
I PDF sono ovunque: dai contratti commerciali e documenti accademici alle brochure di marketing e ai documenti legali. Ma oltre al testo e alle immagini visibili, ogni PDF contiene informazioni nascoste chiamate metadati. Questi dati "dietro le quinte" offrono dettagli critici sull'origine del documento, sull'autore, sulla data di creazione e altro ancora. Che tu sia un creatore di contenuti, uno sviluppatore, un professionista legale o semplicemente qualcuno che cerca di organizzare i file, sapere come estrarre i metadati da un PDF è un'abilità preziosa.
Questa guida ti illustrerà i metodi più efficaci per estrarre i metadati dei PDF, dagli strumenti integrati semplici alle librerie di programmazione avanzate.
- Perché preoccuparsi di estrarre i metadati?
- 4 metodi comprovati per estrarre i metadati dei PDF
- Note critiche per l'elaborazione dei metadati dei PDF
- Domande frequenti (FAQ)
Perché preoccuparsi di estrarre i metadati?
I metadati dei PDF sono molto più utili di quanto si possa pensare, con un valore fondamentale in diversi scenari:
| Caso d'uso | Perché è importante |
|---|---|
| Forensics digitali | Tracciare l'origine e le modifiche dei documenti; rilevare file contraffatti |
| e-discovery legale | I timestamp dei metadati sono prove ammissibili in tribunale |
| Gestione dei contenuti | Taggare automaticamente migliaia di PDF per autore, data o parola chiave |
| SEO e visibilità di ricerca | Google utilizza il titolo/soggetto del PDF negli snippet di ricerca |
| Protezione della privacy | Trovare e rimuovere dati personali nascosti prima della condivisione |
| Automazione del flusso di lavoro | Estrarre numeri di fattura e date di report senza lettura manuale |
| Archiviazione di librerie | Creare database di PDF ricercabili per la ricerca |
Anche per un singolo documento, sapere come leggere i metadati del PDF aiuta a verificarne l'autenticità ed evitare la fuga di informazioni sensibili.
Leggi anche: Come modificare i metadati dei PDF (4 metodi)
4 metodi comprovati per estrarre i metadati dei PDF (dal principiante al professionista)
A seconda di quanto ti senti a tuo agio con gli strumenti e di quanti file stai gestendo, hai diverse opzioni per ottenere i metadati da un PDF, coprendo approcci no-code, online, di programmazione e da riga di comando.
1. Adobe Acrobat Pro (Windows/Mac)
Adobe Acrobat Pro è lo standard del settore per il lavoro sui PDF. Fornisce un'interfaccia grafica pulita per visualizzare ed esportare metadati standard e avanzati.
Ecco come usarlo:
- Apri il tuo PDF in Adobe Acrobat Pro.
- Fai clic su "File" > "Proprietà" (o premi Ctrl+D/Comando+D).
- La scheda "Descrizione" visualizza i metadati standard (titolo, autore, soggetto, ecc.). La scheda "Avanzate" mostra dati XMP più approfonditi (ad esempio, la versione del software di creazione PDF).
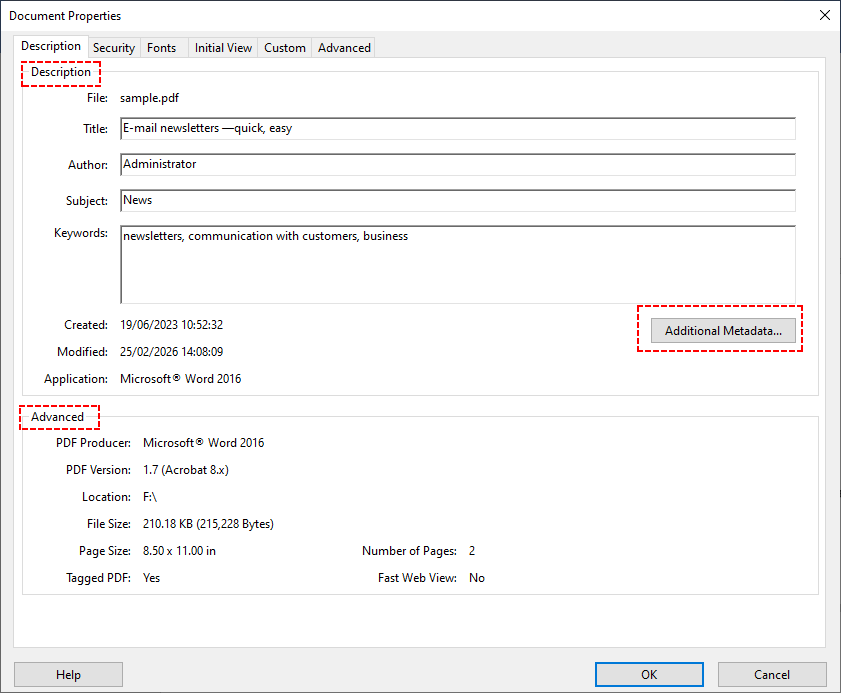
- Per campi ancora più personalizzati, fai clic su "Metadati aggiuntivi" per sfogliare tutte le proprietà XMP.
