Convert Excel to PDF with JavaScript in React
Microsoft Excel is a powerful tool for managing and analyzing data, but its file format can be difficult to share, especially when recipients don’t have Excel. Converting an Excel file to PDF solves this problem by preserving the document’s layout, fonts, and formatting, ensuring it looks the same on any device. PDFs are universally accessible, making them ideal for sharing reports, invoices, or presentations. They also prevent unwanted editing, ensuring the content remains intact and easily viewable by anyone. In this article, we will demonstrate how to convert Excel to PDF in React using Spire.XLS for JavaScript.
- Convert an Entire Excel Workbook to PDF
- Convert a Specific Worksheet to PDF
- Fit Sheet on One Page while Converting a Worksheet to PDF
- Customize Page Margins while Converting a Worksheet to PDF
- Specify Page Size while Converting a Worksheet to PDF
- Convert a Cell Range to PDF
Install Spire.XLS for JavaScript
To get started with converting Excel to PDF in a React application, you can either download Spire.XLS for JavaScript from our website or install it via npm with the following command:
npm i spire.office
The downloaded product package has been integrated Spire.Doc for JavaScript,Spire.XLS for JavaScript,Spire.PDF for JavaScript,Spire.Presentation for JavaScript. To use the functionality of Spire.XLS for JavaScript, you need to copy the corresponding files (spire.xls.js, Spire.Xls.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and _framework) to the project's "public" folder. At the same time, in order to ensure text rendering, the related font files can be added with custom paths. In the following example, the font addition path is: public\static\font.
For more details, refer to the documentation: How to Integrate Spire.XLS for JavaScript in a React Project
Convert an Entire Excel Workbook to PDF
Converting an entire Excel workbook to PDF allows users to share all sheets in a single, universally accessible file. Using the Workbook.SaveToFile() function of Spire.XLS for JavaScript, you can easily save the entire workbook in PDF format. The key steps are as follows.
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() function.
- Load the Excel file using the Workbook.LoadFromFile() function.
- Save the Excel file to PDF using the Workbook.SaveToFile() function.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert Excel file to PDF
const ExcelToPDF = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Specify output PDF file path
const outputFileName = 'out.pdf';
// Load input file into Virtual File System (VFS)
const inputFileName = 'ToPDF.xlsx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Load existing Excel document
workbook.LoadFromFile({ fileName: inputFileName });
workbook.ConverterSetting.SheetFitToPage = true;
// Save the workbook as PDF
workbook.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.PDF });
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1> Convert Excel file to PDF using JavaScript in React </h1>
<button onClick={ExcelToPDF} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
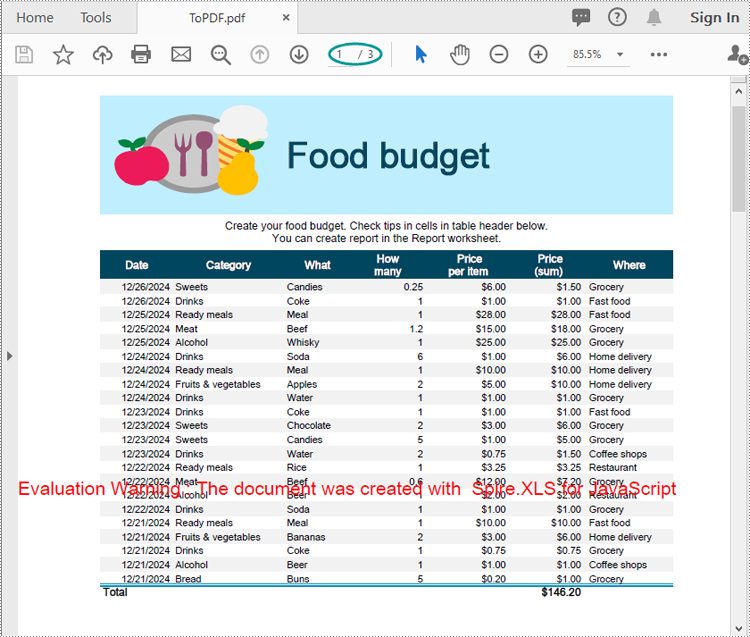
Run the code to launch the React app at localhost:3000. Once it's running, click on the "Convert" button to download the PDF version of the Excel file:

Below is the converted PDF document:
Convert a Specific Worksheet to PDF
To convert a single worksheet to PDF, use the Worksheet.SaveToPdf() function in Spire.XLS for JavaScript. This feature lets you efficiently extract and convert only the necessary worksheet, making your reporting process more streamlined. The key steps are as follows.
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() function.
- Load the Excel file using the Workbook.LoadFromFile() function.
- Get a specific worksheet using the Workbook.Worksheets.get(index) function.
- Save the worksheet to PDF using the Worksheet.SaveToPdf() function.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert Excel file to PDF
const ExcelToPDF = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Specify output PDF file path
const outputFileName = 'out.pdf';
// Load input file into Virtual File System (VFS)
const inputFileName = 'ToPDF.xlsx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Load existing Excel document
workbook.LoadFromFile({ fileName: inputFileName });
// Get the second worksheet
let sheet = workbook.Worksheets.get(0);
//Save the worksheet to PDF
sheet.SaveToPdf({fileName: outputFileName});
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert an Excel Worksheet to PDF Using JavaScript in React</h1>
<button onClick={ExcelToPDF} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
Fit Sheet on One Page while Converting a Worksheet to PDF
Fitting a worksheet onto a single page in the output PDF enhances readability, especially for large datasets. Spire.XLS for JavaScript offers the Workbook.ConverterSetting.SheetFitToPage property, which determines whether the worksheet content should be scaled to fit on a single page when saved as a PDF. The key steps are as follows.
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() function.
- Load the Excel file using the Workbook.LoadFromFile() function.
- Fit the worksheet on one page by setting the Workbook.ConverterSetting.SheetFitToPage property to true.
- Get a specific worksheet using the Workbook.Worksheets.get(index) function.
- Save the worksheet to PDF using the Worksheet.SaveToPdf() function.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert Excel file to PDF
const ExcelToPDF = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Load input file into Virtual File System (VFS)
const inputFileName = 'ToPDF.xlsx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Load existing Excel document
workbook.LoadFromFile({ fileName: inputFileName });
// Fit sheet on one page
workbook.ConverterSetting.SheetFitToPage = true;
// Get the first worksheet
let sheet = workbook.Worksheets.get(0);
// Specify the output PDF file path
const outputFileName = 'FitSheetOnOnePage.pdf';
//Save the worksheet to PDF
sheet.SaveToPdf({fileName: outputFileName});
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert an Excel Worksheet to PDF Using JavaScript in React</h1>
<button onClick={ExcelToPDF} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
Customize Page Margins while Converting a Worksheet to PDF
Customizing page margins when converting an Excel worksheet to PDF ensures that your content is well-aligned and visually appealing. Using the Worksheet.PageSetup.TopMargin, Worksheet.PageSetup.BottomMargin, Worksheet.PageSetup.LeftMargin, and Worksheet.PageSetup.RightMargin properties, you can adjust or remove page margins as needed. The key steps are as follows.
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() function.
- Load the Excel file using the Workbook.LoadFromFile() function.
- Get a specific worksheet using the Workbook.Worksheets.get(index) function.
- Adjust the page margins of the worksheet using the Worksheet.PageSetup.PageMargins property.
- Save the worksheet to PDF using the Worksheet.SaveToPdf() function.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert Excel file to PDF
const ExcelToPDF = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Load input file into Virtual File System (VFS)
const inputFileName = 'ToPDF.xlsx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Load existing Excel document
workbook.LoadFromFile({ fileName: inputFileName });
// Get the first worksheet
let sheet = workbook.Worksheets.get(0);
// Adjust page margins of the worksheet
sheet.PageSetup.TopMargin = 0.5;
sheet.PageSetup.BottomMargin = 0.5;
sheet.PageSetup.LeftMargin = 0.3;
sheet.PageSetup.RightMargin = 0.3;
// Specify the output PDF file path
const outputFileName = 'ToPdfWithSpecificPageMargins.pdf';
//Save the worksheet to PDF
sheet.SaveToPdf({ fileName: outputFileName });
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert an Excel Worksheet to PDF Using JavaScript in React</h1>
<button onClick={ExcelToPDF} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
Specify Page Size while Converting a Worksheet to PDF
Choosing the correct page size when converting an Excel worksheet to PDF is essential for meeting specific printing or submission standards. Spire.XLS for JavaScript offers the Worksheet.PageSetup.PaperSize property, which allows you to select from various predefined page sizes or set a custom size. The key steps are as follows.
