
PDFs sind allgegenwärtig – von Geschäftsverträgen und wissenschaftlichen Arbeiten bis hin zu Marketingbroschüren und juristischen Dokumenten. Aber jenseits des sichtbaren Textes und der Bilder enthalten PDFs verborgene Informationen, die als Metadaten bezeichnet werden. Diese Daten hinter den Kulissen liefern wichtige Details über den Ursprung, den Autor, das Erstellungsdatum und mehr eines Dokuments. Egal, ob Sie Content Creator, Entwickler, Jurist oder einfach nur jemand sind, der Dateien organisieren möchte, die Fähigkeit, Metadaten aus PDFs zu extrahieren, ist wertvoll.
Diese Anleitung führt Sie durch die effektivsten Methoden zum Extrahieren von PDF-Metadaten, von einfachen integrierten Tools bis hin zu fortschrittlichen Programmierbibliotheken.
- Warum Metadaten aus PDFs extrahieren?
- 4 bewährte Methoden zum Extrahieren von PDF-Metadaten
- Wichtige Hinweise zur Verarbeitung von PDF-Metadaten
- Häufig gestellte Fragen (FAQ)
Warum Metadaten aus PDFs extrahieren?
PDF-Metadaten sind weitaus nützlicher, als Sie vielleicht denken, und bieten Kernwerte in verschiedenen Szenarien:
| Anwendungsfall | Warum es wichtig ist |
|---|---|
| Digitale Forensik | Dokumentenherkunft und -änderungen verfolgen; gefälschte Dateien erkennen |
| Elektronische Beweiserhebung im Rechtswesen | Metadaten-Zeitstempel sind gerichtlich verwertbare Beweismittel |
| Content Management | Tausende von PDFs automatisch nach Autor, Datum oder Schlüsselwort taggen |
| SEO & Suchsichtbarkeit | Google verwendet den PDF-Titel/Betreff in Suchergebnissen |
| Datenschutz | Versteckte persönliche Daten vor der Weitergabe finden und entfernen |
| Workflow-Automatisierung | Rechnungsnummern und Berichtsdaten ohne manuelles Lesen extrahieren |
| Archivierung von Bibliotheken | Durchsuchbare PDF-Datenbanken für die Forschung erstellen |
Selbst bei einem einzelnen Dokument hilft Ihnen das Wissen, wie man PDF-Metadaten liest, die Authentizität zu überprüfen und das Auslaufen sensibler Informationen zu vermeiden.
Lesen Sie auch: So bearbeiten Sie PDF-Metadaten (4 Methoden)
4 bewährte Methoden zum Extrahieren von PDF-Metadaten (Vom Anfänger bis zum Profi)
Abhängig davon, wie vertraut Sie mit Tools sind und wie viele Dateien Sie bearbeiten, stehen Ihnen verschiedene Optionen zur Verfügung, um Metadaten aus PDFs zu erhalten, die No-Code-, Online-, Programmier- und Kommandozeilenansätze abdecken.
1. Adobe Acrobat Pro (Windows/Mac)
Adobe Acrobat Pro ist der Industriestandard für PDF-Arbeiten. Es bietet eine saubere grafische Oberfläche zum Anzeigen und Exportieren von Standard- und erweiterten Metadaten.
So verwenden Sie es:
- Öffnen Sie Ihr PDF in Adobe Acrobat Pro.
- Klicken Sie auf „Datei“ > „Eigenschaften“ (oder drücken Sie Strg+D/Cmd+D).
- Der Tab „Beschreibung“ zeigt Standardmetadaten (Titel, Autor, Betreff usw.). Der Tab „Erweitert“ zeigt tiefere XMP-Daten (z. B. Version der PDF-Erstellungssoftware).
