Cómo convertir CSV a Word (métodos manuales y de Python)
Tabla de Contenidos
- ¿Por qué convertir CSV a Word?
- Método 1 – Copiar y Pegar Datos CSV en Word
- Método 2 – Convertir CSV a una Tabla de Word usando Texto a Tabla
- Método 3 – Usar un Convertidor en Línea de CSV a Word
- Limitaciones de la Conversión Manual y en Línea de CSV a Word
- Método 4 – Convertir CSV a Word Automáticamente con Python
- Ejemplo Completo de Python para Convertir CSV a Word
- ¿Por qué usar Spire.Doc para la Conversión de CSV a Word?
- Métodos de Conversión de CSV a Word Comparados
- Preguntas Frecuentes

Los archivos CSV se utilizan ampliamente para almacenar e intercambiar datos tabulares, pero no siempre son el mejor formato para compartir información. Cuando necesite incluir datos de hojas de cálculo en un informe, propuesta, documento de proyecto o entrega para un cliente, convertir un archivo CSV a un documento de Word a menudo proporciona mejores opciones de presentación y formato.
Existen varias formas de convertir CSV a Word, desde técnicas manuales sencillas hasta convertidores dedicados de CSV a Word y soluciones automatizadas. El mejor método depende de su flujo de trabajo, el tamaño de sus datos y la frecuencia con la que necesite realizar la conversión.
En esta guía, aprenderá cuatro formas prácticas de convertir archivos CSV a documentos de Word, incluidos métodos manuales, convertidores en línea de CSV a Word y un enfoque basado en Python para convertir datos CSV a documentos DOCX automáticamente. Ya sea que necesite una conversión rápida única o una solución escalable para tareas recurrentes, encontrará una opción que se adapte a sus necesidades.
Navegación Rápida
- ¿Por qué convertir CSV a Word?
- Método 1 – Copiar y Pegar Datos CSV en Word
- Método 2 – Convertir CSV a una Tabla de Word usando Texto a Tabla
- Método 3 – Usar un Convertidor en Línea de CSV a Word
- Limitaciones de la Conversión Manual y en Línea de CSV a Word
- Método 4 – Convertir CSV a Word Automáticamente con Python
- Ejemplo Completo de Python para Convertir CSV a Word
- ¿Por qué usar Spire.Doc para la Conversión de CSV a Word?
- Métodos de Conversión de CSV a Word Comparados
- Preguntas Frecuentes
1. ¿Por qué convertir CSV a Word?
Podría preguntarse: ¿por qué no usar Excel? Después de todo, los archivos CSV se abren de forma nativa en aplicaciones de hojas de cálculo. Si bien Excel es excelente para el análisis de datos y los cálculos, los documentos de Word sirven para propósitos diferentes. Word proporciona un formato superior para informes narrativos, entregas para clientes y documentos listos para imprimir donde los datos deben aparecer junto con texto explicativo, encabezados y diseños con estilo.
Casos de Uso Comunes
| Caso de Uso | Por qué Word en lugar de Excel |
|---|---|
| Informes de negocios | Combine tablas de datos con análisis narrativo y resúmenes ejecutivos |
| Documentación de proyectos | Incorpore datos dentro de documentos estructurados que incluyan instrucciones y contexto |
| Entregas para clientes | Presente datos en documentos de marca y formato profesional |
| Artículos académicos | Siga pautas de formato específicas (APA, MLA) con datos integrados en el texto |
| Preparación de combinación de correspondencia | Use datos CSV como fuente para cartas y etiquetas personalizadas en Word |
Cuando necesite convertir un archivo CSV a un documento de Word, el método correcto depende de la frecuencia con la que lo haga y del control de formato que necesite.
2. Método 1 – Copiar y Pegar Datos CSV en Word
La forma más sencilla de incorporar datos CSV en Word es copiarlos de una hoja de cálculo y pegarlos directamente. Este método funciona bien para conjuntos de datos pequeños y tareas únicas.
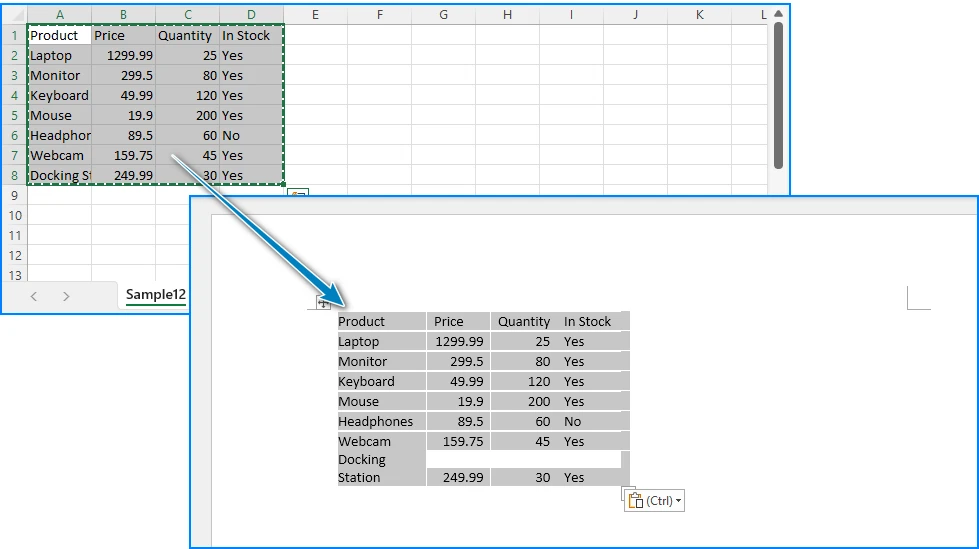
Paso 1: Abrir el Archivo CSV en Excel
Haga doble clic en su archivo .csv, o abra Excel y use Archivo > Abrir para cargar el CSV. Excel analizará automáticamente los valores separados por comas en columnas.
Paso 2: Seleccionar los Datos
Resalte las celdas que desea incluir en su documento de Word. Puede seleccionar toda la hoja presionando Ctrl + A, o seleccionar un rango específico.
Paso 3: Pegar en Word
Abra Microsoft Word, coloque el cursor donde desee los datos y presione Ctrl + V. Word convertirá automáticamente los datos tabulares en una tabla de Word.
Paso 4: Aplicar Formato de Tabla
Utilice la pestaña Diseño de tabla de Word para aplicar un estilo, ajustar los anchos de columna y formatear los encabezados.
Pros y Contras
| Aspecto | Evaluación |
|---|---|
| Facilidad de uso | Muy fácil — no se requieren herramientas especiales |
| Velocidad | Rápido para conjuntos de datos pequeños |
| Control de formato | Limitado — el formato puede romperse con datos grandes |
| Escalabilidad | No apto para archivos con cientos o miles de filas |
| Reproducibilidad | Proceso manual — difícil de repetir consistentemente |
Si también está trabajando con flujos de trabajo de hojas de cálculo, puede encontrar útil nuestra guía sobre cómo convertir archivos CSV a Excel.
3. Método 2 – Convertir CSV a una Tabla de Word usando Texto a Tabla
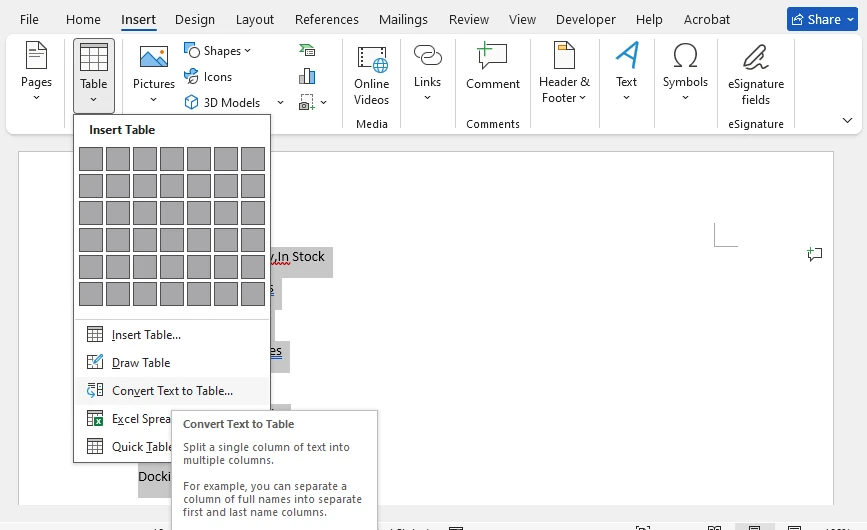
Word tiene una función integrada que puede convertir texto delimitado directamente en una tabla, sin necesidad de Excel. Este método es particularmente relevante si está buscando cómo convertir CSV a una tabla de Word, ya que utiliza la conversión nativa de Word Texto a Tabla.
Paso 1: Abrir el Archivo CSV en un Editor de Texto
Abra su archivo .csv en el Bloc de notas, Notepad++ o cualquier editor de texto plano. Verá los valores sin procesar separados por comas.
Paso 2: Copiar el Contenido CSV
Seleccione todo el texto (Ctrl + A) y cópielo (Ctrl + C).
Paso 3: Pegar en Word como Texto Plano
En Word, pegue el contenido. Aparecerá como texto plano con comas separando los valores.
Paso 4: Usar la Conversión de Texto a Tabla
Seleccione el texto pegado, luego vaya a Insertar > Tabla > Convertir texto en tabla. En el cuadro de diálogo:
- Establezca Separar texto en a Comas
- Ajuste el número de columnas si es necesario
- Haga clic en Aceptar
Word convertirá el texto separado por comas en una tabla correctamente estructurada.
Paso 5: Formatear la Tabla
Aplique un estilo de tabla desde la pestaña Diseño de tabla, formatee la fila de encabezado y ajuste los anchos de columna según sea necesario.
Pros y Contras
| Aspecto | Evaluación |
|---|---|
| Facilidad de uso | Fácil — no se necesita Excel, funciona completamente dentro de Word |
| Control de formato | Medio — Word maneja la estructura de la tabla automáticamente |
| Escalabilidad | Funciona para archivos de tamaño moderado; los archivos muy grandes pueden ser lentos |
| Precisión | Buena — Word analiza correctamente los delimitadores de coma en la mayoría de los casos |
| Limitación | Puede interpretar erróneamente las comas dentro de campos entre comillas (por ejemplo, "Smith, John") |
Si sus datos ya están almacenados en libros de Excel en lugar de archivos CSV, consulte nuestra guía sobre cómo convertir hojas de Excel a documentos de Word.
4. Método 3 – Usar un Convertidor en Línea de CSV a Word
Si no tiene Excel o Word instalado, o simplemente necesita una conversión rápida única, un convertidor en línea de CSV a Word puede hacer el trabajo en segundos. Varias herramientas gratuitas le permiten cargar un archivo CSV y descargar un documento de Word.
Cómo Funciona
- Busque "convertidor de CSV a Word en línea" en su navegador
- Cargue su archivo
.csven el sitio web del convertidor - Espere a que se complete la conversión
- Descargue el archivo
.docxgenerado
Qué Buscar en un Convertidor en Línea
Al elegir un convertidor en línea de CSV a Word, considere:
- Límites de tamaño de archivo
- Formatos de salida compatibles (DOC vs DOCX)
- Políticas de privacidad de datos
- Calidad del formato de tabla
- Soporte de conversión por lotes
Pros y Contras
| Aspecto | Evaluación |
|---|---|
| Facilidad de uso | Muy fácil — no se requiere instalación de software |
| Velocidad | Rápido para archivos pequeños a medianos |
| Control de formato | Bajo — obtienes lo que produce la herramienta |
| Privacidad | Preocupación — sus datos se cargan en un servidor de terceros |
| Límites de tamaño de archivo | La mayoría de las herramientas imponen restricciones de tamaño de carga |
| Procesamiento por lotes | No compatible — un archivo a la vez |
Cuándo Usar un Convertidor en Línea
Los convertidores en línea son una opción razonable cuando tiene un solo archivo CSV no sensible y solo necesita una conversión rápida. Sin embargo, si sus datos contienen información personal, registros financieros o contenido crítico para el negocio, cargarlos en un servicio de terceros puede no ser apropiado.
Si necesita conversiones repetibles o a gran escala, la automatización suele ser una mejor solución a largo plazo.
5. Limitaciones de la Conversión Manual y en Línea de CSV a Word
Los métodos manuales y las herramientas en línea funcionan para uso ocasional, pero fallan cuando necesita procesar archivos CSV regularmente o a escala. Aquí están los desafíos comunes:
Desafíos Comunes
- Trabajo repetitivo — Si convierte CSV a Word cada semana o cada día, el copiar y pegar manual se vuelve tedioso y propenso a errores.
- Grandes conjuntos de datos — Word tiene dificultades para manejar tablas con miles de filas pegadas desde Excel. El rendimiento se degrada y el formato se rompe.
- Procesamiento por lotes — Cuando necesita convertir varios archivos CSV a documentos de Word, hacerlo uno por uno no es práctico.
- Consistencia de formato — El formato manual varía cada vez. Los encabezados, fuentes y estilos de tabla pueden verse diferentes entre documentos.
- Preocupaciones de privacidad — Los convertidores en línea requieren cargar sus datos en servidores externos, lo que puede no ser aceptable para información confidencial.
- Generación automatizada de informes — Si los informes deben generarse según un horario (diario, semanal), la conversión manual no puede seguir el ritmo.
Para estas situaciones, la automatización con Python proporciona un camino práctico, y la siguiente sección muestra exactamente cómo implementarlo.
6. Método 4 – Convertir CSV a Word Automáticamente con Python
Python es una opción natural para automatizar la conversión de CSV a Word. Tiene un módulo csv incorporado para leer datos, y con Spire.Doc para Python, puede crear y formatear documentos de Word sin necesidad de tener Microsoft Word instalado.
Esta sección detalla la implementación completa: instalación de la biblioteca, lectura de datos CSV, construcción de una tabla de Word y guardado del resultado como DOCX.
Instalar Spire.Doc para Python
Instale la biblioteca a través de pip:
pip install spire.doc
Importe las clases requeridas en su script de Python:
from spire.doc import *
from spire.doc.common import *
Paso 1: Leer Datos CSV
El módulo csv incorporado de Python lee archivos CSV en una lista de filas:
import csv
csv_data = []
with open("sales_data.csv", "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
La primera fila generalmente contiene los encabezados de columna, y las filas subsiguientes contienen los datos.
Paso 2: Crear un Documento de Word y una Tabla
Cree un nuevo documento de Word, agregue una sección e inicialice una tabla con las dimensiones de sus datos CSV:
document = Document()
section = document.AddSection()
num_rows = len(csv_data)
num_cols = len(csv_data[0]) if csv_data else 0
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
Paso 3: Rellenar la Tabla con Datos CSV
Itere a través de las filas CSV y escriba cada valor en la celda correspondiente. Formatee la fila de encabezado con un estilo distintivo:
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
Este código formatea la primera fila como un encabezado con fondo azul oscuro y texto blanco en negrita, y aplica colores alternos a las filas para mejorar la legibilidad.
Paso 4: Guardar como DOCX
Guarde el documento de Word generado:
document.SaveToFile("SalesReport.docx", FileFormat.Docx)
document.Close()
A continuación, se muestra una vista previa de los datos CSV y el documento de Word generado:
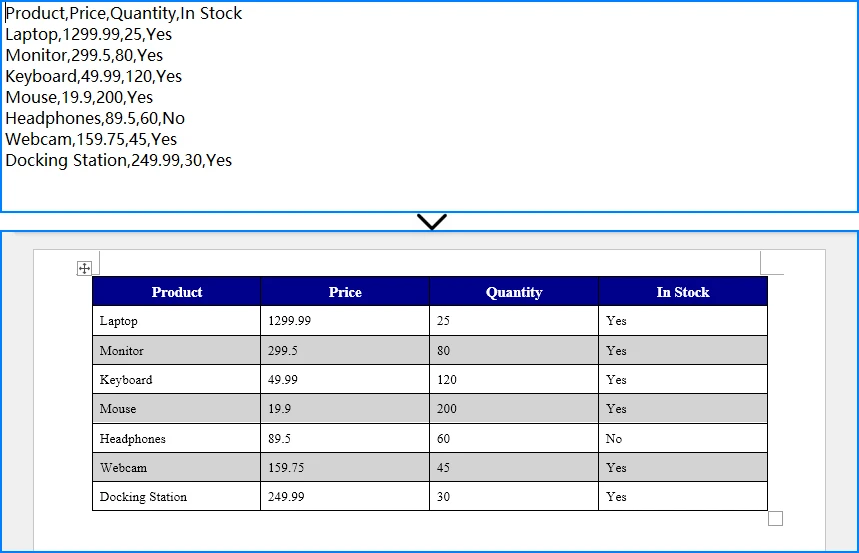
El resultado es un archivo .docx correctamente formateado que contiene sus datos CSV en una tabla de Word.
Para opciones de personalización de tablas más avanzadas, consulte nuestra guía sobre cómo crear y formatear tablas de Word con Python.
7. Ejemplo Completo de Python para Convertir CSV a Word
Aquí está el script completo y ejecutable que lee un archivo CSV y lo convierte a un documento de Word con un título, tabla formateada, colores alternos de fila y bordes de tabla.
import csv
from spire.doc import *
from spire.doc.common import *
def csv_to_word(csv_path, output_path, title="Data Report"):
csv_data = []
with open(csv_path, "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
if not csv_data:
print("CSV file is empty.")
return
num_rows = len(csv_data)
num_cols = len(csv_data[0])
document = Document()
section = document.AddSection()
title_para = section.AddParagraph()
title_range = title_para.AppendText(title)
title_range.CharacterFormat.FontSize = 18
title_range.CharacterFormat.Bold = True
title_para.Format.HorizontalAlignment = HorizontalAlignment.Center
title_para.Format.AfterSpacing = 12
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
table.Format.Borders.Vertical.BorderType = BorderStyle.Single
table.Format.Borders.Vertical.LineWidth = 0.5
table.Format.Borders.Horizontal.BorderType = BorderStyle.Single
table.Format.Borders.Horizontal.LineWidth = 0.5
document.SaveToFile(output_path, FileFormat.Docx)
document.Close()
print(f"Word document saved to: {output_path}")
csv_to_word("sales_data.csv", "SalesReport.docx", "Q4 Sales Report")
Cómo Funciona
csv.readerlee el archivo CSV fila por fila, manejando diferentes codificaciones a través deutf-8-sig(que maneja los marcadores BOM).Document()crea un documento de Word en blanco.AddSection()agrega una sección (página) al documento.AddTable(True)crea una nueva tabla con ajuste automático habilitado.ResetCells()establece las dimensiones exactas.AppendText()escribe cada valor CSV en la celda correspondiente como un rango de texto.- El formato de encabezado aplica un fondo azul oscuro, texto blanco en negrita y alineación centrada a la primera fila.
- Los colores alternos de fila usan gris claro para las filas pares y sin relleno para las filas impares, mejorando la legibilidad.
SaveToFile()exporta el documento como un archivo.docx.
8. ¿Por qué usar Spire.Doc para la Conversión de CSV a Word?
Spire.Doc para Python ofrece varias ventajas técnicas para los desarrolladores que necesitan generar documentos de Word a partir de datos CSV mediante programación.
Ventajas
| Ventaja | Detalles |
|---|---|
| Sin dependencia de Microsoft Word | Cree y manipule archivos DOCX sin instalar Microsoft Word en el servidor o máquina |
| Formato de tabla completo | Controle el sombreado de celdas, bordes, alineación, alturas de fila, anchos de columna y estilos de tabla |
| Generación automatizada de informes | Cree scripts que conviertan CSV a Word en un horario, integrándose con canalizaciones de datos |
| Procesamiento de documentos por lotes | Procese varios archivos CSV en un bucle, generando documentos de Word separados para cada uno |
| Integración con Python | Funciona sin problemas con el módulo csv estándar de Python y otras bibliotecas de procesamiento de datos |
| Soporte completo de DOCX | Genere documentos compatibles con Microsoft Word, LibreOffice y Google Docs |
Clases API Clave
Document— Representa un documento de Word. Úselo para crear nuevos documentos o cargar existentes.Section— Representa una sección (página) dentro de un documento. Contiene párrafos, tablas y otro contenido.Table— Representa una tabla en un documento de Word. Admite manipulación de filas/columnas, estilos y bordes.TableRow/TableCell— Proporcionan acceso a filas y celdas individuales para formatear e insertar contenido.Paragraph/TextRange— Manejan el contenido de texto dentro de las celdas, incluyendo fuente, tamaño, color y alineación.
