
Les PDF sont partout : des contrats commerciaux et articles universitaires aux brochures marketing et documents juridiques. Mais au-delà du texte et des images visibles, chaque PDF contient des informations cachées appelées métadonnées. Ces données en coulisses offrent des détails critiques sur l'origine du document, l'auteur, la date de création, et bien plus encore. Que vous soyez un créateur de contenu, un développeur, un professionnel du droit ou simplement quelqu'un cherchant à organiser des fichiers, savoir comment extraire les métadonnées d'un PDF est une compétence précieuse.
Ce guide vous présentera les méthodes les plus efficaces pour extraire les métadonnées d'un PDF, des simples outils intégrés aux bibliothèques de programmation avancées.
- Pourquoi s'embêter à extraire les métadonnées ?
- 4 méthodes éprouvées pour extraire les métadonnées d'un PDF
- Remarques critiques pour le traitement des métadonnées PDF
- Foire aux questions (FAQ)
Pourquoi s'embêter à extraire les métadonnées ?
Les métadonnées PDF sont bien plus utiles que vous ne le pensez, avec une valeur fondamentale dans de multiples scénarios :
| Cas d'utilisation | Pourquoi c'est important |
|---|---|
| Informatique légale | Suivre l'origine et les modifications du document ; détecter les fichiers falsifiés |
| E-discovery juridique | Les horodatages des métadonnées sont des preuves recevables devant les tribunaux |
| Gestion de contenu | Étiqueter automatiquement des milliers de PDF par auteur, date ou mot-clé |
| SEO et visibilité dans les recherches | Google utilise le titre/sujet du PDF dans les extraits de recherche |
| Protection de la vie privée | Trouver et supprimer les données personnelles cachées avant le partage |
| Automatisation du flux de travail | Extraire les numéros de facture et les dates de rapport sans lecture manuelle |
| Archivage en bibliothèque | Créer des bases de données PDF consultables pour la recherche |
Même pour un seul document, savoir lire les métadonnées PDF vous aide à vérifier l'authenticité et à éviter la fuite d'informations sensibles.
À lire aussi : Comment modifier les métadonnées d'un PDF (4 méthodes)
4 méthodes éprouvées pour extraire les métadonnées d'un PDF (du débutant au pro)
Selon votre aisance avec les outils et le nombre de fichiers à traiter, vous disposez de plusieurs options pour obtenir les métadonnées d'un PDF, couvrant les approches sans code, en ligne, par programmation et en ligne de commande.
1. Adobe Acrobat Pro (Windows/Mac)
Adobe Acrobat Pro est la norme de l'industrie pour le travail sur PDF. Il offre une interface graphique claire pour visualiser et exporter les métadonnées standard et avancées.
Voici comment l'utiliser :
- Ouvrez votre PDF dans Adobe Acrobat Pro.
- Cliquez sur « Fichier » > « Propriétés » (ou appuyez sur Ctrl+D/Command+D).
- L'onglet « Description » affiche les métadonnées standard (titre, auteur, sujet, etc.). L'onglet « Avancé » affiche des données XMP plus approfondies (par exemple, la version du logiciel de création du PDF).