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() function.
- Load the Excel file using the Workbook.LoadFromFile() function.
- Get a specific worksheet using the Workbook.Worksheets.get(index) function.
- Set the page size of the worksheet using the Worksheet.PageSetup.PaperSize property.
- Save the worksheet to PDF using the Worksheet.SaveToPdf() function.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert Excel file to PDF
const ExcelToPDF = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Load input file into Virtual File System (VFS)
const inputFileName = 'ToPDF.xlsx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Load existing Excel document
workbook.LoadFromFile({ fileName: inputFileName });
// Get the first worksheet
let sheet = workbook.Worksheets.get(0);
// Set the page size of the worksheet
sheet.PageSetup.PaperSize = wasmModule.PaperSizeType.PaperA3;
// Specify the output PDF file path
const outputFileName = 'ToPdfWithSpecificPageSize.pdf';
//Save the worksheet to PDF
sheet.SaveToPdf({ fileName: outputFileName });
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert an Excel Worksheet to PDF Using JavaScript in React</h1>
<button onClick={ExcelToPDF} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;
Convert a Cell Range to PDF
Converting a specific cell range to PDF allows users to export only a selected portion of the worksheet, ideal for focused reporting or sharing key data points. Using the Worksheet.PageSetup.PrintArea property, you can specify a cell range for conversion. The key steps are as follows.
- Load the font file to ensure correct text rendering.
- Create a Workbook object using the new wasmModule.Workbook() function.
- Load the Excel file using the Workbook.LoadFromFile() function.
- Get a specific worksheet using the Workbook.Worksheets.get(index) function.
- Specify the cell range of the worksheet for conversion using the Worksheet.PageSetup.PrintArea property.
- Save the worksheet to PDF using the Worksheet.SaveToPdf() function.
Code example:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Function to convert Excel file to PDF
const ExcelToPDF = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into Virtual File System (VFS)
await window.spire.FetchFileToVFS('Arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Load input file into Virtual File System (VFS)
const inputFileName = 'ToPDF.xlsx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Load existing Excel document
workbook.LoadFromFile({ fileName: inputFileName });
// Get the first worksheet
let sheet = workbook.Worksheets.get(0);
// Set the page size of the worksheet
sheet.PageSetup.PrintArea = "B5:E17";
// Specify the output PDF file path
const outputFileName = 'CellRangeToPDF.pdf';
//Save the worksheet to PDF
sheet.SaveToPdf({ fileName: outputFileName });
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create a URL for the Blob and initiate download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert an Excel Worksheet to PDF Using JavaScript in React</h1>
<button onClick={ExcelToPDF} disabled={!wasmModule}>
Convert
</button>
</div>
);
}
export default App;

Get a Free License
To fully experience the capabilities of Spire.XLS for JavaScript without any evaluation limitations, you can request a free 30-day trial license.
Convert Word to PDF with JavaScript in React
Converting Word documents to PDF is crucial for maintaining formatting and ensuring consistent viewing across various devices. This conversion process protects the content and layout, making PDFs a preferred choice for sharing official documents such as contracts and reports. PDFs not only preserve the original design but also enhance security, as they are less susceptible to unauthorized edits.
This article demonstrates how to convert Word documents to PDF in React using Spire.Doc for JavaScript. It covers the installation process and provides practical examples to help you configure different conversion options efficiently.
- Install Spire.Doc for JavaScript
- General Steps to Convert Word to PDF in React
- Convert Word to PDF with Installed Fonts Embedded
- Convert Word to PDF with Non-Installed Fonts Embedded
- Convert Word to Password-Protected PDF
- Convert Word to PDF with Hyperlinks Disabled
- Convert Word to PDF with Bookmarks Preserved
- Convert Word to PDF with Custom Image Quality
Install Spire.Doc for JavaScript
To get started with converting Word documents to PDF in a React application, you can either download Spire.Doc for JavaScript from our website or install it via npm with the following command:
npm i spire.officeThe downloaded product package integrates Spire.Doc for JavaScript, Spire.XLS for JavaScript, Spire.PDF for JavaScript, and Spire.Presentation for JavaScript. To use the features of Spire.Doc for JavaScript, you need to copy the corresponding files (spire.doc.js, Spire.Doc.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and the _framework folder) to the public folder of your project. To ensure proper text rendering, you can add relevant font files with a custom path. In the following example, the font is added to the path: public\static\font.
For more details, refer to the documentation: How to Integrate Spire.Doc for JavaScript in a React Project
General Steps to Convert Word to PDF in React
Converting Word documents to PDF in React using Spire.Doc for JavaScript involves several key steps. Here's a step-by-step guide to help you get started:
- Load Fonts: Load necessary font files into the virtual file system (VFS) for accurate rendering.
- Prepare Document: Fetch the input Word file, create a new document, and load the file into it.
- Set PDF Conversion Parameters: Configure any necessary conversion options, such as embedding fonts or preserving bookmarks.
- Convert to PDF: Convert the document to PDF with the specified options.
- Download PDF: Read the generated PDF from the VFS, create a Blob object, and trigger the download for the user.
Convert Word to PDF with Installed Fonts Embedded
When converting documents, you may want to ensure that all fonts used in the Word document are embedded into the PDF. This is especially important for maintaining the document's layout.
Spire.Doc for JavaScript offer the ToPdfParameterList class to customize the conversion options. The key parameter set here is IsEmbeddedAllFonts, which guarantees that all fonts are included in the final PDF.
The following code snippet demonstrates how to embed installed fonts when converting Word to PDF using JavaScript.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert Word to PDF
const convertWordToPdf = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('times.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbd.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Fetch the input file and add it to the VFS
const inputFileName = 'input.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new document
const doc = new wasmModule.Document();
// Load the word file
doc.LoadFromFile(inputFileName);
// Create a parameter list for the PDF conversion
let parameters = new wasmModule.ToPdfParameterList();
// Set the parameter to embed all fonts in the PDF
parameters.IsEmbeddedAllFonts = true;
// Specify the input and output file paths
const outputFileName = 'ToPDF.pdf';
// Save the document as a PDF file
doc.SaveToFile({ fileName: outputFileName, paramList: parameters });
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create download link
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// dispose
doc.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert Word to PDF Using JavaScript in React</h1>
<button onClick={convertWordToPdf} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
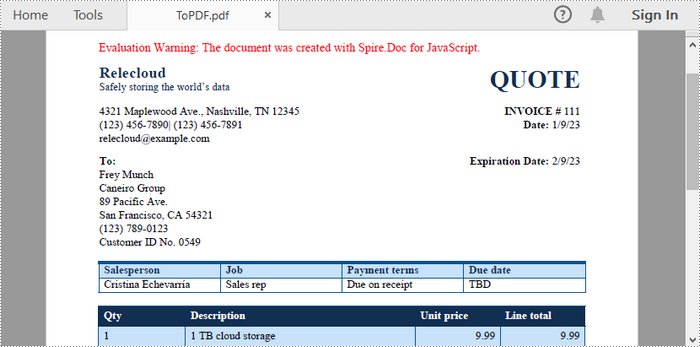
export default App;Run the code, and the React app will launch at localhost:3000. Click "Generate," and a "Save As" window will appear, prompting you to save the output file in your chosen folder.

Below is a screenshot of the generated PDF document:
Convert Word to PDF with Non-Installed Fonts Embedded
For fonts that are not installed on your machine but applied in the Word document, you can also embed these fonts directly into the PDF. This ensures that the document looks consistent across different devices.
To embed non-installed fonts, start by creating a ToPdfParameterList object to customize the conversion process. Next, define a list of custom fonts for the PDF output. Finally, assign the custom font paths to the parameters using the ToPdfParameterList.PrivateFontPaths property.
