
Knowledgebase (2370)
Children categories
Excel documents are widely used in many applications, and it is often necessary to customize their appearance to improve their readability. One way to achieve this is by setting a background color or image for the document, which can enhance its visual appeal and give it a more professional look. This article will demonstrate how to set background color and image for Excel in Java using Spire.XLS for Java.
Install Spire.XLS for Java
First, you're required to add the Spire.Xls.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.7.3</version>
</dependency>
</dependencies>
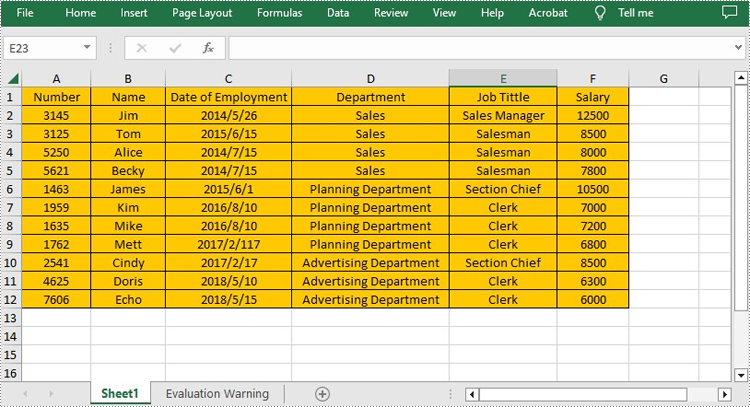
Set Background Color for Excel in Java
With Spire.XLS for Java, not only can you set the background color for the entire range of cells used in the worksheet, but you can also set it for a specific range of cells within the worksheet. The following are the steps to set background color for Excel.
- Create a Workbook instance.
- Load a sample Excel file using Workbook.loadFromFile() method.
- Get a specific worksheet from the workbook using Workbook.getWorksheets.get(index) method.
- Use Worksheet.getAllocatedRange().getStyle().setColor() method to set background color for the used cell range or Worksheet.getCellRange().getStyle().setColor() method to set background color for a specified cell range in the worksheet.
- Save the result file using Workbook.saveToFile() method.
- Java
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import java.awt.*;
public class BackgroundColor{
public static void main(String[] args){
//Create a Workbook instance
Workbook workbook = new Workbook();
//Load an Excel file
workbook.loadFromFile("sample.xlsx");
//Get the first worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
//Set background color for the used cell range in the worksheet
sheet.getAllocatedRange().getStyle().setColor(Color.orange);
//Set background color for a specified cell range in the worksheet
//sheet.getCellRange("A1:E19").getStyle().setColor(Color.pink);
//Save the file
workbook.saveToFile("SetBackColor.xlsx", ExcelVersion.Version2013);
}
}
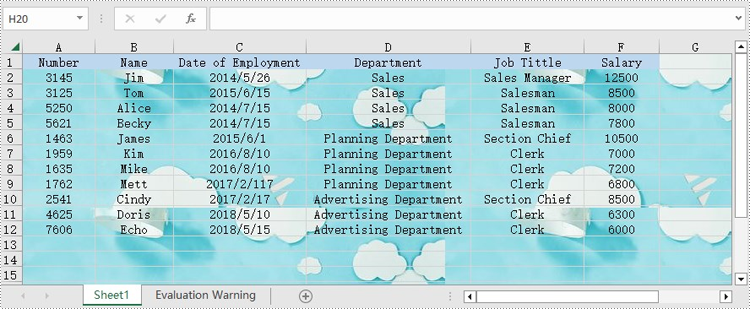
Set Background Image for Excel in Java
Spire.XLS for Java also offers Worksheet.getPageSetup().setBackgoundImage() method for users to set the image background. The following are the steps to achieve this.
- Create a Workbook instance.
- Load a sample Excel file using Workbook.loadFromFile() method.
- Get a specific worksheet from the workbook using Workbook.getWorksheets.get(index) method.
- Set the image as the background image of the worksheet using Worksheet. getPageSetup().setBackgoundImage() method.
- Save the result file using Workbook.saveToFile() method.