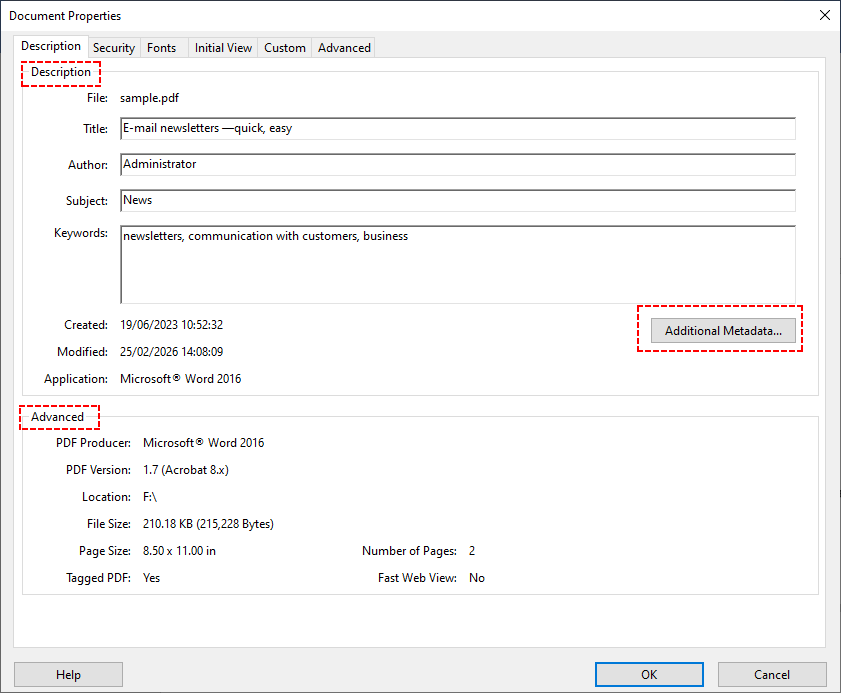
- Pour encore plus de champs personnalisés, cliquez sur « Métadonnées supplémentaires » pour parcourir toutes les propriétés XMP.
- Sélectionnez « Exporter » pour enregistrer sous forme de fichier XMP. Ce fichier peut être importé dans d'autres outils Adobe ou lu par des scripts personnalisés.
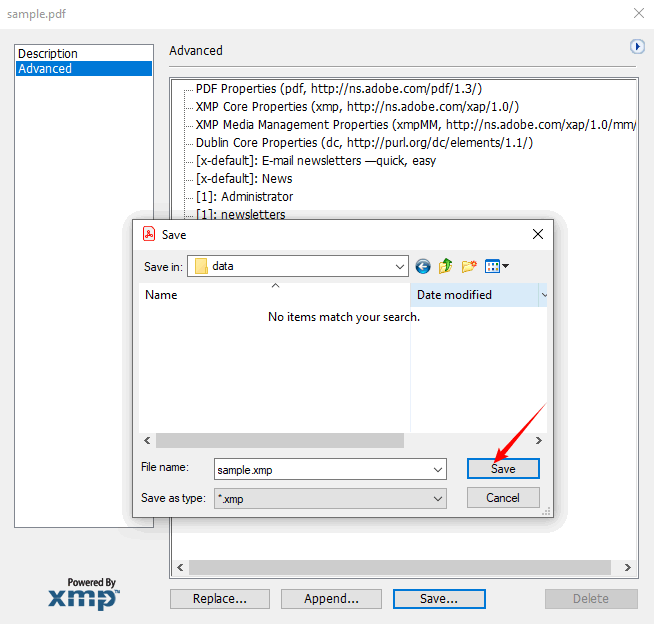
Inconvénient : Nécessite un abonnement. Convient aux professionnels qui possèdent déjà Acrobat Pro, mais excessif pour une vérification rapide d'un seul fichier.
De nombreux PDF sécurisés restreignent l'accès aux métadonnées, donc supprimer les autorisations PDF déverrouille l'accès complet aux métadonnées et au contenu du document, vous permettant d'extraire, de modifier ou d'exporter les métadonnées de fichiers protégés par mot de passe ou restreints sans limitations.
2. Extracteurs de métadonnées en ligne gratuits (rapides et faciles)
Une recherche rapide sur Google révèle des dizaines de sites qui vous permettent de télécharger un PDF et de visualiser ses métadonnées. Des exemples populaires comme Metadata2Go et GroupDocs PDF Metadata Extractor sont incroyablement pratiques : pas d'installation, pas de paiement, et ils fonctionnent sur n'importe quel appareil.
Obtenez les métadonnées PDF en ligne en utilisant Metadata2Go :
- Allez sur la page View Metadata de l'outil.
- Téléchargez le PDF par glisser-déposer ou cliquez sur « Choose file ».
- Attendez que l'outil extraie les métadonnées de votre fichier PDF.
