C#/VB.NET: Extract Text from PDF Documents
Table of Contents
Installed via NuGet
PM> Install-Package Spire.PDF
Related Links
PDF documents are fixed in layout and do not allow users to perform modifications in them. To make the PDF content editable again, you can convert PDF to Word or extract text from PDF. In this article, you will learn how to extract text from a specific PDF page, how to extract text from a particular rectangle area, and how to extract text by SimpleTextExtractionStrategy in C# and VB.NET using Spire.PDF for .NET.
- Extract Text from a Specified Page
- Extract Text from a Rectangle
- Extract Text using SimpleTextExtractionStrategy
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
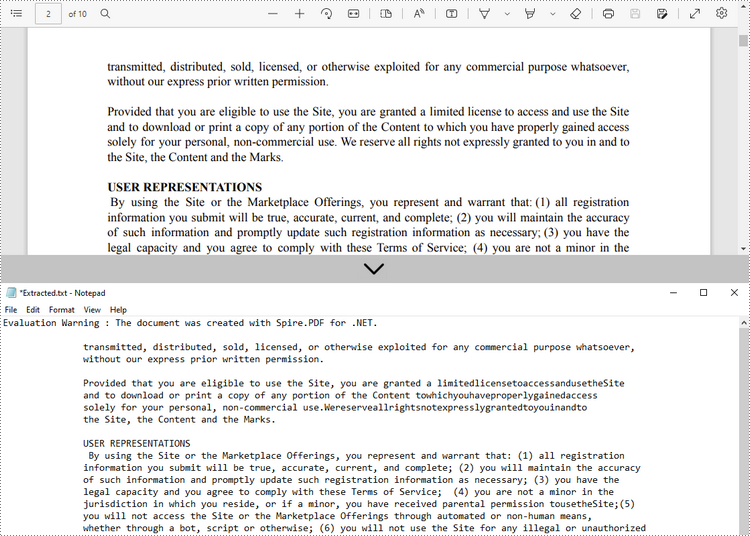
Extract Text from a Specified Page
The following are the steps to extract text from a certain page of a PDF document using Spire.PDF for .NET.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and set the IsExtractAllText property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extract Text from a Rectangle
The following are the steps to extract text from a rectangle area of a page using Spire.PDF for .NET.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and specify the rectangle area through the ExtractArea property of it.
- Extract text from the rectangle using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
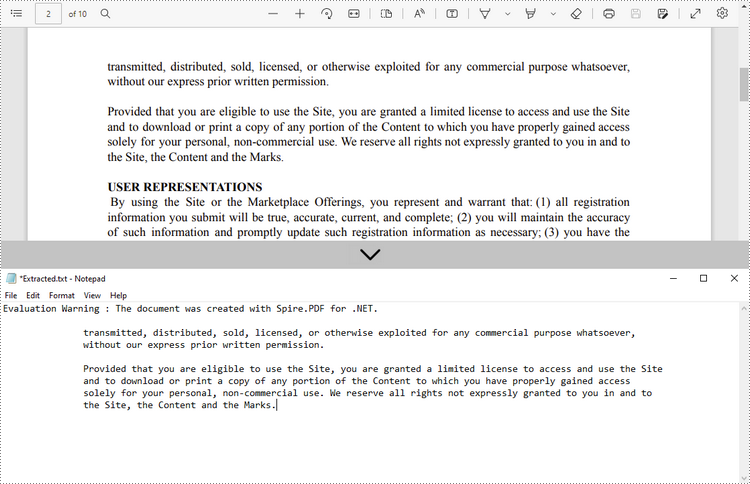
Extract Text using SimpleTextExtractionStrategy
The above methods extract text line by line. When extracting text using SimpleTextExtractionStrategy, it keeps track of the current Y position of each string and inserts a line break into the output if the Y position has changed. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object and set the IsSimpleExtraction property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#/VB.NET: Extraia texto de documentos PDF
Índice
Instalado via NuGet
PM> Install-Package Spire.PDF
Links Relacionados
Os documentos PDF têm layout fixo e não permitem que os usuários façam modificações neles. Para tornar o conteúdo PDF editável novamente, você pode converter PDF para Word ou extraia texto de PDF. Neste artigo você aprenderá como extrair texto de uma página PDF específica, como extrair texto de uma área retangular específica, e como extraia texto por SimpleTextExtractionStrategy em C# e VB.NET usando Spire.PDF for .NET.
