5 лучших конвертеров EPUB в TXT (онлайн и программные методы)

Хотя EPUB широко используется для электронных книг, он может стать неудобным, когда вам нужен необработанный текст для таких задач, как анализ контента, обработка ИИ или использование на легких устройствах, которые не поддерживают сложную форматирование. В этих случаях использование надежного конвертера EPUB в TXT позволяет легко извлекать чистый, читаемый контент. В этом руководстве рассматриваются наиболее эффективные инструменты, доступные в 2026 году, которые помогут вам легко конвертировать EPUB в текстовый файл.
- Лучшие онлайн-конвертеры EPUB в TXT
- Настольные и программные конвертеры EPUB в TXT
- Краткое сравнение
- Часто задаваемые вопросы
Лучшие онлайн-конвертеры EPUB в TXT (без установки)
Онлайн-конвертеры EPUB в TXT — это самое быстрое решение, когда у вас есть несколько файлов и вам нужны немедленные результаты без накладных расходов на программное обеспечение. Поскольку эти инструменты работают непосредственно в вашем браузере, они работают практически на любом устройстве без аппаратных ограничений. Большинство инструментов следуют простому рабочему процессу: загрузка — конвертация — скачивание, что делает их идеальными для быстрых конвертаций.
В этом разделе мы представим три широко используемых онлайн-конвертера: CloudConvert, Zamzar и Convertio, каждый из которых предлагает уникальные функции, которые помогут вам легко справиться с конвертацией EPUB в текст.
CloudConvert — Универсальный набор инструментов
CloudConvert зарекомендовал себя как высокозащищенная облачная платформа, поддерживающая более 200 форматов. Он идеально интегрируется с профессиональными рабочими процессами, позволяя напрямую импортировать данные из Google Drive, Dropbox и OneDrive. Более того, способность движка сохранять исходный поток книги лучше, чем у базовых инструментов.
Преимущества:
- Предлагает расширенную безопасность с сертификацией ISO 27001.
- Позволяет пользователям настраивать кодировку текста и окончания строк.
- Предоставляет чистый интерфейс без рекламы, с которым легко работать.
Недостатки:
- Бесплатный тариф ограничивает вас 25 минутами конвертации в день.
- Производительность может снижаться в часы пик для пользователей, не являющихся премиум-пользователями.
Zamzar — Конвертер в один клик
Zamzar — это конвертер файлов EPUB в TXT для пользователей, которые ценят простоту превыше всего. Он разработан для простоты и эффективности, устраняя сложные настройки, которые могут сбить с толку пользователей. Его часто используют многие люди, которым нужно быстро изменить EPUB на документ .txt.
Преимущества:
- Регистрация учетной записи не требуется для базового использования.
- Функция «уведомить по электронной почте по завершении» отлично подходит для больших файлов.
- Поддерживает невероятно широкий спектр традиционных форматов файлов.
Недостатки:
- Бесплатные пользователи не могут выполнять пакетные конвертации одновременно.
- Скорость конвертации ниже по сравнению с другими облачными конкурентами.
Convertio — Лучший для мобильных пользователей
Если вы используете мобильное устройство, Convertio обеспечивает наиболее отзывчивый опыт в качестве онлайн-конвертера EPUB в TXT. Он использует распределенную архитектуру конвертации, которая гарантирует, что ваш браузер не зависнет в ожидании файла. Он также обладает мощными возможностями OCR для сканированных документов.
Преимущества:
- Высоко оптимизирован для мобильных браузеров и сенсорных интерфейсов.
- Предлагает функцию пакетной загрузки для нескольких небольших файлов.
- Интегрированное расширение Chrome для еще более быстрого доступа.
Недостатки:
- Строгое ограничение размера файла в 100 МБ для бесплатных учетных записей.
- Функция OCR платная.
Примечание: Конвертация EPUB в TXT удаляет форматирование, такое как заголовки, стили и изображения, оставляя только обычный текстовый контент. Если вам нужно сохранить это форматирование, вы можете вместо этого конвертировать EPUB в PDF. См. это руководство: Как конвертировать EPUB в PDF (быстрое и простое руководство)
Настольные и программные конвертеры EPUB в TXT
Для тех, кто работает с сотнями файлов или конфиденциальными данными, лучше подходят офлайн и автоматизированные методы. В отличие от онлайн-инструментов, эти решения позволяют конвертировать EPUB в формат TXT локально, обеспечивая безопасность ваших документов и предлагая превосходные возможности пакетной обработки.
Calibre — Профессиональный инструмент для электронных книг
Calibre считается самым популярным в мире менеджером электронных книг с открытым исходным кодом. Это настольное приложение, которое позволяет управлять всей вашей библиотекой, предоставляя мощный движок для локальной конвертации EPUB в формат TXT.

Как конвертировать с помощью Calibre:
- Шаг 1. Нажмите Добавить книги, чтобы импортировать файлы EPUB в библиотеку.
- Шаг 2. Выберите книгу и нажмите значок Конвертировать книги в верхнем меню.
- Шаг 3. Измените выходной формат в правом верхнем углу на TXT.
- Шаг 4. Нажмите OK и дождитесь завершения счетчика заданий.
Преимущества:
- Полностью бесплатный и работает офлайн.
- Поддерживает расширенный поиск и замену в процессе конвертации.
Недостатки:
- Интерфейс довольно перегружен.
- Он требует значительных системных ресурсов по сравнению с легкими скриптами и онлайн-конвертерами EPUB в TXT.
Free Spire.Doc — Пакетная конвертация для разработчиков
Для разработчиков отличным выбором является библиотека Free Spire.Doc for Python. Хотя она в первую очередь предназначена для обработки документов Word, она также поддерживает загрузку файлов EPUB и их экспорт в виде обычного текста.
Как работает код:
Конвертация форматов с помощью Free Spire.Doc проста. Сначала вы создаете объект Document, затем загружаете файл EPUB и, наконец, используете метод SaveToFile() для преобразования и сохранения его в виде нового текстового файла. Если вам также нужно обрабатывать другие конвертации документов, например, конвертировать документы Word в текст, эта библиотека также будет полезна.
from spire.doc import *
from spire.doc.common import *
# Укажите путь к входному и выходному файлу
inputFile = "/input/sample.epub"
outputFile = "/output/ToText.txt"
# Создайте объект Document
doc = Document()
# Загрузите файл EPUB
doc.LoadFromFile(inputFile)
# Сохраните документ как текст
doc.SaveToFile(outputFile, FileFormat.Txt)
doc.Close()
Преимущества:
- Может быть легко интегрирована в автоматизированные серверные конвейеры.
- Отсутствие утечек данных, что обеспечивает 100% конфиденциальность.
Недостатки:
- Требует настройки среды Python на вашем компьютере.
- Требуются базовые навыки программирования.
Также читайте: Конвертация TXT в Word: 4 простых и бесплатных метода
Краткое сравнение: какой конвертер выбрать?
| Метод | Скорость | Конфиденциальность | Пакетная обработка | Лучше всего подходит для |
|---|---|---|---|---|
| Онлайн-инструменты | Мгновенно | Средняя | Ограниченно | Разовые, небольшие файлы |
| Настольный (Calibre) | Быстро | Высокая | Сильная | Личные коллекции книг |
| Программирование | На основе скриптов | Наивысшая | Неограниченно | Разработчики и автоматизация |
Резюме
Выбор идеального конвертера EPUB в TXT зависит от ваших текущих потребностей. Если у вас есть один файл, и вам нужно конвертировать его за секунды, CloudConvert или Convertio — ваши лучшие варианты для беспроблемного использования. Для читателей, которые хотят конвертировать личную библиотеку, сохраняя конфиденциальность, Calibre лучше подходит для офлайн-управления. Наконец, для бизнеса или разработчиков, ищущих масштабируемый, безопасный способ конвертации EPUB в текстовый файл, Free Spire.Doc предлагает наиболее профессиональное и настраиваемое решение.
Часто задаваемые вопросы о конвертерах EPUB в TXT
В1: Как бесплатно конвертировать EPUB в TXT?
О: Вы можете использовать бесплатные онлайн-инструменты, такие как CloudConvert или Convertio, для быстрых конвертаций. Для офлайн-использования Calibre является надежным бесплатным вариантом, поддерживающим пакетную обработку.
В2: Могу ли я конвертировать EPUB в TXT на мобильном телефоне или Android?
О: Да. Онлайн-конвертеры работают непосредственно в мобильных браузерах, что делает их самым простым вариантом на Android или iOS.
В3: Потеряю ли я форматирование при конвертации EPUB в TXT?
О: Да. Файлы TXT содержат только обычный текст, поэтому форматирование, такое как изображения, заголовки и стили, будет удалено. Если вам нужно сохранить макет, рассмотрите возможность конвертации EPUB в PDF или Word.
Также читайте:
Como gerar um arquivo CSV: 4 métodos simples
Sumário

Arquivos CSV (Valores Separados por Vírgula) são o padrão universal para intercâmbio de dados — leves, legíveis por humanos e compatíveis com Microsoft Excel, Google Sheets e linguagens de programação como Python. Quer você esteja organizando dados de clientes, exportando relatórios, migrando informações ou construindo conjuntos de dados de ML, saber como gerar um arquivo CSV é uma habilidade fundamental.
Este guia apresenta 4 métodos simples e práticos para criar um arquivo CSV, desde métodos rápidos sem código até scripts automatizados. Você também receberá dicas para lidar com caracteres especiais e converter dados de JSON, PDF e Excel para CSV.
- Método 1: Criar Manualmente com um Editor de Texto
- Método 2: Gerar CSV com Microsoft Excel
- Método 3: Criar CSV com Google Sheets (Grátis)
- Método 4: Criar um Arquivo CSV em Python
- Bônus: Gerar Arquivo CSV de Diferentes Fontes de Dados
Por que Usar Arquivos CSV?
Um arquivo CSV armazena dados tabulares em texto puro. Cada linha representa um registro de dados, e cada registro contém campos separados por vírgulas.
Vantagens principais dos CSVs:
- Compatibilidade universal – Funciona com a maioria das ferramentas de planilha, CRMs, bancos de dados e linguagens de programação.
- Leve – Sem formatação proprietária, tamanho de arquivo pequeno.
- Ideal para intercâmbio de dados – Rápido para importar/exportar entre diferentes sistemas.
- Padrão aberto e gratuito – Gratuito para criar e usar sem ferramentas pagas.
Casos de uso comuns:
- Carregar listas de produtos em uma plataforma de e-commerce
- Importar leads/contatos em CRMs
- Backup ou migração de dados
- Alimentar dados em Python (pandas), R ou bancos de dados SQL
Método 1: Criar Manualmente com um Editor de Texto
Para conjuntos de dados pequenos e simples (por exemplo, uma curta lista de nomes e e-mails), você pode criar um arquivo CSV manualmente usando um editor de texto como o Bloco de Notas (Windows).
Observação: Este método é propenso a erros para dados grandes – use apenas para listas rápidas e pequenas.
Etapas para criação manual de arquivo CSV:
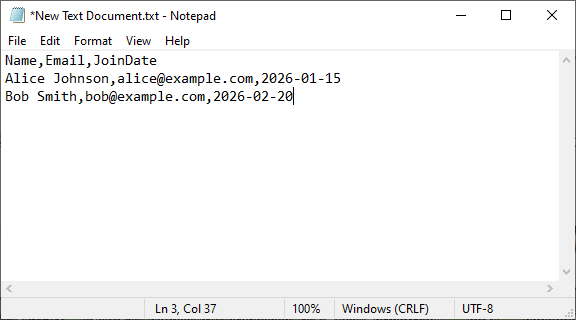
- Abra seu editor de texto.
- Digite cada linha em uma nova linha. Separe os valores com vírgulas. Por exemplo:
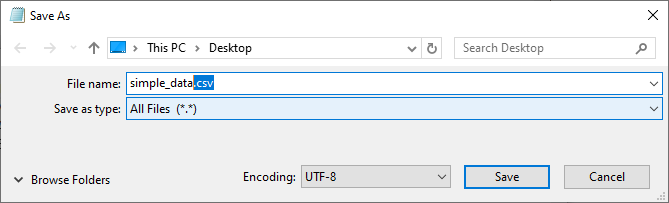
- Clique em “Arquivo” → “Salvar como”.
- Nomeie o arquivo com a extensão .csv (por exemplo, dados_simples.csv) e altere “Salvar como tipo” para “Todos os Arquivos” → Salvar.
Lidando com dados complicados
Se um campo contiver uma vírgula ou quebra de linha, coloque-o entre aspas duplas. Exemplo:
"Smith, John",john@example.com,"Olá\nMundo!"
Você também pode abrir um arquivo de texto existente e seguir as etapas 3-4 para salvá-lo como um arquivo CSV. Para mais métodos de conversão, consulte: 3 Melhores Maneiras de Converter TXT para CSV (Rápido e Sem Erros)
Método 2: Gerar CSV com Microsoft Excel
O Excel é a ferramenta mais comum para criar arquivos CSV, especialmente se você já trabalha com planilhas. Siga estas instruções passo a passo para evitar erros de formatação e garantir que seu CSV seja utilizável.
Etapa 1: Prepare seus Dados no Excel
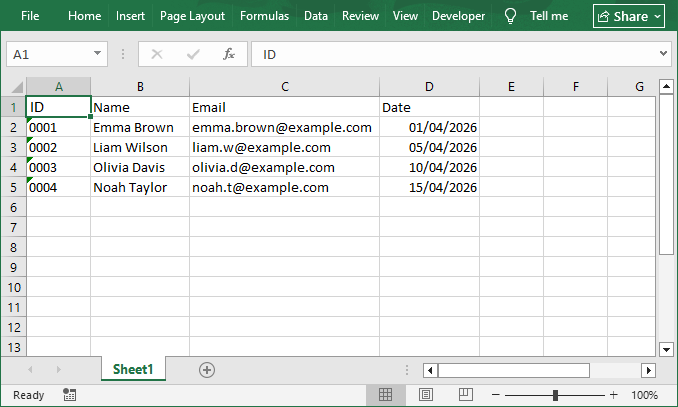
Abra o Excel e organize seus dados em linhas e colunas. Cada coluna deve ter um cabeçalho claro (por exemplo, “ID”, “Nome”, “E-mail”, “Data”), e cada linha deve representar uma única entrada.