- Exportez les résultats au format CSV/TXT/JSON/HTML selon vos besoins.
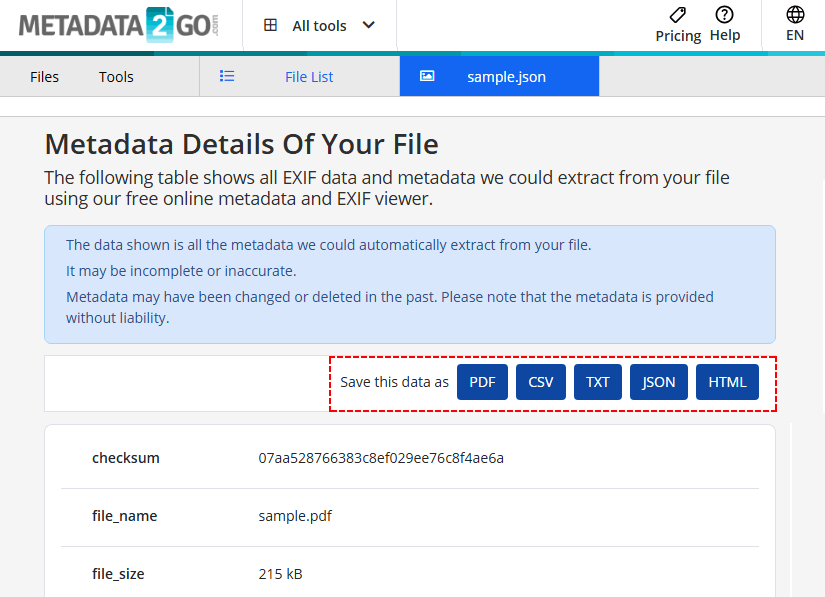
Risque de sécurité : Ne téléchargez jamais de documents sensibles ou confidentiels sur un outil en ligne gratuit.
3. Extraire les métadonnées PDF par programmation (pour les développeurs)
Si vous devez extraire les métadonnées de centaines de PDF ou intégrer l'extraction de métadonnées dans votre propre application, la programmation est la solution. Voici un exemple détaillé utilisant C# et la bibliothèque Free Spire.PDF for .NET.
Étape 1 - Installer la bibliothèque via NuGet
Install-Package FreeSpire.PDF
Étape 2 – Écrire le code C# pour lire les métadonnées PDF
using Spire.Pdf;
using System.IO;
using System.Text;
namespace ExtractPDFMetadata
{
class Program
{
static void Main(string[] args)
{
// Créer un objet PdfDocument
PdfDocument pdf = new PdfDocument();
// Charger le fichier PDF (changez le chemin vers votre fichier)
pdf.LoadFromFile("F:\\sample.pdf");
// Accéder aux informations du document
PdfDocumentInformation info = pdf.DocumentInformation;
// Construire la chaîne de métadonnées
StringBuilder content = new StringBuilder();
content.AppendLine("Résultats de l'extraction des métadonnées PDF");
content.AppendLine("================================");
content.Append("Titre : " + info.Title + "\r\n");
content.Append("Auteur : " + info.Author + "\r\n");
content.Append("Créateur : " + info.Creator + "\r\n");
content.Append("Sujet : " + info.Subject + "\r\n");
content.Append("Mots-clés : " + info.Keywords + "\r\n");
content.Append("Producteur PDF : " + info.Producer + "\r\n");
// Écrire le résultat dans un fichier TXT
File.WriteAllText("ExtractPDFMetadata.txt", content.ToString());
}
}
}
Le code charge un fichier PDF, récupère ses champs de métadonnées standard et les écrit dans un fichier texte.
