
PDF-файлы повсюду — от деловых контрактов и научных работ до маркетинговых брошюр и юридических документов. Но помимо видимого текста и изображений, каждый PDF-файл содержит скрытую информацию, называемую метаданными. Эти «закулисные» данные предоставляют критически важную информацию об источнике документа, авторе, дате создания и многом другом. Независимо от того, являетесь ли вы создателем контента, разработчиком, юристом или просто человеком, желающим упорядочить файлы, знание того, как извлечь метаданные из PDF, является ценным навыком.
В этом руководстве мы рассмотрим наиболее эффективные методы извлечения метаданных PDF, от простых встроенных инструментов до продвинутых библиотек программирования.
- Зачем извлекать метаданные?
- 4 проверенных способа извлечения метаданных PDF
- Важные замечания по обработке метаданных PDF
- Часто задаваемые вопросы (FAQ)
Зачем извлекать метаданные?
Метаданные PDF гораздо полезнее, чем вы можете себе представить, и имеют основную ценность в различных сценариях:
| Сценарий использования | Почему это важно |
|---|---|
| Цифровая криминалистика | Отслеживание происхождения и изменений документа; обнаружение поддельных файлов |
| Юридическое электронное обнаружение | Временные метки метаданных являются допустимым доказательством в суде |
| Управление контентом | Автоматическая маркировка тысяч PDF-файлов по автору, дате или ключевому слову |
| SEO и видимость в поиске | Google использует заголовок/тему PDF в сниппетах поиска |
| Защита конфиденциальности | Найти и удалить скрытые личные данные перед обменом |
| Автоматизация рабочего процесса | Извлечение номеров счетов и дат отчетов без ручного чтения |
| Архивирование библиотек | Создание поисковых баз данных PDF для исследований |
Даже для одного документа знание того, как читать метаданные PDF, помогает проверить подлинность и избежать утечки конфиденциальной информации.
Также читайте: Как редактировать метаданные PDF (4 метода)
4 проверенных способа извлечения метаданных PDF (от новичка до профессионала)
В зависимости от того, насколько вы знакомы с инструментами и сколько файлов вы обрабатываете, у вас есть несколько вариантов для получения метаданных из PDF, охватывающих подходы без кода, онлайн, программирование и командную строку.
1. Adobe Acrobat Pro (Windows/Mac)
Adobe Acrobat Pro — это отраслевой стандарт для работы с PDF. Он предоставляет чистый графический интерфейс для просмотра и экспорта как стандартных, так и расширенных метаданных.
Вот как им пользоваться:
- Откройте ваш PDF-файл в Adobe Acrobat Pro.
- Нажмите «Файл» > «Свойства» (или нажмите Ctrl+D/Command+D).
- Вкладка «Описание» отображает стандартные метаданные (заголовок, автор, тема и т. д.). Вкладка «Дополнительно» показывает более глубокие данные XMP (например, версию программного обеспечения, создавшего PDF).
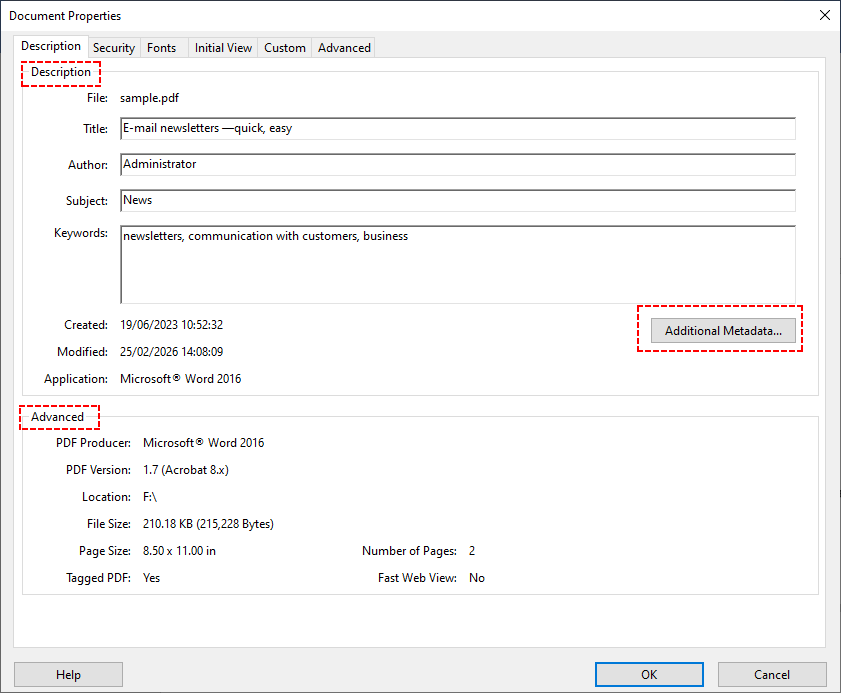
- Для еще большего количества пользовательских полей нажмите «Дополнительные метаданные», чтобы просмотреть все свойства XMP.