Dicas importantes para compatibilidade com CSV:
- Remova células mescladas, filtros ou formatação condicional (arquivos CSV não podem reter isso).
- Converta fórmulas em valores.
- Formate colunas com zeros à esquerda como “Texto” para preservar os zeros.
Exemplo de Dados:
Etapa 2: Salvar o Arquivo como CSV
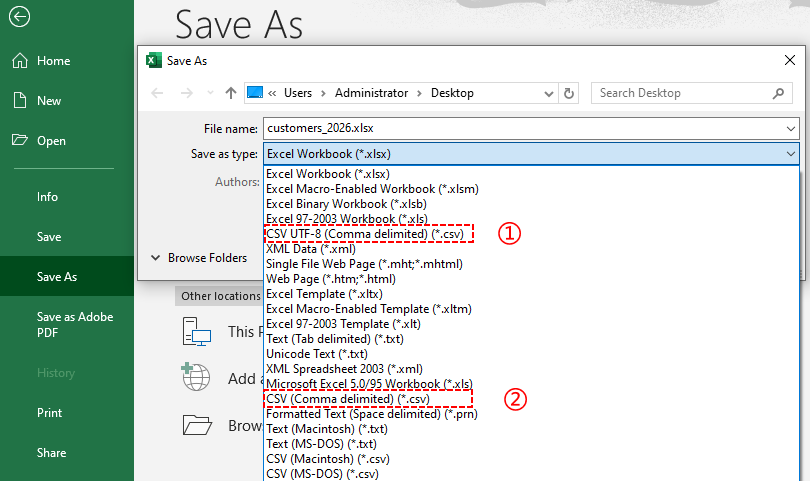
Clique em “Arquivo” → “Salvar Como” → escolha um local. Na lista suspensa “Salvar como tipo”, selecione:
- CSV UTF‑8 (delimitado por vírgula) (*.csv): melhor para caracteres não ingleses
- CSV (delimitado por vírgula) (*.csv): padrão, mas pode quebrar caracteres especiais
Etapa 3: Nomeie seu Arquivo e Salve
Dê um nome descritivo ao seu arquivo e clique em “Salvar”. O Excel exibirá um aviso de que alguns recursos (como formatação) serão perdidos – basta clicar em “Sim”.
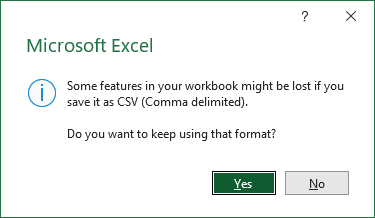
Dica Profissional: Para sistemas europeus que usam ponto e vírgula como delimitadores, altere suas configurações regionais do Windows primeiro e depois salve como CSV.
Método 3: Criar CSV com Google Sheets (Grátis)
Se você não tem Excel ou prefere ferramentas baseadas em nuvem (sem necessidade de instalação de software), o Google Sheets é uma alternativa gratuita. Ele funciona em qualquer navegador e facilita a colaboração.
Veja como criar um arquivo CSV no Google Sheets:
-
Abra o Google Sheets: Vá para sheets.google.com, faça login com sua conta do Google e crie uma nova planilha em branco.
-
Insira seus Dados: Assim como no Excel, insira seus dados estruturados nas células.
-
Baixar como CSV: Clique no menu “Arquivo”, passe o mouse sobre “Download” e selecione “Valores separados por vírgula (.csv)” no menu suspenso. (Observe que o Google Sheets exporta apenas a planilha ativa atual. Certifique-se de que você está na guia correta antes de baixar.)
-
Salve o Arquivo: Seu navegador baixará automaticamente o arquivo CSV para a pasta “Downloads” do seu computador. Você pode então movê-lo para o local desejado.
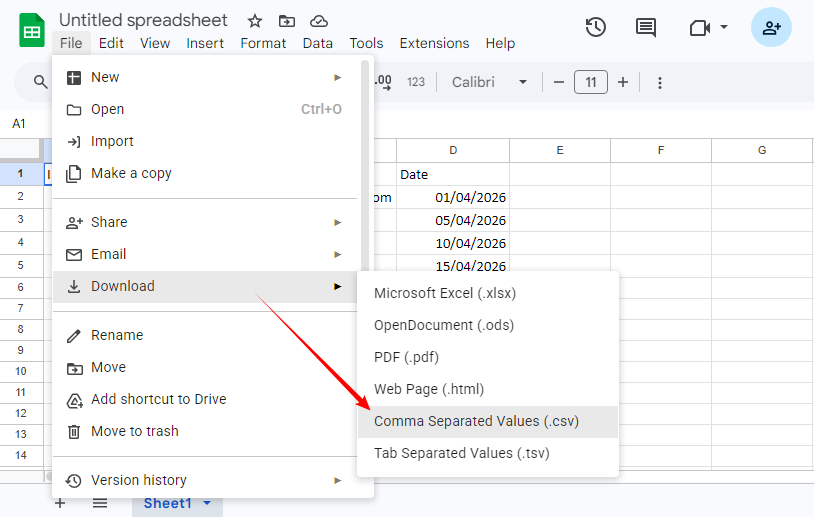
Vantagem: O Google Sheets lida automaticamente com a codificação UTF‑8, portanto, emojis e caracteres internacionais são preservados.
Método 4: Criar um Arquivo CSV em Python
Ao trabalhar com grandes conjuntos de dados ou precisar automatizar a geração de CSV (por exemplo, processamento em lote), o Python é uma ferramenta poderosa. Usaremos a biblioteca Spire.XLS Gratuita para Python para controle total sobre a codificação e os delimitadores.
Etapa 1: Instalar a Biblioteca Python Gratuita
Antes de começar, abra seu prompt de comando ou terminal e execute:
pip install Spire.XLS.Free
Etapa 2: Escrever Código Python para Gerar CSV
Crie um novo arquivo Python e adicione o seguinte código. Este exemplo cria um arquivo CSV do zero com dados estáticos:
from spire.xls import *
from spire.xls.common import *
# 1. Criar um novo workbook
workbook = Workbook()
# 2. Obter a primeira planilha
worksheet = workbook.Worksheets[0]
# 3. Preencher dados nas células
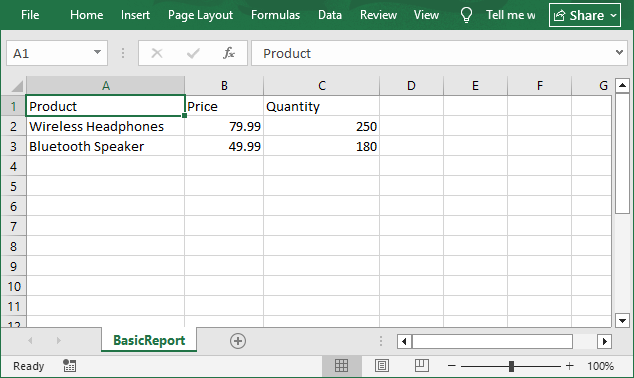
# Linha de cabeçalho
worksheet.Range["A1"].Text = "Produto"
worksheet.Range["B1"].Text = "Preço"
worksheet.Range["C1"].Text = "Quantidade"
worksheet.Range["A2"].Text = "Fones de Ouvido Sem Fio"
worksheet.Range["B2"].NumberValue = 79.99
worksheet.Range["C2"].NumberValue = 250
worksheet.Range["A3"].Text = "Caixa de Som Bluetooth"
worksheet.Range["B3"].NumberValue = 49.99
worksheet.Range["C3"].NumberValue = 180
# 4. Salvar a planilha em CSV
worksheet.SaveToFile("BasicReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Abrir o CSV gerado no Excel:
Exemplos Avançados com Spire.XLS Gratuito
Especificando um delimitador e codificação personalizados
# Salvar com delimitadores de ponto e vírgula (para sistemas europeus)
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
# Salvar com delimitadores de tabulação
worksheet.SaveToFile("output.csv", "\t", Encoding.get_UTF8())
# Salvar com codificação Unicode
worksheet.SaveToFile("output.csv", ",", Encoding.get_Unicode())
Exportar um arquivo Excel existente para CSV:
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
worksheet = workbook.Worksheets[0]
worksheet.SaveToFile("output.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Para desenvolvedores C#: Aprenda Como Criar um Arquivo CSV em C# (Do Zero, Lista ou Excel)
Bônus: Gerar Arquivo CSV de Diferentes Fontes de Dados
Arquivos CSV podem ser criados a partir de praticamente qualquer fonte de dados. Abaixo estão os cenários mais comuns.
Do Excel para CSV
- Método A: Abra o arquivo Excel no Excel → Salvar Como → CSV (como no Método 2).
- Método B: Use o Spire.XLS Gratuito para Python como mostrado no Método 4 – carregue o arquivo Excel e chame SaveToFile.
Do JSON para CSV
JSON é o formato padrão para APIs da web. Convertê-lo para CSV permite analisar os dados em planilhas ou bancos de dados.
- Tutorial completo: Converter JSON para CSV – inclui exemplos em Python, usando MS Excel e conversores online.
De Tabelas PDF para CSV
PDFs são ótimos para impressão, mas terríveis para dados estruturados. Para extrair tabelas para CSV, use uma destas abordagens:
- Adobe Acrobat Pro: Abra PDF → Exportar → Planilha → Salvar como CSV.
- Conversores online: Faça upload do PDF e depois baixe como CSV.
- Biblioteca Python (Spire.PDF): Extraia automaticamente tabelas de todas as páginas PDF e exporte para CSV.
Para um guia completo, veja: Converter Tabelas PDF para CSV: Manual, Online e Automatizado
Conclusão
Não importa seu nível de habilidade ou as ferramentas que você tem à mão, gerar um arquivo CSV é simples. Você não precisa ser um desenvolvedor ou possuir software caro. Alguns cliques no Excel ou Google Sheets, algumas linhas de Python, ou até mesmo um editor de texto simples podem fazer o trabalho.
Para ajudá-lo a escolher a abordagem certa rapidamente, aqui está um resumo:
| Método | Melhor para | Dificuldade |
|---|---|---|
| Editor de texto | Dados minúsculos e simples | ★ Iniciante |
| Excel | Planilhas existentes, uso ocasional | ★ Iniciante |
| Google Sheets | Grátis, baseado em nuvem, sem instalação | ★ Iniciante |
| Python com Spire.XLS Gratuito | Grandes volumes de dados, automação, multiplataforma | ★★ Intermediário |
O melhor método é aquele que se adapta às suas necessidades imediatas: tamanho dos dados, nível de habilidade ou automação. Qualquer que seja sua escolha, o resultado é o mesmo: um arquivo CSV limpo e universal que funciona perfeitamente em qualquer plataforma.
Perguntas Frequentes sobre Geração de Arquivos CSV
P: Qual é a diferença entre arquivos CSV e Excel?
R: Arquivos CSV são texto puro com valores separados por vírgula (sem formatação/fórmulas), enquanto arquivos Excel são binários e podem armazenar formatação, gráficos e fórmulas. Arquivos CSV são menores e mais compatíveis, enquanto o Excel é melhor para análise de dados complexos.
P: Posso ter várias planilhas em um arquivo CSV?
R: Não. CSV é um formato de planilha única. Você precisa de arquivos CSV separados para cada planilha, ou converter para Excel (XLSX).
P: Posso usar um delimitador personalizado (ponto e vírgula, tabulação) em vez de vírgulas?
R: Sim. No Excel/Google Sheets, selecione o formato delimitado ao salvar. Em Python, defina o delimitador no método SaveToFile.
P: Posso criar um arquivo CSV online gratuitamente?
R: Sim, use ferramentas online de geração de CSV como ConvertCSV e TableConvert. No entanto, evite enviar dados confidenciais.
Veja Também
- Converter CSV para TXT: 4 Métodos Fáceis para Todos os Usuários
- 4 Maneiras Comprovadas de Converter CSV para Excel (Grátis e Automatizado)
- Lista Python para CSV: 1D/2D/Dicionários – Tutorial Fácil
- Como Ler Arquivos CSV em Python: Um Guia Abrangente
- C#/VB.NET: Converter Excel para CSV e CSV para Excel
CSV 파일 생성 방법: 4가지 간단한 방법
CSV(쉼표로 구분된 값) 파일은 데이터 교환을 위한 보편적인 표준입니다. 가볍고 사람이 읽기 쉬우며 Microsoft Excel, Google Sheets 및 Python과 같은 프로그래밍 언어와 호환됩니다. 고객 데이터를 정리하거나, 보고서를 내보내거나, 정보를 마이그레이션하거나, ML 데이터 세트를 구축하는 경우 CSV 파일을 생성하는 방법을 아는 것은 기본적인 기술입니다.
이 가이드에서는 코드가 필요 없는 빠른 방법부터 자동화된 스크립트까지 4가지의 간단하고 실행 가능한 방법을 통해 CSV 파일을 만드는 방법을 안내합니다. 또한 특수 문자를 처리하고 JSON, PDF 및 Excel에서 CSV로 데이터를 변환하는 팁도 제공합니다.
- 방법 1: 텍스트 편집기로 수동 생성
- 방법 2: Microsoft Excel로 CSV 생성
- 방법 3: Google Sheets로 CSV 생성 (무료)
- 방법 4: Python으로 CSV 파일 생성
- 보너스: 다양한 데이터 소스에서 CSV 파일 생성
CSV 파일을 사용해야 하는 이유는 무엇인가요?
CSV 파일은 일반 텍스트로 표 형식 데이터를 저장합니다. 각 줄은 데이터 레코드를 나타내고 각 레코드는 쉼표로 구분된 필드를 포함합니다.
CSV의 주요 장점:
- 보편적인 호환성 – 대부분의 스프레드시트 도구, CRM, 데이터베이스 및 프로그래밍 언어와 작동합니다.
- 가벼움 – 독점적인 서식이 없고 파일 크기가 작습니다.
- 데이터 교환에 이상적 – 다른 시스템 간에 빠르고 가져오기/내보내기가 가능합니다.
- 무료 및 개방형 표준 – 유료 도구 없이 무료로 생성하고 사용할 수 있습니다.