- Seleziona "Esporta" per salvare come file XMP. Questo file può essere importato in altri strumenti Adobe o letto da script personalizzati.
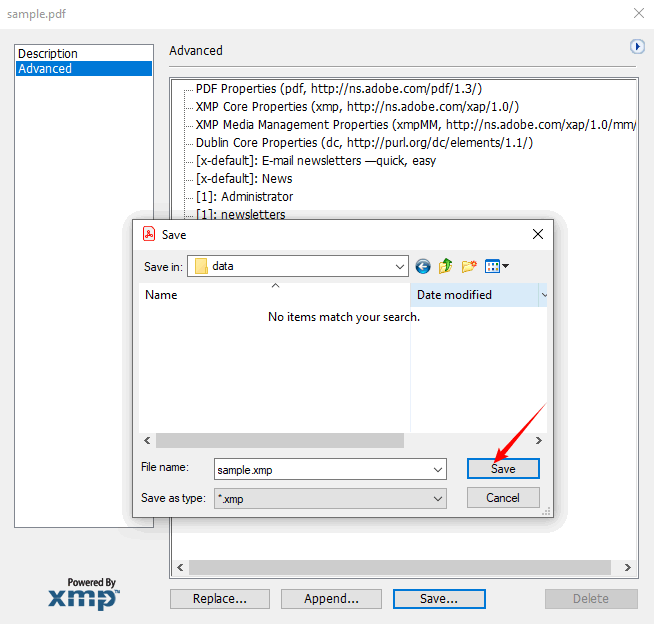
Svantaggio: Richiede un abbonamento. Adatto ai professionisti che hanno già Acrobat Pro, ma eccessivo per un rapido controllo di un singolo file.
Molti PDF protetti limitano l'accesso ai metadati, quindi rimuovere le autorizzazioni PDF sblocca l'accesso completo ai metadati e al contenuto del documento, consentendoti di estrarre, modificare o esportare metadati da file protetti da password o con restrizioni senza limitazioni.
2. Estrattori di metadati online gratuiti (veloci e facili)
Una rapida ricerca su Google rivela dozzine di siti che ti permettono di caricare un PDF e visualizzare i suoi metadati. Esempi popolari come Metadata2Go e GroupDocs PDF Metadata Extractor sono incredibilmente convenienti: nessuna installazione, nessun pagamento e funzionano su qualsiasi dispositivo.
Ottieni metadati PDF online utilizzando Metadata2Go:
- Vai alla pagina Visualizza metadati dello strumento.
- Carica il PDF tramite drag-and-drop o fai clic su "Scegli file".
- Attendi che lo strumento estragga i metadati dal tuo file PDF.
- Esporta i risultati in CSV/TXT/JSON/HTML secondo necessità.
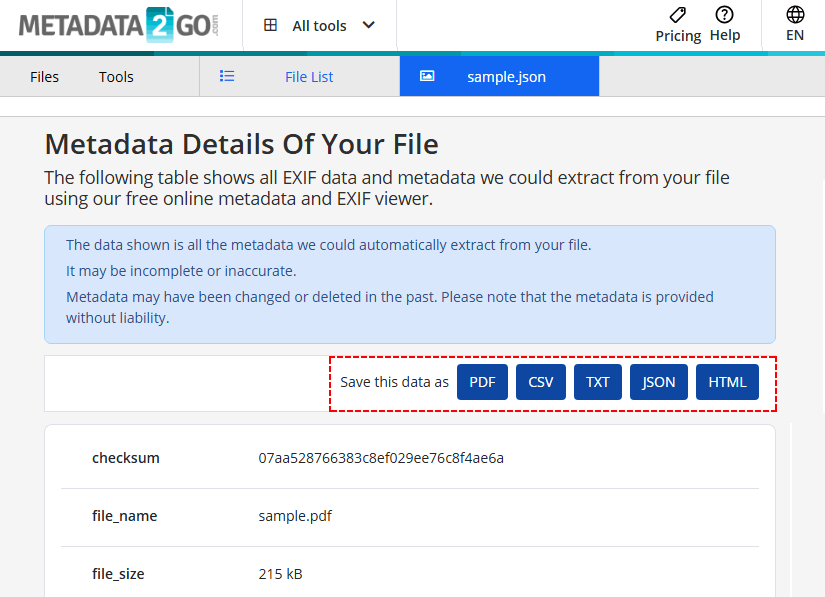
Rischio di sicurezza: Non caricare mai documenti sensibili o riservati su uno strumento online gratuito.
