
Knowledgebase (2370)
Children categories
How to Download / Export Excel Files in JavaScript & React
2026-05-28 02:21:57 Written by Allen Yang
Modern web applications often need to generate downloadable Excel reports directly in the browser without relying on backend services. Whether you're building dashboards, reporting tools, or data-heavy business applications, browser-based spreadsheet export has become a common frontend requirement.
The challenge lies in creating Excel files that work across different browsers while maintaining formatting, supporting multiple output formats, and ensuring fast downloads—all without sending sensitive data to a server. Traditional approaches often require complex server-side processing or rely on limited client-side libraries.
Spire.XLS for JavaScript enables developers to generate, export, and download Excel files using JS entirely in the browser using WebAssembly technology. This approach provides true client-side Excel generation with support for multiple formats including XLS, XLSX, XLSB, ODS, PDF, XML, and XPS.
This article demonstrates how to generate and download Excel files in modern JavaScript and React applications using browser-side processing with Spire.XLS for JavaScript. We'll cover basic file generation, stream-based exports, React integration, and HTML table conversion with practical code examples.
Quick Navigation
- Why Export Excel in Browser
- Install Spire.XLS for JavaScript
- Download Excel File in JavaScript
- Export HTML Table to Excel
- React JS Export Excel Example
- About Client-Side Excel Export
- Troubleshooting
- Conclusion
- FAQ
Why Export Excel in Browser
Browser-side Excel export provides significant advantages over traditional server-side approaches:
- Enhanced Privacy – Sensitive data never leaves the client device, reducing security risks and compliance concerns
- Faster Downloads – Eliminating server round-trips reduces latency and improves user experience
- No Server-Side Processing – Reduces backend infrastructure costs and eliminates server bottlenecks
- Works Offline – Client-side generation functions even without network connectivity
- Scalable Architecture – Each user's browser handles their own export, distributing computational load
- Framework Agnostic – Works seamlessly with React, Vue, Angular, and vanilla JavaScript applications
By implementing Excel export functionality in the browser, developers can create responsive, secure, and cost-effective solutions that scale naturally with user demand.
Install Spire.XLS for JavaScript
Before generating and downloading Excel files in JavaScript, you need to install Spire.XLS for JavaScript and configure it in your development environment.
Installation via npm
Spire.XLS for JavaScript can be installed via npm:
npm i spire.xls
After installation, include the library in your project:
import { Workbook } from '@e-iceblue/spire.xls';
Note: The current WebAssembly runtime is provided through the spire.office package structure internally, even when installing spire.xls from npm. This is why initialization imports reference /node_modules/spire.office/.
Manual Installation
Alternatively, you can download the package from the e-iceblue website and copy the dependencies to your project directory.
For detailed setup instructions, refer to the Getting Started with Spire.XLS for JavaScript.
Initialize the WASM Module
Before using Spire.XLS, you must initialize the WebAssembly module. The initialization process loads required resources and sets up the runtime:
// Import and initialize the common module first
import('/node_modules/spire.office/spire.common.js').then(async (commonModule) => {
// Initialize the WASM runtime
await commonModule.initializeWasm();
// Load the XLS module
await import('/node_modules/spire.office/spire.xls.js');
console.log('Spire.XLS ready');
});
Important Notes:
- Initialization is required before accessing
window.spirexlsorwindow.xlswasm - The browser downloads required WebAssembly resources during first load
- Always verify the module exists before performing Excel operations
Version Note: This article uses spire.office v11.4.1+. The module is accessed via window.spirexls or window.xlswasm. Older examples using window.wasmModule.spirexls may require updates.
Spire.XLS for JavaScript integrates seamlessly with all major frontend frameworks and build tools:
- React – Use with hooks (
useState,useEffect) for state-driven Excel export components - Vue.js – Integrate with Vue's reactive data system and lifecycle methods
- Angular – Compatible with Angular services and dependency injection patterns
- Next.js – Works in client-side components for server-rendered React applications
The WebAssembly module loads once at application initialization and can be shared across components, making it efficient for multi-page applications regardless of the framework choice.
Download Excel File in JavaScript
The following example demonstrates how to generate an Excel file with Spire.XLS for JavaScript and download it directly in the browser.