9. Métodos de Conversión de CSV a Word Comparados
| Método | Facilidad de Uso | Procesamiento por Lotes | Control de Formato | Privacidad | Mejor Para |
|---|---|---|---|---|---|
| Copiar y Pegar | ★★★★★ | ✗ | Bajo | ✓ | Tareas únicas, conjuntos de datos pequeños |
| Texto a Tabla | ★★★★☆ | ✗ | Medio | ✓ | Flujos de trabajo sin Excel, datos moderados |
| Convertidor en Línea | ★★★★★ | ✗ | Bajo | ✗ | Conversiones rápidas únicas |
| Python + Spire.Doc | ★★★☆☆ | ✓ | Alto | ✓ | Tareas recurrentes, procesamiento por lotes, automatización |
Resumen: Los métodos manuales y las herramientas en línea son rápidos y accesibles, pero no escalan. La automatización con Python y Spire.Doc requiere una pequeña inversión inicial de configuración, pero vale la pena cuando necesita una conversión de CSV a Word consistente, repetible o por lotes.
10. Preguntas Frecuentes
¿Cómo convierto un archivo CSV a un documento de Word?
Puede convertir un archivo CSV a un documento de Word utilizando varios métodos: (1) Abra el CSV en Excel, copie los datos y péguelos en Word; (2) Use la función Texto a Tabla de Word para convertir texto separado por comas directamente en una tabla; (3) Use un convertidor en línea de CSV a Word para una conversión rápida única; (4) Use Python con Spire.Doc para Python para automatizar la conversión mediante programación. El enfoque de Python es el mejor para tareas recurrentes o procesamiento por lotes.
¿Puedo convertir CSV a DOCX automáticamente?
Sí. Puede automatizar la conversión de CSV a DOCX usando Python. Lea los datos CSV con el módulo csv incorporado de Python, luego use Spire.Doc para Python para crear un documento de Word, poblar una tabla con los datos CSV y guardarlo como un archivo .docx. Este enfoque funciona sin Microsoft Word instalado y se puede programar para que se ejecute automáticamente.
¿Cómo inserto datos CSV en una tabla de Word?
Para insertar datos CSV en una tabla de Word manualmente, puede usar la función Insertar > Tabla > Convertir texto en tabla de Word: pegue el texto CSV, luego conviértalo usando comas como delimitador. Para la inserción programática, use Python: lea el CSV con el módulo csv, cree una tabla en un documento de Word usando Spire.Doc para Python, e itere a través de las filas CSV para poblar cada celda.
¿Existe un convertidor gratuito de CSV a Word en línea?
Sí, varios sitios web ofrecen conversión gratuita de CSV a Word. Sin embargo, los convertidores en línea tienen limitaciones: restricciones de tamaño de archivo, control de formato limitado y preocupaciones de privacidad, ya que sus datos se cargan en un servidor de terceros. Para datos sensibles o conversiones recurrentes, una solución local de Python con Spire.Doc para Python es una alternativa más confiable y privada.
¿Puede Python convertir archivos CSV a documentos de Word?
Sí, Python puede convertir archivos CSV a documentos de Word. Usando Spire.Doc para Python, puede leer datos CSV con el módulo csv estándar, crear un documento de Word, agregar una tabla formateada, poblarla con el contenido CSV y guardar el resultado como un archivo DOCX. Esto funciona sin Microsoft Word y admite el procesamiento por lotes de varios archivos CSV.
¿Spire.Doc para Python requiere que Microsoft Word esté instalado?
No. Spire.Doc para Python es una biblioteca independiente que crea y manipula documentos de Word de forma independiente. No requiere que Microsoft Word o ningún componente de Office esté instalado en su sistema. Esto lo hace adecuado para entornos de servidor y flujos de trabajo automatizados.
Conclusión
Convertir CSV a Word es una tarea común con múltiples enfoques. Los métodos manuales —copiar y pegar y la función Texto a Tabla de Word— funcionan bien para uso ocasional con conjuntos de datos pequeños. Los convertidores en línea ofrecen conveniencia para tareas rápidas y únicas, pero plantean preocupaciones de privacidad y carecen de control de formato. Ninguna de estas opciones escala para el procesamiento por lotes, la generación programada de informes o escenarios que requieren un formato consistente en muchos documentos.
La automatización con Python y Spire.Doc para Python proporciona una solución confiable para convertir CSV a DOCX mediante programación. Lee datos CSV, crea tablas de Word formateadas y genera documentos profesionales sin necesidad de Microsoft Word, lo que lo hace ideal para flujos de trabajo automatizados, procesamiento por lotes y generación de documentos del lado del servidor.
Puede solicitar una licencia gratuita de 30 días para evaluar todas las funciones de Spire.Doc para Python.
Ver También
So konvertieren Sie CSV in Word (manuelle und Python-Methoden)
Inhaltsverzeichnis
- Warum CSV in Word konvertieren?
- Methode 1 – CSV-Daten kopieren und in Word einfügen
- Methode 2 – CSV mit „Text in Tabelle“ in eine Word-Tabelle konvertieren
- Methode 3 – Einen Online-CSV-zu-Word-Konverter verwenden
- Einschränkungen bei manueller und Online-CSV-zu-Word-Konvertierung
- Methode 4 – CSV automatisch mit Python in Word konvertieren
- Vollständiges Python-Beispiel für CSV zu Word
- Warum Spire.Doc für die CSV-zu-Word-Konvertierung verwenden?
- Vergleich der CSV-zu-Word-Konvertierungsmethoden
- FAQ
CSV-Dateien werden häufig zum Speichern und Austauschen von tabellarischen Daten verwendet, sind aber nicht immer das beste Format für die Weitergabe von Informationen. Wenn Sie Tabellenkalkulationsdaten in einen Bericht, einen Vorschlag, ein Projektdokument oder eine Kundenlieferung aufnehmen müssen, bietet die Konvertierung einer CSV-Datei in ein Word-Dokument oft eine bessere Präsentation und Formatierungsoptionen.
Es gibt verschiedene Möglichkeiten, CSV in Word zu konvertieren, von einfachen manuellen Techniken bis hin zu speziellen CSV-zu-Word-Konvertern und automatisierten Lösungen. Die beste Methode hängt von Ihrem Workflow, der Größe Ihrer Daten und der Häufigkeit ab, mit der Sie die Konvertierung durchführen müssen.
In diesem Leitfaden lernen Sie vier praktische Möglichkeiten kennen, CSV in Word-Dokumente zu konvertieren, einschließlich manueller Methoden, Online-CSV-zu-Word-Konverter und eines Python-basierten Ansatzes zur automatischen Konvertierung von CSV-Daten in DOCX-Dokumente. Egal, ob Sie eine schnelle einmalige Konvertierung oder eine skalierbare Lösung für wiederkehrende Aufgaben benötigen, Sie finden eine passende Option.
Schnellnavigation
- Warum CSV in Word konvertieren?
- Methode 1 – CSV-Daten kopieren und in Word einfügen
- Methode 2 – CSV mit „Text in Tabelle“ in eine Word-Tabelle konvertieren
- Methode 3 – Einen Online-CSV-zu-Word-Konverter verwenden
- Einschränkungen bei manueller und Online-CSV-zu-Word-Konvertierung
- Methode 4 – CSV automatisch mit Python in Word konvertieren
- Vollständiges Python-Beispiel für CSV zu Word
- Warum Spire.Doc für die CSV-zu-Word-Konvertierung verwenden?
- Vergleich der CSV-zu-Word-Konvertierungsmethoden
- FAQ
1. Warum CSV in Word konvertieren?
Sie fragen sich vielleicht: Warum nicht einfach Excel verwenden? Schließlich werden CSV-Dateien nativ in Tabellenkalkulationsprogrammen geöffnet. Während Excel hervorragend für Datenanalysen und Berechnungen geeignet ist, dienen Word-Dokumente anderen Zwecken. Word bietet eine überlegene Formatierung für narrative Berichte, Kundenlieferungen und druckfertige Dokumente, bei denen Daten neben erklärendem Text, Kopfzeilen und formatierten Layouts erscheinen müssen.
Gängige Anwendungsfälle
| Anwendungsfall | Warum Word statt Excel |
|---|---|
| Geschäftsberichte | Kombinieren Sie Datentabellen mit narrativen Analysen und Managementzusammenfassungen |
| Projektdokumentation | Betten Sie Daten in strukturierte Dokumente ein, die Anweisungen und Kontext enthalten |
| Kundenlieferungen | Präsentieren Sie Daten in gebrandeten, professionell formatierten Dokumenten |
| Wissenschaftliche Arbeiten | Befolgen Sie spezifische Formatierungsrichtlinien (APA, MLA) mit in den Text integrierten Daten |
| Serienbriefvorbereitung | Verwenden Sie CSV-Daten als Quelle für personalisierte Briefe und Etiketten in Word |
Wenn Sie eine CSV-Datei in ein Word-Dokument konvertieren müssen, hängt die richtige Methode davon ab, wie oft Sie dies tun und wie viel Formatierungskontrolle Sie benötigen.
2. Methode 1 – CSV-Daten kopieren und in Word einfügen
Der einfachste Weg, CSV-Daten in Word zu bringen, ist, sie aus einer Tabellenkalkulation zu kopieren und direkt einzufügen. Diese Methode eignet sich gut für kleine Datensätze und einmalige Aufgaben.
Schritt 1: CSV-Datei in Excel öffnen
Doppelklicken Sie auf Ihre .csv-Datei oder öffnen Sie Excel und verwenden Sie Datei > Öffnen, um die CSV zu laden. Excel analysiert die durch Kommas getrennten Werte automatisch in Spalten.
Schritt 2: Daten auswählen
Markieren Sie die Zellen, die Sie in Ihr Word-Dokument aufnehmen möchten. Sie können das gesamte Blatt durch Drücken von Strg + A auswählen oder einen bestimmten Bereich auswählen.
Schritt 3: In Word einfügen
Öffnen Sie Microsoft Word, platzieren Sie den Cursor dort, wo die Daten erscheinen sollen, und drücken Sie Strg + V. Word konvertiert die tabellarischen Daten automatisch in eine Word-Tabelle.
Schritt 4: Tabellenformatierung anwenden
Verwenden Sie die Registerkarte Tabellenentwurf von Word, um einen Stil anzuwenden, Spaltenbreiten anzupassen und Kopfzeilen zu formatieren.
Vorteile und Nachteile
| Aspekt | Bewertung |
|---|---|
| Benutzerfreundlichkeit | Sehr einfach – keine speziellen Werkzeuge erforderlich |
| Geschwindigkeit | Schnell für kleine Datensätze |
| Formatierungskontrolle | Begrenzt – Formatierung kann bei großen Datenmengen fehlschlagen |
| Skalierbarkeit | Nicht geeignet für Dateien mit Hunderten oder Tausenden von Zeilen |
| Reproduzierbarkeit | Manueller Prozess – schwer konsistent zu wiederholen |
Wenn Sie auch mit Tabellenkalkulations-Workflows arbeiten, ist unser Leitfaden zum Konvertieren von CSV-Dateien in Excel möglicherweise hilfreich.
3. Methode 2 – CSV mit „Text in Tabelle“ in eine Word-Tabelle konvertieren
Word verfügt über eine integrierte Funktion, die getrennten Text direkt in eine Tabelle konvertieren kann – kein Excel erforderlich. Diese Methode ist besonders relevant, wenn Sie nach einer Möglichkeit suchen, CSV in eine Word-Tabelle zu konvertieren, da sie die native Text-in-Tabelle-Konvertierung von Word verwendet.
Schritt 1: CSV-Datei in einem Texteditor öffnen
Öffnen Sie Ihre .csv-Datei in Notepad, Notepad++ oder einem beliebigen einfachen Texteditor. Sie sehen die rohen, durch Kommas getrennten Werte.
Schritt 2: CSV-Inhalt kopieren
Wählen Sie den gesamten Text aus (Strg + A) und kopieren Sie ihn (Strg + C).
Schritt 3: Als Nur-Text in Word einfügen
Fügen Sie den Inhalt in Word ein. Er wird als einfacher Text mit Kommas als Trennzeichen angezeigt.
Schritt 4: Text-in-Tabelle-Konvertierung verwenden
Wählen Sie den eingefügten Text aus und gehen Sie dann zu Einfügen > Tabelle > Text in Tabelle konvertieren. Im Dialogfeld:
- Stellen Sie Text trennen bei auf Kommas
- Passen Sie die Anzahl der Spalten bei Bedarf an
- Klicken Sie auf OK
Word konvertiert den durch Kommas getrennten Text in eine ordnungsgemäß strukturierte Tabelle.
Schritt 5: Tabelle formatieren
Wenden Sie einen Tabellenstil aus der Registerkarte Tabellenentwurf an, formatieren Sie die Kopfzeile und passen Sie die Spaltenbreiten nach Bedarf an.
Vorteile und Nachteile
| Aspekt | Bewertung |
|---|---|
| Benutzerfreundlichkeit | Einfach – kein Excel erforderlich, funktioniert vollständig innerhalb von Word |
| Formatierungskontrolle | Mittel – Word verarbeitet die Tabellenstruktur automatisch |
| Skalierbarkeit | Funktioniert für mäßig große Dateien; sehr große Dateien können langsam sein |
| Genauigkeit | Gut – Word analysiert Komma-Trennzeichen in den meisten Fällen korrekt |
| Einschränkung | Kann Kommas in Anführungszeichen-Feldern falsch interpretieren (z. B. „Smith, John“) |
Wenn Ihre Daten bereits in Excel-Arbeitsmappen und nicht in CSV-Dateien gespeichert sind, lesen Sie unseren Leitfaden zum Konvertieren von Excel-Tabellen in Word-Dokumente.
4. Methode 3 – Einen Online-CSV-zu-Word-Konverter verwenden
Wenn Sie Excel oder Word nicht installiert haben oder einfach nur eine schnelle einmalige Konvertierung benötigen, kann ein Online-CSV-zu-Word-Konverter die Aufgabe in Sekundenschnelle erledigen. Mehrere kostenlose Tools ermöglichen es Ihnen, eine CSV-Datei hochzuladen und ein Word-Dokument herunterzuladen.
So funktioniert es
- Suchen Sie in Ihrem Browser nach „CSV zu Word Konverter online“
- Laden Sie Ihre
.csv-Datei auf die Website des Konverters hoch - Warten Sie, bis die Konvertierung abgeschlossen ist
- Laden Sie die generierte
.docx-Datei herunter
Worauf Sie bei einem Online-Konverter achten sollten
Berücksichtigen Sie bei der Auswahl eines Online-CSV-zu-Word-Konverters Folgendes:
- Dateigrößenbeschränkungen
- Unterstützte Ausgabeformate (DOC vs. DOCX)
- Datenschutzrichtlinien
- Qualität der Tabellenformatierung
- Unterstützung für Stapelkonvertierung
Vorteile und Nachteile
| Aspekt | Bewertung |
|---|---|
| Benutzerfreundlichkeit | Sehr einfach – keine Softwareinstallation erforderlich |
| Geschwindigkeit | Schnell für kleine bis mittlere Dateien |
| Formatierungskontrolle | Gering – Sie erhalten, was das Tool produziert |
| Datenschutz | Bedenken – Ihre Daten werden auf einen Server eines Drittanbieters hochgeladen |
| Dateigrößenbeschränkungen | Die meisten Tools haben Upload-Größenbeschränkungen |
| Stapelverarbeitung | Nicht unterstützt – eine Datei nach der anderen |
Wann ein Online-Konverter verwendet werden sollte
Online-Konverter sind eine vernünftige Wahl, wenn Sie eine einzelne, nicht sensible CSV-Datei haben und nur eine schnelle Konvertierung benötigen. Wenn Ihre Daten jedoch persönliche Informationen, Finanzdaten oder geschäftskritische Inhalte enthalten, ist das Hochladen auf einen Drittanbieterdienst möglicherweise nicht angemessen.
Wenn Sie wiederholbare oder groß angelegte Konvertierungen benötigen, ist Automatisierung in der Regel die bessere Langzeitlösung.
5. Einschränkungen bei manueller und Online-CSV-zu-Word-Konvertierung
Manuelle Methoden und Online-Tools funktionieren für gelegentliche Zwecke, versagen jedoch, wenn Sie CSV-Dateien regelmäßig oder in großem Umfang verarbeiten müssen. Hier sind die häufigsten Herausforderungen:
Häufige Herausforderungen
- Repetitive Arbeit – Wenn Sie jede Woche oder jeden Tag CSV in Word konvertieren, wird manuelles Kopieren und Einfügen mühsam und fehleranfällig.
- Große Datensätze – Word hat Schwierigkeiten, Tabellen mit Tausenden von Zeilen zu verarbeiten, die aus Excel eingefügt wurden. Die Leistung nimmt ab und die Formatierung bricht zusammen.
- Stapelverarbeitung – Wenn Sie mehrere CSV-Dateien in Word-Dokumente konvertieren müssen, ist die manuelle Bearbeitung einzeln unpraktisch.
- Konsistenz der Formatierung – Manuelle Formatierung variiert jedes Mal. Kopfzeilen, Schriftarten und Tabellenstile können in verschiedenen Dokumenten unterschiedlich aussehen.
- Datenschutzbedenken – Online-Konverter erfordern das Hochladen Ihrer Daten auf externe Server, was für sensible Informationen möglicherweise nicht akzeptabel ist.
- Automatisierte Berichterstellung – Wenn Berichte nach einem Zeitplan (täglich, wöchentlich) generiert werden müssen, kann die manuelle Konvertierung nicht mithalten.
Für diese Situationen bietet die Python-Automatisierung einen praktischen Weg – und der nächste Abschnitt zeigt genau, wie Sie sie implementieren.
6. Methode 4 – CSV automatisch mit Python in Word konvertieren
Python ist eine natürliche Wahl für die Automatisierung der CSV-zu-Word-Konvertierung. Es verfügt über ein integriertes csv-Modul zum Lesen von Daten, und mit Spire.Doc für Python können Sie Word-Dokumente erstellen und formatieren, ohne dass Microsoft Word installiert sein muss.
Dieser Abschnitt führt Sie durch die vollständige Implementierung: Installation der Bibliothek, Lesen von CSV-Daten, Erstellen einer Word-Tabelle und Speichern des Ergebnisses als DOCX.
Spire.Doc für Python installieren
Installieren Sie die Bibliothek über pip:
pip install spire.doc
Importieren Sie die erforderlichen Klassen in Ihr Python-Skript:
from spire.doc import *
from spire.doc.common import *
Schritt 1: CSV-Daten lesen
Das integrierte csv-Modul von Python liest CSV-Dateien in eine Liste von Zeilen:
import csv
csv_data = []
with open("sales_data.csv", "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
Die erste Zeile enthält normalerweise Spaltenüberschriften, und die folgenden Zeilen enthalten die Daten.
Schritt 2: Ein Word-Dokument und eine Tabelle erstellen
Erstellen Sie ein neues Word-Dokument, fügen Sie einen Abschnitt hinzu und initialisieren Sie eine Tabelle mit den Abmessungen Ihrer CSV-Daten:
document = Document()
section = document.AddSection()
num_rows = len(csv_data)
num_cols = len(csv_data[0]) if csv_data else 0
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
Schritt 3: Tabelle mit CSV-Daten füllen
Iterieren Sie durch die CSV-Zeilen und schreiben Sie jeden Wert in die entsprechende Zelle. Formatieren Sie die Kopfzeile mit einem eigenen Stil:
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
Dieser Code formatiert die erste Zeile als Kopfzeile mit dunkelblauem Hintergrund und weißem Fettdruck und wendet abwechselnde Zeilenfarben zur besseren Lesbarkeit an.
Schritt 4: Als DOCX speichern
Speichern Sie das generierte Word-Dokument:
document.SaveToFile("SalesReport.docx", FileFormat.Docx)
document.Close()
Unten sehen Sie eine Vorschau der CSV-Daten und des generierten Word-Dokuments:
Das Ergebnis ist eine ordnungsgemäß formatierte .docx-Datei, die Ihre CSV-Daten in einer Word-Tabelle enthält.
Für erweiterte Anpassungsoptionen für Tabellen lesen Sie unseren Leitfaden zum Erstellen und Formatieren von Word-Tabellen mit Python.
7. Vollständiges Python-Beispiel für CSV zu Word
Hier ist das vollständige, ausführbare Skript, das eine CSV-Datei liest und sie in ein Word-Dokument mit einem Titel, einer formatierten Tabelle, abwechselnden Zeilenfarben und Tabellenrahmen konvertiert.
import csv
from spire.doc import *
from spire.doc.common import *
def csv_to_word(csv_path, output_path, title="Data Report"):
csv_data = []
with open(csv_path, "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
if not csv_data:
print("CSV file is empty.")
return
num_rows = len(csv_data)
num_cols = len(csv_data[0])
document = Document()
section = document.AddSection()
title_para = section.AddParagraph()
title_range = title_para.AppendText(title)
title_range.CharacterFormat.FontSize = 18
title_range.CharacterFormat.Bold = True
title_para.Format.HorizontalAlignment = HorizontalAlignment.Center
title_para.Format.AfterSpacing = 12
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
table.Format.Borders.Vertical.BorderType = BorderStyle.Single
table.Format.Borders.Vertical.LineWidth = 0.5
table.Format.Borders.Horizontal.BorderType = BorderStyle.Single
table.Format.Borders.Horizontal.LineWidth = 0.5
document.SaveToFile(output_path, FileFormat.Docx)
document.Close()
print(f"Word document saved to: {output_path}")
csv_to_word("sales_data.csv", "SalesReport.docx", "Q4 Sales Report")
So funktioniert es
csv.readerliest die CSV-Datei Zeile für Zeile und behandelt verschiedene Kodierungen überutf-8-sig(das BOM-Marker verarbeitet).Document()erstellt ein leeres Word-Dokument.AddSection()fügt einen Abschnitt (Seite) zum Dokument hinzu.AddTable(True)erstellt eine neue Tabelle mit aktivierter automatischer Anpassung.ResetCells()legt die genauen Abmessungen fest.AppendText()schreibt jeden CSV-Wert als Textbereich in die entsprechende Zelle.- Kopfzeilenformatierung wendet einen dunkelblauen Hintergrund, weißen Fettdruck und zentrierte Ausrichtung auf die erste Zeile an.
- Abwechselnde Zeilenfarben verwenden Hellgrau für gerade Zeilen und keine Füllung für ungerade Zeilen, was die Lesbarkeit verbessert.
SaveToFile()exportiert das Dokument als.docx-Datei.
8. Warum Spire.Doc für die CSV-zu-Word-Konvertierung verwenden?
Spire.Doc für Python bietet mehrere technische Vorteile für Entwickler, die programmgesteuert Word-Dokumente aus CSV-Daten generieren müssen.
Vorteile
| Vorteil | Details |
|---|---|
| Keine Abhängigkeit von Microsoft Word | Erstellen und bearbeiten Sie DOCX-Dateien, ohne Microsoft Word auf dem Server oder Computer installieren zu müssen |
| Umfassende Tabellenformatierung | Steuern Sie Zellschattierung, Rahmen, Ausrichtung, Zeilenhöhen, Spaltenbreiten und Tabellenstile |
| Automatisierte Berichterstellung | Erstellen Sie Skripte, die CSV auf Zeitplan in Word konvertieren und in Datenpipelines integrieren |
| Stapelverarbeitung von Dokumenten | Verarbeiten Sie mehrere CSV-Dateien in einer Schleife und generieren Sie für jede separate Word-Dokumente |
| Python-Integration | Funktioniert nahtlos mit dem Standard-csv-Modul von Python und anderen Datenverarbeitungsbibliotheken |
| Vollständige DOCX-Unterstützung | Generieren Sie Dokumente, die mit Microsoft Word, LibreOffice und Google Docs kompatibel sind |
Wichtige API-Klassen
Document– Stellt ein Word-Dokument dar. Verwenden Sie es, um neue Dokumente zu erstellen oder vorhandene zu laden.Section– Stellt einen Abschnitt (Seite) innerhalb eines Dokuments dar. Enthält Absätze, Tabellen und andere Inhalte.Table– Stellt eine Tabelle in einem Word-Dokument dar. Unterstützt Zeilen-/Spaltenmanipulation, Formatierung und Rahmen.TableRow/TableCell– Bieten Zugriff auf einzelne Zeilen und Zellen für Formatierung und Inhaltseinfügung.Paragraph/TextRange– Verarbeiten Textinhalte innerhalb von Zellen, einschließlich Schriftart, Größe, Farbe und Ausrichtung.
9. Vergleich der CSV-zu-Word-Konvertierungsmethoden
| Methode | Benutzerfreundlichkeit | Stapelverarbeitung | Formatierungskontrolle | Datenschutz | Am besten geeignet für |
|---|---|---|---|---|---|
| Kopieren & Einfügen | ★★★★★ | ✗ | Gering | ✓ | Einmalige, kleine Datensätze |
| Text-in-Tabelle | ★★★★☆ | ✗ | Mittel | ✓ | Workflows ohne Excel, moderate Datenmengen |
| Online-Konverter | ★★★★★ | ✗ | Gering | ✗ | Schnelle einmalige Konvertierungen |
| Python + Spire.Doc | ★★★☆☆ | ✓ | Hoch | ✓ | Wiederkehrende Aufgaben, Stapelverarbeitung, Automatisierung |
Zusammenfassung: Manuelle Methoden und Online-Tools sind schnell und zugänglich, aber nicht skalierbar. Python-Automatisierung mit Spire.Doc erfordert eine geringe Einrichtungsgebühr, zahlt sich aber aus, wenn Sie konsistente, wiederholbare oder Stapelkonvertierungen von CSV in Word benötigen.
10. FAQ
Wie konvertiere ich eine CSV-Datei in ein Word-Dokument?
Sie können eine CSV-Datei mit mehreren Methoden in ein Word-Dokument konvertieren: (1) Öffnen Sie die CSV in Excel, kopieren Sie die Daten und fügen Sie sie in Word ein; (2) Verwenden Sie die Funktion „Text in Tabelle“ von Word, um durch Kommas getrennten Text direkt in eine Tabelle zu konvertieren; (3) Verwenden Sie einen Online-CSV-zu-Word-Konverter für eine schnelle einmalige Konvertierung; (4) Verwenden Sie Python mit Spire.Doc für Python, um die Konvertierung programmatisch zu automatisieren. Der Python-Ansatz ist am besten für wiederkehrende Aufgaben oder Stapelverarbeitung geeignet.
Kann ich CSV automatisch in DOCX konvertieren?
Ja. Sie können die CSV-zu-DOCX-Konvertierung mit Python automatisieren. Lesen Sie die CSV-Daten mit dem integrierten csv-Modul von Python, erstellen Sie dann mit Spire.Doc für Python ein Word-Dokument, füllen Sie eine Tabelle mit den CSV-Daten und speichern Sie sie als .docx-Datei. Dieser Ansatz funktioniert ohne Microsoft Word und kann so geplant werden, dass er automatisch ausgeführt wird.
Wie füge ich CSV-Daten in eine Word-Tabelle ein?
Um CSV-Daten manuell in eine Word-Tabelle einzufügen, können Sie die Funktion Einfügen > Tabelle > Text in Tabelle konvertieren von Word verwenden – fügen Sie den CSV-Text ein und konvertieren Sie ihn dann mit Kommas als Trennzeichen. Für die programmatische Einfügung verwenden Sie Python: Lesen Sie die CSV mit dem csv-Modul, erstellen Sie eine Tabelle in einem Word-Dokument mit Spire.Doc für Python und iterieren Sie durch die CSV-Zeilen, um jede Zelle zu füllen.
Gibt es einen kostenlosen CSV-zu-Word-Konverter online?
Ja, mehrere Websites bieten kostenlose CSV-zu-Word-Konvertierungen an. Online-Konverter haben jedoch Einschränkungen: Dateigrößenbeschränkungen, eingeschränkte Formatierungskontrolle und Datenschutzbedenken, da Ihre Daten auf einen Server eines Drittanbieters hochgeladen werden. Für sensible Daten oder wiederkehrende Konvertierungen ist eine lokale Python-Lösung mit Spire.Doc für Python eine zuverlässigere und privatere Alternative.
Kann Python CSV-Dateien in Word-Dokumente konvertieren?
Ja, Python kann CSV-Dateien in Word-Dokumente konvertieren. Mit Spire.Doc für Python können Sie CSV-Daten mit dem Standard-csv-Modul lesen, ein Word-Dokument erstellen, eine formatierte Tabelle hinzufügen, diese mit den CSV-Inhalten füllen und das Ergebnis als DOCX-Datei speichern. Dies funktioniert ohne Microsoft Word und unterstützt die Stapelverarbeitung mehrerer CSV-Dateien.
Benötigt Spire.Doc für Python Microsoft Word, um installiert zu sein?
Nein. Spire.Doc für Python ist eine eigenständige Bibliothek, die Word-Dokumente unabhängig erstellt und bearbeitet. Sie erfordert keine Installation von Microsoft Word oder einer Office-Komponente auf Ihrem System. Dies macht es für Serverumgebungen und automatisierte Workflows geeignet.
Fazit
Die Konvertierung von CSV in Word ist eine gängige Aufgabe mit mehreren Ansätzen. Manuelle Methoden – Kopieren und Einfügen sowie die Text-in-Tabelle-Funktion von Word – eignen sich gut für gelegentliche Anwendungsfälle mit kleinen Datensätzen. Online-Konverter bieten Komfort für schnelle, einmalige Aufgaben, werfen jedoch Datenschutzbedenken auf und bieten keine Formatierungskontrolle. Keine dieser Optionen skaliert für Stapelverarbeitung, geplante Berichterstellung oder Szenarien, die eine konsistente Formatierung über viele Dokumente hinweg erfordern.
Python-Automatisierung mit Spire.Doc für Python bietet eine zuverlässige Lösung für die programmatische Konvertierung von CSV in DOCX. Sie liest CSV-Daten, erstellt formatierte Word-Tabellen und generiert professionelle Dokumente, ohne Microsoft Word zu benötigen – ideal für automatisierte Workflows, Stapelverarbeitung und serverseitige Dokumentengenerierung.
Sie können eine kostenlose 30-Tage-Lizenz beantragen, um alle Funktionen von Spire.Doc für Python zu bewerten.
Siehe auch
Как конвертировать CSV в Word (ручные и Python методы)
Оглавление
- Зачем конвертировать CSV в Word?
- Метод 1 – Копирование и вставка данных CSV в Word
- Метод 2 – Преобразование CSV в таблицу Word с помощью функции «Текст в таблицу»
- Метод 3 – Использование онлайн-конвертера CSV в Word
- Ограничения ручного и онлайн-преобразования CSV в Word
- Метод 4 – Автоматическое преобразование CSV в Word с помощью Python
- Полный пример преобразования CSV в Word на Python
- Почему использовать Spire.Doc для преобразования CSV в Word?
- Сравнение методов преобразования CSV в Word
- Часто задаваемые вопросы
Файлы CSV широко используются для хранения и обмена табличными данными, но они не всегда являются лучшим форматом для обмена информацией. Когда вам нужно включить данные электронной таблицы в отчет, предложение, документ проекта или отчет для клиента, преобразование файла CSV в документ Word часто обеспечивает лучшую презентацию и возможности форматирования.
Существует несколько способов преобразования CSV в Word, от простых ручных методов до специализированных конвертеров CSV в Word и автоматизированных решений. Лучший метод зависит от вашего рабочего процесса, размера данных и того, как часто вам нужно выполнять преобразование.
В этом руководстве вы узнаете четыре практических способа преобразования CSV в документы Word, включая ручные методы, онлайн-конвертеры CSV в Word и подход на основе Python для автоматического преобразования данных CSV в документы DOCX. Независимо от того, нужно ли вам быстрое одноразовое преобразование или масштабируемое решение для повторяющихся задач, вы найдете подходящий вариант.
Быстрая навигация
- Зачем конвертировать CSV в Word?
- Метод 1 – Копирование и вставка данных CSV в Word
- Метод 2 – Преобразование CSV в таблицу Word с помощью функции «Текст в таблицу»
- Метод 3 – Использование онлайн-конвертера CSV в Word
- Ограничения ручного и онлайн-преобразования CSV в Word
- Метод 4 – Автоматическое преобразование CSV в Word с помощью Python
- Полный пример преобразования CSV в Word на Python
- Почему использовать Spire.Doc для преобразования CSV в Word?
- Сравнение методов преобразования CSV в Word
- Часто задаваемые вопросы
1. Зачем конвертировать CSV в Word?
Вы можете спросить: почему бы не использовать Excel? В конце концов, файлы CSV открываются нативно в программах для работы с электронными таблицами. Хотя Excel отлично подходит для анализа данных и расчетов, документы Word служат другим целям. Word предоставляет превосходные возможности форматирования для текстовых отчетов, отчетов для клиентов и документов, готовых к печати, где данные должны отображаться вместе с пояснительным текстом, заголовками и стилизованными макетами.
Распространенные сценарии использования
| Сценарий использования | Почему Word лучше Excel |
|---|---|
| Бизнес-отчеты | Объединение таблиц данных с текстовым анализом и резюме для руководства |
| Документация проекта | Встраивание данных в структурированные документы, содержащие инструкции и контекст |
| Отчеты для клиентов | Представление данных в брендированных, профессионально оформленных документах |
| Академические работы | Соблюдение конкретных правил форматирования (APA, MLA) с интеграцией данных в текст |
| Подготовка к слиянию почты | Использование данных CSV в качестве источника для персонализированных писем и наклеек в Word |
Когда вам нужно преобразовать файл CSV в документ Word, правильный метод зависит от того, как часто вы это делаете и насколько детальный контроль форматирования вам нужен.
2. Метод 1 – Копирование и вставка данных CSV в Word
Самый простой способ перенести данные CSV в Word — скопировать их из электронной таблицы и вставить напрямую. Этот метод хорошо подходит для небольших наборов данных и одноразовых задач.
Шаг 1: Откройте файл CSV в Excel
Дважды щелкните файл .csv или откройте Excel и используйте Файл > Открыть, чтобы загрузить CSV. Excel автоматически разделит значения, разделенные запятыми, по столбцам.
Шаг 2: Выберите данные
Выделите ячейки, которые вы хотите включить в свой документ Word. Вы можете выбрать весь лист, нажав Ctrl + A, или выбрать определенный диапазон.
Шаг 3: Вставьте в Word
Откройте Microsoft Word, поместите курсор туда, где должны быть данные, и нажмите Ctrl + V. Word автоматически преобразует табличные данные в таблицу Word.
Шаг 4: Примените форматирование таблицы
Используйте вкладку Конструктор таблиц в Word, чтобы применить стиль, настроить ширину столбцов и отформатировать заголовки.
Преимущества и недостатки
| Аспект | Оценка |
|---|---|
| Простота использования | Очень просто — специальные инструменты не требуются |
| Скорость | Быстро для небольших наборов данных |
| Контроль форматирования | Ограничено — форматирование может нарушиться при больших объемах данных |
| Масштабируемость | Не подходит для файлов с сотнями или тысячами строк |
| Воспроизводимость | Ручной процесс — трудно повторять последовательно |
Если вы также работаете с рабочими процессами электронных таблиц, вам может быть полезно наше руководство по преобразованию файлов CSV в Excel.
3. Метод 2 – Преобразование CSV в таблицу Word с помощью функции «Текст в таблицу»
Word имеет встроенную функцию, которая может преобразовывать текст, разделенный разделителями, непосредственно в таблицу — Excel не требуется. Этот метод особенно актуален, если вы ищете способ преобразовать CSV в таблицу Word, поскольку он использует встроенное в Word преобразование «Текст в таблицу».
Шаг 1: Откройте файл CSV в текстовом редакторе
Откройте файл .csv в Блокноте, Notepad++ или любом другом простом текстовом редакторе. Вы увидите необработанные значения, разделенные запятыми.
Шаг 2: Скопируйте содержимое CSV
Выделите весь текст (Ctrl + A) и скопируйте его (Ctrl + C).
Шаг 3: Вставьте в Word как обычный текст
В Word вставьте содержимое. Оно появится как обычный текст с запятыми, разделяющими значения.
Шаг 4: Используйте преобразование «Текст в таблицу»
Выделите вставленный текст, затем перейдите в Вставка > Таблица > Преобразовать текст в таблицу. В диалоговом окне:
- Установите Разделить текст по: Запятые
- При необходимости измените количество столбцов
- Нажмите OK
Word преобразует текст, разделенный запятыми, в правильно структурированную таблицу.
Шаг 5: Отформатируйте таблицу
Примените стиль таблицы с вкладки Конструктор таблиц, отформатируйте строку заголовка и при необходимости настройте ширину столбцов.
Преимущества и недостатки
| Аспект | Оценка |
|---|---|
| Простота использования | Легко — Excel не нужен, работает полностью в Word |
| Контроль форматирования | Средний — Word автоматически обрабатывает структуру таблицы |
| Масштабируемость | Работает для файлов умеренного размера; очень большие файлы могут работать медленно |
| Точность | Хорошо — Word в большинстве случаев правильно анализирует разделители-запятые |
| Ограничение | Может неправильно интерпретировать запятые внутри заключенных в кавычки полей (например, «Смит, Джон») |
Если ваши данные уже хранятся в рабочих книгах Excel, а не в файлах CSV, ознакомьтесь с нашим руководством по преобразованию листов Excel в документы Word.
4. Метод 3 – Использование онлайн-конвертера CSV в Word
Если у вас не установлен Excel или Word, или вам просто нужно быстрое одноразовое преобразование, онлайн-конвертер CSV в Word справится с задачей за считанные секунды. Несколько бесплатных инструментов позволяют загрузить файл CSV и скачать документ Word.
Как это работает
- Найдите в браузере «онлайн-конвертер CSV в Word»
- Загрузите файл
.csvна веб-сайт конвертера - Дождитесь завершения преобразования
- Скачайте сгенерированный файл
.docx
На что обратить внимание при выборе онлайн-конвертера
При выборе онлайн-конвертера CSV в Word учитывайте:
- Ограничения размера файла
- Поддерживаемые выходные форматы (DOC или DOCX)
- Политики конфиденциальности данных
- Качество форматирования таблицы
- Поддержка пакетной обработки
Преимущества и недостатки
| Аспект | Оценка |
|---|---|
| Простота использования | Очень просто — установка программного обеспечения не требуется |
| Скорость | Быстро для небольших и средних файлов |
| Контроль форматирования | Низкий — вы получаете то, что производит инструмент |
| Конфиденциальность | Проблема — ваши данные загружаются на сторонний сервер |
| Ограничения размера файла | Большинство инструментов накладывают ограничения на размер загрузки |
| Пакетная обработка | Не поддерживается — один файл за раз |
Когда использовать онлайн-конвертер
Онлайн-конвертеры — разумный выбор, когда у вас есть один неконфиденциальный файл CSV, и вам просто нужно быстрое преобразование. Однако, если ваши данные содержат личную информацию, финансовые записи или бизнес-критически важный контент, загрузка их на сторонний сервис может быть неприемлемой.
Если вам нужны повторяемые или крупномасштабные преобразования, автоматизация обычно является лучшим долгосрочным решением.
5. Ограничения ручного и онлайн-преобразования CSV в Word
Ручные методы и онлайн-инструменты подходят для периодического использования, но они неэффективны, когда вам нужно обрабатывать файлы CSV регулярно или в больших объемах. Вот распространенные проблемы:
Распространенные проблемы
- Повторяющаяся работа — Если вы конвертируете CSV в Word каждую неделю или каждый день, ручное копирование и вставка становится утомительным и подверженным ошибкам.
- Большие наборы данных — Word с трудом справляется с таблицами, содержащими тысячи строк, скопированных из Excel. Производительность снижается, а форматирование нарушается.
- Пакетная обработка — Когда вам нужно преобразовать несколько файлов CSV в документы Word, делать это по одному непрактично.
- Согласованность форматирования — Ручное форматирование каждый раз отличается. Заголовки, шрифты и стили таблиц могут выглядеть по-разному в документах.
- Проблемы конфиденциальности — Онлайн-конвертеры требуют загрузки ваших данных на внешние серверы, что может быть неприемлемо для конфиденциальной информации.
- Автоматическая генерация отчетов — Если отчеты должны генерироваться по расписанию (ежедневно, еженедельно), ручное преобразование не сможет справиться с этим.
В этих ситуациях автоматизация на Python обеспечивает практичный путь вперед — и следующий раздел подробно описывает, как ее реализовать.
6. Метод 4 – Автоматическое преобразование CSV в Word с помощью Python
Python является естественным выбором для автоматизации преобразования CSV в Word. Он имеет встроенный модуль csv для чтения данных, а с помощью Spire.Doc для Python вы можете создавать и форматировать документы Word без необходимости установки Microsoft Word.
В этом разделе подробно описана полная реализация: установка библиотеки, чтение данных CSV, создание таблицы Word и сохранение результата в формате DOCX.
Установка Spire.Doc для Python
Установите библиотеку через pip:
pip install spire.doc
Импортируйте необходимые классы в ваш скрипт Python:
from spire.doc import *
from spire.doc.common import *
Шаг 1: Чтение данных CSV
Встроенный модуль csv Python читает файлы CSV в список строк:
import csv
csv_data = []
with open("sales_data.csv", "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
Первая строка обычно содержит заголовки столбцов, а последующие строки — данные.
Шаг 2: Создание документа Word и таблицы
Создайте новый документ Word, добавьте раздел и инициализируйте таблицу с размерами ваших данных CSV:
document = Document()
section = document.AddSection()
num_rows = len(csv_data)
num_cols = len(csv_data[0]) if csv_data else 0
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
Шаг 3: Заполнение таблицы данными CSV
Перебирайте строки CSV и записывайте каждое значение в соответствующую ячейку. Отформатируйте строку заголовка с отличительным стилем:
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
Этот код форматирует первую строку как заголовок с темно-синим фоном и белым жирным текстом, а также применяет чередующиеся цвета строк для удобочитаемости.
Шаг 4: Сохранение в формате DOCX
Сохраните сгенерированный документ Word:
document.SaveToFile("SalesReport.docx", FileFormat.Docx)
document.Close()
Ниже представлен предварительный просмотр данных CSV и сгенерированного документа Word:
Результатом является правильно отформатированный файл .docx, содержащий ваши данные CSV в таблице Word.
Для получения более продвинутых опций настройки таблиц ознакомьтесь с нашим руководством по созданию и форматированию таблиц Word с помощью Python.
7. Полный пример преобразования CSV в Word на Python
Вот полный исполняемый скрипт, который читает файл CSV и преобразует его в документ Word с заголовком, отформатированной таблицей, чередующимися цветами строк и границами таблицы.
import csv
from spire.doc import *
from spire.doc.common import *
def csv_to_word(csv_path, output_path, title="Data Report"):
csv_data = []
with open(csv_path, "r", encoding="utf-8-sig") as file:
reader = csv.reader(file)
for row in reader:
csv_data.append(row)
if not csv_data:
print("CSV file is empty.")
return
num_rows = len(csv_data)
num_cols = len(csv_data[0])
document = Document()
section = document.AddSection()
title_para = section.AddParagraph()
title_range = title_para.AppendText(title)
title_range.CharacterFormat.FontSize = 18
title_range.CharacterFormat.Bold = True
title_para.Format.HorizontalAlignment = HorizontalAlignment.Center
title_para.Format.AfterSpacing = 12
table = section.AddTable(True)
table.ResetCells(num_rows, num_cols)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, 100)
for r in range(num_rows):
row = table.Rows[r]
row.Height = 22
row.HeightType = TableRowHeightType.Exactly
for c in range(num_cols):
cell = row.Cells[c]
paragraph = cell.AddParagraph()
text_range = paragraph.AppendText(csv_data[r][c])
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
if r == 0:
row.IsHeader = True
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_DarkBlue()
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.TextColor = Color.get_White()
text_range.CharacterFormat.FontSize = 11
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
else:
text_range.CharacterFormat.FontSize = 10
if r % 2 == 0:
cell.CellFormat.Shading.BackgroundPatternColor = Color.get_LightGray()
else:
cell.CellFormat.Shading.BackgroundPatternColor = Color.Empty()
table.Format.Borders.Vertical.BorderType = BorderStyle.Single
table.Format.Borders.Vertical.LineWidth = 0.5
table.Format.Borders.Horizontal.BorderType = BorderStyle.Single
table.Format.Borders.Horizontal.LineWidth = 0.5
document.SaveToFile(output_path, FileFormat.Docx)
document.Close()
print(f"Word document saved to: {output_path}")
csv_to_word("sales_data.csv", "SalesReport.docx", "Q4 Sales Report")
Как это работает
csv.readerчитает файл CSV построчно, обрабатывая различные кодировки с помощьюutf-8-sig(который обрабатывает маркеры BOM).Document()создает пустой документ Word.AddSection()добавляет раздел (страницу) в документ.AddTable(True)создает новую таблицу с включенной автоподгонкой.ResetCells()устанавливает точные размеры.AppendText()записывает каждое значение CSV в соответствующую ячейку как текстовый диапазон.- Форматирование заголовка применяет темно-синий фон, жирный белый текст и выравнивание по центру к первой строке.
- Чередующиеся цвета строк используют светло-серый для четных строк и отсутствие заливки для нечетных строк, улучшая читаемость.
SaveToFile()экспортирует документ в формате.docx.
8. Почему использовать Spire.Doc для преобразования CSV в Word?
Spire.Doc для Python предлагает несколько технических преимуществ для разработчиков, которым необходимо программно генерировать документы Word из данных CSV.
Преимущества
| Преимущество | Детали |
|---|---|
| Отсутствие зависимости от Microsoft Word | Создавайте и манипулируйте файлами DOCX без установки Microsoft Word на сервере или компьютере |
| Комплексное форматирование таблиц | Управляйте заливкой ячеек, границами, выравниванием, высотой строк, шириной столбцов и стилями таблиц |
| Автоматическая генерация отчетов | Создавайте скрипты, которые преобразуют CSV в Word по расписанию, интегрируясь с конвейерами данных |
| Пакетная обработка документов | Обрабатывайте несколько файлов CSV в цикле, генерируя отдельные документы Word для каждого |
| Интеграция с Python | Бесшовно работает со стандартным модулем csv Python и другими библиотеками обработки данных |
| Полная поддержка DOCX | Генерируйте документы, совместимые с Microsoft Word, LibreOffice и Google Docs |
Ключевые классы API
Document— Представляет документ Word. Используйте его для создания новых документов или загрузки существующих.Section— Представляет раздел (страницу) в документе. Содержит абзацы, таблицы и другой контент.Table— Представляет таблицу в документе Word. Поддерживает манипулирование строками/столбцами, стилизацию и границы.TableRow/TableCell— Предоставляют доступ к отдельным строкам и ячейкам для форматирования и вставки контента.Paragraph/TextRange— Обрабатывают текстовый контент в ячейках, включая шрифт, размер, цвет и выравнивание.
9. Сравнение методов преобразования CSV в Word
| Метод | Простота использования | Пакетная обработка | Контроль форматирования | Конфиденциальность | Лучше всего подходит для |
|---|---|---|---|---|---|
| Копирование и вставка | ★★★★★ | ✗ | Низкий | ✓ | Одноразовые, небольшие наборы данных |
| Текст в таблицу | ★★★★☆ | ✗ | Средний | ✓ | Рабочие процессы без Excel, умеренные данные |
| Онлайн-конвертер | ★★★★★ | ✗ | Низкий | ✗ | Быстрые одноразовые преобразования |
| Python + Spire.Doc | ★★★☆☆ | ✓ | Высокий | ✓ | Повторяющиеся задачи, пакетная обработка, автоматизация |
Резюме: Ручные методы и онлайн-инструменты быстры и доступны, но не масштабируются. Автоматизация на Python с Spire.Doc требует небольших первоначальных вложений, но окупается, когда вам нужно последовательное, повторяемое или пакетное преобразование CSV в Word.
10. Часто задаваемые вопросы
Как преобразовать файл CSV в документ Word?
Вы можете преобразовать файл CSV в документ Word несколькими способами: (1) Откройте CSV в Excel, скопируйте данные и вставьте их в Word; (2) Используйте функцию Word «Текст в таблицу», чтобы преобразовать текст, разделенный запятыми, непосредственно в таблицу; (3) Используйте онлайн-конвертер CSV в Word для быстрого одноразового преобразования; (4) Используйте Python с Spire.Doc для Python для программного автоматического преобразования. Подход на Python лучше всего подходит для повторяющихся задач или пакетной обработки.
Могу ли я автоматически преобразовывать CSV в DOCX?
Да. Вы можете автоматизировать преобразование CSV в DOCX с помощью Python. Читайте данные CSV с помощью встроенного модуля csv Python, затем используйте Spire.Doc для Python для создания документа Word, заполнения таблицы данными CSV и сохранения ее в формате .docx. Этот подход работает без Microsoft Word и может быть запланирован для автоматического запуска.
Как вставить данные CSV в таблицу Word?
Чтобы вручную вставить данные CSV в таблицу Word, вы можете использовать функцию Word Вставка > Таблица > Преобразовать текст в таблицу — вставьте текст CSV, затем преобразуйте его, используя запятые в качестве разделителя. Для программной вставки используйте Python: прочитайте CSV с помощью модуля csv, создайте таблицу в документе Word с помощью Spire.Doc для Python и перебирайте строки CSV, чтобы заполнить каждую ячейку.
Существует ли бесплатный онлайн-конвертер CSV в Word?
Да, несколько веб-сайтов предлагают бесплатное преобразование CSV в Word. Однако онлайн-конвертеры имеют ограничения: ограничения на размер файла, ограниченный контроль форматирования и проблемы с конфиденциальностью, поскольку ваши данные загружаются на сторонний сервер. Для конфиденциальных данных или повторяющихся преобразований локальное решение на Python с Spire.Doc для Python является более надежной и конфиденциальной альтернативой.
Может ли Python преобразовывать файлы CSV в документы Word?
Да, Python может преобразовывать файлы CSV в документы Word. Используя Spire.Doc для Python, вы можете читать данные CSV с помощью стандартного модуля csv, создавать документ Word, добавлять отформатированную таблицу, заполнять ее содержимым CSV и сохранять результат в виде файла DOCX. Это работает без Microsoft Word и поддерживает пакетную обработку нескольких файлов CSV.
Требуется ли Spire.Doc для Python установка Microsoft Word?
Нет. Spire.Doc для Python — это автономная библиотека, которая создает и манипулирует документами Word независимо. Она не требует установки Microsoft Word или каких-либо компонентов Office в вашей системе. Это делает ее подходящей для серверных сред и автоматизированных рабочих процессов.
Заключение
Преобразование CSV в Word — распространенная задача с множеством подходов. Ручные методы — копирование и вставка, а также функция Word «Текст в таблицу» — хорошо подходят для периодического использования с небольшими наборами данных. Онлайн-конвертеры предлагают удобство для быстрых одноразовых задач, но вызывают опасения по поводу конфиденциальности и не имеют контроля над форматированием. Ни один из этих вариантов не масштабируется для пакетной обработки, запланированной генерации отчетов или сценариев, требующих согласованного форматирования во многих документах.
Автоматизация на Python с Spire.Doc для Python предоставляет надежное решение для программного преобразования CSV в DOCX. Он читает данные CSV, создает отформатированные таблицы Word и генерирует профессиональные документы без необходимости установки Microsoft Word — что делает его идеальным для автоматизированных рабочих процессов, пакетной обработки и генерации документов на стороне сервера.
Вы можете подать заявку на бесплатную 30-дневную лицензию для оценки всех функций Spire.Doc для Python.
См. также
Como verificar o tamanho da página PDF: 4 métodos gratuitos e fáceis
Sumário
- Por que saber o tamanho da página do seu PDF é importante
- O Método Mais Fácil - Usando o Adobe Acrobat Reader
- Método do Navegador Web - Verificando via Chrome/Edge
- Sem Software? Usando Verificador Online de Tamanho de Página PDF
- Automatize com Código - Verifique o Tamanho da Página do PDF via C#
- Tabela de Referência de Tamanho de Página PDF Padrão
- Perguntas Frequentes

Verificar o tamanho da página de um PDF é uma operação diária essencial para funcionários de escritório, designers gráficos e profissionais de impressão. Dimensões de página incorretas podem levar a conteúdo cortado, layouts distorcidos e até mesmo à rejeição automática de submissões de documentos oficiais.
Desde verificações rápidas únicas em PDFs individuais até a inspeção em massa de centenas de documentos, diferentes cenários de uso exigem soluções personalizadas. Este artigo irá guiá-lo sobre como verificar o tamanho da página do PDF usando 4 ferramentas rápidas e gratuitas. Nenhum software pago é necessário e, ao final, você nunca mais terá que adivinhar as dimensões de um PDF.
- Por que saber o tamanho da página do seu PDF é importante
- O Método Mais Fácil - Usando o Adobe Acrobat Reader
- Método do Navegador Web - Verificando via Chrome/Edge
- Sem Software? Usando Verificador Online de Tamanho de Página PDF
- Automatize com Código - Verifique o Tamanho da Página do PDF via C#
- Tabela de Referência de Tamanho de Página PDF Padrão
- Perguntas Frequentes
Por que saber o tamanho da página do seu PDF é importante
Verificar as dimensões exatas de uma página PDF é crucial por vários motivos:
- Impressão Profissional: Impressoras exigem especificações exatas. Um tamanho de página incorreto pode levar a texto cortado, margens desalinhadas e trabalhos de impressão rejeitados.
- Envio de Formulários: Muitos formulários e aplicações oficiais exigem um tamanho de papel específico (por exemplo, Carta ou A4). Usar o tamanho errado pode resultar em rejeição automática.
- Design e Layout: Designers precisam garantir que os elementos se encaixem perfeitamente dentro dos limites da página.
- Consistência de Arquivo: Um documento PDF pode conter páginas de tamanhos mistos. Verificá-las garante um produto final uniforme e profissional.
⚠️ Observação: Não confunda tamanho da página com tamanho do arquivo. Eles são independentes.
- Tamanho da página = largura e altura físicas (por exemplo, 8,5”×11”, 210×297 mm).
- Tamanho do arquivo = espaço de armazenamento em disco (por exemplo, 2,5 MB).
O Método Mais Fácil - Usando o Adobe Acrobat Reader
O Adobe Acrobat Reader é um visualizador de PDF gratuito e popular. Ele fornece medições precisas do tamanho da página e funciona com todos os arquivos PDF, incluindo aqueles com dimensões personalizadas ou não padrão.
Aqui está a maneira mais rápida de encontrar o tamanho da página do PDF:
- Abra o arquivo PDF desejado com o Adobe Acrobat Reader.
- Vá para Arquivo > Propriedades (ou simplesmente use o atalho de teclado Ctrl+D no Windows).
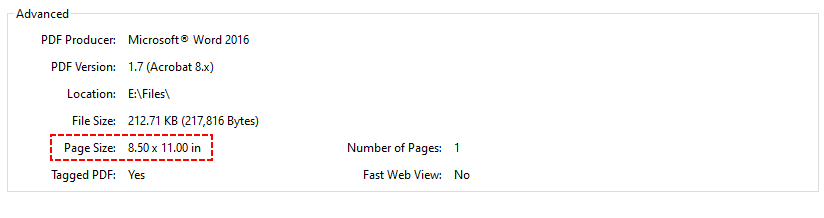
- Na caixa de diálogo Propriedades do Documento, clique na guia Descrição.
- Role para baixo para encontrar o campo Tamanho da Página. Ele exibirá as dimensões exatas (por exemplo, 8,5 x 11 pol / 210 x 297 mm).
Após verificar as dimensões da página do seu PDF, os próximos passos lógicos são redimensionar e cortar. Redimensionar altera o tamanho de toda a página do PDF — por exemplo, convertendo A4 para Carta, escalando o conteúdo para cima ou para baixo. Cortar páginas de PDF remove bordas indesejadas (margens brancas, marcas de corte) sem escalar o conteúdo.
Método do Navegador Web - Verificando via Chrome/Edge
Se você não tem um visualizador de PDF instalado, navegadores modernos como Google Chrome e Microsoft Edge podem exibir tamanhos de página PDF sem nenhum software adicional.
Como saber o tamanho do papel do PDF em um navegador:
- Abra seu arquivo PDF no navegador Chrome (ou Edge).
- Clique nos três pontos verticais (ícone de menu) no canto superior direito.
- No menu suspenso, selecione “Propriedades do Documento”.
- Verifique o Tamanho da Página, além da orientação retrato/paisagem no painel pop-up.
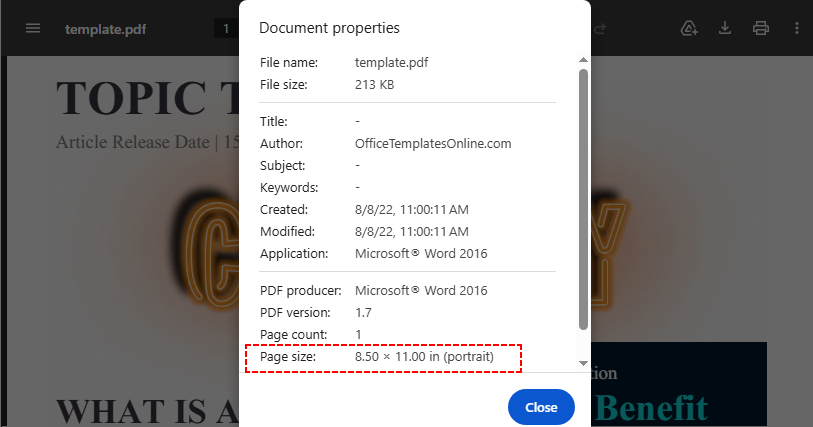
❌ Limitação: Para documentos de várias páginas com tamanhos de página mistos, a maioria dos navegadores não consegue exibir as dimensões exatas — eles mostram apenas "varia". Nesse cenário, use os métodos abaixo.
Sem Software? Usando Verificador Online de Tamanho de Página PDF
Para usuários que preferem evitar software de desktop completamente, ou que precisam de uma solução rápida e multiplataforma, as ferramentas online de PDF são uma excelente alternativa. Esses analisadores baseados na web geralmente escaneiam o documento inteiro e identificam tamanhos de página PDF mistos em segundos.
Etapas para verificar o tamanho da página do PDF online:
- Abra um verificador online gratuito e confiável de tamanho de página PDF (por exemplo, Analisador de Dimensões de Página do SwiftPDFLab)
- Envie seu arquivo PDF por meio de arrastar e soltar ou upload pelo navegador de arquivos.
- A plataforma analisará todas as páginas e apresentará especificações detalhadas:
- Número de páginas
- Dimensões da página (em polegadas, mm ou pontos – você pode alternar unidades)
- Orientação (retrato/paisagem)
- Classificação de tamanho padrão (por exemplo, “A4”, “Carta”, “Legal”)
- Um indicador se o documento tem tamanhos de página mistos
- Opcional: Exporte as informações da página como um arquivo CSV para fins de documentação.
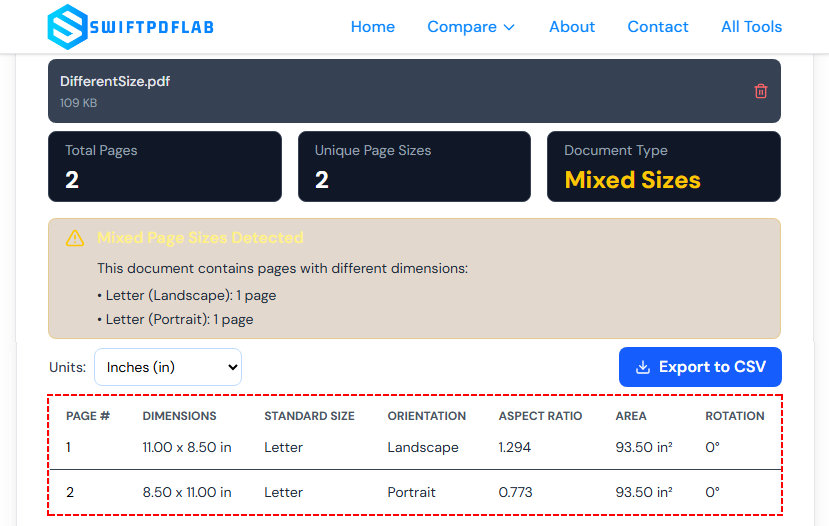
Lembrete de Privacidade: Nunca envie documentos PDF confidenciais ou sensíveis para ferramentas online públicas para evitar vazamento de dados.
Automatize com Código - Verifique o Tamanho da Página do PDF via C#
Se você trabalha com um grande número de PDFs ou precisa integrar a detecção de tamanho de página em um fluxo de trabalho automatizado, usar uma biblioteca .NET como o Free Spire.PDF é a abordagem mais eficiente.
Por que usar este método?
- Você pode escanear todas as páginas instantaneamente.
- Obtenha dimensões em pontos, polegadas, cm ou pixels.
- Funciona em servidores (sem necessidade de GUI).
- Biblioteca gratuita sem marcas d'água para operações básicas (limite de 10 páginas).
Código C# para Obter o Tamanho da Página do PDF
Todo PDF armazena internamente as dimensões da página em pontos (1 ponto = 1/72 polegada). O código a seguir carrega um PDF e imprime a largura e a altura de cada página em pontos.
using System;
using Spire.Pdf;
namespace GetPDFPageSize_Points
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("SamplePDF.pdf");
// Percorre cada página do PDF
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
float widthPt = page.Size.Width;
float heightPt = page.Size.Height;
Console.WriteLine($"Página {i+1}: {widthPt} pt × {heightPt} pt");
}
Console.ReadKey();
}
}
}
Saída:
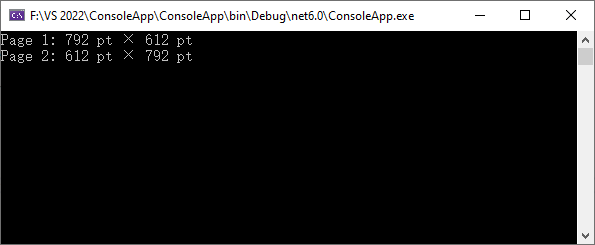
Convertendo Pontos para Outras Unidades
Pontos são técnicos, mas nem sempre fáceis de usar. Para apresentar dimensões em polegadas, centímetros ou pixels, use PdfUnitConvertor para alternar unidades de medida
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// Converter para polegadas
float inchW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// Converter para centímetros
float cmW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float cmH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// Converter para pixels
float pxW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pxH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
Além das dimensões da página, você também pode precisar detectar a orientação e o ângulo de rotação da página — informações especialmente úteis ao processar documentos digitalizados ou ao endireitar páginas PDF automaticamente.
Tabela de Referência de Tamanho de Página PDF Padrão
Após verificar o tamanho da página do seu PDF, use esta tabela para identificar formatos padrão ou verificar a conformidade com os requisitos de envio.
| Tamanho do Papel | Largura × Altura (mm) | Largura × Altura (polegadas) | Largura × Altura (pontos) | Uso Comum |
|---|---|---|---|---|
| A4 | 210 × 297 mm | 8,27 × 11,69 pol | 595 × 842 pt | Cartas, relatórios, formulários (maioria dos países) |
| US Letter | 216 × 279 mm | 8,5 × 11 pol | 612 × 792 pt | Cartas comerciais, currículos (EUA, Canadá) |
| A3 | 297 × 420 mm | 11,69 × 16,54 pol | 842 × 1191 pt | Diagramas, pôsteres, pequenos jornais |
| A5 | 148 × 210 mm | 5,83 × 8,27 pol | 420 × 595 pt | Cadernos, folhetos, livretos |
| Legal | 216 × 356 mm | 8,5 × 14 pol | 612 × 1008 pt | Contratos legais (EUA) |
| Tabloid / Ledger | 279 × 432 mm | 11 × 17 pol | 792 × 1224 pt | Folhetos, boletins informativos |
Como interpretar tamanhos personalizados?
Se as dimensões não corresponderem a nenhuma linha padrão, seu PDF usa um tamanho de página personalizado. Isso é comum para:
- Capturas de tela salvas como PDF (tamanho corresponde à resolução da tela)
- Desenhos CAD ou plantas arquitetônicas
- Imagens digitalizadas com margens cortadas
Conclusão
Saber como verificar o tamanho da página do PDF é uma habilidade fundamental para qualquer pessoa que trabalhe com documentos digitais. As quatro soluções acima cobrem todos os cenários de usuário: use o Adobe Reader para verificação local de arquivo único, navegadores para verificações casuais rápidas, ferramentas online para uso temporário entre dispositivos e codificação C# para inspeção automatizada em massa em nível empresarial.
Sempre verifique as dimensões da página antes de imprimir ou enviar documentos para evitar erros de formatação e consulte as especificações de papel padrão e fórmulas de conversão para corresponder às regras de envio exigidas sem esforço.
Perguntas Frequentes
P: Um único PDF pode ter páginas de tamanhos diferentes?
Sim, absolutamente. Um documento PDF pode conter uma mistura de diferentes tamanhos e orientações de página. Por exemplo, você pode ter uma página de texto A4 em retrato seguida por um diagrama A3 em paisagem. É sempre uma boa ideia verificar os tamanhos das páginas de todo o documento para evitar inconsistências.
P: Como verifico se um PDF tem tamanhos de página mistos?
- Método manual (documentos pequenos): No Adobe Acrobat Reader, percorra cada página para verificar sua dimensão. Isso é tedioso para PDFs longos.
- Método de ferramenta online: Faça o upload para um verificador gratuito de tamanho de página; ele listará os tamanhos de todas as páginas instantaneamente.
- Método de script C#: Use o código acima para escanear cada página e sinalizar quaisquer páginas que diferem da primeira.
P: Como converto entre polegadas, mm e pontos?
Você pode usar fórmulas de conversão simples:
- Pontos → Polegadas: Divida os pontos por 72. (por exemplo, 612 pt / 72 = 8,5 pol).
- Polegadas → Pontos: Multiplique as polegadas por 72. (por exemplo, 8,5 pol * 72 = 612 pt).
- Polegadas → mm: Multiplique as polegadas por 25,4. (por exemplo, 8,5 pol * 25,4 = 215,9 mm).
- mm → Polegadas: Divida os mm por 25,4. (por exemplo, 210 mm / 25,4 = 8,2677 pol).
Para referência rápida: 1 polegada = 72 pontos = 25,4 milímetros.
P: Existe uma maneira de verificar os tamanhos das páginas de vários PDFs de uma vez (em lote)?
Sim, escreva um script C# para percorrer uma pasta, carregar cada PDF e extrair os tamanhos das páginas. Aqui está um exemplo mínimo:
string[] files = Directory.GetFiles(@"C:\PDFs\", "*.pdf");
foreach (string file in files)
{
using (PdfDocument pdf = new PdfDocument())
{
pdf.LoadFromFile(file);
Console.WriteLine($"{Path.GetFileName(file)}: {pdf.Pages[0].Size.Width} x {pdf.Pages[0].Size.Height} pts");
}
}
Veja Também
PDF 페이지 크기 확인 방법: 4가지 무료 쉬운 방법
PDF의 페이지 크기를 확인하는 것은 사무직원, 그래픽 디자이너, 인쇄 전문가 모두에게 필수적인 일상 작업입니다. 잘못된 페이지 크기는 콘텐츠가 잘리거나, 레이아웃이 왜곡되거나, 심지어 공식 문서 제출이 자동으로 거부될 수도 있습니다.
개별 PDF에 대한 빠른 일회성 확인부터 수백 개의 문서를 대규모로 일괄 검사하는 것까지, 다양한 사용 시나리오에는 맞춤형 솔루션이 필요합니다. 이 글에서는 4가지 빠르고 무료 도구를 사용하여 PDF 페이지 크기를 확인하는 방법을 안내합니다. 유료 소프트웨어는 필요 없으며, 이 글을 마치면 PDF의 크기를 다시 추측할 필요가 없을 것입니다.
- PDF 페이지 크기를 알아야 하는 이유
- 가장 쉬운 방법 - Adobe Acrobat Reader 사용
- 웹 브라우저 방법 - Chrome/Edge를 통해 확인
- 소프트웨어 없음? 온라인 PDF 페이지 크기 확인기 사용
- 코드로 자동화 - C#을 통해 PDF 페이지 크기 확인
- 표준 PDF 페이지 크기 참조 테이블
- 자주 묻는 질문
PDF 페이지 크기를 알아야 하는 이유
PDF 페이지의 정확한 크기를 확인하는 것은 여러 가지 이유로 중요합니다:
- 전문 인쇄: 인쇄업체는 정확한 사양을 요구합니다. 잘못된 페이지 크기는 텍스트가 잘리거나, 여백이 잘못 정렬되거나, 인쇄 작업이 거부될 수 있습니다.
- 양식 제출: 많은 공식 양식 및 신청서에는 특정 용지 크기(예: Letter 또는 A4)가 필요합니다. 잘못된 크기를 사용하면 자동으로 거부될 수 있습니다.
- 디자인 및 레이아웃: 디자이너는 요소가 페이지 경계 내에 완벽하게 맞도록 해야 합니다.
- 파일 일관성: PDF 문서에는 크기가 혼합된 페이지가 포함될 수 있습니다. 이를 확인하면 균일하고 전문적인 최종 결과물을 얻을 수 있습니다.
⚠️ 참고: 페이지 크기와 파일 크기를 혼동하지 마세요. 서로 관련이 없습니다.
- 페이지 크기 = 물리적 너비 및 높이 (예: 8.5”×11”, 210×297 mm).
- 파일 크기 = 디스크의 저장 공간 (예: 2.5 MB).
가장 쉬운 방법 - Adobe Acrobat Reader 사용
Adobe Acrobat Reader는 인기 있는 무료 PDF 뷰어입니다. 정확한 페이지 크기 측정을 제공하며 사용자 정의 또는 비표준 크기를 포함한 모든 PDF 파일과 함께 작동합니다.
PDF 페이지 크기를 찾는 가장 빠른 방법은 다음과 같습니다:
- Adobe Acrobat Reader로 대상 PDF 파일을 엽니다.
- 파일 > 속성으로 이동하거나 (또는 Windows에서 바로 가기 키 Ctrl+D 사용).
- 문서 속성 대화 상자에서 설명 탭을 클릭합니다.
- 아래로 스크롤하여 페이지 크기 필드를 찾습니다. 정확한 크기(예: 8.5 x 11인치 / 210 x 297 mm)가 표시됩니다.
PDF 페이지 크기를 확인한 후 다음 단계는 크기 조정 및 자르기입니다. 크기 조정은 전체 PDF 페이지 크기를 변경합니다. 예를 들어 A4를 Letter로 변환할 때 콘텐츠를 확대 또는 축소합니다. PDF 페이지 자르기는 콘텐츠를 확대/축소하지 않고 원치 않는 가장자리(흰색 여백, 자르기 표시)를 제거합니다.
웹 브라우저 방법 - Chrome/Edge를 통해 확인
PDF 뷰어를 설치하지 않은 경우 Google Chrome 및 Microsoft Edge와 같은 최신 브라우저에서 추가 소프트웨어 없이 PDF 페이지 크기를 표시할 수 있습니다.
브라우저에서 PDF 용지 크기를 아는 방법:
- Chrome (또는 Edge) 브라우저에서 PDF 파일을 엽니다.
- 오른쪽 상단의 세 개의 세로 점 (메뉴 아이콘)을 클릭합니다.
- 드롭다운에서 "문서 속성"을 선택합니다.
- 팝업 패널에서 페이지 크기와 세로/가로 방향을 확인합니다.
❌ 제한 사항: 페이지 크기가 혼합된 다중 페이지 문서의 경우 대부분의 브라우저는 정확한 크기를 표시하지 못하고 "다름"만 표시합니다. 이 경우 아래 방법을 사용하세요.
소프트웨어 없음? 온라인 PDF 페이지 크기 확인기 사용
데스크톱 소프트웨어를 완전히 피하고 싶거나 빠른 크로스 플랫폼 솔루션이 필요한 사용자에게는 온라인 PDF 도구가 훌륭한 대안입니다. 이러한 웹 기반 분석기는 일반적으로 전체 문서를 스캔하고 혼합된 PDF 페이지 크기를 몇 초 안에 식별합니다.
온라인에서 PDF 페이지 크기를 확인하는 단계:
- 신뢰할 수 있는 무료 온라인 PDF 페이지 크기 확인기(예: SwiftPDFLab의 페이지 크기 분석기)를 엽니다.
- 드래그 앤 드롭 또는 파일 브라우저 업로드를 통해 PDF 파일을 업로드합니다.
- 플랫폼이 모든 페이지를 분석하고 자세한 사양을 출력합니다:
- 페이지 수
- 페이지 크기 (인치, mm 또는 포인트 – 단위를 전환할 수 있습니다)
- 방향 (세로/가로)
- 표준 크기 분류 (예: "A4", "Letter", "Legal")
- 문서에 혼합된 페이지 크기가 있는지 여부를 나타내는 표시기
- 선택 사항: 문서화 목적으로 페이지 정보를 CSV 파일로 내보냅니다.
개인 정보 보호 알림: 데이터 유출을 방지하기 위해 기밀 또는 민감한 PDF 문서를 공개 온라인 도구에 업로드하지 마십시오.
코드로 자동화 - C#을 통해 PDF 페이지 크기 확인
많은 수의 PDF를 다루거나 페이지 크기 감지를 자동화된 워크플로에 통합해야 하는 경우, Free Spire.PDF와 같은 .NET 라이브러리를 사용하는 것이 가장 효율적인 접근 방식입니다.
이 방법을 사용하는 이유는 무엇인가요?
- 모든 페이지를 즉시 스캔할 수 있습니다.
- 포인트, 인치, cm 또는 픽셀 단위로 크기를 얻을 수 있습니다.
- 서버에서 작동합니다 (GUI 불필요).
- 기본 작업에 대한 워터마크 없는 무료 라이브러리 (10페이지 제한).
PDF 페이지 크기를 얻는 C# 코드
모든 PDF는 내부적으로 페이지 크기를 포인트 (1 포인트 = 1/72 인치)로 저장합니다. 다음 코드는 PDF를 로드하고 각 페이지의 너비와 높이를 포인트 단위로 출력합니다.
using System;
using Spire.Pdf;
namespace GetPDFPageSize_Points
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("SamplePDF.pdf");
// 모든 PDF 페이지를 순회
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
float widthPt = page.Size.Width;
float heightPt = page.Size.Height;
Console.WriteLine($"페이지 {i+1}: {widthPt} pt × {heightPt} pt");
}
Console.ReadKey();
}
}
}
출력:
포인트를 다른 단위로 변환
포인트는 기술적이지만 항상 사용자 친화적이지는 않습니다. 크기를 인치, 센티미터 또는 픽셀로 표시하려면 PdfUnitConvertor를 사용하여 측정 단위를 전환하세요.
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// 인치로 변환
float inchW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// 센티미터로 변환
float cmW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float cmH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// 픽셀로 변환
float pxW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pxH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
페이지 크기뿐만 아니라 페이지 방향 및 회전 각도를 감지해야 할 수도 있습니다. 이 정보는 스캔된 문서를 처리하거나 PDF 페이지를 자동으로 똑바로 펴는 데 특히 유용합니다.
표준 PDF 페이지 크기 참조 테이블
PDF 페이지 크기를 확인한 후 이 테이블을 사용하여 표준 형식을 식별하거나 제출 요구 사항 준수 여부를 확인하세요.
| 용지 크기 | 너비 × 높이 (mm) | 너비 × 높이 (인치) | 너비 × 높이 (포인트) | 일반 용도 |
|---|---|---|---|---|
| A4 | 210 × 297 mm | 8.27 × 11.69 in | 595 × 842 pt | 편지, 보고서, 양식 (대부분의 국가) |
| US Letter | 216 × 279 mm | 8.5 × 11 in | 612 × 792 pt | 비즈니스 편지, 이력서 (미국, 캐나다) |
| A3 | 297 × 420 mm | 11.69 × 16.54 in | 842 × 1191 pt | 다이어그램, 포스터, 소형 신문 |
| A5 | 148 × 210 mm | 5.83 × 8.27 in | 420 × 595 pt | 노트북, 전단지, 소책자 |
| Legal | 216 × 356 mm | 8.5 × 14 in | 612 × 1008 pt | 법률 계약 (미국) |
| Tabloid / Ledger | 279 × 432 mm | 11 × 17 in | 792 × 1224 pt | 브로셔, 뉴스레터 |
사용자 정의 크기를 해석하는 방법?
치수가 표준 행과 일치하지 않으면 PDF에서 사용자 정의 페이지 크기를 사용한 것입니다. 이는 다음과 같은 경우에 일반적입니다:
- PDF로 저장된 스크린샷 (화면 해상도와 일치하는 크기)
- CAD 도면 또는 건축 계획
- 여백이 잘린 스캔 이미지
마무리
PDF 페이지 크기를 확인하는 방법을 아는 것은 디지털 문서를 다루는 모든 사람에게 기본적인 기술입니다. 위에서 설명한 네 가지 솔루션은 모든 사용자 시나리오를 다룹니다. 단일 로컬 파일 확인에는 Adobe Reader를, 빠른 캐주얼 확인에는 브라우저를, 크로스 디바이스 임시 사용에는 온라인 도구를, 엔터프라이즈급 일괄 자동 검사에는 C# 코딩을 사용하세요.
인쇄 또는 문서 제출 전에 항상 페이지 크기를 확인하여 서식 오류를 피하고, 표준 용지 사양 및 변환 공식을 참조하여 필요한 제출 규칙을 쉽게 맞추세요.
자주 묻는 질문
Q: 단일 PDF에 다른 크기의 페이지가 포함될 수 있나요?
네, 물론입니다. PDF 문서에는 다양한 페이지 크기와 방향이 혼합되어 포함될 수 있습니다. 예를 들어, 세로 A4 텍스트 페이지 다음에 가로 A3 다이어그램이 올 수 있습니다. 불일치를 피하기 위해 전체 문서의 페이지 크기를 확인하는 것이 좋습니다.
Q: PDF에 혼합된 페이지 크기가 있는지 어떻게 확인하나요?
- 수동 방법 (소규모 문서): Adobe Acrobat Reader에서 각 페이지를 스크롤하여 크기를 확인합니다. 긴 PDF의 경우 번거롭습니다.
- 온라인 도구 방법: 무료 페이지 크기 확인기에 업로드하면 모든 페이지의 크기를 즉시 나열합니다.
- C# 스크립트 방법: 위의 코드를 사용하여 각 페이지를 스캔하고 첫 번째 페이지와 다른 페이지를 표시합니다.
Q: 인치, mm 및 포인트 간에 어떻게 변환하나요?
간단한 변환 공식을 사용할 수 있습니다:
- 포인트 → 인치: 포인트를 72로 나눕니다. (예: 612 pt / 72 = 8.5 in).
- 인치 → 포인트: 인치에 72를 곱합니다. (예: 8.5 in * 72 = 612 pt).
- 인치 → mm: 인치에 25.4를 곱합니다. (예: 8.5 in * 25.4 = 215.9 mm).
- mm → 인치: mm를 25.4로 나눕니다. (예: 210 mm / 25.4 = 8.2677 in).
빠른 참조: 1인치 = 72 포인트 = 25.4 밀리미터.
Q: 여러 PDF의 페이지 크기를 한 번에 (일괄) 확인할 수 있는 방법이 있나요?
네, C# 스크립트를 작성하여 폴더를 반복하고 각 PDF를 로드한 다음 페이지 크기를 추출할 수 있습니다. 다음은 최소한의 예입니다:
string[] files = Directory.GetFiles(@"C:\PDFs\", "*.pdf");
foreach (string file in files)
{
using (PdfDocument pdf = new PdfDocument())
{
pdf.LoadFromFile(file);
Console.WriteLine($"{Path.GetFileName(file)}: {pdf.Pages[0].Size.Width} x {pdf.Pages[0].Size.Height} pts");
}
}
참고 자료
Come controllare le dimensioni della pagina PDF: 4 metodi gratuiti e semplici
Indice
- Perché è importante conoscere le dimensioni della pagina PDF
- Il metodo più semplice: utilizzare Adobe Acrobat Reader
- Metodo del browser web: controllo tramite Chrome/Edge
- Nessun software? Utilizzo di un controllo online delle dimensioni delle pagine PDF
- Automatizza con il codice: controlla le dimensioni delle pagine PDF tramite C#
- Tabella di riferimento delle dimensioni standard delle pagine PDF
- Domande frequenti
Il controllo delle dimensioni delle pagine PDF è un'operazione quotidiana essenziale per impiegati d'ufficio, grafici e professionisti della stampa. Dimensioni di pagina errate possono portare a contenuti ritagliati, layout distorti e persino al rifiuto automatico delle presentazioni di documenti ufficiali.
Dai controlli rapidi una tantum su singoli PDF all'ispezione in blocco su larga scala di centinaia di documenti, diversi scenari di utilizzo richiedono soluzioni su misura. Questo articolo ti guiderà su come controllare le dimensioni delle pagine PDF utilizzando 4 strumenti veloci e gratuiti. Non è richiesto alcun software a pagamento e, alla fine, non dovrai più indovinare le dimensioni di un PDF.
- Perché è importante conoscere le dimensioni della pagina PDF
- Il metodo più semplice: utilizzare Adobe Acrobat Reader
- Metodo del browser web: controllo tramite Chrome/Edge
- Nessun software? Utilizzo di un controllo online delle dimensioni delle pagine PDF
- Automatizza con il codice: controlla le dimensioni delle pagine PDF tramite C#
- Tabella di riferimento delle dimensioni standard delle pagine PDF
- Domande frequenti
Perché è importante conoscere le dimensioni della pagina PDF
Il controllo delle dimensioni esatte di una pagina PDF è fondamentale per diversi motivi:
- Stampa professionale: le tipografie richiedono specifiche esatte. Una dimensione di pagina errata può portare a testo tagliato, margini disallineati e lavori di stampa rifiutati.
- Invio di moduli: molti moduli e applicazioni ufficiali richiedono una dimensione di carta specifica (ad es. Letter o A4). L'utilizzo della dimensione errata potrebbe comportare il rifiuto automatico.
- Design e layout: i designer devono assicurarsi che gli elementi si adattino perfettamente ai margini della pagina.
- Coerenza dei file: un documento PDF può contenere pagine di dimensioni miste. Controllarle garantisce un prodotto finale uniforme e professionale.
⚠️ Nota: Non confondere le dimensioni della pagina con le dimensioni del file. Sono non correlate.
- Dimensioni della pagina = larghezza e altezza fisiche (ad es. 8,5"×11", 210×297 mm).
- Dimensioni del file = spazio di archiviazione su disco (ad es. 2,5 MB).
Il metodo più semplice: utilizzare Adobe Acrobat Reader
Adobe Acrobat Reader è un popolare visualizzatore PDF gratuito. Fornisce misurazioni precise delle dimensioni delle pagine e funziona con tutti i file PDF, inclusi quelli con dimensioni personalizzate o non standard.
Ecco il modo più rapido per trovare le dimensioni delle pagine PDF:
- Apri il file PDF di destinazione con Adobe Acrobat Reader.
- Vai su File > Proprietà (o usa semplicemente la scorciatoia da tastiera Ctrl+D su Windows).
- Nella finestra di dialogo Proprietà documento, fai clic sulla scheda Descrizione.
- Scorri verso il basso per trovare il campo Dimensioni pagina. Verranno visualizzate le dimensioni esatte (ad es. 8,5 x 11 pollici / 210 x 297 mm).
Dopo aver controllato le dimensioni delle pagine PDF, i passaggi successivi logici sono il ridimensionamento e il ritaglio. Il ridimensionamento modifica le dimensioni dell'intera pagina PDF, ad esempio convertendo A4 in Letter ridimensionando il contenuto verso l'alto o verso il basso. Il ritaglio delle pagine PDF rimuove i bordi indesiderati (margini bianchi, segni di ritaglio) senza ridimensionare il contenuto.
Metodo del browser web: controllo tramite Chrome/Edge
Se non hai un visualizzatore PDF installato, i browser moderni come Google Chrome e Microsoft Edge possono visualizzare le dimensioni delle pagine PDF senza alcun software aggiuntivo.
Come conoscere le dimensioni della carta PDF in un browser:
- Apri il tuo file PDF nel browser Chrome (o Edge).
- Fai clic sui tre puntini verticali (icona del menu) nell'angolo in alto a destra.
- Dal menu a discesa, seleziona "Proprietà documento".
- Controlla le Dimensioni pagina più l'orientamento verticale/orizzontale nel pannello a comparsa.
❌ Limitazione: Per documenti multipagina con dimensioni di pagina miste, la maggior parte dei browser non può visualizzare le dimensioni esatte, mostra solo "varia". In questo scenario, utilizza i metodi seguenti.
Nessun software? Utilizzo di un controllo online delle dimensioni delle pagine PDF
Per gli utenti che preferiscono evitare del tutto il software desktop, o che necessitano di una rapida soluzione multipiattaforma, gli strumenti PDF online sono un'ottima alternativa. Questi analizzatori basati sul web in genere scansionano l'intero documento e identificano le dimensioni miste delle pagine PDF in pochi secondi.
Passaggi per controllare le dimensioni delle pagine PDF online:
- Apri un analizzatore di dimensioni pagine PDF online gratuito e affidabile (ad es. Analizzatore di dimensioni pagine di SwiftPDFLab)
- Carica il tuo file PDF tramite trascinamento o caricamento dal browser di file.
- La piattaforma analizzerà tutte le pagine e fornirà specifiche dettagliate:
- Numero di pagine
- Dimensioni della pagina (in pollici, mm o punti – puoi cambiare unità)
- Orientamento (verticale/orizzontale)
- Classificazione delle dimensioni standard (ad es. "A4", "Letter", "Legal")
- Un indicatore se il documento ha dimensioni di pagina miste
- Opzionale: Esporta le informazioni sulla pagina come file CSV a scopo di documentazione.
Promemoria sulla privacy: non caricare mai documenti PDF riservati o sensibili su strumenti online pubblici per evitare fughe di dati.
Automatizza con il codice: controlla le dimensioni delle pagine PDF tramite C#
Se lavori con un gran numero di PDF o hai bisogno di integrare il rilevamento delle dimensioni delle pagine in un flusso di lavoro automatizzato, l'utilizzo di una libreria .NET come Free Spire.PDF è l'approccio più efficiente.
Perché utilizzare questo metodo?
- Puoi scansionare tutte le pagine istantaneamente.
- Ottieni le dimensioni in punti, pollici, cm o pixel.
- Funziona sui server (nessuna GUI richiesta).
- Libreria gratuita senza watermark per operazioni di base (limite di 10 pagine).
Codice C# per ottenere le dimensioni delle pagine PDF
Ogni PDF memorizza internamente le dimensioni delle pagine in punti (1 punto = 1/72 di pollice). Il codice seguente carica un PDF e stampa la larghezza e l'altezza di ogni pagina in punti.
using System;
using Spire.Pdf;
namespace GetPDFPageSize_Points
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("SamplePDF.pdf");
// Scorre ogni pagina PDF
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
float widthPt = page.Size.Width;
float heightPt = page.Size.Height;
Console.WriteLine($"Pagina {i+1}: {widthPt} pt × {heightPt} pt");
}
Console.ReadKey();
}
}
}
Output:
Conversione di punti in altre unità
I punti sono tecnici ma non sempre di facile comprensione. Per presentare le dimensioni in pollici, centimetri o pixel, utilizzare PdfUnitConvertor per cambiare le unità di misura
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// Converti in pollici
float inchW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// Converti in centimetri
float cmW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float cmH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// Converti in pixel
float pxW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pxH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
Oltre alle semplici dimensioni delle pagine, potrebbe essere necessario anche rilevare l'orientamento e l'angolo di rotazione della pagina, informazioni particolarmente utili quando si elaborano documenti scansionati o si raddrizzano automaticamente le pagine PDF.
Tabella di riferimento delle dimensioni standard delle pagine PDF
Dopo aver controllato le dimensioni delle pagine PDF, utilizza questa tabella per identificare i formati standard o verificare la conformità ai requisiti di presentazione.
| Dimensione carta | Larghezza × Altezza (mm) | Larghezza × Altezza (pollici) | Larghezza × Altezza (punti) | Uso comune |
|---|---|---|---|---|
| A4 | 210 × 297 mm | 8,27 × 11,69 pollici | 595 × 842 pt | Lettere, relazioni, moduli (la maggior parte dei paesi) |
| US Letter | 216 × 279 mm | 8,5 × 11 pollici | 612 × 792 pt | Lettere commerciali, curriculum (USA, Canada) |
| A3 | 297 × 420 mm | 11,69 × 16,54 pollici | 842 × 1191 pt | Diagrammi, poster, piccoli giornali |
| A5 | 148 × 210 mm | 5,83 × 8,27 pollici | 420 × 595 pt | Quaderni, volantini, libretti |
| Legal | 216 × 356 mm | 8,5 × 14 pollici | 612 × 1008 pt | Contratti legali (USA) |
| Tabloid / Ledger | 279 × 432 mm | 11 × 17 pollici | 792 × 1224 pt | Brochure, newsletter |
Come interpretare le dimensioni personalizzate?
Se le dimensioni non corrispondono a nessuna riga standard, il tuo PDF utilizza una dimensione di pagina personalizzata. Questo è comune per:
- Screenshot salvati come PDF (le dimensioni corrispondono alla risoluzione dello schermo)
- Disegni CAD o progetti architettonici
- Immagini scansionate con margini ritagliati
Conclusione
Sapere come controllare le dimensioni delle pagine PDF è un'abilità fondamentale per chiunque lavori con documenti digitali. Le quattro soluzioni sopra coprono tutti gli scenari utente: utilizzare Adobe Reader per la verifica di singoli file locali, i browser per controlli rapidi e occasionali, gli strumenti online per un uso temporaneo multipiattaforma e la codifica C# per l'ispezione automatizzata di massa a livello aziendale.
Verifica sempre le dimensioni delle pagine prima di stampare o inviare documenti per evitare errori di formattazione e fai riferimento alle specifiche standard della carta e alle formule di conversione per rispettare facilmente le regole di presentazione richieste.
Domande frequenti
D: Un singolo PDF può avere pagine di dimensioni diverse?
Sì, assolutamente. Un documento PDF può contenere un mix di diverse dimensioni e orientamenti di pagina. Ad esempio, potresti avere una pagina di testo A4 in verticale seguita da un diagramma A3 in orizzontale. È sempre una buona idea controllare le dimensioni delle pagine dell'intero documento per evitare incongruenze.
D: Come faccio a verificare se un PDF ha dimensioni di pagina miste?
- Metodo manuale (documenti piccoli): In Adobe Acrobat Reader, scorri ogni pagina per controllarne le dimensioni. Questo è noioso per PDF lunghi.
- Metodo dello strumento online: Carica su un controllo gratuito delle dimensioni delle pagine; elencherà istantaneamente le dimensioni di tutte le pagine.
- Metodo dello script C#: Utilizza il codice sopra per scansionare ogni pagina e segnalare quelle che differiscono dalla prima pagina.
D: Come si converte tra pollici, mm e punti?
Puoi utilizzare semplici formule di conversione:
- Punti → Pollici: Dividi i punti per 72. (ad es. 612 pt / 72 = 8,5 pollici).
- Pollici → Punti: Moltiplica i pollici per 72. (ad es. 8,5 pollici * 72 = 612 pt).
- Pollici → mm: Moltiplica i pollici per 25,4. (ad es. 8,5 pollici * 25,4 = 215,9 mm).
- mm → Pollici: Dividi i mm per 25,4. (ad es. 210 mm / 25,4 = 8,2677 pollici).
Per un riferimento rapido: 1 pollice = 72 punti = 25,4 millimetri.
D: Esiste un modo per controllare le dimensioni delle pagine di più PDF contemporaneamente (in blocco)?
Sì, scrivi uno script C# per scorrere una cartella, caricare ogni PDF ed estrarre le dimensioni delle pagine. Ecco un esempio minimo:
string[] files = Directory.GetFiles(@"C:\PDFs\", "*.pdf");
foreach (string file in files)
{
using (PdfDocument pdf = new PdfDocument())
{
pdf.LoadFromFile(file);
Console.WriteLine($"{Path.GetFileName(file)}: {pdf.Pages[0].Size.Width} x {pdf.Pages[0].Size.Height} pts");
}
}
Vedi anche
- Come estrarre pagine da un PDF gratuitamente — Nessun Adobe necessario
- I 4 migliori modi per ruotare PDF gratuitamente: online, offline e Python
- Come comprimere un PDF: i migliori strumenti per rendere i PDF più piccoli
- C#/VB.NET: Cambia le dimensioni delle pagine PDF
- Python: Cambia o ottieni le dimensioni delle pagine PDF
Comment vérifier la taille de page d'un PDF : 4 méthodes gratuites et faciles
Table des matières
- Pourquoi connaître la taille de page de votre PDF est important
- La méthode la plus simple - Utiliser Adobe Acrobat Reader
- Méthode du navigateur Web - Vérification via Chrome/Edge
- Pas de logiciel ? Utiliser un vérificateur de taille de page PDF en ligne
- Automatiser avec du code - Vérifier la taille de page d'un PDF via C#
- Tableau de référence des tailles de page PDF standard
- FAQ
La vérification de la taille de page d'un PDF est une opération quotidienne essentielle pour le personnel de bureau, les graphistes et les professionnels de l'impression. Des dimensions de page incorrectes peuvent entraîner un contenu tronqué, des mises en page déformées, voire le rejet automatique des soumissions de documents officiels.
Des vérifications rapides ponctuelles sur des PDF individuels à l'inspection en masse de centaines de documents, différents scénarios d'utilisation nécessitent des solutions adaptées. Cet article vous guidera sur comment vérifier la taille de page d'un PDF en utilisant 4 outils rapides et gratuits. Aucun logiciel payant n'est requis, et à la fin, vous n'aurez plus jamais à deviner les dimensions d'un PDF.
- Pourquoi connaître la taille de page de votre PDF est important
- La méthode la plus simple - Utiliser Adobe Acrobat Reader
- Méthode du navigateur Web - Vérification via Chrome/Edge
- Pas de logiciel ? Utiliser un vérificateur de taille de page PDF en ligne
- Automatiser avec du code - Vérifier la taille de page d'un PDF via C#
- Tableau de référence des tailles de page PDF standard
- FAQ
Pourquoi connaître la taille de page de votre PDF est important
La vérification des dimensions exactes d'une page PDF est cruciale pour plusieurs raisons :
- Impression professionnelle : Les imprimeurs exigent des spécifications exactes. Une taille de page incorrecte peut entraîner des textes coupés, des marges mal alignées et le rejet des travaux d'impression.
- Soumission de formulaires : De nombreux formulaires et candidatures officiels nécessitent une taille de papier spécifique (par exemple, Lettre ou A4). L'utilisation d'une taille incorrecte pourrait entraîner un rejet automatique.
- Conception et mise en page : Les concepteurs doivent s'assurer que les éléments s'intègrent parfaitement dans les limites de la page.
- Cohérence des fichiers : Un document PDF peut contenir des pages de tailles mixtes. Leur vérification garantit un produit final uniforme et professionnel.
⚠️ Remarque : Ne confondez pas la taille de la page avec la taille du fichier. Ils ne sont pas liés.
- Taille de la page = largeur et hauteur physiques (par exemple, 8,5"×11", 210×297 mm).
- Taille du fichier = espace de stockage sur le disque (par exemple, 2,5 Mo).
La méthode la plus simple - Utiliser Adobe Acrobat Reader
Adobe Acrobat Reader est un lecteur PDF gratuit populaire. Il fournit des mesures précises de la taille des pages et fonctionne avec tous les fichiers PDF, y compris ceux avec des dimensions personnalisées ou non standard.
Voici le moyen le plus rapide de trouver la taille de page d'un PDF :
- Ouvrez votre fichier PDF cible avec Adobe Acrobat Reader.
- Allez dans Fichier > Propriétés (ou utilisez simplement le raccourci clavier Ctrl+D sous Windows).
- Dans la boîte de dialogue Propriétés du document, cliquez sur l'onglet Description.
- Faites défiler vers le bas pour trouver le champ Taille de la page. Il affichera les dimensions exactes (par exemple, 8,5 x 11 pouces / 210 x 297 mm).
Après avoir vérifié les dimensions de votre page PDF, les prochaines étapes logiques sont le redimensionnement et le recadrage. Le redimensionnement modifie la taille de la page PDF entière, par exemple, en convertissant A4 en Lettre en mettant à l'échelle le contenu vers le haut ou vers le bas. Le recadrage des pages PDF supprime les bords indésirables (marges blanches, marques de coupe) sans mettre à l'échelle le contenu.
Méthode du navigateur Web - Vérification via Chrome/Edge
Si vous n'avez pas de lecteur PDF installé, les navigateurs modernes comme Google Chrome et Microsoft Edge peuvent afficher les tailles de page PDF sans aucun logiciel supplémentaire.
Comment connaître la taille du papier PDF dans un navigateur :
- Ouvrez votre fichier PDF dans le navigateur Chrome (ou Edge).
- Cliquez sur les trois points verticaux (icône de menu) dans le coin supérieur droit.
- Dans le menu déroulant, sélectionnez « Propriétés du document ».
- Vérifiez la Taille de la page ainsi que l'orientation portrait/paysage dans le panneau contextuel.
❌ Limitation : Pour les documents multipages avec des tailles de page mixtes, la plupart des navigateurs ne peuvent pas afficher les dimensions exactes ; ils affichent seulement « varie ». Dans ce scénario, utilisez les méthodes ci-dessous.
Pas de logiciel ? Utiliser un vérificateur de taille de page PDF en ligne
Pour les utilisateurs qui préfèrent éviter complètement les logiciels de bureau, ou qui ont besoin d'une solution multiplateforme rapide, les outils PDF en ligne sont une excellente alternative. Ces analyseurs basés sur le Web analysent généralement l'ensemble du document et identifient les tailles de page PDF mixtes en quelques secondes.
Étapes pour vérifier la taille de page PDF en ligne :
- Ouvrez un vérificateur de taille de page PDF gratuit et fiable (par exemple, l'analyseur de dimensions de page de SwiftPDFLab)
- Téléchargez votre fichier PDF par glisser-déposer ou via le navigateur de fichiers.
- La plateforme analysera toutes les pages et affichera des spécifications détaillées :
- Nombre de pages
- Dimensions de la page (en pouces, mm ou points – vous pouvez changer d'unité)
- Orientation (portrait/paysage)
- Classification de la taille standard (par exemple, « A4 », « Lettre », « Légal »)
- Un indicateur si le document a des tailles de page mixtes
- Facultatif : Exportez les informations de page sous forme de fichier CSV à des fins de documentation.
Rappel de confidentialité : Ne téléchargez jamais de documents PDF confidentiels ou sensibles sur des outils en ligne publics pour éviter les fuites de données.
Automatiser avec du code - Vérifier la taille de page d'un PDF via C#
Si vous travaillez avec un grand nombre de PDF ou si vous avez besoin d'intégrer la détection de la taille des pages dans un flux de travail automatisé, l'utilisation d'une bibliothèque .NET comme Free Spire.PDF est l'approche la plus efficace.
Pourquoi utiliser cette méthode ?
- Vous pouvez analyser toutes les pages instantanément.
- Obtenez les dimensions en points, pouces, cm ou pixels.
- Fonctionne sur les serveurs (pas d'interface graphique nécessaire).
- Bibliothèque gratuite sans filigranes pour les opérations de base (limite de 10 pages).
Code C# pour obtenir la taille de page PDF
Chaque PDF stocke en interne les dimensions de page en points (1 point = 1/72 pouce). Le code suivant charge un PDF et affiche la largeur et la hauteur de chaque page en points.
using System;
using Spire.Pdf;
namespace GetPDFPageSize_Points
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("SamplePDF.pdf");
// Parcourir chaque page PDF
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
float widthPt = page.Size.Width;
float heightPt = page.Size.Height;
Console.WriteLine($"Page {i+1}: {widthPt} pt × {heightPt} pt");
}
Console.ReadKey();
}
}
}
Sortie :
Conversion des points en autres unités
Les points sont techniques mais pas toujours conviviaux. Pour présenter les dimensions en pouces, centimètres ou pixels, utilisez PdfUnitConvertor pour changer les unités de mesure
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// Convertir en pouces
float inchW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// Convertir en centimètres
float cmW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float cmH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// Convertir en pixels
float pxW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pxH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
Au-delà des dimensions de page, vous pourriez également avoir besoin de détecter l'orientation de la page et l'angle de rotation — des informations particulièrement utiles lors du traitement de documents numérisés ou du redressement automatique de pages PDF.
Tableau de référence des tailles de page PDF standard
Après avoir vérifié la taille de page de votre PDF, utilisez ce tableau pour identifier les formats standard ou vérifier la conformité aux exigences de soumission.
| Taille du papier | Largeur × Hauteur (mm) | Largeur × Hauteur (pouces) | Largeur × Hauteur (points) | Utilisation courante |
|---|---|---|---|---|
| A4 | 210 × 297 mm | 8,27 × 11,69 pouces | 595 × 842 pt | Lettres, rapports, formulaires (la plupart des pays) |
| US Letter | 216 × 279 mm | 8,5 × 11 pouces | 612 × 792 pt | Lettres commerciales, CV (États-Unis, Canada) |
| A3 | 297 × 420 mm | 11,69 × 16,54 pouces | 842 × 1191 pt | Diagrammes, affiches, petits journaux |
| A5 | 148 × 210 mm | 5,83 × 8,27 pouces | 420 × 595 pt | Cahiers, dépliants, livrets |
| Légal | 216 × 356 mm | 8,5 × 14 pouces | 612 × 1008 pt | Contrats légaux (États-Unis) |
| Tabloïd / Ledger | 279 × 432 mm | 11 × 17 pouces | 792 × 1224 pt | Brochures, newsletters |
Comment interpréter les tailles personnalisées ?
Si les dimensions ne correspondent à aucune ligne standard, votre PDF utilise une taille de page personnalisée. C'est courant pour :
- Captures d'écran enregistrées en PDF (taille correspondant à la résolution de l'écran)
- Dessins CAO ou plans architecturaux
- Images numérisées avec marges rognées
Conclusion
Savoir comment vérifier la taille de page d'un PDF est une compétence fondamentale pour quiconque travaille avec des documents numériques. Les quatre solutions ci-dessus couvrent tous les scénarios d'utilisateurs : utilisez Adobe Reader pour la vérification de fichiers locaux uniques, les navigateurs pour des vérifications rapides occasionnelles, les outils en ligne pour une utilisation temporaire multi-appareils, et le codage C# pour une inspection automatisée en masse au niveau de l'entreprise.
Vérifiez toujours les dimensions des pages avant l'impression ou la soumission de documents pour éviter les erreurs de mise en forme, et consultez les spécifications de papier standard et les formules de conversion pour respecter sans effort les règles de soumission requises.
FAQ
Q : Un seul PDF peut-il avoir des pages de tailles différentes ?
Oui, absolument. Un document PDF peut contenir un mélange de différentes tailles et orientations de page. Par exemple, vous pourriez avoir une page de texte A4 en portrait suivie d'un diagramme A3 en paysage. Il est toujours conseillé de vérifier les tailles de page de l'ensemble du document pour éviter les incohérences.
Q : Comment vérifier si un PDF a des tailles de page mixtes ?
- Méthode manuelle (petits documents) : Dans Adobe Acrobat Reader, faites défiler chaque page pour vérifier ses dimensions. C'est fastidieux pour les PDF longs.
- Méthode de l'outil en ligne : Téléchargez sur un vérificateur de taille de page gratuit ; il listera instantanément les tailles de toutes les pages.
- Méthode du script C# : Utilisez le code ci-dessus pour analyser chaque page et signaler celles qui diffèrent de la première page.
Q : Comment convertir entre pouces, mm et points ?
Vous pouvez utiliser des formules de conversion simples :
- Points → Pouces : Divisez les points par 72. (par exemple, 612 pt / 72 = 8,5 pouces).
- Pouces → Points : Multipliez les pouces par 72. (par exemple, 8,5 pouces * 72 = 612 pt).
- Pouces → mm : Multipliez les pouces par 25,4. (par exemple, 8,5 pouces * 25,4 = 215,9 mm).
- mm → Pouces : Divisez les mm par 25,4. (par exemple, 210 mm / 25,4 = 8,2677 pouces).
Pour référence rapide : 1 pouce = 72 points = 25,4 millimètres.
Q : Existe-t-il un moyen de vérifier les tailles de page de plusieurs PDF à la fois (en masse) ?
Oui, écrivez un script C# pour parcourir un dossier, charger chaque PDF et extraire les tailles de page. Voici un exemple minimal :
string[] files = Directory.GetFiles(@"C:\PDFs\", "*.pdf");
foreach (string file in files)
{
using (PdfDocument pdf = new PdfDocument())
{
pdf.LoadFromFile(file);
Console.WriteLine($"{Path.GetFileName(file)}: {pdf.Pages[0].Size.Width} x {pdf.Pages[0].Size.Height} pts");
}
}
Voir aussi
- Comment extraire des pages d'un PDF gratuitement — Sans Adobe
- 4 meilleures façons de faire pivoter un PDF gratuitement : en ligne, hors ligne et Python
- Comment compresser un PDF : les meilleurs outils pour réduire la taille des PDF
- C#/VB.NET : Modifier la taille de page PDF
- Python : Modifier ou obtenir la taille de page PDF
Cómo comprobar el tamaño de página de un PDF: 4 métodos gratuitos y sencillos
Tabla de Contenidos
- Por qué es importante conocer el tamaño de página de tu PDF
- El método más fácil: Usando Adobe Acrobat Reader
- Método del navegador web: Comprobación a través de Chrome/Edge
- ¿Sin software? Usando un verificador de tamaño de página de PDF en línea
- Automatiza con código: Comprueba el tamaño de página de un PDF con C#
- Tabla de referencia de tamaños de página de PDF estándar
- Preguntas frecuentes
Comprobar el tamaño de página de un PDF es una operación diaria esencial para el personal de oficina, los diseñadores gráficos y los profesionales de la impresión. Las dimensiones incorrectas de la página pueden provocar que el contenido se recorte, diseños desalineados e incluso el rechazo automático de envíos de documentos oficiales.
Desde comprobaciones rápidas de archivos PDF individuales hasta la inspección masiva de cientos de documentos, los diferentes escenarios de uso requieren soluciones personalizadas. Este artículo te guiará sobre cómo comprobar el tamaño de página de un PDF utilizando 4 herramientas rápidas y gratuitas. No se requiere software de pago, y al final, nunca más tendrás que adivinar las dimensiones de un PDF.
- Por qué es importante conocer el tamaño de página de tu PDF
- El método más fácil: Usando Adobe Acrobat Reader
- Método del navegador web: Comprobación a través de Chrome/Edge
- ¿Sin software? Usando un verificador de tamaño de página de PDF en línea
- Automatiza con código: Comprueba el tamaño de página de un PDF con C#
- Tabla de referencia de tamaños de página de PDF estándar
- Preguntas frecuentes
Por qué es importante conocer el tamaño de página de tu PDF
Comprobar las dimensiones exactas de una página PDF es crucial por varias razones:
- Impresión Profesional: Las imprentas requieren especificaciones exactas. Un tamaño de página incorrecto puede provocar cortes de texto, márgenes desalineados y trabajos de impresión rechazados.
- Envío de Formularios: Muchos formularios y solicitudes oficiales requieren un tamaño de papel específico (por ejemplo, Carta o A4). Usar el tamaño incorrecto podría resultar en un rechazo automático.
- Diseño y Maquetación: Los diseñadores necesitan asegurarse de que los elementos encajen perfectamente dentro de los límites de la página.
- Consistencia de Archivos: Un documento PDF puede contener páginas de tamaños mixtos. Comprobarlas garantiza un producto final uniforme y profesional.
⚠️ Nota: No confundas el tamaño de página con el tamaño del archivo. No están relacionados.
- Tamaño de página = ancho y alto físicos (por ejemplo, 8,5”×11”, 210×297 mm).
- Tamaño del archivo = espacio de almacenamiento en disco (por ejemplo, 2,5 MB).
El método más fácil: Usando Adobe Acrobat Reader
Adobe Acrobat Reader es un visor de PDF gratuito y popular. Ofrece mediciones precisas del tamaño de página y funciona con todos los archivos PDF, incluidos aquellos con dimensiones personalizadas o no estándar.
Aquí está la forma más rápida de encontrar el tamaño de página de un PDF:
- Abre tu archivo PDF deseado con Adobe Acrobat Reader.
- Ve a Archivo > Propiedades (o simplemente usa el atajo de teclado Ctrl+D en Windows).
- En el cuadro de diálogo Propiedades del documento, haz clic en la pestaña Descripción.
- Desplázate hacia abajo para encontrar el campo Tamaño de página. Mostrará las dimensiones exactas (por ejemplo, 8,5 x 11 pulgadas / 210 x 297 mm).
Después de comprobar las dimensiones de la página de tu PDF, los siguientes pasos lógicos son el redimensionamiento y el recorte. Redimensionar cambia el tamaño de toda la página del PDF, por ejemplo, convirtiendo A4 a Carta escalando el contenido hacia arriba o hacia abajo. Recortar páginas PDF elimina los bordes no deseados (márgenes blancos, marcas de corte) sin escalar el contenido.
Método del navegador web: Comprobación a través de Chrome/Edge
Si no tienes instalado un visor de PDF, los navegadores modernos como Google Chrome y Microsoft Edge pueden mostrar los tamaños de página de PDF sin ningún software adicional.
Cómo conocer el tamaño del papel de un PDF en un navegador:
- Abre tu archivo PDF en el navegador Chrome (o Edge).
- Haz clic en los tres puntos verticales (icono de menú) en la esquina superior derecha.
- En el menú desplegable, selecciona "Propiedades del documento".
- Comprueba el Tamaño de página junto con la orientación vertical/horizontal en el panel emergente.
❌ Limitación: Para documentos de varias páginas con tamaños de página mixtos, la mayoría de los navegadores no pueden mostrar las dimensiones exactas; solo muestran "varía". En este escenario, utiliza los métodos a continuación.
¿Sin software? Usando un verificador de tamaño de página de PDF en línea
Para los usuarios que prefieren evitar por completo el software de escritorio, o que necesitan una solución rápida multiplataforma, las herramientas de PDF en línea son una excelente alternativa. Estos analizadores basados en web suelen escanear todo el documento e identificar tamaños de página de PDF mixtos en segundos.
Pasos para comprobar el tamaño de página de un PDF en línea:
- Abre un verificador de tamaño de página de PDF gratuito y de confianza (por ejemplo, Analizador de Dimensiones de Página de SwiftPDFLab)
- Sube tu archivo PDF mediante arrastrar y soltar o cargándolo desde el explorador de archivos.
- La plataforma analizará todas las páginas y mostrará especificaciones detalladas:
- Número de páginas
- Dimensiones de la página (en pulgadas, mm o puntos; puedes cambiar las unidades)
- Orientación (vertical/horizontal)
- Clasificación del tamaño estándar (por ejemplo, "A4", "Carta", "Oficio")
- Un indicador si el documento tiene tamaños de página mixtos
- Opcional: Exporta la información de la página como un archivo CSV para fines de documentación.
Recordatorio de privacidad: Nunca subas documentos PDF confidenciales o sensibles a herramientas en línea públicas para evitar fugas de datos.
Automatiza con código: Comprueba el tamaño de página de un PDF con C#
Si trabajas con un gran número de PDFs o necesitas integrar la detección del tamaño de página en un flujo de trabajo automatizado, usar una biblioteca .NET como Free Spire.PDF es el enfoque más eficiente.
¿Por qué usar este método?
- Puedes escanear todas las páginas al instante.
- Obtén dimensiones en puntos, pulgadas, cm o píxeles.
- Funciona en servidores (no requiere GUI).
- Biblioteca gratuita sin marcas de agua para operaciones básicas (límite de 10 páginas).
Código C# para obtener el tamaño de página de un PDF
Cada PDF almacena internamente las dimensiones de la página en puntos (1 punto = 1/72 de pulgada). El siguiente código carga un PDF e imprime el ancho y alto de cada página en puntos.
using System;
using Spire.Pdf;
namespace GetPDFPageSize_Points
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("SamplePDF.pdf");
// Recorre cada página del PDF
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
float widthPt = page.Size.Width;
float heightPt = page.Size.Height;
Console.WriteLine($"Página {i+1}: {widthPt} pt × {heightPt} pt");
}
Console.ReadKey();
}
}
}
Salida:
Convertir puntos a otras unidades
Los puntos son técnicos pero no siempre fáciles de usar. Para presentar las dimensiones en pulgadas, centímetros o píxeles, usa PdfUnitConvertor para cambiar las unidades de medida
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// Convertir a pulgadas
float inchW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// Convertir a centímetros
float cmW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float cmH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// Convertir a píxeles
float pxW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pxH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
Más allá de las dimensiones de la página, también puedes necesitar detectar la orientación y el ángulo de rotación de la página, información especialmente útil al procesar documentos escaneados o al enderezar automáticamente páginas PDF.
Tabla de referencia de tamaños de página de PDF estándar
Después de comprobar el tamaño de página de tu PDF, utiliza esta tabla para identificar formatos estándar o verificar el cumplimiento de los requisitos de envío.
| Tamaño de Papel | Ancho × Alto (mm) | Ancho × Alto (pulgadas) | Ancho × Alto (puntos) | Uso Común |
|---|---|---|---|---|
| A4 | 210 × 297 mm | 8,27 × 11,69 pulgadas | 595 × 842 pt | Cartas, informes, formularios (la mayoría de los países) |
| US Letter | 216 × 279 mm | 8,5 × 11 pulgadas | 612 × 792 pt | Cartas comerciales, currículums (EE. UU., Canadá) |
| A3 | 297 × 420 mm | 11,69 × 16,54 pulgadas | 842 × 1191 pt | Diagramas, pósteres, periódicos pequeños |
| A5 | 148 × 210 mm | 5,83 × 8,27 pulgadas | 420 × 595 pt | Cuadernos, folletos, libretos |
| Legal | 216 × 356 mm | 8,5 × 14 pulgadas | 612 × 1008 pt | Contratos legales (EE. UU.) |
| Tabloide / Ledger | 279 × 432 mm | 11 × 17 pulgadas | 792 × 1224 pt | Folletos, boletines |
¿Cómo interpretar tamaños personalizados?
Si las dimensiones no coinciden con ninguna fila estándar, tu PDF utiliza un tamaño de página personalizado. Esto es común para:
- Capturas de pantalla guardadas como PDF (el tamaño coincide con la resolución de la pantalla)
- Dibujos CAD o planos arquitectónicos
- Imágenes escaneadas con márgenes recortados
Resumen
Saber cómo comprobar el tamaño de página de un PDF es una habilidad fundamental para cualquiera que trabaje con documentos digitales. Las cuatro soluciones anteriores cubren todos los escenarios de usuario: usa Adobe Reader para la verificación de archivos locales individuales, los navegadores para comprobaciones rápidas informales, las herramientas en línea para uso temporal multiplataforma y la codificación C# para la inspección automatizada masiva a nivel empresarial.
Verifica siempre las dimensiones de la página antes de imprimir o enviar un documento para evitar errores de formato, y consulta las especificaciones de papel estándar y las fórmulas de conversión para cumplir fácilmente con las reglas de envío requeridas.
Preguntas frecuentes
P: ¿Puede un solo PDF tener páginas de diferentes tamaños?
Sí, absolutamente. Un documento PDF puede contener una mezcla de diferentes tamaños y orientaciones de página. Por ejemplo, podrías tener una página de texto A4 en vertical seguida de un diagrama A3 en horizontal. Siempre es una buena idea comprobar los tamaños de página de todo el documento para evitar inconsistencias.
P: ¿Cómo compruebo si un PDF tiene tamaños de página mixtos?
- Método manual (documentos pequeños): En Adobe Acrobat Reader, desplázate por cada página para comprobar sus dimensiones. Esto es tedioso para PDFs largos.
- Método de herramienta en línea: Sube a un verificador gratuito de tamaño de página; listará los tamaños de todas las páginas al instante.
- Método de script C#: Usa el código anterior para escanear cada página y marcar las que difieren de la primera página.
P: ¿Cómo convierto entre pulgadas, mm y puntos?
Puedes usar fórmulas de conversión sencillas:
- Puntos → Pulgadas: Divide los puntos entre 72. (por ejemplo, 612 pt / 72 = 8,5 pulgadas).
- Pulgadas → Puntos: Multiplica las pulgadas por 72. (por ejemplo, 8,5 pulgadas * 72 = 612 pt).
- Pulgadas → mm: Multiplica las pulgadas por 25,4. (por ejemplo, 8,5 pulgadas * 25,4 = 215,9 mm).
- mm → Pulgadas: Divide los mm entre 25,4. (por ejemplo, 210 mm / 25,4 = 8,2677 pulgadas).
Para referencia rápida: 1 pulgada = 72 puntos = 25,4 milímetros.
P: ¿Hay alguna forma de comprobar los tamaños de página de varios PDFs a la vez (en lote)?
Sí, escribe un script C# para recorrer una carpeta, cargar cada PDF y extraer los tamaños de página. Aquí tienes un ejemplo mínimo:
string[] files = Directory.GetFiles(@"C:\PDFs\", "*.pdf");
foreach (string file in files)
{
using (PdfDocument pdf = new PdfDocument())
{
pdf.LoadFromFile(file);
Console.WriteLine($"{Path.GetFileName(file)}: {pdf.Pages[0].Size.Width} x {pdf.Pages[0].Size.Height} pts");
}
}
Ver también
- Cómo extraer páginas de un PDF gratis — Sin necesidad de Adobe
- Las 4 mejores formas de rotar PDF gratis: en línea, sin conexión y Python
- Cómo comprimir un PDF: Las mejores herramientas para hacer los PDF más pequeños
- C#/VB.NET: Cambiar el tamaño de página de PDF
- Python: Cambiar u obtener el tamaño de página de PDF
So überprüfen Sie die Seitengröße einer PDF-Datei: 4 kostenlose einfache Methoden
Inhaltsverzeichnis
- Warum die Kenntnis der PDF-Seitengröße wichtig ist
- Die einfachste Methode – Verwendung von Adobe Acrobat Reader
- Webbrowser-Methode – Überprüfung über Chrome/Edge
- Keine Software? Verwendung eines Online-Prüfers für PDF-Seitengrößen
- Automatisieren mit Code – Überprüfung der PDF-Seitengröße über C#
- Referenztabelle für Standard-PDF-Seitengrößen
- FAQs
Die Überprüfung der Seitengröße von PDFs ist für Büroangestellte, Grafikdesigner und Druckprofis gleichermaßen eine wesentliche tägliche Aufgabe. Falsche Seitenabmessungen können zu abgeschnittenem Inhalt, verzerrten Layouts und sogar zur automatischen Ablehnung offizieller Dokumenteneinreichungen führen.
Von schnellen Einzelprüfungen einzelner PDFs bis hin zur groß angelegten Masseninspektion Hunderter von Dokumenten erfordern unterschiedliche Anwendungsszenarien maßgeschneiderte Lösungen. Dieser Artikel führt Sie durch die Überprüfung der PDF-Seitengröße mit 4 schnellen und kostenlosen Tools. Es ist keine kostenpflichtige Software erforderlich, und am Ende müssen Sie die Abmessungen eines PDFs nie wieder erraten.
- Warum die Kenntnis der PDF-Seitengröße wichtig ist
- Die einfachste Methode – Verwendung von Adobe Acrobat Reader
- Webbrowser-Methode – Überprüfung über Chrome/Edge
- Keine Software? Verwendung eines Online-Prüfers für PDF-Seitengrößen
- Automatisieren mit Code – Überprüfung der PDF-Seitengröße über C#
- Referenztabelle für Standard-PDF-Seitengrößen
- FAQs
Warum die Kenntnis der PDF-Seitengröße wichtig ist
Die Überprüfung der genauen Abmessungen einer PDF-Seite ist aus mehreren Gründen entscheidend:
- Professioneller Druck: Drucker benötigen genaue Spezifikationen. Eine falsche Seitengröße kann zu abgeschnittenem Text, falsch ausgerichteten Rändern und abgelehnten Druckaufträgen führen.
- Formulareinreichungen: Viele offizielle Formulare und Anträge erfordern eine bestimmte Papiergröße (z. B. Letter oder A4). Die Verwendung der falschen Größe könnte zur automatischen Ablehnung führen.
- Design und Layout: Designer müssen sicherstellen, dass die Elemente perfekt in die Seitenränder passen.
- Dateikonsistenz: Ein PDF-Dokument kann Seiten mit gemischten Größen enthalten. Die Überprüfung stellt ein einheitliches und professionelles Endergebnis sicher.
⚠️ Hinweis: Verwechseln Sie nicht die Seitengröße mit der Dateigröße. Sie sind nicht miteinander verbunden.
- Seitengröße = physische Breite & Höhe (z. B. 8,5"×11", 210×297 mm).
- Dateigröße = Speicherplatz auf der Festplatte (z. B. 2,5 MB).
Die einfachste Methode – Verwendung von Adobe Acrobat Reader
Adobe Acrobat Reader ist ein beliebter kostenloser PDF-Betrachter. Er liefert präzise Messungen der Seitengröße und funktioniert mit allen PDF-Dateien, einschließlich solcher mit benutzerdefinierten oder nicht standardmäßigen Abmessungen.
Hier ist der schnellste Weg, die Seitengröße eines PDFs zu ermitteln:
- Öffnen Sie Ihre Ziel-PDF-Datei mit Adobe Acrobat Reader.
- Gehen Sie zu Datei > Eigenschaften (oder verwenden Sie einfach die Tastenkombination Strg+D unter Windows).
- Klicken Sie im Dialogfeld Dokumenteigenschaften auf die Registerkarte Beschreibung.
- Scrollen Sie nach unten, um das Feld Seitengröße zu finden. Es zeigt die genauen Abmessungen an (z. B. 8,5 x 11 Zoll / 210 x 297 mm).
Nachdem Sie die Seitenabmessungen Ihres PDFs überprüft haben, sind die nächsten logischen Schritte das Ändern der Größe und das Zuschneiden. Das Ändern der Größe ändert die gesamte PDF-Seitengröße – z. B. die Umwandlung von A4 in Letter durch Skalierung des Inhalts nach oben oder unten. Das Zuschneiden von PDF-Seiten entfernt unerwünschte Ränder (weiße Ränder, Schnittmarken), ohne den Inhalt zu skalieren.
Webbrowser-Methode – Überprüfung über Chrome/Edge
Wenn Sie keinen PDF-Betrachter installiert haben, können moderne Browser wie Google Chrome und Microsoft Edge PDF-Seitengrößen ohne zusätzliche Software anzeigen.
So ermitteln Sie die Papiergröße eines PDFs im Browser:
- Öffnen Sie Ihre PDF-Datei im Chrome- (oder Edge-) Browser.
- Klicken Sie auf die drei vertikalen Punkte (Menüsymbol) in der oberen rechten Ecke.
- Wählen Sie im Dropdown-Menü „Dokumenteigenschaften“ aus.
- Überprüfen Sie die Seitengröße sowie die Ausrichtung im Hoch- oder Querformat im Popup-Fenster.
❌ Einschränkung: Bei mehrseitigen Dokumenten mit gemischten Seitengrößen können die meisten Browser keine genauen Abmessungen anzeigen – sie zeigen nur „variiert“ an. Verwenden Sie in diesem Fall die unten stehenden Methoden.
Keine Software? Verwendung eines Online-Prüfers für PDF-Seitengrößen
Für Benutzer, die Desktop-Software vollständig vermeiden möchten oder eine schnelle plattformübergreifende Lösung benötigen, sind Online-PDF-Tools eine ausgezeichnete Alternative. Diese webbasierten Analyseprogramme scannen normalerweise das gesamte Dokument und identifizieren gemischte PDF-Seitengrößen in Sekundenschnelle.
