
Imagina esto: finalmente encuentras el informe de investigación exacto, el contrato comercial o el documento técnico lleno de datos que necesitas, pero está atrapado en un PDF. Cuando intentas copiar y pegar su contenido, te encuentras con un formato desordenado, texto no seleccionable o frustrantes bloqueos de protección de contenido. La pregunta es universal: ¿cómo extraer texto de archivos PDF sin tener que volver a escribir manualmente o usar software costoso?
En esta guía completa, exploraremos las mejores formas de extraer texto de un PDF de forma gratuita (incluidos los PDF escaneados con OCR). Ya seas estudiante, profesional de negocios o desarrollador, encontrarás el método perfecto para extraer texto de un PDF con precisión y eficiencia.
- ¿Por qué extraer texto de un PDF puede ser complicado?
- El truco más simple: copiar y pegar
- Las mejores herramientas gratuitas en línea para extraer texto de un PDF
- Herramientas de escritorio gratuitas de PDF24 Creator para extraer texto de PDF
- Herramienta de desarrollador gratuita para extraer texto de PDF en C#
- Preguntas Frecuentes (FAQ)
¿Por qué extraer texto de un PDF puede ser complicado?
Los PDF almacenan el texto de una manera que prioriza la consistencia visual. Esto significa que el texto puede estar almacenado en bloques fragmentados, en un orden inusual o, peor aún, como parte de una imagen. Hay dos tipos principales de PDF, cada uno con desafíos de extracción únicos:
- PDF digitales: Contienen texto seleccionable, pero los diseños complejos como artículos de varias columnas o tablas pueden confundir las acciones simples de copiar y pegar.
- PDF escaneados: Son esencialmente imágenes de páginas. Para extraer texto de un PDF escaneado, necesitas la tecnología OCR (Reconocimiento Óptico de Caracteres), que analiza la imagen y reconoce las formas de las letras.
Afortunadamente, las herramientas gratuitas a continuación manejan ambos tipos con facilidad.
El truco más simple: copiar y pegar
Si tienes un PDF digital simple y solo necesitas una pequeña sección de texto, no pases por alto lo básico. Es la forma más rápida de obtener texto de un PDF para tareas pequeñas.
- Abre el PDF: Usa un visor estándar como Adobe Acrobat Reader, un navegador web (como Chrome o Edge) o una aplicación de vista previa.
- Selecciona y copia: Resalta el texto que deseas, haz clic derecho y selecciona "Copiar", o usa los atajos de teclado “Ctrl+C” (Windows) o “Comando+C” (Mac).
- Pega: Abre un editor de texto (como el Bloc de notas o TextEdit) o un documento de Word y pega el texto con “Ctrl+V” o “Comando+V”.
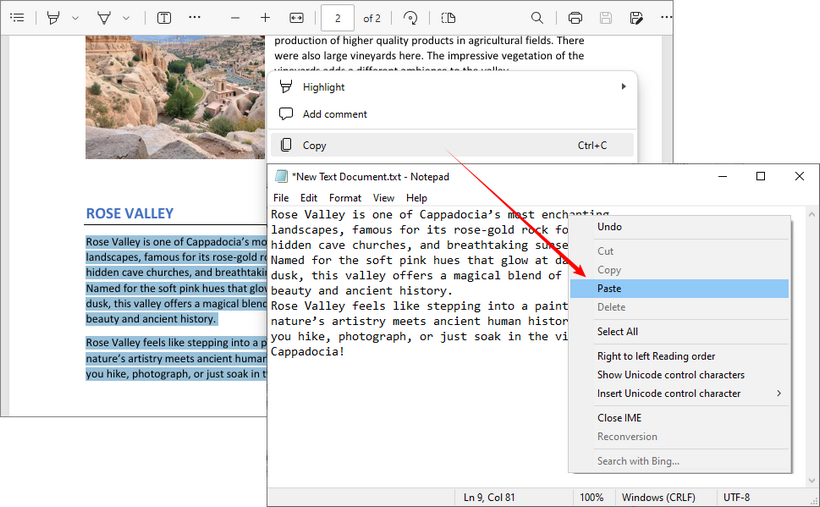
El inconveniente: Este método falla para documentos escaneados, PDF protegidos o cuando necesitas preservar un formato complejo. Para estos casos, utiliza las herramientas gratuitas dedicadas a continuación o consulta nuestra guía sobre cómo copiar texto de un PDF protegido.
