
Los PDF están en todas partes: desde contratos comerciales y trabajos académicos hasta folletos de marketing y documentos legales. Pero más allá del texto e imágenes visibles, cada PDF contiene información oculta llamada metadatos. Estos datos detrás de escena ofrecen detalles críticos sobre el origen del documento, el autor, la fecha de creación y más. Ya sea que sea un creador de contenido, desarrollador, profesional legal o simplemente alguien que busca organizar archivos, saber cómo extraer metadatos de un PDF es una habilidad valiosa.
Esta guía le mostrará los métodos más efectivos para extraer metadatos de PDF, desde herramientas integradas sencillas hasta bibliotecas de programación avanzadas.
- ¿Por qué molestarse en extraer metadatos?
- 4 Métodos probados para extraer metadatos de PDF
- Notas críticas para el procesamiento de metadatos de PDF
- Preguntas frecuentes (FAQ)
¿Por qué molestarse en extraer metadatos?
Los metadatos de PDF son mucho más útiles de lo que podrías pensar, con valor central en múltiples escenarios:
| Caso de Uso | Por qué es importante |
|---|---|
| Forense digital | Rastrear el origen y los cambios del documento; detectar archivos falsificados |
| Descubrimiento electrónico legal | Las marcas de tiempo de los metadatos son pruebas admisibles en juicio |
| Gestión de contenidos | Etiquetar automáticamente miles de PDF por autor, fecha o palabra clave |
| SEO y visibilidad en búsquedas | Google utiliza el título/tema del PDF en los fragmentos de búsqueda |
| Protección de la privacidad | Encontrar y eliminar datos personales ocultos antes de compartir |
| Automatización de flujos de trabajo | Extraer números de factura y fechas de informes sin lectura manual |
| Archivo de biblioteca | Crear bases de datos de PDF buscables para investigación |
Incluso para un solo documento, saber cómo leer metadatos de PDF ayuda a verificar la autenticidad y evitar la fuga de información confidencial.
Lea también: Cómo editar metadatos de PDF (4 métodos)
4 Métodos probados para extraer metadatos de PDF (Desde principiante hasta profesional)
Dependiendo de su comodidad con las herramientas y la cantidad de archivos con los que está tratando, tiene varias opciones para obtener metadatos de un PDF, cubriendo enfoques sin código, en línea, de programación y de línea de comandos.
1. Adobe Acrobat Pro (Windows/Mac)
Adobe Acrobat Pro es el estándar de la industria para el trabajo con PDF. Proporciona una interfaz gráfica limpia para ver y exportar metadatos estándar y avanzados.
Así es como se usa:
- Abra su PDF en Adobe Acrobat Pro.
- Haga clic en "Archivo" > "Propiedades" (o presione Ctrl+D/Comando+D).
- La pestaña "Descripción" muestra metadatos estándar (título, autor, tema, etc.). La pestaña "Avanzado" muestra datos XMP más profundos (por ejemplo, versión del software de creación de PDF).
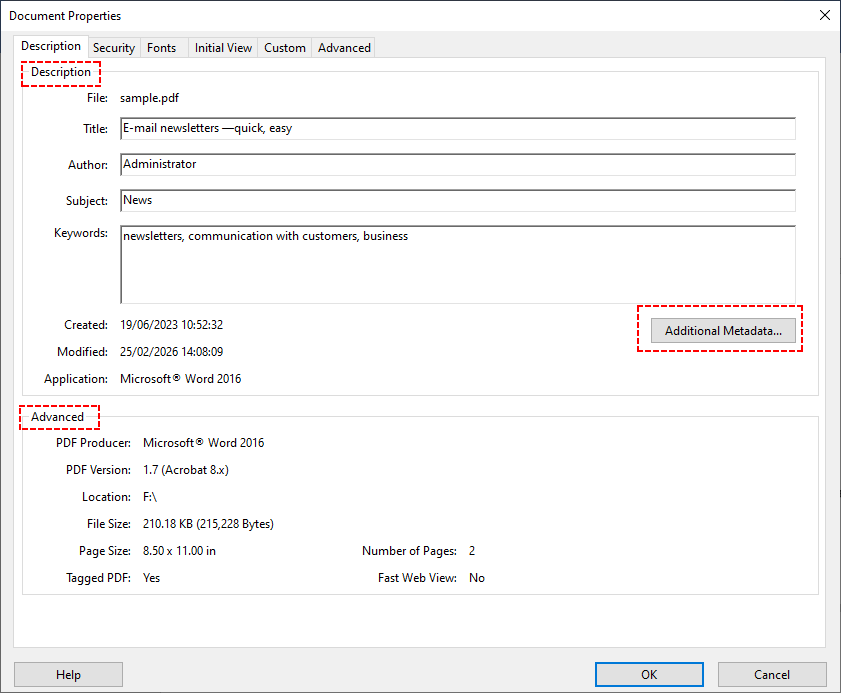
- Para campos aún más personalizados, haga clic en "Metadatos adicionales" para explorar todas las propiedades XMP.
