
Knowledgebase (2370)
Children categories
Export DataGrid and GridView to Excel in C# (Without Interop)
2026-02-03 08:05:39 Written by jie zou
Exporting tabular data from UI controls to Excel is a common requirement in C# applications. In both WinForms and ASP.NET projects, users often need to take the data currently displayed in a DataGrid, DataGridView, or GridView and export it to an Excel file for reporting, sharing, or further processing.
In real-world scenarios, exported Excel files are rarely used as raw data only. Readable layouts, header styles, column widths, and number formats are usually expected as part of the export result.
This article demonstrates how to export DataGridView and GridView/DataGrid data to Excel in C# using Spire.XLS for .NET, without relying on Microsoft Office Interop. The solution focuses on exporting displayed data accurately, keeping the implementation clean, and applying Excel formatting in a consistent and reusable way.
Table of Contents
- Advantages of Programmatic Excel Export in C#
- Core Concept: Export Displayed Data via a DataTable
- Step 1: Extract Displayed Data into a DataTable
- Step 2: Export DataTable to Excel in C#
- Step 3: Apply Formatting to the Exported Excel File
- Performance and Practical Considerations
- Summary
- FAQ
Advantages of Programmatic Excel Export in C#
While Microsoft Office Interop can generate Excel files, using a programmatic approach in C# provides clear benefits for exporting data from DataGrid, DataGridView, or GridView:
- Does not require Microsoft Excel to be installed on the machine
- Suitable for server-side or cloud environments
- Maintains high performance even with large datasets
- Simplifies automation and background export scenarios
By exporting data directly via code, developers can create reliable, maintainable, and scalable Excel exports that work consistently across different application types.
Core Concept: Export Displayed Data via a DataTable
Although DataGrid, DataGridView, and GridView are UI controls, they serve the same fundamental purpose: displaying structured data in rows and columns. Attempting to export these controls directly often leads to UI-dependent logic and maintenance challenges.
A more reliable and reusable workflow is:
Displayed UI data → DataTable → Excel file
In this design:
- The DataTable represents exactly what the user sees
- The Excel export logic remains independent of the UI layer
- The same approach works for WinForms and ASP.NET applications
- Formatting and layout can be applied at the Excel level
The DataTable acts as a clean intermediate structure rather than the final export target, and using Spire.XLS for .NET, DataTable can be easily exported to a well-formatted Excel file.
Step 1: Extract Displayed Data into a DataTable
The first step is to extract the currently displayed data from the UI control into a DataTable. This step focuses on capturing visible rows and columns, not on reconstructing the original data source.
Export Displayed Data from DataGridView (WinForms)
In WinForms applications, users typically expect the DataGridView content to be exported as it appears on screen. The following method converts the displayed DataGridView data into a DataTable:
DataTable ConvertDataGridViewToDataTable(DataGridView dgv)
{
DataTable dt = new DataTable();
foreach (DataGridViewColumn column in dgv.Columns)
{
dt.Columns.Add(column.HeaderText, column.ValueType ?? typeof(string));
}
foreach (DataGridViewRow row in dgv.Rows)
{
if (row.IsNewRow) continue;
DataRow dr = dt.NewRow();
for (int i = 0; i < dgv.Columns.Count; i++)
{
dr[i] = row.Cells[i].Value ?? DBNull.Value;
}
dt.Rows.Add(dr);
}
return dt;
}
This approach preserves column headers, column order, and displayed values when exporting DataGridView data to Excel in C#.
Export Displayed Data from GridView (ASP.NET)
In ASP.NET applications, GridView controls render tabular data for users to view and interact with. To export the displayed GridView data, the rendered rows can be converted into a DataTable as shown below:
DataTable ConvertGridViewToDataTable(GridView gv)
{
DataTable dt = new DataTable();
foreach (TableCell cell in gv.HeaderRow.Cells)
{
dt.Columns.Add(cell.Text);
}
foreach (GridViewRow row in gv.Rows)
{
DataRow dr = dt.NewRow();
for (int i = 0; i < row.Cells.Count; i++)
{
dr[i] = row.Cells[i].Text;
}
dt.Rows.Add(dr);
}
return dt;
}
This method provides a consistent data structure that can be reused for exporting GridView data to Excel in C#, without introducing UI-specific export logic.
If you need to export data directly from a database to an Excel file, you can refer to this guide: Export Database to Excel in C#.
Step 2: Export DataTable to Excel in C#
Once the displayed data has been extracted into a DataTable, exporting it to Excel becomes a UI-independent operation.
In this example, Spire.XLS for .NET is used to generate Excel files programmatically, without requiring Microsoft Excel to be installed.
