C#/VB.NET: trova ed evidenzia testo specifico nel PDF
Sommario
Installato tramite NuGet
PM> Install-Package Spire.PDF
Link correlati
La ricerca di un testo specifico in un documento PDF a volte può essere fastidiosa, soprattutto quando il documento contiene centinaia di pagine. Evidenziare il testo con un colore di sfondo può aiutarti a trovarlo e localizzarlo rapidamente. In questo articolo imparerai come trovare ed evidenziare testo specifico in PDF in C# e VB.NET utilizzando Spire.PDF for .NET.
Installa Spire.PDF for .NET
Per cominciare, devi aggiungere i file DLL inclusi nel pacchetto Spire.PDF for.NET come riferimenti nel tuo progetto .NET. I file DLL possono essere scaricati da questo link o installato tramite NuGet.
PM> Install-Package Spire.PDF
Trova ed evidenzia testo specifico in PDF in C# e VB.NET
Di seguito sono riportati i passaggi per trovare ed evidenziare un testo specifico in un documento PDF:
- Crea un'istanza PdfDocument.
- Carica un documento PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Crea un'istanza PdfTextFindOptions.
- Specificare il parametro di ricerca del testo tramite la proprietà PdfTextFindOptions.Parameter.
- Scorri le pagine del documento PDF.
- All'interno del ciclo, crea un'istanza PdfTextFinder e imposta l'opzione di ricerca del testo tramite la proprietà PdfTextFinder.Options.
- Trova un testo specifico nel documento utilizzando il metodo PdfTextFinder.Find() e salva i risultati in un elenco PdfTextFragment.
- Passa in rassegna l'elenco e chiama il metodo PdfTextFragment.Highlight() per evidenziare tutte le occorrenze del testo specifico con il colore.
- Salvare il documento risultante utilizzando il metodo PdfDocument.SaveToFile().
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
using System.Drawing;
namespace HighlightTextInPdf
{
internal class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.LoadFromFile("Sample.pdf");
//Creare a PdfTextFindOptions instance
PdfTextFindOptions findOptions = new PdfTextFindOptions();
//Specify the text finding parameter
findOptions.Parameter = TextFindParameter.WholeWord;
//Loop through the pages in the PDF file
foreach (PdfPageBase page in pdf.Pages)
{
//Create a PdfTextFinder instance
PdfTextFinder finder = new PdfTextFinder(page);
//Set the text finding option
finder.Options = findOptions;
//Find a specific text
List<PdfTextFragment> results = finder.Find("Video");
//Highlight all occurrences of the specific text
foreach (PdfTextFragment text in results)
{
text.HighLight(Color.Green);
}
}
//Save the result file
pdf.SaveToFile("HighlightText.pdf");
}
}
}
Richiedi una licenza temporanea
Se desideri rimuovere il messaggio di valutazione dai documenti generati o eliminare le limitazioni della funzione, per favore richiedere una licenza di prova di 30 giorni per te.
C#/VB.NET : rechercher et mettre en surbrillance du texte spécifique dans un PDF
Table des matières
Installé via NuGet
PM> Install-Package Spire.PDF
Liens connexes
Rechercher un texte spécifique dans un document PDF peut parfois s'avérer fastidieux, surtout lorsque le document contient des centaines de pages. Mettre en surbrillance le texte avec une couleur d'arrière-plan peut vous aider à le trouver et à le localiser rapidement. Dans cet article, vous apprendrez comment recherchez et surlignez du texte spécifique dans un PDF en C# et VB.NET à l'aide de Spire.PDF for .NET.
Installer Spire.PDF for .NET
Pour commencer, vous devez ajouter les fichiers DLL inclus dans le package Spire.PDF for.NET comme références dans votre projet .NET. Les fichiers DLL peuvent être téléchargés à partir de ce lien ou installés via NuGet.
PM> Install-Package Spire.PDF
Rechercher et mettre en surbrillance du texte spécifique dans un PDF en C# et VB.NET
Voici les étapes pour rechercher et surligner un texte spécifique dans un document PDF :
- Créez une instance PdfDocument.
- Chargez un document PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Créez une instance de PdfTextFindOptions.
- Spécifiez le paramètre de recherche de texte via la propriété PdfTextFindOptions.Parameter.
- Parcourez les pages du document PDF.
- Dans la boucle, créez une instance de PdfTextFinder et définissez l'option de recherche de texte via la propriété PdfTextFinder.Options.
- Recherchez un texte spécifique dans le document à l'aide de la méthode PdfTextFinder.Find() et enregistrez les résultats dans une liste PdfTextFragment.
- Parcourez la liste et appelez la méthode PdfTextFragment.Highlight() pour mettre en évidence toutes les occurrences du texte spécifique avec de la couleur.
- Enregistrez le document résultat à l'aide de la méthode PdfDocument.SaveToFile().