Create and Download an XLSX File
// Ensure the WASM module has been initialized
if (!window.spirexls && !window.xlswasm) {
console.error("Spire.XLS is not initialized.");
return;
}
// Get the initialized WebAssembly module
const wasmModule = window.spirexls || window.xlswasm;
// Create a new workbook
const workbook = new wasmModule.Workbook();
const worksheet = workbook.Worksheets.get(0);
// Create sample data
const products = [
["Product", "Quantity", "Price"],
["Laptop", 10, 999.99]
["Mouse", 50, 24.99]
]
// Insert data into the worksheet
for (let i = 0; i < products.length; i++) {
for (let j = 0; j < products[i].length; j++) {
if (typeof products[i][j] === "string") {
worksheet.Range.get({ row: i + 1, column: j + 1 }).Text = products[i][j];
}
else {
worksheet.Range.get({ row: i + 1, column: j + 1 }).NumberValue = products[i][j];
}
}
}
// Add a total column
worksheet.Range.get({ row: 1, column: products[0].length + 1 }).Text = "Total";
worksheet.Range.get({ row: 2, column: products[0].length + 1 }).Formula = "=B2*C2";
worksheet.Range.get({ row: 3, column: products[0].length + 1 }).Formula = "=B3*C3";
// Save the workbook to the virtual file system (VFS)
const outputFileName = "Report.xlsx";
workbook.SaveToFile({
fileName: outputFileName,
version: wasmModule.ExcelVersion.Version2016
});
// Release workbook resources
workbook.Dispose();
// Read the generated file from VFS
const fileArray =
window.dotnetRuntime.Module.FS.readFile(outputFileName);
// Create a Blob object
const excelBlob = new Blob(
[fileArray],
{
type: "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
}
);
// Trigger browser download
const url = URL.createObjectURL(excelBlob);
const a = document.createElement("a");
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
Below is a preview of the generated XLSX file:
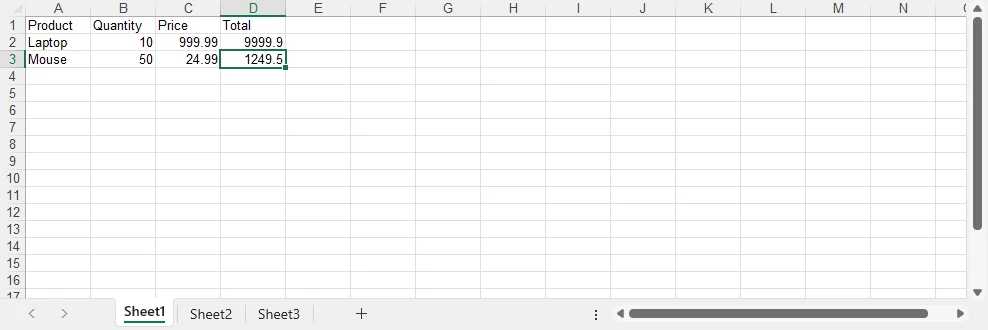
How the Export Process Works
- Create a workbook and populate worksheet data
- Save the workbook into the WebAssembly virtual file system (VFS)
- Read the generated XLSX file from VFS
- Convert the file data into a Blob object
- Trigger the browser download using a temporary URL
About the Virtual File System (VFS)
The file generated by SaveToFile() is stored in the WebAssembly virtual file system rather than the user's physical disk. This in-memory file system allows Spire.XLS to perform standard file operations securely inside the browser environment. The downloaded XLSX file is created after reading the generated file data from VFS and converting it into a browser Blob object.
Advantages of This Approach
- Works entirely in the browser
- No server-side processing required
- Uses standard browser Blob download APIs
- Supports direct XLSX file generation with Spire.XLS
If you also need to work with lightweight data exchange formats, you can further explore how to convert Excel files to CSV and import CSV data into Excel using JavaScript.
Export HTML Tables to Excel in JavaScript
In dashboard and reporting applications, business data is often displayed as HTML tables. Instead of rebuilding spreadsheet structures manually, you can directly convert existing frontend tables into Excel workbooks using Spire.XLS for JavaScript.
The following example demonstrates a complete browser-side workflow that:
- Reads an existing HTML table from the page
- Converts the HTML table into an Excel workbook
- Applies Excel-native formatting
- Downloads the generated XLSX file directly in the browser
HTML Table Export Example
async function exportTableToExcel() {
if (!window.spirexls && !window.xlswasm) {
alert("Spire.XLS module not loaded yet.");
return;
}
const button = document.getElementById("exportBtn");
button.disabled = true;
button.innerText = "Exporting...";
const wasmModule = window.spirexls || window.xlswasm;
try {
// Get HTML table
const tableHtml =
document.getElementById("salesTable").outerHTML;
// Remove inline styles
const safeTableHtml =
tableHtml.replace(/style="[^"]*"/g, '');
const htmlContent = `
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
${safeTableHtml}
</body>
</html>
`;
const htmlFileName = "Table.html";
window.dotnetRuntime.Module.FS.writeFile(
htmlFileName,
htmlContent
);
const workbook = new wasmModule.Workbook();
workbook.LoadFromHtml(htmlFileName);
const sheet = workbook.Worksheets.get(0);
const lastRow = Number(sheet.LastRow);
const lastCol = Number(sheet.LastColumn);
const headerRow =
sheet.Range.get_Item(1, 1, 1, lastCol);
headerRow.BuiltInStyle =
wasmModule.BuiltInStyles.Heading3;
for (let i = 2; i <= lastRow; i++) {
const row =
sheet.Range.get_Item(i, 1, i, lastCol);
row.BuiltInStyle =
i % 2 === 0
? wasmModule.BuiltInStyles.Accent3_20
: wasmModule.BuiltInStyles.Accent3_60;
}
for (let j = 1; j <= lastCol; j++) {
sheet.AutoFitColumn(j);
}
const outputFileName = "SalesReport.xlsx";
workbook.SaveToFile({
fileName: outputFileName,
version: wasmModule.ExcelVersion.Version2016
});
workbook.Dispose();
const fileData =
window.dotnetRuntime.Module.FS.readFile(outputFileName);
const blob = new Blob([fileData], {
type:
"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
});
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
} catch (error) {
alert("Export failed: " + error.message);
} finally {
button.disabled = false;
button.innerText = "Export Excel";
}
}
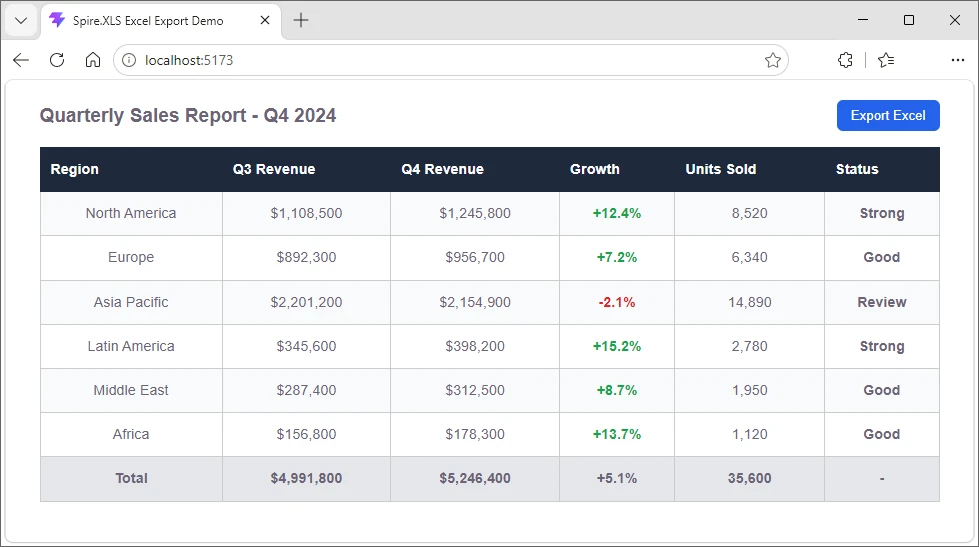
The following screenshot shows the HTML-based sales report table example displayed in the browser before export.
