
Stellen Sie sich vor: Sie finden endlich den genauen Forschungsbericht, den Geschäftsvertrag oder das datenreiche Whitepaper, das Sie benötigen, aber es ist in einem PDF gefangen. Wenn Sie versuchen, den Inhalt zu kopieren und einzufügen, stoßen Sie auf durcheinandergebrachte Formatierungen, nicht auswählbaren Text oder frustrierende Inhaltsschutzblöcke. Die Frage ist universell: Wie extrahiert man Text aus PDF-Dateien ohne manuelles Abtippen oder teure Software?
In diesem umfassenden Leitfaden werden wir die besten Möglichkeiten untersuchen, kostenlos Text aus PDF zu extrahieren (einschließlich gescannter PDFs mit OCR). Ob Sie Student, Geschäftsprofi oder Entwickler sind, Sie werden die perfekte Methode finden, um PDF-Text genau und effizient zu extrahieren.
- Warum das Extrahieren von PDF-Text schwierig sein kann?
- Der einfachste Trick – Kopieren und Einfügen
- Top kostenlose Online-Tools zum Extrahieren von Text aus PDF
- PDF24 Creator Kostenlose Desktop-Tools zur PDF-Textextraktion
- Kostenloses Entwickler-Tool zum Extrahieren von PDF-Text in C#
- Häufig gestellte Fragen (FAQ)
Warum das Extrahieren von PDF-Text schwierig sein kann?
PDFs speichern Text auf eine Weise, die die visuelle Konsistenz priorisiert. Das bedeutet, dass der Text möglicherweise als fragmentierte Blöcke, in einer ungewöhnlichen Reihenfolge oder, schlimmer noch, als Teil eines Bildes gespeichert ist. Es gibt zwei Haupttypen von PDFs, von denen jeder einzigartige Extraktionsherausforderungen mit sich bringt:
- Digitale PDFs: Diese enthalten auswählbaren Text, aber komplexe Layouts wie mehrspaltige Artikel oder Tabellen können einfache Kopier- und Einfügeaktionen verwirren.
- Gescannte PDFs: Dies sind im Wesentlichen Bilder von Seiten. Um Text aus einem gescannten PDF zu extrahieren, benötigen Sie die OCR (Optical Character Recognition)-Technologie, die das Bild analysiert und die Formen von Buchstaben erkennt.
Glücklicherweise bewältigen die unten aufgeführten kostenlosen Tools beide Typen mit Leichtigkeit.
Der einfachste Trick – Kopieren und Einfügen
Wenn Sie ein einfaches, digitales PDF haben und nur einen kleinen Textabschnitt benötigen, übersehen Sie nicht die Grundlagen. Es ist der schnellste Weg, um Text aus PDF für kleine Aufgaben zu erhalten.
- Öffnen Sie das PDF: Verwenden Sie einen Standard-Viewer wie Adobe Acrobat Reader, einen Webbrowser (wie Chrome oder Edge) oder eine Vorschau-App.
- Auswählen und Kopieren: Markieren Sie den gewünschten Text, klicken Sie mit der rechten Maustaste und wählen Sie "Kopieren" oder verwenden Sie die Tastenkombinationen „Strg+C“ (Windows) oder „Befehl+C“ (Mac).
- Einfügen: Öffnen Sie einen Texteditor (wie Notepad oder TextEdit) oder ein Word-Dokument und fügen Sie den Text mit „Strg+V“ oder „Befehl+V“ ein.