- Extraia texto de uma página específica
- Extrair texto de um retângulo
- Extraia texto usando SimpleTextExtractionStrategy
Instale o Spire.PDF for .NET
Para começar, você precisa adicionar os arquivos DLL incluídos no pacote Spire.PDF for.NET como referências em seu projeto .NET. Os arquivos DLL podem ser baixados deste link ou instalados via NuGet.
PM> Install-Package Spire.PDF
Extraia texto de uma página específica
A seguir estão as etapas para extrair texto de uma determinada página de um documento PDF usando Spire.PDF for .NET.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica por meio da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e defina a propriedade IsExtractAllText como true.
- Extraia o texto da página selecionada usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extrair texto de um retângulo
A seguir estão as etapas para extrair texto de uma área retangular de uma página usando Spire.PDF for .NET.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica por meio da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e especifique a área do retângulo por meio da propriedade ExtractArea dele.
- Extraia o texto do retângulo usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extraia texto usando SimpleTextExtractionStrategy
Os métodos acima extraem texto linha por linha. Ao extrair texto usando SimpleTextExtractionStrategy, ele rastreia a posição Y atual de cada string e insere uma quebra de linha na saída se a posição Y tiver mudado. A seguir estão as etapas detalhadas.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica por meio da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e defina a propriedade IsSimpleExtraction como true.
- Extraia o texto da página selecionada usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Solicite uma licença temporária
Se desejar remover a mensagem de avaliação dos documentos gerados ou se livrar das limitações de função, por favor solicite uma licença de teste de 30 dias para você mesmo.
C#/VB.NET: извлечение текста из PDF-документов
Оглавление
Установлено через NuGet
PM> Install-Package Spire.PDF
Ссылки по теме
PDF-документы имеют фиксированный макет и не позволяют пользователям вносить в них изменения. Чтобы снова сделать содержимое PDF доступным для редактирования, вы можете конвертировать PDF в Word или извлечь текст из PDF. В этой статье вы узнаете, как извлечь текст из определенной страницы PDF, как извлечь текст из определенной области прямоугольника, и как извлекайте текст с помощью SimpleTextExtractionStrategy в C# и VB.NET используя Spire.PDF for .NET.
- Извлечь текст с указанной страницы
- Извлечь текст из прямоугольника
- Извлеките текст с помощью SimpleTextExtractionStrategy
Установите Spire.PDF for .NET
Для начала вам необходимо добавить файлы DLL, включенные в пакет Spire.PDF for.NET, в качестве ссылок в ваш проект .NET. Файлы DLL можно загрузить по этой ссылке или установить через NuGet.
PM> Install-Package Spire.PDF
Извлечь текст с указанной страницы
Ниже приведены шаги по извлечению текста из определенной страницы PDF-документа с помощью Spire.PDF for .NET.
- Создайте объект PDFDocument.
- Загрузите PDF-файл с помощью метода PdfDocument.LoadFromFile().
- Получите конкретную страницу через свойство PdfDocument.Pages[index].
- Создайте объект PdfTextExtractor.
- Создайте объект PdfTextExtractOptions и задайте для свойства IsExtractAllText значение true.
- Извлеките текст с выбранной страницы с помощью метода PdfTextExtractor.ExtractText().
- Запишите извлеченный текст в файл TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Извлечь текст из прямоугольника
Ниже приведены шаги по извлечению текста из прямоугольной области страницы с помощью Spire.PDF for .NET.
- Создайте объект PDFDocument.
- Загрузите PDF-файл с помощью метода PdfDocument.LoadFromFile().
- Получите конкретную страницу через свойство PdfDocument.Pages[index].
- Создайте объект PdfTextExtractor.
- Создайте объект PdfTextExtractOptions и укажите область прямоугольника с помощью его свойства ExtractArea.