- Java
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class BackgroundImage {
public static void main(String[] args) throws IOException {
//Create a Workbook instance
Workbook workbook = new Workbook();
//Load an Excel file
workbook.loadFromFile("sample.xlsx");
//Get the first worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
//Load an image
BufferedImage image = ImageIO.read( new File("background.jpg"));
//Set the image as the background image of the worksheet
sheet.getPageSetup().setBackgoundImage(image);
//Save the file
workbook.saveToFile("SetBackImage.xlsx", ExcelVersion.Version2013);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Textboxes in Excel are versatile tools that enhance the functionality of your spreadsheets. They allow users to add annotations, labels, or supplementary information, making it easier to convey important messages or insights. Whether you're looking to highlight critical data points, provide detailed explanations, or create visually appealing reports, effectively managing textboxes is essential.
In this article, you will learn how to insert a textbox, extract text from a textbox, and delete a textbox in Excel using Java and Spire.XLS for Java.
- Insert a Textbox to Excel in Java
- Extract Text from a Textbox in Excel in Java
- Delete a Textbox in Excel in Java
Install Spire.XLS for Java
First of all, you're required to add the Spire.Xls.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.7.3</version>
</dependency>
</dependencies>
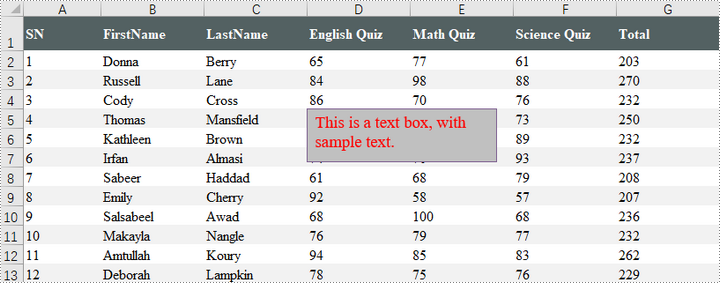
Insert a Textbox to Excel in Java
A textbox can be inserted into a worksheet using the Worksheet.getTextBoxes().addTextBox() method. This method returns an ITextBoxShape object, which provides various methods like setText(), setHAlignment(), and getFill() for configuring the text and formatting of the textbox.
To add a textbox with personalized text and formatting in Excel, follow these steps:
- Create a Workbook object.
- Load an Excel file from the specified file path.
- Retrieve a specific worksheet from the workbook.
- Insert a textbox at the desired location using Worksheet.getTextBoxes().addTextBox() method.
- Set the textbox text using ITextBoxShape.setText() method.
- Customize the textbox's appearance using other methods available in the ITextBoxShape object.
- Save the workbook as a new Excel file.
- Java
import com.spire.xls.*;
import com.spire.xls.core.ITextBoxShape;
import java.awt.*;
public class AddTextbox {
public static void main(String[] args) {
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel document
workbook.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.xlsx");
// Get a specific sheet
Worksheet sheet = workbook.getWorksheets().get(0);
// Add a textbox to the specified location
ITextBoxShape textBoxShape = sheet.getTextBoxes().addTextBox(5, 4, 60, 200);
// Set text of the textbox
textBoxShape.setText("This is a text box, with sample text.");
// Create a font
ExcelFont font = workbook.createFont();
font.setFontName("Times New Roman");
font.setSize(14);
font.setColor(Color.red);
// Apply font to the text
textBoxShape.getRichText().setFont(0, textBoxShape.getText().length() - 1, font);
// Set horizontal alignment
textBoxShape.setHAlignment(CommentHAlignType.Left);
// Set the fill color of the shape
textBoxShape.getFill().setFillType(ShapeFillType.SolidColor);
textBoxShape.getFill().setForeColor(Color.LIGHT_GRAY);
// Save the Excel file
workbook.saveToFile("output/AddTextBox.xlsx", ExcelVersion.Version2010);
// Dispose resources
workbook.dispose();
}
}
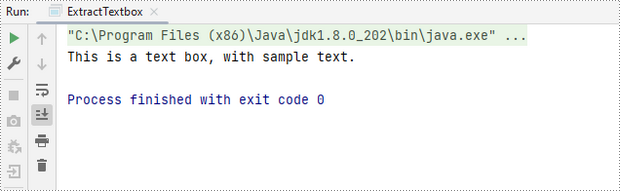
Extract Text from a Textbox in Excel in Java
You can access a specific textbox using the Worksheet.getTextBoxes().get() method. After retrieving it, the text can be accessed with the ITextBox.getText() method.
