Come confrontare due documenti Word: 3 metodi efficaci inclusi

Anteprima del contenuto:
- Metodo 1. Utilizzare lo strumento di confronto integrato di Microsoft Word
- Metodo 2. Confrontare documenti Word utilizzando strumenti online
- Metodo 3. Confrontare documenti Word automaticamente con codice C#
- FAQ
Quando si lavora con documenti Word, che si tratti di contratti, report o bozze collaborative, una domanda si ripresenta continuamente: cosa è effettivamente cambiato? Confrontare manualmente due versioni riga per riga non è solo dispendioso in termini di tempo, ma anche soggetto a errori. Sia che tu stia rivedendo le modifiche di un collega, preparando contenuti per la pubblicazione o verificando le revisioni per la conformità, hai bisogno di un modo più efficiente e affidabile per individuare le differenze.
Questa guida introduce tre metodi pratici per confrontare documenti Word, ognuno adatto a diversi scenari e livelli di competenza. Alla fine, avrai una chiara comprensione di quale approccio si adatta meglio al tuo flusso di lavoro e come utilizzarlo in modo efficace per risparmiare tempo e migliorare l'accuratezza.
Metodo 1. Utilizzare lo strumento di confronto integrato di Microsoft Word
Pro
- Altamente accurato
- Costruito specificamente per il confronto di documenti
- Ottimo per la modifica collaborativa
Contro
- Può sembrare opprimente per i principianti
- Personalizzazione limitata per flussi di lavoro avanzati
- Richiede l'installazione di Microsoft Word
Quando si lavora con revisioni dettagliate, modifiche tracciate o documenti formali, un semplice controllo visivo non è più sufficiente: è necessario un approccio più accurato e strutturato. In queste situazioni, lo strumento di confronto integrato di Microsoft Word diventa una soluzione molto più efficace.
Microsoft Word fornisce una funzionalità dedicata per il confronto di documenti che può rilevare automaticamente le differenze e presentarle in un formato chiaro e organizzato, rendendo il processo di revisione più semplice ed efficiente.
Passaggi per confrontare due documenti utilizzando lo strumento di confronto integrato di Microsoft Word:
Passaggio 1. Apri Microsoft Word e vai alla scheda "Revisione". Trova la sezione "Confronta" e scegli "Confronta".
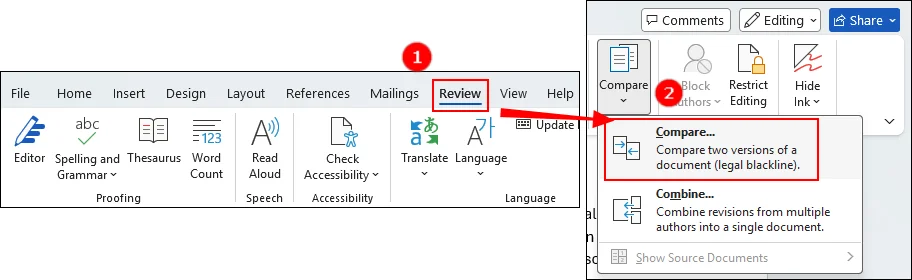
Passaggio 2. Naviga per scegliere i due documenti che desideri confrontare. Quindi, fai clic su "OK" e Microsoft Word genererà un nuovo documento con le differenze chiaramente contrassegnate.
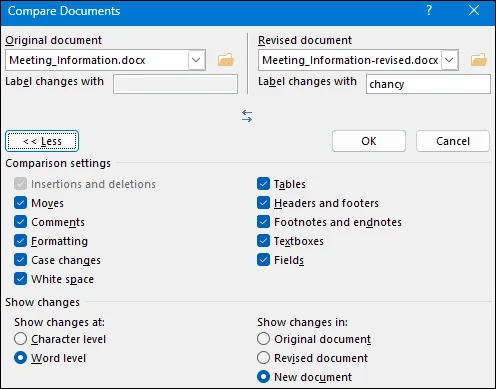
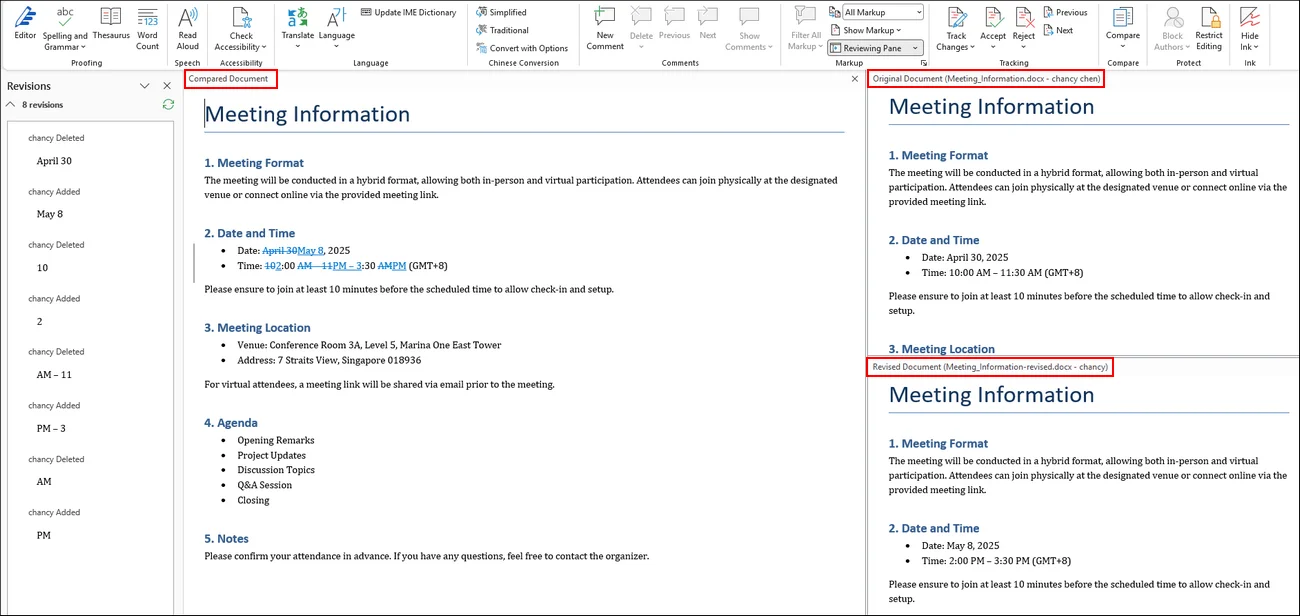
Passaggio 3. Dopo alcuni secondi, verrà generato il risultato del confronto.
Metodo 2. Confrontare documenti Word utilizzando strumenti online
Pro
- Nessuna installazione richiesta
- Funziona su qualsiasi dispositivo
- Veloce e facile da usare
Contro
- Preoccupazioni sulla privacy (documenti sensibili)
- Limitazioni sulla dimensione dei file
- Dipendenza da Internet
Sebbene lo strumento integrato di Word sia potente, non è sempre conveniente, soprattutto se non hai accesso a Word o hai bisogno di un confronto rapido su un altro dispositivo. In questi casi, gli strumenti online offrono un'alternativa veloce e accessibile senza richiedere l'installazione di software.
Gli strumenti online per il confronto di documenti offrono un modo rapido per confrontare file direttamente nel tuo browser. Questi strumenti sono particolarmente utili quando lavori su più dispositivi o hai bisogno di una soluzione rapida senza installazione.
Come confrontare due documenti Word con uno strumento online:
Passaggio 1. Apri un browser sul tuo computer e cerca uno strumento di confronto online su Google.
Passaggio 2. Vai al sito ufficiale dello strumento e carica i due documenti Word che desideri confrontare.
Passaggio 3. Attendi il completamento del confronto, quindi scarica il file del risultato.
Metodo 3. Confrontare documenti Word automaticamente con codice C#
Pro
- Completamente automatizzato
- Scalabile per grandi flussi di lavoro
- Personalizzabile per esigenze specifiche
Contro
- Richiede conoscenze di programmazione
- Sforzo di configurazione e integrazione
- Non ideale per utenti non tecnici
Gli strumenti online sono convenienti, ma non sono sufficienti quando hai bisogno di automazione, integrazione o elaborazione di documenti su larga scala. Se sei uno sviluppatore o lavori in un sistema che gestisce documenti programmaticamente, avrai bisogno di una soluzione più flessibile. È qui che entra in gioco il confronto basato su codice.
Un'opzione per gli sviluppatori è utilizzare una libreria di elaborazione documenti .NET per automatizzare i confronti. Ad esempio, puoi utilizzare Spire.Doc for .NET, un'API di elaborazione documenti che consente agli sviluppatori di creare, leggere, modificare e analizzare file Word senza richiedere l'installazione di Microsoft Word.
Passaggi completi per confrontare automaticamente due documenti Word con codice C#:
Passaggio 1. Installa il file DLL. Puoi aggiungere la dipendenza scaricandola dal sito ufficiale o installarla direttamente con NuGet con il codice seguente:
PM> Install-Package Spire.Doc
Passaggio 2. Copia il codice di esempio seguente e adattalo alla tua situazione:
Codice di esempio:
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Carica un documento Word
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
//Carica l'altro documento Word
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
//Confronta i due documenti
doc1.Compare(doc2, "Chancy");
//Salva le differenze in un terzo documento
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
Risultato:

Suggerimento: Puoi richiedere una licenza di prova gratuita al team di vendita per rimuovere le limitazioni di valutazione.
FAQ
D1. Posso confrontare due documenti Word ed evidenziare le differenze?
Sì. Lo strumento di confronto integrato di Microsoft Word evidenzia automaticamente le differenze, inclusi testo, formattazione e commenti.
D2. È sicuro utilizzare strumenti online per il confronto di Word?
Dipende. Per documenti sensibili, è meglio evitare gli strumenti online a causa di potenziali rischi per la privacy.
D3. Come confronto più documenti Word contemporaneamente?
Gli strumenti manuali e integrati sono limitati. Per il confronto in batch, l'utilizzo di soluzioni basate su codice è l'approccio più efficiente.
Conclusione
Ogni metodo che abbiamo trattato serve a uno scopo diverso: dagli strumenti integrati alle soluzioni automatizzate avanzate. La scelta giusta dipende dal tuo flusso di lavoro, dalle tue competenze tecniche e dal livello di accuratezza di cui hai bisogno.
Scegliere l'approccio giusto è fondamentale per migliorare l'efficienza e l'accuratezza. Una volta fatto, il confronto dei documenti diventa più veloce, più semplice e molto più affidabile, facendoti risparmiare tempo e aiutandoti a concentrarti su ciò che conta: il contenuto stesso.