- Выберите «Экспорт», чтобы сохранить в файл XMP. Этот файл можно импортировать в другие инструменты Adobe или прочитать с помощью пользовательских скриптов.
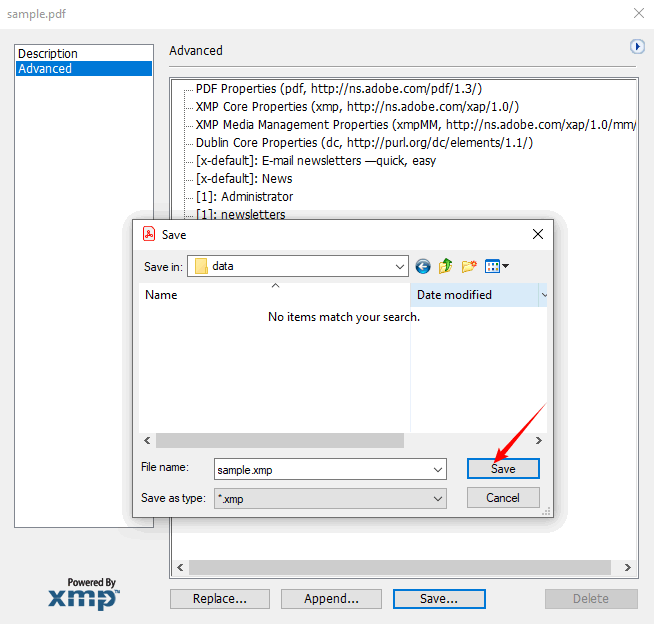
Недостаток: Требуется подписка. Подходит для профессионалов, у которых уже есть Acrobat Pro, но избыточен для быстрой проверки одного файла.
Многие защищенные PDF-файлы ограничивают доступ к метаданным, поэтому удаление разрешений PDF открывает полный доступ к метаданным и содержимому документа, позволяя извлекать, изменять или экспортировать метаданные из файлов, защищенных паролем или ограниченных, без ограничений.
2. Бесплатные онлайн-экстракторы метаданных (быстро и просто)
Быстрый поиск в Google выдаст десятки сайтов, которые позволяют загрузить PDF и просмотреть его метаданные. Популярные примеры, такие как Metadata2Go и GroupDocs PDF Metadata Extractor, невероятно удобны — не требуют установки, оплаты и работают на любом устройстве.
Получите метаданные PDF онлайн с помощью Metadata2Go:
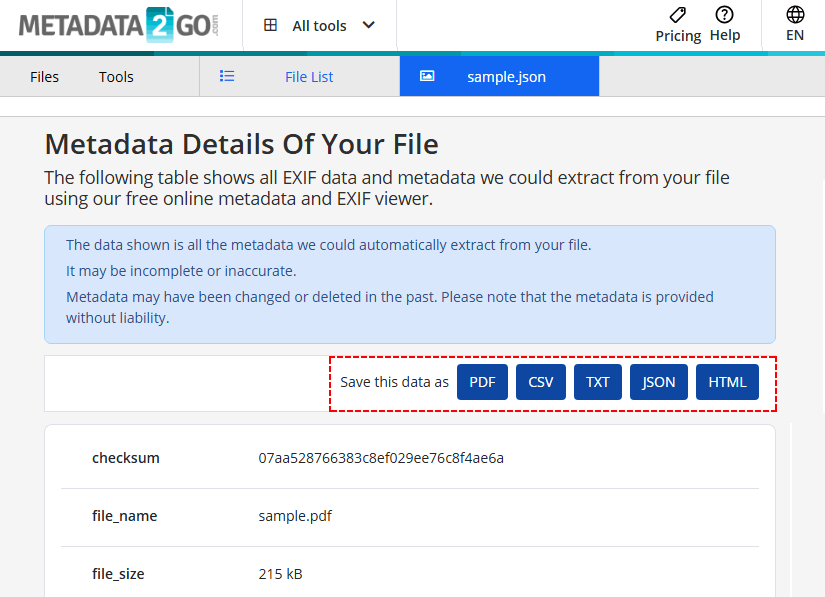
- Перейдите на страницу инструмента View Metadata.
- Загрузите PDF-файл путем перетаскивания или нажмите «Выбрать файл».
- Дождитесь, пока инструмент извлечет метаданные из вашего PDF-файла.
- Экспортируйте результаты в CSV/TXT/JSON/HTML по мере необходимости.