- Извлеките текст из прямоугольника с помощью метода PdfTextExtractor.ExtractText().
- Запишите извлеченный текст в файл TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Извлеките текст с помощью SimpleTextExtractionStrategy
Вышеупомянутые методы извлекают текст построчно. При извлечении текста с помощью SimpleTextExtractionStrategy он отслеживает текущую позицию Y каждой строки и вставляет разрыв строки в выходные данные, если позиция Y изменилась. Ниже приведены подробные шаги.
- Создайте объект PDFDocument.
- Загрузите PDF-файл с помощью метода PdfDocument.LoadFromFile().
- Получите конкретную страницу через свойство PdfDocument.Pages[index].
- Создайте объект PdfTextExtractor.
- Создайте объект PdfTextExtractOptions и задайте для свойства IsSimpleExtraction значение true.
- Извлеките текст с выбранной страницы с помощью метода PdfTextExtractor.ExtractText().
- Запишите извлеченный текст в файл TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Подать заявку на временную лицензию
Если вы хотите удалить сообщение об оценке из сгенерированных документов или избавиться от ограничений функции, пожалуйста запросите 30-дневную пробную лицензию для себя.
C#/VB.NET: Text aus PDF-Dokumenten extrahieren
Inhaltsverzeichnis
Über NuGet installiert
PM> Install-Package Spire.PDF
verwandte Links
PDF-Dokumente haben ein festes Layout und erlauben es Benutzern nicht, Änderungen daran vorzunehmen. Um den PDF-Inhalt wieder bearbeitbar zu machen, können Sie dies tun PDF zu Word konvertieren oder extrahieren Sie Text aus PDF. In diesem Artikel erfahren Sie, wie das geht Text aus einer bestimmten PDF-Seite extrahieren, wie man Text aus einem bestimmten Rechteckbereich extrahieren, und wie Extrahieren Sie Text mit SimpleTextExtractionStrategy in C# und VB.NET unter Verwendung von Spire.PDF for .NET.
- Extrahieren Sie Text von einer bestimmten Seite
- Extrahieren Sie Text aus einem Rechteck
- Extrahieren Sie Text mit SimpleTextExtractionStrategy
Installieren Sie Spire.PDF for .NET
Zunächst müssen Sie die im Spire.PDF for.NET-Paket enthaltenen DLL-Dateien als Referenzen in Ihrem .NET-Projekt hinzufügen. Die DLL-Dateien können entweder über diesen Link heruntergeladen oder über NuGet installiert werden.
PM> Install-Package Spire.PDF
Extrahieren Sie Text von einer bestimmten Seite
Im Folgenden finden Sie die Schritte zum Extrahieren von Text aus einer bestimmten Seite eines PDF-Dokuments mit Spire.PDF for .NET.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und legen Sie die IsExtractAllText-Eigenschaft auf true fest.
- Extrahieren Sie Text aus der ausgewählten Seite mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extrahieren Sie Text aus einem Rechteck
Im Folgenden finden Sie die Schritte zum Extrahieren von Text aus einem rechteckigen Bereich einer Seite mit Spire.PDF for .NET.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und geben Sie den Rechteckbereich über dessen ExtractArea-Eigenschaft an.
- Extrahieren Sie Text aus dem Rechteck mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extrahieren Sie Text mit SimpleTextExtractionStrategy
Die oben genannten Methoden extrahieren Text Zeile für Zeile. Beim Extrahieren von Text mit SimpleTextExtractionStrategy wird die aktuelle Y-Position jeder Zeichenfolge verfolgt und ein Zeilenumbruch in die Ausgabe eingefügt, wenn sich die Y-Position geändert hat. Im Folgenden finden Sie die detaillierten Schritte.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und legen Sie die IsSimpleExtraction-Eigenschaft auf true fest.
- Extrahieren Sie Text aus der ausgewählten Seite mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Beantragen Sie eine temporäre Lizenz
Wenn Sie die Bewertungsmeldung aus den generierten Dokumenten entfernen oder die Funktionseinschränkungen beseitigen möchten, wenden Sie sich bitte an uns Fordern Sie eine 30-Tage-Testlizenz an für sich selbst.
