---|
| HTML | Full control over layout via CSS, tables, responsive design; easy to iterate | Needs an HTML-to-PDF conversion engine (e.g. Qt WebEngine, headless Chrome) | Invoices, reports, documents with variable-length content, tables, images |
| You can take an existing branded PDF and replace placeholders | Only supports simple inline text replacements (no reflow for multiline content) | Templates with fixed layout and limited dynamic fields (e.g. contracts, certificates) | |
| Word (DOCX) | Familiar to non-developers; supports rich editing | Requires library (like Spire.Doc) to replace placeholders and convert to PDF | Organizations with existing Word-based templates or documents maintained by non-technical staff |
In practice, for documents with rich layout and dynamic content, HTML templates are often the best choice. For documents where layout must be rigid and placeholders are few, PDF templates can suffice. And if your stakeholders prefer Word-based templates, converting from Word to PDF may be the most comfortable workflow.
Setting Up the Environment
Before you begin coding, set up your project for Spire.PDF (and possibly Spire.Doc) usage:
- Download / add dependency
- (If using HTML templates) Install HTML-to-PDF engine / plugin
Spire.PDF needs an external engine or plugin (e.g. Qt WebEngine or a headless Chrome /Chromium) to render HTML + CSS to PDF.
- Download the appropriate plugin for your platform (Windows x86, Windows x64, Linux, macOS).
- Unzip to a local folder and locate the plugins directory, e.g.: C:\plugins-windows-x64\plugins
- Configure the plugin path in code:
- Prepare your templates
To get started, download Spire.PDF for Java from our website and add the JAR files to your project's build path. If you’re using Maven, include the following dependency in your pom.xml.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
HtmlConverter.setPluginPath("C:\\plugins-windows-x64\\plugins");
- For HTML: define placeholders (e.g. {{PLACEHOLDER}}) in your template HTML / CSS.
- For PDF: build or procure a base PDF that includes placeholder text (e.g. {PROJECT_NAME}) in the spots you want replaced.
Generating PDFs from Templates in Java
From an HTML Template
Here’s how you can use Spire.PDF to convert an HTML template into a PDF document, replacing placeholders with actual data.
Sample Code (HTML → PDF)
import com.spire.pdf.graphics.PdfMargins;
import com.spire.pdf.htmlconverter.LoadHtmlType;
import com.spire.pdf.htmlconverter.qt.HtmlConverter;
import com.spire.pdf.htmlconverter.qt.Size;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.Map;
public class GeneratePdfFromHtmlTemplate {
public static void main(String[] args) throws Exception {
// Path to the HTML template file
String htmlFilePath = "template/invoice_template.html";
// Read HTML content from file
String htmlTemplate = new String(Files.readAllBytes(Paths.get(htmlFilePath)));
// Sample data for invoice
Map invoiceData = new HashMap<>();
invoiceData.put("INVOICE_NUMBER", "12345");
invoiceData.put("INVOICE_DATE", "2025-08-25");
invoiceData.put("BILLER_NAME", "John Doe");
invoiceData.put("BILLER_ADDRESS", "123 Main St, Anytown, USA");
invoiceData.put("BILLER_EMAIL", "johndoe@example.com");
invoiceData.put("ITEM_DESCRIPTION", "Consulting Services");
invoiceData.put("ITEM_QUANTITY", "10");
invoiceData.put("ITEM_UNIT_PRICE", "$100");
invoiceData.put("ITEM_TOTAL", "$1000");
invoiceData.put("SUBTOTAL", "$1000");
invoiceData.put("TAX_RATE", "5");
invoiceData.put("TAX", "$50");
invoiceData.put("TOTAL", "$1050");
// Replace placeholders with actual values
String populatedHtml = populateTemplate(htmlTemplate, invoiceData);
// Output PDF file
String outputFile = "output/Invoice.pdf";
// Set the QT plugin path for HTML conversion
HtmlConverter.setPluginPath("C:\\plugins-windows-x64\\plugins");
// Convert HTML string to PDF
HtmlConverter.convert(
populatedHtml,
outputFile,
true, // Enable JavaScript
100000, // Timeout (ms)
new Size(595, 842), // A4 size
new PdfMargins(20), // Margins
LoadHtmlType.Source_Code // Load HTML from string
);
System.out.println("PDF generated successfully: " + outputFile);
}
/**
* Replace placeholders in HTML template with actual values.
*/
private static String populateTemplate(String template, Map data) {
String result = template;
for (Map.Entry entry : data.entrySet()) {
result = result.replace("{{" + entry.getKey() + "}}", entry.getValue());
}
return result;
}
}How it work:
- Design an HTML file using CSS, tables, images, etc., with placeholders (e.g. {{NAME}}).
- Store data values in a Map<String, String>.
- Replace placeholders with actual values at runtime.
- Use HtmlConverter.convert to generate a styled PDF.
This approach works well when your content may grow or shrink (tables, paragraphs), because HTML rendering handles flow and wrapping.
Output:

From a PDF Template
If you already have a branded PDF template with placeholder text, you can open it and replace inline text within.
Sample Code (PDF placeholder replacement)
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextReplaceOptions;
import com.spire.pdf.texts.PdfTextReplacer;
import com.spire.pdf.texts.ReplaceActionType;
import java.util.EnumSet;
import java.util.HashMap;
import java.util.Map;
public class GeneratePdfFromPdfTemplate {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Template.pdf");
// Create a PdfTextReplaceOptions object and specify the options
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
textReplaceOptions.setReplaceType(EnumSet.of(ReplaceActionType.WholeWord));
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Create a PdfTextReplacer object based on the page
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
textReplacer.setOptions(textReplaceOptions);
// Dictionary for old and new strings
Map<String, String> replacements = new HashMap<>();
replacements.put("{PROJECT_NAME}", "New Website Development");
replacements.put("{PROJECT_NO}", "2023-001");
replacements.put("{PROJECT MANAGER}", "Alice Johnson");
replacements.put("{PERIOD}", "Q3 2023");
replacements.put("{PERIOD}", "Q3 2023");
replacements.put("{START_DATE}", "Jul 1, 2023");
replacements.put("{END_DATE}", "Sep 30, 2023");
// Loop through the dictionary to replace text
for (Map.Entry<String, String> pair : replacements.entrySet()) {
textReplacer.replaceText(pair.getKey(), pair.getValue());
}
// Save the document to a different PDF file
doc.saveToFile("output/FromPdfTemplate.pdf");
doc.dispose();
}
}
How it works:
- Load an existing PDF template .
- Use PdfTextReplacer to find and replace placeholder text.
- Save the updated file as a new PDF.
This method works only for inline, simple text replacement . It does not reflow or adjust layout if the replacement text is longer or shorter.
Output:

Best Practices for Template-Based PDF Generation
Here are some tips and guidelines to ensure reliability, maintainability, and quality of your generated PDFs:
- Use HTML templates for rich content : If your document includes tables, variable-length sections, images, or requires responsive layouts, HTML templates offer more flexibility.
- Use PDF templates for stable, fixed layouts : When your document layout is tightly controlled and only a few placeholders change, PDF templates can save you the effort of converting HTML.
- Support Word templates if your team relies on them : If your design team uses Word, use Spire.Doc for Java to replace placeholders in DOCX and export to PDF.
- Unique placeholder markers : Use distinct delimiters (e.g. {FIELD_NAME}, or {FIELD_DATE}) to avoid accidental partial replacements.
- Keep templates external and versioned : Don’t embed template strings in code. Store them in resource files or external directories.
- Test with real data sets : Use realistic data to validate layout — e.g. long names, large tables, multilingual text.
Final Thoughts
Generating PDFs from templates is a powerful, maintainable approach — especially in Java applications. Depending on your needs:
- Use HTML templates when you require dynamic layout, variable-length content, and rich styling.
- Use PDF templates when your layout is fixed and you only need to swap a few fields.
- Leverage Word templates (via Spire.Doc) if your team already operates in that environment.
By combining a clean template system with Spire.PDF (and optionally Spire.Doc), you can produce high-quality, data-driven PDFs in a maintainable, scalable way.
FAQs
Q1. Can I use Word templates (DOCX) in Java for PDF generation?
Yes. Use Spire.Doc for Java to load a Word document, replace placeholders, and export to PDF. This workflow is convenient if your organization already maintains templates in Word.
Q2. Can I insert images or charts into templates?
Yes. Whether you generate PDFs from HTML templates or modify PDF templates, you can embed images, charts, shapes, etc. Just ensure your placeholders or template structure allow space for them.
Q3. Why do I need Qt WebEngine or Chrome for HTML-to-PDF conversion?
The HTML-to-PDF conversion must render CSS, fonts, and layout precisely. Spire.PDF delegates the heavy lifting to an external engine (e.g. Qt WebEngine or Chrome). Without a plugin, styles may not render correctly.
Q4. Does Spire.PDF support multiple languages / international text in templates?
Yes. Spire.PDF supports Unicode and can render multilingual content (English, Chinese, Arabic, etc.) without losing formatting.
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
Modify or Edit PDF Files in Java: Practical Code Examples Included
2025-10-15 09:35:00 Written by zaki zou
Working with PDF files is a common requirement in many Java applications—whether you’re generating invoices, modifying contracts, or adding annotations to reports. While the PDF format is reliable for sharing documents, editing it programmatically can be tricky without the right library.
In this tutorial, you’ll learn how to add, replace, remove, and secure content in a PDF file using Spire.PDF for Java , a comprehensive and developer-friendly PDF API. We’ll walk through examples of adding pages, text, images, tables, annotations, replacing content, deleting elements, and securing files with watermarks and passwords.
Table of Contents:
- Why Use Spire.PDF to Edit PDF in Java
- Setting Up Your Java Environment
- Adding Content to a PDF File
- Replacing Content in a PDF File
- Removing Content from a PDF File
- Securing Your PDF File
- Conclusion
- FAQs About Editing PDF in Java
Why Use Spire.PDF to Edit PDF in Java
Spire.PDF offers a comprehensive set of features that make it an excellent choice for developers looking to work with PDF files in Java. Here are some reasons why you should consider using Spire.PDF:
- Ease of Use : The API is straightforward and intuitive, allowing you to perform complex operations with minimal code.
- Rich Features : Spire.PDF supports a wide range of functionalities, including text and image manipulation, page management, and security features.
- High Performance : The library is optimized for performance, ensuring that even large PDF files can be processed quickly.
- No Dependencies : Spire.PDF is a standalone library, meaning you won’t have to include any additional dependencies in your project.
By leveraging Spire.PDF, you can easily handle PDF files without getting bogged down in the complexities of the format itself.
Setting Up Your Java Environment
Installation
To begin using Spire.PDF, you'll first need to add it to your project. You can download the library from its official website or include it via Maven:
For Maven users:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.9.6</version>
</dependency>
</dependencies>
For manual setup:
Download Spire.PDF for Java from the official website and add the JAR file to your project’s classpath.
Initiate Document Loading
Once you have the library set up, you can start loading PDF documents. Here’s how to do it:
PdfDocument doc = new PdfDocument();
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\sample.pdf");
This snippet initializes a new PdfDocument object and loads a PDF file from the specified path. By calling loadFromFile , you prepare the document for further editing.