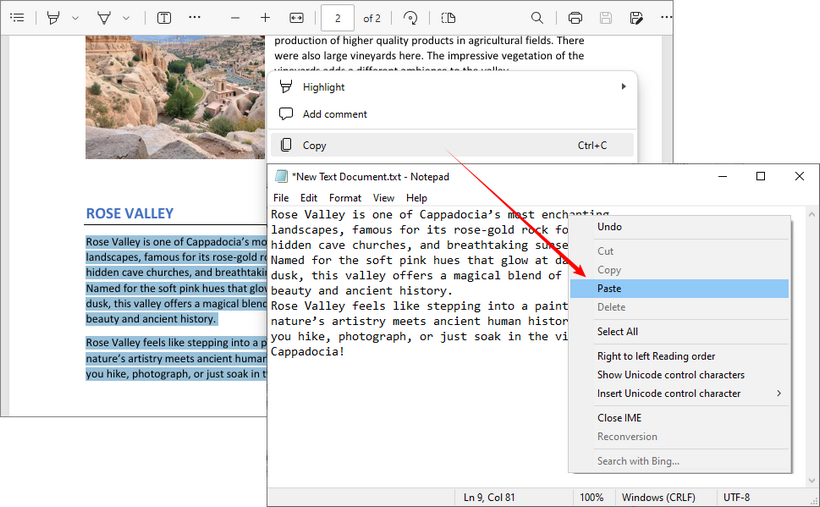
Der Haken: Diese Methode schlägt bei gescannten Dokumenten, geschützten PDFs oder wenn Sie komplexe Formatierungen beibehalten müssen, fehl. Verwenden Sie für diese Fälle die unten aufgeführten dedizierten kostenlosen Tools oder lesen Sie unseren Leitfaden zum Kopieren von Text aus einem gesicherten PDF.
Top kostenlose Online-Tools zum Extrahieren von Text aus PDF
Für die meisten Benutzer sind kostenlose Online-Tools der schnellste und einfachste Weg, um kostenlos Text aus PDF zu extrahieren. Sie funktionieren direkt in Ihrem Browser, erfordern keine Installation und viele enthalten jetzt leistungsstarke OCR-Funktionen. Nachfolgend finden Sie die beiden Top-Picks für verschiedene Anwendungsfälle – von der einfachen Textextraktion bis zur mehrsprachigen OCR.
CLOUDXDOCS - Einfachstes kostenloses Tool für digitale PDFs
Wenn Sie ein schnörkelloses, werbefreies Tool zum Extrahieren von Text aus textbasierten PDFs (nicht gescannt) benötigen, ist CLOUDXDOCS ideal. Es ist 100 % kostenlos, erfordert keine Registrierung und funktioniert mit einem Klick – perfekt, um in Sekundenschnelle Text aus PDF-Dateien zu extrahieren.
Schritte zum Online-Extrahieren von Text aus PDF:
- Besuchen Sie den CLOUDXDOCS kostenlosen PDF zu Text Konverter.
- Laden Sie Ihre PDF-Datei per Drag & Drop hoch oder klicken Sie zum Durchsuchen.
- Warten Sie, bis das Tool Ihre Datei verarbeitet hat.
- Laden Sie den extrahierten Text als TXT-Datei herunter.
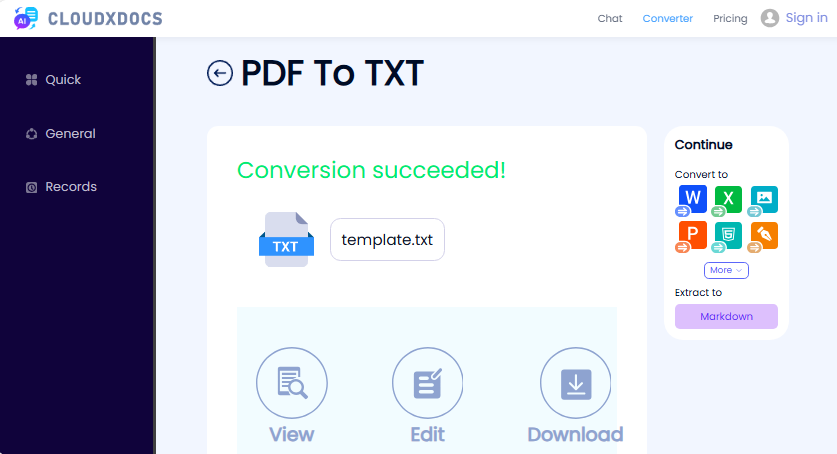
✔ Vorteile: Keine Anmeldung, keine Werbung, einfache Benutzeroberfläche.