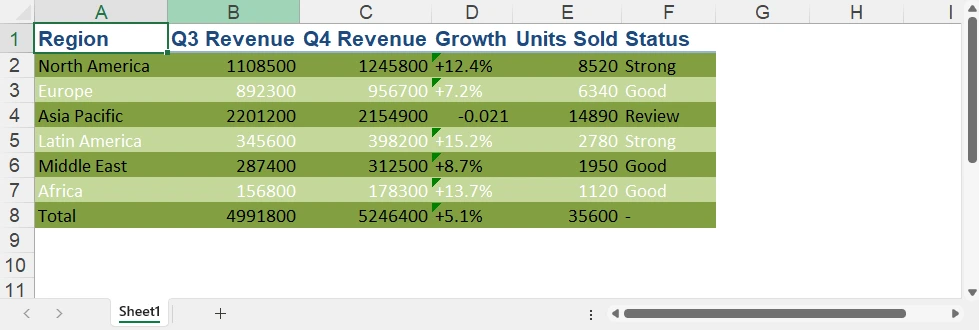
After exporting, the generated Excel workbook preserves the tabular structure and applies additional Excel-native formatting.
Why Use HTML-based Excel Export
Using HTML-based export provides several advantages for modern web applications:
- Reuse existing frontend tables without rebuilding spreadsheet layouts
- Reduce duplicate data formatting and export logic
- Apply Excel-native styles after importing HTML tables
- Export business reports directly from dashboard pages
With Spire.XLS for JavaScript, you can quickly convert browser-rendered HTML tables into downloadable Excel files while keeping the entire export workflow on the client side.
For scenarios that require rendering Excel spreadsheets as browser-based HTML tables, you can also refer to our article about converting Excel to HTML in JavaScript.
Export Excel in React with JavaScript
Integrating Excel export into React applications is straightforward. The key is initializing the WebAssembly runtime before rendering React components and properly releasing workbook resources after export operations.
Initialize Spire.XLS in React
Before creating export components, initialize the WebAssembly module in your app entry file (main.jsx or index.js):
import { StrictMode } from 'react';
import { createRoot } from 'react-dom/client';
import App from './App.jsx';
// Initialize Spire.XLS before mounting React
const initializeSpire = async () => {
// Load the common runtime
const commonModule = await import(
'/node_modules/spire.office/spire.common.js'
);
// Initialize WebAssembly runtime
await commonModule.initializeWasm();
// Load Spire.XLS module
await import(
'/node_modules/spire.office/spire.xls.js'
);
// Optional: preload fonts if needed
// await window.spire.FetchFileToVFS(
// 'ARIAL.TTF',
// '/Library/Fonts/',
// '/'
// );
};
// Start React app after initialization
initializeSpire().then(() => {
createRoot(document.getElementById('root')).render(
<StrictMode>
<App />
</StrictMode>
);
});
Then use the React export component below in your application.
Simplified React Excel Export Component
Here's a minimal React component that demonstrates the core export pattern:
import { useState } from 'react'
const ExcelExportButton = () => {
const [isProcessing, setIsProcessing] = useState(false);
const handleExport = async () => {
if ((!window.spirexls && !window.xlswasm) || isProcessing) return;
setIsProcessing(true);
const wasmModule = window.spirexls || window.xlswasm;
try {
// Create a new workbook and get the first default worksheet
const workbook = new wasmModule.Workbook();
const worksheet = workbook.Worksheets.get(0);
// Insert data into the worksheet
worksheet.Range.get("A1").Text = "Product";
worksheet.Range.get("B1").Text = "Revenue";
worksheet.Range.get("A2").Text = "Laptop";
worksheet.Range.get("B2").NumberValue = 9999.90;
worksheet.Range.get("A3").Text = "Smartphone";
worksheet.Range.get("B3").NumberValue = 4999.99;
const outputFileName = "Report.xlsx";
// Save the workbook to a file in the VFS
workbook.SaveToFile({
fileName: outputFileName,
version: wasmModule.ExcelVersion.Version2016
});
workbook.Dispose();
const fileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const excelBlob = new Blob([fileArray], {
type: "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
});
const url = URL.createObjectURL(excelBlob);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
} catch (error) {
console.error("Excel export failed:", error);
} finally {
setIsProcessing(false);
}
};
return (
<button onClick={handleExport} disabled={isProcessing}>
{isProcessing ? "Generating..." : "Export to Excel"}
</button>
);
}
export default function App() {
return (
<div>
<h1>Spire.XLS Demo</h1>
<ExcelExportButton />
</div>
);
}
Key Implementation Details:
- Minimal state – Only track
isProcessingto disable the button during export - Direct download – Trigger download immediately without storing URLs in state
- Resource cleanup – Always call
Dispose()on workbook objects to prevent memory leaks - Error handling – Wrap export logic in try-catch blocks for robust error management
- Loading states – Disable buttons during processing to prevent duplicate exports
Usage in Your App:
import { ExcelExportButton } from './ExcelExportButton';
function App() {
return (
<div>
<h1>Sales Dashboard</h1>
<ExcelExportButton />
</div>
);
}
This simplified approach focuses on the essential export flow without unnecessary complexity. For more advanced scenarios like loading external files or fonts, refer to the complete documentation.