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
using System.Drawing;
namespace HighlightTextInPdf
{
internal class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.LoadFromFile("Sample.pdf");
//Creare a PdfTextFindOptions instance
PdfTextFindOptions findOptions = new PdfTextFindOptions();
//Specify the text finding parameter
findOptions.Parameter = TextFindParameter.WholeWord;
//Loop through the pages in the PDF file
foreach (PdfPageBase page in pdf.Pages)
{
//Create a PdfTextFinder instance
PdfTextFinder finder = new PdfTextFinder(page);
//Set the text finding option
finder.Options = findOptions;
//Find a specific text
List<PdfTextFragment> results = finder.Find("Video");
//Highlight all occurrences of the specific text
foreach (PdfTextFragment text in results)
{
text.HighLight(Color.Green);
}
}
//Save the result file
pdf.SaveToFile("HighlightText.pdf");
}
}
}
Demander une licence temporaire
Si vous souhaitez supprimer le message d'évaluation des documents générés ou vous débarrasser des limitations fonctionnelles, veuillez demander une licence d'essai de 30 jours pour toi.
- C# : obtenir les coordonnées d'un texte ou d'une image au format PDF
- C#/VB.NET : créer un PDF multicolonne
- Mettre en surbrillance les textes recherchés avec différentes couleurs en C#/VB.NET
- Dessiner du texte dans un document PDF dans Silverlight
- Rechercher et remplacer du texte sur un document PDF en C#
C#/VB.NET: Extract Images from PDF
Table of Contents
Installed via NuGet
PM> Install-Package Spire.PDF
Related Links
Images are often used in PDF documents to present information in an easily understandable manner. In certain cases, you may need to extract images from PDF documents. For example, when you want to use a chart image from a PDF report in a presentation or another document. This article will demonstrate how to extract images from PDF in C# and VB.NET using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Extract Images from PDF in C# and VB.NET
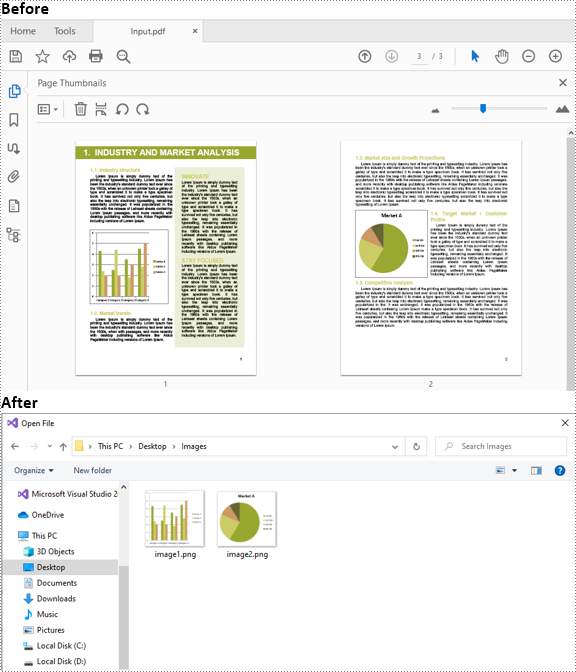
The following are the main steps to extract images from a PDF document using Spire.PDF for .NET:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through all the pages in the document.
- Extract images from each page using PdfPageBase.ExtractImages() method and save them to a specified file path.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#/VB.NET: Extraia imagens de PDF
Instalado via NuGet
PM> Install-Package Spire.PDF
Links Relacionados
As imagens são frequentemente usadas em documentos PDF para apresentar informações de maneira facilmente compreensível. Em certos casos, pode ser necessário extrair imagens de documentos PDF. Por exemplo, quando você deseja usar uma imagem gráfica de um relatório PDF em uma apresentação ou outro documento. Este artigo demonstrará como extrair imagens de PDF em C# e VB.NET usando Spire.PDF for .NET.
Instale o Spire.PDF for .NET
Para começar, você precisa adicionar os arquivos DLL incluídos no pacote Spire.PDF for.NET como referências em seu projeto .NET. Os arquivos DLL podem ser baixados deste link ou instalados via NuGet.
PM> Install-Package Spire.PDF
Extraia imagens de PDF em C# e VB.NET
A seguir estão as etapas principais para extrair imagens de um documento PDF usando Spire.PDF for .NET:
- Crie um objeto PdfDocument.
- Carregue um documento PDF usando o método PdfDocument.LoadFromFile().
- Percorra todas as páginas do documento.
- Extraia imagens de cada página usando o método PdfPageBase.ExtractImages() e salve-as em um caminho de arquivo especificado.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Solicite uma licença temporária
Se desejar remover a mensagem de avaliação dos documentos gerados ou se livrar das limitações de função, por favor solicite uma licença de teste de 30 dias para você mesmo.