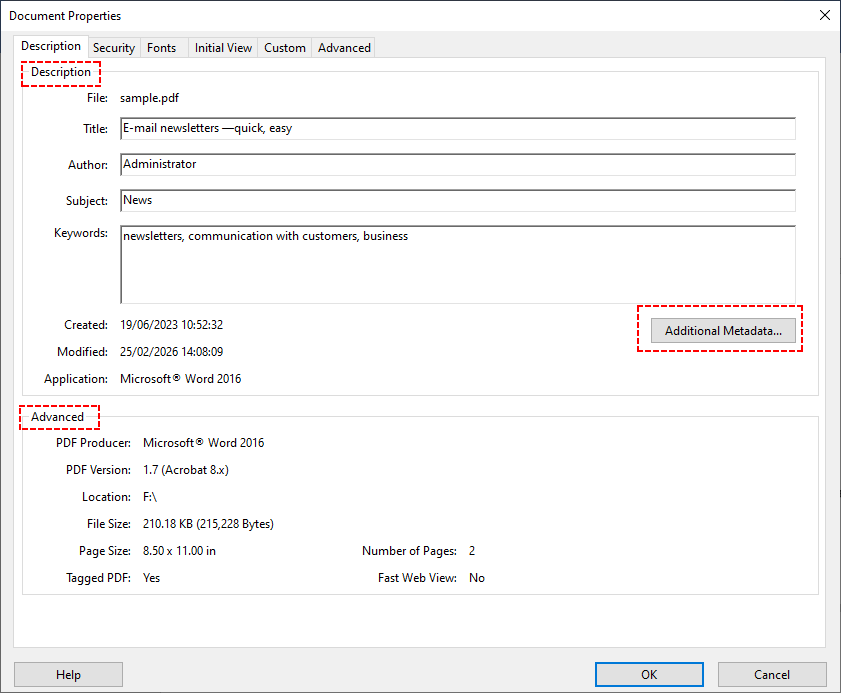
- Für noch mehr benutzerdefinierte Felder klicken Sie auf „Zusätzliche Metadaten“, um alle XMP-Eigenschaften zu durchsuchen.
- Wählen Sie „Exportieren“, um als XMP-Datei zu speichern. Diese Datei kann in andere Adobe-Tools importiert oder von benutzerdefinierten Skripten gelesen werden.
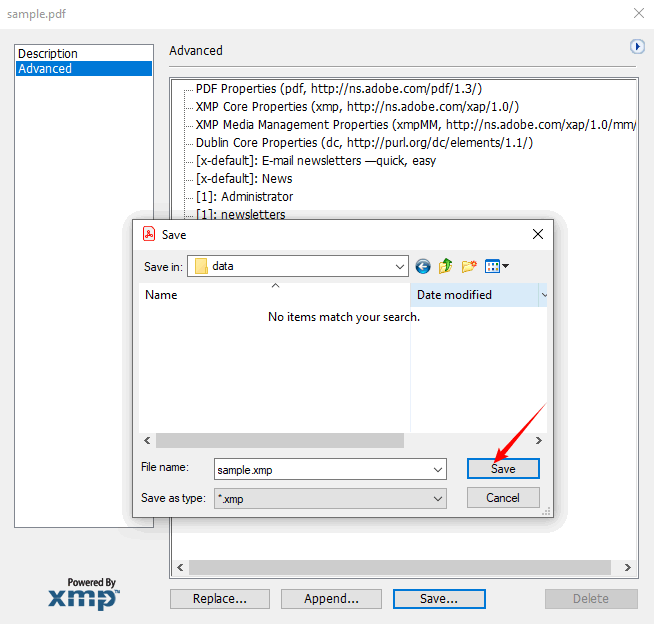
Nachteil: Erfordert ein Abonnement. Geeignet für Profis, die bereits Acrobat Pro haben, aber übertrieben für eine schnelle Überprüfung einer einzelnen Datei.
Viele geschützte PDFs schränken den Zugriff auf Metadaten ein. Daher entfernt das Entfernen von PDF-Berechtigungen den vollen Zugriff auf Metadaten und Dokumenteninhalte, sodass Sie Metadaten aus passwortgeschützten oder eingeschränkten Dateien ohne Einschränkungen extrahieren, ändern oder exportieren können.
2. Kostenlose Online-Metadaten-Extraktoren (Schnell und einfach)
Eine schnelle Google-Suche liefert Dutzende von Websites, auf denen Sie eine PDF-Datei hochladen und ihre Metadaten anzeigen können. Beliebte Beispiele wie Metadata2Go und GroupDocs PDF Metadata Extractor sind unglaublich praktisch – keine Installation, keine Zahlung, und sie funktionieren auf jedem Gerät.
PDF-Metadaten online mit Metadata2Go abrufen:
- Gehen Sie zur Seite Metadaten anzeigen des Tools.