The following code snippet demonstrates how to embed non-installed fonts when converting Word to PDF using JavaScript.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert Word to PDF
const convertWordToPdf = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('FreebrushScriptPLng.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Fetch the input file and add it to the VFS
const inputFileName = 'input.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new document
const doc = new wasmModule.Document();
// Load the word file
doc.LoadFromFile(inputFileName);
// Create a parameter list for the PDF conversion
let parameters = new wasmModule.ToPdfParameterList();
// Define a list of custom fonts to be used in the PDF
let fonts = new wasmModule.PrivateFontPath('Freebrush Script', 'FreebrushScriptPLng.ttf');
// Assign the custom font paths to the parameters for the PDF conversion
parameters.PrivateFontPaths = fonts;
// Save the document as a PDF file
const outputFileName = 'ToPDF.pdf';
doc.SaveToFile({ fileName: outputFileName, paramList: parameters });
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create download link
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// dispose
doc.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert Word to PDF Using JavaScript in React</h1>
<button onClick={convertWordToPdf} disabled={!wasmModule}>
Generate
</button>
); } export default App;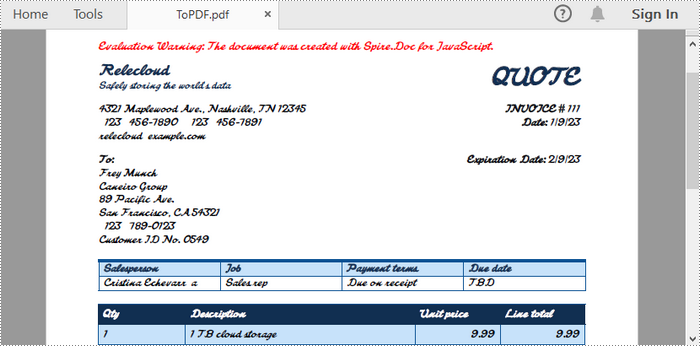
Convert Word to Password-Protected PDF
To enhance security, you can convert a Word document to a password-protected PDF. This feature is essential when sharing sensitive information.
Spire.Doc for JavaScript provides the ToPdfParameterList.PdfSecurity.Encrypt() method, enabling users to protect the generated PDF with an open password, a permission password, and specific document permissions.
The following code illustrates how to convert Word to password-protected PDF using JavaScript.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert Word to PDF
const convertWordToPdf = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('times.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbd.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Fetch the input file and add it to the VFS
const inputFileName = 'input.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new document
const doc = new wasmModule.Document();
// Load the word file
doc.LoadFromFile(inputFileName);
// Create a parameter list for the PDF conversion
let parameters = new wasmModule.ToPdfParameterList();
// Set the parameter to encrypt the generated PDF file
parameters.PdfSecurity.Encrypt('open-psd', 'permission-psd', wasmModule.PdfPermissionsFlags.Default, wasmModule.PdfEncryptionKeySize.Key128Bit);
// Save the document as a PDF file
const outputFileName = 'Encrypted.pdf';
doc.SaveToFile({ fileName: outputFileName, paramList: parameters });
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create download link
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// dispose
doc.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert Word to PDF Using JavaScript in React</h1>
<button onClick={convertWordToPdf} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
export default App;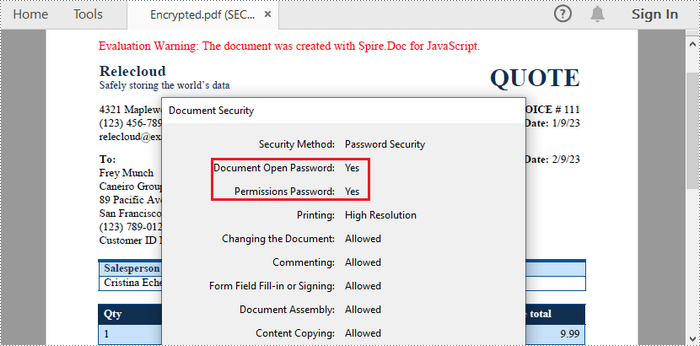
Convert Word to PDF with Hyperlinks Disabled
Disabling hyperlinks when converting a Word document to PDF enhances readability and maintains a clean, distraction-free format. This adjustment can be particularly useful for print materials, presentations, and documents requiring a focus on content without external links.
By setting the ToPdfParameterList.DisableLink property to true, you can ensure that any clickable links in the original document are rendered as plain text in the PDF output.
The following code snippet demonstrates how to disable hyperlinks when converting Word to PDF using JavaScript.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert Word to PDF
const convertWordToPdf = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('times.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbd.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Fetch the input file and add it to the VFS
const inputFileName = 'input.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new document
const doc = new wasmModule.Document();
// Load the word file
doc.LoadFromFile(inputFileName);
// Create a parameter list for the PDF conversion
let parameters = new wasmModule.ToPdfParameterList();
// Set the parameter to disable hyperlinks
parameters.DisableLink = true;
// Save the document as a PDF file
const outputFileName = 'DisableHyperlinks.pdf';
doc.SaveToFile({ fileName: outputFileName, paramList: parameters });
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create download link
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// dispose
doc.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert Word to PDF Using JavaScript in React</h1>
<button onClick={convertWordToPdf} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
export default App;Convert Word to PDF with Bookmarks Preserved
Preserving bookmarks when converting a Word document to PDF enhances navigation in lengthy documents, allowing readers to quickly access specific sections. This feature improves usability and the overall experience of the PDF.
To create bookmarks in the output PDF document from the existing Word bookmarks, set the ToPdfParameterList.CreateWordBookmarks property to true.
The following is an example of preserving bookmarks when converting Word to PDF using JavaScript.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert Word to PDF
const convertWordToPdf = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('times.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbd.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Fetch the input file and add it to the VFS
const inputFileName = 'input.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new document
const doc = new wasmModule.Document();
// Load the word file
doc.LoadFromFile(inputFileName);
// Create a parameter list for the PDF conversion
let parameters = new wasmModule.ToPdfParameterList();
// Set the parameter to create bookmarks in the PDF from existing bookmarks in Word
parameters.CreateWordBookmarks = true;
// Save the document as a PDF file
const outputFileName = 'CreateBookmarks.pdf';
doc.SaveToFile({ fileName: outputFileName, paramList: parameters });
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create download link
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// dispose
doc.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert Word to PDF Using JavaScript in React</h1>
<button onClick={convertWordToPdf} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
export default App;
Convert Word to PDF with Custom Image Quality
If your Word document contains images, you may want to control the quality of these images in the PDF. This can help balance file size and quality.
Spire.Doc for JavaScript includes the Document.JPEGQuality property, which allows developers to set image compression quality on a scale from 1 to 100.
The following is an example of customizing image quality when converting Word to PDF using JavaScript.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to convert Word to PDF
const convertWordToPdf = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the font files into the virtual file system (VFS)
await window.spire.FetchFileToVFS('times.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbd.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesbi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
await window.spire.FetchFileToVFS('timesi.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/static/font/`);
// Fetch the input file and add it to the VFS
const inputFileName = 'input.docx';
await window.spire.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/static/data/`);
// Create a new document
const doc = new wasmModule.Document();
// Load the word file
doc.LoadFromFile(inputFileName);
// Set the output image quality to be 40% of the original image
doc.JPEGQuality = 40;
// Save the document as a PDF file
const outputFileName = 'CustomImageQuality.pdf';
doc.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.PDF });
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/pdf' });
// Create download link
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// dispose
doc.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert Word to PDF Using JavaScript in React</h1>
<button onClick={convertWordToPdf} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
export default App;Get a Free License
To fully experience the capabilities of Spire.Doc for JavaScript without any evaluation limitations, you can request a free 30-day trial license.
Python: Add, Extract and Remove Custom Document Properties in Word Documents
Custom document properties are user-defined fields within a Word document that store specific metadata. Unlike standard properties, such as title, author, or subject, which are predefined by Microsoft Word, these custom properties provide users with the flexibility to define and manage additional metadata fields according to their specific requirements. In this article, we will demonstrate how to add, extract, and remove custom document properties in Word documents in Python using Spire.Doc for Python.
- Add Custom Document Properties to Word in Python
- Extract Custom Document Properties in Word in Python
- Remove Custom Document Properties from Word in Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Add Custom Document Properties to Word in Python
Spire.Doc for Python provides the CustomDocumentProperties.Add() method, which enables developers to assign different types of values, such as text, time, numeric, or yes or no, to the custom properties of a Word document. The steps below demonstrate how to add custom document properties with different types of values to a Word document using Spire.Doc for Python.
- Initialize an instance of the Document class.
- Load a Word document using the Document.LoadFromFile() method.
- Get the custom document properties of the document through the Document.CustomDocumentProperties property.
- Add custom document properties with different data types to the document using the CustomDocumentProperties.Add(name, value) method.
- Save the result document using the Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word document
document.LoadFromFile("Example.docx")
# Add custom document properties with different types of values to the document
customProperties = document.CustomDocumentProperties
customProperties.Add("DocumentCategory", String("Technical Report"))
customProperties.Add("RevisionNumber", Int32(5))
customProperties.Add("LastReviewedDate", DateTime(2024, 12, 1, 0, 0, 0, 0))
customProperties.Add("RequiresFollowUp", Boolean(False))
# Save the result document
document.SaveToFile("AddCustomDocumentProperties.docx", FileFormat.Docx2016)
document.Close()

Extract Custom Document Properties in Word in Python
Extracting custom document properties allows developers to access metadata for further analysis, reporting, or integration into other applications. Spire.Doc for Python makes it simple to retrieve the details of these properties using the CustomDocumentProperty.Name and CustomDocumentProperty.Value properties. The detailed steps are as follows.
- Initialize an instance of the Document class.
- Load a Word document using the Document.LoadFromFile() method.
- Get the custom document properties of the document through the Document.CustomDocumentProperties property.
- Iterate through the custom document properties.
- Extract the name and value of each custom document property.
- Save the extracted data to a text file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word document
document.LoadFromFile("AddCustomDocumentProperties.docx")
# Open a text file to save the extracted custom properties
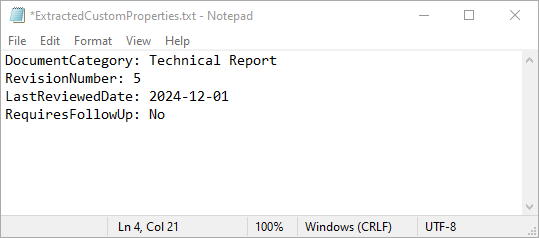
with open("ExtractedCustomProperties.txt", "w") as output_file:
# Iterate through all custom document properties
for i in range(document.CustomDocumentProperties.Count):
# Extract the name and value of each custom property
property_name = document.CustomDocumentProperties.get_Item(i).Name
property_value = document.CustomDocumentProperties.get_Item(i).Value
# Write the property details to the text file
output_file.write(f"{property_name}: {property_value}\n")
document.Close()
Remove Custom Document Properties from Word in Python
Cleaning up custom document properties is crucial for maintaining confidentiality, reducing file size, and ensuring metadata does not contain outdated or irrelevant information. Spire.Doc for Python allows developers to remove custom properties from a Word document using the DocumentProperties.Remove() method. The detailed steps are as follows.
- Initialize an instance of the Document class.
- Load a Word document using the Document.LoadFromFile() method.
- Get the custom document properties of the document through the Document.CustomDocumentProperties property.
- Iterate through the custom document properties.
- Remove each custom document property through its name using the DocumentProperties.Remove() method.
- Save the result document using the Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word document
document.LoadFromFile("AddCustomDocumentProperties.docx")
# Iterate through all custom document properties
customProperties = document.CustomDocumentProperties
for i in range(customProperties.Count - 1, -1, -1):
# Remove each custom document property by its name
customProperties.Remove(customProperties[i].Name)
# Save the result document
document.SaveToFile("RemoveCustomDocumentProperties.docx", FileFormat.Docx2016)
document.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
How to Integrate Spire.Doc for JavaScript in a React Project
Integrating document processing capabilities is crucial for enhancing user experience in many web applications, allowing for efficient report generation and data handling. React, with its component-based architecture, is an excellent choice for frontend development. By integrating Spire.Doc for JavaScript, you can effortlessly create and manage Word documents within your React application.
This guide will walk you through the steps to integrate Spire.Doc for JavaScript into your React projects, covering both setup and a usage example.
- Benefits of Using Spire.Doc for JavaScript in React
- Set Up Your Environment
- Integrate Spire.Doc for JavaScript in Your Project
- Create and Save Word Files Using JavaScript
Benefits of Using Spire.Doc for JavaScript in React
React, a popular JavaScript library for building user interfaces, has become a cornerstone in modern web development. On the other hand, Spire.Doc for JavaScript is a powerful library designed to simplify document processing in web applications.
By integrating Spire.Doc for JavaScript into your React project, you can add advanced Word document processing capabilities to your application. Here are some of the key advantages:
- Seamless Document Creation: Spire.Doc for JavaScript enables document creation and editing directly in React, streamlining management without external tools.
- Cross-Platform Compatibility: Spire.Doc for JavaScript allows document creation compatible with multiple platforms, enabling users to access and edit documents from anywhere.
- Rich Features: Spire.Doc for JavaScript offers extensive capabilities like text formatting, table creation, and image insertion, ideal for applications needing document manipulation.
- Seamless Integration: Compatible with various JavaScript frameworks, including React, Spire.Doc for JavaScript integrates easily into existing projects without disrupting your workflow.
Set Up Your Environment
Step 1. Install React and npm
Download and install Node.js from the official website. Make sure to choose the version that matches your operating system.
After the installation is complete, you can verify that Node.js and npm are working correctly by running the following commands in your terminal:
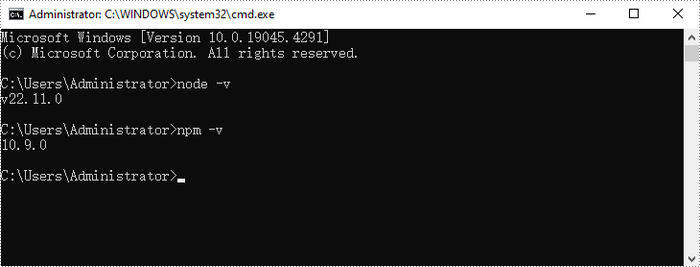
Step 2. Create a New React Project
Create a new React project named my-app using Create React App from terminal:
npx create-react-app my-app
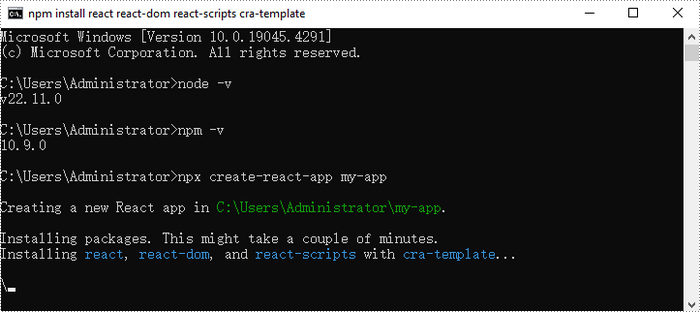
If your React project is compiled successfully, the app will be served at http://localhost:3000, allowing you to view and test your application in a browser.
To visually browse and manage the files in your project, you can open the project using VS Code.
Integrate Spire.Doc for JavaScript in Your Project
Download Spire.Doc for JavaScript from our website and unzip it to a location on your disk. The downloaded product package integrates Spire.Doc for JavaScript, Spire.XLS for JavaScript, Spire.PDF for JavaScript, and Spire.Presentation for JavaScript. To use the features of Spire.Doc for JavaScript, you need to copy the corresponding files (spire.doc.js, Spire.Doc.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and the _framework folder) to the public folder of your project.
You can also install using npm. In the terminal within VS Code, run the following command:
npm i spire.officeOnce the installation is complete, the product package files will be saved in the node_modules/spire.office path of your project. Copy the 5 files mentioned above into the "public" folder in your React project.
To ensure proper text rendering, you can add relevant font files with a custom path. In the following example, the font is added to the path: public\.
Create and Save Word Files Using JavaScript
Modify the code in the "App.js" file to generate a Word file using the WebAssembly (WASM) module. Specifically, utilize the Spire.Doc for JavaScript library for Word file manipulation.
Here is the entire code:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.Doc
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.doc.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.doc.js WASM module:', error);
}
})();
}, []);
// Function to generate word file
const createWord = async () => {
const wasmModule = window.wasmModule.spiredoc;
if (wasmModule) {
// Load the arial.ttf font file into the virtual file system (VFS)
await window.spire.FetchFileToVFS('arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Specify output file name
const outputFileName = 'HelloWorld.docx';
// Create a new document
const doc = new wasmModule.Document();
// Add a section
let section = doc.AddSection();
// Add a paragraph
let paragraph = section.AddParagraph();
// Append text to the paragraph
paragraph.AppendText('Hello, World!');
// Save the document to a Word file
doc.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.Docx2013 });
// Read the saved file and convert it to a Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' });
// Create a URL for the Blob and initiate the download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources
doc.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Create a Word File Using JavaScript in React</h1>
<button onClick={createWord} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
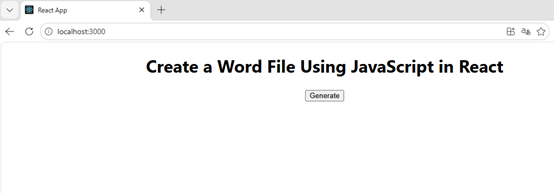
export default App; Start the development server by entering the following command in the terminal within VS Code: Once the React app is successfully compiled, it will open in your default web browser, typically at http://localhost:3000.Click "Generate" to create the 'HelloWorld.docx'. Click "Generate" and a "Save As" window will prompt you to save the output file in the designated folder. If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
npm start

Apply for a Temporary License
How to Integrate Spire.XLS for JavaScript in a React Project
In today's data-driven landscape, efficiently handling Excel files is crucial for web applications. React, a widely-used JavaScript library for user interfaces, can significantly enhance its capabilities by integrating Spire.XLS for JavaScript. This integration allows developers to perform complex operations like reading, writing, and formatting Excel files directly within their React projects.
This article will walk you through the integration of Spire.XLS for JavaScript into your React projects, covering everything from the initial setup to a straightforward usage example.
- Benefits of Using Spire.XLS for JavaScript in React Projects
- Set Up Your Environment
- Integrate Spire.XLS for JavaScript in Your Project
- Create and Save Excel Files Using JavaScript
Benefits of Using Spire.XLS for JavaScript in React Projects
React, a popular JavaScript library for building user interfaces, has revolutionized web development by enabling developers to create interactive and dynamic user experiences. On the other hand, Spire.XLS for JavaScript is a powerful library that allows developers to manipulate Excel files directly in the browser.
By integrating Spire.XLS for JavaScript into your React project, you can add advanced Excel capabilities to your application. Here are some of the key advantages:
- Enhanced Functionality: Spire.XLS for JavaScript enables creating, modifying, and formatting Excel files directly in the browser, enhancing your React app's capabilities and user experience.
- Improved Data Management: Easily import, export, and manipulate Excel files with Spire.XLS, streamlining data management and reducing errors.
- Cross-Browser Compatibility: Designed to work seamlessly across major web browsers, Spire.XLS ensures consistent handling of Excel files in your React application.
- Seamless Integration: Compatible with various JavaScript frameworks, including React, Spire.XLS integrates easily into existing projects without disrupting your workflow.
Set Up Your Environment
Step 1. Install Node.js and npm
Download and install Node.js from the official website. Make sure to choose the version that matches your operating system.
After the installation is complete, you can verify that Node.js and npm are working correctly by running the following commands in your terminal:
node -v npm -v

Step 2. Create a New React Project
Create a new React project named my-app using Create React App from terminal:
npx create-react-app my-app
Once the project is created, you can navigate to the project directory and start the development server using the following commands:
cd my-app npm start

If your React project is compiled successfully, the app will be served at http://localhost:3000, allowing you to view and test your application in a browser.
To visually browse and manage the files in your project, you can open the project using VS Code.

Integrate Spire.XLS for JavaScript in Your Project
Download Spire.XLS for JavaScript from our website and unzip it to a location on your disk. The downloaded product package has been integrated Spire.Doc for JavaScript,Spire.XLS for JavaScript,Spire.PDF for JavaScript,Spire.Presentation for JavaScript. To use the functionality of Spire.XLS for JavaScript, you need to copy the corresponding files (spire.xls.js, Spire.Xls.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and _framework) to the project's “public” folder.
You can also install Spire.XLS for JavaScript using npm. In the terminal within VS Code, run the following command:
npm i spire.office
After downloading this command, find the corresponding file in the node_comodules/spire.office path of the project and copy it to “public” folder.
At the same time, in order to ensure text rendering, the related font files can be added with custom paths. In the following example, the font addition path is: public\font.
Create Excel files using JavaScript
Modify the code in the "App.js" file to generate an Excel file using the WebAssembly (WASM) module. Specifically, utilize the Spire.XLS for JavaScript library for Excel file manipulation.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
const [wasmModule, setWasmModule] = useState(null);
// Load Spire.XLS
useEffect(() => {
(async () => {
try {
const publicUrl = process.env.PUBLIC_URL || '';
const spireModule = await import(/* webpackIgnore: true */ `${publicUrl}/spire.xls.js`);
const rawModule = spireModule.default || spireModule;
window.wasmModule = typeof rawModule === 'function'
? await rawModule({ locateFile: p => p.endsWith('.wasm') ? `${publicUrl}/${p}` : p })
: rawModule;
setWasmModule(window.wasmModule);
} catch (error) {
console.error('Failed to load spire.xls.js WASM module:', error);
}
})();
}, []);
// Create HelloWorld.xlsx
const ExcelToPDF = async () => {
const wasmModule = window.wasmModule.spirexls;
if (wasmModule) {
// Load font into virtual file system (VFS)
await window.spire.FetchFileToVFS('arial.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/font/`);
// Create a new workbook
const workbook = new wasmModule.Workbook();
// Clear default worksheets
workbook.Worksheets.Clear();
// Add a new worksheet named "MySheet"
const sheet = workbook.Worksheets.Add("MySheet");
// Set the text of cell "A1"
sheet.Range.get("A1").Text = "Hello World";
// Set column width to auto-fit
sheet.Range.get("A1").AutoFitColumns();
// Define output file name
const outputFileName = 'HelloWorld.xlsx';
// Save the workbook to the specified path
workbook.SaveToFile({ fileName: outputFileName, version: wasmModule.ExcelVersion.Version2010 });
// Read the saved file and convert to Blob object
const modifiedFileArray = window.dotnetRuntime.Module.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet' });
// Create a URL for the Blob and start download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbook
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Create HelloWorld.xlsx</h1>
<button onClick={ExcelToPDF} disabled={!wasmModule}>
Generate
</button>
</div>
);
}
export default App;
Using "npm start" to run the program, and click "Generate" to download the generated Excel file.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
How to Integrate Spire.Doc for JavaScript in a Node.js Project
Document processing is an essential feature in many modern web applications, enabling tasks such as report generation and data management. Node.js, known for its non-blocking I/O model and extensive ecosystem, provides a powerful platform for backend development. By integrating Spire.Doc for JavaScript, you can streamline the creation and manipulation of Word documents effortlessly.
This guide will take you through the steps to integrate Spire.Doc for JavaScript into your Node.js projects, from initial setup to a basic usage example.
- Benefits of Using Spire.Doc for JavaScript in Node.js Projects
- Set Up Your Environment
- Integrate Spire.Doc for JavaScript in Your Project
- Create and Save Word Files Using JavaScript
Benefits of Using Spire.Doc for JavaScript in Node.js Projects
Node.js is a powerful runtime environment that allows developers to build scalable network applications using JavaScript. Spire.Doc for JavaScript, on the other hand, is a versatile library designed to manipulate Word documents within JavaScript environments. It provides a wide range of features, including document creation, editing, conversion, and more, making it a valuable tool for developers working with document-based applications.
Integrating Spire.Doc for JavaScript into your Node.js project offers numerous benefits, including:
- Efficient Document Management: Easily create, edit, and manage Word documents without the need for Microsoft Word.
- Scalability: Leverage Node.js's non-blocking I/O model to handle large volumes of document processing tasks efficiently.
- Cross-Platform Compatibility: Use Spire.Doc for JavaScript across various platforms, including Windows, macOS, and Linux.
- Ease of Integration: Seamlessly integrate Spire.Doc for JavaScript with other Node.js libraries and tools.
These benefits make Spire.Doc for JavaScript an ideal choice for developers looking to enhance their Node.js projects with robust document processing capabilities.
Set Up Your Environment
Step 1
Download and install Node.js from the official website. Make sure to choose the version that matches your operating system.
After the installation is complete, you can verify that Node.js and npm are installed correctly, along with the version numbers, by entering the following commands in CMD:
node -v npm -v
Step 2
Initialize a Node.js project:
npm init -yInstallation dependencies:
npm install adm-zip@^0.5.16 Configure packaging.json: Customize folder in the root directory to put some font files, you can customize and add fonts based on the font used in your documents. Download Spire.Doc for JavaScript from our website and unzip it to a location on your disk. The downloaded product package integrates Spire.Doc for JavaScript, Spire.XLS for JavaScript, Spire.PDF for JavaScript, and Spire.Presentation for JavaScript. To use the features of Spire.Doc for JavaScript, customize the folder in the root directory, this tutorial defined the 'wasm' folder, and copy the corresponding files (spire.doc.js, Spire.Doc.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and the _framework folder) to the “wasm” folder. Add the 'index.js' file to the root directory of the project and set the following content to create a simple Word file Here is the entire JavaScript code: Using “npm start” run the program, you will find the generated Word file in the designated file path. If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
{
"name": "nodejstest",
"version": "1.0.0",
"description": "Simple test project to generate HelloWorld.docx using spire.doc.js",
"main": "index.js",
"type": "module",
"scripts": {
"start": "node --experimental-modules --experimental-wasm-modules --experimental-vm-modules index.js"
},
"dependencies": {
"adm-zip": "^0.5.16"
}
}
Integrate Spire.Doc for JavaScript in Your Project
//NodeJSTest----create "HelloWorld.docx"
import fs from 'fs/promises';
import path from 'path';
import { fileURLToPath } from 'url';
import AdmZip from 'adm-zip';
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
async function extractWasmFiles() {
const wasmDir = path.join(__dirname, 'wasm');
const frameworkDir = path.join(wasmDir, '_framework');
await fs.mkdir(frameworkDir, { recursive: true });
for (const zipName of ['Spire.Common.Wasm.zip', 'Spire.Doc.Wasm.zip']) {
const zipPath = path.join(wasmDir, zipName);
try {
await fs.access(zipPath);
new AdmZip(zipPath).extractAllTo(wasmDir, true);
} catch {}
}
}
async function main() {
try {
await extractWasmFiles();
const { spiredoc } = await import('./wasm/spire.doc.js');
const spire = globalThis.spire;
if (!spire) throw new Error('WASM module not loaded correctly');
const outputDir = path.join(__dirname, 'output');
await fs.mkdir(outputDir, { recursive: true });
const fontsPath = path.join(__dirname, 'fonts');
try {
await fs.access(fontsPath);
spire.copyLocalPathToVFS(fontsPath, '/Library/Fonts/');
} catch {}
const document = new spiredoc.Document();
document.AddSection().AddParagraph().AppendText('Hello World');
const outputFileName = 'HelloWorld2.docx';
document.SaveToFile({ fileName: outputFileName, fileFormat: spiredoc.FileFormat.Docx2013 });
const outputFile = path.join(outputDir, outputFileName);
spire.copyFileFromFSToLocalStorage(outputFileName, outputFile);
document.Dispose();
console.log(`Document saved to ${outputFile}`);
} catch (error) {
console.error(error);
process.exit(1);
}
}
main();
Apply for a Temporary License
How to Integrate Spire.XLS for JavaScript in a Node.js Project
Excel manipulation is a crucial aspect of many modern web applications, from data analysis to report generation. Node.js, with its non-blocking I/O model and rich ecosystem, is an excellent choice for backend development. When combined with Spire.XLS for JavaScript, you can unlock a world of possibilities for handling Excel files efficiently.
This guide will walk you through the process of integrating Spire.XLS for JavaScript into your Node.js projects, covering everything from initial setup to generating a simple Excel document.
- Benefits of Using Spire.XLS for JavaScript in Node.js Projects
- Set Up Your Environment
- Integrate Spire.XLS for JavaScript in Your Project
- Create and Save Excel Files Using JavaScript
Benefits of Using Spire.XLS for JavaScript in Node.js Projects
Node.js is a great option for developing scalable network applications. When paired with Spire.XLS for JavaScript, you get a robust solution for handling Excel files. Here are some key features and benefits of using Spire.XLS for JavaScript in Node.js projects:
- Comprehensive Excel Support: Spire.XLS for JavaScript supports a wide range of Excel features, including formulas, charts, pivot tables, and more.
- High Performance: The library is optimized for speed, ensuring that your application remains responsive even when handling large datasets.
- Cross-Platform Compatibility: With Node.js, you can run your application on any platform that supports JavaScript, including Windows, macOS, and Linux.
- Secure and Reliable: The library is designed to be secure, with features like data validation and encryption to protect your data.
By leveraging the strengths of both Node.js and Spire.XLS for JavaScript, you can build powerful applications that handle Excel files with ease.
Set Up Your Environment
Step 1
Download and install Node.js from the official website. Make sure to choose the version that matches your operating system.
After the installation is complete, you can verify that Node.js and npm are installed correctly, along with the version numbers, by entering the following commands in CMD:
node -v npm -v
Step 2
Initialize a Node.js project:
npm init -y
Installation dependencies:
npm install adm-zip@^0.5.16
Configure packaging.json:
{
"name": "nodejstest",
"version": "1.0.0",
"description": "Simple test project to generate HelloWorld.xlsx using spire.xls.js",
"main": "index.js",
"type": "module",
"scripts": {
"start": "node --experimental-modules --experimental-wasm-modules --experimental-vm-modules index.js"
},
"dependencies": {
"adm-zip": "^0.5.16"
}
}
Customize folder in the root directory to put some font files, you can customize and add fonts based on the font used in your documents.
Integrate Spire.XLS for JavaScript in Your Project
Download Spire.XLS for JavaScript and unzip it to a location on your disk. The downloaded product package integrates Spire.Doc for JavaScript, Spire.XLS for JavaScript, Spire.PDF for JavaScript, and Spire.Presentation for JavaScript. To use the features of Spire.XLS for JavaScript, customize the folder in the root directory, this tutorial defined the 'wasm' folder, and copy the corresponding files (spire.xls.js, Spire.Xls.Wasm.zip, spire.common.js, Spire.Common.Wasm.zip, and the _framework folder) to the “wasm” folder.
Add the 'index.js' file to the root directory of the project and set the following content to create a simple Excel file
- JavaScript
//NodeJSTest----create "HelloWorld.xlsx"
import fs from 'fs/promises';
import path from 'path';
import { fileURLToPath } from 'url';
import AdmZip from 'adm-zip';
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
async function extractWasmFiles() {
const wasmDir = path.join(__dirname, 'wasm');
const frameworkDir = path.join(wasmDir, '_framework');
await fs.mkdir(frameworkDir, { recursive: true });
for (const zipName of ['Spire.Common.Wasm.zip', 'Spire.Xls.Wasm.zip']) {
const zipPath = path.join(wasmDir, zipName);
try {
await fs.access(zipPath);
new AdmZip(zipPath).extractAllTo(wasmDir, true);
} catch { }
}
}
async function main() {
try {
await extractWasmFiles();
const { spirexls } = await import('./wasm/spire.xls.js');
const spire = globalThis.spire;
if (!spire) throw new Error('WASM module not loaded correctly');
const outputDir = path.join(__dirname, 'output');
await fs.mkdir(outputDir, { recursive: true });
const fontsPath = path.join(__dirname, 'fonts');
try {
await fs.access(fontsPath);
spire.copyLocalPathToVFS(fontsPath, '/Library/Fonts/');
} catch { }
// Create a new workbook
const workbook = new spirexls.Workbook();
// Clear default worksheets
workbook.Worksheets.Clear();
// Add a new worksheet named "MySheet"
const sheet = workbook.Worksheets.Add("MySheet");
// Set text for the "A1" range
sheet.Range.get("A1").Text = "Hello World";
// Set the column width to auto fit
sheet.Range.get("A1").AutoFitColumns();
// Define the output file name
const outputFileName = 'HelloWorld.xlsx';
// Save the workbook to the specified path
workbook.SaveToFile({ fileName: outputFileName, version: spirexls.ExcelVersion.Version2010 });
const outputFile = path.join(outputDir, outputFileName);
spire.copyFileFromFSToLocalStorage(outputFileName, outputFile);
workbook.Dispose();
console.log(`Document saved to ${outputFile}`);
} catch (error) {
console.error(error);
process.exit(1);
}
}
main();
Using “npm start” run the program, you will find the generated Word file in the designated file path.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Insert, Retrieve, Reorder, and Remove Slides in PowerPoint Sections
PowerPoint presentations are a powerful tool for presenting information in an organized and engaging manner. To further enhance the organization of slides, PowerPoint allows users to group slides into sections. This feature makes navigating and managing large presentations much easier. In this article, we'll show you how to manage slides within PowerPoint sections in Python using Spire.Presentation for Python. Specifically, we'll cover how to add, retrieve, reorder, and remove slides in these sections.
- Insert Slides into a PowerPoint Section in Python
- Retrieve Slides from a PowerPoint Section in Python
- Reorder Slides in a PowerPoint Section in Python
- Remove Slides from a PowerPoint Section in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Insert Slides into a PowerPoint Section in Python
Inserting slides is essential when you want to introduce new content to a section. Using Spire.Presentation for Python, you can quickly insert a slide into a section with the Section.Insert() method. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Get a specific section through its index (0-based) using the Presentation.SectionList(index) property.
- Add a new slide to the presentation, then insert it into the section using the Section.Insert() method.
- Remove the added slide from the presentation.
- Save the resulting presentation using the Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Example.pptx")
# Access the first section
first_section = presentation.SectionList.get_Item(0)
# Add a new slide to the presentation and insert it at the start of the section
slide = presentation.Slides.Append()
first_section.Insert(0, slide)
# Remove the added slide from the presentation
presentation.Slides.Remove(slide)
# Save the modified presentation
presentation.SaveToFile("InsertSlidesInSection.pptx", FileFormat.Pptx2016)
# Close the Presentation object
presentation.Dispose()
Retrieve Slides from a PowerPoint Section in Python
Retrieving slides from a specific section allows you to focus on a smaller group of slides for tasks such as reordering or applying custom formatting. Using the Section.GetSlides() method in Spire.Presentation for Python, you can easily access all the slides in a particular section. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Get a specific section through its index (0-based) using the Presentation.SectionList(index) property.
- Retrieve the slides within the section using the Section.GetSlides() method.
- Iterate through the retrieved slides and get the slide number (1-based) of each slide.
- Python
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Example.pptx")
# Retrieve the slides in the 3rd section
section = presentation.SectionList.get_Item(2)
slides = section.GetSlides()
output_content = "The slide numbers in this section are:\n"
# Get the slide number of each slide in the section
for slide in slides:
output_content += str(slide.SlideNumber) + " "
# Save the slide number to a text file
with open("slide_numbers.txt", "w") as file:
file.write(output_content)

Reorder Slides in a PowerPoint Section in Python
Reordering slides is important to ensure related content is in the right order. Spire.Presentation for Python offers the Section.Move() method, which allows you to move a slide to a new position within a section. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Get a specific section through its index (0-based) using the Presentation.SectionList(index) property.
- Move a specific slide in the section to another position using the Section.Move() method.
- Save the resulting presentation using the Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Example.pptx")
# Access the 3rd section
section = presentation.SectionList.get_Item(2)
# Retrieve the slides in the section
slides = section.GetSlides()
# Move the 1st slide in the section to the specified position
section.Move(2, slides[0])
# Save the modified presentation
presentation.SaveToFile("ReorderSlidesInSection.pptx", FileFormat.Pptx2016)
# Close the Presentation object
presentation.Dispose()
Remove Slides from a PowerPoint Section in Python
Removing slides from a section streamlines your presentation, particularly when some slides become outdated or unnecessary. With Spire.Presentation for Python, you can easily remove a single slide or multiple slides from a section using the Section.RemoveAt() or Section.RemoveRange() method. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Get a specific section through its index (0-based) using the Presentation.SectionList(index) property.
- Remove a specific slide or a range of slides from the presentation using the Section.RemoveAt() or Section.RemoveRange() method.
- Save the resulting presentation using the Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Example.pptx")
# Access the 3rd section
section = presentation.SectionList.get_Item(2)
# Remove the first slide from the section
section.RemoveAt(0)
# Or remove a range of slides from the section
# section.RemoveRange(0, 2)
# Save the modified presentation
presentation.SaveToFile("RemoveSlidesInSection.pptx", FileFormat.Pptx2016)
# Close the Presentation object
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Extract Annotations from PDF
Annotations in PDF documents play a crucial role in enhancing collaboration, emphasizing key points, or providing additional context. Extracting annotations is essential for efficiently analyzing PDF content, but manual extraction can be tedious. This guide demonstrates how to extract annotations from PDF with Python using Spire.PDF for Python, providing a faster and more flexible solution to access important information.
- Extract Specified Annotations from PDF Documents
- Extract All Annotations from a PDF Page
- Extract All Annotations from PDF Files
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install it, please refer to this tutorial: How to Install Spire.PDF for Python on Windows.
Extract Specified Annotations from PDF Documents
Although Adobe Acrobat offers a built-in one-click annotation extraction feature, it lacks flexibility when handling specific annotations. If you only need to extract one or a few annotations, you must manually locate and copy them, which can be inefficient, especially when working with PDFs containing multiple annotations. Spire.PDF (short for Spire.PDF for Python), however, provides the PdfAnnotationCollection.get_item() method, enabling targeted extraction of specific annotations, making PDF annotation management more flexible and efficient.
Steps to extract specified annotations from PDF:
- Create an object of PdfDocument class.
- Load a PDF document from the local storage with PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages[] property, and access the annotations collection with PdfPageBase.AnnotationsWidget property.
- Create a list to store annotation information.
- Access the specified annotation using PdfAnnotationCollection.get_Item() method.
- Append annotation details to the list.
- Save the list as a Text file.
Here is the code example of exporting the first annotation on the third page:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
pdf = PdfDocument()
# Load the file from disk
pdf.LoadFromFile( "Sample.pdf")
# Get the third page
page = doc.Pages.get_Item(2)
# Access the annotations on the page
annotations = page.AnnotationsWidget
# Create a list to save information of annotations
sb = []
# Access the first annotation on the page
annotation = annotations.get_Item(0)
# Append the annotation details to the list
sb.append("Annotation information: ")
sb.append("Text: " + annotation.Text)
modifiedDate = annotation.ModifiedDate.ToString()
sb.append("ModifiedDate: " + modifiedDate)
# Save the list as a Text file
with open("GetSpecificAnnotation.txt", "w", encoding="utf-8") as file:
file.write("\n".join(sb))
# Close the PDF file
pdf.Close()
Extract All Annotations from a PDF Page
To export all annotations from a specified PDF page, you can still use the PdfPageBase.AnnotationsWidget property along with the PdfAnnotationCollection.get_item() method. However, you will need to iterate through all the annotations on the page to ensure none are missed. Below are the steps and code examples to guide you through the process.
Steps to extract annotations from PDF pages:
- Create a PdfDocument instance.
- Read a PDF document from the local storage with PdfDocument.LoadFromFile() method.
- Access the annotation collection on the specified page using PdfDocument.Pages.AnnotationsWidget property.
- Create a list to store annotation information.
- Loop through annotations on a certain page.
- Retrieve each annotation using PdfAnnotationCollection.get_Item() method.
- Add annotation details to the list.
- Save the list as a Text file.
Below is the code example of extracting all annotations on the second page:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
pdf = PdfDocument()
# Load the file from disk
pdf.LoadFromFile("Sample.pdf")
# Get all annotations from the second page
annotations = pdf.Pages.get_Item(1).AnnotationsWidget
# Create a list to maintain annotation details
sb = []
# Loop through annotations on the page
if annotations.Count > 0:
for i in range(annotations.Count):
# Get the current annotation
annotation = annotations.get_Item(i)
# Get the annotation details
if isinstance(annotation, PdfPopupAnnotationWidget):
continue
sb.append("Annotation information: ")
sb.append("Text: " + annotation.Text)
modifiedDate = annotation.ModifiedDate.ToString()
sb.append("ModifiedDate: " + modifiedDate)
# Save annotations as a Text file
with open("GetAllAnnotationsFromPage.txt", "w", encoding="utf-8") as file:
file.write("\n".join(sb))
# Release resources
pdf.Close()
Extract All Annotations from PDF Files
The final section of this guide illustrates how to extract all annotations from a PDF document using Python. The process is similar to exporting annotations from a single page but involves iterating through each page, traversing all annotations, and accessing their details. Finally, the extracted annotation details are saved to a text file for further use. Let’s take a closer look at the detailed steps.
Steps to extract all annotations from a PDF document:
- Create an instance of PdfDocument class.
- Read a PDF document from the disk with PdfDocument.LoadFromFile() method.
- Initialize a list to store annotation information.
- Loop through all pages and access the annotation collection with PdfDocument.Pages.AnnotationsWidget property.
- Iterate each annotation in the collection and get annotations using PdfAnnotationCollection.get_item() method.
- Append annotation details to the list.
- Output the list as a Text file.
Here is an example of exporting all annotations from a PDF file:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
pdf = PdfDocument()
# Load the file from disk
pdf.LoadFromFile("Sample.pdf")
# Create a list to save annotation details
sb = []
# Iterate through all pages in the PDF document
for pageIndex in range(pdf.Pages.Count):
sb.append(f"Page {pageIndex + 1}:")
# Access the annotation collection of the current page
annotations = pdf.Pages.get_Item(pageIndex).AnnotationsWidget
# Loop through annotations in the collection
if annotations.Count > 0:
for i in range(annotations.Count):
# Get the annotations of the current page
annotation = annotations.get_Item(i)
# Skip invalid annotations (empty text and default date)
if not annotation.Text.strip() and annotation.ModifiedDate.ToString() == "0001/1/1 0:00:00":
continue
# Extract annotation information
sb.append("Annotation information: ")
sb.append("Text: " + (annotation.Text.strip() or "N/A"))
modifiedDate = annotation.ModifiedDate.ToString()
sb.append("ModifiedDate: " + modifiedDate)
else:
sb.append("No annotations found.")
# Add a blank line after each page
sb.append("")
# Save all annotations to a file
with open("GetAllAnnotationsFromDocument.txt", "w", encoding="utf-8") as file:
file.write("\n".join(sb))
# Close the PDF document
pdf.Close()
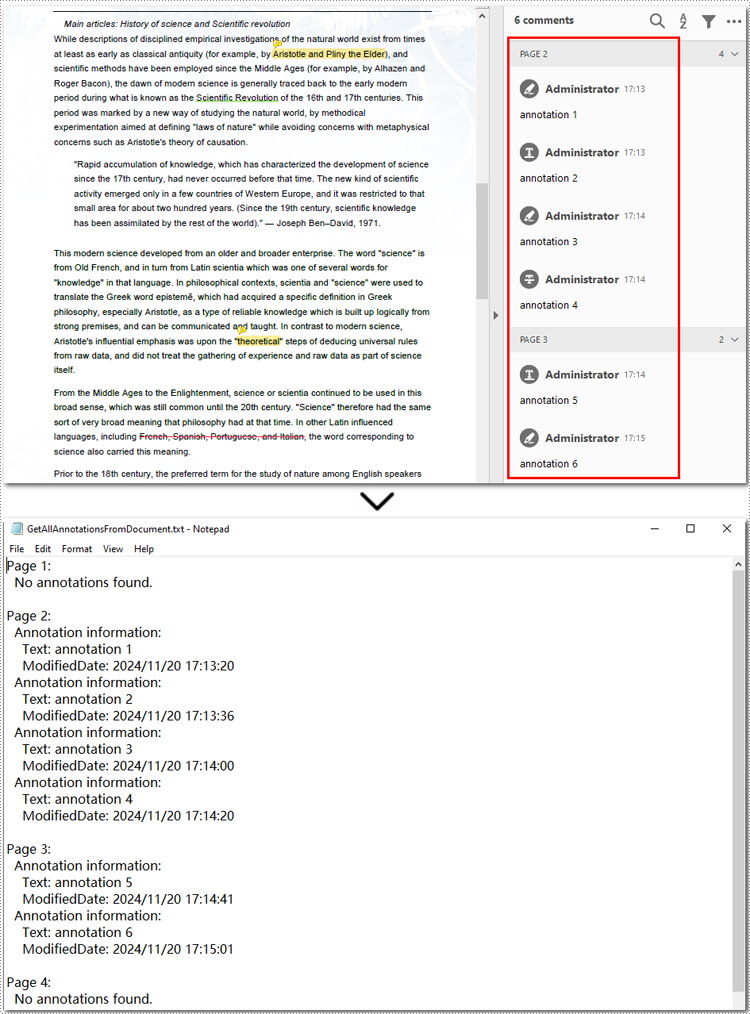
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Split PowerPoint Presentations
Splitting a PowerPoint presentation into smaller files or individual sections can be useful in various situations. For instance, when collaborating with a team, each member may only need a specific section of the presentation to work on. Additionally, breaking a large presentation into smaller parts can simplify sharing over email or uploading to platforms with file size restrictions. In this article, we'll show you how to split PowerPoint presentations by slides, slide ranges, and sections in Python using Spire.Presentation for Python.
- Split PowerPoint Presentations by Slides in Python
- Split PowerPoint Presentations by Slide Ranges in Python
- Split PowerPoint Presentations by Sections in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Split PowerPoint Presentations by Slides in Python
Developers can use Spire.Presentation for Python to split a PowerPoint presentation into individual slides by iterating through the slides in the presentation and adding each slide to a new presentation. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Iterate through all slides in the presentation:
- Access the current slide through the Presentation.Slides[index] property.
- Create a new PowerPoint presentation using the Presentation class and remove its default slide using the Presentation.Slides.RemoveAt(0) method.
- Append the current slide to the new presentation using the Presentation.Slides.AppendBySlide() method.
- Save the new presentation as a file using the ISlide.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Iterate through all slides in the presentation
for i in range(presentation.Slides.Count):
# Get the current slide
slide = presentation.Slides[i]
# Create a new PowerPoint presentation and remove its default slide
newPresentation = Presentation()
newPresentation.Slides.RemoveAt(0)
# Append the current slide to the new presentation
newPresentation.Slides.AppendBySlide(slide)
# Save the new presentation as a file
newPresentation.SaveToFile(f"output/Presentations/Slide-{i + 1}.pptx", FileFormat.Pptx2013)
newPresentation.Dispose()
presentation.Dispose()
Split PowerPoint Presentations by Slide Ranges in Python
Apart from splitting a PowerPoint presentation into individual slides, developers can also divide it into specific ranges of slides by adding the desired slides to new presentations. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Create new PowerPoint presentations using the Presentation class and remove the default slides within them using the Presentation.Slides.RemoveAt(0) method.
- Append specified ranges of slides to the new presentations using the Presentation.Slides.AppendBySlide() method.
- Save the new presentations as files using the Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Create two new PowerPoint presentations and remove their default slides
presentation1 = Presentation()
presentation2 = Presentation()
presentation1.Slides.RemoveAt(0)
presentation2.Slides.RemoveAt(0)
# Append slides 1-3 to the first new presentation
for i in range(3):
presentation1.Slides.AppendBySlide(presentation.Slides[i])
# Append the remaining slides to the second new presentation
for i in range(3, presentation.Slides.Count):
presentation2.Slides.AppendBySlide(presentation.Slides[i])
# Save the new presentations as files
presentation1.SaveToFile("output/Presentations/SlideRange1.pptx", FileFormat.Pptx2013)
presentation2.SaveToFile("output/Presentations/SlideRange2.pptx", FileFormat.Pptx2013)
presentation1.Dispose()
presentation2.Dispose()
presentation.Dispose()
Split PowerPoint Presentations by Sections in Python
Sections in PowerPoint are often used to organize slides into manageable groups. With Spire.Presentation for Python, developers can split a PowerPoint presentation into sections by iterating through the sections in the presentation and adding the slides within each section to a new presentation. The detailed steps are as follows.
- Create an instance of the Presentation class.
- Load a PowerPoint presentation using the Presentation.LoadFromFile() method.
- Iterate through all sections in the presentation:
- Access the current section through the Presentation.SectionList[] property.
- Create a new PowerPoint presentation using the Presentation class and remove its default slide using the Presentation.Slides.RemoveAt(0) method.
- Add a section to the new presentation with the same name using the Presentation.SectionList.Append() method.
- Retrieve the slides of the current section using the Section.GetSlides() method.
- Iterate through the retrieved slides and add them to the section of the new presentation using the Section.Insert() method.
- Save the new presentation as a file using the Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
presentation = Presentation()
# Load a PowerPoint presentation
presentation.LoadFromFile("Sample.pptx")
# Iterate through all sections
for i in range(presentation.SectionList.Count):
# Get the current section
section = presentation.SectionList.get_Item(0)
# Create a new PowerPoint presentation and remove its default slide
newPresentation = Presentation()
newPresentation.Slides.RemoveAt(0)
# Add a section to the new presentation
newSection = newPresentation.SectionList.Append(section.Name)
# Retrieve the slides of the current section
slides = section.GetSlides()
# Insert each retrieved slide into the section of the new presentation
for slide_index, slide in enumerate(slides):
newSection.Insert(slide_index, slide)
# Save the new presentation as a file
newPresentation.SaveToFile(f"output/Presentations/Section-{i + 1}.pptx", FileFormat.Pptx2019)
newPresentation.Dispose()
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.