C#/VB.NET: extraer texto de documentos PDF
Tabla de contenido
Instalado a través de NuGet
PM> Install-Package Spire.PDF
enlaces relacionados
Los documentos PDF tienen un diseño fijo y no permiten a los usuarios realizar modificaciones en ellos. Para volver a editar el contenido del PDF, puede convertir PDF a Word o extraer texto de PDF. En este artículo, aprenderá cómo extraer texto de una página PDF específica, cómo extraer texto de un área rectangular particular, y cómo extraiga texto mediante SimpleTextExtractionStrategy en C# y VB.NET usando Spire.PDF for .NET.
- Extraer texto de una página especificada
- Extraer texto de un rectángulo
- Extraer texto usando SimpleTextExtractionStrategy
Instalar Spire.PDF for .NET
Para empezar, debe agregar los archivos DLL incluidos en el paquete Spire.PDF for .NET como referencias en su proyecto .NET. Los archivos DLL se pueden descargar desde este enlace o instalar a través de NuGet.
PM> Install-Package Spire.PDF
Extraer texto de una página especificada
Los siguientes son los pasos para extraer texto de una determinada página de un documento PDF usando Spire.PDF for .NET.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y establezca la propiedad IsExtractAllText en verdadero.
- Extraiga texto de la página seleccionada utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extraer texto de un rectángulo
Los siguientes son los pasos para extraer texto de un área rectangular de una página usando Spire.PDF for .NET.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y especifique el área del rectángulo a través de la propiedad ExtractArea del mismo.
- Extraiga texto del rectángulo utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extraer texto usando SimpleTextExtractionStrategy
Los métodos anteriores extraen texto línea por línea. Al extraer texto usando SimpleTextExtractionStrategy, realiza un seguimiento de la posición Y actual de cada cadena e inserta un salto de línea en la salida si la posición Y ha cambiado. Los siguientes son los pasos detallados.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y establezca la propiedad IsSimpleExtraction en verdadero.
- Extraiga texto de la página seleccionada utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Solicitar una licencia temporal
Si desea eliminar el mensaje de evaluación de los documentos generados o deshacerse de las limitaciones de la función, por favor solicitar una licencia de prueba de 30 días para ti.
C#/VB.NET: PDF 문서에서 텍스트 추출
목차
NuGet을 통해 설치됨
PM> Install-Package Spire.PDF
관련된 링크들
PDF 문서는 레이아웃이 고정되어 있어 사용자가 수정할 수 없습니다. PDF 내용을 다시 편집 가능하게 만들려면 다음을 수행하십시오 PDF를 워드로 변환 또는 PDF에서 텍스트를 추출합니다. 이 기사에서는 다음 방법을 배웁니다 특정 PDF 페이지에서 텍스트를 추출하고, 어떻게 특정 직사각형 영역에서 텍스트를 추출하고, 그리고 어떻게 SimpleTextExtractionStrategy로 텍스트를 추출합니다 C# 및 VB.NET Spire.PDF for .NET사용합니다.
Spire.PDF for .NET 설치
먼저 Spire.PDF for.NET 패키지에 포함된 DLL 파일을 .NET 프로젝트의 참조로 추가해야 합니다. DLL 파일은 이 링크 에서 다운로드하거나 NuGet을 통해 설치할 수 있습니다.
PM> Install-Package Spire.PDF
지정된 페이지에서 텍스트 추출
다음은 Spire.PDF for.NET를 사용하여 PDF 문서의 특정 페이지에서 텍스트를 추출하는 단계입니다.
- PdfDocument 개체를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfDocument.Pages[index] 속성을 통해 특정 페이지를 가져옵니다.
- PdfTextExtractor 개체를 만듭니다.
- PdfTextExtractOptions 개체를 만들고 IsExtractAllText 속성을 true로 설정합니다.
- PdfTextExtractor.ExtractText() 메서드를 사용하여 선택한 페이지에서 텍스트를 추출합니다.
