insert-a-page-in-word
Inhaltsverzeichnis

Beim Schreiben oder Bearbeiten eines Word-Dokuments müssen wir häufig eine neue Seite beginnen – sei es direkt zwischen zwei bestehenden Absätzen oder am Ende eines Abschnitts. Das wiederholte Drücken der Eingabetaste ist jedoch nur eine vorübergehende Lösung; sobald Sie den Inhalt darüber bearbeiten, kann sich das Layout leicht verschieben.
Um dieses Layout-Chaos zu vermeiden, müssen Sie wissen, wie man in Word richtig eine Seite einfügt. In dieser Anleitung führen wir Sie durch alle professionellen Methoden, um Ihrem Dokument nahtlos eine Seite hinzuzufügen, einschließlich schneller Tastenkombinationen, automatisierter Layout-Regeln und Programmier-Tricks für Entwickler. So stellen Sie sicher, dass Ihre Seiten genau dort umbrechen, wo Sie es beabsichtigen, ohne unerwartete Formatierungsänderungen.
- Einfügen einer leeren Seite in Word über die Symbolleiste
- Sofortiges Einfügen einer Seite in Word mittels Seitenumbruch
- Einfügen eines Deckblatts in Word-Dokumente
- Automatisches Einfügen von Seiten mit „Seitenumbruch davor“
- Programmgesteuertes Einfügen einer Seite in Word mit Free Spire.Doc
- FAQs
Einfügen einer leeren Seite in Word über die Symbolleiste
Wenn Sie Dokumente lieber über das Hauptmenü bearbeiten, ist das Menüband (Ribbon) die beste Methode, um eine Seite in eine Word-Datei einzufügen. Dieser Ansatz ermöglicht es Ihnen, Ihren Text genau dort zu trennen, wo Sie es möchten, und sorgt für einen reibungslosen Übergang zur nächsten Seite.
Verwenden Sie diese Option, wenn Sie eine leere Seite mitten in bestehenden Inhalten einfügen möchten, z. B. um eine frische, leere Fläche für einen neuen Abschnitt oder eine kommende Galerie zu schaffen.
- Schritt 1. Platzieren Sie Ihren Cursor genau an der Stelle, an der der neue, leere Bereich erscheinen soll.
- Schritt 2. Gehen Sie auf die Registerkarte Einfügen im oberen Menüband.
- Schritt 3. Klicken Sie in der Gruppe Seiten auf die Schaltfläche Leere Seite.
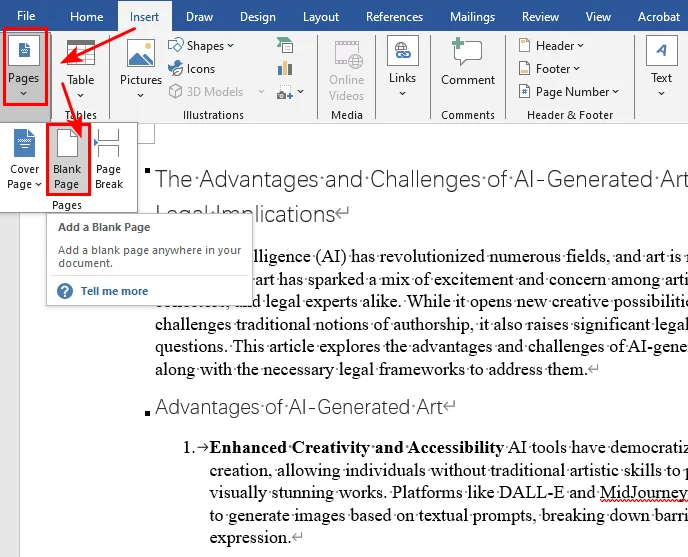
Microsoft Word fügt sofort eine saubere, leere Seite an dieser Stelle ein und schiebt den bestehenden Text auf die folgende Seite.