Las mejores herramientas gratuitas en línea para extraer texto de un PDF
Para la mayoría de los usuarios, las herramientas gratuitas en línea son la forma más rápida y fácil de extraer texto de un PDF de forma gratuita. Funcionan directamente en tu navegador, no requieren instalación y muchas ahora incluyen potentes funciones de OCR. A continuación se presentan las dos mejores opciones para diferentes casos de uso, desde la extracción de texto básica hasta el OCR multilingüe.
CLOUDXDOCS - La herramienta gratuita más simple para PDF digitales
Si necesitas una herramienta sin adornos y sin publicidad para extraer texto de PDF basados en texto (no escaneados), CLOUDXDOCS es ideal. Es 100% gratuito, no requiere registro y funciona con un solo clic, perfecto para tomar texto de archivos PDF en segundos.
Pasos para extraer texto de un PDF en línea:
- Visita el Convertidor gratuito de PDF a texto de CLOUDXDOCS.
- Sube tu archivo PDF arrastrándolo y soltándolo o haciendo clic para buscar.
- Espera a que la herramienta procese tu archivo.
- Descarga el texto extraído como un archivo TXT.
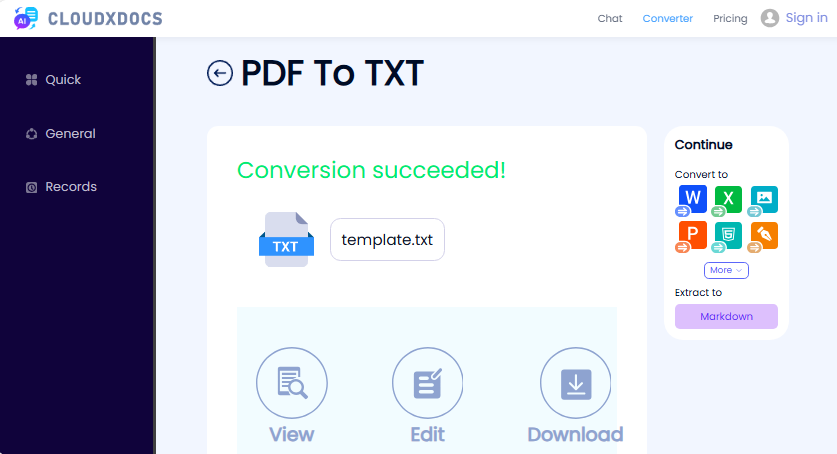
✔ Ventajas: Sin registro, sin anuncios, interfaz simple.
✘ Desventajas: Sin OCR (no funcionará para PDF escaneados).
i2OCR - Herramienta de OCR gratuita para PDF escaneados
i2OCR es una herramienta gratuita en línea que se especializa en OCR para imágenes y PDF escaneados, y admite más de 100 idiomas, lo que es perfecto para PDF que no están en inglés. Es gratuito para el uso de una sola página y ofrece múltiples formatos de salida.
Pasos para extraer texto de un PDF escaneado en línea de forma gratuita:
- Visita la herramienta de OCR para PDF de i2OCR.
- Selecciona tu idioma de reconocimiento y el motor de OCR preferido.
- Haz clic en “Seleccionar PDF” para subir tu PDF escaneado.
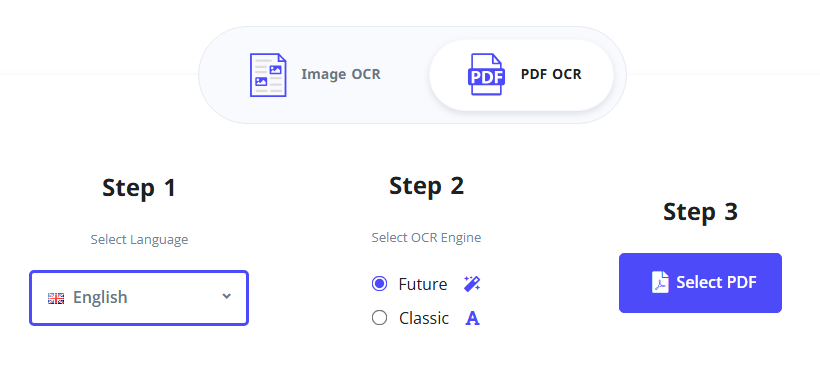
- Haz clic en “Iniciar OCR” y espera a que la herramienta procese el escaneo.