Install Spire.XLS for .NET
Spire.XLS for .NET can be installed via NuGet:
Install-Package Spire.XLS
You can also download Spire.XLS for .NET and add it to your project manually.
Basic Excel Export Example
using Spire.Xls;
Workbook workbook = new Workbook();
Worksheet worksheet = workbook.Worksheets[0];
// Import DataTable into Excel, including column headers
worksheet.InsertDataTable(exportTable, true, 1, 1);
// Save the Excel file
workbook.SaveToFile("ExportedData.xlsx", ExcelVersion.Version2016);
Below is a preview of the exported Excel file:
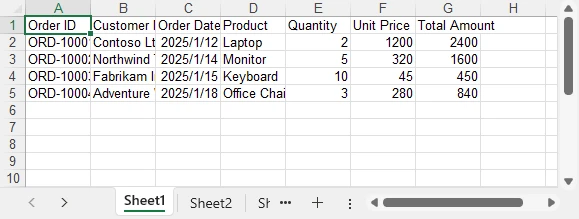
This export logic can be reused for DataGrid, DataGridView, and GridView scenarios without modification.
Step 3: Apply Formatting to the Exported Excel File
Formatting is a common requirement for Excel exports, regardless of how the data was sourced. Applying styles, adjusting column widths, and setting number formats significantly improves the usability of the exported file.
The following example demonstrates common formatting operations that can be applied to any exported Excel worksheet:
CellStyle headerStyle = workbook.Styles.Add("HeaderStyle");
headerStyle.Font.IsBold = true;
headerStyle.Font.Size = 13;
headerStyle.HorizontalAlignment = HorizontalAlignType.Center;
headerStyle.VerticalAlignment = VerticalAlignType.Center;
headerStyle.Color = Color.LightGray;
// Apply header style
CellRange headerRange = worksheet.Range[1, 1, 1, worksheet.AllocatedRange.Rows[0].CellsCount];
headerRange.Style = headerStyle;
// Auto-fit columns
worksheet.AllocatedRange.AutoFitColumns();
// Format date and currency columns
worksheet.Range[$"C2:C{worksheet.AllocatedRange.RowCount}"].NumberFormat = "yyyy-mm-dd";
worksheet.Range[$"F2:G{worksheet.AllocatedRange.RowCount}"].NumberFormat = "$#,##0.00";Below is a preview of the Excel file after applying formatting:
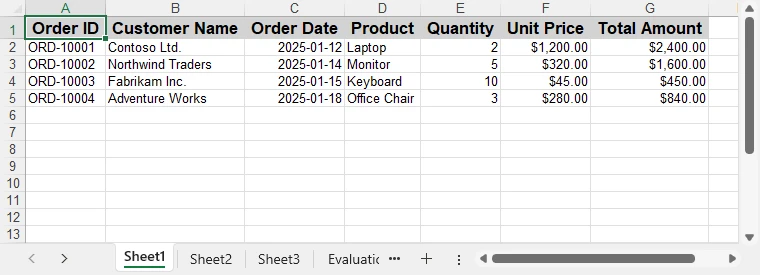
These formatting steps can be combined or extended based on reporting requirements, without changing the data extraction logic.
Spire.XLS for .NET also supports more Excel formatting features, such as conditional formatting, charts, and more. You can check How to Create Excel Files in C# for more formating options.
Performance and Practical Considerations
When exporting large DataGrid or GridView datasets:
- Run export operations asynchronously in desktop applications
- Avoid blocking the UI thread during Excel generation
- Export only necessary or visible columns
- Generate Excel files server-side in ASP.NET applications
Because the export process operates on a DataTable rather than UI elements, it remains maintainable and scalable as data volume increases.
Summary
Exporting DataGrid, DataGridView, or GridView data to Excel in C# does not require Microsoft Office Interop. By extracting the displayed data into a DataTable and generating Excel files programmatically, developers can implement reliable and reusable Excel export functionality.
With consistent formatting support and a clear separation between UI and export logic, this approach works well for real-world reporting scenarios in both desktop and web applications. For evaluating the library or testing export functionality, you can apply for a temporary license.
FAQ
Q1: How can I export DataGridView data to Excel in C#?
A1: You can extract the displayed data from a DataGridView into a DataTable and then use Spire.XLS for .NET to generate an Excel file programmatically, without relying on Microsoft Excel.
Q2: Can I apply formatting when exporting GridView to Excel in C#?
A2: Yes, Spire.XLS allows you to apply styles, adjust column widths, and set number formats to any exported Excel worksheet, ensuring readable and professional-looking reports.
Q3: Do I need Microsoft Excel installed to export DataGrid or GridView data in C#?