- Laden Sie die PDF-Datei per Drag-and-Drop hoch oder klicken Sie auf „Datei auswählen“.
- Warten Sie, bis das Tool Metadaten aus Ihrer PDF-Datei extrahiert hat.
- Exportieren Sie die Ergebnisse nach Bedarf in CSV/TXT/JSON/HTML.
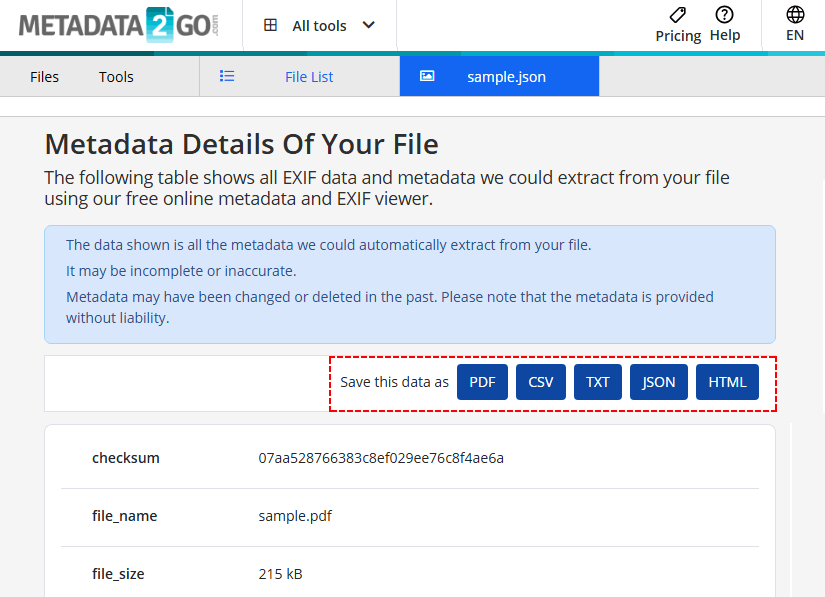
Sicherheitsrisiko: Laden Sie niemals sensible oder vertrauliche Dokumente auf ein kostenloses Online-Tool hoch.
3. PDF-Metadaten programmatisch extrahieren (Für Entwickler)
Wenn Sie Metadaten aus Hunderten von PDFs extrahieren oder die Metadatenextraktion in Ihre eigene Anwendung integrieren müssen, ist Programmierung der richtige Weg. Nachfolgend finden Sie ein detailliertes Beispiel mit C# und der Bibliothek Free Spire.PDF for .NET.
Schritt 1 – Installieren Sie die Bibliothek über NuGet
Install-Package FreeSpire.PDF
Schritt 2 – Schreiben Sie C#-Code zum Lesen von PDF-Metadaten
using Spire.Pdf;
using System.IO;
using System.Text;
namespace ExtractPDFMetadata
{
class Program
{
static void Main(string[] args)
{
// Erstellen Sie ein PdfDocument-Objekt
PdfDocument pdf = new PdfDocument();
// Laden Sie die PDF-Datei (ändern Sie den Pfad zu Ihrer Datei)
pdf.LoadFromFile("F:\\sample.pdf");
// Greifen Sie auf die Dokumenteninformationen zu
PdfDocumentInformation info = pdf.DocumentInformation;
// Erstellen Sie eine Metadaten-Zeichenkette
StringBuilder content = new StringBuilder();
content.AppendLine("Ergebnisse der PDF-Metadatenextraktion");
content.AppendLine("================================");
content.Append("Titel: " + info.Title + "\r\n");
content.Append("Autor: " + info.Author + "\r\n");
content.Append("Ersteller: " + info.Creator + "\r\n");
content.Append("Betreff: " + info.Subject + "\r\n");
content.Append("Schlüsselwörter: " + info.Keywords + "\r\n");
content.Append("PDF-Produzent: " + info.Producer + "\r\n");
// Schreiben Sie das Ergebnis in eine TXT-Datei
File.WriteAllText("ExtractPDFMetadata.txt", content.ToString());
}
}
}
Der Code lädt eine PDF-Datei, ruft ihre Standard-Metadatenfelder ab und schreibt sie in eine Textdatei.