If you also need browser-side document distribution workflows, you can further explore how to convert Excel files to PDF in JavaScript and React applications.
Client-Side Excel Generation in JavaScript Without Backend
Modern web applications increasingly generate Excel files directly in the browser instead of relying on backend services. With Spire.XLS for JavaScript, spreadsheet creation, formatting, and export operations run entirely on the client side using WebAssembly.
Why No Backend Server Is Needed
Traditional Excel export workflows usually require a server to:
- Receive frontend data
- Generate spreadsheet files
- Return downloadable files to the browser
With WebAssembly-based processing, these steps happen entirely inside the browser runtime instead.
Benefits of Browser-side Excel Export
Compared with traditional server-side export workflows, client-side Excel generation provides several advantages:
| Feature | Browser-side Export | Server-side Export |
|---|---|---|
| Data Processing | Runs locally in browser | Requires backend server |
| Privacy | Data stays on client device | Data sent over network |
| Response Speed | Instant local processing | Depends on network latency |
| Infrastructure Cost | No export server required | Requires backend resources |
| Offline Support | Supported | Usually unavailable |
| Scalability | Handled by client devices | Limited by server capacity |
How Browser-side Export Works
When using Spire.XLS for JavaScript:
- The WebAssembly runtime loads in the browser
- Spreadsheet processing runs locally in memory
- Files are temporarily stored in the browser virtual file system (VFS)
- JavaScript converts the generated file into a downloadable Blob
- The browser triggers the download directly
This architecture makes browser-based Excel export especially suitable for dashboards, reporting systems, internal business tools, and privacy-sensitive applications.
Troubleshooting and Best Practices
When using Spire.XLS for JavaScript in browser environments, the following issues are commonly encountered.
WASM Module Not Initialized
If window.spirexls or window.xlswasm is undefined, ensure the WebAssembly runtime is fully initialized before using the API:
await commonModule.initializeWasm();
await import('/node_modules/spire.office/spire.xls.js');
Missing Resource or ZIP Loading Errors
If the browser console shows 404 errors or WebAssembly loading failures:
- Ensure ZIP and WASM resources are placed in the correct static directory
- Vite projects should place assets in the
public/folder - Verify the browser can successfully load
.zipand.wasmfiles
Font-related Warnings
Some environments may display warnings such as:
"Arial font is not installed"
You can preload fonts before creating workbooks:
await window.spire.FetchFileToVFS(
'ARIAL.TTF',
'/Library/Fonts/',
'/'
);
Invalid or Corrupted XLSX Files
If Excel opens with repair warnings, explicitly specify the Excel version during export:
workbook.SaveToFile({
fileName: outputFileName,
version: wasmModule.ExcelVersion.Version2016
});
Memory Management
Always release workbook resources after export to avoid memory leaks in long-running applications:
const workbook = new wasmModule.Workbook();
try {
// Excel operations
} finally {
workbook.Dispose();
}
Browser-side Performance Considerations
For very large datasets, browser-side processing may become slow or memory-intensive. In such scenarios:
- Show loading indicators during export
- Avoid exporting extremely large datasets in a single operation
- Consider server-side processing for enterprise-scale reports
Conclusion
Spire.XLS for JavaScript provides a practical way to generate and export Excel files directly in modern web applications using JavaScript and WebAssembly. Its browser-based architecture makes it suitable for dashboards, reporting systems, and frontend applications that require downloadable spreadsheet generation without relying on backend services.
The examples in this article demonstrate how to build browser-based Excel export workflows using JavaScript, React, and WebAssembly while keeping spreadsheet processing entirely on the client side. You can apply for a 30-day free license to evaluate all features before purchasing.
FAQ
Q1: Can I download Excel files in JavaScript without a backend server?
A1: Yes. Spire.XLS for JavaScript uses WebAssembly technology to generate and download Excel files entirely in the browser. The workbook is created in browser memory and downloaded directly without requiring any backend API or server-side processing.
Q2: How do I export HTML tables to Excel in JavaScript?
A2: You can extract an existing HTML table from the DOM, write the HTML into the WebAssembly virtual file system, and load it into a workbook using LoadFromHtml(). This approach allows you to reuse browser-rendered tables without rebuilding spreadsheet layouts manually.
Q3: Can I use Spire.XLS for JavaScript in React applications?
A3: Yes. Spire.XLS for JavaScript works with React, Vite, and other modern frontend frameworks. You only need to initialize the WebAssembly module before rendering components and then perform Excel operations directly inside React components or utility functions.