3. Estrazione programmatica dei metadati dei PDF (per sviluppatori)
Se hai bisogno di estrarre metadati da centinaia di PDF o integrare l'estrazione dei metadati nella tua applicazione, la programmazione è la strada da percorrere. Di seguito è riportato un esempio dettagliato che utilizza C# e la libreria Free Spire.PDF for .NET.
Passaggio 1 - Installa la libreria tramite NuGet
Install-Package FreeSpire.PDF
Passaggio 2 – Scrivi codice C# per leggere i metadati del PDF
using Spire.Pdf;
using System.IO;
using System.Text;
namespace ExtractPDFMetadata
{
class Program
{
static void Main(string[] args)
{
// Crea un oggetto PdfDocument
PdfDocument pdf = new PdfDocument();
// Carica il file PDF (modifica il percorso del tuo file)
pdf.LoadFromFile("F:\\sample.pdf");
// Accedi alle informazioni del documento
PdfDocumentInformation info = pdf.DocumentInformation;
// Costruisci la stringa dei metadati
StringBuilder content = new StringBuilder();
content.AppendLine("Risultati estrazione metadati PDF");
content.AppendLine("================================");
content.Append("Titolo: " + info.Title + "\r\n");
content.Append("Autore: " + info.Author + "\r\n");
content.Append("Creatore: " + info.Creator + "\r\n");
content.Append("Soggetto: " + info.Subject + "\r\n");
content.Append("Parole chiave: " + info.Keywords + "\r\n");
content.Append("Produttore PDF: " + info.Producer + "\r\n");
// Scrivi il risultato in un file TXT
File.WriteAllText("ExtractPDFMetadata.txt", content.ToString());
}
}
}
Il codice carica un file PDF, ottiene i suoi campi di metadati standard e li scrive in un file di testo.
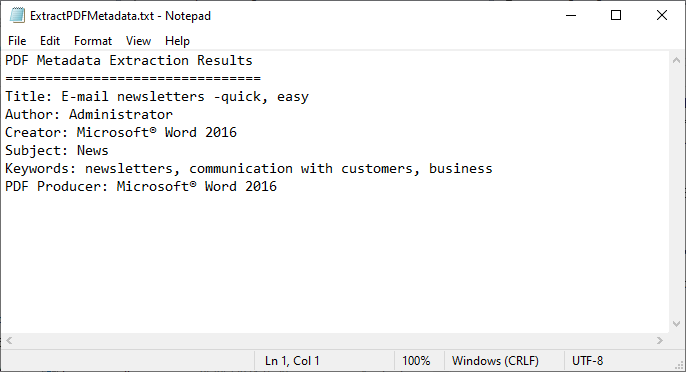
Elaborazione batch: Per estrarre metadati da più file, scorri tutti i PDF in una cartella:
foreach (string file in Directory.GetFiles(@"C:\Invoices\", "*.pdf"))
{
// elabora ogni file
}
Suggerimento Pro: Oltre ai metadati di base, Free Spire.PDF supporta anche l'estrazione di altri elementi, come l'estrazione di immagini, collegamenti ipertestuali, valori dei campi modulo, ecc.
4. Riga di comando con ExifTool (per utenti avanzati)
Se ti senti a tuo agio con un terminale o un prompt dei comandi, ExifTool è un potente strumento di estrazione di metadati. È gratuito, multipiattaforma (Windows, macOS, Linux) e legge metadati da quasi tutti i tipi di file, non solo PDF.
Installazione
Su Windows, scarica l'eseguibile dal sito ufficiale.
Uso di base – visualizza i metadati di un singolo PDF:
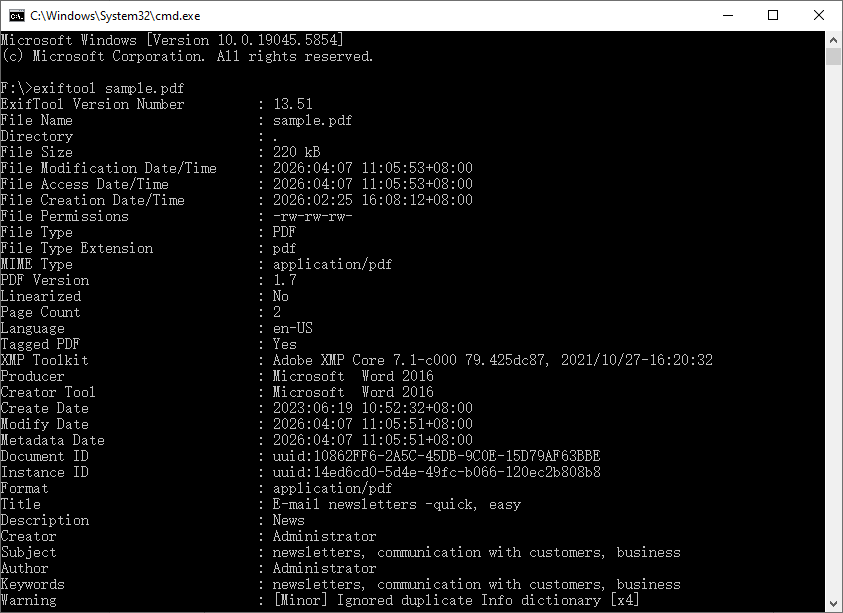
exiftool sample.pdf
Questo stampa un lungo elenco di coppie tag-valore direttamente nel terminale.