A3: No. By using a programmatic library like Spire.XLS, Excel files can be generated directly from DataTable objects without requiring Excel on the machine, making it suitable for server-side and cloud applications.

CSV (Comma-Separated Values) files are the backbone of data exchange across industries—from data analysis to backend systems. They’re lightweight, human-readable, and compatible with almost every tool (Excel, Google Sheets, databases). If you’re a developer seeking a reliable way to create a CSV file in Python, Spire.XLS for Python is a powerful library that simplifies the process.
In this comprehensive guide, we'll explore how to generate a CSV file in Python with Spire.XLS, covering basic CSV creation and advanced use cases like list to CSV and Excel to CSV conversion.
What You’ll Learn
- Installation and Setup
- Basic: Create a Simple CSV File in Python
- Dynamic Data: Generate CSV from a List of Dictionaries in Python
- Excel-to-CSV: Generate CSV From an Excel File in Python
- Best Practices for CSV Creation
- FAQ: Create CSV in Python
Installation and Setup
Getting started with Spire.XLS for Python is straightforward. Follow these steps to set up your environment:
Step 1: Ensure Python 3.6 or higher is installed.
Step 2: Install the library via pip (the official package manager for Python):
pip install Spire.XLS
Step 3 (Optional): Request a temporary free license to test full features without any limitations.
Basic: Create a Simple CSV File in Python
Let’s start with a simple scenario: creating a CSV file from scratch with static data (e.g., a sales report). The code below creates a new workbook, populates it with data, and saves it as a CSV file.
from spire.xls import *
from spire.xls.common import *
# 1. Create a new workbook
workbook = Workbook()
# 2. Get the first worksheet (default sheet)
worksheet = workbook.Worksheets[0]
# 3. Populate data into cells
# Header row
worksheet.Range["A1"].Text = "ProductID"
worksheet.Range["B1"].Text = "ProductName"
worksheet.Range["C1"].Text = "Price"
worksheet.Range["D1"].Text = "QuantitySold"
worksheet.Range["A2"].NumberValue = 101
worksheet.Range["B2"].Text = "Wireless Headphones"
worksheet.Range["C2"].NumberValue = 79.99
worksheet.Range["D2"].NumberValue = 250
worksheet.Range["A3"].NumberValue = 102
worksheet.Range["B3"].Text = "Bluetooth Speaker"
worksheet.Range["C3"].NumberValue = 49.99
worksheet.Range["D3"].NumberValue = 180
# Save the worksheet to CSV
worksheet.SaveToFile("BasicSalesReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Core Workflow
- Initialize Core object: Workbook() creates a new Excel workbook, Worksheets[0] accesses the target sheet.
- Fill data into cells: Use .Text (for strings) and .NumberValue (for numbers) to ensure correct data types.
- Export & cleanup: SaveToFile() exports the worksheet to CSV , and Dispose() prevents memory leaks.
Output:
The resulting BasicSalesReport.csv will look like this:

Dynamic Data: Generate CSV from a List of Dictionaries in Python
In real-world scenarios, data is often stored in dictionaries (e.g., from APIs/databases). The code below converts a list of dictionaries to a CSV:
from spire.xls import *
from spire.xls.common import *
# Sample data (e.g., from a database/API)
customer_data = [
{"CustomerID": 1, "Name": "John Doe", "Email": "john@example.com", "Country": "USA"},
{"CustomerID": 2, "Name": "Maria Garcia", "Email": "maria@example.es", "Country": "Spain"},
{"CustomerID": 3, "Name": "Li Wei", "Email": "wei@example.cn", "Country": "China"}
]
# 1. Create workbook and worksheet
workbook = Workbook()
worksheet = workbook.Worksheets[0]
# 2. Write headers (extract keys from the first dictionary)
headers = list(customer_data[0].keys())
for col_idx, header in enumerate(headers, start=1):
worksheet.Range[1, col_idx].Text = header # Row 1 = headers
# 3. Write data rows
for row_idx, customer in enumerate(customer_data, start=2): # Start at row 2
for col_idx, key in enumerate(headers, start=1):
# Handle different data types (text/numbers)
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row_idx, col_idx].NumberValue = value
else:
worksheet.Range[row_idx, col_idx].Text = value
# 4. Save as CSV
worksheet.SaveToFile("CustomerData.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
This example is ideal for JSON to CSV conversion, database dumps, and REST API data exports. Key advantages include:
- Dynamic Headers: Automatically extracts headers from the keys of the first dictionary in the dataset.
- Scalable: Seamlessly adapts to any volume of dictionaries or key-value pairs (perfect for dynamic data).