Q4: Why does Excel show a repair warning when opening exported files?
A4: This usually happens when the Excel version is not explicitly specified during export. To avoid compatibility issues, specify the output version when calling SaveToFile():
workbook.SaveToFile({
fileName: outputFileName,
version: wasmModule.ExcelVersion.Version2016
});

CSV (Comma-Separated Values) and XML (eXtensible Markup Language) are two mainstream data exchange formats in modern software development. CSV excels at lightweight storage and transmission of tabular data, while XML is widely used for cross-system data interaction due to its hierarchical structure and strict validation rules. Converting CSV to XML is a common demand in scenarios such as configuration file generation, database record export, and third-party API integration.
Manual CSV parsing and XML generation are error-prone, inefficient, and difficult to maintain for large datasets. For C# developers, Spire.XLS for .NET provides a lightweight, high-performance solution for CSV-to-XML conversion.
This article will guide you through two core methods to convert CSV to XML in C# using Spire.XLS, covering basic conversion and customized XML output with complete code examples.
- Understanding the Two XML Output Types
- Method 1: Convert CSV to Excel XML in C#
- Method 2: Convert CSV to Custom XML in C#
- Handling Real World CSV Scenarios
- FAQs About CSV to XML Conversion
Prerequisites
Install Spire.XLS via NuGet
The quickest way to add Spire.XLS to your project is through the NuGet Package Manager. In Visual Studio, run the following command in the Package Manager Console:
Install-Package Spire.XLS
Alternatively, search for “Spire.XLS” in the NuGet UI and install the latest version.
Prepare a Sample CSV Data (For Testing)
Create a Products.csv file in your project’s output folder with this sample tabular data (includes headers and rows):
ID,ProductName,Category,Price,StockQuantity,ReleaseDate
1,Laptop,Electronics,999.99,50,2023-01-15
2,Wireless Mouse,Electronics,25.50,200,2023-02-20
3,Cotton T-Shirt,Apparel,19.99,150,2022-11-05
4,Coffee Mug,Home Goods,12.99,300,2022-09-10
5,Desk Chair,Furniture,150.00,75,2023-03-01
Understanding the Two XML Output Types
When converting CSV file to XML using Spire.XLS for .NET, you can produce two distinct types of XML output:
1. Excel XML (SpreadsheetML)
A standardized XML format based on Microsoft's Open XML specification. It retains the original table layout, cell formatting and overall structure of the CSV file. This is an ideal choice if you need to open, edit or process the generated XML with Excel and other spreadsheet-compatible tools.
2. Custom XML Structure
A user-defined XML schema enables free mapping of CSV columns to custom element tags, nested hierarchies, and adjustable presentation rules. This is ideal for integrating with third-party APIs, legacy systems, and business platforms that require specific fixed XML node structures.
Both approaches are covered in detail with C# code examples in the following sections. For developers working in Python, refer to our separate guide: Convert CSV to XML in Python
Method 1: Convert CSV to Excel XML in C#
This is the simplest approach that requires only a few lines of code. The CSV is loaded into a Workbook, then saved directly as Excel XML (SpreadsheetML) format. Suitable for cases where the target system accepts Excel's native XML format.
CSV to XML C# Code Example:
using Spire.Xls;
namespace CsvToExcelXmlConverter
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook instance
Workbook workbook = new Workbook();
// Load CSV into the first worksheet
workbook.LoadFromFile("Products.csv", ",", 1, 1);
// Save as Excel SpreadsheetML format
workbook.SaveAsXml("output.xml");
// Clean up resources
workbook.Dispose();
}
}
}
Core Methods:
- LoadFromFile() – Spire.XLS automatically parses the CSV content into the first worksheet of the workbook.
- SaveAsXml() – Export the loaded CSV data as an Excel XML file.
The core data parts looks like:
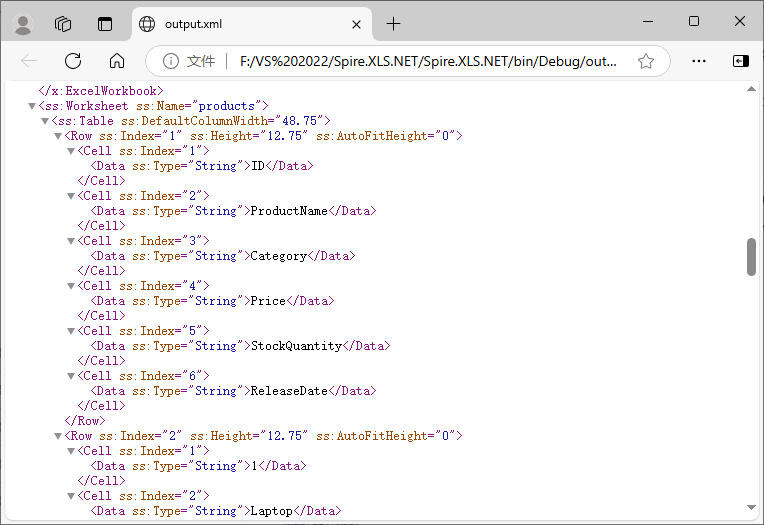
Beyond converting CSV files, Spire.XLS for .NET also enables seamless conversion of Excel (XLS / XLSX) to XML using the same robust Workbook.SaveAsXml() method.