Leggi anche:
Comment comparer deux documents Word : 3 méthodes efficaces incluses
Aperçu du contenu :
- Méthode 1. Utiliser l'outil de comparaison intégré de Microsoft Word
- Méthode 2. Comparer des documents Word à l'aide d'outils en ligne
- Méthode 3. Comparer automatiquement des documents Word avec du code C#
- FAQ
Lorsque vous travaillez avec des documents Word, qu'il s'agisse de contrats, de rapports ou de brouillons collaboratifs, une question revient sans cesse : qu'est-ce qui a réellement changé ? Comparer manuellement deux versions ligne par ligne est non seulement fastidieux, mais aussi source d'erreurs. Que vous examiniez les modifications d'un collègue, prépariez du contenu pour publication ou vérifiiez les révisions pour la conformité, vous avez besoin d'un moyen plus efficace et fiable de repérer les différences.
Ce guide présente trois méthodes pratiques pour comparer des documents Word, chacune adaptée à différents scénarios et niveaux de compétence. À la fin, vous aurez une compréhension claire de l'approche qui convient le mieux à votre flux de travail et de la manière de l'utiliser efficacement pour gagner du temps et améliorer la précision.
Méthode 1. Utiliser l'outil de comparaison intégré de Microsoft Word
Avantages
- Très précis
- Conçu spécifiquement pour la comparaison de documents
- Idéal pour la collaboration
Inconvénients
- Peut sembler intimidant pour les débutants
- Personnalisation limitée pour les flux de travail avancés
- Nécessite l'installation de Microsoft Word
Lorsque vous travaillez avec des révisions détaillées, des suivis de modifications ou des documents officiels, une simple vérification visuelle ne suffit plus : vous avez besoin d'une approche plus précise et structurée. Dans ces situations, l'outil de comparaison intégré de Microsoft Word devient une solution beaucoup plus efficace.
Microsoft Word fournit une fonctionnalité dédiée à la comparaison de documents qui peut détecter automatiquement les différences et les présenter dans un format clair et organisé, rendant le processus de révision plus facile et plus efficace.
Étapes pour comparer deux documents à l'aide de l'outil de comparaison intégré de Microsoft Word :
Étape 1. Ouvrez Microsoft Word et accédez à l'onglet "Révision". Trouvez la section "Comparer" et choisissez "Comparer".
Étape 2. Naviguez pour choisir les deux documents que vous souhaitez comparer. Ensuite, cliquez sur "OK", et Microsoft Word générera un nouveau document avec les différences clairement marquées.
Étape 3. Après quelques secondes, le résultat de la comparaison sera généré.
Méthode 2. Comparer des documents Word à l'aide d'outils en ligne
Avantages
- Aucune installation requise
- Fonctionne sur n'importe quel appareil
- Rapide et facile à utiliser
Inconvénients
- Problèmes de confidentialité (documents sensibles)
- Limitations de taille de fichier
- Dépendance à Internet
Bien que l'outil intégré de Word soit puissant, il n'est pas toujours pratique, surtout si vous n'avez pas accès à Word ou si vous avez besoin d'une comparaison rapide sur un autre appareil. Dans ces cas, les outils en ligne offrent une alternative rapide et accessible sans nécessiter d'installation logicielle.
Les outils de comparaison de documents en ligne offrent un moyen rapide de comparer des fichiers directement dans votre navigateur. Ces outils sont particulièrement utiles lorsque vous travaillez sur différents appareils ou que vous avez besoin d'une solution rapide sans installation.
Comment comparer deux documents Word avec un outil en ligne :
Étape 1. Ouvrez un navigateur sur votre ordinateur et recherchez un outil de comparaison en ligne sur Google.
Étape 2. Accédez au site officiel de l'outil et téléchargez les deux documents Word que vous souhaitez comparer.
Étape 3. Attendez que la comparaison soit terminée, puis téléchargez le fichier de résultat.
Méthode 3. Comparer automatiquement des documents Word avec du code C#
Avantages
- Entièrement automatisé
- Évolutif pour les grands flux de travail
- Personnalisable pour des besoins spécifiques
Inconvénients
- Nécessite des connaissances en programmation
- Effort de configuration et d'intégration
- Pas idéal pour les utilisateurs non techniques
Les outils en ligne sont pratiques, mais ils sont insuffisants lorsque vous avez besoin d'automatisation, d'intégration ou de traitement de documents à grande échelle. Si vous êtes un développeur, ou si vous travaillez dans un système qui traite des documents par programme, vous aurez besoin d'une solution plus flexible. C'est là qu'intervient la comparaison basée sur le code.
Une option pour les développeurs est d'utiliser une bibliothèque de traitement de documents .NET pour automatiser les comparaisons. Par exemple, vous pouvez utiliser Spire.Doc for .NET, une API de traitement de documents qui permet aux développeurs de créer, lire, modifier et analyser des fichiers Word sans nécessiter l'installation de Microsoft Word.
Étapes complètes pour comparer automatiquement deux documents Word avec du code C# :
Étape 1. Installez le fichier DLL. Vous pouvez ajouter la dépendance en la téléchargeant depuis le site officiel ou l'installer directement avec NuGet avec le code ci-dessous :
PM> Install-Package Spire.Doc
Étape 2. Copiez le code d'exemple ci-dessous et ajustez-le en fonction de votre situation :
Exemple de code :
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Charger un document Word
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
//Charger l'autre document Word
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
//Comparer deux documents
doc1.Compare(doc2, "Chancy");
//Enregistrer les différences dans un troisième document
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
Résultat :
Astuce : Vous pouvez demander une licence d'essai gratuite à l'équipe des ventes via la page TemLicense pour supprimer les limitations d'évaluation.
FAQ
Q1. Puis-je comparer deux documents Word et mettre en évidence les différences ?
Oui. L'outil de comparaison intégré de Microsoft Word met automatiquement en évidence les différences, y compris le texte, la mise en forme et les commentaires.
Q2. Est-il sûr d'utiliser des outils de comparaison Word en ligne ?
Cela dépend. Pour les documents sensibles, il est préférable d'éviter les outils en ligne en raison des risques potentiels pour la confidentialité.
Q3. Comment comparer plusieurs documents Word à la fois ?
Les outils manuels et intégrés sont limités. Pour la comparaison par lots, l'utilisation de solutions basées sur le code est l'approche la plus efficace.
Conclusion
Chaque méthode que nous avons abordée sert un objectif différent, des outils intégrés aux solutions automatisées avancées. Le bon choix dépend de votre flux de travail, de vos compétences techniques et du niveau de précision dont vous avez besoin.
Choisir la bonne approche est essentiel pour améliorer l'efficacité et la précision. Une fois que vous l'aurez fait, la comparaison de documents deviendra plus rapide, plus facile et beaucoup plus fiable, vous faisant gagner du temps et vous permettant de vous concentrer sur ce qui compte : le contenu lui-même.
Lire aussi :
Cómo comparar dos documentos de Word: se incluyen 3 métodos efectivos
Tabla de contenido
Vista previa del contenido:
- Método 1. Usar la herramienta Comparar integrada de Microsoft Word
- Método 2. Comparar documentos de Word usando herramientas en línea
- Método 3. Comparar documentos de Word automáticamente con código C#
- Preguntas frecuentes
Al trabajar con documentos de Word, ya sean contratos, informes o borradores colaborativos, surge una pregunta una y otra vez: ¿qué ha cambiado realmente? Comparar manualmente dos versiones línea por línea no solo consume tiempo, sino que también es propenso a errores. Ya sea que esté revisando las ediciones de un colega, preparando contenido para su publicación o verificando revisiones para el cumplimiento, necesita una forma más eficiente y confiable de detectar diferencias.
Esta guía presenta tres métodos prácticos para comparar documentos de Word, cada uno adecuado para diferentes escenarios y niveles de habilidad. Al final, tendrá una comprensión clara de qué enfoque se adapta mejor a su flujo de trabajo y cómo utilizarlo de manera efectiva para ahorrar tiempo y mejorar la precisión.
Método 1. Usar la herramienta Comparar integrada de Microsoft Word
Ventajas
- Altamente preciso
- Creado específicamente para la comparación de documentos
- Ideal para edición colaborativa
Desventajas
- Puede resultar abrumador para principiantes
- Personalización limitada para flujos de trabajo avanzados
- Requiere Microsoft Word instalado
Cuando trabaje con revisiones detalladas, control de cambios o documentos formales, una simple verificación visual ya no es suficiente: necesita un enfoque más preciso y estructurado. En estas situaciones, la herramienta de comparación integrada de Microsoft Word se convierte en una solución mucho más efectiva.
Microsoft Word proporciona una función dedicada para la comparación de documentos que puede detectar automáticamente las diferencias y presentarlas en un formato claro y organizado, lo que hace que el proceso de revisión sea más fácil y eficiente.
Pasos para comparar dos documentos usando la herramienta Comparar integrada de Microsoft Word:
Paso 1. Abra Microsoft Word y vaya a la pestaña "Revisar". Busque la sección "Comparar" y elija "Comparar".
Paso 2. Navegue para elegir los dos documentos que desea comparar. Luego, haga clic en "Aceptar", y Microsoft Word generará un nuevo documento con las diferencias claramente marcadas.
Paso 3. Después de unos segundos, se generará el resultado de la comparación.
Método 2. Comparar documentos de Word usando herramientas en línea
Ventajas
- No requiere instalación
- Funciona en cualquier dispositivo
- Rápido y fácil de usar
Desventajas
- Preocupaciones de privacidad (documentos confidenciales)
- Limitaciones de tamaño de archivo
- Dependencia de Internet
Aunque la herramienta integrada de Word es potente, no siempre es conveniente, especialmente si no tiene acceso a Word o necesita una comparación rápida en otro dispositivo. En esos casos, las herramientas en línea ofrecen una alternativa rápida y accesible sin necesidad de instalar software.
Las herramientas de comparación de documentos en línea proporcionan una forma rápida de comparar archivos directamente en su navegador. Estas herramientas son especialmente útiles cuando trabaja en varios dispositivos o necesita una solución rápida sin instalación.
¿Cómo puede comparar dos documentos de Word con una herramienta en línea?
Paso 1. Abra un navegador en su computadora y busque una herramienta de comparación en línea en Google.
Paso 2. Vaya al sitio oficial de la herramienta y cargue los dos documentos de Word que desea comparar.
Paso 3. Espere a que se complete la comparación y luego descargue el archivo de resultado.
Método 3. Comparar documentos de Word automáticamente con código C#
Ventajas
- Totalmente automatizado
- Escalable para flujos de trabajo grandes
- Personalizable para necesidades específicas
Desventajas
- Requiere conocimientos de programación
- Esfuerzo de configuración e integración
- No es ideal para usuarios no técnicos
Las herramientas en línea son convenientes, pero no son suficientes cuando necesita automatización, integración o procesamiento de documentos a gran escala. Si es un desarrollador, o trabaja en un sistema que maneja documentos mediante programación, necesitará una solución más flexible. Ahí es donde entra la comparación basada en código.
Una opción para los desarrolladores es utilizar una biblioteca de procesamiento de documentos .NET para automatizar las comparaciones. Por ejemplo, puede usar Spire.Doc for .NET, una API de procesamiento de documentos que permite a los desarrolladores crear, leer, editar y analizar archivos de Word sin necesidad de tener Microsoft Word instalado.