- 추출된 텍스트를 TXT 파일에 씁니다.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
직사각형에서 텍스트 추출
다음은 Spire.PDF for.NET를 사용하여 페이지의 직사각형 영역에서 텍스트를 추출하는 단계입니다.
- PdfDocument 개체를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfDocument.Pages[index] 속성을 통해 특정 페이지를 가져옵니다.
- PdfTextExtractor 개체를 만듭니다.
- PdfTextExtractOptions 개체를 만들고 해당 개체의 ExtractArea 속성을 통해 사각형 영역을 지정합니다.
- PdfTextExtractor.ExtractText() 메서드를 사용하여 사각형에서 텍스트를 추출합니다.
- 추출된 텍스트를 TXT 파일에 씁니다.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
SimpleTextExtractionStrategy를 사용하여 텍스트 추출
위의 방법은 텍스트를 한 줄씩 추출합니다. SimpleTextExtractionStrategy를 사용하여 텍스트를 추출할 때 각 문자열의 현재 Y 위치를 추적하고 Y 위치가 변경된 경우 출력에 줄 바꿈을 삽입합니다. 자세한 단계는 다음과 같습니다.
- PdfDocument 개체를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfDocument.Pages[index] 속성을 통해 특정 페이지를 가져옵니다.
- PdfTextExtractor 개체를 만듭니다.
- PdfTextExtractOptions 개체를 만들고 IsSimpleExtraction 속성을 true로 설정합니다.
- PdfTextExtractor.ExtractText() 메서드를 사용하여 선택한 페이지에서 텍스트를 추출합니다.
- 추출된 텍스트를 TXT 파일에 씁니다.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
임시 라이센스 신청
생성된 문서에서 평가 메시지를 제거하고 싶거나, 기능 제한을 없애고 싶다면 30일 평가판 라이센스 요청 자신을 위해.
C#/VB.NET: estrae testo da documenti PDF
Sommario
Installato tramite NuGet
PM> Install-Package Spire.PDF
Link correlati
I documenti PDF hanno un layout fisso e non consentono agli utenti di apportare modifiche al loro interno. Per rendere nuovamente modificabile il contenuto del PDF, puoi farlo convertire PDF in Word o estrarre testo da PDF. In questo articolo imparerai come farlo estrarre il testo da una pagina PDF specifica, come estrarre il testo da una particolare area rettangolare, e come farlo estrarre testo con SimpleTextExtractionStrategy in C# e VB.NET utilizzando Spire.PDF for .NET.
- Estrai testo da una pagina specificata
- Estrai testo da un rettangolo
- Estrai testo utilizzando SimpleTextExtractionStrategy
Installa Spire.PDF for .NET
Per cominciare, devi aggiungere i file DLL inclusi nel pacchetto Spire.PDF for.NET come riferimenti nel tuo progetto .NET. I file DLL possono essere scaricati da questo link o installato tramite NuGet.
PM> Install-Package Spire.PDF
Estrai testo da una pagina specificata
Di seguito sono riportati i passaggi per estrarre il testo da una determinata pagina di un documento PDF utilizzando Spire.PDF for .NET.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e imposta la proprietà IsExtractAllText su true.
- Estrai il testo dalla pagina selezionata utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Estrai testo da un rettangolo
Di seguito sono riportati i passaggi per estrarre il testo da un'area rettangolare di una pagina utilizzando Spire.PDF for .NET.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e specifica l'area del rettangolo tramite la sua proprietà ExtractArea.
- Estrai il testo dal rettangolo utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Estrai testo utilizzando SimpleTextExtractionStrategy
I metodi precedenti estraggono il testo riga per riga. Quando si estrae il testo utilizzando SimpleTextExtractionStrategy, tiene traccia della posizione Y corrente di ciascuna stringa e inserisce un'interruzione di riga nell'output se la posizione Y è cambiata. Di seguito sono riportati i passaggi dettagliati.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e imposta la proprietà IsSimpleExtraction su true.
- Estrai il testo dalla pagina selezionata utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Richiedi una licenza temporanea
Se desideri rimuovere il messaggio di valutazione dai documenti generati o eliminare le limitazioni della funzione, per favore richiedere una licenza di prova di 30 giorni per te.