일반적인 사용 사례:
- 전자 상거래 플랫폼에 제품 목록 업로드
- CRM으로 리드/연락처 가져오기
- 데이터 백업 또는 마이그레이션
- Python(pandas), R 또는 SQL 데이터베이스에 데이터 공급
방법 1: 텍스트 편집기로 수동 생성
작고 간단한 데이터 세트(예: 짧은 이름 및 이메일 목록)의 경우 메모장(Windows)과 같은 텍스트 편집기를 사용하여 CSV 파일을 수동으로 만들 수 있습니다.
참고: 이 방법은 대규모 데이터의 경우 오류가 발생하기 쉽습니다. 빠르고 작은 목록에만 사용하세요.
CSV 파일 수동 생성 단계:
- 텍스트 편집기를 엽니다.
- 각 줄을 새 줄에 입력합니다. 값을 쉼표로 구분합니다. 예:
- “파일” → “다른 이름으로 저장”을 클릭합니다.
- 파일 이름을 .csv 확장자(예: simple_data.csv)로 지정하고 “파일 형식”을 “모든 파일”로 변경한 후 저장합니다.
까다로운 데이터 처리
필드에 쉼표나 줄 바꿈이 포함된 경우 큰따옴표로 묶습니다. 예:
"Smith, John",john@example.com,"Hello\nworld!"
기존 텍스트 파일을 열고 3-4단계를 따라 CSV 파일로 저장할 수도 있습니다. 더 많은 변환 방법은 다음을 참조하세요: TXT를 CSV로 변환하는 3가지 최고의 방법 (빠르고 오류 없음)
방법 2: Microsoft Excel로 CSV 생성
Excel은 특히 스프레드시트 작업을 이미 하고 있다면 CSV 파일을 만드는 가장 일반적인 도구입니다. 서식 오류를 피하고 CSV를 사용할 수 있도록 하려면 다음 단계별 지침을 따르세요.
1단계: Excel에서 데이터 준비
Excel을 열고 데이터를 행과 열로 구성합니다. 각 열에는 명확한 헤더(예: “ID”, “이름”, “이메일”, “날짜”)가 있어야 하며 각 행은 단일 항목을 나타내야 합니다.
CSV 호환성을 위한 중요 팁:
- 병합된 셀, 필터 또는 조건부 서식 제거 (CSV 파일은 이를 유지할 수 없습니다).
- 수식을 값으로 변환합니다.
- 선행 0이 있는 열을 “텍스트”로 서식을 지정하여 0을 유지합니다.
예제 데이터:
2단계: 파일을 CSV로 저장
“파일” → “다른 이름으로 저장”을 클릭하고 위치를 선택합니다. “파일 형식” 드롭다운에서 다음을 선택합니다.
- CSV UTF-8(쉼표로 구분) (*.csv): 비영어 문자에 가장 적합합니다.
- CSV(쉼표로 구분) (*.csv): 표준이지만 특수 문자가 깨질 수 있습니다.
3단계: 파일 이름 지정 및 저장
파일에 설명적인 이름을 지정하고 “저장”을 클릭합니다. Excel에서 일부 기능(예: 서식)이 손실된다는 경고가 표시됩니다. “예”를 클릭하기만 하면 됩니다.
전문가 팁: 구분 기호로 세미콜론을 사용하는 유럽 시스템의 경우 먼저 Windows 지역 설정을 변경한 다음 CSV로 저장합니다.
방법 3: Google Sheets로 CSV 생성 (무료)
Excel이 없거나 클라우드 기반 도구를 선호하는 경우(소프트웨어 설치 불필요) Google Sheets는 무료 대안입니다. 모든 브라우저에서 작동하며 협업을 쉽게 만듭니다.
Google Sheets에서 CSV 파일을 만드는 방법:
-
Google Sheets 열기: sheets.google.com으로 이동하여 Google 계정으로 로그인하고 새 빈 스프레드시트를 만듭니다.
-
데이터 입력: Excel과 마찬가지로 셀에 구조화된 데이터를 입력합니다.
-
CSV로 다운로드: “파일” 메뉴를 클릭하고 “다운로드”로 이동한 다음 드롭다운 메뉴에서 “쉼표로 구분된 값(.csv)”을 선택합니다. (Google Sheets는 현재 활성 시트만 내보냅니다. 다운로드하기 전에 올바른 탭에 있는지 확인하세요.)
-
파일 저장: 브라우저에서 CSV 파일을 컴퓨터의 “다운로드” 폴더로 자동으로 다운로드합니다. 그런 다음 원하는 위치로 이동할 수 있습니다.
장점: Google Sheets는 UTF-8 인코딩을 자동으로 처리하므로 이모티콘과 국제 문자가 보존됩니다.
방법 4: Python으로 CSV 파일 생성
대규모 데이터 세트를 다루거나 CSV 생성을 자동화해야 하는 경우(예: 일괄 처리) Python은 강력한 도구입니다. 인코딩 및 구분 기호에 대한 완전한 제어를 위해 무료 Spire.XLS for Python 라이브러리를 사용합니다.
1단계: 무료 Python 라이브러리 설치
시작하기 전에 명령 프롬프트 또는 터미널을 열고 다음을 실행합니다.
pip install Spire.XLS.Free
2단계: CSV 생성을 위한 Python 코드 작성
새 Python 파일을 만들고 다음 코드를 추가합니다. 이 예제에서는 정적 데이터로 처음부터 CSV 파일을 만듭니다.
from spire.xls import *
from spire.xls.common import *
# 1. 새 워크북 생성
workbook = Workbook()
# 2. 첫 번째 워크시트 가져오기
worksheet = workbook.Worksheets[0]
# 3. 셀에 데이터 채우기
# 헤더 행
worksheet.Range["A1"].Text = "Product"
worksheet.Range["B1"].Text = "Price"
worksheet.Range["C1"].Text = "Quantity"
worksheet.Range["A2"].Text = "Wireless Headphones"
worksheet.Range["B2"].NumberValue = 79.99
worksheet.Range["C2"].NumberValue = 250
worksheet.Range["A3"].Text = "Bluetooth Speaker"
worksheet.Range["B3"].NumberValue = 49.99
worksheet.Range["C3"].NumberValue = 180
# 4. 워크시트를 CSV로 저장
worksheet.SaveToFile("BasicReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
생성된 CSV를 Excel에서 열기:
Free Spire.XLS를 사용한 고급 예제
사용자 지정 구분 기호 및 인코딩 지정
# 세미콜론 구분 기호로 저장 (유럽 시스템용)
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
# 탭 구분 기호로 저장
worksheet.SaveToFile("output.csv", "\t", Encoding.get_UTF8())
# 유니코드 인코딩으로 저장
worksheet.SaveToFile("output.csv", ",", Encoding.get_Unicode())
기존 Excel 파일을 CSV로 내보내기:
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
worksheet = workbook.Worksheets[0]
worksheet.SaveToFile("output.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
C# 개발자용: C#에서 CSV 파일 생성 방법(처음부터, 목록 또는 Excel) 알아보기
보너스: 다양한 데이터 소스에서 CSV 파일 생성
CSV 파일은 거의 모든 데이터 소스에서 만들 수 있습니다. 아래는 가장 일반적인 시나리오입니다.
Excel에서 CSV로
- 방법 A: Excel에서 Excel 파일 열기 → 다른 이름으로 저장 → CSV (방법 2와 같음).
- 방법 B: 방법 4에 표시된 대로 Free Spire.XLS for Python 사용 – Excel 파일을 로드하고 SaveToFile 호출.
JSON에서 CSV로
JSON은 웹 API의 표준 형식입니다. 이를 CSV로 변환하면 스프레드시트나 데이터베이스에서 데이터를 분석할 수 있습니다.
- 전체 튜토리얼: JSON을 CSV로 변환 – Python 예제, MS Excel 및 온라인 변환기 사용 포함.
PDF 테이블에서 CSV로
PDF는 인쇄에는 좋지만 구조화된 데이터에는 좋지 않습니다. 테이블을 CSV로 추출하려면 다음 방법 중 하나를 사용하세요.
- Adobe Acrobat Pro: PDF 열기 → 내보내기 → 스프레드시트 → CSV로 저장.
- 온라인 변환기: PDF 업로드 후 CSV로 다운로드.
- Python 라이브러리 (Spire.PDF): 모든 PDF 페이지에서 테이블을 자동으로 추출하여 CSV로 내보냅니다.
전체 가이드는 다음을 참조하세요: PDF 테이블을 CSV로 변환: 수동, 온라인 및 자동
결론
기술 수준이나 보유한 도구에 관계없이 CSV 파일 생성은 간단합니다. 개발자이거나 값비싼 소프트웨어를 소유할 필요가 없습니다. Excel 또는 Google Sheets에서 몇 번의 클릭, 몇 줄의 Python 코드 또는 일반 텍스트 편집기로도 작업을 완료할 수 있습니다.
한눈에 올바른 접근 방식을 선택하는 데 도움이 되도록 요약합니다.
| 방법 | 가장 적합한 대상 | 난이도 |
|---|---|---|
| 텍스트 편집기 | 매우 작고 간단한 데이터 | ★ 초급 |
| Excel | 기존 스프레드시트, 가끔 사용 | ★ 초급 |
| Google Sheets | 무료, 클라우드 기반, 설치 불필요 | ★ 초급 |
| Free Spire.XLS가 포함된 Python | 대규모 데이터, 자동화, 크로스 플랫폼 | ★★ 중급 |
가장 좋은 방법은 즉각적인 요구 사항(데이터 크기, 기술 수준 또는 자동화)에 맞는 것입니다. 어떤 방법을 선택하든 결과는 동일합니다. 즉, 모든 플랫폼에서 원활하게 작동하는 깔끔하고 보편적인 CSV 파일입니다.
CSV 파일 생성에 대한 FAQ
Q: CSV와 Excel 파일의 차이점은 무엇인가요?
A: CSV 파일은 쉼표로 구분된 값이 있는 일반 텍스트(서식/수식 없음)인 반면 Excel 파일은 이진이며 서식, 차트 및 수식을 저장할 수 있습니다. CSV 파일은 더 작고 호환성이 높으며 Excel은 복잡한 데이터 분석에 더 좋습니다.
Q: CSV 파일에 여러 시트를 가질 수 있나요?
A: 아니요. CSV는 단일 시트 형식입니다. 각 시트에 대해 별도의 CSV 파일이 필요하거나 Excel(XLSX)로 변환해야 합니다.
Q: 쉼표 대신 사용자 지정 구분 기호(세미콜론, 탭)를 사용할 수 있나요?
A: 예. Excel/Google Sheets에서는 저장 시 구분 기호 형식을 선택합니다. Python에서는 SaveToFile 메서드에서 구분 기호를 설정합니다.
Q: 온라인에서 무료로 CSV 파일을 만들 수 있나요?
A: 예, ConvertCSV 및 TableConvert와 같은 온라인 CSV 생성기 도구를 사용할 수 있습니다. 그러나 민감한 데이터를 업로드하지 않도록 주의하세요.
참고
Come generare un file CSV: 4 semplici metodi
Indice
I file CSV (Comma-Separated Values) sono lo standard universale per lo scambio di dati: leggeri, leggibili dall'uomo e compatibili con Microsoft Excel, Google Sheets e linguaggi di programmazione come Python. Sia che tu stia organizzando dati dei clienti, esportando report, migrando informazioni o creando set di dati per ML, sapere come generare un file CSV è un'abilità fondamentale.
Questa guida ti illustra 4 metodi semplici e attuabili per creare un file CSV, da metodi rapidi senza codice a script automatizzati. Riceverai anche suggerimenti per gestire caratteri speciali e convertire dati da JSON, PDF ed Excel in CSV.
- Metodo 1: Creazione manuale con un editor di testo
- Metodo 2: Genera CSV con Microsoft Excel
- Metodo 3: Crea CSV con Google Sheets (Gratuito)
- Metodo 4: Crea un file CSV in Python
- Bonus: Genera file CSV da diverse origini dati
Perché dovresti usare i file CSV?
Un file CSV memorizza dati tabulari in testo semplice. Ogni riga rappresenta un record di dati e ogni record contiene campi separati da virgole.
Vantaggi principali dei CSV:
- Compatibilità universale – Funziona con la maggior parte degli strumenti per fogli di calcolo, CRM, database e linguaggi di programmazione.
- Leggero – Nessuna formattazione proprietaria, dimensioni ridotte del file.
- Ideale per lo scambio di dati – Veloce da importare/esportare tra diversi sistemi.
- Standard gratuito e aperto – Gratuito da creare e utilizzare senza strumenti a pagamento.
Casi d'uso comuni:
- Caricamento di elenchi di prodotti su una piattaforma di e-commerce
- Importazione di lead/contatti nei CRM
- Backup o migrazione dati
- Alimentazione di dati in Python (pandas), R o database SQL
Metodo 1: Creazione manuale con un editor di testo
Per set di dati piccoli e semplici (ad esempio, un breve elenco di nomi ed email), puoi creare manualmente un file CSV utilizzando un editor di testo come Blocco note (Windows).
Nota: Questo metodo è soggetto a errori per dati di grandi dimensioni – utilizzalo solo per elenchi rapidi e minuscoli.
Passaggi per la creazione manuale di file CSV:
- Apri il tuo editor di testo.
- Digita ogni riga su una nuova linea. Separa i valori con virgole. Ad esempio:
- Fai clic su "File" → "Salva con nome".
- Nomina il file con un'estensione .csv (ad esempio, dati_semplici.csv) e cambia "Salva come tipo" in "Tutti i file" → Salva.
Gestione di dati complessi
Se un campo contiene una virgola o un'interruzione di riga, racchiudilo tra virgolette doppie. Esempio:
"Rossi, Mario",mario@esempio.com,"Ciao\nmondo!"
Puoi anche aprire un file di testo esistente e seguire i passaggi 3-4 per salvarlo come file CSV. Per altri metodi di conversione, fai riferimento a: 3 modi migliori per convertire TXT in CSV (veloce e senza errori)
Metodo 2: Genera CSV con Microsoft Excel
Excel è lo strumento più comune per creare file CSV, soprattutto se lavori già con fogli di calcolo. Segui queste istruzioni passo passo per evitare errori di formattazione e garantire che il tuo CSV sia utilizzabile.
Passaggio 1: Prepara i tuoi dati in Excel
Apri Excel e organizza i tuoi dati in righe e colonne. Ogni colonna dovrebbe avere un'intestazione chiara (ad esempio, "ID", "Nome", "Email", "Data") e ogni riga dovrebbe rappresentare una singola voce.