- Copia el texto extraído o descárgalo como TXT, Word o HTML.
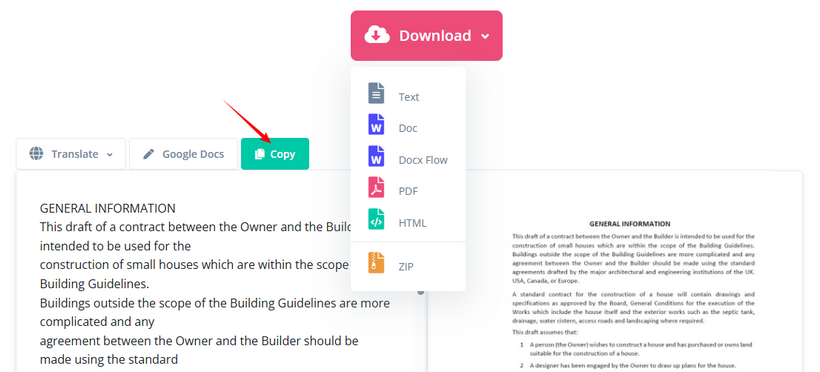
✔ Ventajas: Soporte para más de 100 idiomas, OCR gratuito, múltiples formatos de salida, sin registro.
✘ Desventajas: El plan gratuito solo admite una página a la vez.
Además de texto, los PDF a menudo contienen imágenes, gráficos o diagramas valiosos; descubre cómo extraer imágenes incrustadas en tu documento PDF.
Herramientas de escritorio gratuitas de PDF24 Creator para extraer texto de PDF
Si trabajas con PDF con frecuencia, necesitas acceso sin conexión o tienes archivos masivos para procesar, PDF24 Creator es la opción ideal. Esta herramienta de escritorio gratuita y exclusiva para Windows ofrece capacidades completas de manejo de PDF, incluida la extracción de texto, OCR para PDF escaneados y procesamiento por lotes, todo mientras mantiene tus archivos locales para una máxima privacidad.
Extraer texto de un PDF digital (seleccionable)
- Ve a la página oficial de descarga de PDF24 Creator y descarga la versión adecuada para tu sistema Windows.
- Instala e inicia PDF24. Verás la Caja de herramientas de PDF24 (un panel con muchas herramientas de PDF).
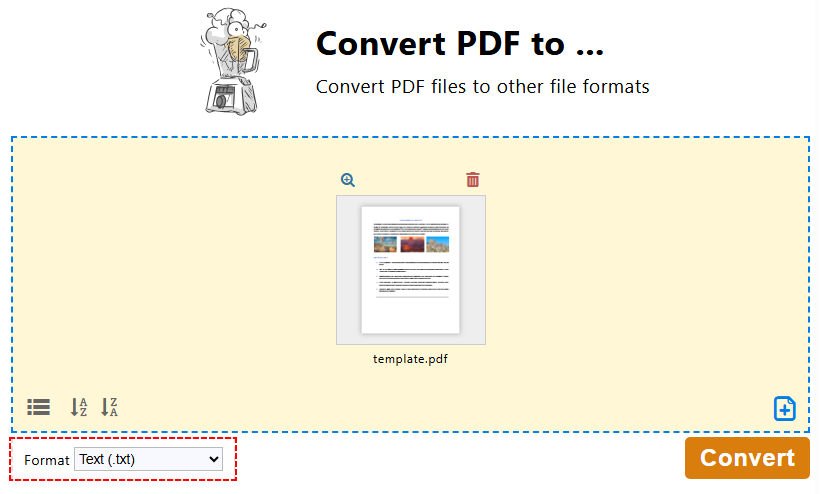
- En la Caja de herramientas de PDF24, haz clic en "Convertir PDF a…".
- Haz clic en "Elegir archivos" o arrastra y suelta para subir tu archivo PDF.
- Elige “Texto (.txt)” como formato de salida y haz clic en "Convertir".
- Guarda el archivo de texto extraído en tu dispositivo.