C#/VB.NET: извлечение изображений из PDF
Установлено через NuGet
PM> Install-Package Spire.PDF
Ссылки по теме
Изображения часто используются в документах PDF для представления информации в понятной форме. В некоторых случаях вам может потребоваться извлечь изображения из PDF-документов. Например, если вы хотите использовать изображение диаграммы из отчета PDF в презентации или другом документе. В этой статье будет показано, как извлекать изображения из PDF в C# и VB.NET использование Spire.PDF for .NET.
Установите Spire.PDF for .NET
Для начала вам необходимо добавить файлы DLL, включенные в пакет Spire.PDF for.NET, в качестве ссылок в ваш проект .NET. Файлы DLL можно загрузить по этой ссылке или установить через NuGet.
PM> Install-Package Spire.PDF
Извлечение изображений из PDF в C# и VB.NET
Ниже приведены основные шаги по извлечению изображений из PDF-документа с помощью Spire.PDF for .NET:
- Создайте объект PDFDocument.
- Загрузите PDF-документ с помощью метода PdfDocument.LoadFromFile().
- Прокрутите все страницы документа.
- Извлеките изображения с каждой страницы с помощью метода PdfPageBase.ExtractImages() и сохраните их по указанному пути к файлу.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Подать заявку на временную лицензию
Если вы хотите удалить сообщение об оценке из сгенерированных документов или избавиться от ограничений функции, пожалуйста запросите 30-дневную пробную лицензию для себя.
C#/VB.NET: extraer imágenes de PDF
Inhaltsverzeichnis
Über NuGet installiert
PM> Install-Package Spire.PDF
verwandte Links
In PDF-Dokumenten werden häufig Bilder verwendet, um Informationen leicht verständlich darzustellen. In bestimmten Fällen müssen Sie möglicherweise Bilder aus PDF-Dokumenten extrahieren. Wenn Sie beispielsweise ein Diagrammbild aus einem PDF-Bericht in einer Präsentation oder einem anderen Dokument verwenden möchten. Dieser Artikel zeigt, wie das geht Extrahieren Sie Bilder aus PDF in C# und VB.NET Verwendung von Spire.PDF for .NET.
Installieren Sie Spire.PDF for .NET
Zunächst müssen Sie die im Spire.PDF for.NET-Paket enthaltenen DLL-Dateien als Referenzen in Ihrem .NET-Projekt hinzufügen. Die DLL-Dateien können entweder über diesen Link heruntergeladen oder über NuGet installiert werden.
PM> Install-Package Spire.PDF
Extrahieren Sie Bilder aus PDF in C# und VB.NET
Im Folgenden sind die wichtigsten Schritte zum Extrahieren von Bildern aus einem PDF-Dokument mit Spire.PDF for .NET aufgeführt:
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie ein PDF-Dokument mit der Methode PdfDocument.LoadFromFile().
- Durchlaufen Sie alle Seiten im Dokument.
- Extrahieren Sie Bilder von jeder Seite mit der Methode PdfPageBase.ExtractImages() und speichern Sie sie in einem angegebenen Dateipfad.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Beantragen Sie eine temporäre Lizenz
Wenn Sie die Bewertungsmeldung aus den generierten Dokumenten entfernen oder die Funktionseinschränkungen beseitigen möchten, wenden Sie sich bitte an uns Fordern Sie eine 30-Tage-Testlizenz an für sich selbst.
C#/VB.NET: extraer imágenes de PDF
Tabla de contenido
Instalado a través de NuGet
PM> Install-Package Spire.PDF
enlaces relacionados
Las imágenes se utilizan a menudo en documentos PDF para presentar información de una manera fácilmente comprensible. En determinados casos, es posible que necesites extraer imágenes de documentos PDF. Por ejemplo, cuando desea utilizar una imagen de gráfico de un informe PDF en una presentación u otro documento. Este artículo demostrará cómo extraer imágenes de PDF en C# y VB.NET usando Spire.PDF for .NET.
Instalar Spire.PDF for .NET
Para empezar, debe agregar los archivos DLL incluidos en el paquete Spire.PDF for .NET como referencias en su proyecto .NET. Los archivos DLL se pueden descargar desde este enlace o instalar a través de NuGet.
PM> Install-Package Spire.PDF
Extraiga imágenes de PDF en C# y VB.NET
Los siguientes son los pasos principales para extraer imágenes de un documento PDF usando Spire.PDF for .NET:
- Cree un objeto PdfDocument.
- Cargue un documento PDF utilizando el método PdfDocument.LoadFromFile().
- Recorre todas las páginas del documento.
- Extraiga imágenes de cada página utilizando el método PdfPageBase.ExtractImages() y guárdelas en una ruta de archivo especificada.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Solicitar una licencia temporal
Si desea eliminar el mensaje de evaluación de los documentos generados o deshacerse de las limitaciones de la función, por favor solicitar una licencia de prueba de 30 días para ti.