Suggerimenti importanti per la compatibilità CSV:
- Rimuovi celle unite, filtri o formattazione condizionale (i file CSV non possono conservarli).
- Converti formule in valori.
- Formatta le colonne con zeri iniziali come "Testo" per preservare gli zeri.
Dati di esempio:
Passaggio 2: Salva il file come CSV
Fai clic su "File" → "Salva con nome" → scegli una posizione. Nel menu a discesa "Salva come tipo", seleziona:
- CSV UTF-8 (delimitato da virgole) (*.csv): migliore per caratteri non inglesi
- CSV (delimitato da virgole) (*.csv): standard ma potrebbe danneggiare caratteri speciali
Passaggio 3: Nomina il tuo file e salva
Dai un nome descrittivo al tuo file e fai clic su "Salva". Excel visualizzerà un avviso che alcune funzionalità (come la formattazione) andranno perse – fai semplicemente clic su "Sì".
Suggerimento Pro: Per i sistemi europei che utilizzano il punto e virgola come delimitatore, modifica prima le impostazioni regionali di Windows, quindi salva come CSV.
Metodo 3: Crea CSV con Google Sheets (Gratuito)
Se non hai Excel o preferisci strumenti basati su cloud (nessuna installazione di software richiesta), Google Sheets è un'alternativa gratuita. Funziona in qualsiasi browser e facilita la collaborazione.
Ecco come creare un file CSV in Google Sheets:
-
Apri Google Sheets: Vai su sheets.google.com, accedi con il tuo account Google e crea un nuovo foglio di calcolo vuoto.
-
Inserisci i tuoi dati: Proprio come Excel, inserisci i tuoi dati strutturati nelle celle.
-
Scarica come CSV: Fai clic sul menu "File", passa il mouse su "Scarica" e seleziona "Valori separati da virgole (.csv)" dal menu a discesa. (Nota che Google Sheets esporta solo il foglio attivo corrente. Assicurati di essere sulla scheda corretta prima di scaricare.)
-
Salva il file: Il tuo browser scaricherà automaticamente il file CSV nella cartella "Download" del tuo computer. Puoi quindi spostarlo nella posizione desiderata.
Vantaggio: Google Sheets gestisce automaticamente la codifica UTF-8, quindi emoji e caratteri internazionali vengono conservati.
Metodo 4: Crea un file CSV in Python
Quando si lavora con grandi set di dati o è necessario automatizzare la generazione di CSV (ad esempio, elaborazione batch), Python è uno strumento potente. Utilizzeremo la libreria Spire.XLS gratuito per Python per un controllo completo su codifica e delimitatori.
Passaggio 1: Installa la libreria Python gratuita
Prima di iniziare, apri il prompt dei comandi o il terminale ed esegui:
pip install Spire.XLS.Free
Passaggio 2: Scrivi codice Python per generare CSV
Crea un nuovo file Python e aggiungi il seguente codice. Questo esempio crea un file CSV da zero con dati statici:
from spire.xls import *
from spire.xls.common import *
# 1. Crea una nuova cartella di lavoro
workbook = Workbook()
# 2. Ottieni il primo foglio di lavoro
worksheet = workbook.Worksheets[0]
# 3. Popola i dati nelle celle
# Riga di intestazione
worksheet.Range["A1"].Text = "Prodotto"
worksheet.Range["B1"].Text = "Prezzo"
worksheet.Range["C1"].Text = "Quantità"
worksheet.Range["A2"].Text = "Cuffie Wireless"
worksheet.Range["B2"].NumberValue = 79.99
worksheet.Range["C2"].NumberValue = 250
worksheet.Range["A3"].Text = "Altoparlante Bluetooth"
worksheet.Range["B3"].NumberValue = 49.99
worksheet.Range["C3"].NumberValue = 180
# 4. Salva il foglio di lavoro in CSV
worksheet.SaveToFile("BasicReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Apri il CSV generato in Excel:
Esempi avanzati con Spire.XLS gratuito
Specificare un delimitatore e una codifica personalizzati
# Salva con delimitatori punto e virgola (per sistemi europei)
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
# Salva con delimitatori di tabulazione
worksheet.SaveToFile("output.csv", "\t", Encoding.get_UTF8())
# Salva con codifica Unicode
worksheet.SaveToFile("output.csv", ",", Encoding.get_Unicode())
Esportazione di un file Excel esistente in CSV:
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
worksheet = workbook.Worksheets[0]
worksheet.SaveToFile("output.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Per sviluppatori C#: scopri Come creare un file CSV in C# (da zero, lista o Excel)
Bonus: Genera file CSV da diverse origini dati
I file CSV possono essere creati da quasi tutte le origini dati. Di seguito sono riportati gli scenari più comuni.
Da Excel a CSV
- Metodo A: Apri il file Excel in Excel → Salva con nome → CSV (come nel Metodo 2).
- Metodo B: Utilizza Spire.XLS gratuito per Python come mostrato nel Metodo 4: carica il file Excel e chiama SaveToFile.
Da JSON a CSV
JSON è il formato standard per le API web. La conversione in CSV ti consente di analizzare i dati nei fogli di calcolo o nei database.
- Tutorial completo: Converti JSON in CSV – include esempi Python, utilizzo di MS Excel e convertitori online.
Da tabelle PDF a CSV
I PDF sono ottimi per la stampa ma terribili per i dati strutturati. Per estrarre tabelle in CSV, utilizza uno di questi approcci:
- Adobe Acrobat Pro: Apri PDF → Esporta → Foglio di calcolo → Salva come CSV.
- Convertitori online: Carica il PDF e poi scarica come CSV.
- Libreria Python (Spire.PDF): Estrai automaticamente tabelle da tutte le pagine PDF ed esporta in CSV.
Per una guida completa, vedi: Converti tabelle PDF in CSV: Manuale, Online e Automatizzato
Conclusione
Indipendentemente dal tuo livello di competenza o dagli strumenti che hai a disposizione, generare un file CSV è semplice. Non hai bisogno di essere uno sviluppatore o di possedere software costosi. Pochi clic in Excel o Google Sheets, poche righe di Python, o anche un semplice editor di testo possono portare a termine il lavoro.
Per aiutarti a scegliere l'approccio giusto a colpo d'occhio, ecco un breve riepilogo:
| Metodo | Ideale per | Difficoltà |
|---|---|---|
| Editor di testo | Dati minuscoli e semplici | ★ Principiante |
| Excel | Fogli di calcolo esistenti, uso occasionale | ★ Principiante |
| Google Sheets | Gratuito, basato su cloud, nessuna installazione | ★ Principiante |
| Python con Spire.XLS gratuito | Grandi volumi di dati, automazione, multipiattaforma | ★★ Intermedio |
Il metodo migliore è quello che si adatta alle tue esigenze immediate: dimensione dei dati, livello di competenza o automazione. Qualunque tu scelga, il risultato è lo stesso: un file CSV pulito e universale che funziona senza problemi su qualsiasi piattaforma.
Domande frequenti sulla generazione di file CSV
D: Qual è la differenza tra file CSV e file Excel?
R: I file CSV sono testo semplice con valori separati da virgole (nessuna formattazione/formule), mentre i file Excel sono binari e possono memorizzare formattazione, grafici e formule. I file CSV sono più piccoli e più compatibili, mentre Excel è migliore per analisi di dati complesse.
D: Posso avere più fogli in un file CSV?
R: No. CSV è un formato a foglio singolo. Hai bisogno di file CSV separati per ogni foglio, o convertire in Excel (XLSX).
D: Posso usare un delimitatore personalizzato (punto e virgola, tabulazione) invece delle virgole?
R: Sì. In Excel/Google Sheets, seleziona il formato delimitato durante il salvataggio. In Python, imposta il delimitatore nel metodo SaveToFile.
D: Posso creare un file CSV online gratuitamente?
R: Sì, usa strumenti online per la generazione di CSV come ConvertCSV e TableConvert. Tuttavia, evita di caricare dati sensibili.
Vedi anche
Comment générer un fichier CSV : 4 méthodes simples
Table des matières
Les fichiers CSV (Comma-Separated Values) sont la norme universelle pour l'échange de données : légers, lisibles par l'homme et compatibles avec Microsoft Excel, Google Sheets et les langages de programmation comme Python. Que vous organisiez des données clients, exportiez des rapports, migriez des informations ou construisiez des ensembles de données ML, savoir comment générer un fichier CSV est une compétence fondamentale.
Ce guide vous présente 4 méthodes simples et actionnables pour créer un fichier CSV, des méthodes rapides sans code aux scripts automatisés. Vous obtiendrez également des conseils pour gérer les caractères spéciaux et convertir des données de JSON, PDF et Excel en CSV.
- Méthode 1 : Créer manuellement avec un éditeur de texte
- Méthode 2 : Générer un CSV avec Microsoft Excel
- Méthode 3 : Créer un CSV avec Google Sheets (Gratuit)
- Méthode 4 : Créer un fichier CSV en Python
- Bonus : Générer un fichier CSV à partir de différentes sources de données
Pourquoi utiliser des fichiers CSV ?
Un fichier CSV stocke des données tabulaires en texte brut. Chaque ligne représente un enregistrement de données, et chaque enregistrement contient des champs séparés par des virgules.
Avantages principaux des CSV :
- Compatibilité universelle – Fonctionne avec la plupart des outils de tableur, CRM, bases de données et langages de programmation.
- Léger – Pas de formatage propriétaire, petite taille de fichier.
- Idéal pour l'échange de données – Rapide à importer/exporter entre différents systèmes.
- Norme libre et ouverte – Gratuit à créer et à utiliser sans outils payants.
Cas d'utilisation courants :
- Téléchargement de listes de produits sur une plateforme e-commerce
- Importation de prospects/contacts dans les CRM
- Sauvegarde ou migration de données
- Alimentation de données dans Python (pandas), R ou des bases de données SQL
Méthode 1 : Créer manuellement avec un éditeur de texte
Pour des ensembles de données petits et simples (par exemple, une courte liste de noms et d'e-mails), vous pouvez créer un fichier CSV manuellement à l'aide d'un éditeur de texte comme le Bloc-notes (Windows).
Remarque : Cette méthode est sujette aux erreurs pour les grandes quantités de données – à n'utiliser que pour des listes rapides et minuscules.
Étapes pour la création manuelle d'un fichier CSV :
- Ouvrez votre éditeur de texte.
- Tapez chaque ligne sur une nouvelle ligne. Séparez les valeurs par des virgules. Par exemple :
- Cliquez sur « Fichier » → « Enregistrer sous ».
- Nommez le fichier avec une extension .csv (par exemple, simple_data.csv) et changez le « Type de fichier » en « Tous les fichiers » → Enregistrer.
Gestion des données délicates
Si un champ contient une virgule ou un saut de ligne, entourez-le de guillemets doubles. Exemple :
"Smith, John",john@example.com,"Hello\nworld!"
Vous pouvez également ouvrir un fichier texte existant et suivre les étapes 3-4 pour l'enregistrer en tant que fichier CSV. Pour plus de méthodes de conversion, référez-vous à : 3 meilleures façons de convertir du TXT en CSV (rapide et sans erreur)
Méthode 2 : Générer un CSV avec Microsoft Excel
Excel est l'outil le plus courant pour créer des fichiers CSV, surtout si vous travaillez déjà avec des feuilles de calcul. Suivez ces instructions étape par étape pour éviter les erreurs de formatage et garantir que votre CSV soit utilisable.
Étape 1 : Préparer vos données dans Excel
Ouvrez Excel et organisez vos données en lignes et colonnes. Chaque colonne doit avoir un en-tête clair (par exemple, « ID », « Nom », « E-mail », « Date »), et chaque ligne doit représenter une seule entrée.
Conseils importants pour la compatibilité CSV :
- Supprimez les cellules fusionnées, les filtres ou la mise en forme conditionnelle (les fichiers CSV ne peuvent pas les conserver).
- Convertissez les formules en valeurs.
- Formatez les colonnes avec des zéros non significatifs en tant que « Texte » pour préserver les zéros.
Exemple de données :
Étape 2 : Enregistrer le fichier en tant que CSV
Cliquez sur « Fichier » → « Enregistrer sous » → choisissez un emplacement. Dans le menu déroulant « Type de fichier », sélectionnez :
- CSV UTF‑8 (délimité par des virgules) (*.csv) : idéal pour les caractères non anglais
- CSV (délimité par des virgules) (*.csv) : standard mais peut poser des problèmes avec les caractères spéciaux
Étape 3 : Nommez votre fichier et enregistrez
Donnez un nom descriptif à votre fichier et cliquez sur « Enregistrer ». Excel affichera un avertissement indiquant que certaines fonctionnalités (comme la mise en forme) seront perdues – cliquez simplement sur « Oui ».
Astuce Pro : Pour les systèmes européens qui utilisent des points-virgules comme délimiteurs, modifiez d'abord vos paramètres régionaux Windows, puis enregistrez au format CSV.
Méthode 3 : Créer un CSV avec Google Sheets (Gratuit)
Si vous n'avez pas Excel ou préférez les outils basés sur le cloud (aucune installation de logiciel requise), Google Sheets est une alternative gratuite. Il fonctionne dans n'importe quel navigateur et facilite la collaboration.
Voici comment créer un fichier CSV dans Google Sheets :
-
Ouvrez Google Sheets : Allez sur sheets.google.com, connectez-vous avec votre compte Google et créez une nouvelle feuille de calcul vierge.
-
Entrez vos données : Comme dans Excel, entrez vos données structurées dans les cellules.
-
Télécharger en CSV : Cliquez sur le menu « Fichier », survolez « Télécharger » et sélectionnez « Valeurs séparées par des virgules (.csv) » dans le menu déroulant. (Notez que Google Sheets n'exporte que la feuille active. Assurez-vous d'être sur le bon onglet avant de télécharger.)
-
Enregistrez le fichier : Votre navigateur téléchargera automatiquement le fichier CSV dans le dossier « Téléchargements » de votre ordinateur. Vous pourrez ensuite le déplacer à l'emplacement souhaité.
Avantage : Google Sheets gère automatiquement l'encodage UTF‑8, de sorte que les emojis et les caractères internationaux sont préservés.