Extraer texto de un PDF escaneado (usando OCR)
Para PDF escaneados o basados en imágenes, utiliza el OCR integrado de PDF24 para reconocer el texto de los escaneos de PDF y convertirlos en texto editable o PDF con capacidad de búsqueda:
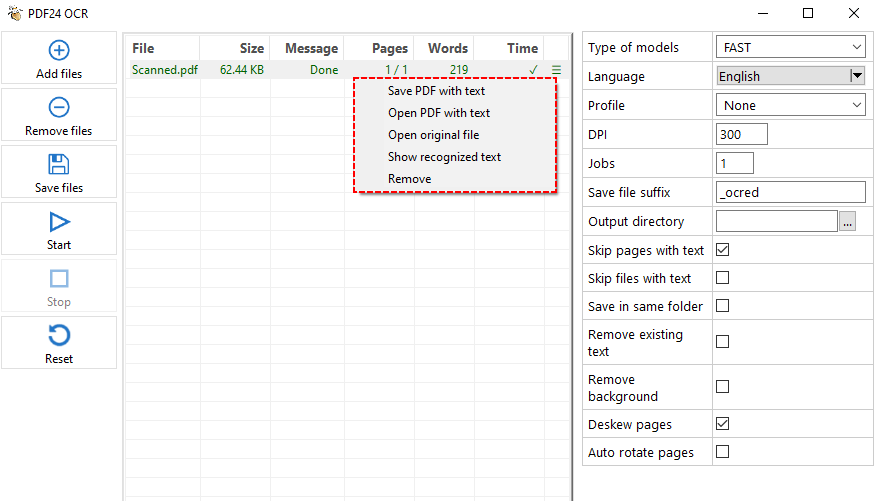
- En la Caja de herramientas de PDF24, haz clic en "PDF OCR".
- Haz clic en "Agregar archivo(s)" y selecciona tu PDF escaneado.
- En el panel de configuración de la derecha, selecciona el modo de reconocimiento de texto, el idioma, los DPI, el directorio de salida, etc.
- Haz clic en el botón "Iniciar" para procesar el PDF.
- PDF24 procesará cada página, reconocerá el texto y lo guardará en un archivo de texto o en un PDF con capacidad de búsqueda.
Consejo profesional para usuarios de Adobe:
Si tienes Adobe Acrobat Pro (de pago), puedes extraer texto yendo a la herramienta “Exportar PDF” y seleccionando “Texto (sin formato)” como formato de salida. Acrobat guardará el archivo como un documento .txt al instante.
Herramienta de desarrollador gratuita para extraer texto de PDF en C#
Si eres desarrollador, Free Spire.PDF for .NET es una biblioteca gratuita y sin dependencias para leer texto de PDF mediante programación. Es rápida, ligera y perfecta para integrar la extracción de texto de PDF en tus proyectos.
Código C# para extraer texto de un PDF
El código itera a través de cada página en un archivo PDF digital y extrae todo el texto del PDF. Las clases y métodos principales de extracción de texto incluyen:
- PdfTextExtractor: Una clase de utilidad especializada que extrae texto de una sola página de PDF (una página a la vez).
- PdfTextExtractOptions: Una clase de configuración para la extracción de texto. Establece reglas como si se debe extraer todo el texto.