Sofortiges Einfügen einer Seite in Word mittels Seitenumbruch
Im Allgemeinen wird ein einzelner Seitenumbruch verwendet, um Inhalte zu trennen und eine bestimmte Überschrift oder einen Absatz an den Anfang der nächsten Seite zu schieben. Zwei aufeinanderfolgende Seitenumbrüche erzeugen normalerweise eine leere Seite zwischen Inhaltsabschnitten. Egal, ob Sie die Symbolleiste oder Tastenkombinationen bevorzugen, die Beherrschung dieser Methode hilft Ihnen, schnell leere Seiten in Word zu generieren.
Methode 1: Tastenkombination zum Einfügen eines Seitenumbruchs
Wenn Sie unter Zeitdruck stehen, ist die Verwendung einer Tastenkombination der schnellste Weg, um einen Seitenumbruch in ein Word-Dokument einzufügen.
- Schritt 1. Klicken Sie, um Ihren Cursor direkt vor den Text zu setzen, den Sie nach unten verschieben möchten.
- Schritt 2. Drücken Sie einmal Strg + Eingabetaste (Windows) oder Cmd + Return (Mac), um den Text nach unten zu schieben, oder drücken Sie die Kombination zweimal, wenn Sie direkt dort eine leere Seite einfügen möchten.
Methode 2: Einfügen eines Seitenumbruchs über das Menüband
Wenn Sie visuelle Menüs bevorzugen, können Sie genau das gleiche Ergebnis über die Hauptnavigationsleiste von Microsoft Word erzielen:
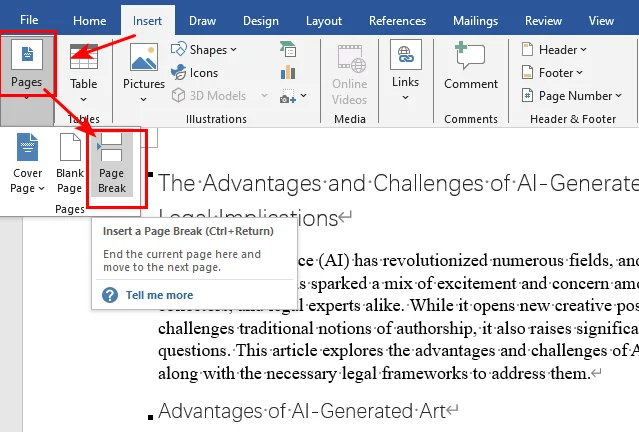
- Schritt 1. Platzieren Sie Ihren Cursor direkt vor den Text oder die Überschrift, die verschoben werden soll.
- Schritt 2. Navigieren Sie zur Registerkarte Einfügen im Menüband.
- Schritt 3. Klicken Sie in der Gruppe Seiten auf Seitenumbruch (klicken Sie zweimal darauf, wenn Sie eine vollständige leere Seite erstellen möchten).
Das könnte Sie auch interessieren: Wie man Seitenumbrüche in Word entfernt (4 einfache Methoden)
Einfügen eines Deckblatts in Word-Dokumente
Jeder professionelle Bericht, Geschäftsvorschlag oder akademische Aufsatz benötigt eine aussagekräftige Titelseite. Anstatt manuell zu formatieren, sollten Sie Word die Design- und Strukturarbeit überlassen.
Wenn Sie wissen möchten, wie man ein Deckblatt in Word einfügt, bietet die Software eine integrierte Funktion, die ein einleitendes Layout für Sie erstellt.
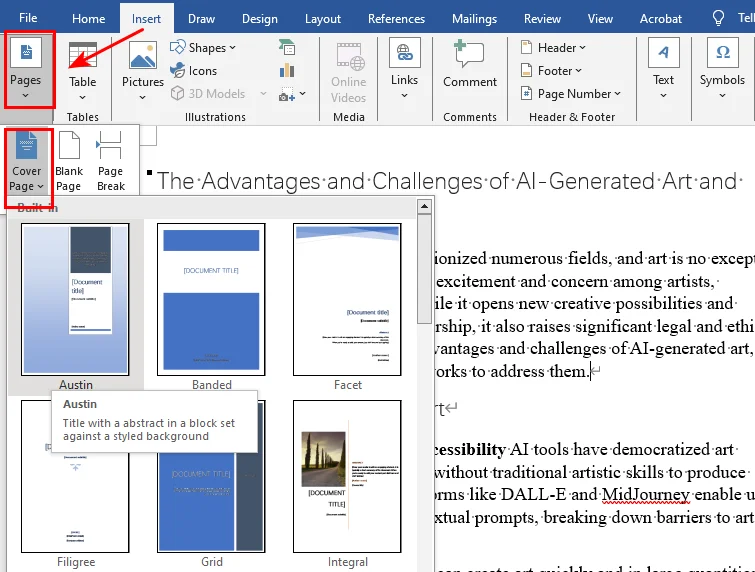
- Schritt 1. Klicken Sie an eine beliebige Stelle in Ihrem Dokument.