✘ Nachteile: Kein OCR (funktioniert nicht bei gescannten PDFs).
i2OCR - Kostenloses OCR-Tool für gescannte PDFs
i2OCR ist ein kostenloses Online-Tool, das sich auf OCR für Bilder und gescannte PDFs spezialisiert hat und über 100 Sprachen unterstützt – perfekt für nicht-englische PDFs. Es ist für die einseitige Nutzung kostenlos und bietet mehrere Ausgabeformate.
Schritte zum kostenlosen Online-Extrahieren von Text aus gescannten PDFs:
- Besuchen Sie das i2OCR PDF OCR-Tool.
- Wählen Sie Ihre Erkennungssprache und die bevorzugte OCR-Engine.
- Klicken Sie auf „PDF auswählen“, um Ihr gescanntes PDF hochzuladen.
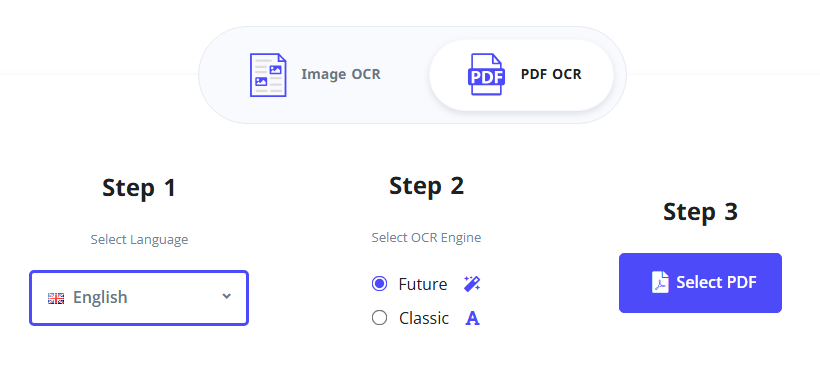
- Klicken Sie auf „OCR starten“ und warten Sie, bis das Tool den Scan verarbeitet hat.
- Kopieren Sie den extrahierten Text oder laden Sie ihn als TXT, Word oder HTML herunter.
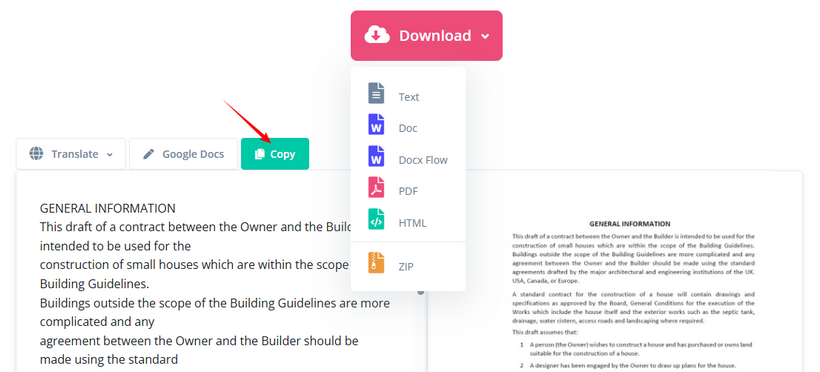
✔ Vorteile: Unterstützung für über 100 Sprachen, kostenloses OCR, mehrere Ausgabeformate, keine Anmeldung.
✘ Nachteile: Der kostenlose Plan unterstützt nur eine Seite auf einmal.
Neben Text enthalten PDFs oft wertvolle Bilder, Diagramme oder Schaubilder – entdecken Sie, wie Sie in Ihrem PDF-Dokument eingebettete Bilder extrahieren.
PDF24 Creator Kostenlose Desktop-Tools zur PDF-Textextraktion
Wenn Sie häufig mit PDFs arbeiten, Offline-Zugriff benötigen oder große Dateien zu verarbeiten haben, ist PDF24 Creator die ideale Wahl. Dieses kostenlose, exklusiv für Windows erhältliche Desktop-Tool bietet umfassende PDF-Bearbeitungsfunktionen – einschließlich Textextraktion, OCR für gescannte PDFs und Stapelverarbeitung – und das alles, während Ihre Dateien für maximale Privatsphäre lokal bleiben.