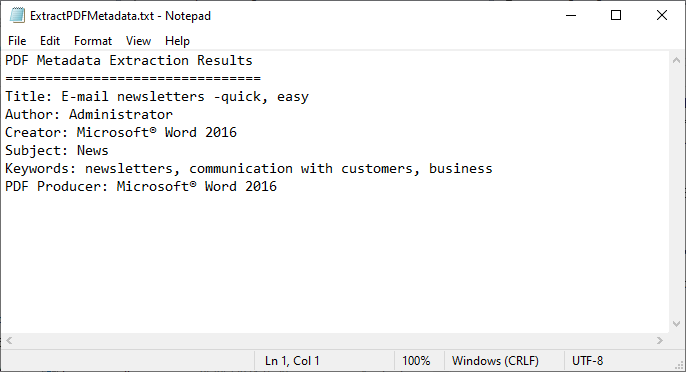
Traitement par lots : Pour extraire les métadonnées de plusieurs fichiers, parcourez tous les PDF d'un dossier :
foreach (string file in Directory.GetFiles(@"C:\Invoices\", "*.pdf"))
{
// traiter chaque fichier
}
Conseil de pro : Au-delà des métadonnées de base, Free Spire.PDF prend également en charge l'extraction d'autres éléments, tels que l'extraction d'images, d'hyperliens, de valeurs de champs de formulaire, etc.
4. Ligne de commande avec ExifTool (pour les utilisateurs avancés)
Si vous êtes à l'aise avec un terminal ou une invite de commande, ExifTool est un puissant outil d'extraction de métadonnées. Il est gratuit, multiplateforme (Windows, macOS, Linux) et lit les métadonnées de presque tous les types de fichiers, pas seulement les PDF.
Installation
Sur Windows, téléchargez l'exécutable depuis le site officiel.
Utilisation de base – visualiser les métadonnées d'un seul PDF :
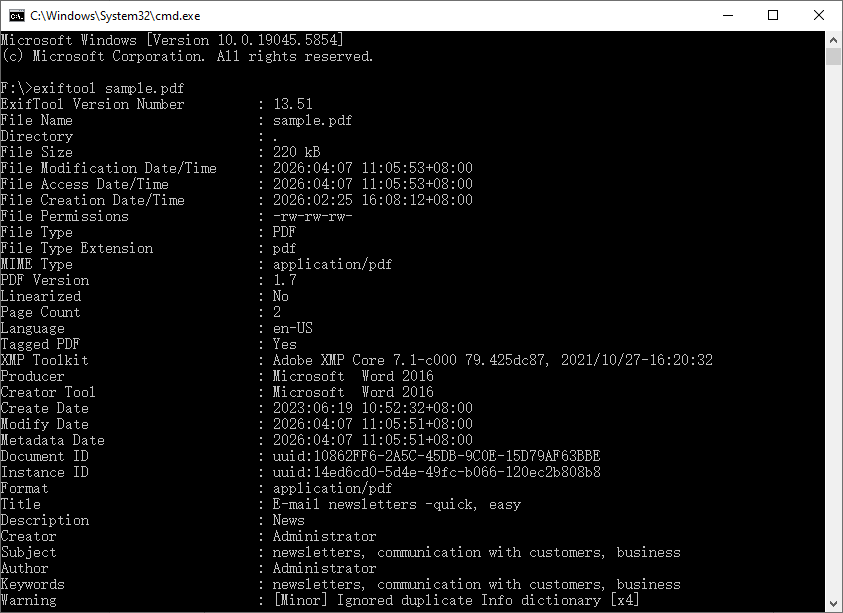
exiftool sample.pdf
Cela affiche une longue liste de paires étiquette-valeur directement dans le terminal.
Exportation par lots vers CSV (idéal pour l'analyse dans Excel) :
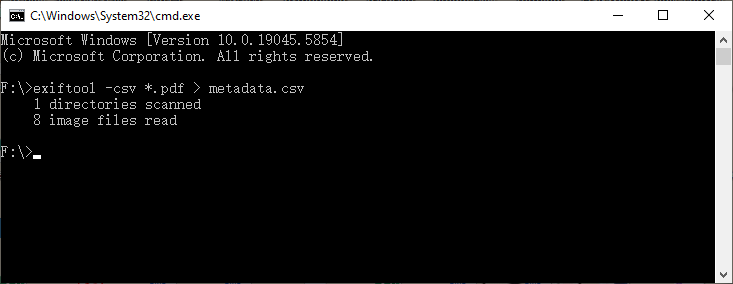
exiftool -csv *.pdf > metadata.csv
Cette commande audite des centaines de PDF à la fois et produit un CSV que vous pouvez ouvrir dans Excel ou Google Sheets, vous offrant un catalogue consultable.