- Schritt 2. Gehen Sie auf die Registerkarte Einfügen im Menüband.
- Schritt 3. Klicken Sie auf Deckblatt und wählen Sie Ihr bevorzugtes Layout aus der integrierten Galerie aus.
Word behandelt Deckblätter anders als den regulären Dokumentinhalt. Wenn Sie ein integriertes Deckblatt einfügen, platziert Word es automatisch am Anfang des Dokuments und kann verhindern, dass die Seitennummerierung auf der Titelseite erscheint.
Automatisches Einfügen von Seiten mit „Seitenumbruch davor“
Diese Funktion ist besonders nützlich bei langen Berichten, Handbüchern und Büchern, bei denen jedes Kapitel auf einer neuen Seite beginnen sollte. Anstatt Seitenumbrüche manuell einzufügen, können Sie die Einstellung Seitenumbruch davor in Word verwenden, um sicherzustellen, dass bestimmte Überschriften immer auf einer neuen Seite beginnen.
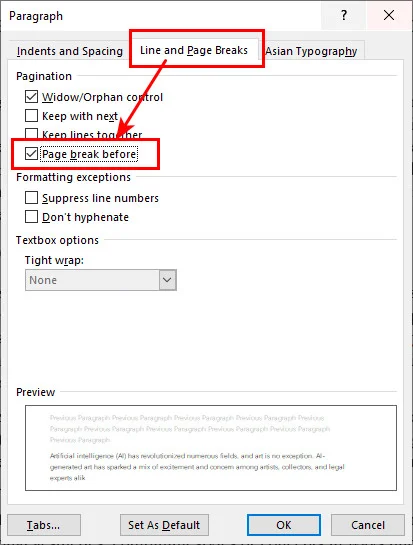
- Schritt 1. Klicken Sie mit der rechten Maustaste auf die spezifische Überschrift oder die Formatvorlage „Überschrift 1“ auf der Registerkarte „Start“ und wählen Sie Absatz.
- Schritt 2. Gehen Sie im Dialogfenster auf die Registerkarte Zeilen- und Seitenumbruch.
- Schritt 3. Aktivieren Sie das Kontrollkästchen neben Seitenumbruch davor und klicken Sie auf OK.
Jetzt erstellt Word jedes Mal, wenn Sie diese Überschriften-Formatvorlage anwenden, automatisch eine neue Seite dafür. Selbst wenn Sie Absätze in früheren Abschnitten löschen, werden Ihre Kapitel nie zusammenrücken oder falsch ausgerichtet sein.
Programmgesteuertes Einfügen einer Seite in Word mit Free Spire.Doc
Beim Erstellen von Rechnungen, Zusammenstellen monatlicher Kundenabrechnungen oder Erstellen dynamischer Verträge ist es sehr empfehlenswert, das Einfügen von Seiten in Word-Dokumente zu automatisieren, um Zeit und Mühe zu sparen. Die Verwendung von Free Spire.Doc for Python macht es einfach, diesen gesamten Prozess zu optimieren. In Anlehnung an die Technik mit zwei Umbrüchen, die wir im vorherigen Abschnitt gelernt haben, ermöglicht diese Bibliothek das Hinzufügen von Seitenumbrüchen mit der Methode AppendBreak. Durch das Einfügen von zwei aufeinanderfolgenden Seitenumbruch-Objekten direkt in einen Absatz oder Textbereich können Sie mühelos eine leere Seite in Ihrer Ausgabedatei hinzufügen, ohne Microsoft Word öffnen zu müssen.