Pasos completos para comparar dos documentos de Word automáticamente con código C#:
Paso 1. Instale el archivo DLL. Puede agregar la dependencia descargándola desde el sitio web oficial o instalarla con NuGet directamente con el siguiente código:
PM> Install-Package Spire.Doc
Paso 2. Copie el siguiente código de ejemplo y ajústelo según su propia situación:
Código de ejemplo:
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Cargar un documento de Word
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
//Cargar el otro documento de Word
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
//Comparar dos documentos
doc1.Compare(doc2, "Chancy");
//Guardar las diferencias en un tercer documento
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
Resultado:
Consejo: Puede solicitar una licencia de prueba gratuita al equipo de ventas para eliminar las limitaciones de evaluación.
Preguntas frecuentes
P1. ¿Puedo comparar dos documentos de Word y resaltar las diferencias?
Sí. La herramienta Comparar integrada de Microsoft Word resalta automáticamente las diferencias, incluido el texto, el formato y los comentarios.
P2. ¿Es seguro usar herramientas de comparación de Word en línea?
Depende. Para documentos confidenciales, es mejor evitar las herramientas en línea debido a posibles riesgos de privacidad.
P3. ¿Cómo comparo varios documentos de Word a la vez?
Las herramientas manuales e integradas son limitadas. Para la comparación por lotes, el uso de soluciones basadas en código es el enfoque más eficiente.
Conclusión
Cada método que hemos cubierto cumple un propósito diferente, desde herramientas integradas hasta soluciones automatizadas avanzadas. La elección correcta depende de su flujo de trabajo, sus habilidades técnicas y el nivel de precisión que necesite.
Elegir el enfoque correcto es clave para mejorar la eficiencia y la precisión. Una vez que lo haga, la comparación de documentos se vuelve más rápida, más fácil y mucho más confiable, lo que le ahorrará tiempo y le ayudará a concentrarse en lo que importa: el contenido en sí.
Leer también:
Wie man zwei Word-Dokumente vergleicht: 3 effektive Methoden enthalten
Inhaltsvorschau:
- Methode 1. Verwenden Sie das integrierte Vergleichstool von Microsoft Word
- Methode 2. Vergleichen Sie Word-Dokumente mit Online-Tools
- Methode 3. Vergleichen Sie Word-Dokumente automatisch mit C#-Code
- FAQs
Wenn Sie mit Word-Dokumenten arbeiten – seien es Verträge, Berichte oder kollaborative Entwürfe –, taucht immer wieder eine Frage auf: Was hat sich tatsächlich geändert? Zwei Versionen Zeile für Zeile manuell zu vergleichen, ist nicht nur zeitaufwendig, sondern auch fehleranfällig. Ob Sie die Bearbeitungen eines Kollegen überprüfen, Inhalte für die Veröffentlichung vorbereiten oder Überarbeitungen auf Konformität prüfen, Sie benötigen eine effizientere und zuverlässigere Methode, um Unterschiede zu erkennen.
Diese Anleitung stellt drei praktische Methoden zum Vergleichen von Word-Dokumenten vor, die jeweils für unterschiedliche Szenarien und Kenntnisstände geeignet sind. Am Ende werden Sie ein klares Verständnis dafür haben, welcher Ansatz am besten zu Ihrem Workflow passt und wie Sie ihn effektiv nutzen können, um Zeit zu sparen und die Genauigkeit zu verbessern.
Methode 1. Verwenden Sie das integrierte Vergleichstool von Microsoft Word
Vorteile
- Sehr genau
- Speziell für den Dokumentenvergleich entwickelt
- Ideal für kollaboratives Bearbeiten
Nachteile
- Kann für Anfänger überfordernd sein
- Begrenzte Anpassungsmöglichkeiten für fortgeschrittene Workflows
- Microsoft Word muss installiert sein
Wenn Sie mit detaillierten Überarbeitungen, Nachverfolgungsänderungen oder formellen Dokumenten arbeiten, reicht eine einfache visuelle Prüfung nicht mehr aus – Sie benötigen einen genaueren und strukturierteren Ansatz. In diesen Situationen wird das integrierte Vergleichstool von Microsoft Word zu einer wesentlich effektiveren Lösung.
Microsoft Word bietet eine spezielle Funktion für den Dokumentenvergleich, die Unterschiede automatisch erkennen und in einem klaren, organisierten Format darstellen kann, wodurch der Überprüfungsprozess einfacher und effizienter wird.
Schritte zum Vergleichen zweier Dokumente mit dem integrierten Vergleichstool von Microsoft Word:
Schritt 1. Öffnen Sie Microsoft Word und gehen Sie zur Registerkarte „Überprüfen“. Suchen Sie den Abschnitt „Vergleichen“ und wählen Sie „Vergleichen“.
Schritt 2. Navigieren Sie, um die beiden zu vergleichenden Dokumente auszuwählen. Klicken Sie dann auf „OK“, und Microsoft Word erstellt ein neues Dokument mit deutlich markierten Unterschieden.
Schritt 3. Nach einigen Sekunden wird das Vergleichsergebnis generiert.
Methode 2. Vergleichen Sie Word-Dokumente mit Online-Tools
Vorteile
- Keine Installation erforderlich
- Funktioniert auf jedem Gerät
- Schnell und einfach zu bedienen
Nachteile
- Datenschutzbedenken (sensible Dokumente)
- Dateigrößenbeschränkungen
- Abhängigkeit vom Internet
Obwohl das integrierte Tool von Word leistungsstark ist, ist es nicht immer praktisch, insbesondere wenn Sie keinen Zugriff auf Word haben oder einen schnellen Vergleich auf einem anderen Gerät benötigen. In diesen Fällen bieten Online-Tools eine schnelle und zugängliche Alternative, ohne dass eine Softwareinstallation erforderlich ist.
Online-Tools zum Vergleichen von Dokumenten bieten eine schnelle Möglichkeit, Dateien direkt in Ihrem Browser zu vergleichen. Diese Tools sind besonders nützlich, wenn Sie geräteübergreifend arbeiten oder eine schnelle Lösung ohne Installation benötigen.
Wie können Sie zwei Word-Dokumente mit einem Online-Tool vergleichen:
Schritt 1. Öffnen Sie einen Browser auf Ihrem Computer und suchen Sie bei Google nach einem Online-Vergleichstool.
Schritt 2. Gehen Sie zur offiziellen Website des Tools und laden Sie die beiden Word-Dokumente hoch, die Sie vergleichen möchten.
Schritt 3. Warten Sie, bis der Vergleich abgeschlossen ist, und laden Sie dann die Ergebnisdatei herunter.
Methode 3. Vergleichen Sie Word-Dokumente automatisch mit C#-Code
Vorteile
- Vollständig automatisiert
- Skalierbar für große Workflows
- Anpassbar für spezifische Bedürfnisse
Nachteile
- Erfordert Programmierkenntnisse
- Aufwand für Einrichtung und Integration
- Nicht ideal für nicht-technische Benutzer
Online-Tools sind praktisch, aber sie reichen nicht aus, wenn Sie Automatisierung, Integration oder die Verarbeitung großer Dokumentenmengen benötigen. Wenn Sie Entwickler sind – oder in einem System arbeiten, das Dokumente programmatisch verarbeitet –, benötigen Sie eine flexiblere Lösung. Hier kommt der codebasierte Vergleich ins Spiel.
Eine Option für Entwickler ist die Verwendung einer .NET-Dokumentenverarbeitungsbibliothek zur Automatisierung von Vergleichen. Sie können beispielsweise Spire.Doc for .NET verwenden, eine API zur Dokumentenverarbeitung, die es Entwicklern ermöglicht, Word-Dateien zu erstellen, zu lesen, zu bearbeiten und zu analysieren, ohne dass Microsoft Word installiert sein muss.
Vollständige Schritte zum automatischen Vergleichen zweier Word-Dokumente mit C#-Code:
Schritt 1. Installieren Sie die DLL-Datei. Sie können die Abhängigkeit hinzufügen, indem Sie sie von der offiziellen Website herunterladen oder sie direkt mit dem folgenden Code über NuGet installieren:
PM> Install-Package Spire.Doc
Schritt 2. Kopieren Sie den folgenden Beispielcode und passen Sie ihn an Ihre Situation an:
Beispielcode:
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Ein Word-Dokument laden
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
//Das andere Word-Dokument laden
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
//Zwei Dokumente vergleichen
doc1.Compare(doc2, "Chancy");
//Die Unterschiede in einem dritten Dokument speichern
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
Ergebnis:
Tipp: Sie können eine kostenlose Testlizenz vom Vertriebsteam anfordern, um Evaluierungseinschränkungen zu entfernen.
FAQs
F1. Kann ich zwei Word-Dokumente vergleichen und Unterschiede hervorheben?
Ja. Das integrierte Vergleichstool von Microsoft Word hebt automatisch Unterschiede hervor, einschließlich Text, Formatierung und Kommentaren.
F2. Ist es sicher, Online-Tools zum Vergleichen von Word-Dokumenten zu verwenden?
Das kommt darauf an. Bei sensiblen Dokumenten ist es aufgrund potenzieller Datenschutzrisiken besser, Online-Tools zu meiden.
F3. Wie vergleiche ich mehrere Word-Dokumente gleichzeitig?
Manuelle und integrierte Tools sind begrenzt. Für den Stapelvergleich ist die Verwendung von codebasierten Lösungen der effizienteste Ansatz.
Fazit
Jede der von uns behandelten Methoden dient einem anderen Zweck – von integrierten Tools bis hin zu fortschrittlichen automatisierten Lösungen. Die richtige Wahl hängt von Ihrem Workflow, Ihren technischen Fähigkeiten und dem erforderlichen Genauigkeitsgrad ab.
Die Wahl des richtigen Ansatzes ist entscheidend für die Verbesserung von Effizienz und Genauigkeit. Sobald Sie dies getan haben, wird der Dokumentenvergleich schneller, einfacher und weitaus zuverlässiger, was Ihnen Zeit spart und Ihnen hilft, sich auf das Wesentliche zu konzentrieren: den Inhalt selbst.
Lesen Sie auch:
Как сравнить два документа Word: 3 эффективных метода включены
Содержание
Предварительный просмотр содержимого:
- Способ 1. Использование встроенного инструмента сравнения Microsoft Word
- Способ 2. Сравнение документов Word с помощью онлайн-инструментов
- Способ 3. Автоматическое сравнение документов Word с помощью кода C#
- Часто задаваемые вопросы
При работе с документами Word — будь то контракты, отчеты или совместные черновики — постоянно возникает вопрос: что именно изменилось? Ручное сравнение двух версий построчно не только отнимает много времени, но и чревато ошибками. Независимо от того, просматриваете ли вы правки коллеги, готовите контент к публикации или проверяете соответствие изменений, вам нужен более эффективный и надежный способ выявления различий.
В этом руководстве представлены три практических способа сравнения документов Word, каждый из которых подходит для разных сценариев и уровней подготовки. К концу вы получите четкое представление о том, какой подход лучше всего подходит для вашего рабочего процесса и как эффективно его использовать для экономии времени и повышения точности.