Text aus einem digitalen (auswählbaren) PDF extrahieren
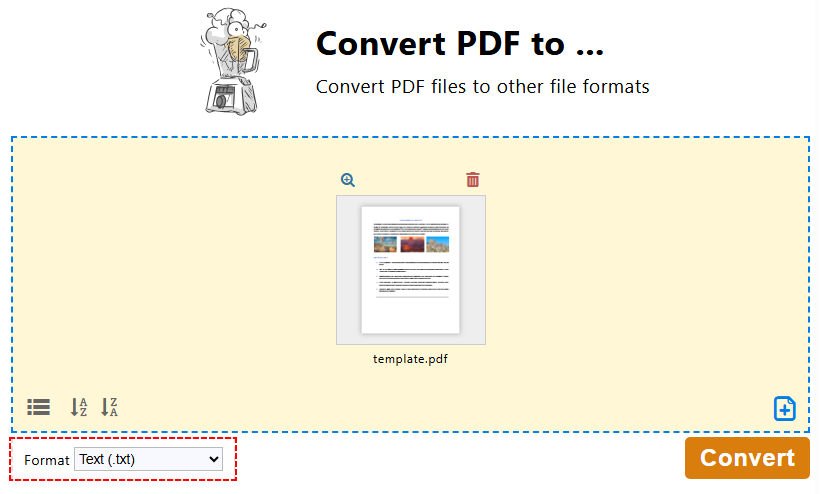
- Gehen Sie zur offiziellen PDF24 Creator-Downloadseite und laden Sie die passende Version für Ihr Windows-System herunter.
- Installieren und starten Sie PDF24. Sie sehen die PDF24 Toolbox (ein Dashboard mit vielen PDF-Tools).
- Klicken Sie in der PDF24 Toolbox auf „PDF konvertieren in…“.
- Klicken Sie auf „Dateien auswählen“ oder ziehen Sie Ihre PDF-Datei per Drag & Drop, um sie hochzuladen.
- Wählen Sie „Text (.txt)“ als Ausgabeformat und klicken Sie auf „Konvertieren“.
- Speichern Sie die extrahierte Textdatei auf Ihrem Gerät.
Text aus einem gescannten PDF extrahieren (mit OCR)
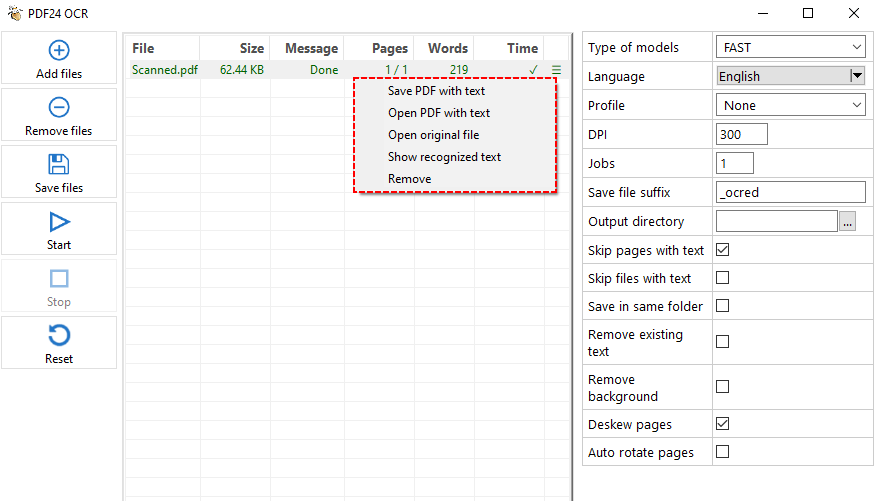
Für gescannte/bildbasierte PDFs verwenden Sie die integrierte OCR von PDF24, um Text aus PDF-Scans zu erkennen und in bearbeitbaren Text oder durchsuchbare PDFs umzuwandeln:
- Klicken Sie in der PDF24 Toolbox auf „PDF OCR“.
- Klicken Sie auf „Datei(en) hinzufügen“ und wählen Sie Ihr gescanntes PDF aus.
- Wählen Sie im rechten Einstellungsfenster den Texterkennungsmodus, die Sprache, die DPI, das Ausgabeverzeichnis usw. aus.
- Klicken Sie auf die Schaltfläche „Start“, um das PDF zu verarbeiten.
- PDF24 verarbeitet jede Seite, erkennt den Text und speichert ihn in einer Textdatei oder einem durchsuchbaren PDF.
Profi-Tipp für Adobe-Benutzer:
Wenn Sie Adobe Acrobat Pro (kostenpflichtig) haben, können Sie Text extrahieren, indem Sie zum Werkzeug „PDF exportieren“ gehen und „Text (einfach)“ als Ausgabeformat auswählen. Acrobat speichert die Datei sofort als .txt-Dokument.
Kostenloses Entwickler-Tool zum Extrahieren von PDF-Text in C#
Wenn Sie Entwickler sind, ist Free Spire.PDF for .NET eine kostenlose, abhängigkeitsfreie Bibliothek zum programmgesteuerten Lesen von Text aus PDFs. Es ist schnell, leicht und perfekt für die Integration der PDF-Textextraktion in Ihre Projekte.
C#-Code zum Extrahieren von Text aus PDF
Der Code durchläuft jede Seite in einer digitalen PDF-Datei und extrahiert den gesamten Text aus dem PDF. Zu den wichtigsten Klassen und Methoden zur Textextraktion gehören:
- PdfTextExtractor: Eine spezialisierte Dienstprogrammklasse, die Text von einer einzelnen PDF-Seite (eine Seite nach der anderen) extrahiert.
- PdfTextExtractOptions: Eine Konfigurationsklasse für die Textextraktion. Legt Regeln fest, z. B. ob der gesamte Text extrahiert werden soll.
- ExtractText(): Führt die Textextraktion auf der PDF-Seite aus und gibt die extrahierte Zeichenfolge zurück.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Text;
namespace ExtractAllTextFromPDF
{
internal class Program
{
static void Main(string[] args)
{
// Create a PDF document instance
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.LoadFromFile("SamplePDF.pdf");
// Initialize a StringBuilder to hold the extracted text
StringBuilder extractedText = new StringBuilder();
// Loop through each page in the PDF
foreach (PdfPageBase page in pdf.Pages)
{
// Create a PdfTextExtractor for the current page
PdfTextExtractor extractor = new PdfTextExtractor(page);
// Set extraction options
PdfTextExtractOptions option = new PdfTextExtractOptions
{
IsExtractAllText = true
};
// Extract text from the current page
string text = extractor.ExtractText(option);
// Append the extracted text to the StringBuilder
extractedText.AppendLine(text);
}
// Save the extracted text to a text file
File.WriteAllText("ExtractedText.txt", extractedText.ToString());
// Close the PDF document
pdf.Close();
}
}
}
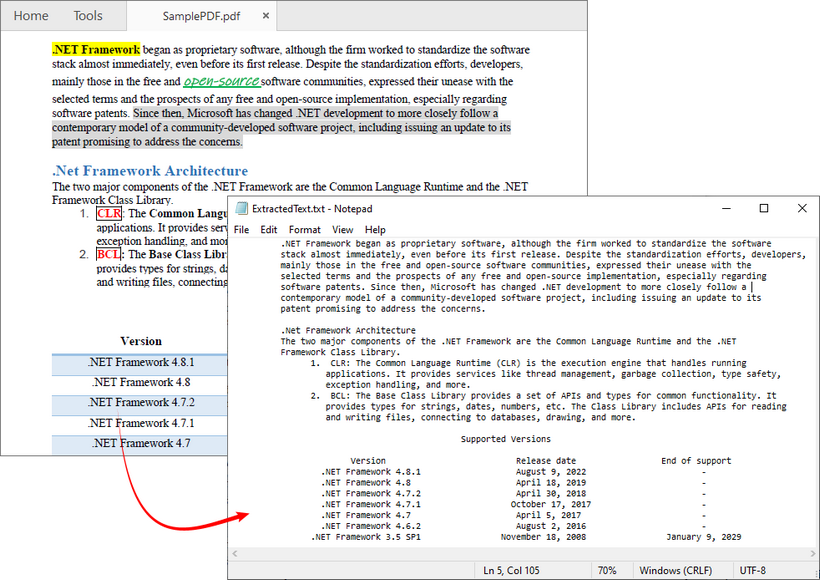