Method 2: Convert CSV to Custom XML in C#
When the target system expects a specific XML schema, you’ll need to build a custom XML document. Spire.XLS, together with the built-in .NET XmlWriter class, makes this straightforward: simply iterate over worksheet rows and columns, then generate well-structured XML efficiently.
Custom XML Code Example:
using Spire.Xls;
using System.Xml;
namespace CSVtoXMLConverter
{
class program
{
static void Main(string[] args)
{
// Initialize workbook and load CSV
Workbook workbook = new Workbook();
workbook.LoadFromFile("Products.csv", ",", 1, 1);
Worksheet worksheet = workbook.Worksheets[0];
// Create custom XML settings (indentation for readability)
XmlWriterSettings settings = new XmlWriterSettings
{
Indent = true,
IndentChars = "\t",
OmitXmlDeclaration = false,
Encoding = System.Text.Encoding.UTF8
};
// Save CSV to XML with CUSTOM ROOT NODE and FORMATTING
XmlWriter writer = XmlWriter.Create("Custom_Output.xml", settings);
writer.WriteStartDocument();
// Custom root element: <ProductInventory>
writer.WriteStartElement("ProductInventory");
// Loop through CSV rows (skip header row: start at 2)
for (int row = 2; row <= worksheet.LastRow; row++)
{
// Custom data node: <Product>
writer.WriteStartElement("Product");
// Loop through CSV columns and write custom elements
for (int col = 1; col <= worksheet.LastColumn; col++)
{
string header = worksheet.Range[1, col].Text;
string value = worksheet.Range[row, col].Text;
writer.WriteElementString(header, value);
}
writer.WriteEndElement(); // Close <Product>
}
writer.WriteEndElement(); // Close <ProductInventory>
writer.WriteEndDocument();
writer.Close();
workbook.Dispose();
}
}
}
How the code works:
- Load the CSV file into a Workbook.
- Access the worksheet – Retrieve the first worksheet containing the imported data.
- Create an XmlWriter – Configure it with indentation, encoding, and other formatting preferences.
- Write the XML document – Start the document, write the custom root element, then loop through rows (skipping the header row) and columns, writing an element per column using the header text as the tag name.
- Close resources – Close the XmlWriter and dispose of the Workbook.
Output:
The generated XML uses <ProductInventory> as the root node and <Product> as the data node, with child nodes named after CSV headers, fully matching custom business requirements.
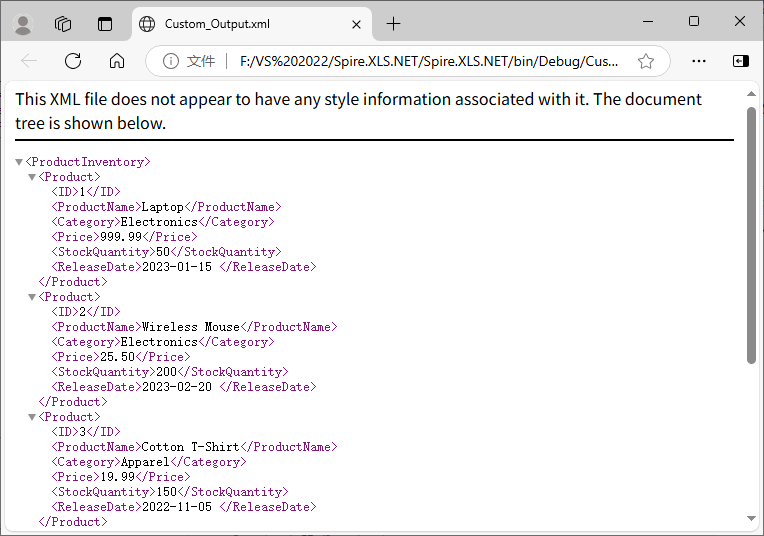
Bonus Tip: For scenarios requiring formal document delivery, you can also use Spire.XLS for .NET to convert XML files to PDF in C# effortlessly.
Handling Real‑World CSV Scenarios
Real-world CSV files often have non-standard delimiters, empty values, redundant rows/columns, or missing headers. The following solutions solve these common problems:
Different Delimiters
CSV files may use tabs (\t), semicolons (;), or pipes (|). Spire.XLS supports specifying custom delimiters when loading CSV files:
// Tab-separated
workbook.LoadFromFile("data.tsv", "\t", 1, 1);
// Semicolon-separated (common in European locales)
workbook.LoadFromFile("data.csv", ";", 1, 1);
// Pipe-separated
workbook.LoadFromFile("data.psv", "|", 1, 1);
Skipping Rows and Columns
If the CSV contains metadata rows or empty columns, adjust your loop bounds:
// start from row 3
for (int row = 3; row <= worksheet.LastRow; row++)
//start from column 3
for (int col = 3; col <= worksheet.LastColumn; col++)
Handling Missing Values and Empty Cells
Empty cells in CSV files appear as empty strings. You can handle them by writing a default value or omitting the elements:
// Option 1: Fill empty values with "N/A"
string value = worksheet.Range[row, col].Text;
if (string.IsNullOrEmpty(value))
value = "N/A";
writer.WriteElementString(header, value);
// Option 2: Omit empty nodes
string value = worksheet.Range[row, col].Text;
if (!string.IsNullOrEmpty(value))
writer.WriteElementString(header, value);
Missing Header Row
If your CSV has no header row, you can pass an array of custom names, or generate generic column names such as:
for (int col = 1; col <= worksheet.LastColumn; col++)
{
string header = $"Column{col}";
string value = worksheet.Range[row, col].Text;
writer.WriteElementString(header, value);
}
Conclusion
Converting CSV to XML in C# with Spire.XLS for .NET eliminates manual parsing and reduces code complexity. Whether you need a simple one-line conversion to Excel XML or a fully customized XML structure, the code examples in this guide let you seamlessly integrate CSV-to-XML conversion into your C# applications.