Способ 1. Использование встроенного инструмента сравнения Microsoft Word
Преимущества
- Высокая точность
- Специально разработан для сравнения документов
- Отлично подходит для совместного редактирования
Недостатки
- Может показаться сложным для новичков
- Ограниченная настройка для расширенных рабочих процессов
- Требуется установленный Microsoft Word
Когда вы работаете с подробными правками, отслеживаемыми изменениями или официальными документами, простой визуальной проверки уже недостаточно — вам нужен более точный и структурированный подход. В таких ситуациях встроенный инструмент сравнения Microsoft Word становится гораздо более эффективным решением.
Microsoft Word предоставляет специальную функцию для сравнения документов, которая может автоматически обнаруживать различия и представлять их в четком, организованном формате, делая процесс проверки проще и эффективнее.
Шаги для сравнения двух документов с помощью встроенного инструмента сравнения Microsoft Word:
Шаг 1. Откройте Microsoft Word и перейдите на вкладку «Рецензирование». Найдите раздел «Сравнить» и выберите «Сравнить».
Шаг 2. Найдите и выберите два документа, которые вы хотите сравнить. Затем нажмите «ОК», и Microsoft Word создаст новый документ с четко отмеченными различиями.
Шаг 3. Через несколько секунд будет сгенерирован результат сравнения.
Способ 2. Сравнение документов Word с помощью онлайн-инструментов
Преимущества
- Установка не требуется
- Работает на любом устройстве
- Быстро и просто в использовании
Недостатки
- Проблемы с конфиденциальностью (конфиденциальные документы)
- Ограничения по размеру файла
- Зависимость от интернета
Хотя встроенный инструмент Word мощный, он не всегда удобен, особенно если у вас нет доступа к Word или вам нужно быстрое сравнение на другом устройстве. В таких случаях онлайн-инструменты предлагают быструю и доступную альтернативу без необходимости установки программного обеспечения.
Онлайн-инструменты для сравнения документов предоставляют быстрый способ сравнения файлов непосредственно в браузере. Эти инструменты особенно полезны, когда вы работаете на разных устройствах или нуждаетесь в быстром решении без установки.
Как сравнить два документа Word с помощью онлайн-инструмента:
Шаг 1. Откройте браузер на своем компьютере и найдите онлайн-инструмент сравнения в Google.
Шаг 2. Перейдите на официальный сайт инструмента и загрузите два документа Word, которые вы хотите сравнить.
Шаг 3. Дождитесь завершения сравнения, затем загрузите файл с результатом.
Способ 3. Автоматическое сравнение документов Word с помощью кода C#
Преимущества
- Полностью автоматизированный
- Масштабируемый для больших рабочих процессов
- Настраиваемый для конкретных нужд
Недостатки
- Требуются знания программирования
- Усилия по настройке и интеграции
- Не подходит для нетехнических пользователей
Онлайн-инструменты удобны, но они не подходят, когда вам нужна автоматизация, интеграция или крупномасштабная обработка документов. Если вы разработчик или работаете в системе, которая программно обрабатывает документы, вам понадобится более гибкое решение. Вот тут-то и приходит на помощь сравнение на основе кода.
Один из вариантов для разработчиков — использовать библиотеку обработки документов .NET для автоматизации сравнений. Например, вы можете использовать Spire.Doc for .NET, API для обработки документов, который позволяет разработчикам создавать, читать, редактировать и анализировать файлы Word без необходимости установки Microsoft Word.
Полные шаги для автоматического сравнения двух документов Word с помощью кода C#:
Шаг 1. Установите файл DLL. Вы можете добавить зависимость, загрузив ее с официального сайта или установить с помощью NuGet напрямую с помощью кода ниже:
PM> Install-Package Spire.Doc
Шаг 2. Скопируйте приведенный ниже пример кода и настройте его в соответствии с вашей ситуацией:
Пример кода:
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Загрузить один документ Word
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
//Загрузить другой документ Word
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
//Сравнить два документа
doc1.Compare(doc2, "Chancy");
//Сохранить различия в третьем документе
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
Результат:
Совет: Вы можете запросить бесплатную пробную лицензию у отдела продаж, чтобы снять ограничения оценки.
Часто задаваемые вопросы
В1. Могу ли я сравнить два документа Word и выделить различия?
Да. Встроенный инструмент сравнения Microsoft Word автоматически выделяет различия, включая текст, форматирование и комментарии.
В2. Безопасно ли использовать онлайн-инструменты для сравнения Word?
Зависит. Для конфиденциальных документов лучше избегать онлайн-инструментов из-за потенциальных рисков конфиденциальности.
В3. Как сравнить несколько документов Word одновременно?
Ручные и встроенные инструменты ограничены. Для пакетного сравнения наиболее эффективным подходом является использование решений на основе кода.
Заключение
Каждый рассмотренный нами метод служит своей цели — от встроенных инструментов до передовых автоматизированных решений. Правильный выбор зависит от вашего рабочего процесса, технических навыков и требуемого уровня точности.
Выбор правильного подхода является ключом к повышению эффективности и точности. Как только вы это сделаете, сравнение документов станет быстрее, проще и гораздо надежнее, сэкономив вам время и позволяя сосредоточиться на главном: самом контенте.
Читайте также:
How to Compare Two Word Documents: 3 Effective Methods Included
Content Preview:
- Method 1. Use Microsoft Word’s Built-in Compare Tool
- Method 2. Compare Word Documents Using Online Tools
- Method 3. Compare Word Documents Automatically with C# Code
- FAQs
When working with Word documents—whether contracts, reports, or collaborative drafts—one question comes up again and again: what actually changed? Manually comparing two versions line by line is not only time-consuming but also prone to errors. Whether you're reviewing a colleague's edits, preparing content for publication, or checking revisions for compliance, you need a more efficient and reliable way to spot differences.
This guide introduces three practical methods to compare Word documents, each suited to different scenarios and skill levels. By the end, you'll have a clear understanding of which approach fits your workflow best and how to use it effectively to save time and improve accuracy.
Method 1. Use Microsoft Word's Built-in Compare Tool
Pros
- Highly accurate
- Built specifically for document comparison
- Great for collaborative editing
Cons
- Can feel overwhelming for beginners
- Limited customization for advanced workflows
- Requires Microsoft Word installed
When you're working with detailed revisions, tracked changes, or formal documents, a simple visual check is no longer enough—you need a more accurate and structured approach. In these situations, Microsoft Word’s built-in comparison tool becomes a much more effective solution.
Microsoft Word provides a dedicated feature for document comparison that can automatically detect differences and present them in a clear, organized format, making the review process easier and more efficient.
Steps to compare two documents using Microsoft Word's built-in Compare tool:
Step 1. Open Microsoft Word and go to "Review" tab. Find the "Compare" section and choose "Compare".
Step 2. Browse to choose the two documents you’d like to compare. Then, click "OK", and Microsoft Word will generate a new document with the differences clearly marked.
Step 3. After a few seconds, the comparison result will be generated.
Method 2. Compare Word Documents Using Online Tools
Pros
- No installation required
- Works on any device
- Fast and easy to use
Cons
- Privacy concerns (sensitive documents)
- File size limitations
- Internet dependency
Although Word's built-in tool is powerful, it’s not always convenient, especially if you don't have access to Word or need a quick comparison on another device. In those cases, online tools offer a fast and accessible alternative without requiring software installation.
Online document comparison tools provide a quick way to compare files directly in your browser. These tools are especially useful when you're working across devices or need a fast, no-installation solution.
How can you compare two Word documents with an online tool:
Step 1. Open a browser on your computer and search for an online compare tool on Google.
Step 2. Go to the official site of the tool and upload the two Word documents you'd like to compare with.
Step 3. Wait for the comparison to complete, then download the result file.
Method 3. Compare Word Documents Automatically with C# Code
Pros
- Fully automated
- Scalable for large workflows
- Customizable for specific needs
Cons
- Requires programming knowledge
- Setup and integration effort
- Not ideal for non-technical users
Online tools are convenient, but they fall short when you need automation, integration, or large-scale document processing. If you're a developer—or working in a system that handles documents programmatically—you'll need a more flexible solution. That's where code-based comparison comes in.
One option for developers is to use a .NET document processing library to automate comparisons. For example, you can use Spire.Doc for .NET, a document processing API that allows developers to create, read, edit, and analyze Word files without requiring Microsoft Word to be installed.
Full steps to compare two Word documents automatically with C# code:
Step 1. Install the DLL file. You can add the dependency by downloading it from the official website or install with NuGet directly with code below:
PM> Install-Package Spire.Doc
Step 2. Copy the sample code below and adjust according to your own situation:
Sample Code:
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Load one Word document
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
//Load the other Word document
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
//Compare two documents
doc1.Compare(doc2, "Chancy");
//Save the differences in a third document
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
Result:
Tip: You can request a free trial license from the sales team to remove evaluation limitations.
FAQs
Q1. Can I compare two Word documents and highlight differences?
Yes. Microsoft Word's built-in Compare tool automatically highlights differences including text, formatting, and comments.
Q2. Is it safe to use online Word comparison tools?
It depends. For sensitive documents, it's better to avoid online tools due to potential privacy risks.
Q3. How do I compare multiple Word documents at once?
Manual and built-in tools are limited. For batch comparison, using code-based solutions is the most efficient approach.
Conclusion
Each method we've covered serves a different purpose—from built-in tools to advanced automated solutions. The right choice depends on your workflow, technical skills, and the level of accuracy you need.
Choosing the right approach is key to improving efficiency and accuracy. Once you do, document comparison becomes faster, easier, and far more reliable, saving you time and helping you focus on what matters: the content itself.
Read Also:
HTML para RTF (Rich Text): Online, Word, Pandoc e C#

HTML (HyperText Markup Language) é a espinha dorsal da web, mas nem sempre é o melhor formato para edição ou compartilhamento de documentos. RTF (Rich Text Format), por outro lado, é um formato de documento multiplataforma suportado por praticamente todos os processadores de texto — Microsoft Word, Google Docs, LibreOffice e até softwares mais antigos como o WordPad.
Converter HTML para RTF permite que você:
- Preserve a formatação básica (negrito, itálico, fontes, cores)
- Mantenha imagens e tabelas intactas
- Compartilhe documentos editáveis sem depender de navegadores web
- Evite alterações de layout causadas por CSS ou arquivos externos ausentes
Seja você um desenvolvedor, criador de conteúdo ou profissional de negócios, dominar a conversão eficiente de HTML para rich text (RTF) otimiza seu fluxo de trabalho e elimina frustrações de formatação. Abaixo, exploramos 4 métodos práticos, desde ferramentas online de um clique até soluções de código automatizadas, adequados para todos os cenários de uso.
- Conversores Gratuitos de HTML para RTF Online
- Converter com o Microsoft Word
- Ferramenta de Linha de Comando Pandoc
- Automatizar com C#
- Qual Método de HTML para RTF é o Mais Adequado para Você?