Über das Extrahieren des gesamten Textes hinaus ermöglicht Ihnen Free Spire.PDF auch, Text von einer einzelnen Seite oder einem bestimmten Bereich zu extrahieren. Das Extraktionsergebnis wird unten gezeigt:
Profi-Tipp: Um Text aus einem gescannten PDF in C# zu extrahieren, folgen Sie der offiziellen Anleitung: OCR an gescannten PDFs in C# zur Textextraktion durchführen
Häufig gestellte Fragen (FAQ)
F1: Wie kann ich kostenlos Text aus einem gescannten PDF extrahieren?
A: Tools wie i2OCR, PDF24 bieten alle kostenlose OCR-Optionen. Laden Sie einfach Ihr gescanntes PDF hoch und aktivieren Sie die OCR-Einstellung vor dem Extrahieren.
F2: Unterstützen kostenlose Tools die Stapel-Textextraktion?
A: Ja, aber die Methode ist entscheidend. Die meisten kostenlosen Online-Tools haben Mengenbeschränkungen, aber Sie können ein Offline-Desktop-Tool wie PDF24 Creator oder eine programmatische Lösung verwenden, um mehrere PDFs im Stapel zu verarbeiten.
F3: Was ist der beste Weg, um Tabellen aus einem PDF zu extrahieren?
A: Das Extrahieren von Tabellen in reinen Text ist bekanntermaßen schwierig, da die tabellarische Struktur verloren geht. Ihre beste Wahl ist die Verwendung eines Tools, das das PDF in Excel (XLSX) oder CSV konvertieren kann. Dadurch wird versucht, die Daten in Zellen zu platzieren und die Struktur beizubehalten.
F4: Wie extrahiere ich Text aus einem PDF und behalte die Formatierung bei?
A: Reiner Text (.txt) kann Formatierungen wie Fett, Kursiv oder Schriftgrößen nicht beibehalten. Um die Formatierung beizubehalten, sollten Sie Ihr PDF in ein Word-Dokument (.docx) konvertieren.
Zusammenfassung
Dieser Artikel stellt mehrere zuverlässige Möglichkeiten vor, kostenlos Text aus PDF zu extrahieren, unabhängig von Ihrem technischen Kenntnisstand oder der Komplexität des Dokuments.
Für eine schnelle, einmalige Aufgabe ist ein zuverlässiges Online-Tool wie CLOUDXDOCS die beste Wahl. Für wiederkehrende Arbeiten oder sensible Informationen greifen Sie auf Offline-Software wie PDF24 zurück. Und wenn Sie eine hochmoderne, automatisierte Inhalts-Pipeline aufbauen möchten, kann die Erkundung einer Codelösung wie Free Spire.PDF Ihren Arbeitsablauf revolutionieren.
Mit diesem Leitfaden sind Sie nun gerüstet, den in jedem PDF verborgenen Text freizuschalten und für sich zu nutzen.
Siehe auch
- PDF-Tabellen in CSV konvertieren: Manuell, Online & Automatisiert
- Wie man ein PDF entsichert (mit oder ohne Passwort)
- Wie man kostenlos Seiten aus einem PDF extrahiert – kein Adobe erforderlich
- Text aus PDF in Python extrahieren: Ein vollständiger Leitfaden mit praktischen Codebeispielen
- PDF zu Text in Java: Text aus PDFs extrahieren (textbasiert & gescannt)