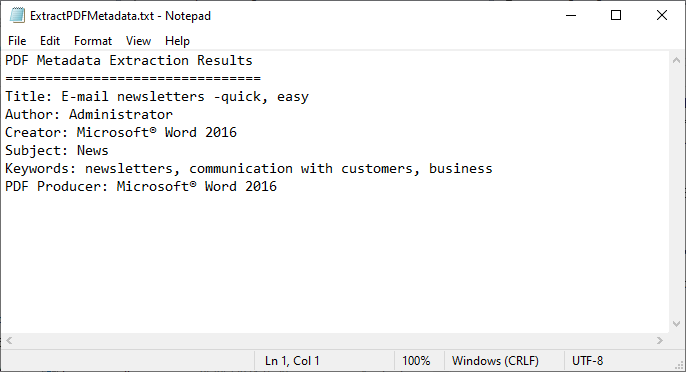
Stapelverarbeitung: Um Metadaten aus mehreren Dateien zu extrahieren, durchlaufen Sie alle PDFs in einem Ordner:
foreach (string file in Directory.GetFiles(@"C:\Invoices\", "*.pdf"))
{
// jede Datei verarbeiten
}
Profi-Tipp: Neben grundlegenden Metadaten unterstützt Free Spire.PDF auch die Extraktion anderer Elemente, wie z. B. das Extrahieren von Bildern, Hyperlinks, Formularfeldwerte usw.
4. Kommandozeile mit ExifTool (Für fortgeschrittene Benutzer)
Wenn Sie mit einem Terminal oder einer Eingabeaufforderung vertraut sind, ist ExifTool ein leistungsstarkes Werkzeug zur Metadatenextraktion. Es ist kostenlos, plattformübergreifend (Windows, macOS, Linux) und liest Metadaten aus fast jedem Dateityp, nicht nur aus PDFs.
Installation
Unter Windows laden Sie die ausführbare Datei von der offiziellen Website herunter.
Grundlegende Verwendung – Metadaten einer einzelnen PDF anzeigen:
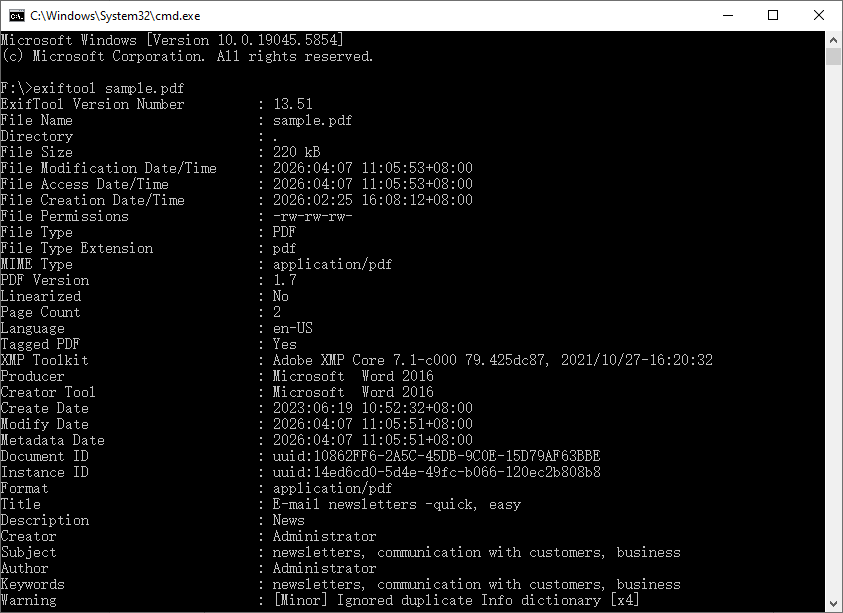
exiftool sample.pdf
Dies gibt eine lange Liste von Tag-Wert-Paaren direkt im Terminal aus.