- Perguntas Frequentes (FAQ)
1. Conversores Gratuitos de HTML para RTF Online (Mais Rápido para Arquivos Pequenos)
✔ Ideal para: Conversões rápidas e pontuais de arquivos pequenos que não são sensíveis.
Se você precisa converter alguns arquivos HTML rapidamente e não quer instalar software, os conversores online são o caminho a seguir. Eles funcionam analisando seu arquivo HTML e gerando um documento RTF para download. Aqui estão as principais opções:
- CLOUDXDOCS: Interface limpa e sem anúncios, perfeita para formatação HTML básica
- Convertio: Suporta uploads de arquivos de até 100 MB, retém estilos básicos.
- OnlineConvert: Gratuito, sem registro, preserva tabelas e CSS inline.
Passos gerais para converter HTML para RTF online:
- Acesse o conversor escolhido.
- Carregue o arquivo .html.
- Selecione RTF como formato de saída.
- Clique em Converter e baixe o arquivo RTF gerado.
Exemplo de uso do conversor CLOUDXDOCS:
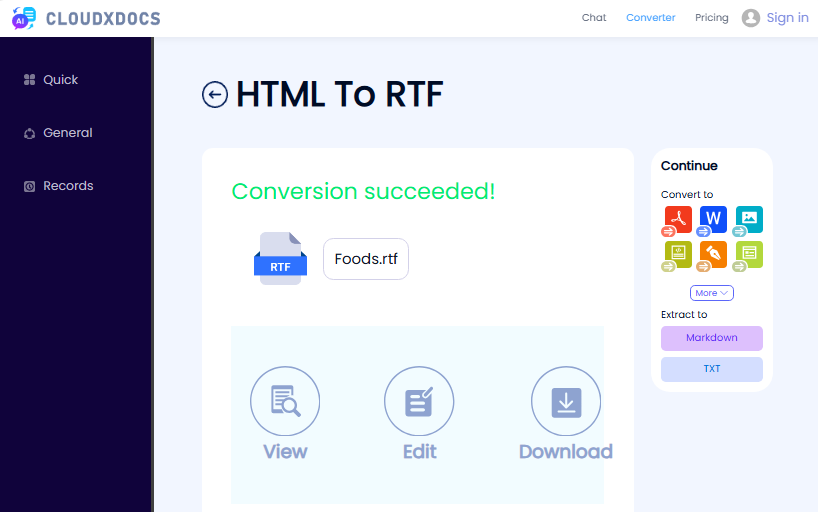
Bônus: Além de converter um arquivo HTML para RTF para rich text editável, a conversão de HTML para PDF é igualmente essencial para criar documentos compartilháveis e com layout fixo.
2. Converter com o Microsoft Word (Offline, Alta Fidelidade)
✔ Ideal para: Usuários que já possuem o Microsoft Word e precisam da maior precisão de formatação possível para tabelas complexas, fontes e elementos aninhados.
O Microsoft Word possui recursos de renderização de HTML integrados. Ele pode abrir qualquer arquivo .html e preservar a maioria dos estilos CSS (inline, incorporados e até folhas de estilo externas). Em seguida, você salva como RTF.
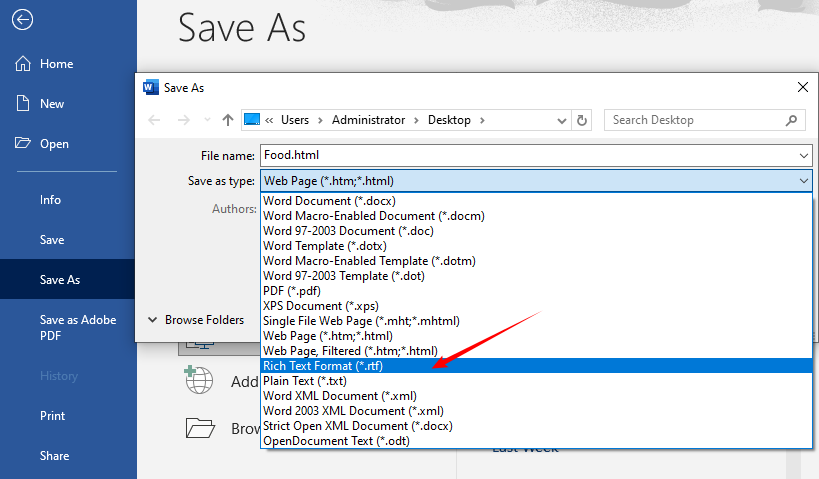
Como converter HTML para rich text no Word:
- Abra o Microsoft Word.
- Vá em Arquivo > Abrir e selecione seu arquivo .html.
- O Word analisará automaticamente a estrutura HTML e a renderizará como um documento formatado.
- Uma vez carregado, vá em Arquivo > Salvar como.
- Escolha Rich Text Format (.rtf) no menu suspenso de tipos de arquivo.
- Salve o arquivo.
Dicas Avançadas
- Correção de imagens ausentes: Se as imagens estiverem vinculadas a caminhos locais, o Word pode não encontrá-las. Antes de abrir no Word, edite o HTML para usar URLs absolutas ou incorpore imagens como base64.
- Ajuste das configurações da página: O Word usa sua configuração de página padrão (geralmente Carta ou A4). Para alterar, vá em “Layout > Tamanho” antes de salvar.
- Tratamento de consultas @media CSS: O Word ignora a maioria dos estilos CSS específicos para impressão. Se o seu HTML tiver estilos de impressão separados, eles podem não ser aplicados. Considere removê-los.
Alternativa Gratuita: Use o LibreOffice (Windows/Mac/Linux) para conversão gratuita e de alta qualidade de HTML para rich text offline, sem pagar pelo Microsoft Word.
3. Ferramenta de Linha de Comando Pandoc (Melhor para Conversões em Lote)
✔ Ideal para: Desenvolvedores, redatores técnicos e qualquer pessoa familiarizada com a linha de comando que precise converter muitos arquivos HTML rapidamente, de forma confiável e gratuita.
Pandoc é uma ferramenta gratuita e de código aberto de linha de comando que converte documentos entre dezenas de formatos, incluindo HTML para RTF. É o padrão ouro para processamento em lote ou integração em scripts.
Como usar o Pandoc:
- Instale o Pandoc em pandoc.org.
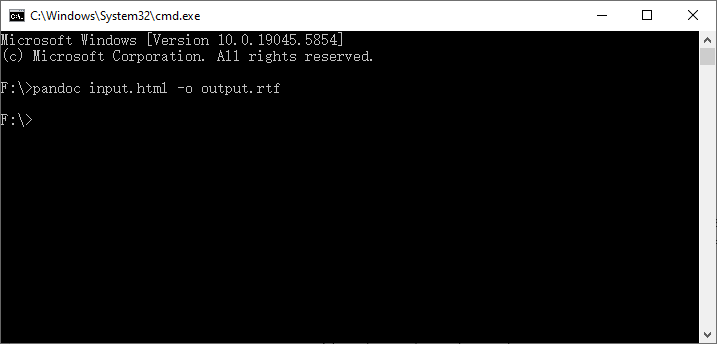
- Conversão de arquivo único (abra o Prompt de Comando/Terminal):
pandoc input.html -o output.rtf
- Converter todos os arquivos HTML em uma pasta para RTF em lote (Windows PowerShell):
Get-ChildItem *.html | ForEach-Object { pandoc $_.FullName -o $($_.BaseName + ".rtf") }
Quando escolher o Pandoc: Você se preocupa com a estrutura do documento (títulos, parágrafos, listas) e não precisa de estilos CSS exatos. Para conversões pixel-perfeitas, use o Microsoft Word ou o LibreOffice.
RTF preserva a formatação. Se o seu objetivo é remover completamente a formatação, o recurso de HTML para texto permite extrair conteúdo de texto puro instantaneamente de qualquer arquivo HTML.
4. Automatizar com C# (Solução .NET Programável)
✔ Ideal para: Desenvolvedores .NET que integram a conversão de HTML para RTF em aplicativos web, software desktop ou fluxos de trabalho automatizados onde você não quer depender de executáveis externos.
Free Spire.Doc for .NET é uma biblioteca .NET gratuita que permite a conversão programática de HTML para RTF em C# com apenas algumas linhas de código. Ela suporta o tratamento de estruturas HTML complexas, como estilos CSS, tabelas e listas.
Exemplo de Código C# para Converter um Arquivo HTML para RTF
using Spire.Doc;
namespace ConvertHtmlToRTF
{
class Program
{
static void Main()
{
// 1. Criar um objeto Document
Document doc = new Document();
// 2. Carregar um arquivo HTML
doc.LoadFromFile("Test.html", FileFormat.Html);
// 3. Salvar o arquivo HTML no formato rtf
doc.SaveToFile("HTMLtoRTF.rtf", FileFormat.Rtf);
doc.Dispose();
}
}
}
Este código carrega um arquivo HTML local e gera um documento RTF formatado usando o método SaveToFile(). Além do processamento de arquivos locais, o Free Spire.Doc suporta totalmente a conversão de strings HTML dinâmicas obtidas de entrada do usuário, APIs de terceiros ou bancos de dados.
Resultado da conversão:
Quando escolher o Free Spire.Doc: Você já está em um ecossistema .NET, precisa converter fragmentos HTML ou documentos completos programaticamente, e seus documentos são curtos. Para documentos grandes, considere o Pandoc ou a versão comercial do Spire.Doc.
Tabela Comparativa: Qual Método de HTML para RTF é o Mais Adequado para Você?
| Método | Preservação de Estilo | Custo | Habilidade Técnica | Privacidade | Capaz de Lote |
|---|---|---|---|---|---|
| Conversor Online | Médio | Grátis (limites) | Baixo | Baixo (dados saem do seu dispositivo) | Limitado |
| Microsoft Word | Muito Alto | Pago (licença) | Baixo | Alto | Não (manual, cada arquivo) |
| Pandoc (CLI) | Médio (apenas estrutura) | Grátis | Médio | Alto | Sim (scriptável) |
| C# + Spire.Doc | Alto | Grátis (limites) | Alto | Alto | Sim (programático) |
Considerações Finais
Converter HTML para RTF é simples e acessível para todos os usuários. Para tarefas rápidas de arquivo único, use conversores gratuitos de HTML para rich text online. Para conversões de documentos frequentes ou sensíveis, escolha softwares offline como Microsoft Word e LibreOffice. Para processamento em lote e fluxos de trabalho automatizados, recorra a ferramentas de linha de comando como Pandoc ou bibliotecas de programação como Free Spire.Doc.
Ao seguir as dicas deste guia, você desfrutará de conversões de HTML para RTF perfeitas e precisas, totalmente adaptadas às suas necessidades.
Perguntas Frequentes (FAQ)
P: A conversão de HTML para RTF é gratuita?
R: Sim, alguns conversores online, LibreOffice, Pandoc e Free Spire.Doc são todos gratuitos para usar.
P: Posso converter HTML para RTF sem perder a formatação?
R: Sim. Use o Microsoft Word (offline), Pandoc ou Free Spire.Doc para máxima retenção de estilo. Incorpore imagens como base64 no HTML para manter todas as imagens.