- Clean Output: Preserves the original order of dictionary keys for consistent CSV structure.
The generated CSV file:
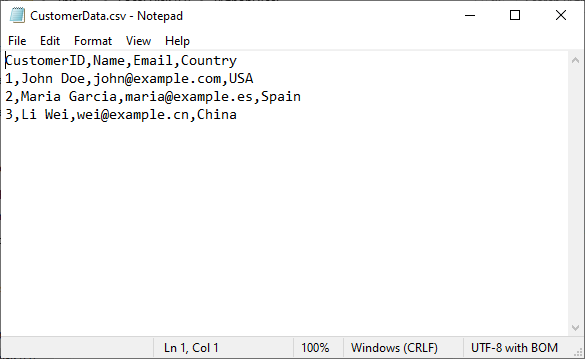
Excel-to-CSV: Generate CSV From an Excel File in Python
Spire.XLS excels at converting Excel (XLS/XLSX) to CSV in Python. This is useful if you have Excel reports and need to export them to CSV for data pipelines or third-party tools.
from spire.xls import *
# 1. Initialize a workbook instance
workbook = Workbook()
# 2. Load a xlsx file
workbook.LoadFromFile("Expenses.xlsx")
# 3. Save Excel as a CSV file
workbook.SaveToFile("XLSXToCSV.csv", FileFormat.CSV)
workbook.Dispose()
Conversion result:
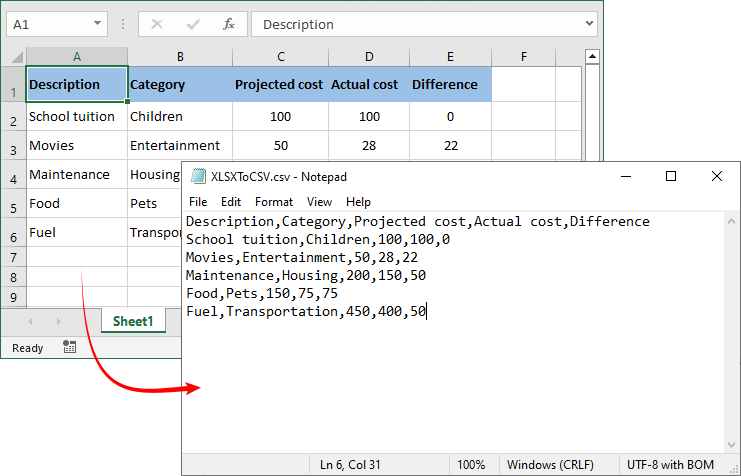
Note: By default, SaveToFile() converts only the first worksheet. For converting multiple sheets to separate CSV files, refer to the comprehensive guide: Convert Excel (XLSX/XLS) to CSV in Python – Batch & Multi-Sheet
Best Practices for CSV Creation
Follow these guidelines to ensure robust and professional CSV output:
- Validate Data First: Clean empty rows/columns before exporting to CSV.
- Use UTF-8 Encoding: Always specify UTF-8 encoding (Encoding.get_UTF8()) to support international characters seamlessly.
- Batch Process Smartly: For 100k+ rows, process data in chunks (avoid loading all data into memory at once).
- Choose the Correct Delimiter: Be mindful of regional settings. For European users, use a semicolon (;) as the delimiter to avoid locale issues.
- Dispose Objects: Release workbook/worksheet resources with Dispose() to prevent memory leaks.
Conclusion
Spire.XLS simplifies the process of leveraging Python to generate CSV files. Whether you're creating reports from scratch, converting Excel workbooks, or handling dynamic data from APIs and databases, this library delivers a robust and flexible solution.
By following this guide, you can easily customize delimiters, specify encodings such as UTF-8, and manage data types—ensuring your CSV files are accurate, compatible, and ready for any application. For more advanced features, you can explore the Spire.XLS for Python tutorials.
FAQ: Create CSV in Python
Q1: Why choose Spire.XLS over Python’s built-in csv module?
A: While Python's csv module is excellent for basic read/write operations, Spire.XLS offers significant advantages:
- Better data type handling: Automatic distinction between text and numeric data.
- Excel Compatibility: Seamlessly converts between Excel (XLSX/XLS) and CSV—critical for teams using Excel as a data source.
- Advanced Customization: Supports customizing the delimiter and encoding of the generated CSV file.
- Batch processing: Efficient handling of large datasets and multiple files.
- Cross-Platform Support: Works on Windows, macOS, and Linux (no Excel installation required).
Q2: Can I use Spire.XLS for Python to read CSV files?