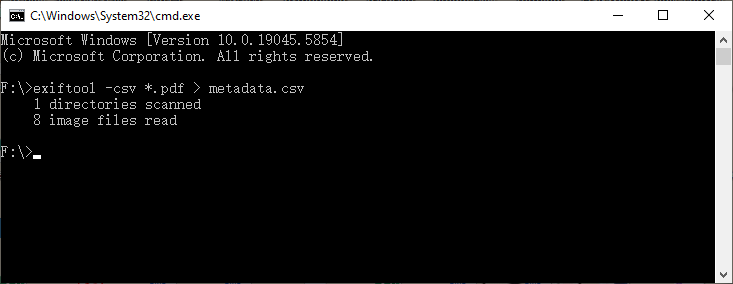
Stapelweise Export nach CSV (ideal für die Analyse in Excel):
exiftool -csv *.pdf > metadata.csv
Dieser Befehl prüft Hunderte von PDFs gleichzeitig und erstellt eine CSV-Datei, die Sie in Excel oder Google Sheets öffnen können, um einen durchsuchbaren Katalog zu erhalten.
Wann Sie dies verwenden sollten: Große Stapelprüfungen, forensische Analysen oder wenn Sie die Effizienz der Kommandozeile bevorzugen.
Die Metadatenentfernung ist eine kritische Sicherheitsfunktion, die neben der Extraktion funktioniert. Nachdem Sie die extrahierten Metadaten überprüft haben, können Sie alle versteckten sensiblen Metadaten aus PDFs entfernen, um Datenschutzlecks zu verhindern, bevor Sie Dateien extern weitergeben.
Wichtige Hinweise zur Verarbeitung von PDF-Metadaten
- Metadaten können bearbeitet oder gefälscht werden.
Nur weil in einem PDF steht „Autor: Max Mustermann“, heißt das nicht, dass Max Mustermann es tatsächlich geschrieben hat. Es liefert hilfreichen Kontext, ist aber ohne tiefere Analyse kein forensischer Beweis.
- Gescannte PDFs sind anders.
Wenn jemand ein physisches Dokument gescannt und als PDF gespeichert hat, erhalten Sie normalerweise nur Scannerinformationen und ein Erstellungsdatum. Es gibt keinen „Autor“ oder „Schlüsselwörter“, es sei denn, jemand fügt sie später hinzu.
- SEO-Tipp.
Wenn Sie PDFs auf Ihrer Website platzieren, füllen Sie die Felder Titel und Betreff aus. Google verwendet diese oft für den Titel und die Beschreibung in den Suchergebnissen, was besser ist, als einen zufälligen Dateinamen anzuzeigen.
Zusammenfassung
Das Extrahieren von Metadaten aus PDFs ist eine praktische Fähigkeit, die Zeit spart, die Privatsphäre schützt und manchmal genau das Detail aufdeckt, das Sie gesucht haben. Egal, ob Sie das Eigenschaftenfenster von Acrobat für eine schnelle Überprüfung, ein kostenloses Online-Tool für öffentliche Dokumente, ein C#-Skript zur Verarbeitung Tausender von Rechnungen oder ExifTool für Massenprüfungen über die Kommandozeile verwenden, die richtige Methode hängt davon ab, wie viele Dateien Sie bearbeiten und wie tief Sie gehen müssen.
Wenn Sie das nächste Mal eine PDF-Datei herunterladen oder eine zum Teilen vorbereiten, nehmen Sie sich einen Moment Zeit, um ihre Metadaten anzusehen. Sie werden vielleicht überrascht sein, was angehängt ist, und Sie wissen jetzt genau, wie Sie es extrahieren können.
Häufig gestellte Fragen (FAQ)
F1: Kann ich Metadaten aus gescannten PDFs extrahieren?
Gescannte PDFs (die nur Bilder sind) haben normalerweise keine Metadaten. Sie müssen eine OCR-Software verwenden, um das Bild in Text umzuwandeln und dann Metadaten manuell hinzuzufügen.
F2: Sind Metadaten dasselbe wie Dateieigenschaften?
Nicht ganz. Dateieigenschaften (wie Dateigröße, Erstellungsdatum) werden vom Betriebssystem verwaltet. PDF-Metadaten sind in das PDF selbst eingebettet und reisen mit dem Dokument.
F3: Kann ich PDF-Metadaten bearbeiten oder löschen?
Ja. Verwenden Sie Adobe Acrobat Pro (grafisch) oder ExifTool (Kommandozeile), um Metadaten zu bearbeiten/löschen; Programmierbibliotheken unterstützen ebenfalls die Änderung.
F4: Beeinflussen Metadaten die Dateigröße von PDFs?
Nein. Metadaten sind leichte Textdaten und haben keinen spürbaren Einfluss auf die Dateigröße.