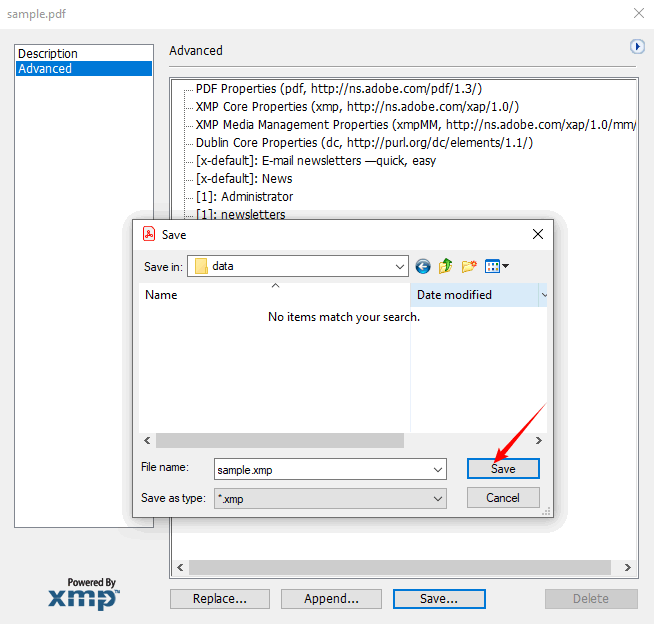
- Seleccione "Exportar" para guardar como un archivo XMP. Este archivo puede ser importado en otras herramientas de Adobe o leído por scripts personalizados.
Desventaja: Requiere una suscripción. Adecuado para profesionales que ya tienen Acrobat Pro, pero excesivo para una verificación rápida de un solo archivo.
Muchos PDF protegidos restringen el acceso a los metadatos, por lo que eliminar permisos de PDF desbloquea el acceso completo a los metadatos y al contenido del documento, lo que le permite extraer, modificar o exportar metadatos de archivos protegidos con contraseña o restringidos sin limitaciones.
2. Extractores de metadatos en línea gratuitos (rápido y fácil)
Una búsqueda rápida en Google arroja docenas de sitios que le permiten cargar un PDF y ver sus metadatos. Ejemplos populares como Metadata2Go y GroupDocs PDF Metadata Extractor son increíblemente convenientes: sin instalación, sin pago y funcionan en cualquier dispositivo.
Obtener metadatos de PDF en línea usando Metadata2Go:
- Vaya a la página Ver Metadatos de la herramienta.
- Cargue el PDF mediante arrastrar y soltar o haga clic en "Elegir archivo".
- Espere a que la herramienta extraiga los metadatos de su archivo PDF.
- Exporte los resultados a CSV/TXT/JSON/HTML según sea necesario.
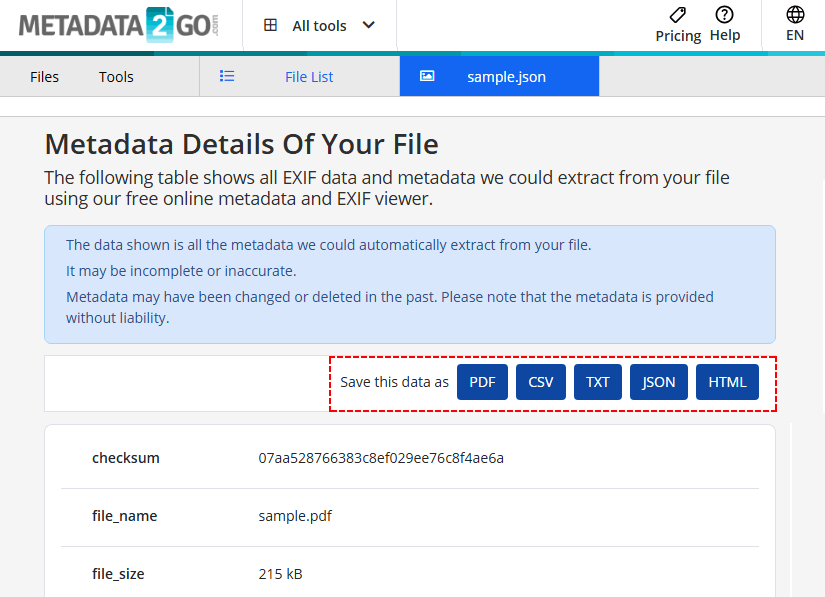
Riesgo de seguridad: Nunca cargue documentos sensibles o confidenciales en una herramienta en línea gratuita.