A: Yes. Spire.XLS supports parsing CSV files and extracting their data. Details refer to: How to Read CSV Files in Python: A Comprehensive Guide
Q3: Can Spire.XLS convert CSV files back to Excel format?
A: Yes! Spire.XLS supports bidirectional conversion. A quick example:
from spire.xls import *
# Create a workbook
workbook = Workbook()
# Load a CSV file
workbook.LoadFromFile("sample.csv", ",", 1, 1)
# Save CSV as Excel
workbook.SaveToFile("CSVToExcel.xlsx", ExcelVersion.Version2016)
Q4: How do I change the CSV delimiter?
A: The SaveToFile() method’s second parameter controls the delimiter:
# Semicolon (for European locales):
worksheet.SaveToFile("EU.csv", ";", Encoding.get_UTF8())
# Tab (for tab-separated values/TSV)
worksheet.SaveToFile("TSV_File.csv", "\t", Encoding.get_UTF8())
Transform DataTables into Professional PDF Reports with C#
2026-01-23 02:56:48 Written by Allen Yang
In many .NET-based business systems, structured data is often represented as a DataTable. When this data needs to be distributed, archived, or delivered as a read-only report, exporting a DataTable to PDF using C# becomes a common and practical requirement.
Compared with formats such as Excel or CSV, PDF is typically chosen when layout stability, visual consistency, and document integrity are more important than data editability. This makes PDF especially suitable for reports, invoices, audit records, and system-generated documents.
This tutorial takes a code-first approach to converting a DataTable to PDF in C#, focusing on the technical implementation rather than conceptual explanations. The solution is based on Spire.PDF for .NET, using its PdfGrid component to render DataTable content as a structured table inside a PDF document.
Table of Contents
- 1. Overview: DataTable to PDF Export in C#
- 2. Environment Setup
- 3. Core Workflow and Code Implementation
- 4. Controlling Table Layout, Page Flow, and Pagination
- 5. Customizing Table Appearance
- 6. PDF File and Stream Output
- 7. Practical Tips and Common Issues
1. Overview: DataTable to PDF Export in C#
Exporting a DataTable to PDF is fundamentally a data-binding and rendering task, not a low-level drawing problem.
Instead of manually calculating row positions, column widths, or page breaks, the recommended approach is to bind an existing DataTable to a PDF table component and let the rendering engine handle layout and pagination automatically.
In Spire.PDF for .NET, this role is fulfilled by the PdfGrid class.
Why PdfGrid Is the Right Abstraction
PdfGrid is a Spire.PDF for .NET component designed specifically for rendering structured, tabular data in PDF documents. It treats rows, columns, headers, and pagination as first-class concepts rather than graphical primitives.
From a technical standpoint, PdfGrid provides:
- Direct binding via the DataSource property, which accepts a DataTable
- Automatic column generation based on the DataTable schema
- Built-in header and row rendering
- Automatic page breaking when content exceeds page bounds
As a result, exporting a DataTable to PDF becomes a declarative operation: you describe what data should be rendered, and the PDF engine determines how it is laid out across pages.
The following sections focus on the concrete implementation and practical refinements of this approach.
2. Environment Setup
All examples in this article apply to both .NET Framework and modern .NET (6+) projects. The implementation is based entirely on managed code and does not require platform-specific configuration.
Installing Spire.PDF for .NET
Spire.PDF for .NET can be installed via NuGet:
Install-Package Spire.PDF
You can also download Spire.PDF for .NET and include it in your project manually.
Once installed, the library provides APIs for PDF document creation, page management, table rendering, and style control.
3. DataTable to PDF in C#: Core Workflow and Code Implementation
With the environment prepared, exporting a DataTable to PDF becomes a linear, implementation-driven process.
At its core, the workflow relies on binding an existing DataTable to PdfGrid and delegating layout, pagination, and table rendering to the PDF engine. There is no need to manually draw rows, columns, or borders.
From an implementation perspective, the process consists of the following steps:
- Prepare a populated DataTable
- Create a PDF document and page
- Bind the DataTable to a PdfGrid
- Render the grid onto the page
- Save the PDF output
These steps are typically executed together as a single, continuous code path in real-world applications. The following example demonstrates the complete workflow in one place.
Complete Example: Exporting a DataTable to PDF
The example below uses a business-oriented DataTable schema to reflect a typical reporting scenario. The source of the DataTable (database, API, or in-memory processing) does not affect the export logic.
DataTable dataTable = new DataTable();
dataTable.Columns.Add("OrderId", typeof(int));
dataTable.Columns.Add("CustomerName", typeof(string));
dataTable.Columns.Add("OrderDate", typeof(DateTime));
dataTable.Columns.Add("TotalAmount", typeof(decimal));
dataTable.Rows.Add(1001, "Contoso Ltd.", DateTime.Today, 1280.50m);
dataTable.Rows.Add(1002, "Northwind Co.", DateTime.Today, 760.00m);
dataTable.Rows.Add(1003, "Adventure Works", DateTime.Today, 2145.75m);
dataTable.Rows.Add(1004, "Wingtip Toys", DateTime.Today, 1230.00m);
dataTable.Rows.Add(1005, "Bike World", DateTime.Today, 1230.00m);
dataTable.Rows.Add(1006, "Woodgrove Bank", DateTime.Today, 1230.00m);
PdfDocument document = new PdfDocument();
PdfPageBase page = document.Pages.Add();
PdfGrid grid = new PdfGrid();
grid.DataSource = dataTable;
grid.Draw(page, new PointF(40f, 0));
document.SaveToFile("DataTableToPDF.pdf");
document.Close();
This single code block completes the entire DataTable-to-PDF export process. Below is a preview of the generated PDF:
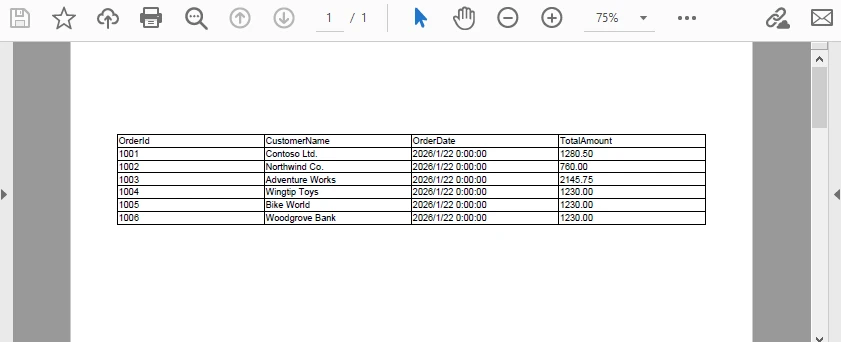
Key technical characteristics of this implementation:
- PdfGrid.DataSource accepts a DataTable directly, with no manual row or column mapping
- Column headers are generated automatically from DataColumn.ColumnName
- Row data is populated from each DataRow
- Pagination and page breaks are handled internally during rendering
- No coordinate-level table layout logic is required
The result is a structured, paginated PDF table that accurately reflects the DataTable’s schema and data. This method is already a fully functional and production-ready solution for exporting a DataTable to PDF in C#.
In practical applications, however, additional control is often required for layout positioning, page size, orientation, and visual styling. The following sections focus on refining table placement, appearance, and pagination behavior without altering the core export logic.
4. Controlling Table Layout, Page Flow, and Pagination
In real-world documents, table rendering is part of a larger page composition. Page geometry, table start position, and pagination behavior together determine how tabular data flows across one or more pages.
In PdfGrid, these concerns are resolved during rendering. The grid itself does not manage absolute layout or page transitions; instead, layout and pagination are governed by page configuration and the parameters supplied when calling Draw.
The following example demonstrates a typical layout and pagination configuration used in production reports.
Layout and Pagination Example
PdfDocument document = new PdfDocument();
// Create an A4 page with margins
PdfPageBase page = document.Pages.Add(
PdfPageSize.A4,
new PdfMargins(40),
PdfPageRotateAngle.RotateAngle0, // Rotates the page coordinate system
PdfPageOrientation.Landscape // Sets the page orientation
);
PdfGrid grid = new PdfGrid();
grid.DataSource = dataTable;
// Enable header repetition across pages
grid.RepeatHeader = true;
// Define table start position
float startX = 40f;
float startY = 80f;
// Render the table
grid.Draw(page, new PointF(startX, startY));
Below is a preview of the generated PDF with page configuration applied:
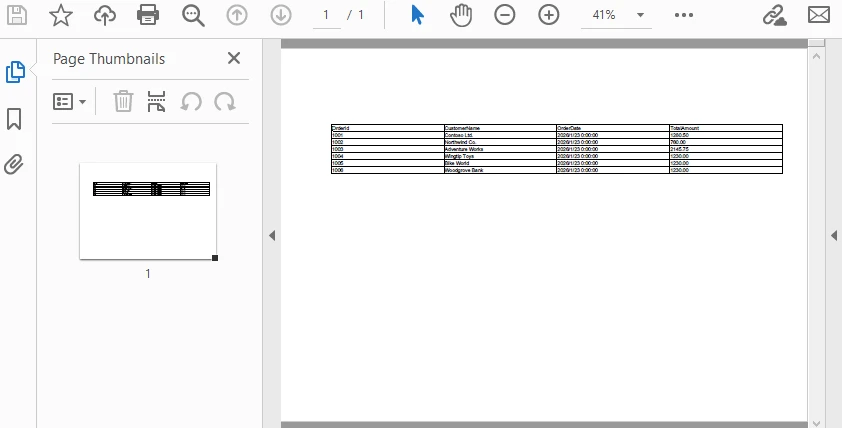
Technical Explanation
The rendering behavior illustrated above can be understood as a sequence of layout and flow decisions applied at draw time:
-
PdfPageBase
- Pages.Add creates a new page with configurable size, margins, rotation, and orientation.