Риск безопасности: Никогда не загружайте конфиденциальные или секретные документы в бесплатный онлайн-инструмент.
3. Программное извлечение метаданных PDF (для разработчиков)
Если вам нужно извлечь метаданные из сотен PDF-файлов или интегрировать извлечение метаданных в ваше собственное приложение, программирование — это правильный путь. Ниже приведен подробный пример с использованием C# и библиотеки Free Spire.PDF for .NET.
Шаг 1 — Установите библиотеку через NuGet
Install-Package FreeSpire.PDF
Шаг 2 – Напишите код C#, чтобы прочитать метаданные PDF
using Spire.Pdf;
using System.IO;
using System.Text;
namespace ExtractPDFMetadata
{
class Program
{
static void Main(string[] args)
{
// Создать объект PdfDocument
PdfDocument pdf = new PdfDocument();
// Загрузить PDF-файл (измените путь к вашему файлу)
pdf.LoadFromFile("F:\\sample.pdf");
// Доступ к информации документа
PdfDocumentInformation info = pdf.DocumentInformation;
// Создать строку метаданных
StringBuilder content = new StringBuilder();
content.AppendLine("Результаты извлечения метаданных PDF");
content.AppendLine("================================");
content.Append("Заголовок: " + info.Title + "\r\n");
content.Append("Автор: " + info.Author + "\r\n");
content.Append("Создатель: " + info.Creator + "\r\n");
content.Append("Тема: " + info.Subject + "\r\n");
content.Append("Ключевые слова: " + info.Keywords + "\r\n");
content.Append("PDF Producer: " + info.Producer + "\r\n");
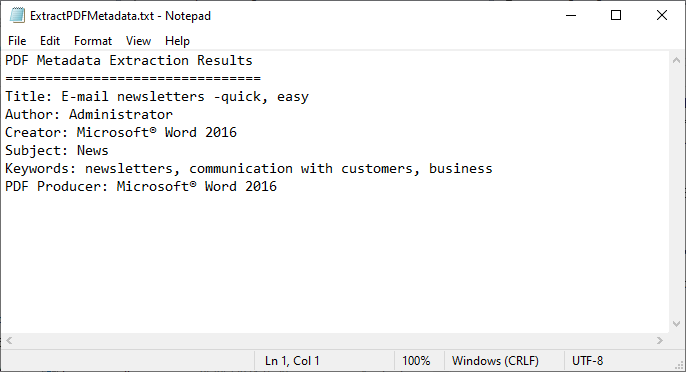
// Записать результат в TXT-файл
File.WriteAllText("ExtractPDFMetadata.txt", content.ToString());
}
}
}
Код загружает PDF-файл, получает его стандартные поля метаданных и записывает их в текстовый файл.
Пакетная обработка: Для извлечения метаданных из нескольких файлов переберите все PDF-файлы в папке:
foreach (string file in Directory.GetFiles(@"C:\Invoices\", "*.pdf"))
{
// обработать каждый файл
}
Совет профессионала: Помимо базовых метаданных, Free Spire.PDF также поддерживает извлечение других элементов, таких как извлечение изображений, гиперссылки, значения полей формы и т. д.
4. Командная строка с ExifTool (для продвинутых пользователей)
Если вы уверенно работаете с терминалом или командной строкой, ExifTool — это мощный инструмент для извлечения метаданных. Он бесплатный, кроссплатформенный (Windows, macOS, Linux) и читает метаданные практически из любого типа файлов, а не только из PDF.
Установка
В Windows загрузите исполняемый файл с официального сайта.
Базовое использование – просмотр метаданных одного PDF:
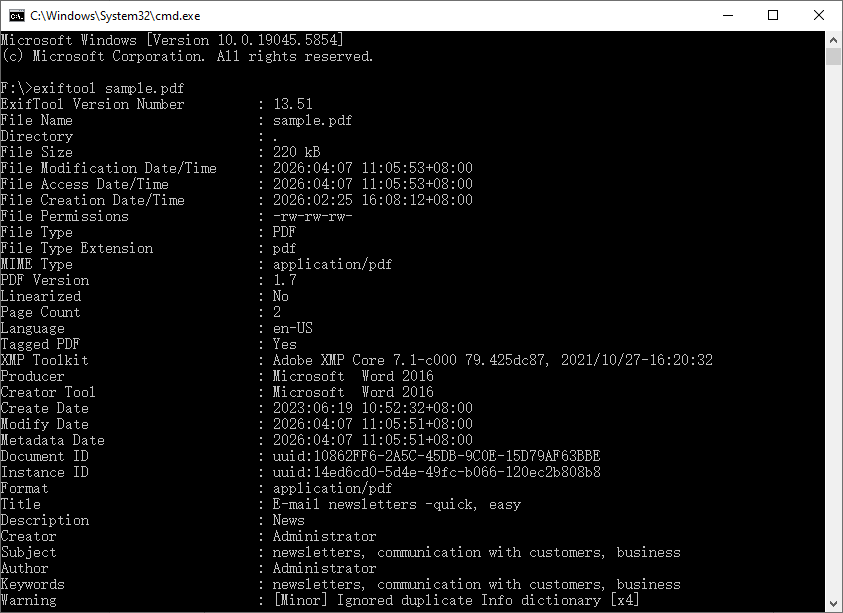
exiftool sample.pdf
Это выведет длинный список пар «тег-значение» непосредственно в терминал.