Méthode 4 : Créer un fichier CSV en Python
Lorsque vous travaillez avec de grands ensembles de données ou que vous avez besoin d'automatiser la génération de CSV (par exemple, traitement par lots), Python est un outil puissant. Nous utiliserons la bibliothèque Spire.XLS gratuit pour Python pour un contrôle total sur l'encodage et les délimiteurs.
Étape 1 : Installer la bibliothèque Python gratuite
Avant de commencer, ouvrez votre invite de commande ou votre terminal et exécutez :
pip install Spire.XLS.Free
Étape 2 : Écrire du code Python pour générer un CSV
Créez un nouveau fichier Python et ajoutez le code suivant. Cet exemple crée un fichier CSV à partir de zéro avec des données statiques :
from spire.xls import *
from spire.xls.common import *
# 1. Créer un nouveau classeur
workbook = Workbook()
# 2. Obtenir la première feuille de calcul
worksheet = workbook.Worksheets[0]
# 3. Remplir les données dans les cellules
# Ligne d'en-tête
worksheet.Range["A1"].Text = "Produit"
worksheet.Range["B1"].Text = "Prix"
worksheet.Range["C1"].Text = "Quantité"
worksheet.Range["A2"].Text = "Casque sans fil"
worksheet.Range["B2"].NumberValue = 79.99
worksheet.Range["C2"].NumberValue = 250
worksheet.Range["A3"].Text = "Enceinte Bluetooth"
worksheet.Range["B3"].NumberValue = 49.99
worksheet.Range["C3"].NumberValue = 180
# 4. Enregistrer la feuille de calcul au format CSV
worksheet.SaveToFile("BasicReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Ouvrez le CSV généré dans Excel :
Exemples avancés avec Spire.XLS gratuit
Spécifier un délimiteur et un encodage personnalisés
# Enregistrer avec des délimiteurs point-virgule (pour les systèmes européens)
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
# Enregistrer avec des délimiteurs tabulation
worksheet.SaveToFile("output.csv", "\t", Encoding.get_UTF8())
# Enregistrer avec un encodage Unicode
worksheet.SaveToFile("output.csv", ",", Encoding.get_Unicode())
Exporter un fichier Excel existant au format CSV :
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
worksheet = workbook.Worksheets[0]
worksheet.SaveToFile("output.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Pour les développeurs C# : Apprenez Comment créer un fichier CSV en C# (à partir de zéro, d'une liste ou d'Excel)
Bonus : Générer un fichier CSV à partir de différentes sources de données
Les fichiers CSV peuvent être créés à partir de pratiquement n'importe quelle source de données. Ci-dessous, les scénarios les plus courants.
D'Excel vers CSV
- Méthode A : Ouvrez le fichier Excel dans Excel → Enregistrer sous → CSV (comme dans la Méthode 2).
- Méthode B : Utilisez Spire.XLS gratuit pour Python comme montré dans la Méthode 4 – chargez le fichier Excel et appelez SaveToFile.
De JSON vers CSV
JSON est le format standard pour les API web. Le convertir en CSV vous permet d'analyser les données dans des feuilles de calcul ou des bases de données.
- Tutoriel complet : Convertir JSON en CSV – comprend des exemples Python, l'utilisation de MS Excel et des convertisseurs en ligne.
Des tableaux PDF vers CSV
Les PDF sont parfaits pour l'impression mais terribles pour les données structurées. Pour extraire des tableaux en CSV, utilisez l'une de ces approches :
- Adobe Acrobat Pro : Ouvrez le PDF → Exporter → Feuille de calcul → Enregistrer en CSV.
- Convertisseurs en ligne : Téléchargez le PDF puis téléchargez au format CSV.
- Bibliothèque Python (Spire.PDF) : Extrayez automatiquement les tableaux de toutes les pages PDF et exportez en CSV.
Pour un guide complet, consultez : Convertir des tableaux PDF en CSV : Manuel, en ligne et automatisé
Conclusion
Peu importe votre niveau de compétence ou les outils dont vous disposez, générer un fichier CSV est simple. Vous n'avez pas besoin d'être un développeur ou de posséder des logiciels coûteux. Quelques clics dans Excel ou Google Sheets, quelques lignes de Python, ou même un simple éditeur de texte peuvent faire le travail.
Pour vous aider à choisir la bonne approche en un coup d'œil, voici un bref résumé :
| Méthode | Idéal pour | Difficulté |
|---|---|---|
| Éditeur de texte | Données minuscules et simples | ★ Débutant |
| Excel | Feuilles de calcul existantes, usage occasionnel | ★ Débutant |
| Google Sheets | Gratuit, basé sur le cloud, sans installation | ★ Débutant |
| Python avec Spire.XLS gratuit | Grandes quantités de données, automatisation, multiplateforme | ★★ Intermédiaire |
La meilleure méthode est celle qui correspond à vos besoins immédiats : taille des données, niveau de compétence ou automatisation. Quelle que soit celle que vous choisissez, le résultat est le même : un fichier CSV propre et universel qui fonctionne de manière transparente sur n'importe quelle plateforme.
FAQ sur la génération de fichiers CSV
Q : Quelle est la différence entre les fichiers CSV et les fichiers Excel ?
R : Les fichiers CSV sont du texte brut avec des valeurs séparées par des virgules (pas de formatage/formules), tandis que les fichiers Excel sont binaires et peuvent stocker du formatage, des graphiques et des formules. Les fichiers CSV sont plus petits et plus compatibles, tandis qu'Excel est meilleur pour l'analyse de données complexes.
Q : Puis-je avoir plusieurs feuilles dans un fichier CSV ?
R : Non. CSV est un format à feuille unique. Vous avez besoin de fichiers CSV séparés pour chaque feuille, ou de convertir en Excel (XLSX).
Q : Puis-je utiliser un délimiteur personnalisé (point-virgule, tabulation) au lieu des virgules ?
R : Oui. Dans Excel/Google Sheets, sélectionnez le format délimité lors de l'enregistrement. En Python, définissez le délimiteur dans la méthode SaveToFile.
Q : Puis-je créer un fichier CSV en ligne gratuitement ?
R : Oui, utilisez les outils de génération de CSV en ligne comme ConvertCSV et TableConvert. Cependant, évitez de télécharger des données sensibles.
Voir aussi
- Convertir CSV en TXT : 4 méthodes faciles pour tous les utilisateurs
- 4 façons éprouvées de convertir CSV en Excel (gratuit et automatisé)
- Liste Python vers CSV : 1D/2D/Dictionnaires – Tutoriel facile
- Comment lire des fichiers CSV en Python : Un guide complet
- C#/VB.NET : Convertir Excel en CSV et CSV en Excel
Cómo generar un archivo CSV: 4 métodos sencillos
Tabla de Contenidos
Los archivos CSV (Valores Separados por Comas) son el estándar universal para el intercambio de datos: ligeros, legibles por humanos y compatibles con Microsoft Excel, Google Sheets y lenguajes de programación como Python. Ya sea que estés organizando datos de clientes, exportando informes, migrando información o creando conjuntos de datos de ML, saber cómo generar un archivo CSV es una habilidad fundamental.
Esta guía te muestra 4 métodos sencillos y prácticos para crear un archivo CSV, desde métodos rápidos sin código hasta scripts automatizados. También obtendrás consejos para manejar caracteres especiales y convertir datos de JSON, PDF y Excel a CSV.
- Método 1: Crear manualmente con un editor de texto
- Método 2: Generar CSV con Microsoft Excel
- Método 3: Crear CSV con Google Sheets (Gratis)
- Método 4: Crear un archivo CSV en Python
- Extra: Generar archivo CSV desde diferentes fuentes de datos
¿Por qué deberías usar archivos CSV?
Un archivo CSV almacena datos tabulares en texto plano. Cada línea representa un registro de datos, y cada registro contiene campos separados por comas.
Ventajas principales de los CSV:
- Compatibilidad universal: Funciona con la mayoría de herramientas de hojas de cálculo, CRM, bases de datos y lenguajes de programación.
- Ligero: Sin formato propietario, tamaño de archivo pequeño.
- Ideal para intercambio de datos: Rápido de importar/exportar entre diferentes sistemas.
- Estándar abierto y gratuito: Gratis para crear y usar sin herramientas de pago.
Casos de uso comunes:
- Cargar listas de productos en una plataforma de comercio electrónico
- Importar clientes potenciales/contactos a CRM
- Copia de seguridad o migración de datos
- Alimentar datos en Python (pandas), R o bases de datos SQL
Método 1: Crear manualmente con un editor de texto
Para conjuntos de datos pequeños y simples (por ejemplo, una lista corta de nombres y correos electrónicos), puedes crear un archivo CSV manualmente usando un editor de texto como el Bloc de notas (Windows).
Nota: Este método es propenso a errores para datos grandes; úsalo solo para listas rápidas y pequeñas.
Pasos para la creación manual de archivos CSV:
- Abre tu editor de texto.
- Escribe cada fila en una nueva línea. Separa los valores con comas. Por ejemplo:
- Haz clic en "Archivo" → "Guardar como".
- Nombra el archivo con una extensión .csv (por ejemplo, datos_simples.csv) y cambia "Tipo" a "Todos los archivos" → Guardar.
Manejo de datos complicados
Si un campo contiene una coma o un salto de línea, enciérralo entre comillas dobles. Ejemplo:
"Smith, John",john@example.com,"Hola\nMundo!"
También puedes abrir un archivo de texto existente y seguir los pasos 3-4 para guardarlo como un archivo CSV. Para más métodos de conversión, consulta: 3 Mejores maneras de convertir TXT a CSV (Rápido y sin errores)
Método 2: Generar CSV con Microsoft Excel
Excel es la herramienta más común para crear archivos CSV, especialmente si ya trabajas con hojas de cálculo. Sigue estas instrucciones paso a paso para evitar errores de formato y asegurar que tu CSV sea utilizable.
Paso 1: Prepara tus datos en Excel
Abre Excel y organiza tus datos en filas y columnas. Cada columna debe tener un encabezado claro (por ejemplo, "ID", "Nombre", "Correo electrónico", "Fecha"), y cada fila debe representar una entrada única.
Consejos importantes para la compatibilidad con CSV:
- Elimina celdas combinadas, filtros o formato condicional (los archivos CSV no pueden conservarlos).
- Convierte fórmulas en valores.
- Formatea columnas con ceros a la izquierda como "Texto" para preservar los ceros.
Datos de ejemplo:
Paso 2: Guarda el archivo como CSV
Haz clic en "Archivo" → "Guardar como" → elige una ubicación. En el menú desplegable "Tipo", selecciona:
- CSV UTF-8 (delimitado por comas) (*.csv): mejor para caracteres no ingleses
- CSV (delimitado por comas) (*.csv): estándar pero puede romper caracteres especiales
Paso 3: Nombra tu archivo y guarda
Dale un nombre descriptivo a tu archivo y haz clic en "Guardar". Excel mostrará una advertencia de que algunas características (como el formato) se perderán; simplemente haz clic en "Sí".
Consejo profesional: Para sistemas europeos que usan punto y coma como delimitadores, cambia primero la configuración regional de Windows y luego guarda como CSV.
Método 3: Crear CSV con Google Sheets (Gratis)
Si no tienes Excel o prefieres herramientas basadas en la nube (sin necesidad de instalar software), Google Sheets es una alternativa gratuita. Funciona en cualquier navegador y facilita la colaboración.
Así es como se crea un archivo CSV en Google Sheets:
-
Abrir Google Sheets: Ve a sheets.google.com, inicia sesión con tu cuenta de Google y crea una nueva hoja de cálculo en blanco.
-
Introduce tus datos: Al igual que en Excel, introduce tus datos estructurados en las celdas.
-
Descargar como CSV: Haz clic en el menú "Archivo", pasa el cursor sobre "Descargar" y selecciona "Valores separados por comas (.csv)" en el menú desplegable. (Ten en cuenta que Google Sheets solo exporta la hoja activa actual. Asegúrate de estar en la pestaña correcta antes de descargar).
-
Guardar el archivo: Tu navegador descargará automáticamente el archivo CSV en la carpeta "Descargas" de tu computadora. Luego puedes moverlo a la ubicación deseada.
Ventaja: Google Sheets maneja automáticamente la codificación UTF-8, por lo que los emojis y los caracteres internacionales se conservan.
Método 4: Crear un archivo CSV en Python
Cuando trabajas con grandes conjuntos de datos o necesitas automatizar la generación de CSV (por ejemplo, procesamiento por lotes), Python es una herramienta poderosa. Usaremos la biblioteca Gratuita Spire.XLS para Python para un control total sobre la codificación y los delimitadores.
Paso 1: Instala la biblioteca gratuita de Python
Antes de empezar, abre tu símbolo del sistema o terminal y ejecuta:
pip install Spire.XLS.Free
Paso 2: Escribe código Python para generar CSV
Crea un nuevo archivo Python y añade el siguiente código. Este ejemplo crea un archivo CSV desde cero con datos estáticos:
from spire.xls import *
from spire.xls.common import *
# 1. Crear un nuevo libro de trabajo
workbook = Workbook()
# 2. Obtener la primera hoja de cálculo
worksheet = workbook.Worksheets[0]
# 3. Rellenar datos en las celdas
# Fila de encabezado
worksheet.Range["A1"].Text = "Producto"
worksheet.Range["B1"].Text = "Precio"
worksheet.Range["C1"].Text = "Cantidad"
worksheet.Range["A2"].Text = "Auriculares inalámbricos"
worksheet.Range["B2"].NumberValue = 79.99
worksheet.Range["C2"].NumberValue = 250
worksheet.Range["A3"].Text = "Altavoz Bluetooth"
worksheet.Range["B3"].NumberValue = 49.99
worksheet.Range["C3"].NumberValue = 180
# 4. Guardar la hoja de cálculo en CSV
worksheet.SaveToFile("BasicReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Abre el CSV generado en Excel:
Ejemplos avanzados con Free Spire.XLS
Especificar un delimitador y codificación personalizados
# Guardar con delimitadores de punto y coma (para sistemas europeos)
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
# Guardar con delimitadores de tabulación
worksheet.SaveToFile("output.csv", "\t", Encoding.get_UTF8())
# Guardar con codificación Unicode
worksheet.SaveToFile("output.csv", ",", Encoding.get_Unicode())
Exportar un archivo Excel existente a CSV:
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
worksheet = workbook.Worksheets[0]
worksheet.SaveToFile("output.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Para desarrolladores de C#: Aprende Cómo crear un archivo CSV en C# (desde cero, lista o Excel)
Extra: Generar archivo CSV desde diferentes fuentes de datos
Los archivos CSV se pueden crear a partir de prácticamente cualquier fuente de datos. A continuación se presentan los escenarios más comunes.