-
RepeatHeader
- Boolean property controlling whether column headers are rendered on each page. When enabled, headers repeat automatically during multi-page rendering.
-
Draw method
- Accepts a PointF defining the starting position on the page.
- Responsible for rendering the grid and automatically handling pagination.
By configuring page geometry, table start position, and pagination behavior together, PdfGrid enables predictable multi-page table rendering without manual page management or row-level layout control.
Page numbers are also important for PDF reports. Refer to How to Add Pages Numbers to PDF with C# to learn page numbering techniques.
5. Customizing Table Appearance
Once layout is stable, appearance becomes the primary concern. PdfGrid provides a centralized styling model that allows table-wide, column-level, and row-level customization without interfering with data binding or pagination.
The example below consolidates common styling configurations typically applied in reporting scenarios.
Styling Example: Headers, Rows, and Columns
PdfDocument document = new PdfDocument();
PdfPageBase page = document.AppendPage();
PdfGrid grid = new PdfGrid();
grid.DataSource = dataTable;
// Create and apply the header style
PdfGridCellStyle headerStyle = new PdfGridCellStyle();
headerStyle.Font =
new PdfFont(PdfFontFamily.Helvetica, 10f, PdfFontStyle.Bold);
headerStyle.BackgroundBrush =
new PdfSolidBrush(Color.FromArgb(60, 120, 200));
headerStyle.TextBrush = PdfBrushes.White;
grid.Headers.ApplyStyle(headerStyle);
// Create row styles
PdfGridCellStyle defaultStyle = new PdfGridCellStyle();
defaultStyle.Font = new PdfFont(PdfFontFamily.Helvetica, 9f);
PdfGridCellStyle alternateStyle = new PdfGridCellStyle();
alternateStyle.BackgroundBrush = new PdfSolidBrush(Color.LightSkyBlue);
// Apply row styles
for (int rowIndex = 0; rowIndex < grid.Rows.Count; rowIndex++)
{
if (rowIndex % 2 == 0)
{
grid.Rows[rowIndex].ApplyStyle(defaultStyle);
}
else
{
grid.Rows[rowIndex].ApplyStyle(alternateStyle);
}
}
// Explicit column widths
grid.Columns[0].Width = 60f; // OrderId
grid.Columns[1].Width = 140f; // CustomerName
grid.Columns[2].Width = 90f; // OrderDate
grid.Columns[3].Width = 90f; // TotalAmount
// Render the table
grid.Draw(page, new PointF(40f, 80f));
Below is a preview of the generated PDF with the above styling applied:
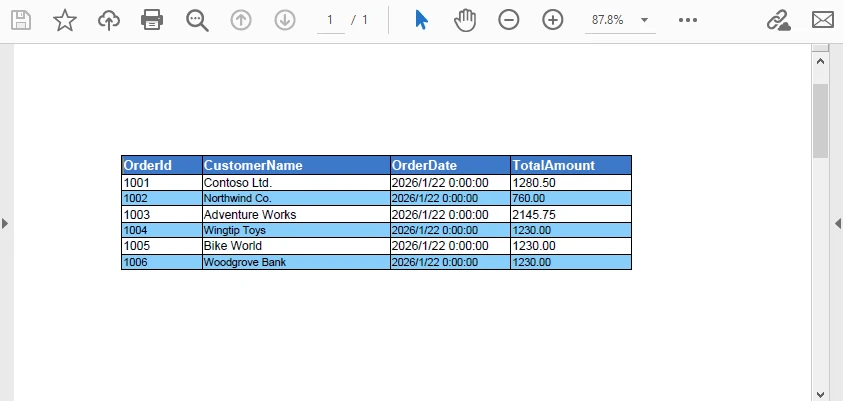
Styling Behavior Notes
-
Header styling
- Header appearance is defined through a dedicated PdfGridCellStyle and applied using grid.Headers.ApplyStyle(...).
- This ensures all header cells share the same font, background color, text color, and alignment across pages.
-
Row styling
- Data rows are styled explicitly via grid.Rows[i].ApplyStyle(...).