- ExtractText(): Ejecuta la extracción de texto en la página del PDF y devuelve la cadena de texto extraída.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Text;
namespace ExtractAllTextFromPDF
{
internal class Program
{
static void Main(string[] args)
{
// Create a PDF document instance
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.LoadFromFile("SamplePDF.pdf");
// Initialize a StringBuilder to hold the extracted text
StringBuilder extractedText = new StringBuilder();
// Loop through each page in the PDF
foreach (PdfPageBase page in pdf.Pages)
{
// Create a PdfTextExtractor for the current page
PdfTextExtractor extractor = new PdfTextExtractor(page);
// Set extraction options
PdfTextExtractOptions option = new PdfTextExtractOptions
{
IsExtractAllText = true
};
// Extract text from the current page
string text = extractor.ExtractText(option);
// Append the extracted text to the StringBuilder
extractedText.AppendLine(text);
}
// Save the extracted text to a text file
File.WriteAllText("ExtractedText.txt", extractedText.ToString());
// Close the PDF document
pdf.Close();
}
}
}
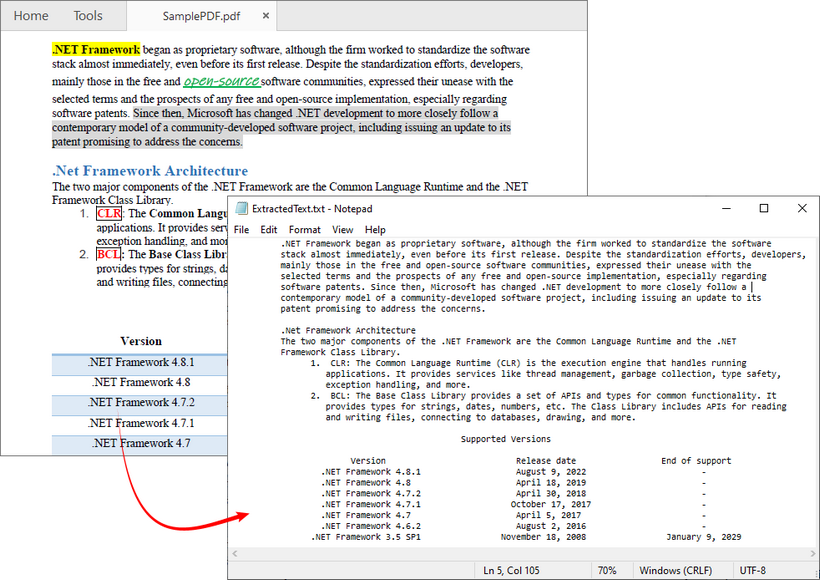
Además de extraer todo el texto, Free Spire.PDF también te permite extraer texto de una sola página o de un área específica. El resultado de la extracción se muestra a continuación:
Consejo profesional: Para extraer texto de un PDF escaneado en C#, sigue la guía oficial: Realizar OCR en PDF escaneados en C# para la extracción de texto
Preguntas Frecuentes (FAQ)
P1: ¿Cómo puedo extraer texto de un PDF escaneado de forma gratuita?
R: Herramientas como i2OCR y PDF24 ofrecen opciones de OCR gratuitas. Simplemente sube tu PDF escaneado y activa la configuración de OCR antes de extraer.
P2: ¿Las herramientas gratuitas admiten la extracción masiva de texto?
R: Sí, pero el método importa. La mayoría de las herramientas gratuitas en línea tienen límites masivos, pero puedes usar una herramienta de escritorio sin conexión como PDF24 Creator o una solución programática para procesar múltiples PDF en lote.
P3: ¿Cuál es la mejor manera de extraer tablas de un PDF?
R: Extraer tablas a texto sin formato es notoriamente difícil, ya que se pierde la estructura tabular. Tu mejor opción es usar una herramienta que pueda convertir el PDF a Excel (XLSX) o CSV. Esto intentará colocar los datos en celdas, preservando la estructura.
P4: ¿Cómo extraigo texto de un PDF y mantengo el formato?
R: El texto sin formato (.txt) no puede preservar el formato como negrita, cursiva o tamaños de fuente. Para mantener el formato, debes convertir tu PDF a un documento de Word (.docx).
Resumen
Este artículo presenta varias formas confiables de extraer texto de un PDF de forma gratuita, independientemente de tu nivel de habilidad técnica o la complejidad del documento.
Para una tarea rápida y única, una herramienta en línea confiable como CLOUDXDOCS es tu mejor opción. Para trabajos recurrentes o información sensible, recurre a un software sin conexión como PDF24. Y si buscas construir una canalización de contenido automatizada y de vanguardia, explorar una solución de código como Free Spire.PDF puede revolucionar tu flujo de trabajo.
Con esta guía, ahora estás equipado para desbloquear el texto oculto en cualquier PDF y ponerlo a trabajar para ti.
Ver También
- Convertir tablas de PDF a CSV: Manual, en línea y automatizado
- Cómo desproteger un PDF (con o sin contraseña)
- Cómo extraer páginas de un PDF de forma gratuita — No se necesita Adobe
- Extraer texto de un PDF en Python: una guía completa con ejemplos de código prácticos
- PDF a texto en Java: extraer texto de PDF (basados en texto y escaneados)