De Excel a CSV
- Método A: Abre el archivo de Excel en Excel → Guardar como → CSV (como en el Método 2).
- Método B: Usa Free Spire.XLS para Python como se muestra en el Método 4: carga el archivo de Excel y llama a `SaveToFile`.
De JSON a CSV
JSON es el formato estándar para las API web. Convertirlo a CSV te permite analizar los datos en hojas de cálculo o bases de datos.
- Tutorial completo: Convertir JSON a CSV – incluye ejemplos de Python, usando MS Excel y convertidores en línea.
De tablas PDF a CSV
Los PDF son geniales para imprimir pero terribles para datos estructurados. Para extraer tablas a CSV, usa uno de estos enfoques:
- Adobe Acrobat Pro: Abre PDF → Exportar → Hoja de cálculo → Guardar como CSV.
- Convertidores en línea: Sube el PDF y luego descárgalo como CSV.
- Biblioteca de Python (Spire.PDF): Extrae automáticamente tablas de todas las páginas PDF y exporta a CSV.
Para una guía completa, consulta: Convertir tablas PDF a CSV: Manual, en línea y automatizado
Conclusión
Sin importar tu nivel de habilidad o las herramientas que tengas a mano, generar un archivo CSV es sencillo. No necesitas ser un desarrollador ni poseer software costoso. Unos pocos clics en Excel o Google Sheets, unas pocas líneas de Python, o incluso un editor de texto plano pueden hacer el trabajo.
Para ayudarte a elegir el enfoque correcto de un vistazo, aquí tienes un resumen rápido:
| Método | Mejor para | Dificultad |
|---|---|---|
| Editor de texto | Datos pequeños y simples | ★ Principiante |
| Excel | Hojas de cálculo existentes, uso ocasional | ★ Principiante |
| Google Sheets | Gratis, basado en la nube, sin instalación | ★ Principiante |
| Python con Free Spire.XLS | Datos grandes, automatización, multiplataforma | ★★ Intermedio |
El mejor método es el que se adapta a tus necesidades inmediatas: tamaño de los datos, nivel de habilidad o automatización. Cualquiera que elijas, el resultado es el mismo: un archivo CSV limpio y universal que funciona sin problemas en cualquier plataforma.
Preguntas frecuentes sobre la generación de archivos CSV
P: ¿Cuál es la diferencia entre archivos CSV y archivos Excel?
R: Los archivos CSV son texto plano con valores separados por comas (sin formato/fórmulas), mientras que los archivos Excel son binarios y pueden almacenar formato, gráficos y fórmulas. Los archivos CSV son más pequeños y más compatibles, mientras que Excel es mejor para análisis de datos complejos.
P: ¿Puedo tener varias hojas en un archivo CSV?
R: No. CSV es un formato de una sola hoja. Necesitas archivos CSV separados para cada hoja, o convertir a Excel (XLSX).
P: ¿Puedo usar un delimitador personalizado (punto y coma, tabulación) en lugar de comas?
R: Sí. En Excel/Google Sheets, selecciona el formato delimitado al guardar. En Python, establece el delimitador en el método `SaveToFile`.
P: ¿Puedo crear un archivo CSV en línea gratis?
R: Sí, usa herramientas generadoras de CSV en línea como ConvertCSV y TableConvert. Sin embargo, evita subir datos confidenciales.
Ver también
So erstellen Sie eine CSV-Datei: 4 einfache Methoden
CSV (Comma-Separated Values)-Dateien sind der universelle Standard für den Datenaustausch – leichtgewichtig, gut lesbar und kompatibel mit Microsoft Excel, Google Tabellen und Programmiersprachen wie Python. Egal, ob Sie Kundendaten organisieren, Berichte exportieren, Informationen migrieren oder ML-Datensätze erstellen, zu wissen, wie man eine CSV-Datei generiert, ist eine grundlegende Fähigkeit.
Diese Anleitung führt Sie durch 4 einfache, umsetzbare Methoden, um eine CSV-Datei zu erstellen, von schnellen No-Code-Methoden bis hin zu automatisierten Skripten. Sie erhalten auch Tipps zur Behandlung von Sonderzeichen und zur Konvertierung von Daten aus JSON, PDF und Excel in CSV.
- Methode 1: Manuell mit einem Texteditor erstellen
- Methode 2: CSV mit Microsoft Excel generieren
- Methode 3: CSV mit Google Tabellen (kostenlos) erstellen
- Methode 4: CSV-Datei in Python erstellen
- Bonus: CSV-Datei aus verschiedenen Datenquellen generieren
Warum sollten Sie CSV-Dateien verwenden?
Eine CSV-Datei speichert tabellarische Daten in einfachem Text. Jede Zeile stellt einen Datensatz dar, und jeder Datensatz enthält Felder, die durch Kommas getrennt sind.
Hauptvorteile von CSVs:
- Universelle Kompatibilität – Funktioniert mit den meisten Tabellenkalkulationsprogrammen, CRMs, Datenbanken und Programmiersprachen.
- Leichtgewichtig – Keine proprietäre Formatierung, geringe Dateigröße.
- Ideal für den Datenaustausch – Schnelles Importieren/Exportieren zwischen verschiedenen Systemen.
- Kostenloser & offener Standard – Kostenlos zu erstellen und zu verwenden ohne kostenpflichtige Tools.
Gängige Anwendungsfälle:
- Hochladen von Produktlisten auf eine E-Commerce-Plattform
- Importieren von Leads/Kontakten in CRMs
- Datensicherung oder Migration
- Bereitstellen von Daten für Python (pandas), R oder SQL-Datenbanken
Methode 1: Manuell mit einem Texteditor erstellen
Für kleine, einfache Datensätze (z. B. eine kurze Liste von Namen und E-Mails) können Sie eine CSV-Datei manuell mit einem Texteditor wie Notepad (Windows) erstellen.
Hinweis: Diese Methode ist fehleranfällig für große Datenmengen – nur für schnelle, winzige Listen verwenden.
Schritte zur manuellen Erstellung einer CSV-Datei:
- Öffnen Sie Ihren Texteditor.
- Geben Sie jede Zeile in eine neue Zeile ein. Trennen Sie Werte durch Kommas. Zum Beispiel:
- Klicken Sie auf „Datei“ → „Speichern unter“.
- Benennen Sie die Datei mit der .csv-Erweiterung (z. B. simple_data.csv) und ändern Sie „Dateityp“ auf „Alle Dateien“ → Speichern.
Umgang mit kniffligen Daten
Wenn ein Feld ein Komma oder einen Zeilenumbruch enthält, schließen Sie es in doppelte Anführungszeichen ein. Beispiel:
"Smith, John",john@example.com,"Hallo\nWelt!"
Sie können auch eine vorhandene Textdatei öffnen und die Schritte 3-4 befolgen, um sie als CSV-Datei zu speichern. Weitere Konvertierungsmethoden finden Sie unter: 3 beste Wege, TXT in CSV zu konvertieren (schnell & fehlerfrei)
Methode 2: CSV mit Microsoft Excel generieren
Excel ist das gängigste Werkzeug zur Erstellung von CSV-Dateien, insbesondere wenn Sie bereits mit Tabellenkalkulationen arbeiten. Befolgen Sie diese Schritt-für-Schritt-Anleitung, um Formatierungsfehler zu vermeiden und sicherzustellen, dass Ihre CSV verwendbar ist.
Schritt 1: Daten in Excel vorbereiten
Öffnen Sie Excel und organisieren Sie Ihre Daten in Zeilen und Spalten. Jede Spalte sollte eine klare Kopfzeile haben (z. B. „ID“, „Name“, „E-Mail“, „Datum“), und jede Zeile sollte einen einzelnen Eintrag darstellen.
Wichtige Tipps für die CSV-Kompatibilität:
- Entfernen Sie zusammengeführte Zellen, Filter oder bedingte Formatierungen (CSV-Dateien können diese nicht beibehalten).
- Formeln in Werte umwandeln.
- Formatieren Sie Spalten mit führenden Nullen als „Text“, um Nullen zu erhalten.
Beispieldaten:
Schritt 2: Datei als CSV speichern
Klicken Sie auf „Datei“ → „Speichern unter“ → wählen Sie einen Speicherort. Wählen Sie im Dropdown-Menü „Dateityp“:
- CSV UTF-8 (durch Trennzeichen getrennt) (*.csv): am besten für nicht-englische Zeichen
- CSV (durch Trennzeichen getrennt) (*.csv): Standard, kann aber Sonderzeichen beeinträchtigen
Schritt 3: Datei benennen und speichern
Geben Sie Ihrer Datei einen aussagekräftigen Namen und klicken Sie auf „Speichern“. Excel zeigt eine Warnung an, dass einige Funktionen (wie Formatierung) verloren gehen – klicken Sie einfach auf „Ja“.
Profi-Tipp: Für europäische Systeme, die Semikolons als Trennzeichen verwenden, ändern Sie zuerst Ihre regionalen Windows-Einstellungen und speichern Sie dann als CSV.
Methode 3: CSV mit Google Tabellen (kostenlos) erstellen
Wenn Sie kein Excel haben oder Cloud-basierte Tools bevorzugen (keine Softwareinstallation erforderlich), ist Google Tabellen eine kostenlose Alternative. Es funktioniert in jedem Browser und erleichtert die Zusammenarbeit.
So erstellen Sie eine CSV-Datei in Google Tabellen:
-
Google Tabellen öffnen: Gehen Sie zu sheets.google.com, melden Sie sich mit Ihrem Google-Konto an und erstellen Sie eine neue leere Tabelle.
-
Daten eingeben: Genau wie in Excel geben Sie Ihre strukturierten Daten in die Zellen ein.
-
Als CSV herunterladen: Klicken Sie auf das Menü „Datei“, fahren Sie mit der Maus über „Herunterladen“ und wählen Sie im Dropdown-Menü „Comma-separated values (.csv)“ aus. (Beachten Sie, dass Google Tabellen nur das aktuell aktive Blatt exportiert. Stellen Sie sicher, dass Sie sich auf dem richtigen Tab befinden, bevor Sie herunterladen.)
-
Datei speichern: Ihr Browser lädt die CSV-Datei automatisch in den Ordner „Downloads“ Ihres Computers herunter. Sie können sie dann an den gewünschten Speicherort verschieben.
Vorteil: Google Tabellen verarbeitet die UTF-8-Kodierung automatisch, sodass Emojis und internationale Zeichen erhalten bleiben.
Methode 4: CSV-Datei in Python erstellen
Wenn Sie mit großen Datensätzen arbeiten oder die CSV-Generierung automatisieren müssen (z. B. Stapelverarbeitung), ist Python ein leistungsstarkes Werkzeug. Wir verwenden die kostenlose Spire.XLS for Python-Bibliothek für die volle Kontrolle über Kodierung und Trennzeichen.
Schritt 1: Die kostenlose Python-Bibliothek installieren
Öffnen Sie vor Beginn Ihre Eingabeaufforderung oder Ihr Terminal und führen Sie aus:
pip install Spire.XLS.Free
Schritt 2: Python-Code zum Generieren von CSV schreiben
Erstellen Sie eine neue Python-Datei und fügen Sie den folgenden Code hinzu. Dieses Beispiel erstellt eine CSV-Datei von Grund auf mit statischen Daten:
from spire.xls import *
from spire.xls.common import *
# 1. Eine neue Arbeitsmappe erstellen
workbook = Workbook()
# 2. Das erste Arbeitsblatt abrufen
worksheet = workbook.Worksheets[0]
# 3. Daten in Zellen einfügen
# Kopfzeile
worksheet.Range["A1"].Text = "Produkt"
worksheet.Range["B1"].Text = "Preis"
worksheet.Range["C1"].Text = "Menge"
worksheet.Range["A2"].Text = "Kabellose Kopfhörer"
worksheet.Range["B2"].NumberValue = 79.99
worksheet.Range["C2"].NumberValue = 250
worksheet.Range["A3"].Text = "Bluetooth-Lautsprecher"
worksheet.Range["B3"].NumberValue = 49.99
worksheet.Range["C3"].NumberValue = 180
# 4. Das Arbeitsblatt als CSV speichern
worksheet.SaveToFile("BasicReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Öffnen Sie die generierte CSV in Excel:
Erweiterte Beispiele mit Free Spire.XLS
Festlegen eines benutzerdefinierten Trennzeichens und einer Kodierung
# Speichern mit Semikolon-Trennzeichen (für europäische Systeme)
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
# Speichern mit Tabulator-Trennzeichen
worksheet.SaveToFile("output.csv", "\t", Encoding.get_UTF8())
# Speichern mit Unicode-Kodierung
worksheet.SaveToFile("output.csv", ",", Encoding.get_Unicode())
Exportieren einer vorhandenen Excel-Datei nach CSV:
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
worksheet = workbook.Worksheets[0]
worksheet.SaveToFile("output.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Für C#-Entwickler: Erfahren Sie wie man eine CSV-Datei in C# erstellt (von Grund auf, Liste oder Excel)
Bonus: CSV-Datei aus verschiedenen Datenquellen generieren
CSV-Dateien können aus praktisch jeder Datenquelle erstellt werden. Nachfolgend sind die gängigsten Szenarien aufgeführt.
Von Excel zu CSV
- Methode A: Excel-Datei in Excel öffnen → Speichern unter → CSV (wie in Methode 2).
- Methode B: Verwenden Sie Free Spire.XLS für Python wie in Methode 4 gezeigt – laden Sie die Excel-Datei und rufen Sie SaveToFile auf.
Von JSON zu CSV
JSON ist das Standardformat für Web-APIs. Die Konvertierung in CSV ermöglicht es Ihnen, die Daten in Tabellenkalkulationen oder Datenbanken zu analysieren.
- Vollständiges Tutorial: JSON in CSV konvertieren – enthält Python-Beispiele, die Verwendung von MS Excel und Online-Konvertern.