P: Posso converter vários arquivos HTML para RTF em lote?
R: Sim. Use ferramentas de linha de comando (Pandoc) ou biblioteca de programação (Free Spire.Doc) para conversões em lote. Algumas ferramentas online também suportam uploads em massa (verifique seus limites de tamanho de arquivo).
P: O RTF suporta hiperlinks do HTML?
R: Sim, o RTF suporta hiperlinks. A maioria dos conversores preserva <a href="/..."> como links clicáveis no RTF. No entanto, alguns visualizadores de RTF podem exigir que você segure Ctrl+Clique.
P: Posso converter uma URL de página da web diretamente para RTF?
R: Sim. Alguns conversores online (OnlineConvert) suportam entrada de URL; você também pode salvar a página da web como HTML primeiro e, em seguida, convertê-la offline.
Veja Também
- 5 Melhores Conversores Gratuitos de HTML para Word (Testados e Recomendados)
- Como Baixar uma Página da Web como PDF: Guia para Iniciantes
- 4 Métodos Eficazes para Extrair Tabelas HTML para Excel (Manual e Automatizado)
- Análise de HTML em C#: Strings, Arquivos e URLs
- C#: Converter RTF para HTML, Imagem
HTML을 RTF(리치 텍스트)로 변환: 온라인, Word, Pandoc 및 C#
HTML(HyperText Markup Language)은 웹의 근간이지만, 문서 편집이나 공유에 항상 최적의 형식은 아닙니다. 반면에 RTF(Rich Text Format)는 Microsoft Word, Google Docs, LibreOffice 및 WordPad와 같은 구형 소프트웨어에서도 지원되는 크로스 플랫폼 문서 형식입니다.
HTML을 RTF로 변환하면 다음과 같은 이점이 있습니다.
- 기본 서식(굵게, 기울임꼴, 글꼴, 색상) 유지
- 이미지 및 표 유지
- 웹 브라우저에 의존하지 않고 편집 가능한 문서 공유
- CSS 또는 누락된 외부 파일로 인한 레이아웃 변경 방지
개발자, 콘텐츠 제작자 또는 비즈니스 전문가이든 효율적인 HTML을 서식 있는 텍스트(RTF)로 변환하는 방법을 익히면 워크플로우가 간소화되고 서식 관련 불편함이 해소됩니다. 아래에서는 모든 사용 시나리오에 적합한 원클릭 온라인 도구부터 자동화된 코드 솔루션까지 4가지 실용적인 방법을 살펴봅니다.
- 무료 온라인 HTML to RTF 변환기
- Microsoft Word로 변환
- Pandoc 명령줄 도구
- C#으로 자동화
- 어떤 HTML to RTF 방법을 선택해야 할까요?
- 자주 묻는 질문 (FAQ)
1. 무료 온라인 HTML to RTF 변환기 (작은 파일에 가장 빠름)
✔ 최적: 민감하지 않은 작은 파일의 빠르고 일회성 변환.
몇 개의 HTML 파일을 빠르게 변환해야 하고 소프트웨어를 설치하고 싶지 않다면 온라인 변환기가 좋습니다. HTML 파일을 구문 분석하고 다운로드 가능한 RTF 문서를 생성하는 방식으로 작동합니다. 다음은 최고의 선택입니다.
- CLOUDXDOCS: 깔끔한 광고 없는 인터페이스, 기본 HTML 서식에 적합
- Convertio: 최대 100MB 파일 업로드 지원, 기본 스타일 유지.
- OnlineConvert: 무료, 등록 불필요, 표 및 인라인 CSS 유지.
온라인에서 HTML을 RTF로 변환하는 일반적인 단계:
- 선택한 변환기로 이동합니다.
- .html 파일을 업로드합니다.
- 출력 형식으로 RTF를 선택합니다.
- 변환을 클릭하고 생성된 RTF 파일을 다운로드합니다.
CLOUDXDOCS 변환기 사용 예시:
보너스: 편집 가능한 서식 있는 텍스트를 위해 HTML 파일을 RTF로 변환하는 것 외에도, HTML을 PDF로 변환하는 것도 공유 가능한 고정 레이아웃 문서를 만드는 데 똑같이 중요합니다.
2. Microsoft Word로 변환 (오프라인, 높은 충실도)
✔ 최적: Microsoft Word를 이미 소유하고 있으며 복잡한 표, 글꼴 및 중첩된 요소에 대해 가능한 가장 높은 서식 정확도가 필요한 사용자.
Microsoft Word에는 HTML 렌더링 기능이 내장되어 있습니다. .html 파일을 열고 대부분의 CSS 스타일(인라인, 포함, 외부 스타일시트 포함)을 유지할 수 있습니다. 그런 다음 RTF로 저장합니다.
Word에서 HTML을 서식 있는 텍스트로 변환하는 방법:
- Microsoft Word를 엽니다.
- 파일 > 열기로 이동하여 .html 파일을 선택합니다.
- Word는 HTML 구조를 자동으로 구문 분석하고 서식이 지정된 문서로 렌더링합니다.
- 로드되면 파일 > 다른 이름으로 저장으로 이동합니다.
- 파일 형식 드롭다운에서 Rich Text Format (.rtf)을 선택합니다.
- 파일을 저장합니다.
고급 팁
- 누락된 이미지 수정: 이미지가 로컬 경로에 연결된 경우 Word에서 찾지 못할 수 있습니다. Word에서 열기 전에 HTML을 편집하여 절대 URL을 사용하거나 이미지를 base64로 포함하십시오.
- 페이지 설정 조정: Word는 기본 페이지 설정(일반적으로 Letter 또는 A4)을 사용합니다. 변경하려면 저장하기 전에 “레이아웃 > 크기”로 이동하십시오.
- CSS @media 쿼리 처리: Word는 대부분의 인쇄 전용 CSS를 무시합니다. HTML에 별도의 인쇄 스타일이 있는 경우 적용되지 않을 수 있습니다. 제거하는 것을 고려하십시오.
무료 대안: Microsoft Word를 구매하지 않고도 무료 오프라인 고품질 HTML을 서식 있는 텍스트로 변환하려면 LibreOffice(Windows/Mac/Linux)를 사용하십시오.
3. Pandoc 명령줄 도구 (일괄 변환에 최적)
✔ 최적: 명령줄에 익숙한 개발자, 기술 작가 및 무료로 많은 HTML 파일을 빠르고 안정적으로 변환해야 하는 모든 사람.
Pandoc은 HTML을 RTF를 포함한 수십 가지 형식 간에 문서를 변환하는 무료 오픈 소스 명령줄 도구입니다. 일괄 처리 또는 스크립트 통합의 표준입니다.
Pandoc 사용 방법:
- pandoc.org에서 Pandoc을 설치합니다.
- 단일 파일 변환 (명령 프롬프트/터미널 열기):
pandoc input.html -o output.rtf
- 폴더의 모든 HTML 파일을 RTF로 일괄 변환 (Windows PowerShell):
Get-ChildItem *.html | ForEach-Object { pandoc $_.FullName -o $($_.BaseName + ".rtf") }
Pandoc을 선택하는 경우: 문서 구조(제목, 단락, 목록)를 중요하게 생각하며 정확한 CSS 스타일이 필요하지 않은 경우. 픽셀 단위의 정확한 변환을 원하면 Microsoft Word 또는 LibreOffice를 사용하십시오.
RTF는 서식을 유지합니다. 형식을 완전히 제거하는 것이 목표라면 HTML을 텍스트로 기능을 사용하여 모든 HTML 파일에서 일반 텍스트 콘텐츠를 즉시 추출할 수 있습니다.
4. C#으로 자동화 (프로그래밍 가능한 .NET 솔루션)
✔ 최적: 웹 애플리케이션, 데스크톱 소프트웨어 또는 외부 실행 파일에 의존하고 싶지 않은 자동화된 워크플로우에 HTML→RTF 변환을 통합하는 .NET 개발자.
Free Spire.Doc for .NET은 몇 줄의 코드로 프로그래밍 가능한 C# HTML to RTF 변환을 지원하는 무료 .NET 라이브러리입니다. CSS 스타일, 표, 목록과 같은 복잡한 HTML 구조를 처리할 수 있습니다.
HTML 파일을 RTF로 변환하는 C# 코드 예시
using Spire.Doc;
namespace ConvertHtmlToRTF
{
class Program
{
static void Main()
{
// 1. Document 객체 생성
Document doc = new Document();
// 2. HTML 파일 로드
doc.LoadFromFile("Test.html", FileFormat.Html);
// 3. HTML 파일을 rtf 형식으로 저장
doc.SaveToFile("HTMLtoRTF.rtf", FileFormat.Rtf);
doc.Dispose();
}
}
}
이 코드는 로컬 HTML 파일을 로드하고 SaveToFile() 메서드를 사용하여 서식이 지정된 RTF 문서를 생성합니다. 로컬 파일 처리 외에도 Free Spire.Doc은 사용자 입력, 타사 API 또는 데이터베이스에서 가져온 동적 HTML 문자열 변환을 완벽하게 지원합니다.
변환 결과:
Free Spire.Doc을 선택하는 경우: 이미 .NET 생태계에 있고 HTML 조각 또는 전체 문서를 프로그래밍 방식으로 변환해야 하며 문서가 짧은 경우. 대용량 문서는 Pandoc 또는 Spire.Doc 상용 버전을 고려하십시오.
비교 표: 어떤 HTML to RTF 방법을 선택해야 할까요?
| 방법 | 스타일 유지 | 비용 | 기술 수준 | 개인 정보 보호 | 일괄 처리 가능 |
|---|---|---|---|---|---|
| 온라인 변환기 | 중간 | 무료 (제한 있음) | 낮음 | 낮음 (데이터가 기기를 떠남) | 제한적 |
| Microsoft Word | 매우 높음 | 유료 (라이선스) | 낮음 | 높음 | 아니요 (각 파일 수동) |
| Pandoc (CLI) | 중간 (구조만) | 무료 | 중간 | 높음 | 예 (스크립트 가능) |
| C# + Spire.Doc | 높음 | 무료 (제한 있음) | 높음 | 높음 | 예 (프로그래밍 방식) |
최종 생각
HTML을 RTF로 변환하는 것은 모든 사용자에게 간단하고 접근하기 쉽습니다. 빠르고 단일 파일 작업에는 무료 온라인 HTML to 서식 있는 텍스트 변환기를 사용하십시오. 빈번하거나 민감한 문서 변환에는 Microsoft Word 및 LibreOffice와 같은 오프라인 소프트웨어를 선택하십시오. 일괄 처리 및 자동화된 워크플로우에는 Pandoc 또는 Free Spire.Doc과 같은 프로그래밍 라이브러리와 같은 명령줄 도구를 사용하십시오.
이 가이드의 팁을 따르면 필요에 완벽하게 맞춤화된 원활하고 정확한 HTML to RTF 변환을 즐길 수 있습니다.
자주 묻는 질문 (FAQ)
Q: HTML to RTF 변환은 무료인가요?