C#/VB.NET : extraire le texte des documents PDF
Table des matières
Installé via NuGet
PM> Install-Package Spire.PDF
Liens connexes
Les documents PDF ont une mise en page fixe et ne permettent pas aux utilisateurs d'y apporter des modifications. Pour rendre le contenu PDF à nouveau modifiable, vous pouvez convertir un PDF en Word ou extraire du texte d'un PDF. Dans cet article, vous apprendrez comment extraire le texte d'une page PDF spécifique, comment extraire le texte d'une zone de rectangle particulière, et comment extraire le texte par SimpleTextExtractionStrategy en C# et VB.NET l'aide de Spire.PDF for .NET.
- Extraire le texte d'une page spécifiée
- Extraire le texte d'un rectangle
- Extraire du texte à l'aide de SimpleTextExtractionStrategy
Installer Spire.PDF for .NET
Pour commencer, vous devez ajouter les fichiers DLL inclus dans le package Spire.PDF for.NET comme références dans votre projet .NET. Les fichiers DLL peuvent être téléchargés à partir de ce lien ou installés via NuGet.
PM> Install-Package Spire.PDF
Extraire le texte d'une page spécifiée
Voici les étapes pour extraire le texte d'une certaine page d'un document PDF à l'aide de Spire.PDF for .NET.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et définissez la propriété IsExtractAllText sur true.
- Extrayez le texte de la page sélectionnée à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extraire le texte d'un rectangle
Voici les étapes pour extraire le texte d’une zone rectangulaire d’une page à l’aide de Spire.PDF for .NET.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et spécifiez la zone rectangulaire via sa propriété ExtractArea.
- Extrayez le texte du rectangle à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Extraire du texte à l'aide de SimpleTextExtractionStrategy
Les méthodes ci-dessus extraient le texte ligne par ligne. Lors de l'extraction de texte à l'aide de SimpleTextExtractionStrategy, il garde une trace de la position Y actuelle de chaque chaîne et insère un saut de ligne dans la sortie si la position Y a changé. Voici les étapes détaillées.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et définissez la propriété IsSimpleExtraction sur true.
- Extrayez le texte de la page sélectionnée à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Demander une licence temporaire
Si vous souhaitez supprimer le message d'évaluation des documents générés ou vous débarrasser des limitations fonctionnelles, veuillez demander une licence d'essai de 30 jours pour toi.
C#/VB.NET: Insert, Replace or Delete Images in PDF
Table of Contents
Installed via NuGet
PM> Install-Package Spire.PDF
Related Links
Compared with text-only documents, documents containing images are undoubtedly more vivid and engaging to readers. When generating or editing a PDF document, you may sometimes need to insert images to improve its appearance and make it more appealing. In this article, you will learn how to insert, replace or delete images in PDF documents in C# and VB.NET using Spire.PDF for .NET.
- Insert an Image into a PDF Document
- Replace an Image with Another Image in a PDF Document
- Delete a Specific Image in a PDF Document
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Insert an Image into a PDF Document in C# and VB.NET
The following steps demonstrate how to insert an image into an existing PDF document:
- Initialize an instance of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the desired page in the PDF document through PdfDocument.Pages[pageIndex] property.
- Load an image using PdfImage.FromFile() method.
- Specify the width and height of the image area on the page.
- Specify the X and Y coordinates to start drawing the image.
- Draw the image on the page using PdfPageBase.Canvas.DrawImage() method.