Adding Content to a PDF File in Java
Add a New Page
Adding a new page to an existing PDF document is quite simple. Here’s how you can do it:
// Add a new page
PdfPageBase new_page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(54));
// Draw text or do other operations on the page
new_page.getCanvas().drawString("This is a Newly-Added Page.", new PdfTrueTypeFont(new Font("Times New Roman",Font.PLAIN,18)), PdfBrushes.getBlue(), 0, 0);
In this code, we create a new page with A4 size and specified margins using the add method. We then draw a string on the new page using a specified font and color. The drawString method places the text at the top-left corner of the page, allowing you to add content quickly.
Add Text to a PDF File
To insert text into a specific area of an existing page, use the following code:
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Define a rectangle for placing the text
Rectangle2D.Float rect = new Rectangle2D.Float(54, 300, (float) page.getActualSize().getWidth() - 108, 100);
// Create a brush and a font
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Times New Roman",Font.PLAIN,18));
// Draw text on the page at the specified area
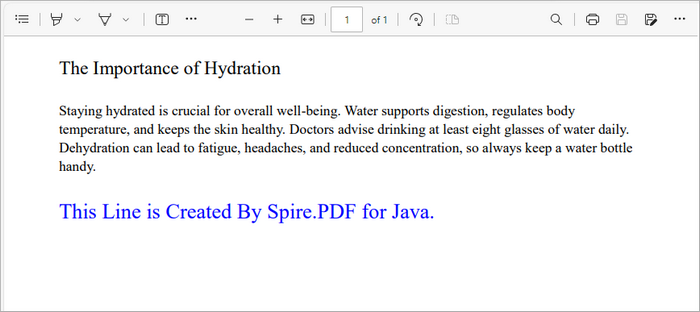
page.getCanvas().drawString("This Line is Created By Spire.PDF for Java.",font, brush, rect);
This snippet retrieves the first page of the document and defines a rectangle where the text will be placed. The Rectangle2D.Float class allows you to specify the exact dimensions for positioning the text. We then draw the specified text with a blue brush and custom font using the drawString method, which ensures that the text is rendered in the defined area.
Add an Image to a PDF File
Inserting images into a PDF is straightforward as well:
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Load an image
PdfImage image = PdfImage.fromFile("C:\\Users\\Administrator\\Desktop\\logo.png");
// Specify coordinates for adding image
float x = 54;
float y = 300;
// Draw image on the page at the specified coordinates
page.getCanvas().drawImage(image, x, y);
Here, we load an image from a specified file path and draw it on the first page at the defined coordinates (x, y). The drawImage method allows you to position the image precisely, making it easy to incorporate visuals into your document.
Add a Table to a PDF File
Adding tables is also supported in Spire.PDF:
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Create a table
PdfTable table = new PdfTable();
// Define table data
String[][] data = {
new String[]{"Name", "Age", "Country"},
new String[]{"Alice", "25", "USA"},
new String[]{"Bob", "30", "UK"},
new String[]{"Charlie", "28", "Canada"}
};
// Assign data to the table
table.setDataSource(data);
// Set table style
PdfTableStyle style = new PdfTableStyle();
style.getDefaultStyle().setFont(new PdfTrueTypeFont(new Font("Arial", Font.PLAIN, 12)));
table.setStyle(style);
// Draw the table on the page
table.draw(page, new Point2D.Float(50, 80));
In this example, we create a table and define its data source using a 2D array. After assigning the data, we set a style for the table using PdfTableStyle , which allows you to customize the font and appearance of the table. Finally, we use the draw method to render the table on the first page at the specified coordinates.
Add an Annotation or Comment
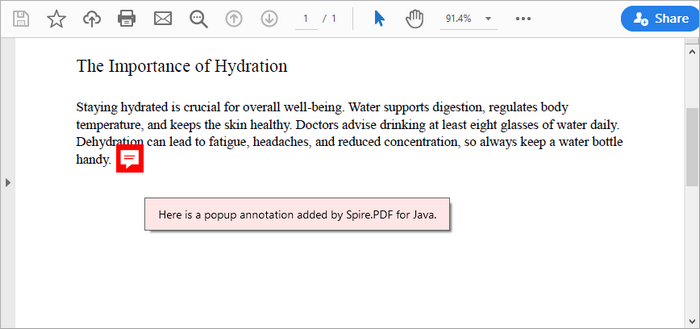
Annotations can enhance the interactivity of PDFs:
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Create a free text annotation
PdfPopupAnnotation popupAnnotation = new PdfPopupAnnotation();
popupAnnotation.setLocation(new Point2D.Double(90, 260));
// Set the content of the annotation
popupAnnotation.setText("Here is a popup annotation added by Spire.PDF for Java.");
// Set the icon and color of the annotation
popupAnnotation.setIcon(PdfPopupIcon.Comment);
popupAnnotation.setColor(new PdfRGBColor(Color.RED));
// Add the annotation to the collection of the annotations
page.getAnnotations().add(popupAnnotation);
This snippet creates a popup annotation at a specified location on the page. By calling setLocation , you definewhere the annotation appears. The setText method allows you to specify the content displayed in the annotation, while you can set the icon and color to customize its appearance. Finally, the annotation is added to the page's collection of annotations.
You may also like: Add Page Numbers to a PDF Document in Java
Replacing Content in a PDF File in Java
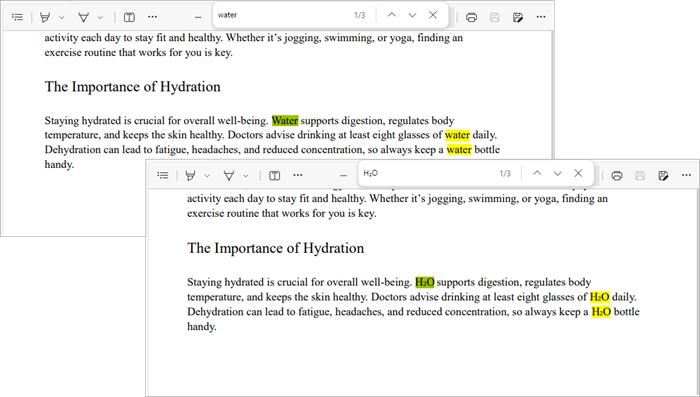
Replace Text in a PDF File
To replace existing text within a PDF, you can use the following code:
// Create a PdfTextReplaceOptions object
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
// Specify the options for text replacement
textReplaceOptions.setReplaceType(EnumSet.of(ReplaceActionType.IgnoreCase));
// Iterate through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Get a specific page
PdfPageBase page = doc.getPages().get(i);
// Create a PdfTextReplacer object based on the page
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
// Set the replace options
textReplacer.setOptions(textReplaceOptions);
// Replace all occurrences of target text with new text
textReplacer.replaceAllText("Water", "H₂O");
}
In this example, we create a PdfTextReplaceOptions object to specify replacement options, such as ignoring case sensitivity. We then iterate through all pages of the document, creating a PdfTextReplacer for each page. The replaceAllText method is called on the text replacer to replace all occurrences of "Water" with "H₂O".
Replace an Image in a PDF File
Replacing an image follows a similar pattern:
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Load an image
PdfImage image = PdfImage.fromFile("C:\\Users\\Administrator\\Desktop\\logo.png");
// Get the image information from the page
PdfImageHelper imageHelper = new PdfImageHelper();
PdfImageInfo[] imageInfo = imageHelper.getImagesInfo(page);
// Replace Image
imageHelper.replaceImage(imageInfo[0], image);
This code retrieves the image information from the specified page using the PdfImageHelper class. After loading a new image from a file, we call replaceImage to replace the first image found on the page with the new one.
You may also like: Replace Fonts in PDF Documents in Java
Removing Content from a PDF File in Java
Remove a Page from a PDF File
To remove an entire page from a PDF, use the following code:
// Remove a specific page
doc.getPages().removeAt(0);
This straightforward command removes the first page from the document. By calling removeAt , you specify the index of the page to be removed, simplifying page management in your PDF.
Delete an Image from a PDF File
To remove an image from a page:
// Get a specific page
PdfPageBase page = pdf.getPages().get(0);
// Get the image information from the page
PdfImageHelper imageHelper = new PdfImageHelper();
PdfImageInfo[] imageInfos = imageHelper.getImagesInfo(page);
// Delete the specified image on the page
imageHelper.deleteImage(imageInfos[0]);
This code retrieves all images from the first page and deletes the first image using the deleteImage method from PdfImageHelper .
Delete an Annotation
Removing an annotation is simple as well:
// Get a specific page
PdfPageBase page = pdf.getPages().get(0);
// Remove the specified annotation
page.getAnnotationsWidget().removeAt(0);
This snippet removes the first annotation from the specified page. The removeAt method is used to specify which annotation to remove, ensuring that the document can be kept clean and free of unnecessary comments.
Delete an Attachment
To delete an attachment from a PDF:
// Get the attachments collection
PdfAttachmentCollection attachments = doc.getAttachments();
// Remove a specific attachment
attachments.removeAt(0);
This code retrieves the collection of attachments from the document and removes the first one using the removeAt method.
Securing Your PDF File in Java
Apply a Watermark to a PDF File
Watermarks can be added for branding or copyright purposes:
// Create a font and a brush
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial Black", Font.PLAIN, 50), true);
PdfBrush brush = PdfBrushes.getBlue();
// Specify the watermark text
String watermarkText = "DO NOT COPY";
// Specify the opacity level
float opacity = 0.6f;
// Iterate through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
PdfPageBase page = doc.getPages().get(i);
// Set the transparency level for the watermark
page.getCanvas().setTransparency(opacity);
// Measure the size of the watermark text
Dimension2D textSize = font.measureString(watermarkText);
// Get the width and height of the page
double pageWidth = page.getActualSize().getWidth();
double pageHeight = page.getActualSize().getHeight();
// Calculate the position to center the watermark on the page
double x = (pageWidth - textSize.getWidth()) / 2;
double y = (pageHeight - textSize.getHeight()) / 2;
// Draw the watermark text on the page at the calculated position
page.getCanvas().drawString(watermarkText, font, brush, x, y);
}
This code configures the appearance of a text watermark and places it at the center of each page in a PDF file using the drawString method, effectively discouraging unauthorized copying.
Password Protect a PDF File
To secure your PDF with a password:
// Specify the user and owner passwords
String userPassword = "open_psd";
String ownerPassword = "permission_psd";
// Create a PdfSecurityPolicy object with the two passwords
PdfSecurityPolicy securityPolicy = new PdfPasswordSecurityPolicy(userPassword, ownerPassword);
// Set encryption algorithm
securityPolicy.setEncryptionAlgorithm(PdfEncryptionAlgorithm.AES_256);
// Set document permissions (If you do not set, the default is Forbid All)
securityPolicy.setDocumentPrivilege(PdfDocumentPrivilege.getAllowAll());
// Restrict editing
securityPolicy.getDocumentPrivilege().setAllowModifyContents(false);
securityPolicy.getDocumentPrivilege().setAllowCopyContentAccessibility(false);
securityPolicy.getDocumentPrivilege().setAllowContentCopying(false);
// Encrypt the PDF file
doc.encrypt(securityPolicy);
This code applies password protection and encryption to a PDF document by defining a user password (for opening) and an owner password (for permissions like editing and printing). The PdfSecurityPolicy object manages security settings, including the AES-256 encryption algorithm and permission levels. Finally, doc.encrypt(securityPolicy) encrypts the document, ensuring only authorized users can access or modify it.