3. Extraer metadatos de PDF mediante programación (para desarrolladores)
Si necesita extraer metadatos de cientos de PDF o integrar la extracción de metadatos en su propia aplicación, la programación es el camino a seguir. A continuación, se muestra un ejemplo detallado que utiliza C# y la biblioteca Free Spire.PDF for .NET.
Paso 1 - Instalar la biblioteca a través de NuGet
Install-Package FreeSpire.PDF
Paso 2 – Escribir código C# para leer metadatos de PDF
using Spire.Pdf;
using System.IO;
using System.Text;
namespace ExtractPDFMetadata
{
class Program
{
static void Main(string[] args)
{
// Crear un objeto PdfDocument
PdfDocument pdf = new PdfDocument();
// Cargar el archivo PDF (cambiar la ruta a su archivo)
pdf.LoadFromFile("F:\\sample.pdf");
// Acceder a la información del documento
PdfDocumentInformation info = pdf.DocumentInformation;
// Construir cadena de metadatos
StringBuilder content = new StringBuilder();
content.AppendLine("Resultados de Extracción de Metadatos de PDF");
content.AppendLine("================================");
content.Append("Título: " + info.Title + "\r\n");
content.Append("Autor: " + info.Author + "\r\n");
content.Append("Creador: " + info.Creator + "\r\n");
content.Append("Tema: " + info.Subject + "\r\n");
content.Append("Palabras clave: " + info.Keywords + "\r\n");
content.Append("Productor de PDF: " + info.Producer + "\r\n");
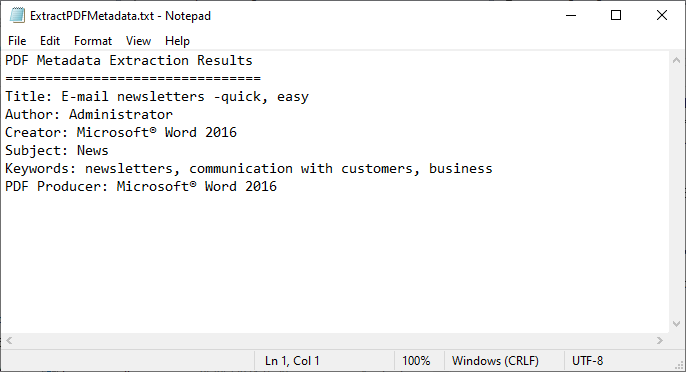
// Escribir el resultado en un archivo TXT
File.WriteAllText("ExtractPDFMetadata.txt", content.ToString());
}
}
}
El código carga un archivo PDF, obtiene sus campos de metadatos estándar y los escribe en un archivo de texto.
Procesamiento por lotes: Para extraer metadatos de varios archivos, recorra todos los PDF en una carpeta:
foreach (string file in Directory.GetFiles(@"C:\Invoices\", "*.pdf"))
{
// procesar cada archivo
}
Consejo Pro: Más allá de los metadatos básicos, Free Spire.PDF también admite la extracción de otros elementos, como la extracción de imágenes, hipervínculos, valores de campos de formulario, etc.
4. Línea de comandos con ExifTool (para usuarios avanzados)
Si se siente cómodo con una terminal o línea de comandos, ExifTool es una potente herramienta de extracción de metadatos. Es gratuito, multiplataforma (Windows, macOS, Linux) y lee metadatos de casi cualquier tipo de archivo, no solo de PDF.
Instalar
En Windows, descargue el ejecutable del sitio oficial.
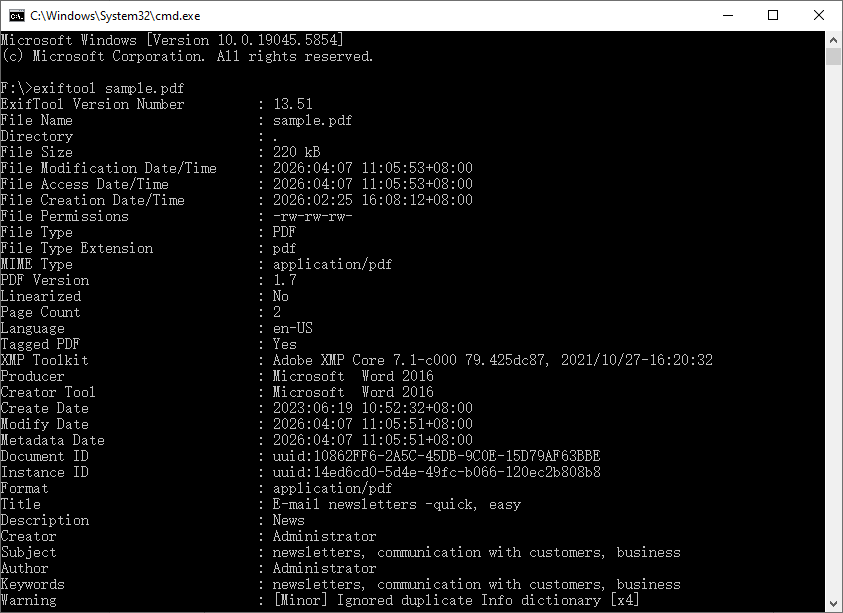
Uso básico – ver metadatos de un solo PDF:
exiftool sample.pdf
Esto imprime una larga lista de pares de etiquetas-valores directamente en la terminal.