C#/VB.NET: PDF에서 이미지 추출
NuGet을 통해 설치됨
PM> Install-Package Spire.PDF
관련된 링크들
이미지는 쉽게 이해할 수 있는 방식으로 정보를 표시하기 위해 PDF 문서에서 자주 사용됩니다. 어떤 경우에는 PDF 문서에서 이미지를 추출해야 할 수도 있습니다. 예를 들어 프레젠테이션이나 다른 문서에서 PDF 보고서의 차트 이미지를 사용하려는 경우입니다. 이 문서에서는 다음 방법을 보여줍니다 C# 및 VB.NET의 PDF에서 이미지 추출 Spire.PDF for .NET사용합니다.
Spire.PDF for .NET 설치
먼저 Spire.PDF for.NET 패키지에 포함된 DLL 파일을 .NET 프로젝트의 참조로 추가해야 합니다. DLL 파일은 이 링크 에서 다운로드하거나 NuGet을 통해 설치할 수 있습니다.
PM> Install-Package Spire.PDF
C# 및 VB.NET의 PDF에서 이미지 추출
다음은 Spire.PDF for .NET를 사용하여 PDF 문서에서 이미지를 추출하는 주요 단계입니다.
- PdfDocument 개체를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 문서를 로드합니다.
- 문서의 모든 페이지를 반복합니다.
- PdfPageBase.ExtractImages() 메서드를 사용하여 각 페이지에서 이미지를 추출하고 지정된 파일 경로에 저장합니다.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
임시 라이센스 신청
생성된 문서에서 평가 메시지를 제거하고 싶거나, 기능 제한을 없애고 싶다면 30일 평가판 라이센스 요청 자신을 위해.
C#/VB.NET: estrae immagini da PDF
Installato tramite NuGet
PM> Install-Package Spire.PDF
Link correlati
Le immagini vengono spesso utilizzate nei documenti PDF per presentare le informazioni in modo facilmente comprensibile. In alcuni casi, potrebbe essere necessario estrarre immagini da documenti PDF. Ad esempio, quando desideri utilizzare un'immagine del grafico da un report PDF in una presentazione o in un altro documento. Questo articolo mostrerà come farlo estrarre immagini da PDF in C# e VB.NET utilizzando Spire.PDF for .NET.
Installa Spire.PDF for .NET
Per cominciare, devi aggiungere i file DLL inclusi nel pacchetto Spire.PDF for.NET come riferimenti nel tuo progetto .NET. I file DLL possono essere scaricati da questo link o installato tramite NuGet.
PM> Install-Package Spire.PDF
Estrai immagini da PDF in C# e VB.NET
Di seguito sono riportati i passaggi principali per estrarre immagini da un documento PDF utilizzando Spire.PDF for .NET:
- Crea un oggetto PdfDocument.
- Carica un documento PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Passa in rassegna tutte le pagine del documento.
- Estrai le immagini da ogni pagina utilizzando il metodo PdfPageBase.ExtractImages() e salvale in un percorso file specificato.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Richiedi una licenza temporanea
Se desideri rimuovere il messaggio di valutazione dai documenti generati o eliminare le limitazioni della funzione, per favore richiedere una licenza di prova di 30 giorni per te.
C#/VB.NET : extraire des images d'un PDF
Table des matières
Installé via NuGet
PM> Install-Package Spire.PDF
Liens connexes
Les images sont souvent utilisées dans les documents PDF pour présenter les informations de manière facilement compréhensible. Dans certains cas, vous devrez peut-être extraire des images de documents PDF. Par exemple, lorsque vous souhaitez utiliser une image graphique d'un rapport PDF dans une présentation ou un autre document. Cet article montrera comment extraire des images d'un PDF en C# et VB.NET en utilisant Spire.PDF for .NET.
Installer Spire.PDF for .NET
Pour commencer, vous devez ajouter les fichiers DLL inclus dans le package Spire.PDF for.NET comme références dans votre projet .NET. Les fichiers DLL peuvent être téléchargés à partir de ce lien ou installés via NuGet.
PM> Install-Package Spire.PDF
Extraire des images d'un PDF en C# et VB.NET
Voici les principales étapes pour extraire des images d'un document PDF à l'aide de Spire.PDF for .NET :
- Créez un objet PdfDocument.
- Chargez un document PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Parcourez toutes les pages du document.
- Extrayez les images de chaque page à l’aide de la méthode PdfPageBase.ExtractImages() et enregistrez-les dans un chemin de fichier spécifié.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Demander une licence temporaire
Si vous souhaitez supprimer le message d'évaluation des documents générés ou vous débarrasser des limitations fonctionnelles, veuillez demander une licence d'essai de 30 jours pour toi.