Von PDF-Tabellen zu CSV
PDFs eignen sich hervorragend zum Drucken, aber schlecht für strukturierte Daten. Um Tabellen in CSV zu extrahieren, verwenden Sie einen der folgenden Ansätze:
- Adobe Acrobat Pro: PDF öffnen → Exportieren → Tabellenkalkulation → Als CSV speichern.
- Online-Konverter: PDF hochladen und dann als CSV herunterladen.
- Python-Bibliothek (Spire.PDF): Tabellen aus allen PDF-Seiten automatisch extrahieren und nach CSV exportieren.
Für eine vollständige Anleitung siehe: PDF-Tabellen in CSV konvertieren: Manuell, Online & Automatisiert
Fazit
Unabhängig von Ihren Fähigkeiten oder den verfügbaren Werkzeugen ist die Generierung einer CSV-Datei unkompliziert. Sie benötigen weder einen Entwickler noch teure Software. Ein paar Klicks in Excel oder Google Tabellen, ein paar Zeilen Python oder sogar ein einfacher Texteditor können die Aufgabe erledigen.
Um Ihnen bei der schnellen Auswahl der richtigen Methode zu helfen, hier eine kurze Zusammenfassung:
| Methode | Am besten geeignet für | Schwierigkeit |
|---|---|---|
| Texteditor | Winzige, einfache Daten | ★ Anfänger |
| Excel | Vorhandene Tabellenkalkulationen, gelegentliche Nutzung | ★ Anfänger |
| Google Tabellen | Kostenlos, Cloud-basiert, keine Installation | ★ Anfänger |
| Python mit Free Spire.XLS | Große Datenmengen, Automatisierung, plattformübergreifend | ★★ Fortgeschritten |
Die beste Methode ist diejenige, die Ihren unmittelbaren Bedürfnissen entspricht: Datengröße, Fähigkeitsniveau oder Automatisierung. Welche Sie auch wählen, das Ergebnis ist dasselbe: eine saubere, universelle CSV-Datei, die nahtlos auf jeder Plattform funktioniert.
Häufig gestellte Fragen zum Generieren von CSV-Dateien
F: Was ist der Unterschied zwischen CSV- und Excel-Dateien?
A: CSV-Dateien sind einfache Textdateien mit durch Kommas getrennten Werten (keine Formatierung/Formeln), während Excel-Dateien binär sind und Formatierungen, Diagramme und Formeln speichern können. CSV-Dateien sind kleiner und kompatibler, während Excel besser für komplexe Datenanalysen geeignet ist.
F: Kann ich mehrere Blätter in einer CSV-Datei haben?
A: Nein. CSV ist ein Einzelseitenformat. Sie benötigen separate CSV-Dateien für jedes Blatt oder eine Konvertierung in Excel (XLSX).
F: Kann ich ein benutzerdefiniertes Trennzeichen (Semikolon, Tabulator) anstelle von Kommas verwenden?
A: Ja. In Excel/Google Tabellen wählen Sie beim Speichern das getrennte Format aus. In Python legen Sie das Trennzeichen in der SaveToFile-Methode fest.
F: Kann ich kostenlos eine CSV-Datei online erstellen?
A: Ja, verwenden Sie Online-CSV-Generatoren wie ConvertCSV und TableConvert. Vermeiden Sie jedoch das Hochladen sensibler Daten.
Siehe auch
- CSV in TXT konvertieren: 4 einfache Methoden für alle Benutzer
- 4 bewährte Methoden zur Konvertierung von CSV in Excel (kostenlos & automatisiert)
- Python-Liste in CSV: 1D/2D/Dicts – Einfaches Tutorial
- CSV-Dateien in Python lesen: Ein umfassender Leitfaden
- C#/VB.NET: Konvertieren von Excel in CSV und CSV in Excel
Как создать CSV-файл: 4 простых способа
Оглавление
Файлы CSV (Comma-Separated Values) являются универсальным стандартом для обмена данными — они легкие, читаемые человеком и совместимы с Microsoft Excel, Google Sheets и языками программирования, такими как Python. Независимо от того, организуете ли вы данные клиентов, экспортируете отчеты, мигрируете информацию или создаете наборы данных для машинного обучения, знание того, как создать файл CSV, является фундаментальным навыком.
В этом руководстве мы рассмотрим 4 простых, практичных способа создания файла CSV: от быстрых методов без кода до автоматизированных скриптов. Вы также получите советы по работе со специальными символами и преобразованию данных из JSON, PDF и Excel в CSV.
- Способ 1: Создание вручную в текстовом редакторе
- Способ 2: Генерация CSV в Microsoft Excel
- Способ 3: Создание CSV в Google Sheets (бесплатно)
- Способ 4: Создание файла CSV в Python
- Бонус: Генерация файла CSV из различных источников данных
Зачем использовать файлы CSV?
Файл CSV хранит табличные данные в виде простого текста. Каждая строка представляет собой запись данных, а каждая запись содержит поля, разделенные запятыми.
Основные преимущества CSV:
- Универсальная совместимость — работает с большинством табличных редакторов, CRM, баз данных и языков программирования.
- Легкость — отсутствие проприетарного форматирования, небольшой размер файла.
- Идеально подходит для обмена данными — быстр для импорта/экспорта между различными системами.
- Бесплатный и открытый стандарт — бесплатно создавать и использовать без платных инструментов.
Распространенные сценарии использования:
- Загрузка списков товаров на платформу электронной коммерции
- Импорт лидов/контактов в CRM
- Резервное копирование или миграция данных
- Передача данных в Python (pandas), R или базы данных SQL
Способ 1: Создание вручную в текстовом редакторе
Для небольших, простых наборов данных (например, короткий список имен и адресов электронной почты) вы можете создать файл CSV вручную с помощью текстового редактора, такого как Блокнот (Windows).
Примечание: Этот метод подвержен ошибкам при работе с большими данными — используйте его только для быстрых, очень маленьких списков.
Шаги по ручному созданию файла CSV:
- Откройте текстовый редактор.
- Введите каждую строку на новой строке. Разделяйте значения запятыми. Например:
- Нажмите «Файл» → «Сохранить как».
- Назовите файл с расширением .csv (например, simple_data.csv) и измените «Тип файла» на «Все файлы» → Сохранить.
Обработка сложных данных
Если поле содержит запятую или перевод строки, заключите его в двойные кавычки. Пример:
"Смит, Джон",john@example.com,"Привет\nмир!"
Вы также можете открыть существующий текстовый файл и выполнить шаги 3-4, чтобы сохранить его как файл CSV. Для других методов преобразования обратитесь к: 3 лучших способа преобразования TXT в CSV (быстро и без ошибок)
Способ 2: Генерация CSV в Microsoft Excel
Excel — самый распространенный инструмент для создания файлов CSV, особенно если вы уже работаете с электронными таблицами. Следуйте этим пошаговым инструкциям, чтобы избежать ошибок форматирования и обеспечить работоспособность вашего CSV.
Шаг 1: Подготовьте данные в Excel
Откройте Excel и организуйте свои данные в строки и столбцы. Каждый столбец должен иметь четкий заголовок (например, «ID», «Имя», «Электронная почта», «Дата»), а каждая строка должна представлять одну запись.
Важные советы для совместимости с CSV:
- Удалите объединенные ячейки, фильтры или условное форматирование (файлы CSV не могут их сохранить).
- Преобразуйте формулы в значения.
- Отформатируйте столбцы с ведущими нулями как «Текст», чтобы сохранить нули.
Пример данных:
Шаг 2: Сохраните файл как CSV
Нажмите «Файл» → «Сохранить как» → выберите местоположение. В раскрывающемся списке «Тип файла» выберите:
- CSV UTF-8 (с разделителями-запятыми) (*.csv): лучше всего подходит для неанглийских символов
- CSV (с разделителями-запятыми) (*.csv): стандартный, но может нарушить работу специальных символов
Шаг 3: Назовите файл и сохраните
Присвойте файлу описательное имя и нажмите «Сохранить». Excel отобразит предупреждение о том, что некоторые функции (например, форматирование) будут потеряны — просто нажмите «Да».
Профессиональный совет: Для европейских систем, использующих точки с запятой в качестве разделителей, сначала измените региональные настройки Windows, а затем сохраните как CSV.
Способ 3: Создание CSV в Google Sheets (бесплатно)
Если у вас нет Excel или вы предпочитаете облачные инструменты (не требуется установка программного обеспечения), Google Sheets является бесплатной альтернативой. Он работает в любом браузере и упрощает совместную работу.
Вот как создать файл CSV в Google Sheets:
-
Откройте Google Sheets: Перейдите на sheets.google.com, войдите в свою учетную запись Google и создайте новую пустую таблицу.
-
Введите данные: Так же, как и в Excel, вводите структурированные данные в ячейки.
-
Скачать как CSV: Нажмите меню «Файл», наведите курсор на «Скачать» и выберите «Значения, разделенные запятыми (.csv)» из выпадающего меню. (Обратите внимание, что Google Sheets экспортирует только текущий активный лист. Убедитесь, что вы находитесь на правильной вкладке перед скачиванием.)
-
Сохраните файл: Ваш браузер автоматически загрузит файл CSV в папку «Загрузки» на вашем компьютере. Затем вы можете переместить его в нужное место.
Преимущество: Google Sheets автоматически обрабатывает кодировку UTF-8, поэтому эмодзи и международные символы сохраняются.
Способ 4: Создание файла CSV в Python
При работе с большими наборами данных или необходимости автоматизировать генерацию CSV (например, пакетная обработка) Python является мощным инструментом. Мы будем использовать библиотеку Free Spire.XLS for Python для полного контроля над кодировкой и разделителями.
Шаг 1: Установите бесплатную библиотеку Python
Перед началом откройте командную строку или терминал и выполните:
pip install Spire.XLS.Free
Шаг 2: Напишите код Python для генерации CSV
Создайте новый файл Python и добавьте следующий код. Этот пример создает файл CSV с нуля с использованием статических данных:
from spire.xls import *
from spire.xls.common import *
# 1. Создать новую рабочую книгу
workbook = Workbook()
# 2. Получить первый лист
worksheet = workbook.Worksheets[0]
# 3. Заполнить ячейки данными
# Строка заголовка
worksheet.Range["A1"].Text = "Продукт"
worksheet.Range["B1"].Text = "Цена"
worksheet.Range["C1"].Text = "Количество"
worksheet.Range["A2"].Text = "Беспроводные наушники"
worksheet.Range["B2"].NumberValue = 79.99
worksheet.Range["C2"].NumberValue = 250
worksheet.Range["A3"].Text = "Bluetooth-колонка"
worksheet.Range["B3"].NumberValue = 49.99
worksheet.Range["C3"].NumberValue = 180
# 4. Сохранить лист в формате CSV
worksheet.SaveToFile("BasicReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Откройте сгенерированный CSV в Excel:
Расширенные примеры с Free Spire.XLS
Указание пользовательского разделителя и кодировки
# Сохранить с разделителями-точками с запятой (для европейских систем)
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
# Сохранить с разделителями-табуляцией
worksheet.SaveToFile("output.csv", "\t", Encoding.get_UTF8())
# Сохранить с кодировкой Unicode
worksheet.SaveToFile("output.csv", ",", Encoding.get_Unicode())
Экспорт существующего файла Excel в CSV:
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("input.xlsx")
worksheet = workbook.Worksheets[0]
worksheet.SaveToFile("output.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Для разработчиков C#: Узнайте Как создать файл CSV на C# (с нуля, из списка или Excel)
Бонус: Генерация файла CSV из различных источников данных
Файлы CSV можно создавать практически из любого источника данных. Ниже приведены наиболее распространенные сценарии.
Из Excel в CSV
- Метод A: Откройте файл Excel в Excel → Сохранить как → CSV (как в Способе 2).
- Метод B: Используйте Free Spire.XLS для Python, как показано в Способе 4 — загрузите файл Excel и вызовите SaveToFile.
Из JSON в CSV
JSON — это стандартный формат для веб-API. Преобразование его в CSV позволяет анализировать данные в электронных таблицах или базах данных.
- Полное руководство: Преобразование JSON в CSV — включает примеры на Python, использование MS Excel и онлайн-конвертеров.
Из таблиц PDF в CSV
PDF отлично подходят для печати, но ужасны для структурированных данных. Чтобы извлечь таблицы в CSV, используйте один из следующих подходов:
- Adobe Acrobat Pro: Откройте PDF → Экспорт → Электронная таблица → Сохранить как CSV.
- Онлайн-конвертеры: Загрузите PDF, а затем скачайте как CSV.
- Библиотека Python (Spire.PDF): Автоматически извлекайте таблицы со всех страниц PDF и экспортируйте в CSV.
Полное руководство см. в: Преобразование таблиц PDF в CSV: вручную, онлайн и автоматизированно
Заключение
Независимо от вашего уровня навыков или имеющихся инструментов, создание файла CSV — это просто. Вам не нужен разработчик или дорогое программное обеспечение. Несколько кликов в Excel или Google Sheets, несколько строк кода на Python или даже простой текстовый редактор могут выполнить эту задачу.
Чтобы помочь вам быстро выбрать подходящий метод, вот краткий обзор:
| Метод | Лучше всего подходит для | Сложность |
|---|---|---|
| Текстовый редактор | Очень маленькие, простые данные | ★ Новичок |
| Excel | Существующие электронные таблицы, периодическое использование | ★ Новичок |
| Google Sheets | Бесплатно, облачно, без установки | ★ Новичок |
| Python с Free Spire.XLS | Большие данные, автоматизация, кроссплатформенность | ★★ Средний |
Лучший метод — это тот, который соответствует вашим текущим потребностям: размер данных, уровень навыков или автоматизация. Какой бы вы ни выбрали, результат будет одинаковым: чистый, универсальный файл CSV, который бесперебойно работает на любой платформе.
Часто задаваемые вопросы о создании файлов CSV
В: В чем разница между файлами CSV и Excel?
О: Файлы CSV — это простой текст с значениями, разделенными запятыми (без форматирования/формул), в то время как файлы Excel являются двоичными и могут хранить форматирование, диаграммы и формулы. Файлы CSV меньше и более совместимы, в то время как Excel лучше подходит для сложного анализа данных.
В: Могу ли я иметь несколько листов в файле CSV?