Schritte zur Online-Überprüfung der PDF-Seitengröße:
- Öffnen Sie einen vertrauenswürdigen kostenlosen Online-Prüfer für PDF-Seitengrößen (z. B. SwiftPDFLabs Seitenabmessungsanalysator)
- Laden Sie Ihre PDF-Datei per Drag-and-Drop oder über den Dateibrowser hoch.
- Die Plattform analysiert alle Seiten und gibt detaillierte Spezifikationen aus:
- Anzahl der Seiten
- Seitenabmessungen (in Zoll, mm oder Punkten – Sie können die Einheiten wechseln)
- Ausrichtung (Hoch- oder Querformat)
- Klassifizierung der Standardgröße (z. B. „A4“, „Letter“, „Legal“)
- Ein Indikator, ob das Dokument gemischte Seitengrößen hat
- Optional: Exportieren Sie die Seiteninformationen als CSV-Datei zu Dokumentationszwecken.
Datenschutzhinweis: Laden Sie niemals vertrauliche oder sensible PDF-Dokumente auf öffentliche Online-Tools hoch, um Datenlecks zu vermeiden.
Automatisieren mit Code – Überprüfung der PDF-Seitengröße über C#
Wenn Sie mit großen Mengen von PDFs arbeiten oder die Erkennung von Seitengrößen in einen automatisierten Workflow integrieren müssen, ist die Verwendung einer .NET-Bibliothek wie Free Spire.PDF der effizienteste Ansatz.
Warum diese Methode verwenden?
- Sie können alle Seiten sofort scannen.
- Erhalten Sie Abmessungen in Punkten, Zoll, cm oder Pixeln.
- Funktioniert auf Servern (keine GUI erforderlich).
- Kostenlose Bibliothek ohne Wasserzeichen für grundlegende Operationen (10-Seiten-Limit).
C#-Code zum Abrufen der PDF-Seitengröße
Jedes PDF speichert intern Seitenabmessungen in Punkten (1 Punkt = 1/72 Zoll). Der folgende Code lädt ein PDF und gibt die Breite und Höhe jeder Seite in Punkten aus.
using System;
using Spire.Pdf;
namespace GetPDFPageSize_Points
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("SamplePDF.pdf");
// Durchlaufen jeder PDF-Seite
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
float widthPt = page.Size.Width;
float heightPt = page.Size.Height;
Console.WriteLine($"Seite {i+1}: {widthPt} pt × {heightPt} pt");
}
Console.ReadKey();
}
}
}
Ausgabe:
Konvertierung von Punkten in andere Einheiten
Punkte sind technisch, aber nicht immer benutzerfreundlich. Um Abmessungen in Zoll, Zentimetern oder Pixeln darzustellen, verwenden Sie PdfUnitConvertor, um die Maßeinheiten zu wechseln
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// Konvertieren in Zoll
float inchW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// Konvertieren in Zentimeter
float cmW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float cmH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// Konvertieren in Pixel
float pxW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pxH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
Über die reinen Seitenabmessungen hinaus müssen Sie möglicherweise auch die Seitenorientierung und den Rotationswinkel erkennen – Informationen, die besonders nützlich sind, wenn gescannte Dokumente verarbeitet oder PDF-Seiten automatisch begradigt werden.
Referenztabelle für Standard-PDF-Seitengrößen
Nachdem Sie die PDF-Seitengröße überprüft haben, verwenden Sie diese Tabelle, um Standardformate zu identifizieren oder die Einhaltung von Einreichungsanforderungen zu überprüfen.
| Papierformat | Breite × Höhe (mm) | Breite × Höhe (Zoll) | Breite × Höhe (Punkte) | Häufige Verwendung |
|---|---|---|---|---|
| A4 | 210 × 297 mm | 8,27 × 11,69 Zoll | 595 × 842 pt | Briefe, Berichte, Formulare (die meisten Länder) |
| US Letter | 216 × 279 mm | 8,5 × 11 Zoll | 612 × 792 pt | Geschäftsbriefe, Lebensläufe (USA, Kanada) |
| A3 | 297 × 420 mm | 11,69 × 16,54 Zoll | 842 × 1191 pt | Diagramme, Poster, kleine Zeitungen |
| A5 | 148 × 210 mm | 5,83 × 8,27 Zoll | 420 × 595 pt | Notizbücher, Flyer, Broschüren |
| Legal | 216 × 356 mm | 8,5 × 14 Zoll | 612 × 1008 pt | Rechtliche Verträge (USA) |
| Tabloid / Ledger | 279 × 432 mm | 11 × 17 Zoll | 792 × 1224 pt | Broschüren, Newsletter |
Wie interpretiert man benutzerdefinierte Größen?
Wenn die Abmessungen keiner Standardzeile entsprechen, verwendet Ihr PDF eine benutzerdefinierte Seitengröße. Dies ist üblich für:
- Als PDF gespeicherte Screenshots (Größe entspricht der Bildschirmauflösung)
- CAD-Zeichnungen oder architektonische Pläne
- Gescannte Bilder mit beschnittenen Rändern
Zusammenfassung
Zu wissen, wie man die PDF-Seitengröße überprüft, ist eine grundlegende Fähigkeit für jeden, der mit digitalen Dokumenten arbeitet. Die oben genannten vier Lösungen decken alle Benutzerszenarien ab: Verwenden Sie Adobe Reader für die Überprüfung einzelner lokaler Dateien, Browser für schnelle Gelegenheitsprüfungen, Online-Tools für die temporäre geräteübergreifende Nutzung und C#-Programmierung für die automatisierte Masseninspektion auf Unternehmensebene.
Überprüfen Sie immer die Seitenabmessungen, bevor Sie drucken oder ein Dokument einreichen, um Formatierungsfehler zu vermeiden, und konsultieren Sie Standardpapierformate und Konvertierungsformeln, um die erforderlichen Einreichungsregeln mühelos einzuhalten.
FAQs
F: Kann ein einzelnes PDF Seiten unterschiedlicher Größe haben?
Ja, absolut. Ein PDF-Dokument kann eine Mischung aus verschiedenen Seitengrößen und Ausrichtungen enthalten. Sie könnten zum Beispiel eine Textseite im Hochformat A4 gefolgt von einem Diagramm im Querformat A3 haben. Es ist immer ratsam, die Seitengrößen des gesamten Dokuments zu überprüfen, um Inkonsistenzen zu vermeiden.
F: Wie überprüfe ich, ob ein PDF gemischte Seitengrößen hat?
- Manuelle Methode (kleine Dokumente): Scrollen Sie in Adobe Acrobat Reader durch jede Seite, um ihre Abmessungen zu überprüfen. Dies ist bei langen PDFs mühsam.
- Online-Tool-Methode: Laden Sie es auf einen kostenlosen Prüfer für Seitengrößen hoch; er listet die Größen für alle Seiten sofort auf.
- C#-Skript-Methode: Verwenden Sie den obigen Code, um jede Seite zu scannen und alle zu kennzeichnen, die sich von der ersten Seite unterscheiden.
F: Wie konvertiere ich zwischen Zoll, mm und Punkten?
Sie können einfache Konvertierungsformeln verwenden:
- Punkte → Zoll: Teilen Sie Punkte durch 72. (z. B. 612 pt / 72 = 8,5 Zoll).
- Zoll → Punkte: Multiplizieren Sie Zoll mit 72. (z. B. 8,5 Zoll * 72 = 612 pt).
- Zoll → mm: Multiplizieren Sie Zoll mit 25,4. (z. B. 8,5 Zoll * 25,4 = 215,9 mm).
- mm → Zoll: Teilen Sie mm durch 25,4. (z. B. 210 mm / 25,4 = 8,2677 Zoll).
Zur schnellen Referenz: 1 Zoll = 72 Punkte = 25,4 Millimeter.
F: Gibt es eine Möglichkeit, die Seitengrößen mehrerer PDFs gleichzeitig zu überprüfen (Massenverarbeitung)?
Ja, schreiben Sie ein C#-Skript, um einen Ordner zu durchlaufen, jede PDF-Datei zu laden und die Seitengrößen zu extrahieren. Hier ist ein minimales Beispiel:
string[] files = Directory.GetFiles(@"C:\PDFs\", "*.pdf");
foreach (string file in files)
{
using (PdfDocument pdf = new PdfDocument())
{
pdf.LoadFromFile(file);
Console.WriteLine($"{Path.GetFileName(file)}: {pdf.Pages[0].Size.Width} x {pdf.Pages[0].Size.Height} pts");
}
}
Siehe auch
- So extrahieren Sie Seiten aus einem PDF kostenlos – kein Adobe erforderlich
- 4 beste Möglichkeiten, PDFs kostenlos zu drehen: Online, Offline & Python
- So komprimieren Sie ein PDF: Die besten Tools, um PDFs kleiner zu machen
- C#/VB.NET: PDF-Seitengröße ändern
- Python: PDF-Seitengröße ändern oder abrufen
Как проверить размер страницы PDF: 4 бесплатных простых способа
Содержание
- Почему важно знать размер страницы PDF
- Самый простой способ — использование Adobe Acrobat Reader
- Способ через веб-браузер — проверка через Chrome/Edge
- Нет программ? Используйте онлайн-проверку размера страницы PDF
- Автоматизация с помощью кода — проверка размера страницы PDF через C#
- Справочная таблица стандартных размеров страниц PDF
- Часто задаваемые вопросы
Проверка размера страницы PDF является важной ежедневной операцией для офисных работников, графических дизайнеров и специалистов по печати. Неправильные размеры страниц могут привести к обрезке содержимого, искажению макетов и даже автоматическому отклонению официальных документов.
От быстрой разовой проверки отдельных PDF-файлов до масштабной проверки сотен документов — различные сценарии использования требуют индивидуальных решений. Эта статья проведет вас через как проверить размер страницы PDF с помощью 4 быстрых и бесплатных инструментов. Платное программное обеспечение не требуется, и к концу вы больше никогда не будете угадывать размеры PDF.
- Почему важно знать размер страницы PDF
- Самый простой способ — использование Adobe Acrobat Reader
- Способ через веб-браузер — проверка через Chrome/Edge
- Нет программ? Используйте онлайн-проверку размера страницы PDF
- Автоматизация с помощью кода — проверка размера страницы PDF через C#
- Справочная таблица стандартных размеров страниц PDF
- Часто задаваемые вопросы
Почему важно знать размер страницы PDF
Проверка точных размеров страницы PDF имеет решающее значение по нескольким причинам:
- Профессиональная печать: типографии требуют точных спецификаций. Неправильный размер страницы может привести к обрезке текста, смещению полей и отклонению печатных заданий.
- Подача форм: многие официальные формы и заявления требуют определенного размера бумаги (например, Letter или A4). Использование неправильного размера может привести к автоматическому отклонению.
- Дизайн и макет: дизайнерам необходимо убедиться, что элементы идеально вписываются в границы страницы.
- Согласованность файлов: документ PDF может содержать страницы разных размеров. Их проверка гарантирует единообразный и профессиональный конечный результат.
⚠️ Примечание: Не путайте размер страницы с размером файла. Они не связаны.
- Размер страницы = физическая ширина и высота (например, 8,5 × 11 дюймов, 210 × 297 мм).
- Размер файла = объем дискового пространства (например, 2,5 МБ).
Самый простой способ — использование Adobe Acrobat Reader
Adobe Acrobat Reader — популярный бесплатный просмотрщик PDF. Он обеспечивает точные измерения размера страницы и работает со всеми файлами PDF, включая файлы с пользовательскими или нестандартными размерами.
Вот самый быстрый способ узнать размер страницы PDF:
- Откройте целевой файл PDF в программе Adobe Acrobat Reader.
- Перейдите в меню Файл > Свойства (или просто используйте сочетание клавиш Ctrl+D в Windows).
- В диалоговом окне Свойства документа нажмите на вкладку Описание.
- Прокрутите вниз, чтобы найти поле Размер страницы. Оно отобразит точные размеры (например, 8,5 x 11 дюймов / 210 x 297 мм).
После проверки размеров страниц вашего PDF, следующими логическими шагами являются изменение размера и обрезка. Изменение размера изменяет размер всей страницы PDF — например, преобразование A4 в Letter путем масштабирования содержимого вверх или вниз. Обрезка страниц PDF удаляет ненужные края (белые поля, метки обрезки) без масштабирования содержимого.
Способ через веб-браузер — проверка через Chrome/Edge
Если у вас не установлен просмотрщик PDF, современные браузеры, такие как Google Chrome и Microsoft Edge, могут отображать размеры страниц PDF без какого-либо дополнительного программного обеспечения.
Как узнать размер бумаги PDF в браузере:
- Откройте файл PDF в браузере Chrome (или Edge).
- Нажмите на значок трех вертикальных точек (меню) в правом верхнем углу.
- В выпадающем меню выберите «Свойства документа».
- Проверьте Размер страницы, а также ориентацию (портретную/альбомную) во всплывающей панели.
❌ Ограничение: Для многостраничных документов с разными размерами страниц большинство браузеров не могут отображать точные размеры — они показывают только «разные». В этом случае используйте приведенные ниже методы.
Нет программ? Используйте онлайн-проверку размера страницы PDF
Для пользователей, которые предпочитают полностью избегать настольного программного обеспечения или нуждаются в быстром кроссплатформенном решении, онлайн-инструменты для работы с PDF являются отличной альтернативой. Эти веб-анализаторы обычно сканируют весь документ и за секунды определяют смешанные размеры страниц PDF.
Шаги для проверки размера страницы PDF онлайн:
- Откройте надежный бесплатный онлайн-инструмент для проверки размера страниц PDF (например, Анализатор размеров страниц SwiftPDFLab)
- Загрузите файл PDF с помощью перетаскивания или через браузер файлов.
- Платформа проанализирует все страницы и выдаст подробные характеристики:
- Количество страниц
- Размеры страниц (в дюймах, мм или пунктах — можно переключать единицы измерения)
- Ориентация (портретная/альбомная)
- Классификация стандартного размера (например, «A4», «Letter», «Legal»)
- Индикатор наличия смешанных размеров страниц в документе
- Необязательно: Экспортируйте информацию о страницах в виде CSV-файла для документирования.
Напоминание о конфиденциальности: Никогда не загружайте конфиденциальные или секретные документы PDF в общедоступные онлайн-инструменты, чтобы предотвратить утечку данных.
Автоматизация с помощью кода — проверка размера страницы PDF через C#
Если вы работаете с большим количеством PDF-файлов или вам нужно интегрировать определение размера страницы в автоматизированный рабочий процесс, использование библиотеки .NET, такой как Free Spire.PDF, является наиболее эффективным подходом.
Зачем использовать этот метод?
- Вы можете мгновенно сканировать все страницы.
- Получайте размеры в пунктах, дюймах, см или пикселях.
- Работает на серверах (GUI не требуется).
- Бесплатная библиотека без водяных знаков для основных операций (ограничение 10 страниц).
Код C# для получения размера страницы PDF
Каждый PDF внутренне хранит размеры страниц в пунктах (1 пункт = 1/72 дюйма). Следующий код загружает PDF и выводит ширину и высоту каждой страницы в пунктах.
using System;
using Spire.Pdf;
namespace GetPDFPageSize_Points
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("SamplePDF.pdf");
// Перебираем каждую страницу PDF
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
float widthPt = page.Size.Width;
float heightPt = page.Size.Height;
Console.WriteLine($"Страница {i+1}: {widthPt} пт × {heightPt} пт");
}
Console.ReadKey();
}
}
}
Вывод:
Преобразование пунктов в другие единицы измерения
Пункты — это техническая единица, но не всегда удобная для пользователя. Чтобы представить размеры в дюймах, сантиметрах или пикселях, используйте PdfUnitConvertor для смены единиц измерения.
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
// Конвертировать в дюймы
float inchW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
float inchH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch);
// Конвертировать в сантиметры
float cmW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
float cmH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter);
// Конвертировать в пиксели
float pxW = unitCvtr.ConvertUnits(widthPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
float pxH = unitCvtr.ConvertUnits(heightPt, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel);
Помимо размеров страниц, вам также может потребоваться определить ориентацию страницы и угол поворота — информация, которая особенно полезна при обработке отсканированных документов или автоматическом выпрямлении страниц PDF.
Справочная таблица стандартных размеров страниц PDF
После проверки размера страницы PDF используйте эту таблицу, чтобы определить стандартные форматы или проверить соответствие требованиям подачи документов.
| Размер бумаги | Ширина × Высота (мм) | Ширина × Высота (дюймы) | Ширина × Высота (пункты) | Общее использование |
|---|---|---|---|---|
| A4 | 210 × 297 мм | 8,27 × 11,69 дюйма | 595 × 842 пт | Письма, отчеты, формы (большинство стран) |
| US Letter | 216 × 279 мм | 8,5 × 11 дюймов | 612 × 792 пт | Деловые письма, резюме (США, Канада) |
| A3 | 297 × 420 мм | 11,69 × 16,54 дюйма | 842 × 1191 пт | Диаграммы, плакаты, небольшие газеты |
| A5 | 148 × 210 мм | 5,83 × 8,27 дюйма | 420 × 595 пт | Блокноты, листовки, буклеты |
| Legal | 216 × 356 мм | 8,5 × 14 дюймов | 612 × 1008 пт | Юридические контракты (США) |
| Tabloid / Ledger | 279 × 432 мм | 11 × 17 дюймов | 792 × 1224 пт | Брошюры, информационные бюллетени |
Как интерпретировать пользовательские размеры?
Если размеры не соответствуют ни одной стандартной строке, ваш PDF использует пользовательский размер страницы. Это часто встречается в:
- Скриншоты, сохраненные как PDF (размер соответствует разрешению экрана)
- Чертежи САПР или архитектурные планы
- Отсканированные изображения с обрезанными полями
Заключение
Знание того, как проверить размер страницы PDF, является фундаментальным навыком для всех, кто работает с цифровыми документами. Вышеупомянутые четыре решения охватывают все сценарии пользователей: используйте Adobe Reader для проверки одного локального файла, браузеры для быстрых случайных проверок, онлайн-инструменты для временного использования на разных устройствах и программирование на C# для массовой автоматизированной проверки корпоративного уровня.
Всегда проверяйте размеры страниц перед печатью или подачей документов, чтобы избежать ошибок форматирования, и обращайтесь к стандартным спецификациям бумаги и формулам преобразования, чтобы без труда соответствовать требуемым правилам подачи.
Часто задаваемые вопросы
В: Может ли один PDF-файл содержать страницы разных размеров?
Да, абсолютно. Документ PDF может содержать смесь различных размеров страниц и ориентаций. Например, вы можете иметь текстовую страницу A4 в портретной ориентации, за которой следует диаграмма A3 в альбомной ориентации. Всегда полезно проверять размеры страниц всего документа, чтобы избежать несоответствий.
В: Как проверить, содержит ли PDF-файл страницы разных размеров?
- Ручной метод (небольшие документы): В Adobe Acrobat Reader прокрутите каждую страницу, чтобы проверить ее размеры. Это утомительно для длинных PDF-файлов.
- Метод с использованием онлайн-инструмента: Загрузите в бесплатный инструмент проверки размеров страниц; он мгновенно перечислит размеры всех страниц.
- Метод с использованием скрипта C#: Используйте приведенный выше код для сканирования каждой страницы и пометки тех, которые отличаются от первой страницы.
В: Как конвертировать между дюймами, мм и пунктами?
Вы можете использовать простые формулы преобразования:
- Пункты → Дюймы: Разделите пункты на 72. (например, 612 пт / 72 = 8,5 дюйма).
- Дюймы → Пункты: Умножьте дюймы на 72. (например, 8,5 дюйма * 72 = 612 пт).
- Дюймы → мм: Умножьте дюймы на 25,4. (например, 8,5 дюйма * 25,4 = 215,9 мм).
- мм → Дюймы: Разделите мм на 25,4. (например, 210 мм / 25,4 = 8,2677 дюйма).
Для быстрой справки: 1 дюйм = 72 пункта = 25,4 миллиметра.
В: Есть ли способ проверить размеры страниц нескольких PDF-файлов одновременно (пакетно)?
Да, напишите скрипт C#, чтобы пройти по папке, загрузить каждый PDF и извлечь размеры страниц. Вот минимальный пример:
string[] files = Directory.GetFiles(@"C:\PDFs\", "*.pdf");
foreach (string file in files)
{
using (PdfDocument pdf = new PdfDocument())
{
pdf.LoadFromFile(file);
Console.WriteLine($"{Path.GetFileName(file)}: {pdf.Pages[0].Size.Width} x {pdf.Pages[0].Size.Height} пт");
}
}