Quand utiliser ceci : Audits par lots à grande échelle, analyse forensique, ou lorsque vous préférez l'efficacité de la ligne de commande.
La suppression des métadonnées est une fonctionnalité de sécurité critique qui fonctionne parallèlement à l'extraction. Après avoir examiné les métadonnées extraites, vous pouvez supprimer toutes les métadonnées sensibles cachées des PDF pour éviter les fuites de confidentialité avant de partager des fichiers à l'extérieur.
Remarques critiques pour le traitement des métadonnées PDF
- Les métadonnées peuvent être modifiées ou falsifiées.
Ce n'est pas parce qu'un PDF indique « Auteur : John Doe » que John Doe l'a réellement écrit. Cela fournit un contexte utile mais n'est pas une preuve forensique sans une analyse plus approfondie.
- Les PDF scannés sont différents.
Si quelqu'un a scanné un document physique et l'a enregistré en tant que PDF, les seules métadonnées que vous obtiendrez généralement sont les informations du scanner et une date de création. Il n'y a pas d'« auteur » ou de « mots-clés » à moins que quelqu'un ne les ajoute plus tard.
- Conseil SEO.
Si vous mettez des PDF sur votre site Web, remplissez les champs Titre et Sujet. Google les utilise souvent pour le titre et la description dans les résultats de recherche, ce qui est préférable à l'affichage d'un nom de fichier aléatoire.
Conclusion
L'extraction de métadonnées à partir de PDF est une compétence pratique qui permet de gagner du temps, de protéger la vie privée et parfois de découvrir exactement le détail que vous recherchiez. Que vous utilisiez la fenêtre Propriétés d'Acrobat pour une vérification rapide, un outil en ligne gratuit pour les documents publics, un script C# pour traiter des milliers de factures ou ExifTool pour des audits en ligne de commande en masse, la bonne méthode dépend du nombre de fichiers que vous traitez et de la profondeur dont vous avez besoin.
La prochaine fois que vous téléchargerez un PDF ou que vous en préparerez un pour le partage, prenez un moment pour regarder ses métadonnées. Vous pourriez être surpris de ce qui y est attaché et vous saurez maintenant exactement comment les extraire.
Foire aux questions (FAQ)
Q1 : Puis-je extraire les métadonnées de PDF scannés ?
Les PDF scannés (qui ne sont que des images) n'ont généralement pas de métadonnées. Vous devrez d'abord utiliser un logiciel OCR pour convertir l'image en texte, puis ajouter les métadonnées manuellement.
Q2 : Les métadonnées sont-elles identiques aux propriétés du fichier ?
Pas exactement. Les propriétés du fichier (comme la taille du fichier, la date de création) sont gérées par le système d'exploitation. Les métadonnées PDF sont intégrées à l'intérieur du PDF lui-même et voyagent avec le document.
Q3 : Puis-je modifier ou supprimer les métadonnées d'un PDF ?
Oui. Utilisez Adobe Acrobat Pro (graphique) ou ExifTool (ligne de commande) pour modifier/supprimer les métadonnées ; les bibliothèques de programmation prennent également en charge la modification.
Q4 : Les métadonnées affectent-elles la taille du fichier PDF ?
Non. Les métadonnées sont des données textuelles légères et n'ont aucun impact notable sur la taille du fichier.
Voir aussi
- Modifier les métadonnées PDF : quatre méthodes efficaces
- Extraire du texte d'un PDF gratuitement | PDF numériques et scannés (OCR)
- Comment compresser un PDF : les meilleurs outils pour réduire la taille des PDF
- Java : Définir ou récupérer les propriétés d'un PDF
- Python : Définir et récupérer les propriétés d'un PDF