О: Нет. CSV — это формат одного листа. Вам нужны отдельные файлы CSV для каждого листа или преобразование в Excel (XLSX).
В: Могу ли я использовать пользовательский разделитель (точку с запятой, табуляцию) вместо запятых?
О: Да. В Excel/Google Sheets выберите формат с разделителями при сохранении. В Python укажите разделитель в методе SaveToFile.
В: Могу ли я создать файл CSV онлайн бесплатно?
О: Да, используйте онлайн-генераторы CSV, такие как ConvertCSV и TableConvert. Однако избегайте загрузки конфиденциальных данных.
См. также
- Преобразование CSV в TXT: 4 простых метода для всех пользователей
- 4 проверенных способа преобразования CSV в Excel (бесплатно и автоматизированно)
- Список Python в CSV: 1D/2D/словари — простое руководство
- Как читать файлы CSV в Python: подробное руководство
- C#/VB.NET: Преобразование Excel в CSV и CSV в Excel
Como comparar dois documentos Word: 3 métodos eficazes incluídos

Prévia do Conteúdo:
- Método 1. Use a Ferramenta de Comparação Integrada do Microsoft Word
- Método 2. Compare Documentos do Word Usando Ferramentas Online
- Método 3. Compare Documentos do Word Automaticamente com Código C#
- Perguntas Frequentes
Ao trabalhar com documentos do Word — sejam contratos, relatórios ou rascunhos colaborativos — uma pergunta surge repetidamente: o que realmente mudou? Comparar manualmente duas versões linha por linha não é apenas demorado, mas também propenso a erros. Se você está revisando as edições de um colega, preparando conteúdo para publicação ou verificando revisões para conformidade, você precisa de uma maneira mais eficiente e confiável de identificar as diferenças.
Este guia apresenta três métodos práticos para comparar documentos do Word, cada um adequado para diferentes cenários e níveis de habilidade. Ao final, você terá uma compreensão clara de qual abordagem se adapta melhor ao seu fluxo de trabalho e como usá-la efetivamente para economizar tempo e melhorar a precisão.
Método 1. Use a Ferramenta de Comparação Integrada do Microsoft Word
Prós
- Altamente preciso
- Construído especificamente para comparação de documentos
- Ótimo para edição colaborativa
Contras
- Pode parecer esmagador para iniciantes
- Personalização limitada para fluxos de trabalho avançados
- Requer Microsoft Word instalado
Quando você está trabalhando com revisões detalhadas, controle de alterações ou documentos formais, uma simples verificação visual não é mais suficiente — você precisa de uma abordagem mais precisa e estruturada. Nessas situações, a ferramenta de comparação integrada do Microsoft Word se torna uma solução muito mais eficaz.
O Microsoft Word oferece um recurso dedicado para comparação de documentos que pode detectar automaticamente as diferenças e apresentá-las em um formato claro e organizado, tornando o processo de revisão mais fácil e eficiente.
Passos para comparar dois documentos usando a ferramenta de Comparação integrada do Microsoft Word:
Passo 1. Abra o Microsoft Word e vá para a guia "Revisão". Encontre a seção "Comparar" e escolha "Comparar".
Passo 2. Navegue para escolher os dois documentos que você deseja comparar. Em seguida, clique em "OK", e o Microsoft Word gerará um novo documento com as diferenças claramente marcadas.
Passo 3. Após alguns segundos, o resultado da comparação será gerado.
Método 2. Compare Documentos do Word Usando Ferramentas Online
Prós
- Nenhuma instalação necessária
- Funciona em qualquer dispositivo
- Rápido e fácil de usar
Contras
- Preocupações com privacidade (documentos sensíveis)
- Limitações de tamanho de arquivo
- Dependência da Internet
Embora a ferramenta integrada do Word seja poderosa, ela nem sempre é conveniente, especialmente se você não tiver acesso ao Word ou precisar de uma comparação rápida em outro dispositivo. Nesses casos, as ferramentas online oferecem uma alternativa rápida e acessível sem a necessidade de instalação de software.
Ferramentas online de comparação de documentos fornecem uma maneira rápida de comparar arquivos diretamente no seu navegador. Essas ferramentas são especialmente úteis quando você está trabalhando em vários dispositivos ou precisa de uma solução rápida e sem instalação.
Como comparar dois documentos do Word com uma ferramenta online:
Passo 1. Abra um navegador no seu computador e pesquise por uma ferramenta de comparação online no Google.
Passo 2. Acesse o site oficial da ferramenta e carregue os dois documentos do Word que você deseja comparar.
Passo 3. Aguarde a conclusão da comparação e, em seguida, baixe o arquivo de resultado.
Método 3. Compare Documentos do Word Automaticamente com Código C#
Prós
- Totalmente automatizado
- Escalável para grandes fluxos de trabalho
- Personalizável para necessidades específicas
Contras
- Requer conhecimento de programação
- Esforço de configuração e integração
- Não ideal para usuários não técnicos
Ferramentas online são convenientes, mas falham quando você precisa de automação, integração ou processamento de documentos em larga escala. Se você é um desenvolvedor — ou trabalha em um sistema que lida com documentos programaticamente — você precisará de uma solução mais flexível. É aí que entra a comparação baseada em código.
Uma opção para desenvolvedores é usar uma biblioteca de processamento de documentos .NET para automatizar comparações. Por exemplo, você pode usar o Spire.Doc para .NET, uma API de processamento de documentos que permite aos desenvolvedores criar, ler, editar e analisar arquivos do Word sem a necessidade de ter o Microsoft Word instalado.
Passos completos para comparar dois documentos do Word automaticamente com código C#:
Passo 1. Instale o arquivo DLL. Você pode adicionar a dependência baixando-a do site oficial ou instalar com o NuGet diretamente com o código abaixo:
PM> Install-Package Spire.Doc
Passo 2. Copie o código de exemplo abaixo e ajuste-o de acordo com sua própria situação:
Código de Exemplo:
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Carregar um documento do Word
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
//Carregar o outro documento do Word
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
//Comparar dois documentos
doc1.Compare(doc2, "Chancy");
//Salvar as diferenças em um terceiro documento
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
Resultado:

Dica: Você pode solicitar uma licença de avaliação gratuita da equipe de vendas para remover as limitações de avaliação.
Perguntas Frequentes
P1. Posso comparar dois documentos do Word e destacar as diferenças?
Sim. A ferramenta de Comparação integrada do Microsoft Word destaca automaticamente as diferenças, incluindo texto, formatação e comentários.
P2. É seguro usar ferramentas online de comparação de Word?
Depende. Para documentos sensíveis, é melhor evitar ferramentas online devido a potenciais riscos de privacidade.
P3. Como comparo vários documentos do Word de uma vez?
Ferramentas manuais e integradas são limitadas. Para comparação em lote, usar soluções baseadas em código é a abordagem mais eficiente.
Conclusão
Cada método que cobrimos serve a um propósito diferente — de ferramentas integradas a soluções automatizadas avançadas. A escolha certa depende do seu fluxo de trabalho, habilidades técnicas e do nível de precisão que você precisa.
Escolher a abordagem certa é fundamental para melhorar a eficiência e a precisão. Uma vez que você o faça, a comparação de documentos se torna mais rápida, mais fácil e muito mais confiável, economizando seu tempo e ajudando você a se concentrar no que importa: o conteúdo em si.
Leia Também:
Word 문서 두 개를 비교하는 방법: 3가지 효과적인 방법 포함
콘텐츠 미리보기:
계약서, 보고서 또는 공동 초안 등 Word 문서를 작업할 때마다 반복적으로 제기되는 질문이 있습니다. 실제로 무엇이 변경되었습니까? 두 버전을 줄별로 수동으로 비교하는 것은 시간이 많이 걸릴 뿐만 아니라 오류가 발생하기 쉽습니다. 동료의 편집 내용을 검토하든, 출판용 콘텐츠를 준비하든, 규정 준수를 위해 수정 사항을 확인하든, 차이점을 파악할 수 있는 더 효율적이고 안정적인 방법이 필요합니다.
이 가이드에서는 다양한 시나리오와 기술 수준에 적합한 세 가지 실용적인 Word 문서 비교 방법을 소개합니다. 마지막에는 어떤 접근 방식이 워크플로에 가장 적합한지, 그리고 시간 절약과 정확성 향상을 위해 이를 효과적으로 사용하는 방법을 명확하게 이해하게 될 것입니다.
방법 1. Microsoft Word의 내장 비교 도구 사용
장점
- 매우 정확함
- 문서 비교를 위해 특별히 제작됨
- 협업 편집에 탁월
단점
- 초보자에게는 부담스러울 수 있음
- 고급 워크플로에 대한 사용자 정의 제한
- Microsoft Word 설치 필요
자세한 수정 사항, 추적된 변경 사항 또는 공식 문서를 작업할 때 간단한 시각적 확인만으로는 충분하지 않습니다. 더 정확하고 구조화된 접근 방식이 필요합니다. 이러한 상황에서는 Microsoft Word의 내장 비교 도구가 훨씬 더 효과적인 솔루션이 됩니다.
Microsoft Word는 문서 비교를 위한 전용 기능을 제공하여 차이점을 자동으로 감지하고 명확하고 체계적인 형식으로 표시하여 검토 프로세스를 더 쉽고 효율적으로 만듭니다.
Microsoft Word의 내장 비교 도구를 사용하여 두 문서를 비교하는 단계:
1단계. Microsoft Word를 열고 "검토" 탭으로 이동합니다. "비교" 섹션을 찾아 "비교"를 선택합니다.
2단계. 비교하려는 두 문서를 선택하기 위해 찾아봅니다. 그런 다음 "확인"을 클릭하면 Microsoft Word에서 차이점이 명확하게 표시된 새 문서를 생성합니다.
3단계. 몇 초 후 비교 결과가 생성됩니다.
방법 2. 온라인 도구를 사용하여 Word 문서 비교
장점
- 설치 불필요
- 모든 장치에서 작동
- 빠르고 사용하기 쉬움
단점
- 개인 정보 보호 문제 (민감한 문서)
- 파일 크기 제한
- 인터넷 의존성
Word의 내장 도구는 강력하지만, 특히 Word에 액세스할 수 없거나 다른 장치에서 빠른 비교가 필요한 경우에는 항상 편리하지 않습니다. 이러한 경우 온라인 도구는 소프트웨어 설치 없이 빠르고 액세스 가능한 대안을 제공합니다.
온라인 문서 비교 도구는 브라우저에서 직접 파일을 비교할 수 있는 빠른 방법을 제공합니다. 이러한 도구는 여러 장치에서 작업하거나 빠른 설치 없는 솔루션이 필요한 경우 특히 유용합니다.
온라인 도구로 두 Word 문서를 비교하는 방법:
1단계. 컴퓨터에서 브라우저를 열고 Google에서 온라인 비교 도구를 검색합니다.
2단계. 도구의 공식 사이트로 이동하여 비교하려는 두 Word 문서를 업로드합니다.
3단계. 비교가 완료될 때까지 기다린 다음 결과 파일을 다운로드합니다.
방법 3. C# 코드로 Word 문서 자동 비교
장점
- 완전 자동화
- 대규모 워크플로에 대한 확장성
- 특정 요구 사항에 대한 사용자 정의 가능
단점
- 프로그래밍 지식 필요
- 설정 및 통합 노력
- 비기술 사용자에게는 이상적이지 않음
온라인 도구는 편리하지만 자동화, 통합 또는 대규모 문서 처리가 필요한 경우에는 부족합니다. 개발자이거나 프로그래밍 방식으로 문서를 처리하는 시스템에서 작업하는 경우 더 유연한 솔루션이 필요합니다. 코드 기반 비교가 바로 그것입니다.
개발자를 위한 한 가지 옵션은 .NET 문서 처리 라이브러리를 사용하여 비교를 자동화하는 것입니다. 예를 들어, Microsoft Word를 설치할 필요 없이 개발자가 Word 파일을 생성, 읽기, 편집 및 분석할 수 있는 문서 처리 API인 Spire.Doc for .NET을 사용할 수 있습니다.
C# 코드로 두 Word 문서를 자동으로 비교하는 전체 단계:
1단계. DLL 파일을 설치합니다. 아래 코드로 공식 웹사이트에서 다운로드하거나 NuGet으로 직접 설치하여 종속성을 추가할 수 있습니다.
PM> Install-Package Spire.Doc
2단계. 아래 샘플 코드를 복사하여 자신의 상황에 맞게 조정하십시오.
샘플 코드:
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
// 하나의 Word 문서 로드
Document doc1 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information.docx");
// 다른 Word 문서 로드
Document doc2 = new Document("C:\\Users\\Administrator\\Desktop\\Meeting_Information-revised.docx");
// 두 문서 비교
doc1.Compare(doc2, "Chancy");
// 차이점을 세 번째 문서에 저장
doc1.SaveToFile("Differences.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}
결과:
팁: 평가 제한을 제거하려면 영업팀에 무료 평가판 라이선스를 요청할 수 있습니다.
자주 묻는 질문
Q1. 두 Word 문서를 비교하고 차이점을 강조 표시할 수 있습니까?
예. Microsoft Word의 내장 비교 도구는 텍스트, 서식 및 메모를 포함한 차이점을 자동으로 강조 표시합니다.
Q2. 온라인 Word 비교 도구를 사용하는 것이 안전합니까?
상황에 따라 다릅니다. 민감한 문서의 경우 개인 정보 위험 가능성 때문에 온라인 도구 사용을 피하는 것이 좋습니다.
Q3. 여러 Word 문서를 한 번에 비교하려면 어떻게 해야 합니까?
수동 및 내장 도구는 제한적입니다. 일괄 비교의 경우 코드 기반 솔루션을 사용하는 것이 가장 효율적인 접근 방식입니다.
결론
우리가 다룬 각 방법은 내장 도구부터 고급 자동화 솔루션까지 다양한 목적을 제공합니다. 올바른 선택은 워크플로, 기술 능력 및 필요한 정확도 수준에 따라 달라집니다.
올바른 접근 방식을 선택하는 것이 효율성과 정확성을 향상시키는 데 중요합니다. 일단 선택하면 문서 비교가 더 빠르고 쉬워지며 훨씬 더 안정적이 되어 시간을 절약하고 가장 중요한 콘텐츠 자체에 집중할 수 있습니다.
함께 읽어보기: