
Knowledgebase (2370)
Children categories
A table is a structured way of organizing and presenting data in rows and columns. It usually consists of horizontal rows and vertical columns, and each intersection can contain text, numbers, or other types of data. By inserting a table into a presentation, users can create or display structured data on slides to make the content more organized. In addition, compared to text forms, tabular data can be more intuitive to show the differences between data, which helps readers understand more, thus enhancing the professionalism and readability of the presentation. This article is going to show how to use Spire.Presentation for Python to create or edit a table in a PowerPoint Presentation in Python programs.
- Insert Tables into PowerPoint Presentations in Python
- Edit Tables in PowerPoint Presentations in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Insert Tables into PowerPoint Presentations in Python
Spire.Presentation for Python provides the Presentation.Slides[].Shapes.AppendTable(x: float, y: float, widths: List[float], heights: List[float]) method to add a table to a PowerPoint presentation. The detailed steps are as follows.
- Create an object of Presentation class.
- Load a sample presentation from disk using Presentation.LoadFromFile() method.
- Define the dimensions of the table.
- Add a new table to the sample presentation by calling Presentation.Slides[].Shapes.AppendTable(x: float, y: float, widths: List[float], heights: List[float]) method.
- Define the table data as a two-dimensional string array.
- Loop through the arrays and fill each cell of the table with these data by ITable[columnIndex, rowIndex].TextFrame.Text property.
- Set font name and font size for these data.
- Set the alignment of the first row in the table to center.
- Apply a built-in style to the table using ITable.StylePreset property.
- Save the result file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
import math
from spire.presentation import *
inputFile = "C:/Users/Administrator/Desktop/Sample.pptx"
outputFile = "C:/Users/Administrator/Desktop/CreateTable.pptx"
#Create an object of Presentation class
presentation = Presentation()
#Load a sample presentation from disk
presentation.LoadFromFile(inputFile)
#Define the dimensions of the table
widths = [100, 100, 150, 100, 100]
heights = [15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15]
#Add a new table to this presentation
left = math.trunc(presentation.SlideSize.Size.Width / float(2)) - 275
table = presentation.Slides[0].Shapes.AppendTable(left, 90, widths, heights)
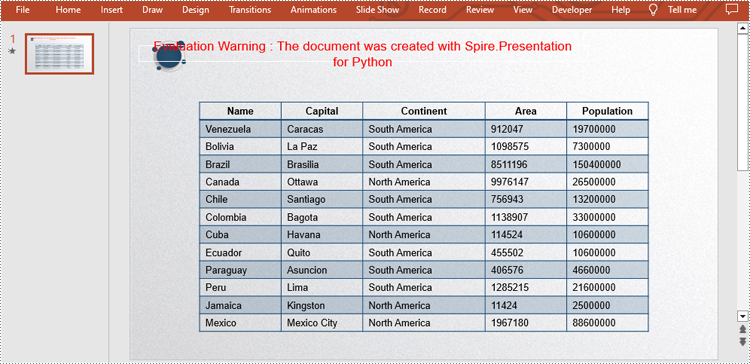
#Define the table data as a two-dimensional string array
dataStr = [["Name", "Capital", "Continent", "Area", "Population"],
["Venezuela", "Caracas", "South America", "912047", "19700000"],
["Bolivia", "La Paz", "South America", "1098575", "7300000"],
["Brazil", "Brasilia", "South America", "8511196", "150400000"],
["Canada", "Ottawa", "North America", "9976147", "26500000"],
["Chile", "Santiago", "South America", "756943", "13200000"],
["Colombia", "Bagota", "South America", "1138907", "33000000"],
["Cuba", "Havana", "North America", "114524", "10600000"],
["Ecuador", "Quito", "South America", "455502", "10600000"],
["Paraguay", "Asuncion", "South America", "406576", "4660000"],
["Peru", "Lima", "South America", "1285215", "21600000"],
["Jamaica", "Kingston", "North America", "11424", "2500000"],
["Mexico", "Mexico City", "North America", "1967180", "88600000"]]
#Loop through the arrays
for i in range(0, 13):
for j in range(0, 5):
#Fill each cell of the table with these data
table[j,i].TextFrame.Text = dataStr[i][j]
#Set font name and font size
table[j,i].TextFrame.Paragraphs[0].TextRanges[0].LatinFont = TextFont("Arial")
table[j,i].TextFrame.Paragraphs[0].TextRanges[0].FontHeight = 12
#Set the alignment of the first row in the table to center
for i in range(0, 5):
table[i,0].TextFrame.Paragraphs[0].Alignment = TextAlignmentType.Center
#Apply a style to the table
table.StylePreset = TableStylePreset.LightStyle3Accent1
#Save the result file
presentation.SaveToFile(outputFile, FileFormat.Pptx2010)
presentation.Dispose()
Edit Tables in PowerPoint Presentations in Python
You are also allowed to edit tables in the presentation as needed, such as replacing data, changing styles, highlighting data, and so on. Here are the detailed steps.
- Create an object of Presentation class.
- Load a sample presentation from disk using Presentation.LoadFromFile() method.
- Store the data used for replacement in a string.
- Loop through the shapes in the first slide, and determine if a certain shape is a table. If yes, convert it to an ITable object.
- Change the style of the table using ITable.StylePreset property.
- Replace the data in a specific cell range by using ITable[columnIndex, rowIndex].TextFrame.Text property.
- Highlight the new data using ITable[columnIndex, rowIndex].TextFrame.TextRange.HighlightColor.Color property.
- Save the result file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
inputFile = "C:/Users/Administrator/Desktop/CreateTable.pptx"
outputFile = "C:/Users/Administrator/Desktop/EditTable.pptx"
#Create an object of Presentation class
presentation = Presentation()
#Load a sample presentation from disk
presentation.LoadFromFile(inputFile)
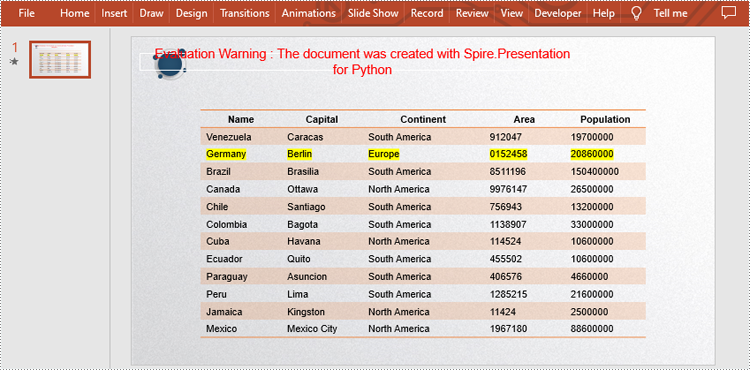
#Store the data used in replacement in a string
strs = ["Germany", "Berlin", "Europe", "0152458", "20860000"]
table = None
#Loop through shapes in the first slide to get the table
for shape in presentation.Slides[0].Shapes:
if isinstance(shape, ITable):
table = shape
#Change the style of the table
table.StylePreset = TableStylePreset.LightStyle1Accent2
for i, unusedItem in enumerate(table.ColumnsList):
#Replace the data in a specific cell range
table[i,2].TextFrame.Text = strs[i]
#Highlight the new data
table[i,2].TextFrame.TextRange.HighlightColor.Color = Color.get_Yellow()
#Save the result file
presentation.SaveToFile(outputFile, FileFormat.Pptx2013)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Grouping shapes in PowerPoint can greatly simplify the shape editing process, especially when dealing with complex arrangements of shapes. It allows you to modify the entire group collectively, saving time and effort compared to adjusting each shape individually. This is particularly beneficial when you need to apply consistent formatting or positioning to a set of shapes. Ungrouping shapes provides increased flexibility and customization options. By ungrouping a set of grouped shapes, you regain individual control over each shape. This allows you to make specific modifications, resize or reposition individual shapes, and apply unique formatting or styling as needed. In this article, we will explain how to group and ungroup shapes in PowerPoint in Python using Spire.Presentation for Python.
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Group Shapes in PowerPoint in Python
Spire.Presentation for Python provides the ISlide.GroupShapes(shapeList: List) method to group two or more shapes on a specific slide. The detailed steps are as follows.
- Create an object of the Presentation class.
- Get the first slide using Presentation.Slides[0] property.
- Add two shapes to the slide using ISlide.Shapes.AppendShape() method.
- Create a list to store the shapes that need to be grouped.
- Add the two shapes to the list.
- Group the two shapes using ISlide.GroupShapes(shapeList: List) method.
- Save the result document using Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create an object of the Presentation class
ppt = Presentation()
# Get the first slide
slide = ppt.Slides[0]
# Add two shapes to the slide
rectangle = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB (250, 180, 450, 220))
rectangle.Fill.FillType = FillFormatType.Solid
rectangle.Fill.SolidColor.KnownColor = KnownColors.SkyBlue
rectangle.Line.Width = 0.1
ribbon = slide.Shapes.AppendShape(ShapeType.Ribbon2, RectangleF.FromLTRB (290, 155, 410, 235))
ribbon.Fill.FillType = FillFormatType.Solid
ribbon.Fill.SolidColor.KnownColor = KnownColors.LightPink
ribbon.Line.Width = 0.1
# Add the two shapes to a list
shape_list = []
shape_list.append(rectangle)
shape_list.append(ribbon)
# Group the two shapes
slide.GroupShapes(shape_list)
# Save the resulting document
ppt.SaveToFile("GroupShapes.pptx", FileFormat.Pptx2013)
ppt.Dispose()

Ungroup Shapes in PowerPoint in Python
To ungroup the grouped shapes in a PowerPoint document, you need to iterate through all slides in the document and all shapes on each slide, find the grouped shapes and then ungroup them using ISlide.Ungroup(groupShape: GroupShape) method. The detailed steps are as follows.
- Create an object of the Presentation class.
- Load the PowerPoint document using Presentation.LoadFromFile() method.
- Iterate through all slides in the document.
- Iterate through all shapes on each slide.
- Check if the current shape is of GroupShape type. If the result is True, ungroup it using ISlide.Ungroup(groupShape: GroupShape) method.
- Save the result document using Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create an object of the Presentation class
ppt = Presentation()
# Load a PowerPoint document
ppt.LoadFromFile("GroupShapes.pptx")
# Iterate through all slides in the document
for i in range(ppt.Slides.Count):
slide = ppt.Slides[i]
# Iterate through all shapes on each slide
for j in range(slide.Shapes.Count):
shape = slide.Shapes[j]
# Check if the shape is a grouped shape
if isinstance(shape, GroupShape):
groupShape = shape
# Ungroup the grouped shape
slide.Ungroup(groupShape)
# Save the resulting document
ppt.SaveToFile("UngroupShapes.pptx", FileFormat.Pptx2013)
ppt.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Watermarks serve as subtle overlays placed on the slides, typically in the form of text or images, which can convey messages, copyright information, company logos, or other visual elements. By incorporating watermarks into your PowerPoint presentations, you can enhance professionalism, reinforce branding, and discourage unauthorized use or distribution of your material. In this article, you will learn how to add text or image watermarks to a PowerPoint document in Python using Spire.Presentation for Python.
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Add a Text Watermark to PowerPoint in Python
Unlike MS Word, PowerPoint does not have a built-in feature that allows to apply watermarks to each slide. However, you can add a shape with text or an image to mimic the watermark effect. A shape can be added to a slide using the ISlide.Shapes.AppendShape() method, and the text of the shape can be set through the IAutoShape.TextFrame.Text property. To prevent the shape from overlapping the existing content on the slide, you'd better send it to the bottom.