- Alternating row appearance is controlled by the row index, making the behavior predictable and easy to extend with additional conditions if needed.
-
Column width control
- Column widths are assigned directly through grid.Columns[index].Width.
- Explicit widths avoid layout shifts caused by content length and produce consistent results in report-style documents.
Make sure to bind the styles before applying styles.
All styles (header, rows, and columns) are resolved before calling grid.Draw(...). The rendering process applies these styles without affecting pagination or data binding.
For more complex styling scenarios, check out How to Create and Style Tables in PDF with C#.
6. Output Options: File vs Stream
Once the table has been rendered, the final step is exporting the PDF output.
The rendering logic remains identical regardless of the output destination.
Saving to a File
Saving directly to a file is suitable for desktop applications, background jobs, and batch exports.
document.SaveToFile("DataTableReport.pdf");
document.Close();
This approach is typically used in:
- Windows desktop applications
- Scheduled report generation
- Offline or server-side batch processing
Writing to a Stream (Web and API Scenarios)
In web-based systems, saving to disk is often unnecessary or undesirable. Instead, the PDF can be written directly to a stream.
using (MemoryStream stream = new MemoryStream())
{
document.SaveToStream(stream);
document.Close();
byte[] pdfBytes = stream.ToArray();
// return pdfBytes as HTTP response
}
Stream output integrates cleanly with ASP.NET controllers or minimal APIs, without the need for temporary file storage.
For a complete example of returning a generated PDF from an ASP.NET application, see how to create and return PDF documents in ASP.NET.
7. Practical Tips and Common Issues
This section focuses on issues commonly encountered in real-world projects when exporting DataTables to PDF.
7.1 Formatting Dates and Numeric Values
PdfGrid renders values using their string representation. To ensure consistent formatting, values should be normalized before binding.
Typical examples include:
- Formatting DateTime values using a fixed culture
- Standardizing currency precision
- Avoiding locale-dependent formats in multi-region systems
This preparation step belongs in the data layer, not the rendering layer.
7.2 Handling Null and Empty Values
DBNull.Value may result in empty cells or inconsistent alignment. Normalizing values before binding avoids layout surprises.
row["TotalAmount"] =
row["TotalAmount"] == DBNull.Value ? 0m : row["TotalAmount"];
This approach keeps rendering logic simple and predictable.
7.3 Preventing Table Width Overflow
Wide DataTables can exceed page width if left unconfigured.
Common mitigation strategies include:
- Explicit column width configuration
- Slight font size reduction
- Switching to landscape orientation
- Increasing page margins selectively
These adjustments should be applied at the layout level rather than modifying the underlying data.
7.4 Large DataTables and Performance Considerations
When exporting DataTables with hundreds or thousands of rows, performance characteristics become more visible.
Practical recommendations:
- Avoid per-cell or per-row styling in large tables.
- Prefer table-level or column-level styles
- Use standard fonts instead of custom embedded fonts
- Keep layout calculations simple and consistent
For example, applying styles using grid.Rows[rowIndex].ApplyStyle(...) inside a loop can introduce unnecessary overhead for large datasets. In such cases, prefer applying a unified style at the row or column collection level (e.g., grid.Rows.ApplyStyle(...)) when individual row differentiation is not required.
In addition to rendering efficiency, in web environments, PDF generation should be performed outside the request thread when possible to avoid blocking.
8. Conclusion
Exporting a DataTable to PDF in C# can be handled directly through PdfGrid without manual table construction or low-level drawing. By binding an existing DataTable, you can generate paginated PDF tables while keeping layout and appearance fully under control.
This article focused on a practical, code-first approach, covering layout positioning, styling, and data preparation as they apply in real-world export scenarios. With these patterns in place, the same workflow scales cleanly from simple reports to large, multi-page documents.
If you plan to evaluate this workflow in a real project, you can apply for a temporary license from E-ICEBLUE to test the full functionality without limitations.
FAQ: DataTable to PDF in C#
When is PdfGrid the right choice for exporting DataTables to PDF?
PdfGrid is most suitable when you need structured, paginated tables with consistent layout. It handles column generation, headers, and page breaks automatically, making it a better choice than manual drawing for reports, invoices, and audit documents.
Should formatting be handled in the DataTable or in PdfGrid?
Data normalization (such as date formats, numeric precision, and null handling) should be done before binding. PdfGrid is best used for layout and visual styling, not for value transformation.
Can PdfGrid handle large DataTables efficiently?
Yes. PdfGrid supports automatic pagination and header repetition. For large datasets, applying table-level or column-level styles instead of per-cell styling helps maintain stable performance.