- Save the result document using PdfDocument.SaveToFile() method.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Graphics;
namespace InsertImage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Input.pdf");
//Get the first page in the PDF document
PdfPageBase page = pdf.Pages[0];
//Load an image
PdfImage image = PdfImage.FromFile("image.jpg");
//Specify the width and height of the image area on the page
float width = image.Width * 0.50f;
float height = image.Height * 0.50f;
//Specify the X and Y coordinates to start drawing the image
float x = 180f;
float y = 70f;
//Draw the image at a specified location on the page
page.Canvas.DrawImage(image, x, y, width, height);
//Save the result document
pdf.SaveToFile("AddImage.pdf", FileFormat.PDF);
}
}
}

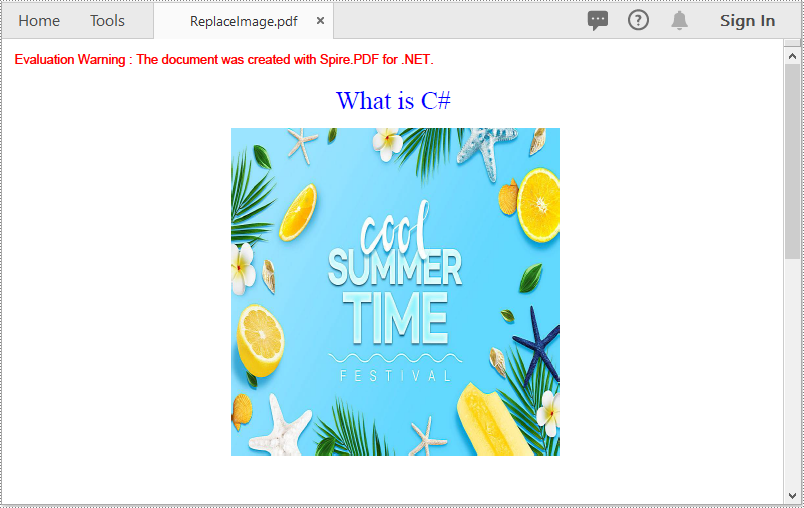
Replace an Image with Another Image in a PDF Document in C# and VB.NET
The following steps demonstrate how to replace an image with another image in a PDF document:
- Initialize an instance of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the desired page in the PDF document through PdfDocument.Pages[pageIndex] property.
- Load an image using PdfImage.FromFile() method.
- Initialize an instance of the PdfImageHelper class.
- Get the image information from the page using PdfImageHelper.GetImagesInfo() method.
- Replace a specific image on the page with the loaded image using PdfImageHelper.ReplaceImage() method.
- Save the result document using PdfDocument.SaveToFile() method.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Utilities;
namespace ReplaceImage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument doc = new PdfDocument();
//Load a PDF document
doc.LoadFromFile("AddImage.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Load an image
PdfImage image = PdfImage.FromFile("image1.jpg");
//Create a PdfImageHelper instance
PdfImageHelper imageHelper = new PdfImageHelper();
//Get the image information from the page
PdfImageInfo[] imageInfo = imageHelper.GetImagesInfo(page);
//Replace the first image on the page with the loaded image
imageHelper.ReplaceImage(imageInfo[0], image);
//Save the result document
doc.SaveToFile("ReplaceImage.pdf", FileFormat.PDF);
}
}
}
Delete a Specific Image in a PDF Document in C# and VB.NET
The following steps demonstrate how to delete an image from a PDF document:
- Initialize an instance of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the desired page in the PDF document through PdfDocument.Pages[pageIndex] property.
- Delete a specific image on the page using PdfPageBase.DeleteImage() method.
- Save the result document using PdfDocument.SaveToFile() method.
- C#
- VB.NET
using Spire.Pdf;
namespace DeleteImage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("AddImage.pdf");
//Get the first page
PdfPageBase page = pdf.Pages[0];
//Delete the first image on the page
page.DeleteImage(0);
//Save the result document
pdf.SaveToFile("DeleteImage.pdf", FileFormat.PDF);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#/VB.NET: inserir, substituir ou excluir imagens em PDF
Índice
Instalado via NuGet
PM> Install-Package Spire.PDF
Links Relacionados
Em comparação com documentos somente de texto, os documentos que contêm imagens são, sem dúvida, mais vívidos e atraentes para os leitores. Ao gerar ou editar um documento PDF, às vezes pode ser necessário inserir imagens para melhorar sua aparência e torná-lo mais atraente. Neste artigo, você aprenderá como inserir, substituir ou excluir imagens em documentos PDF em C# e VB.NET usando Spire.PDF for .NET.