The following are the steps to add a text watermark to a slide using Spire.Presentation for Python.
- Create a Presentation object.
- Load a PowerPoint file using Presentation.LoadFromFile() method.
- Get a specific slide through Prentation.Slides[index] property.
- Add a shape to the slide using ISlide.Shapes.AppendShape() method.
- Add text to the shape through IAutoShape.TextFrame.Text property.
- Send the shape to back using IAutoShape.SetShapeArrange() method.
- Save the presentation to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint file
presentation.LoadFromFile("C:/Users/Administrator/Desktop/input.pptx")
# Define a rectangle
left = (presentation.SlideSize.Size.Width - 350.0) / 2
top = (presentation.SlideSize.Size.Height - 110.0) / 2
rect = RectangleF(left, top, 350.0, 110.0)
for i in range(0, presentation.Slides.Count):
# Add a rectangle shape to
shape = presentation.Slides[i].Shapes.AppendShape(
ShapeType.Rectangle, rect)
# Set the style of the shape
shape.Fill.FillType = FillFormatType.none
shape.ShapeStyle.LineColor.Color = Color.get_Transparent()
shape.Rotation = -35
shape.Locking.SelectionProtection = True
shape.Line.FillType = FillFormatType.none
# Add text to the shape
shape.TextFrame.Text = "CONFIDENTIAL"
textRange = shape.TextFrame.TextRange
# Set the style of the text range
textRange.Fill.FillType = FillFormatType.Solid
textRange.Fill.SolidColor.Color = Color.FromArgb(120, Color.get_Black().R, Color.get_HotPink().G, Color.get_HotPink().B)
textRange.FontHeight = 45
textRange.LatinFont = TextFont("Times New Roman")
# Send the shape to back
shape.SetShapeArrange(ShapeArrange.SendToBack)
# Save to file
presentation.SaveToFile("output/TextWatermark.pptx", FileFormat.Pptx2010)
presentation.Dispose()

Add an Image Watermark to PowerPoint in Python
To add an image watermark, you need first to create a rectangle with the same size as an image. Then fill the shape with this image and place the shape at the center of a slide. To prevent the shape from overlapping the existing content on the slide, you need to send it to the bottom as well. The following are the steps to add an image watermark to a slide using Spire.Presentation for Python.
- Create a Presentation object.
- Load a PowerPoint file using Presentation.LoadFromFile() method.
- Get a specific slide through Prentation.Slides[index] property.
- Load an image using Presentation.Images.AppendStream() method.
- Add a shape that has the same size with the image to the slide using ISlide.Shapes.AppendShape() method.
- Fill the shape with the image through IAuotShape.Fill.PictureFill.Picture.EmbedImage property.
- Send the shape to back using IAutoShape.SetShapeArrange() method.
- Save the presentation to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint file
presentation.LoadFromFile("C:/Users/Administrator/Desktop/input.pptx")
# Load an image
stream = Stream("C:/Users/Administrator/Desktop/logo.png")
image = presentation.Images.AppendStream(stream)
stream.Close()
# Get width and height of the image
width = (float)(image.Width)
height = (float)(image.Height)
#
slideSize = presentation.SlideSize.Size
# Loop through the slides in the presentation
for i in range(0, presentation.Slides.Count):
# Get a specific slide
slide = presentation.Slides[i]
# Add a shape to slide
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF((slideSize.Width - width )/2, (slideSize.Height - height)/2, width, height))
# Fill the shape with image
shape.Line.FillType = FillFormatType.none
shape.Locking.SelectionProtection = True
shape.Fill.FillType = FillFormatType.Picture
shape.Fill.PictureFill.FillType = PictureFillType.Stretch
shape.Fill.PictureFill.Picture.EmbedImage = image
# Send the shape to back
shape.SetShapeArrange(ShapeArrange.SendToBack)
# Save to file
presentation.SaveToFile("output/ImageWatermark.pptx", FileFormat.Pptx2013)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