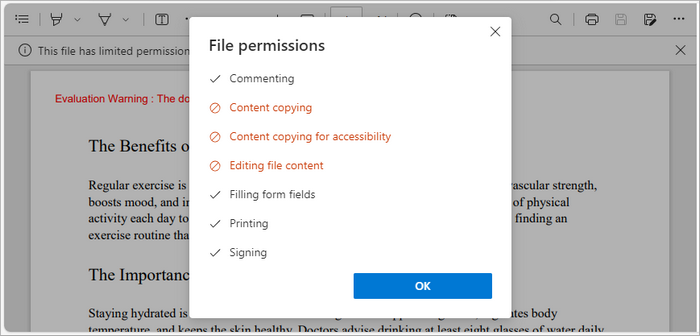
You may also like: How to Add Digital Signatures to PDF in Java
Conclusion
Editing PDF files in Java is often seen as challenging, but with Spire.PDF for Java, it becomes a straightforward and efficient process. This library provides developers with the flexibility to create, modify, replace, and secure PDF content using clean, easy-to-understand APIs. From adding pages and images to encrypting sensitive documents, Spire.PDF simplifies every step of the workflow while maintaining professional output quality.
Beyond basic editing, Spire.PDF’s capabilities extend to automation and enterprise-level solutions. Whether you’re integrating PDF manipulation into a document management system, or generating customized reports, the library offers a stable and scalable foundation for long-term projects. With its comprehensive feature set and strong performance, Spire.PDF for Java is a reliable choice for developers seeking precision, efficiency, and control over PDF documents.
FAQs About Editing PDF in Java
Q1. What is the best library for editing PDFs in Java?
Spire.PDF for Java is a popular choice among developers worldwide, which provides comprehensive range of features for effective PDF manipulation.
Q2. Can I edit existing text in a PDF using Java?
With Spire.PDF for Java, you can replace or modify existing text using classes like PdfTextReplacer along with customizable options for case sensitivity and matching behavior.
Q3. How to insert or replace images in a PDF in Java?
With Spire.PDF for Java, you can use drawImage() to insert images and PdfImageHelper.replaceImage() to replace existing ones on a specific page.
Q4. Can I annotate a PDF file in Java?
Yes, annotations such as highlights, comments, and stamps can be added using the appropriate annotation classes provided by Spire.PDF for Java.
Q5. Can I extract text and images from an existing PDF file?
Yes, you can. Spire.PDF for Java provides methods to extract text, images, and other elements from PDFs easily. For detailed instructions and code examples, refer to: How to Read PDFs in Java: Extract Text, Images, and More
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
How to Convert PDF to CSV in Java (Easily Extract PDF Tables)
2025-08-28 05:43:27 Written by zaki zou
When working with reports, invoices, or datasets stored in PDF format, developers often need a way to reuse the tabular data in spreadsheets, databases, or analytical tools. A common solution is to convert PDF to CSV using Java, since CSV is lightweight, structured, and compatible with almost every platform.
Unlike text or image export, a PDF-to-CSV conversion is mainly about extracting tables from PDF and saving them as CSV. With the help of Spire.PDF for Java, you can detect table structures in PDFs and export them programmatically with just a few lines of code.
In this article, you’ll learn step by step how to perform a PDF to CSV conversion in Java—from setting up the environment, to extracting tables, and even handling more complex scenarios like multi-page documents or multiple tables per page.
Overview of This Tutorial
Environment Setup for PDF to CSV Conversion in Java
Before extracting tables and converting PDF to CSV using Java, you need to set up the development environment. This involves choosing a suitable library and adding it to your project.
Why Choose Spire.PDF for Java
Since PDF files do not provide a built-in export to CSV, extracting tables programmatically is the practical approach. Spire.PDF for Java offers APIs to detect table structures in PDF documents and save them directly as CSV files, making the conversion process simple and efficient.
Install Spire.PDF for Java
Add Spire.PDF for Java to your project using Maven:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
If you are not using Maven, you can download the Spire.PDF for Java package and add the JAR files to your project’s classpath.
Extract Tables from PDF and Save as CSV
The most practical way to perform PDF to CSV conversion is by extracting tables. With Spire.PDF for Java, this can be done with just a few steps:
- Load the PDF document.
- Use PdfTableExtractor to find tables on each page.
- Collect cell values row by row.
- Write the output into a CSV file.
Here is a Java example that shows the process from start to finish:
Java Code Example for PDF to CSV Conversion
import com.spire.pdf.*;
import com.spire.pdf.utilities.*;
import java.io.*;
public class PdfToCsvExample {
public static void main(String[] args) throws Exception {
// Load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("Sample.pdf");
// Create a StringBuilder to store extracted text
StringBuilder sb = new StringBuilder();
// Iterate through each page
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (PdfTable table : tableLists) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
// Escape the cell text safely
String cellText = escapeCsvField(table.getText(row, col));
sb.append(cellText);
if (col < table.getColumnCount() - 1) {
sb.append(",");
}
}
sb.append("\n");
}
}
}
}
// Write the output to a CSV file
FileWriter writer = new FileWriter("output/PDFTable.csv");
writer.write(sb.toString());
writer.close();
pdf.close();
System.out.println("PDF tables successfully exported to CSV.");
}
// Utility method to escape CSV fields
private static String escapeCsvField(String text) {
if (text == null) return "";
// Remove line breaks
text = text.replaceAll("[\\n\\r]", "");
// Escape if contains special characters
if (text.contains(",") || text.contains(";") || text.contains("\"") || text.contains("\n")) {
text = text.replace("\"", "\"\""); // Escape double quotes
text = "\"" + text + "\""; // Wrap with quotes
}
return text;
}
}
Code Walkthrough
- PdfDocument loads the PDF file into memory.
- PdfTableExtractor checks each page for tables.
- PdfTable provides access to rows and columns.
- escapeCsvField() removes line breaks and safely quotes/escapes text if needed.
- StringBuilder accumulates cell text, separated by commas.
- The result is written into Output.csv, which you can open in Excel or any editor.
CSV file generated from a PDF table after running the Java code.
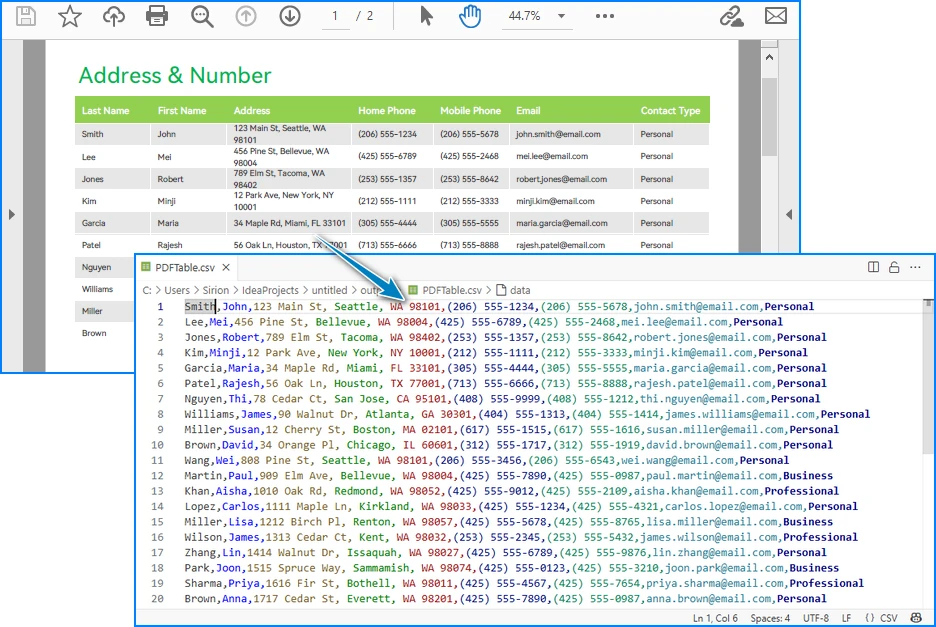
Handling Complex PDF-to-CSV Conversion Cases
In practice, PDFs often contain multiple tables, span multiple pages, or have irregular structures. Let’s see how to extend the solution to handle these scenarios.
1. Multiple Tables per Page
The PdfTable[] returned by extractTable(i) contains all tables detected on a page. You can process each one separately. For example, to save each table as a different CSV file:
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (int t = 0; t < tableLists.length; t++) {
PdfTable table = tableLists[t];
StringBuilder tableContent = new StringBuilder();
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
tableContent.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) {
tableContent.append(",");
}
}
tableContent.append("\n");
}
FileWriter writer = new FileWriter("Table_Page" + i + "_Index" + t + ".csv");
writer.write(tableContent.toString());
writer.close();
}
}
}
Example of multiple tables in one PDF page exported into separate CSV files.
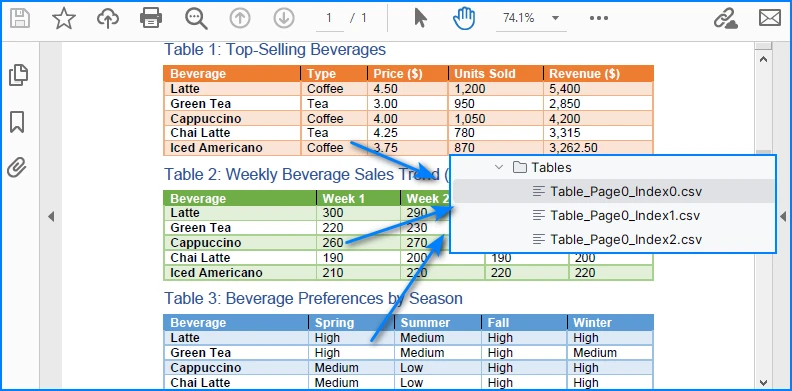
This way, every table is saved as an independent CSV file for better organization.
2. Multi-page or Large Tables
If a table spans across multiple pages, iterating page by page ensures that all data is collected. The key is to append data instead of overwriting:
StringBuilder sb = new StringBuilder();
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tables = extractor.extractTable(i);
if (tables != null) {
for (PdfTable table : tables) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
sb.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) sb.append(",");
}
sb.append("\n");
}
}
}
}
FileWriter writer = new FileWriter("MergedTables.csv");
writer.write(sb.toString());
writer.close();
Example of a large table across multiple PDF pages merged into one CSV file.
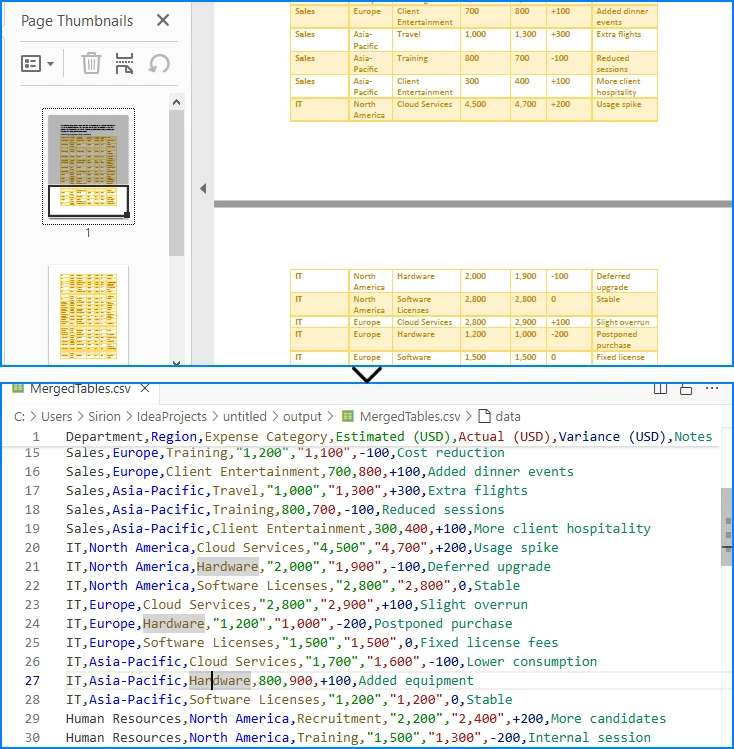
Here, all tables across pages are merged into one CSV file, useful when dealing with continuous reports.
3. Limitations with Formatting
CSV only stores plain text values. Elements like merged cells, fonts, or images are discarded. If preserving styling is critical, exporting to Excel (.xlsx) is a better alternative, which the same library also supports. See How to Export PDF Table to Excel in Java for more details.
4. CSV Special Characters Handling
When writing tables to CSV, certain characters like commas, semicolons, double quotes, or line breaks can break the file structure if not handled properly.
In the Java examples above, the escapeCsvField method removes line breaks and safely quotes or escapes text when needed.
For more advanced scenarios, you can also use Spire.XLS for Java to write data into worksheets and then save as CSV, which automatically handles special characters and ensures correct CSV formatting without manual processing.
Alternatively, for open-source options, libraries like OpenCSV or Apache Commons CSV also automatically handle special characters and CSV formatting, reducing potential issues and simplifying code.
Conclusion
Converting PDF to CSV in Java essentially means extracting tables and saving them in a structured format. CSV is widely supported, lightweight, and ideal for storing and analyzing tabular data. By setting up Spire.PDF for Java and following the code example, you can automate this process, saving time and reducing manual effort.
If you want to explore more advanced features of Spire.PDF for Java, please apply for a free trial license. You can also use Free Spire.PDF for Java for small projects.
FAQ
Q: Can I turn a PDF into a CSV file? A: Yes. While images and styled text cannot be exported, you can extract tables and save them as CSV files using Java.
Q: How to extract data from a PDF file in Java? A: Use a PDF library like Spire.PDF for Java to parse the document, detect tables, and export them to CSV or Excel.
Q: What is the best PDF to CSV converter? A: For Java developers, programmatic solutions such as Spire.PDF for Java offer more flexibility and automation than manual converters.
Q: How to convert PDF to Excel using Java code? A: The process is similar to CSV export. Instead of writing data as comma-separated text, you can export tables into Excel format for richer features.
Java Convert Byte Array to PDF: Load & Create with Spire.PDF
2025-08-21 06:31:19 Written by zaki zou
In modern Java applications, PDF data is not always stored as files on disk. Instead, it may be transmitted over a network, returned by a REST API, or stored as a byte array in a database. In such cases, you’ll often need to convert a byte array back into a PDF file or even generate a new PDF from plain text bytes.
This tutorial will walk you through both scenarios using Spire.PDF for Java, a powerful library for working with PDF documents.
Table of Contents:
- Getting Started with Spire.PDF for Java
- Understanding PDF Bytes vs. Text Bytes
- Loading PDF from Byte Array
- Creating PDF from Text Bytes
- Common Pitfalls to Avoid
- Frequently Asked Questions
- Conclusion
Getting Started with Spire.PDF for Java
Spire.PDF is a powerful and feature-rich API that allows Java developers to create, read, edit, convert, and print PDF documents without any dependencies on Adobe Acrobat.
Key Features:
- Create PDFs with text, images, tables, and shapes.
- Edit existing PDFs and extract text and images.
- Convert PDFs to formats like HTML, Word, Excel, and images.
- Encrypt PDFs with password protection.
- Add watermarks, annotations, and digital signatures.
To get started, download Spire.PDF for Java from our website and add the JAR files to your project's build path. If you’re using Maven, include the following dependency in your pom.xml.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
Once set up, you can now proceed to convert byte arrays to PDFs and perform other PDF-related operations.
Understanding PDF Bytes vs. Text Bytes
Before coding, it’s important to distinguish between two very different kinds of byte arrays :
- PDF File Bytes : These represent the actual binary structure of a valid PDF document. They always start with %PDF-1.x and contain objects, cross-reference tables, and streams. Such byte arrays can be loaded directly into a PdfDocument.
- Text Bytes : These are simply ASCII or UTF-8 encodings of characters. For example,
byte[] bytes = {84, 104, 105, 115};
System.out.println(new String(bytes)); // Output: "This"
Such arrays are not valid PDFs, but you can create a new PDF and write the text into it.
Loading PDF from Byte Array in Java
Suppose you want to download a PDF from a URL and work with it in memory as a byte array. With Spire.PDF for Java, you can easily load and save it back as a PDF document.
import com.spire.pdf.PdfDocument;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class LoadPdfFromByteArray throws Exception{
public static void main(String[] args) {
// The PDF URL
String fileUrl = "https://www.e-iceblue.com/resource/sample.pdf";
// Download PDF into a byte array
byte[] pdfBytes = downloadPdfAsBytes(fileUrl);
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load PDF from byte array
doc.loadFromStream(new ByteArrayInputStream(pdfBytes));
// Save the document locally
doc.saveToFile("downloaded.pdf");
doc.close();
}
// Helper method: download file as byte[]
private static byte[] downloadPdfAsBytes(String fileUrl) throws Exception {
URL url = new URL(fileUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
InputStream inputStream = conn.getInputStream();
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
byte[] data = new byte[4096];
int nRead;
while ((nRead = inputStream.read(data, 0, data.length)) != -1) {
buffer.write(data, 0, nRead);
}
buffer.flush();
inputStream.close();
conn.disconnect();
return buffer.toByteArray();
}
}
How this works
- Make an HTTP request to fetch the PDF file.
- Convert the InputStream into a byte array using ByteArrayOutputStream .
- Pass the byte array into Spire.PDF via loadFromStream .
- Save or manipulate the document as needed.
Output:
Creating PDF from Text Bytes in Java
If you only have plain text bytes (e.g., This document is created from text bytes.), you can decode them into a string and then draw the text onto a new PDF document.
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
public class TextFromBytesToPdf {
public static void main(String[] args) {
// Your text bytes
byte[] byteArray = {
84, 104, 105, 115, 32,
100, 111, 99, 117, 109, 101, 110, 116, 32,
105, 115, 32,
99, 114, 101, 97, 116, 101, 100, 32,
102, 114, 111, 109, 32,
116, 101, 120, 116, 32,
98, 121, 116, 101, 115, 46
};
String text = new String(byteArray);
// Create a PDF document
PdfDocument doc = new PdfDocument();
// Configure the page settings
doc.getPageSettings().setSize(PdfPageSize.A4);
doc.getPageSettings().setMargins(40f);
// Add a page
PdfPageBase page = doc.getPages().add();
// Draw the string onto PDF
PdfFont font = new PdfFont(PdfFontFamily.Helvetica, 20f);
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.black));
page.getCanvas().drawString(text, font, brush, 20, 40);
// Save the document to a PDF file
doc.saveToFile("TextBytes.pdf");
doc.close();
}
}
This will produce a new PDF named TextBytes.pdf (shown below) containing the sentence represented by your byte array.

You might be interested in: How to Generate PDF Documents in Java
Common Pitfalls to Avoid
When converting byte arrays to PDFs, watch out for these issues:
- Confusing plain text with PDF bytes
Not every byte array is a valid PDF. Unless the array starts with %PDF-1.x and contains the proper structure, you can’t load it directly with PdfDocument.loadFromStream .
- Incorrect encoding
If your text bytes are in UTF-16, ISO-8859-1, or another encoding, you need to specify the charset when creating a string:
String text = new String(byteArray, StandardCharsets.UTF_8);
- Large byte arrays
When dealing with large PDFs, consider streaming instead of holding everything in memory to avoid OutOfMemoryError .
- Forgetting to close documents
Always call doc.close() to release resources after saving or processing a PDF.
Frequently Asked Questions
Q1. Can I store a PDF as a byte array in a database?
Yes. You can store a PDF as a BLOB in a relational database. Later, you can retrieve it, load it into a PdfDocument , and save or manipulate it.
Q2. How do I check if a byte array is a valid PDF?
Check if the array begins with the %PDF- header. You can do:
String header = new String(Arrays.copyOfRange(bytes, 0, 5));
if (header.startsWith("%PDF-")) {
// valid PDF
}
Q3. Can Spire.PDF load a PDF directly from an InputStream?
Yes. Instead of converting to a byte array, you can pass the InputStream directly to loadFromStream() .
Q4. Can I convert a PdfDocument back into a byte array?
You can save the document into a ByteArrayOutputStream instead of a file:
ByteArrayOutputStream baos = new ByteArrayOutputStream();
doc.saveToStream(baos);
byte[] pdfBytes = baos.toByteArray();
Q5. What if my byte array contains images instead of text or PDF?
In that case, you’ll need to create a new PDF and insert the image using Spire.PDF’s drawing APIs.
Conclusion
In this article, we explored how to efficiently convert byte arrays to PDF documents using Spire.PDF for Java. Whether you're loading existing PDF files from byte arrays retrieved via APIs or creating new PDFs from plain text bytes, Spire.PDF provides a robust solution to meet your needs.
We covered essential concepts, including the distinction between PDF file bytes and text bytes, and highlighted common pitfalls to avoid during the conversion process. With the right understanding and tools, you can seamlessly integrate PDF functionalities into your Java applications, enhancing your ability to manage and manipulate document data.
For further exploration, consider experimenting with additional features of Spire.PDF, such as editing, encrypting, and converting PDFs to other formats. The possibilities are extensive, and mastering these techniques will undoubtedly improve your development skills and project outcomes.
How to Read PDFs in Java: Extract Text, Images, and More
2025-06-12 07:07:24 Written by Administrator
In today's data-driven landscape, reading PDF files effectively is essential for Java developers. Whether you're handling scanned invoices, structured reports, or image-rich documents, the ability to read PDFs in Java can enhance workflows and reveal critical insights.
This guide will walk you through practical implementations using Spire.PDF for Java to master PDF reading in Java. You will learn to extract searchable text, retrieve embedded images, read tabular data, and perform OCR on scanned PDF documents.
Table of Contents:
- Java Library for Reading PDF Content
- Extract Text from Searchable PDFs
- Retrieve Images from PDFs
- Read Table Data from PDF Files
- Convert Scanned PDFs to Text via OCR
- Conclusion
- FAQs
Java Library for Reading PDF Content
When it comes to reading PDF in Java, choosing the right library is half the battle. Spire.PDF stands out as a robust, feature-rich solution for developers. It supports text extraction, image retrieval, table parsing, and even OCR integration. Its intuitive API and comprehensive documentation make it ideal for both beginners and experts.
To start extracting PDF content, download Spire.PDF for Java from our website and add it as a dependency in your project. If you’re using Maven, include the following in your pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.5.2</version>
</dependency>
</dependencies>
Below, we’ll explore how to leverage Spire.PDF for various PDF reading tasks.
Extract Text from Searchable PDFs in Java
Searchable PDFs store text in a machine-readable format, allowing for efficient content extraction. The PdfTextExtractor class in Spire.PDF provides a straightforward way to access page content, while PdfTextExtractOptions allows for flexible extraction settings, including options for handling special text layouts and specifying areas for extraction.
Step-by-Step Guide
- Initialize a new instance of PdfDocument to work with your PDF file.
- Use the loadFromFile method to load the desired PDF document.
- Loop through each page of the PDF using a for loop.
- For each page, create an instance of PdfTextExtractor to facilitate text extraction.
- Create a PdfTextExtractOptions object to specify how text should be extracted, including any special strategies.
- Call the extract method on the PdfTextExtractor instance to retrieve the text from the page.
- Write the extracted text to a text file.
The example below shows how to retrieve text from every page of a PDF and output it to individual text files.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import com.spire.pdf.texts.PdfTextStrategy;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ExtractTextFromSearchablePdf {
public static void main(String[] args) throws IOException {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Iterate through all pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Get the current page
PdfPageBase page = doc.getPages().get(i);
// Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
// Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
// Specify extract option
extractOptions.setStrategy(PdfTextStrategy.None);
// Extract text from the page
String text = textExtractor.extract(extractOptions);
// Define the output file path
Path outputPath = Paths.get("output/Extracted_Page_" + (i + 1) + ".txt");
// Write to a txt file
Files.write(outputPath, text.getBytes());
}
// Close the document
doc.close();
}
}
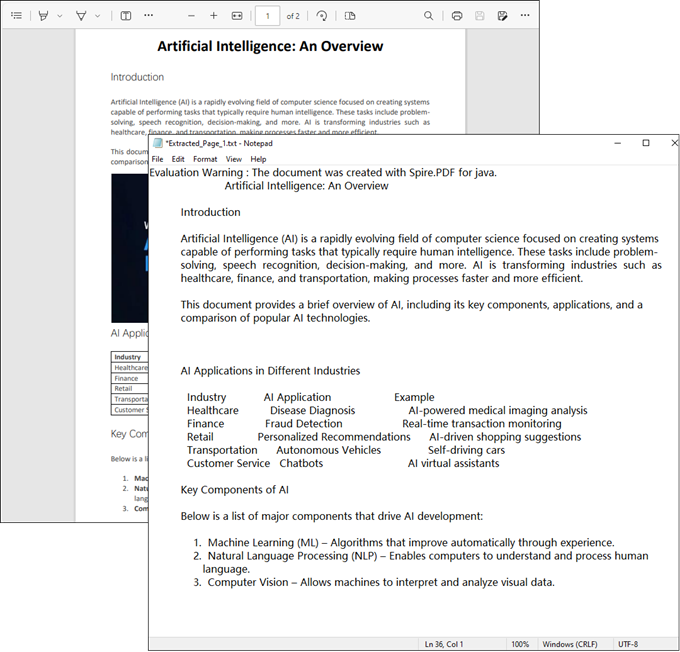
Result:
Retrieve Images from PDFs in Java
The PdfImageHelper class in Spire.PDF enables efficient extraction of embedded images from PDF documents. It identifies images using PdfImageInfo objects, allowing for easy saving as standard image files.
Step-by-Step Guide
- Initialize a new instance of PdfDocument to work with your PDF file.
- Use the loadFromFile method to load the desired PDF.
- Instantiate PdfImageHelper to assist with image extraction.
- Loop through each page of the PDF.
- For each page, retrieve all image information using the getImagesInfo method.
- Loop through the retrieved image information, extract each image, and save it as a PNG file.
The following example extracts all embedded images from a PDF document and saves them as individual PNG files.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ExtractAllImages {
public static void main(String[] args) throws IOException {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Declare an int variable
int m = 0;
// Iterate through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Get a specific page
PdfPageBase page = doc.getPages().get(i);
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.getImagesInfo(page);
// Iterate through the image information
for (int j = 0; j < imageInfos.length; j++)
{
// Get a specific image information
PdfImageInfo imageInfo = imageInfos[j];
// Get the image
BufferedImage image = imageInfo.getImage();
File file = new File(String.format("output/Image-%d.png",m));
m++;
// Save the image file in PNG format
ImageIO.write(image, "PNG", file);
}
}
// Clear up resources
doc.dispose();
}
}
Result:
Read Table Data from PDF Files in Java
For PDF tables that need conversion to structured data, PdfTableExtractor intelligently recognizes cell boundaries and relationships. The resulting PdfTable objects maintain the original table organization, allowing for cell-level data export.
Step-by-Step Guide
- Initialize an instance of PdfDocument to handle your PDF file.
- Use the loadFromFile method to open the desired PDF.
- Instantiate PdfTableExtractor to facilitate table extraction.
- Iterate through each page of the PDF to extract tables.
- For each page, retrieve tables into a PdfTable array using the extractTable method.
- For each table, iterate through its rows and columns to extract data.
- Write the extracted data to individual text files.
This Java code extracts table data from a PDF document and saves each table as a separate text file.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
public class ExtractTableData {
public static void main(String[] args) throws Exception {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Create a PdfTableExtractor instance
PdfTableExtractor extractor = new PdfTableExtractor(doc);
// Initialize a table counter
int tableCounter = 1;
// Loop through the pages in the PDF
for (int pageIndex = 0; pageIndex < doc.getPages().getCount(); pageIndex++) {
// Extract tables from the current page into a PdfTable array
PdfTable[] tableLists = extractor.extractTable(pageIndex);
// If any tables are found
if (tableLists != null && tableLists.length > 0) {
// Loop through the tables in the array
for (PdfTable table : tableLists) {
// Create a StringBuilder for the current table
StringBuilder builder = new StringBuilder();
// Loop through the rows in the current table
for (int i = 0; i < table.getRowCount(); i++) {
// Loop through the columns in the current table
for (int j = 0; j < table.getColumnCount(); j++) {
// Extract data from the current table cell and append to the StringBuilder
String text = table.getText(i, j);
builder.append(text).append(" | ");
}
builder.append("\r\n");
}
// Write data into a separate .txt document for each table
FileWriter fw = new FileWriter("output/Table_" + tableCounter + ".txt");
fw.write(builder.toString());
fw.flush();
fw.close();
// Increment the table counter
tableCounter++;
}
}
}
// Clear up resources
doc.dispose();
}
}
Result:
Convert Scanned PDFs to Text via OCR
Scanned PDFs require special handling through OCR engine such as Spire.OCR for Java. The solution first converts pages to images using Spire.PDF's rendering engine, then applies Spire.OCR's recognition capabilities via the OcrScanner class. This two-step approach effectively transforms physical document scans into editable text while supporting multiple languages.
Step 1. Install Spire.OCR and Configure the Environment
- Download Spire.OCR for Java and add the Jar file as a dependency in your project.
- Download the model that fits in with your operating system from one of the following links, and unzip the package somewhere on your disk.
- Configure the model in your code.
OcrScanner scanner = new OcrScanner();
configureOptions.setModelPath("D:\\win-x64");// model path
For detailed steps, refer to: Extract Text from Images Using the New Model of Spire.OCR for Java
Step 2. Convert a Scanned PDF to Text
This code example converts each page of a scanned PDF into an image, applies OCR to extract text, and saves the results in a text file.
import com.spire.ocr.OcrException;
import com.spire.ocr.OcrScanner;
import com.spire.ocr.ConfigureOptions;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ExtractTextFromScannedPdf {
public static void main(String[] args) throws IOException, OcrException {
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Configure the scanner
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.setModelPath("D:\\win-x64"); // Set model path
configureOptions.setLanguage("English"); // Set language
// Apply the configuration options
scanner.ConfigureDependencies(configureOptions);
// Load a PDF document
PdfDocument doc = new PdfDocument();
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Prepare temporary directory
String tempDirPath = "temp";
new File(tempDirPath).mkdirs(); // Create temp directory
StringBuilder allText = new StringBuilder();
// Iterate through all pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Convert page to image
BufferedImage bufferedImage = doc.saveAsImage(i, PdfImageType.Bitmap);
String imagePath = tempDirPath + File.separator + String.format("page_%d.png", i);
ImageIO.write(bufferedImage, "PNG", new File(imagePath));
// Perform OCR
scanner.scan(imagePath);
String pageText = scanner.getText().toString();
allText.append(String.format("\n--- PAGE %d ---\n%s\n", i + 1, pageText));
// Clean up temp image
new File(imagePath).delete();
}
// Save all extracted text to a file
Path outputTxtPath = Paths.get("output", "extracted_text.txt");
Files.write(outputTxtPath, allText.toString().getBytes());
// Close the document
doc.close();
System.out.println("Text extracted to " + outputTxtPath);
}
}Conclusion
Mastering how to read PDF in Java opens up a world of possibilities for data extraction and document automation. Whether you’re dealing with searchable text, images, tables, or scanned documents, the right tools and techniques can simplify the process.
By leveraging libraries like Spire.PDF and integrating OCR for scanned files, you can build robust solutions tailored to your needs. Start experimenting with the code snippets provided and unlock the full potential of PDF processing in Java!
FAQs
Q1: Can I extract text from scanned PDFs using Java?
Yes, by combining Spire.PDF with Spire.OCR. Convert PDF pages to images and perform OCR to extract text.
Q2: What’s the best library for reading PDFs in Java?
Spire.PDF is highly recommended for its versatility and ease of use. It supports extraction of text, images, tables, and OCR integration.
Q3: Does Spire.PDF support extraction of PDF elements like metadata, attachments, and hyperlinks?
Yes, Spire.PDF provides comprehensive support for extracting:
- Metadata (title, author, keywords)
- Attachments (embedded files)
- Hyperlinks (URLs and document links)
The library offers dedicated classes like PdfDocumentInformation for metadata and methods to retrieve embedded files ( PdfAttachmentCollection ) and hyperlinks ( PdfUriAnnotation ).
Q4: How to parse tables from PDFs into CSV/Excel programmatically?
Using Spire.PDF for Java, you can extract table data from PDFs, then seamlessly export it to Excel (XLSX) or CSV format with Spire.XLS for Java. For a step-by-step guide, refer to our tutorial: Export Table Data from PDF to Excel in Java.
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
When working with PDF files, you may need to adjust the page size to emphasize important content, remove extra white space, or fit specific printing and display requirements. Cropping PDF pages helps streamline the document layout, making the content more readable and well-organized. It also reduces file size, improving both accessibility and sharing. Additionally, precise cropping enhances the document's visual appeal, giving it a more polished and professional look. This article will demonstrate how to crop PDF pages in Java using the Spire.PDF for Java library.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
Crop a PDF Page in Java
Spire.PDF for Java provides the PdfPageBase.setCropBox(Rectangle2D rect) method to set the crop area for a PDF page. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.loadFromFile() method.
- Get a specific page from the PDF using the PdfDocument.getPages().get(int pageIndex) method.
- Create an instance of the Rectangle2D class to define the crop area.
- Use the PdfPageBase.setCropBox(Rectangle2D rect) method to set the crop area for the page.
- Save the cropped PDF using the PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.awt.geom.Rectangle2D;
public class CropPdfPage {
public static void main(String[] args) {
// Create an instance of the PdfDocument class
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.loadFromFile("example.pdf");
// Get the first page of the PDF
PdfPageBase page = pdf.getPages().get(0);
// Define the crop area (parameters: x, y, width, height)
Rectangle2D rectangle = new Rectangle2D.Float(0, 40, 600, 360);
// Set the crop area for the page
page.setCropBox(rectangle);
// Save the cropped PDF
pdf.saveToFile("cropped.pdf");
// Close the document and release resources
pdf.close();
}
}
Crop a PDF page and Export the Result as an Image in Java
After cropping a PDF page, developers can use the PdfDocument.saveAsImage(int pageIndex, PdfImageType type) method to export the result as an image. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.loadFromFile() class.
- Get a specific page from the PDF using the PdfDocument.getPages().get(int pageIndex) mthod.
- Create an instance of the Rectangle2D class to define the crop area.
- Use the PdfPageBase.setCropBox(Rectangle2D rect) method to set the crop area for the page.
- Use the PdfDocument.saveAsImage(int pageIndex, PdfImageType type) method to export the cropped page as an image.
- Save the image as an image file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.geom.Rectangle2D;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class CropPdfPageAndSaveAsImage {
public static void main(String[] args) {
// Create an instance of the PdfDocument class
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.loadFromFile("example.pdf");
// Get the first page of the PDF
PdfPageBase page = pdf.getPages().get(0);
// Define the crop area (parameters: x, y, width, height)
Rectangle2D rectangle = new Rectangle2D.Float(0, 40, 600, 360);
// Set the crop area for the page
page.setCropBox(rectangle);
// Export the cropped page as an image
BufferedImage image = pdf.saveAsImage(0, PdfImageType.Bitmap);
// Save the image as a PNG file
File outputFile = new File("cropped.png");
try {
ImageIO.write(image, "PNG", outputFile);
System.out.println("Cropped page saved as: " + outputFile.getAbsolutePath());
} catch (IOException e) {
System.err.println("Error saving image: " + e.getMessage());
}
// Close the document and release resources
pdf.close();
}
}
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
Enhancing PDF documents with interactive elements has become increasingly important for improving user engagement and functionality. Adding actions to PDFs, such as linking to document pages, executing JavaScript, or triggering a file opening, can significantly elevate the utility of these documents in various professional and personal applications. By incorporating such dynamic features using the Spire.PDF for Java library, developers will be able to unlock new possibilities for their PDF documents, making them more versatile and user-friendly. This article will demonstrate how to add actions to PDF documents with Spire.PDF for Java.
- How to Add Actions to PDF using Spire.PDF for Java
- Create Navigation Actions in PDF with Java
- Create File-Open Actions in PDF with Java
- Create Sound Actions in PDF with Java
- Create JavaScript Actions in PDF with Java
Install Spire.PDF for Java
First of all, you need to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
How to Add Actions to PDF using Spire.PDF for Java
Spire.PDF for Java enables developers to add a variety of actions to PDF documents, such as navigation actions, file-open actions, sound actions, and JavaScript actions. Below is a table of classes and their descriptions for commonly used actions:
| Class | Description |
| PdfGoToAction | Represents an action that navigates to a destination within the current document. |
| PdfLaunchAction | Represents an action that launches and opens a file. |
| PdfJavaScriptAction | Represents an action that executes JavaScript code. |
| PdfSoundAction | Represents an action that plays a sound. |
For more action classes and their descriptions, refer to Spire.PDF for Java action API references.
Actions can be added to PDF documents in two primary ways:
1. Using Action Annotations
This method involves creating an action and linking it to an annotation on the page. The action is displayed and triggered when the annotation is clicked.
General Steps:
- Create a PdfDocument instance and load a PDF document using PdfDocument.LoadFromFile() method.
- Create an action instance and set its properties.
- Optionally, draw cue text or images to indicate the action.
- Create a PdfActionAnnotation instance using the action instance and specify its location on the page.
- Add the action annotation to the page using PdfPageBase.getAnnotations.add() method.
- Save the document using PdfDocument.SaveToFile() method.
2. Assigning Actions to Document Events
Actions can also be assigned to document-level events such as opening, closing, or printing the document. These actions are triggered automatically when the specified events occur.
General Steps:
- Create a PdfDocument instance and load a PDF document using PdfDocument.LoadFromFile() method.
- Create an action instance and set its properties.
- Assign the action to a document event using the following methods:
- PdfDocument.setAfterOpenAction()
- PdfDocument.setAfterPrintAction()
- PdfDocument.setAfterSaveAction()
- PdfDocument.setBeforeCloseAction()
- PdfDocument.setBeforePrintAction()
- PdfDocument.setBeforeSaveAction()
- Save the document using PdfDocument.SaveToFile() method.
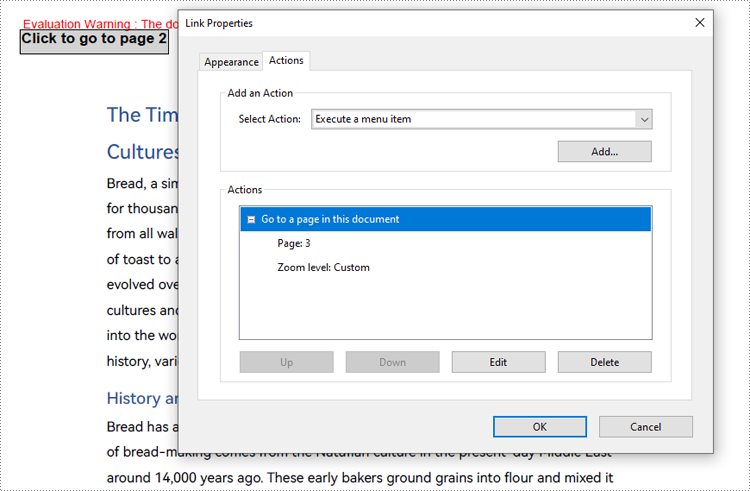
Create Navigation Actions in PDF with Java
The PdfGoToAction class can be used to create navigation actions in PDF documents, allowing users to jump to a specific location within the document. Below is a Java code example demonstrating how to create a navigation button in a PDF document.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.actions.PdfGoToAction;
import com.spire.pdf.annotations.PdfActionAnnotation;
import com.spire.pdf.general.PdfDestination;
import com.spire.pdf.graphics.PdfBrushes;
import com.spire.pdf.graphics.PdfStringFormat;
import com.spire.pdf.graphics.PdfTextAlignment;
import com.spire.pdf.graphics.PdfTrueTypeFont;
import java.awt.*;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
public class AddNavigationActionPDF {
public static void main(String[] args) {
// Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
// Load a PDF file
pdf.loadFromFile("Sample.pdf");
// Create a PdfDestination object
PdfDestination destination = new PdfDestination(2, new Point2D.Float(0, 0), 0.8f);
// Create a PdfGoToAction object using the PdfDestination object
PdfGoToAction goToAction = new PdfGoToAction(destination);
// Draw a rectangle and the cue text on the first page
Rectangle2D rect = new Rectangle2D.Float(20, 30, 120, 20);
pdf.getPages().get(0).getCanvas().drawRectangle(PdfBrushes.getLightGray(), rect);
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 12), true);
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Center);
pdf.getPages().get(0).getCanvas().drawString("Click to go to page 2", font, PdfBrushes.getBlack(), rect, format);
// Create a PdfActionAnnotation object using the PdfGoToAction object
PdfActionAnnotation actionAnnotation = new PdfActionAnnotation(rect, goToAction);
// Add the annotation to the first page
pdf.getPages().get(0).getAnnotations().add(actionAnnotation);
// Save the document
pdf.saveToFile("output/PDFNavigationAction.pdf");
pdf.close();
}
}
Create File-Open Actions in PDF with Java
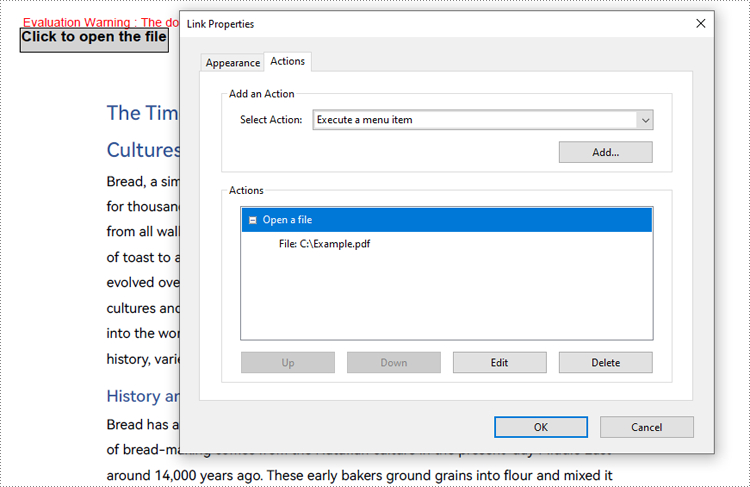
Developers can use the PdfLaunchAction class to create a file-open action in a PDF document. Below is a Java code example showing how to add a file-open action to a PDF document.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.actions.PdfFilePathType;
import com.spire.pdf.actions.PdfLaunchAction;
import com.spire.pdf.annotations.PdfActionAnnotation;
import com.spire.pdf.graphics.PdfBrushes;
import com.spire.pdf.graphics.PdfStringFormat;
import com.spire.pdf.graphics.PdfTextAlignment;
import com.spire.pdf.graphics.PdfTrueTypeFont;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class AddFileOpenActionPDF {
public static void main(String[] args) {
// Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
// Load a PDF file
pdf.loadFromFile("Sample.pdf");
// Create a PdfLaunchAction object and set the file path
PdfLaunchAction launchAction = new PdfLaunchAction("C:/Example.pdf", PdfFilePathType.Absolute);
// Draw a rectangle and the cue text on the first page
Rectangle2D rect = new Rectangle2D.Float(20, 30, 120, 20);
pdf.getPages().get(0).getCanvas().drawRectangle(PdfBrushes.getLightGray(), rect);
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 12), true);
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Center);
pdf.getPages().get(0).getCanvas().drawString("Click to open the file", font, PdfBrushes.getBlack(), rect, format);
// Create a PdfActionAnnotation object using the PdfLaunchAction object
PdfActionAnnotation actionAnnotation = new PdfActionAnnotation(rect, launchAction);
// Add the annotation to the first page
pdf.getPages().get(0).getAnnotations().add(actionAnnotation);
// Save the document
pdf.saveToFile("output/PDFFileOpenAction.pdf");
pdf.close();
}
}
Create Sound Actions in PDF with Java
The PdfSoundAction class is used to handle sound playback in PDF documents, enabling features such as background music and voice reminders. The Java code example below demonstrates how to create sound actions in PDF documents.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.actions.PdfSoundAction;
import com.spire.pdf.annotations.PdfActionAnnotation;
import com.spire.pdf.general.PdfSoundChannels;
import com.spire.pdf.general.PdfSoundEncoding;
import com.spire.pdf.graphics.PdfImage;
import java.awt.geom.Rectangle2D;
public class AddSoundActionPDF {
public static void main(String[] args) {
// Create an instance of PdfDocument
PdfDocument pdf = new PdfDocument();
// Load a PDF file
pdf.loadFromFile("Sample.pdf");
// Create a PdfSoundAction object and set the audio property
PdfSoundAction soundAction = new PdfSoundAction("Music.wav");
soundAction.setRepeat(false);
soundAction.getSound().setBits(16);
soundAction.getSound().setChannels(PdfSoundChannels.Stereo);
soundAction.getSound().setEncoding(PdfSoundEncoding.Signed);
soundAction.getSound().setRate(44100);
// Draw the sound logo on the first page
PdfImage image = PdfImage.fromFile("Sound.jpg");
pdf.getPages().get(0).getCanvas().drawImage(image, new Rectangle2D.Float(40, 40, image.getWidth(), image.getHeight()));
// Create a PdfActionAnnotation object using the PdfSoundAction object at the location of the logo
Rectangle2D rect = new Rectangle2D.Float(40, 40, image.getWidth(), image.getHeight());
PdfActionAnnotation actionAnnotation = new PdfActionAnnotation(rect, soundAction);
// Add the annotation to the first page
pdf.getPages().get(0).getAnnotations().add(actionAnnotation);
// Save the document
pdf.saveToFile("output/PDFSoundAction.pdf");
pdf.close();
}
}
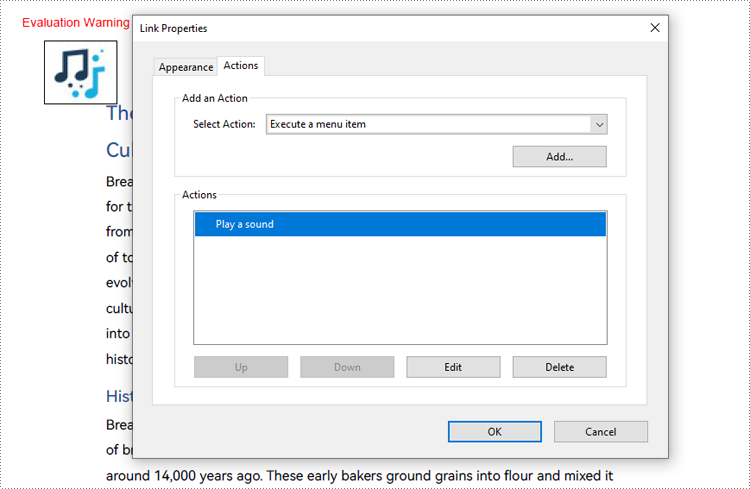
Create JavaScript Actions in PDF with Java
The PdfJavaScript class allows developers to create JavaScript actions within PDF documents, enabling custom interactive features such as creating dynamic forms, validating user input, and automating tasks. The following Java code example demonstrates how to add JavaScript actions to a PDF document.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.actions.PdfJavaScript;
import com.spire.pdf.actions.PdfJavaScriptAction;
public class AddJavaScriptActionPDF {
public static void main(String[] args) {
// Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
// Load a PDF file
pdf.loadFromFile("Sample.pdf");
// Define the JavaScript code and use it to create an instance of PdfJavaScriptAction
String jsCode = """
app.alert({
cMsg: 'Welcome to the article on The Timeless Delight of Bread!\\n\\nThis article explores the rich history, varieties, and cultural significance of bread. Enjoy your reading!',
nIcon: 3,
cTitle: 'Document Introduction'
});
""";
PdfJavaScriptAction javaScriptAction = new PdfJavaScriptAction(jsCode);
// Set the JavaScript action as the action to be executed after opening the PDF file
pdf.setAfterOpenAction(javaScriptAction);
// Save the document
pdf.saveToFile("output/PDFJavaScriptAction.pdf");
pdf.close();
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Verifying digital signatures in PDFs is crucial for ensuring that a document remains unaltered and genuinely comes from the stated signer. This verification process is essential for maintaining the document’s integrity and trustworthiness. Additionally, extracting digital signatures allows you to retrieve signature details, such as the signature image and certificate information, which can be useful for further validation or archival purposes. In this article, we will demonstrate how to verify and extract digital signatures in PDFs in Java using Spire.PDF for Java.
- Verify Digital Signatures in PDF in Java
- Detect Whether a Signed PDF Has Been Modified in Java
- Extract Signature Images and Certificate Information from PDF in Java
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
Verify Digital Signatures in PDF in Java
Spire.PDF for Java provides the PdfSignature.verifySignature() method to check the validity of digital signatures in PDF documents. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using the PdfDocument.Form property.
- Iterate through all fields in the form and find the signature field.
- Get the signature using the PdfSignatureFieldWidget.getSignature() method.
- Verify the validity of the signature using the PdfSignature.verifySignature() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.fields.PdfField;
import com.spire.pdf.security.PdfSignature;
import com.spire.pdf.widget.PdfFormWidget;
import com.spire.pdf.widget.PdfSignatureFieldWidget;
public class VerifySignature {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.loadFromFile("Signature.pdf");
// Get the form of the PDF document
PdfFormWidget formWidget = (PdfFormWidget) pdf.getForm();
if(formWidget.getFieldsWidget().getCount() > 0)
{
// Iterate through all fields in the form
for(int i = 0; i < formWidget.getFieldsWidget().getCount(); i ++)
{
PdfField field = formWidget.getFieldsWidget().get(i);
// Find the signature field
if (field instanceof PdfSignatureFieldWidget)
{
PdfSignatureFieldWidget signatureField = (PdfSignatureFieldWidget) field;
// Get the signature
PdfSignature signature = signatureField.getSignature();
// Verify the signature
boolean valid = signature.verifySignature();
if(valid)
{
System.out.print("The signature is valid!");
}
else
{
System.out.print("The signature is invalid!");
}
}
}
}
}
}
Detect Whether a Signed PDF Has Been Modified in Java
To verify if a signed PDF document has been modified, you can use the PdfSignature.VerifyDocModified() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using the PdfDocument.Form property.
- Iterate through all fields in the form and find the signature field.
- Get the signature using the PdfSignatureFieldWidget.getSignature() method.
- Verify if the document has been modified since it was signed using the PdfSignature.VerifyDocModified() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.fields.PdfField;
import com.spire.pdf.security.PdfSignature;
import com.spire.pdf.widget.PdfFormWidget;
import com.spire.pdf.widget.PdfSignatureFieldWidget;
public class CheckIfSignedPdfIsModified {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.loadFromFile("Signature.pdf");
// Get the form of the PDF document
PdfFormWidget formWidget = (PdfFormWidget) pdf.getForm();
if(formWidget.getFieldsWidget().getCount() > 0) {
// Iterate through all fields in the form
for (int i = 0; i < formWidget.getFieldsWidget().getCount(); i++) {
PdfField field = formWidget.getFieldsWidget().get(i);
// Find the signature field
if (field instanceof PdfSignatureFieldWidget) {
PdfSignatureFieldWidget signatureField = (PdfSignatureFieldWidget) field;
// Get the signature
PdfSignature signature = signatureField.getSignature();
// Verify the signaure
boolean modified = signature.verifyDocModified();
if(modified)
{
System.out.print("The document has been modified!");
}
else
{
System.out.print("The document has not been modified!");
}
}
}
}
}
}
Extract Signature Images and Certificate Information from PDF in Java
To extract signature images and certificate information from PDF, you can use the PdfFormWidget.extractSignatureAsImages() and PdfSignture.getCertificate().toString() methods. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using the PdfDocument.Form property.
- Extract signature images using the PdfFormWidget.extractSignatureAsImages() method and then save each image to file.
- Iterate through all fields in the form and find the signature field.
- Get the signature using the PdfSignatureFieldWidget.getSignature() method.
- Get the certificate information of the signature using the PdfSignture.getCertificate().toString() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.fields.PdfField;
import com.spire.pdf.security.PdfCertificate;
import com.spire.pdf.security.PdfSignature;
import com.spire.pdf.widget.PdfFormWidget;
import com.spire.pdf.widget.PdfSignatureFieldWidget;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractSignatureImage {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.loadFromFile("Signature.pdf");
// Get the form of the PDF document
PdfFormWidget formWidget = (PdfFormWidget) pdf.getForm();
// Extract signature images
Image[] images = formWidget.extractSignatureAsImages();
// Iterate through the images and save each image to file
for (int i = 0; i < images.length; i++) {
try {
// Convert the Image to BufferedImage
BufferedImage bufferedImage = (BufferedImage) images[i];
// Define the output file path
File outputFile = new File("output\\signature_" + i + ".png");
// Save the image as a PNG file
ImageIO.write(bufferedImage, "png", outputFile);
} catch (IOException e) {
e.printStackTrace();
}
}
// Create a text file to save the certificate information
try (BufferedWriter writer = new BufferedWriter(new FileWriter("output\\certificate_info.txt"))) {
if (formWidget.getFieldsWidget().getCount() > 0) {
// Iterate through all fields in the form
for (int i = 0; i < formWidget.getFieldsWidget().getCount(); i++) {
PdfField field = formWidget.getFieldsWidget().get(i);
// Find the signature field
if (field instanceof PdfSignatureFieldWidget) {
PdfSignatureFieldWidget signatureField = (PdfSignatureFieldWidget) field;
// Get the signature
PdfSignature signature = signatureField.getSignature();
// Get the certificate info of the signature
String certificateInfo = signature.getCertificate() != null ? signature.getCertificate().toString() : "No certificate";
// Write the certificate information to the text file
writer.write("Certificate Info: \n" + certificateInfo);
writer.write("-----------------------------------\n");
}
}
} else {
writer.write("No signature fields found.");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
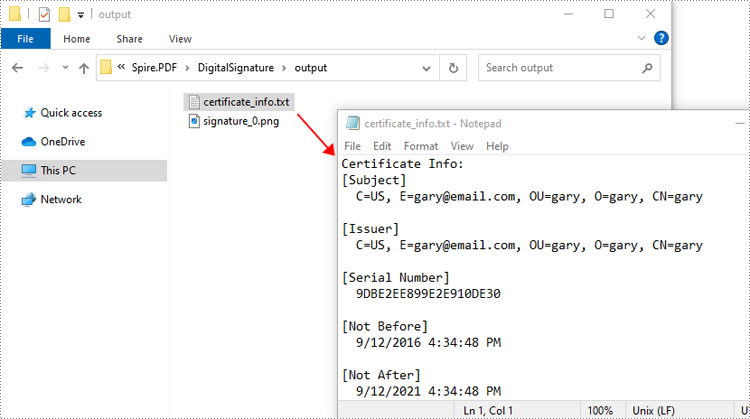
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Adding and removing watermarks in PDF documents play a crucial role in document management, copyright protection, and information security. A watermark can serve as a visual marker, such as a company logo, copyright notice, or the word "Confidential", indicating the source, status, or ownership of the document.
Spire.PDF provides a method for adding watermarks by embedding watermark annotations within the PDF document. This approach affords the flexibility to remove the watermark post-insertion, offering users greater control and options. This article will introduce how to add or remove watermark annotations in PDF documents using Spire.PDF for Java in Java projects.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
Add Watermark Annotations to PDF in Java
Spire.PDF provides a method to add watermark annotations to PDF pages using the PdfWatermarkAnnotation object. Notably, watermarks added by this method can be easily removed later. Here are the key steps involved:
- Initialize an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.loadFromFile() method.
- Create a PdfTrueTypeFont font object to draw the watermark text.
- Create a Rectangle2D type object to define the boundary of the page.
- Use a for loop to iterate over all PdfPageBase objects in the PDF document.
- Create a PdfTemplate object for drawing the watermark, setting its size to match the current page.
- Call a custom insertWatermark() method to draw the watermark content onto the PdfTemplate object.
- Create a PdfWatermarkAnnotation object and define the position where the watermark should be placed.
- Create a PdfAppearance object to configure the visual effects of the watermark.
- Use the PdfAppearance.setNormal(PdfTemplate) method to associate the PdfTemplate object with the PdfAppearance object.
- Use the PdfWatermarkAnnotation.setAppearance(PdfAppearance) method to associate the PdfAppearance object with the PdfWatermarkAnnotation object.
- Add the watermark annotation to the page by calling PdfPageBase.getAnnotationsWidget().add(PdfWatermarkAnnotation).
- Save the changes to a file using the PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
import com.spire.pdf.annotations.*;
import com.spire.pdf.annotations.appearance.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.*;
public class AddWatermarkInPDF {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdfDocument = new PdfDocument();
// Load the PDF document from a file
pdfDocument.loadFromFile("Sample1.pdf");
// Set the font style
Font font = new Font("Arial", Font.PLAIN, 22);
// Create a PdfTrueTypeFont object for subsequent text rendering
PdfTrueTypeFont trueTypeFont = new PdfTrueTypeFont(font);
// Get the page object
PdfPageBase page;
// Define the watermark text
String watermarkAnnotationText = "ID_0";
// Create a size object
Dimension2D dimension2D = new Dimension();
// Create a rectangle object
Rectangle2D loRect = new Rectangle2D.Float();
// Iterate through each page in the PDF
for (int i = 0; i < pdfDocument.getPages().getCount(); i++) {
// Get the current page
page = pdfDocument.getPages().get(i);
// Set the size object to the size of the current page
dimension2D.setSize(page.getClientSize().getWidth(), page.getClientSize().getHeight());
// Set the rectangle object frame, which is the entire page range
loRect.setFrame(new Point2D.Float(0, 0), dimension2D);
// Create a PdfTemplate object to draw the watermark
PdfTemplate template = new PdfTemplate(page.getClientSize().getWidth(), page.getClientSize().getHeight());
// Insert the watermark
insertWatermark(template, trueTypeFont, "Non Editable");
// Create a PdfWatermarkAnnotation object to define the watermark position
PdfWatermarkAnnotation watermarkAnnotation = new PdfWatermarkAnnotation(loRect);
// Create a PdfAppearance object to set the watermark appearance
PdfAppearance appearance = new PdfAppearance(watermarkAnnotation);
// Set the normal state template of the watermark
appearance.setNormal(template);
// Set the appearance to the watermark object
watermarkAnnotation.setAppearance(appearance);
// Set the watermark text
watermarkAnnotation.setText(watermarkAnnotationText);
// Set the watermark print matrix to control the watermark's position and size
watermarkAnnotation.getFixedPrint().setMatrix(new float[]{1, 0, 0, 1, 0, 0});
// Set the horizontal offset
watermarkAnnotation.getFixedPrint().setHorizontalTranslation(0.5f);
// Set the vertical offset
watermarkAnnotation.getFixedPrint().setVerticalTranslation(0.5f);
// Add the watermark to the page's annotation widget
page.getAnnotationsWidget().add(watermarkAnnotation);
}
// Save the PDF document to a file
pdfDocument.saveToFile("AddWatermark.pdf");
// Close and release the PDF document resources
pdfDocument.dispose();
}
static void insertWatermark(PdfTemplate template, PdfTrueTypeFont font, String watermark) {
// Create a Dimension2D object to set the size of the watermark
Dimension2D dimension2D = new Dimension();
// Set the size of the watermark to half the width and one third the height of the template
dimension2D.setSize(template.getWidth() / 2, template.getHeight() / 3);
// Create a PdfTilingBrush object for repeating pattern fill of the watermark
PdfTilingBrush brush = new PdfTilingBrush(dimension2D);
// Set the transparency of the watermark to 0.3
brush.getGraphics().setTransparency(0.3F);
// Start a group of graphic state saves
brush.getGraphics().save();
// Translate the graphics context so its center aligns with the center of the watermark tile
brush.getGraphics().translateTransform((float) brush.getSize().getWidth() / 2, (float) brush.getSize().getHeight() / 2);
// Rotate the graphics context to tilt the watermark at 45 degrees
brush.getGraphics().rotateTransform(-45);
// Draw the watermark text in the graphics context using the specified font, color, and centered alignment
brush.getGraphics().drawString(watermark, font, PdfBrushes.getGray(), 0, 0, new PdfStringFormat(PdfTextAlignment.Center));
// End the group of graphic state saves and restore
brush.getGraphics().restore();
// Reset the watermark transparency to 1, i.e., completely opaque
brush.getGraphics().setTransparency(1);
// Create a Rectangle2D object to define the area for filling the watermark
Rectangle2D loRect = new Rectangle2D.Float();
// Set the fill area for the watermark to cover the entire size of the template
loRect.setFrame(new Point2D.Float(0, 0), template.getSize());
// Draw the watermark on the template using the watermark tile
template.getGraphics().drawRectangle(brush, loRect);
}
}
Remove Watermark Annotations from PDF in Java
Spire.PDF can remove watermark annotations added to PDF pages via the PdfWatermarkAnnotation object. Here are the detailed steps:
- Initialize an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.loadFromFile() method.
- Iterate over every PdfPageBase object in the PDF document using a for loop.
- Retrieve all annotations on the current page using the PdfPageBase.getAnnotationsWidget() method.
- Again, use a for loop to iterate over every annotation object on the current page, filtering out annotations of type PdfWatermarkAnnotationWidget.
- Determine the target watermark annotation by invoking the PdfWatermarkAnnotationWidget.getText() method and perform the deletion operation.
- Save the changes to a file using the PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
import com.spire.pdf.annotations.*;
public class RemoveWatermarkFromPDF {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdfDocument = new PdfDocument();
// Load the PDF document from a file
pdfDocument.loadFromFile("Sample2.pdf");
// Define a string ID to match and remove a specific watermark
String id = "ID_0";
// Iterate through every page in the PDF document
for (int i = 0; i < pdfDocument.getPages().getCount(); i++) {
// Get all annotations on the current page
PdfAnnotationCollection annotationWidget = pdfDocument.getPages().get(i).getAnnotationsWidget();
// Iterate through all annotations on the current page
for (int j = 0; j < annotationWidget.getCount(); j++) {
// Check if the current annotation is a watermark annotation
if (annotationWidget.get(j) instanceof PdfWatermarkAnnotationWidget) {
// If the watermark text equals the ID, remove the watermark
if (annotationWidget.get(j).getText().equals(id)) {
annotationWidget.remove(annotationWidget.get(j));
}
}
}
}
// Save the modified PDF document to a new file
pdfDocument.saveToFile("RemoveWatermark.pdf");
// Dispose of the PdfDocument object resources
pdfDocument.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Bookmarks in PDF function as interactive table of contents, allowing users to quickly jump to specific sections within the document. Extracting these bookmarks not only provides a comprehensive overview of the document's structure, but also reveals its core parts or key information, providing users with a streamlined and intuitive method of accessing content. In this article, you will learn how to extract PDF bookmarks in Java using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
</dependencies>
Extract Bookmarks from PDF in Java
With Spire.PDF for Java, you can create custom methods GetBookmarks() and GetChildBookmark() to get the title and text styles of both parent and child bookmarks in a PDF file, then export them to a TXT file. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get bookmarks collection in the PDF file using PdfDocument.getBookmarks() method.
- Call custom methods GetBookmarks() and GetChildBookmark() to get the text content and text style of parent and child bookmarks.
- Export the extracted PDF bookmarks to a TXT file.
- Java
import com.spire.pdf.*;
import com.spire.pdf.bookmarks.*;
import java.io.*;
public class getAllPdfBookmarks {
public static void main(String[] args) throws IOException{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.loadFromFile("AnnualReport.pdf");
//Get bookmarks collections of the PDF file
PdfBookmarkCollection bookmarks = pdf.getBookmarks();
//Get the contents of bookmarks and save them to a TXT file
GetBookmarks(bookmarks, "GetPdfBookmarks.txt");
}
private static void GetBookmarks(PdfBookmarkCollection bookmarks, String result) throws IOException {
//create a StringBuilder instance
StringBuilder content = new StringBuilder();
//Get parent bookmarks information
if (bookmarks.getCount() > 0) {
content.append("Pdf bookmarks:");
for (int i = 0; i < bookmarks.getCount(); i++) {
PdfBookmark parentBookmark = bookmarks.get(i);
content.append(parentBookmark.getTitle() + "\r\n");
//Get the text style
String textStyle = parentBookmark.getDisplayStyle().toString();
content.append(textStyle + "\r\n");
GetChildBookmark(parentBookmark, content);
}
}
writeStringToTxt(content.toString(),result);
}
private static void GetChildBookmark(PdfBookmark parentBookmark, StringBuilder content)
{
//Get child bookmarks information
if (parentBookmark.getCount() > 0)
{
content.append("Pdf bookmarks:" + "\r\n");
for (int i = 0; i < parentBookmark.getCount(); i++)
{
PdfBookmark childBookmark = parentBookmark.get(i);
content.append(childBookmark.getTitle() +"\r\n");
//Get the text style
String textStyle = childBookmark.getDisplayStyle().toString();
content.append(textStyle +"\r\n");
GetChildBookmark(childBookmark, content);
}
}
}
public static void writeStringToTxt(String content, String txtFileName) throws IOException {
FileWriter fWriter = new FileWriter(txtFileName, true);
try {
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