- Insira uma imagem em um documento PDF
- Substitua uma imagem por outra imagem em um documento PDF
- Excluir uma imagem específica em um documento PDF
Instale o Spire.PDF for .NET
Para começar, você precisa adicionar os arquivos DLL incluídos no pacote Spire.PDF for.NET como referências em seu projeto .NET. Os arquivos DLL podem ser baixados deste link ou instalados via NuGet.
PM> Install-Package Spire.PDF
Insira uma imagem em um documento PDF em C# e VB.NET
As etapas a seguir demonstram como inserir uma imagem em um documento PDF existente:
- Inicialize uma instância da classe PdfDocument.
- Carregue um documento PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página desejada no documento PDF através da propriedade PdfDocument.Pages[pageIndex].
- Carregue uma imagem usando o método PdfImage.FromFile().
- Especifique a largura e a altura da área da imagem na página.
- Especifique as coordenadas X e Y para começar a desenhar a imagem.
- Desenhe a imagem na página usando o método PdfPageBase.Canvas.DrawImage().
- Salve o documento resultante usando o método PdfDocument.SaveToFile().
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Graphics;
namespace InsertImage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Input.pdf");
//Get the first page in the PDF document
PdfPageBase page = pdf.Pages[0];
//Load an image
PdfImage image = PdfImage.FromFile("image.jpg");
//Specify the width and height of the image area on the page
float width = image.Width * 0.50f;
float height = image.Height * 0.50f;
//Specify the X and Y coordinates to start drawing the image
float x = 180f;
float y = 70f;
//Draw the image at a specified location on the page
page.Canvas.DrawImage(image, x, y, width, height);
//Save the result document
pdf.SaveToFile("AddImage.pdf", FileFormat.PDF);
}
}
}
Substitua uma imagem por outra imagem em um documento PDF em C# e VB.NET
As etapas a seguir demonstram como substituir uma imagem por outra imagem em um documento PDF:
- Inicialize uma instância da classe PdfDocument.
- Carregue um documento PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página desejada no documento PDF através da propriedade PdfDocument.Pages[pageIndex].
- Carregue uma imagem usando o método PdfImage.FromFile().
- Inicialize uma instância da classe PdfImageHelper.
- Obtenha as informações da imagem da página usando o método PdfImageHelper.GetImagesInfo().
- Substitua uma imagem específica na página pela imagem carregada usando o método PdfImageHelper.ReplaceImage().
- Salve o documento resultante usando o método PdfDocument.SaveToFile().
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Graphics;
using Spire.Pdf.Utilities;
namespace ReplaceImage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument doc = new PdfDocument();
//Load a PDF document
doc.LoadFromFile("AddImage.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Load an image
PdfImage image = PdfImage.FromFile("image1.jpg");
//Create a PdfImageHelper instance
PdfImageHelper imageHelper = new PdfImageHelper();
//Get the image information from the page
PdfImageInfo[] imageInfo = imageHelper.GetImagesInfo(page);
//Replace the first image on the page with the loaded image
imageHelper.ReplaceImage(imageInfo[0], image);
//Save the result document
doc.SaveToFile("ReplaceImage.pdf", FileFormat.PDF);
}
}
}
Exclua uma imagem específica em um documento PDF em C# e VB.NET
As etapas a seguir demonstram como excluir uma imagem de um documento PDF:
- Inicialize uma instância da classe PdfDocument.
- Carregue um documento PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página desejada no documento PDF através da propriedade PdfDocument.Pages[pageIndex].
- Exclua uma imagem específica da página usando o método PdfPageBase.DeleteImage().
- Salve o documento resultante usando o método PdfDocument.SaveToFile().
- C#
- VB.NET
using Spire.Pdf;
namespace DeleteImage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("AddImage.pdf");
//Get the first page
PdfPageBase page = pdf.Pages[0];
//Delete the first image on the page
page.DeleteImage(0);
//Save the result document
pdf.SaveToFile("DeleteImage.pdf", FileFormat.PDF);
}
}
}
Solicite uma licença temporária
Se desejar remover a mensagem de avaliação dos documentos gerados ou se livrar das limitações de função, por favor solicite uma licença de teste de 30 dias para você mesmo.