A: 예, 일부 온라인 변환기, LibreOffice, Pandoc 및 Free Spire.Doc은 모두 무료로 사용할 수 있습니다.
Q: 서식 손실 없이 HTML을 RTF로 변환할 수 있나요?
A: 예. Microsoft Word(오프라인), Pandoc 또는 Free Spire.Doc을 사용하여 최대 스타일을 유지하십시오. 이미지를 base64로 HTML에 포함하여 모든 이미지를 유지하십시오.
Q: 여러 HTML 파일을 RTF로 일괄 변환할 수 있나요?
A: 예. 일괄 변환에는 명령줄 도구(Pandoc) 또는 프로그래밍 라이브러리(Free Spire.Doc)를 사용하십시오. 일부 온라인 도구는 대량 업로드도 지원합니다(파일 크기 제한 확인).
Q: RTF는 HTML의 하이퍼링크를 지원하나요?
A: 예, RTF는 하이퍼링크를 지원합니다. 대부분의 변환기는 <a href="/...">를 RTF의 클릭 가능한 링크로 유지합니다. 그러나 일부 RTF 뷰어에서는 Ctrl+클릭을 유지해야 할 수 있습니다.
Q: 웹 페이지 URL을 직접 RTF로 변환할 수 있나요?
A: 예. 일부 온라인 변환기(OnlineConvert)는 URL 입력을 지원합니다. 웹 페이지를 먼저 HTML로 저장한 다음 오프라인으로 변환할 수도 있습니다.
함께 보기
HTML in RTF (Rich Text): Online, Word, Pandoc e C#
HTML (HyperText Markup Language) è la spina dorsale del web, ma non è sempre il formato migliore per l'editing o la condivisione di documenti. RTF (Rich Text Format), d'altra parte, è un formato di documento multipiattaforma supportato praticamente da ogni elaboratore di testi: Microsoft Word, Google Docs, LibreOffice e persino software più vecchi come WordPad.
La conversione da HTML a RTF ti consente di:
- Preservare la formattazione di base (grassetto, corsivo, font, colori)
- Mantenere intatte immagini e tabelle
- Condividere documenti modificabili senza fare affidamento sui browser web
- Evitare spostamenti di layout causati da CSS o file esterni mancanti
Che tu sia uno sviluppatore, un creatore di contenuti o un professionista aziendale, padroneggiare un'efficiente conversione da HTML a rich text (RTF) semplifica il tuo flusso di lavoro ed elimina le frustrazioni legate alla formattazione. Di seguito, esploriamo 4 metodi pratici, dagli strumenti online con un clic alle soluzioni di codice automatizzate, adatti a tutti gli scenari di utilizzo.
- Convertitori HTML in RTF online gratuiti
- Converti con Microsoft Word
- Strumento a riga di comando Pandoc
- Automatizza con C#
- Quale metodo da HTML a RTF fa per te?
- Domande frequenti (FAQ)
1. Convertitori HTML in RTF online gratuiti (Il più veloce per file piccoli)
✔ Ideale per: conversioni rapide, una tantum, di file piccoli che non sono sensibili.
Se hai bisogno di convertire rapidamente alcuni file HTML e non vuoi installare software, i convertitori online sono la soluzione. Funzionano analizzando il tuo file HTML e generando un documento RTF scaricabile. Ecco le migliori opzioni:
- CLOUDXDOCS: Interfaccia pulita e senza pubblicità, perfetta per la formattazione HTML di base
- Convertio: Supporta caricamenti di file fino a 100 MB, conserva gli stili di base.
- OnlineConvert: Gratuito, nessuna registrazione, conserva tabelle e CSS inline.
Passaggi generali per convertire HTML in RTF online:
- Vai al convertitore scelto.
- Carica il file .html.
- Seleziona RTF come formato di output.
- Fai clic su Converti e scarica il file RTF generato.
Esempio di utilizzo del convertitore CLOUDXDOCS:
Bonus: Oltre a convertire un file HTML in RTF per ottenere un rich text modificabile, la conversione da HTML a PDF è altrettanto essenziale per creare documenti condivisibili con layout fisso.
2. Converti con Microsoft Word (Offline, Alta fedeltà)
✔ Ideale per: utenti che possiedono già Microsoft Word e necessitano della massima accuratezza di formattazione possibile per tabelle, font ed elementi nidificati complessi.
Microsoft Word ha funzionalità di rendering HTML integrate. Può aprire qualsiasi file .html e preservare la maggior parte degli stili CSS (inline, incorporati e persino fogli di stile esterni). Quindi salvi come RTF.
Come convertire HTML in rich text in Word:
- Apri Microsoft Word.
- Vai su File > Apri e seleziona il tuo file .html.
- Word analizzerà automaticamente la struttura HTML e la renderizzerà come un documento formattato.
- Una volta caricato, vai su File > Salva con nome.
- Scegli Rich Text Format (.rtf) dal menu a discesa del tipo di file.
- Salva il file.
Suggerimenti avanzati
- Correzione di immagini mancanti: Se le immagini sono collegate a percorsi locali, Word potrebbe non trovarle. Prima di aprire in Word, modifica l'HTML per utilizzare URL assoluti o incorpora le immagini come base64.
- Regolazione delle impostazioni di pagina: Word utilizza la sua impostazione di pagina predefinita (solitamente Letter o A4). Per modificarla, vai su "Layout > Dimensioni" prima di salvare.
- Gestione delle query @media CSS: Word ignora la maggior parte degli stili CSS specifici per la stampa. Se il tuo HTML ha stili di stampa separati, potrebbero non essere applicati. Considera di rimuoverli.
Alternativa gratuita: Usa LibreOffice (Windows/Mac/Linux) per una conversione offline gratuita e di alta qualità da HTML a rich text senza pagare per Microsoft Word.
3. Strumento a riga di comando Pandoc (Ideale per conversioni batch)
✔ Ideale per: sviluppatori, scrittori tecnici e chiunque abbia familiarità con la riga di comando che necessita di convertire molti file HTML in modo rapido, affidabile e gratuito.
Pandoc è uno strumento gratuito e open-source a riga di comando che converte documenti tra decine di formati, incluso HTML in RTF. È lo standard di riferimento per l'elaborazione batch o l'integrazione in script.
Come usare Pandoc:
- Installa Pandoc da pandoc.org.
- Conversione di un singolo file (apri Prompt dei comandi/Terminale):
pandoc input.html -o output.rtf
- Converti in batch tutti i file HTML in una cartella in RTF (Windows PowerShell):
Get-ChildItem *.html | ForEach-Object { pandoc $_.FullName -o $($_.BaseName + ".rtf") }
Quando scegliere Pandoc: ti interessa la struttura del documento (intestazioni, paragrafi, elenchi) e non hai bisogno di una formattazione CSS esatta. Per conversioni pixel-perfect, usa Microsoft Word o LibreOffice.
RTF conserva la formattazione. Se il tuo obiettivo è rimuovere completamente la formattazione, la funzione da HTML a testo ti consente di estrarre istantaneamente il contenuto di testo semplice da qualsiasi file HTML.
4. Automatizza con C# (Soluzione .NET programmabile)
✔ Ideale per: sviluppatori .NET che integrano la conversione da HTML a RTF in applicazioni web, software desktop o flussi di lavoro automatizzati in cui non si desidera fare affidamento su eseguibili esterni.
Free Spire.Doc for .NET è una libreria .NET gratuita che consente la conversione programmatica da HTML a RTF in C# con poche righe di codice. Supporta la gestione di strutture HTML complesse come stili CSS, tabelle ed elenchi.
Esempio di codice C# per convertire un file HTML in RTF
using Spire.Doc;
namespace ConvertHtmlToRTF
{
class Program
{
static void Main()
{
// 1. Crea un oggetto Document
Document doc = new Document();
// 2. Carica un file HTML
doc.LoadFromFile("Test.html", FileFormat.Html);
// 3. Salva il file HTML in formato RTF
doc.SaveToFile("HTMLtoRTF.rtf", FileFormat.Rtf);
doc.Dispose();
}
}
}
Questo codice carica un file HTML locale e genera un documento RTF formattato utilizzando il metodo SaveToFile(). Oltre all'elaborazione di file locali, Free Spire.Doc supporta pienamente la conversione di stringhe HTML dinamiche recuperate da input utente, API di terze parti o database.
Risultato della conversione:
Quando scegliere Free Spire.Doc: ti trovi già in un ecosistema .NET, devi convertire frammenti HTML o documenti completi programmaticamente e i tuoi documenti sono brevi. Per documenti di grandi dimensioni, considera Pandoc o la versione commerciale di Spire.Doc.
Tabella di confronto: Quale metodo da HTML a RTF fa per te?
| Metodo | Conservazione dello stile | Costo | Competenza tecnica | Privacy | Capacità batch |
|---|---|---|---|---|---|
| Convertitore online | Medio | Gratuito (limiti) | Basso | Basso (i dati lasciano il tuo dispositivo) | Limitato |
| Microsoft Word | Molto alto | A pagamento (licenza) | Basso | Alto | No (manuale per ogni file) |
| Pandoc (CLI) | Medio (solo struttura) | Gratuito | Medio | Alto | Sì (scriptabile) |
| C# + Spire.Doc | Alto | Gratuito (limiti) | Alto | Alto | Sì (programmabile) |
Considerazioni finali
Convertire HTML in RTF è semplice e accessibile a tutti gli utenti. Per attività rapide su file singoli, utilizza i convertitori gratuiti da HTML a rich text online. Per conversioni di documenti frequenti o sensibili, scegli software offline come Microsoft Word e LibreOffice. Per l'elaborazione batch e i flussi di lavoro automatizzati, rivolgiti a strumenti a riga di comando come Pandoc o librerie di programmazione come Free Spire.Doc.
Seguendo i suggerimenti di questa guida, godrai di conversioni da HTML a RTF fluide e accurate, completamente personalizzate in base alle tue esigenze.
Domande frequenti (FAQ)
D: La conversione da HTML a RTF è gratuita?
R: Sì, alcuni convertitori online, LibreOffice, Pandoc e Free Spire.Doc sono tutti gratuiti da usare.
D: Posso convertire HTML in RTF senza perdere la formattazione?
R: Sì. Usa Microsoft Word (offline), Pandoc o Free Spire.Doc per la massima conservazione dello stile. Incorpora le immagini come base64 in HTML per mantenere tutte le immagini.
D: Posso convertire in batch più file HTML in RTF?
R: Sì. Utilizza strumenti a riga di comando (Pandoc) o librerie di programmazione (Free Spire.Doc) per conversioni batch. Alcuni strumenti online supportano anche caricamenti di massa (verifica i loro limiti di dimensione dei file).
D: RTF supporta gli hyperlink da HTML?
R: Sì, RTF supporta gli hyperlink. La maggior parte dei convertitori conserva <a href="/..."> come collegamenti cliccabili nel RTF. Tuttavia, alcuni visualizzatori RTF potrebbero richiedere di tenere premuto Ctrl+clic.
D: Posso convertire direttamente un URL di una pagina web in RTF?