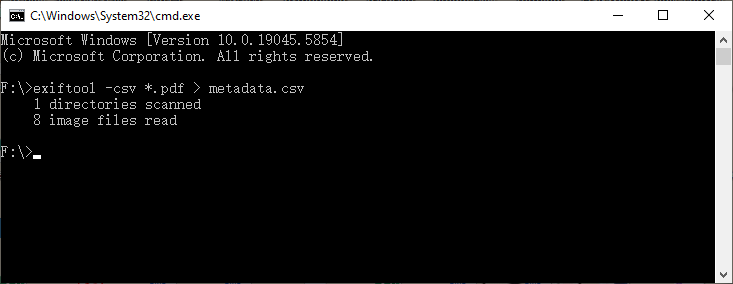
Esportazione batch in CSV (ideale per l'analisi in Excel):
exiftool -csv *.pdf > metadata.csv
Questo comando controlla centinaia di PDF contemporaneamente e produce un CSV che puoi aprire in Excel o Google Sheets, fornendoti un catalogo ricercabile.
Quando usarlo: Audit batch su larga scala, analisi forensi o quando preferisci l'efficienza della riga di comando.
La rimozione dei metadati è una funzionalità di sicurezza critica che funziona insieme all'estrazione. Dopo aver esaminato i metadati estratti, puoi rimuovere tutti i metadati sensibili nascosti dai PDF per prevenire fughe di privacy prima di condividere i file esternamente.
Note critiche per l'elaborazione dei metadati dei PDF
- I metadati possono essere modificati o falsificati.
Solo perché un PDF dice "Autore: John Doe" non significa che John Doe l'abbia effettivamente scritto. Fornisce un contesto utile ma non è una prova forense senza un'analisi più approfondita.
- I PDF scansionati sono diversi.
Se qualcuno ha scansionato un documento fisico e lo ha salvato come PDF, gli unici metadati che otterrai solitamente sono le informazioni dello scanner e una data di creazione. Non ci sono "autore" o "parole chiave" a meno che qualcuno non li aggiunga in seguito.
- Suggerimento SEO.
Se metti PDF sul tuo sito web, compila i campi Titolo e Soggetto. Google spesso li utilizza per il titolo e la descrizione nei risultati di ricerca, il che è meglio che mostrare un nome file casuale.
In conclusione
Estrarre metadati dai PDF è un'abilità pratica che consente di risparmiare tempo, proteggere la privacy e talvolta scoprire esattamente il dettaglio che stavi cercando. Sia che tu utilizzi la finestra Proprietà di Acrobat per un controllo rapido, uno strumento online gratuito per documenti pubblici, uno script C# per elaborare migliaia di fatture o ExifTool per audit batch da riga di comando, il metodo giusto dipende da quanti file stai gestendo e quanto in profondità devi andare.
La prossima volta che scarichi un PDF o ne prepari uno per la condivisione, prenditi un momento per esaminare i suoi metadati. Potresti essere sorpreso da ciò che è allegato e ora saprai esattamente come estrarlo.
Domande frequenti (FAQ)
D1: Posso estrarre metadati da PDF scansionati?
I PDF scansionati (che sono solo immagini) di solito non hanno metadati. Dovrai utilizzare un software OCR per convertire l'immagine in testo prima, quindi aggiungere manualmente i metadati.
D2: I metadati sono la stessa cosa delle proprietà del file?
Non esattamente. Le proprietà del file (come dimensione del file, data di creazione) sono gestite dal sistema operativo. I metadati del PDF sono incorporati all'interno del PDF stesso e viaggiano con il documento.
D3: Posso modificare o eliminare i metadati del PDF?
Sì. Utilizza Adobe Acrobat Pro (grafico) o ExifTool (riga di comando) per modificare/eliminare i metadati; anche le librerie di programmazione supportano la modifica.
D4: I metadati influiscono sulla dimensione del file PDF?
No. I metadati sono dati testuali leggeri e non hanno un impatto percettibile sulla dimensione del file.