For more Excel or CSV-related tasks in .NET development, visit the online documentation.
FAQs About CSV to XML Conversion
Q1: Can I convert only a specific range of cells (e.g., A1:C10)?
Yes. Instead of looping to worksheet.LastRow and LastColumn, set custom bounds (e.g., loop rows 2 to 11 for A1:C10) or directly access a range via worksheet.Range.
Q2: Does Spire.XLS require Microsoft Excel to be installed?
No, it is an independent .NET component and does not rely on Microsoft Excel, Office interop, or any third-party Office software.
Q3: Can I batch convert multiple CSV files to XML at once?
Yes. You can loop through all CSV files in a folder, load each one with Spire.XLS, and export them to corresponding XML files in batches with the same logic in the tutorial.
Q4: Can I add custom attributes and namespaces to generated XML elements?
Absolutely. Use XmlWriter.WriteAttributeString() to add custom attributes to nodes, and WriteStartElement with namespace parameters to define XML namespaces for enterprise-standard XML schemas.

Downloading PDF files from URLs programmatically is essential for developers building document processing systems, web scrapers, content aggregators, or automated report generators. Automating PDF download and processing improves workflow efficiency, allowing developers to extract information, archive documents, or perform analysis without manual intervention.
In this guide, we demonstrate how to download PDFs from URLs using Python with Spire.PDF, process them entirely in memory, handle network errors, manage large files, and troubleshoot common issues.
Quick Navigation:
- Why Use Spire.PDF for Python
- Install Required Libraries
- Download PDF from URL
- Processing PDFs Without Saving
- Handling Large PDFs
- Adding Retry Logic
- Common Issues and Troubleshooting
- Conclusion
- FAQs
1. Why Use Spire.PDF for Python
Spire.PDF for Python enables loading PDFs directly from memory, without needing a disk path. This makes in-memory processing fast and avoids unnecessary disk I/O.
Key capabilities include:
- Load PDFs from bytes or Stream objects
- Extract text, images, and metadata
- Modify PDFs and convert to other formats
- Efficiently handle large files in memory
These capabilities are particularly useful in web scraping pipelines, document archiving systems, automated report generation, and content extraction workflows, where performance and memory efficiency are important.
2. Install Required Libraries
Install Spire.PDF and requests via pip:
pip install spire.pdf requests
Import the necessary modules:
from spire.pdf import *
import requests
3. Download PDF from URL
Here’s a complete example showing how to download a PDF from a URL, process it in memory, and save it to disk. Each line includes explanations for clarity.
import requests
from spire.pdf import *
def download_pdf_from_url():
# Specify the PDF URL
url = "resource/sample.pdf"
# Send HTTP GET request to download the PDF
response = requests.get(url)
# Raise an error if the request failed (4xx or 5xx)
response.raise_for_status()
# Create a Stream object from the downloaded bytes
stream = Stream(response.content)
# Load PDF from Stream
document = PdfDocument(stream)
# Save PDF to local file
document.SaveToFile("Downloaded.pdf")
document.Close()
print("PDF downloaded and saved successfully!")
if __name__ == "__main__":
download_pdf_from_url()
Output:
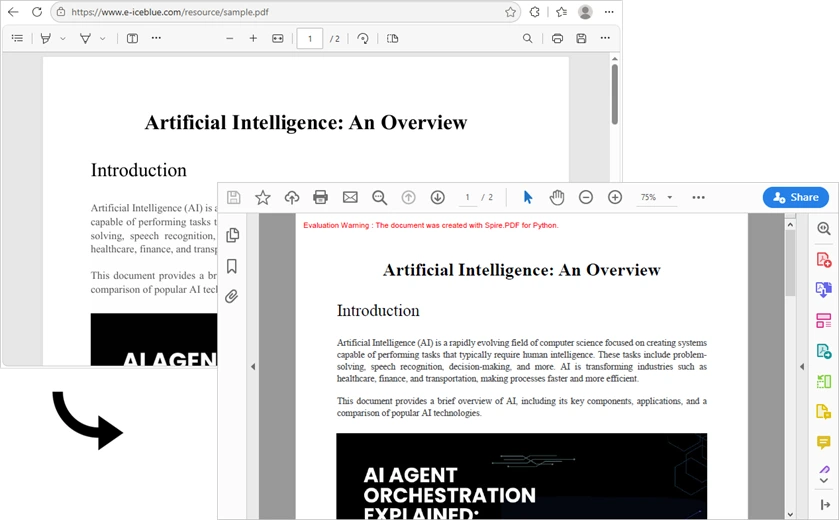
Explanation of key components:
requests.get(url)– Sends the HTTP GET request. The server responds with headers and the PDF binary.response.raise_for_status()– Checks for HTTP errors (e.g., 404, 500).response.content– Contains raw PDF bytes.Stream(response.content)– Wraps bytes in a readable, seekable in-memory stream.PdfDocument(stream)– Loads the PDF into memory for further operations.document.SaveToFile()– writes the PDF to disk.
This workflow loads PDF data into memory for instant saving, improving speed and avoiding unnecessary disk writes.