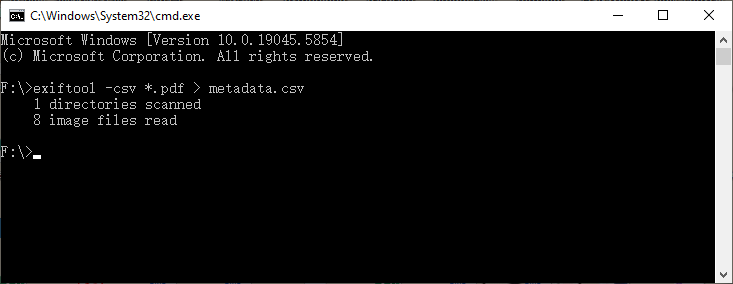
Exportación por lotes a CSV (ideal para análisis en Excel):
exiftool -csv *.pdf > metadata.csv
Este comando audita cientos de PDF a la vez y produce un CSV que puede abrir en Excel o Google Sheets, lo que le proporciona un catálogo buscable.
Cuándo usar esto: Auditorías por lotes a gran escala, análisis forenses o cuando prefiera la eficiencia de la línea de comandos.
La eliminación de metadatos es una característica de seguridad crítica que funciona junto con la extracción. Después de revisar los metadatos extraídos, puede eliminar todos los metadatos confidenciales ocultos de los PDF para evitar fugas de privacidad antes de compartir archivos externamente.
Notas críticas para el procesamiento de metadatos de PDF
- Los metadatos pueden ser editados o falsificados.
El hecho de que un PDF diga "Autor: John Doe" no significa que John Doe lo haya escrito realmente. Proporciona un contexto útil pero no es una prueba forense sin un análisis más profundo.
- Los PDF escaneados son diferentes.
Si alguien escaneó un documento físico y lo guardó como PDF, los únicos metadatos que obtendrá suelen ser información del escáner y una fecha de creación. No hay "autor" ni "palabras clave" a menos que alguien los agregue más tarde.
- Consejo de SEO.
Si pone PDF en su sitio web, complete los campos Título y Tema. Google a menudo los usa para el título y la descripción en los resultados de búsqueda, lo que es mejor que mostrar un nombre de archivo aleatorio.
Resumiendo
Extraer metadatos de PDF es una habilidad práctica que ahorra tiempo, protege la privacidad y, a veces, descubre exactamente el detalle que estaba buscando. Ya sea que use la ventana Propiedades de Acrobat para una verificación rápida, una herramienta en línea gratuita para documentos públicos, un script de C# para procesar miles de facturas o ExifTool para auditorías masivas de línea de comandos, el método correcto depende de cuántos archivos esté tratando y qué tan profundo necesite ir.
La próxima vez que descargue un PDF o prepare uno para compartir, tómese un momento para ver sus metadatos. Le sorprenderá lo que está adjunto y ahora sabrá exactamente cómo extraerlo.
Preguntas frecuentes (FAQ)
P1: ¿Puedo extraer metadatos de PDF escaneados?
Los PDF escaneados (que son solo imágenes) generalmente no tienen metadatos. Necesitará usar software OCR para convertir la imagen a texto primero, y luego agregar metadatos manualmente.
P2: ¿Son los metadatos lo mismo que las propiedades del archivo?
No exactamente. Las propiedades del archivo (como el tamaño del archivo, la fecha de creación) son administradas por el sistema operativo. Los metadatos del PDF están incrustados dentro del propio PDF y viajan con el documento.
P3: ¿Puedo editar o eliminar metadatos de PDF?
Sí. Use Adobe Acrobat Pro (gráfico) o ExifTool (línea de comandos) para editar/eliminar metadatos; las bibliotecas de programación también admiten la modificación.
P4: ¿Los metadatos afectan el tamaño del archivo PDF?
No. Los metadatos son datos de texto ligeros y no tienen un impacto notable en el tamaño del archivo.