Пакетный экспорт в CSV (идеально для анализа в Excel):
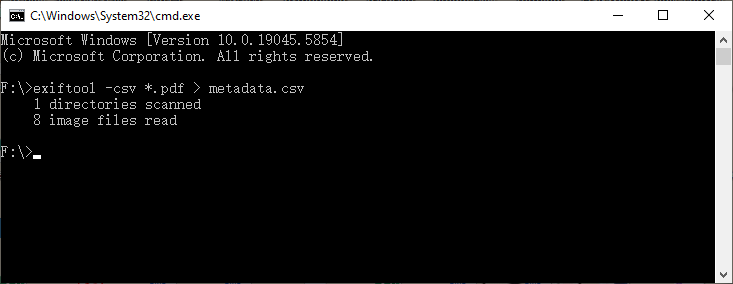
exiftool -csv *.pdf > metadata.csv
Эта команда проверяет сотни PDF-файлов одновременно и создает CSV-файл, который вы можете открыть в Excel или Google Sheets, предоставляя вам каталог с возможностью поиска.
Когда использовать: Масштабные пакетные аудиты, криминалистический анализ или когда вы предпочитаете эффективность командной строки.
Удаление метаданных — это критически важная функция безопасности, которая работает параллельно с извлечением. После просмотра извлеченных метаданных вы можете удалить все скрытые конфиденциальные метаданные из PDF, чтобы предотвратить утечку конфиденциальности перед внешним обменом файлами.
Важные замечания по обработке метаданных PDF
- Метаданные могут быть отредактированы или подделаны.
То, что в PDF указано «Автор: Иван Иванов», не означает, что Иван Иванов действительно его написал. Это дает полезный контекст, но не является криминалистическим доказательством без более глубокого анализа.
- Сканированные PDF отличаются.
Если кто-то отсканировал физический документ и сохранил его как PDF, единственными метаданными, которые вы обычно получите, будут информация сканера и дата создания. «Автор» или «ключевые слова» отсутствуют, если их не добавили позже.
- Совет по SEO.
Если вы размещаете PDF-файлы на своем веб-сайте, заполните поля «Заголовок» и «Тема». Google часто использует их для заголовка и описания в результатах поиска, что лучше, чем показывать случайное имя файла.
Заключение
Извлечение метаданных из PDF — это практический навык, который экономит время, защищает конфиденциальность и иногда раскрывает именно ту деталь, которую вы искали. Независимо от того, используете ли вы окно «Свойства» Acrobat для быстрой проверки, бесплатный онлайн-инструмент для общедоступных документов, скрипт C# для обработки тысяч счетов или ExifTool для пакетных аудитов командной строки, правильный метод зависит от количества обрабатываемых файлов и глубины необходимого анализа.
В следующий раз, когда вы скачаете PDF или подготовите его для обмена, уделите минуту, чтобы взглянуть на его метаданные. Вы можете быть удивлены тем, что к нему прикреплено, и теперь вы будете точно знать, как его извлечь.
Часто задаваемые вопросы (FAQ)
В1: Могу ли я извлечь метаданные из сканированных PDF?
Сканированные PDF-файлы (которые являются просто изображениями) обычно не имеют метаданных. Вам потребуется использовать программное обеспечение OCR, чтобы преобразовать изображение в текст, а затем добавить метаданные вручную.
В2: Метаданные — это то же самое, что и свойства файла?
Не совсем. Свойства файла (такие как размер файла, дата создания) управляются операционной системой. Метаданные PDF встроены в сам PDF и перемещаются вместе с документом.
В3: Могу ли я редактировать или удалять метаданные PDF?
Да. Используйте Adobe Acrobat Pro (графический интерфейс) или ExifTool (командная строка) для редактирования/удаления метаданных; библиотеки программирования также поддерживают модификацию.
В4: Влияют ли метаданные на размер файла PDF?
Нет. Метаданные — это легкие текстовые данные, и они не оказывают заметного влияния на размер файла.