4. Processing PDFs Without Saving
You can extract metadata or text directly in memory without writing files:
def process_pdf_from_url():
url = "resource/sample.pdf"
response = requests.get(url)
response.raise_for_status()
# Load PDF in memory
document = PdfDocument(Stream(response.content))
# Retrieve document information
print(f"Number of pages: {document.Pages.Count}")
info = document.DocumentInformation
print(f"Title: {info.Title}")
print(f"Author: {info.Author}")
# Extract text from the first page
from spire.pdf import PdfTextExtractor
extractor = PdfTextExtractor(document.Pages[0])
text = extractor.ExtractText()
print(f"First 100 characters: {text[:100]}")
document.Close()
if __name__ == "__main__":
process_pdf_from_url()
Why this is useful: You can analyze content, index text, or extract metadata without creating unnecessary files on disk. This is ideal for server-side scripts, cloud functions, or batch processing.
5. Handling Large PDFs
Downloading very large PDFs (e.g., 100MB+) can consume significant memory. Use streaming download and temporary files to reduce memory usage:
import tempfile
import os
def download_large_pdf(url: str, output_path: str):
try:
response = requests.get(url, stream=True, timeout=60)
response.raise_for_status()
# Write chunks to a temporary file
with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as tmp:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
tmp.write(chunk)
temp_path = tmp.name
# Load PDF from temporary file
document = PdfDocument()
document.LoadFromFile(temp_path)
document.SaveToFile(output_path)
document.Close()
# Clean up temporary file
os.unlink(temp_path)
print(f"Large PDF saved to: {output_path}")
except Exception as e:
print(f"Error: {e}")
Notes:
stream=Trueavoids loading the entire file into memory.- Temporary files allow processing PDFs that exceed available RAM.
6. Adding Retry Logic
Network requests may fail intermittently. Adding retries improves robustness:
import time
def download_with_retry(url: str, output_path: str, max_retries: int = 3):
for attempt in range(max_retries):
try:
response = requests.get(url, timeout=30)
response.raise_for_status()
document = PdfDocument(Stream(response.content))
document.SaveToFile(output_path)
document.Close()
print(f"Downloaded successfully: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Attempt {attempt + 1} failed: {e}")
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Retrying in {wait_time} seconds...")
time.sleep(wait_time)
print("All retry attempts failed.")
return False
Why use this: Exponential backoff prevents overwhelming servers and handles transient network failures gracefully.
7. Common Issues and Troubleshooting
PDF Not Found (404)
Problem: The URL does not point to a valid PDF, resulting in a 404 error.
Solution: Verify the URL and add a User-Agent header if needed:
import requests
url = "https://example.com/missing.pdf"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 404:
print("PDF not found (404)")
Server Returns HTML Instead of PDF
Problem: The URL returns an HTML page instead of a PDF.
Solution: Check the Content-Type and parse HTML to locate the actual PDF:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/download-page"
response = requests.get(url)
content_type = response.headers.get('Content-Type', '')
if 'application/pdf' not in content_type and 'text/html' in content_type:
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a', href=True):
if link['href'].endswith('.pdf'):
print(f"Found PDF link: {link['href']}")
# Download the actual PDF URL
Extracted Text Shows Garbled Characters
Problem: Text extraction returns unreadable characters, often due to encoding or scanned PDFs.
Solution: Ensure proper handling or use OCR for scanned PDFs:
from spire.pdf import PdfDocument, PdfTextExtractor
document = PdfDocument("example.pdf")
extractor = PdfTextExtractor(document.Pages[0])
text = extractor.ExtractText()
print(text[:200])
# If text is still garbled, the PDF may be image-based; consider OCR
PDF Loads But Has No Pages
Problem: document.Pages.Count returns 0 even though the file exists.
Solution: PDF may be corrupted or password-protected:
from spire.pdf import PdfDocument, Stream
with open("protected.pdf", "rb") as f:
pdf_bytes = f.read()
# For password-protected PDF
document = PdfDocument(Stream(pdf_bytes), "password")
print(f"Pages: {document.Pages.Count}")
8. Conclusion
In this article, we demonstrated how to download PDF files from URLs in Python using Spire.PDF for Python. By leveraging the Stream class, developers can load PDF data directly from memory without unnecessary disk I/O, enabling efficient document processing pipelines.
We covered the complete workflow: downloading PDF data with the requests library, creating Stream objects from bytes, loading PdfDocument instances, handling network errors, managing large files, and troubleshooting common issues. The production-ready code examples provide a solid foundation for building robust PDF download and processing systems.
To fully experience the capabilities of Spire.PDF for Python without any evaluation limitations, you can request a free 30-day trial license.
9. FAQs
Q1. How do I download a PDF from a URL using Python?
Use the requests library to fetch the PDF data and Spire.PDF to load it from memory:
response = requests.get(url)
stream = Stream(response.content)
document = PdfDocument(stream)
Q2. How do I handle authentication-protected PDFs?
For basic authentication, use the auth parameter:
response = requests.get(url, auth=('username', 'password'))
For token-based authentication, add headers:
headers = {'Authorization': 'Bearer YOUR_TOKEN'}
response = requests.get(url, headers=headers)
Q3. What's the maximum PDF file size I can download?
The theoretical limit depends on your system's available memory. For files larger than 200MB, use the streaming approach with a temporary file instead of loading everything into memory.
Q4. Can I download multiple PDFs in parallel?
Yes. Use concurrent.futures or asyncio to download multiple PDFs simultaneously for better performance.
from concurrent.futures import ThreadPoolExecutor
urls = ["url1.pdf", "url2.pdf", "url3.pdf"]
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(lambda u: download_pdf(u), urls)