R: Sì. Alcuni convertitori online (OnlineConvert) supportano l'input tramite URL; puoi anche salvare la pagina web come HTML prima, quindi convertirla offline.
Vedi anche
HTML en RTF (Rich Text) : en ligne, Word, Pandoc et C#
Table des matières
HTML (HyperText Markup Language) est la base du web, mais ce n'est pas toujours le meilleur format pour l'édition ou le partage de documents. RTF (Rich Text Format), en revanche, est un format de document multiplateforme pris en charge par pratiquement tous les traitements de texte : Microsoft Word, Google Docs, LibreOffice, et même les anciens logiciels comme WordPad.
La conversion de HTML en RTF vous permet de :
- Conserver la mise en forme de base (gras, italique, polices, couleurs)
- Garder les images et les tableaux intacts
- Partager des documents modifiables sans dépendre des navigateurs web
- Éviter les décalages de mise en page causés par le CSS ou les fichiers externes manquants
Que vous soyez un développeur, un créateur de contenu ou un professionnel, maîtriser la conversion efficace de HTML en texte enrichi (RTF) optimise votre flux de travail et élimine les frustrations liées à la mise en forme. Ci-dessous, nous explorons 4 méthodes pratiques, des outils en ligne en un clic aux solutions de code automatisées, adaptées à tous les scénarios d'utilisation.
- Convertisseurs HTML vers RTF en ligne gratuits
- Convertir avec Microsoft Word
- Outil en ligne de commande Pandoc
- Automatiser avec C#
- Quelle méthode de conversion HTML vers RTF vous convient le mieux ?
- Questions fréquemment posées (FAQ)
1. Convertisseurs HTML vers RTF en ligne gratuits (Le plus rapide pour les petits fichiers)
✔ Idéal pour : Conversions rapides, ponctuelles de petits fichiers qui ne sont pas sensibles.
Si vous avez besoin de convertir quelques fichiers HTML rapidement et que vous ne souhaitez pas installer de logiciel, les convertisseurs en ligne sont la solution. Ils analysent votre fichier HTML et génèrent un document RTF téléchargeable. Voici les meilleures options :
- CLOUDXDOCS : Interface propre et sans publicité, parfaite pour la mise en forme HTML de base
- Convertio : Prend en charge les téléchargements de fichiers jusqu'à 100 Mo, conserve les styles de base.
- OnlineConvert : Gratuit, sans inscription, conserve les tableaux et le CSS en ligne.
Étapes générales pour convertir HTML en RTF en ligne :
- Accédez au convertisseur de votre choix.
- Téléchargez le fichier .html.
- Sélectionnez RTF comme format de sortie.
- Cliquez sur Convertir et téléchargez le fichier RTF généré.
Exemple d'utilisation du convertisseur CLOUDXDOCS :
En prime : Au-delà de la conversion d'un fichier HTML en RTF pour un texte enrichi modifiable, la conversion HTML en PDF est tout aussi essentielle pour créer des documents partageables avec une mise en page fixe.
2. Convertir avec Microsoft Word (Hors ligne, Haute fidélité)
✔ Idéal pour : Les utilisateurs qui possèdent déjà Microsoft Word et ont besoin de la plus haute précision de mise en forme possible pour les tableaux complexes, les polices et les éléments imbriqués.
Microsoft Word dispose de capacités de rendu HTML intégrées. Il peut ouvrir n'importe quel fichier .html et conserver la plupart des styles CSS (en ligne, intégrés, et même les feuilles de style externes). Ensuite, vous enregistrez au format RTF.
Comment convertir HTML en texte enrichi dans Word :
- Ouvrez Microsoft Word.
- Allez dans Fichier > Ouvrir et sélectionnez votre fichier .html.
- Word analysera automatiquement la structure HTML et l'affichera sous forme de document formaté.
- Une fois chargé, allez dans Fichier > Enregistrer sous.
- Choisissez Format de texte enrichi (.rtf) dans le menu déroulant des types de fichiers.
- Enregistrez le fichier.
Conseils avancés
- Correction des images manquantes : Si les images sont liées à des chemins locaux, Word peut ne pas les trouver. Avant d'ouvrir dans Word, modifiez le HTML pour utiliser des URL absolues ou intégrez les images en base64.
- Ajustement des paramètres de page : Word utilise sa configuration de page par défaut (généralement Lettre ou A4). Pour changer, allez dans « Mise en page > Taille » avant d'enregistrer.
- Gestion des requêtes @media CSS : Word ignore la plupart des styles CSS spécifiques à l'impression. Si votre HTML a des styles d'impression séparés, ils peuvent ne pas s'appliquer. Envisagez de les supprimer.
Alternative gratuite : Utilisez LibreOffice (Windows/Mac/Linux) pour une conversion HTML vers texte enrichi hors ligne de haute qualité et gratuite, sans avoir à payer pour Microsoft Word.
3. Outil en ligne de commande Pandoc (Idéal pour les conversions par lots)
✔ Idéal pour : Les développeurs, les rédacteurs techniques et toute personne à l'aise avec la ligne de commande qui a besoin de convertir de nombreux fichiers HTML rapidement, de manière fiable et gratuitement.
Pandoc est un outil en ligne de commande gratuit et open-source qui convertit des documents entre des dizaines de formats, y compris HTML vers RTF. C'est la référence pour le traitement par lots ou l'intégration dans des scripts.
Comment utiliser Pandoc :
- Installez Pandoc depuis pandoc.org.
- Conversion d'un seul fichier (ouvrez l'invite de commande/Terminal) :
pandoc input.html -o output.rtf
- Conversion par lots de tous les fichiers HTML d'un dossier en RTF (Windows PowerShell) :
Get-ChildItem *.html | ForEach-Object { pandoc $_.FullName -o $($_.BaseName + ".rtf") }
Quand choisir Pandoc : Vous vous souciez de la structure du document (titres, paragraphes, listes) et n'avez pas besoin d'un style CSS exact. Pour des conversions pixel par pixel, utilisez Microsoft Word ou LibreOffice.
RTF conserve la mise en forme. Si votre objectif est de supprimer complètement la mise en forme, la fonction HTML vers texte vous permet d'extraire instantanément le contenu texte brut de n'importe quel fichier HTML.
4. Automatiser avec C# (Solution .NET programmable)
✔ Idéal pour : Les développeurs .NET qui intègrent la conversion HTML→RTF dans des applications web, des logiciels de bureau ou des flux de travail automatisés où vous ne souhaitez pas dépendre d'exécutables externes.
Free Spire.Doc for .NET est une bibliothèque .NET gratuite qui permet la conversion programmatique C# HTML vers RTF en quelques lignes de code seulement. Elle prend en charge la gestion des structures HTML complexes telles que les styles CSS, les tableaux et les listes.
Exemple de code C# pour convertir un fichier HTML en RTF
using Spire.Doc;
namespace ConvertHtmlToRTF
{
class Program
{
static void Main()
{
// 1. Créer un objet Document
Document doc = new Document();
// 2. Charger un fichier HTML
doc.LoadFromFile("Test.html", FileFormat.Html);
// 3. Enregistrer le fichier HTML au format rtf
doc.SaveToFile("HTMLtoRTF.rtf", FileFormat.Rtf);
doc.Dispose();
}
}
}
Ce code charge un fichier HTML local et génère un document RTF formaté à l'aide de la méthode SaveToFile(). Au-delà du traitement de fichiers locaux, Free Spire.Doc prend entièrement en charge la conversion de chaînes HTML dynamiques récupérées à partir des entrées utilisateur, des API tierces ou des bases de données.
Résultat de la conversion :
Quand choisir Free Spire.Doc : Vous êtes déjà dans un écosystème .NET, vous avez besoin de convertir des fragments HTML ou des documents complets par programme, et vos documents sont courts. Pour les documents volumineux, envisagez Pandoc ou la version commerciale de Spire.Doc.
Tableau comparatif : Quelle méthode de conversion HTML vers RTF vous convient le mieux ?
| Méthode | Conservation du style | Coût | Compétences techniques | Confidentialité | Par lots |
|---|---|---|---|---|---|
| Convertisseur en ligne | Moyen | Gratuit (limites) | Faible | Faible (les données quittent votre appareil) | Limité |
| Microsoft Word | Très élevé | Payant (licence) | Faible | Élevé | Non (manuel pour chaque fichier) |
| Pandoc (CLI) | Moyen (structure uniquement) | Gratuit | Moyen | Élevé | Oui (scriptable) |
| C# + Spire.Doc | Élevé | Gratuit (limites) | Élevé | Élevé | Oui (programmatique) |
Réflexions finales
La conversion de HTML en RTF est simple et accessible à tous les utilisateurs. Pour des tâches rapides et ponctuelles, utilisez les convertisseurs HTML vers texte enrichi en ligne gratuits. Pour des conversions de documents fréquentes ou sensibles, choisissez des logiciels hors ligne comme Microsoft Word et LibreOffice. Pour le traitement par lots et les flux de travail automatisés, tournez-vous vers des outils en ligne de commande tels que Pandoc ou des bibliothèques de programmation comme Free Spire.Doc.
En suivant les conseils de ce guide, vous bénéficierez de conversions HTML vers RTF fluides et précises, entièrement adaptées à vos besoins.
Questions fréquemment posées (FAQ)
Q : La conversion de HTML en RTF est-elle gratuite ?
R : Oui, certains convertisseurs en ligne, LibreOffice, Pandoc et Free Spire.Doc sont tous gratuits à utiliser.
Q : Puis-je convertir HTML en RTF sans perdre la mise en forme ?
R : Oui. Utilisez Microsoft Word (hors ligne), Pandoc ou Free Spire.Doc pour une conservation maximale du style. Intégrez les images en base64 dans le HTML pour conserver toutes les images.
Q : Puis-je convertir par lots plusieurs fichiers HTML en RTF ?
R : Oui. Utilisez des outils en ligne de commande (Pandoc) ou une bibliothèque de programmation (Free Spire.Doc) pour les conversions par lots. Certains outils en ligne prennent également en charge les téléchargements en masse (vérifiez leurs limites de taille de fichier).
Q : RTF prend-il en charge les hyperliens de HTML ?
R : Oui, RTF prend en charge les hyperliens. La plupart des convertisseurs conservent <a href="/..."> comme liens cliquables dans le RTF. Cependant, certains visualiseurs RTF peuvent nécessiter que vous mainteniez Ctrl+clic.
Q : Puis-je convertir directement une URL de page web en RTF ?
R : Oui. Certains convertisseurs en ligne (OnlineConvert) prennent en charge la saisie d'URL ; vous pouvez également enregistrer la page web en HTML d'abord, puis la convertir hors ligne.
Voir aussi
- 5 meilleurs convertisseurs HTML vers Word gratuits (testés et recommandés)
- Comment télécharger une page web en PDF : Guide pour débutants
- 4 méthodes efficaces pour extraire des tableaux HTML vers Excel (manuelles et automatisées)
- Analyse HTML en C# : chaînes, fichiers et URL
- C# : Convertir RTF en HTML, Image