Here are the steps to extract text from a textbox in Excel:
- Create a Workbook object.
- Load an Excel file from the specified file path.
- Retrieve a specific worksheet from the workbook.
- Access the desired textbox using Worksheet.getTextBoxes().get() method.
- Get the textbox's text using ITextBox.getText() method.
- Java
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import com.spire.xls.core.ITextBox;
public class ExtractTextbox {
public static void main(String[] args) {
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.loadFromFile("C:\\Users\\Administrator\\Desktop\\TextBox.xlsx");
// Get a specific worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
// Get a specific textbox
ITextBox textBox = sheet.getTextBoxes().get(0);
// Get text from the textbox
String text = textBox.getText();
// Print out result
System.out.println(text);
}
}
Delete a Textbox in Excel in Java
To delete a specific textbox from a worksheet, utilize the ITextBoxes.get().Remove() method. If you want to clear all textboxes, first obtain the count with the Worksheet.getTextBoxes().getCount() method, then loop through the collection to remove each textbox one by one.
Here's how to remove a textbox from Excel:
- Create a Workbook object.
- Load an Excel file from the desired file path.
- Access a specific worksheet within the workbook.
- Retrieve the textbox collection using Worksheet.getTextBoxes() method.
- Delete the targeted textbox using ITextBoxes.get().Remove() method.
- Save the modified workbook to a new Excel file.
- Java
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import com.spire.xls.core.ITextBoxes;
public class DeleteTextbox {
public static void main(String[] args) {
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.loadFromFile("C:\\Users\\Administrator\\Desktop\\TextBox.xlsx");
// Get a specific worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
// Get textbox collection from the worksheet
ITextBoxes textBoxes = sheet.getTextBoxes();
// Remove a specific textbox
textBoxes.get(0).remove();
// Save the updated document to a different Excel file
workbook.saveToFile("output/DeleteTextbox.xlsx", ExcelVersion.Version2016);
// Dispose resources
workbook.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
When you work with Excel worksheets on a daily basis, you sometimes need to convert them to images for storage or preventing data from being changed when shared with others. This article will show you how to convert a whole Excel worksheet or a specific cell range to an image using Spire.XLS for Java.
Install Spire.XLS for Java
First of all, you're required to add the Spire.Xls.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.7.3</version>
</dependency>
</dependencies>
Convert a Whole Excel Worksheet to Image
The following steps will demonstrate how to convert a whole Excel worksheet to an image.
- Create a Workbook instance.
- Load a sample Excel document using Workbook.loadFromFile() method.
- Get a specific worksheet of the document using Workbook.getWorksheets().get() method.
- Convert the worksheet to an image using Worksheet.saveToImage() method.
- Java
import com.spire.xls.*;
public class ExcelToImage {
public static void main(String[] args){
//Create a workbook instance
Workbook workbook = new Workbook();
//Load a sample Excel document
workbook.loadFromFile("C:\\Users\\Test1\\Desktop\\sample.xlsx");
//Get the first worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
//Save the sheet to an image
sheet.saveToImage("output/SheetToImage.png");
}
}
Convert a Specific Cell Range to Image
Spire.XLS for Java supports converting a specific cell range to an image by using the Worksheet.toImage (int firstRow,int firstColumn,int lastRow,int lastColumn) method. Detailed steps are listed below.
- Create a Workbook instance.
- Load a sample Excel document using Workbook.loadFromFile() method.
- Get a specific worksheet of the document using Workbook.getWorksheets().get() method.
- Create a BufferedImage instance.
- Convert a specific cell range to the ButteredImage object using Worksheet.toImage () method.
- Save the BufferedImage object to a .png image.
- Java
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
public class SpecificCellsToImage {
public static void main(String[] args) throws IOException {
//Create a workbook instance
Workbook workbook = new Workbook();
//Load a sample Excel document
workbook.loadFromFile("C:\\Users\\Test1\\Desktop\\sample.xlsx");
//Get the first worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
//Convert a specific cell range to the BufferedImage object
BufferedImage bufferedImage = sheet.toImage(1, 1, 7, 4);
//Save as a .png image
ImageIO.write(bufferedImage,"PNG",new File("output/specificCellsToImage.png"));
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