Hier ist das Codebeispiel, das zeigt, wie man nach dem ersten Absatz eine neue Seite einfügt:
from spire.doc import *
from spire.doc.common import *
# Erstellen eines Objekts der Document-Klasse
document = Document()
# Laden einer Beispieldatei von der Festplatte
document.LoadFromFile("/input/sample.docx")
# Abrufen des ersten Abschnitts des Dokuments
section = document.Sections[0]
# Abrufen des ersten Absatzes
paragraph = section.Paragraphs[0]
# Anfügen des ersten Seitenumbruchs, um die aktuelle Seite zu beenden
paragraph.AppendBreak(BreakType.PageBreak)
# Anfügen des zweiten Seitenumbruchs, um eine leere Seite zu erstellen
paragraph.AppendBreak(BreakType.PageBreak)
# Speichern der Ergebnisdatei
document.SaveToFile("/output/InsertBlankPage.docx", FileFormat.Docx2013)
document.Close()
Unten sehen Sie eine Vorschau des Ergebnisdokuments; Sie können sehen, dass nach dem ersten Absatz eine neue Seite vorhanden ist: 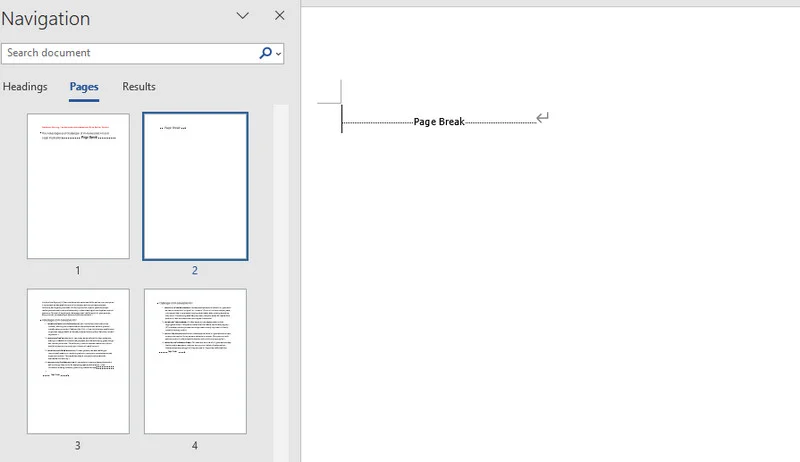
Fazit
Dieser Leitfaden deckt fünf effiziente Möglichkeiten ab, eine Seite in Word-Dokumente einzufügen, von schnellen manuellen Korrekturen in Microsoft Word bis hin zur programmgesteuerten Automatisierung mit Free Spire.Doc for Python. Jede Methode glänzt in unterschiedlichen Szenarien: Manuelle Optionen wie leere Seiten oder Seitenumbrüche sind perfekt für einmalige Bearbeitungen, während Free Spire.Doc die ideale Wahl für die Integration von Arbeitsabläufen und die Verarbeitung großer Dateimengen ist. Durch die Wahl der geeigneten Methode für Ihr Szenario können Sie Seiten effizient einfügen und gleichzeitig ein konsistentes Dokumentlayout beibehalten.
FAQs zum Einfügen von Seiten in Word
F1: Wie füge ich eine Seite im Querformat in Word ein?
Um eine Seite im Querformat in Word einzufügen, müssen Sie diesen spezifischen Abschnitt einfach mit einem Abschnittsumbruch isolieren und dessen Ausrichtung ändern.
Platzieren Sie zuerst Ihren Cursor direkt vor den Inhalt, den Sie drehen möchten, gehen Sie auf Layout > Umbrüche > Nächste Seite und navigieren Sie dann zu Layout > Ausrichtung > Querformat. Dies ermöglicht es Ihnen, eine Seite in Word direkt zu drehen, vom Hoch- ins Querformat, ohne die Formatierung des restlichen Dokuments zu ändern.
F2: Was ist der Unterschied zwischen dem Einfügen einer leeren Seite und einem Seitenumbruch?
Eine leere Seite fügt eine unberührte leere Seite zwischen Abschnitten ein. Ein Seitenumbruch erzeugt keinen leeren Raum; er ist lediglich eine unsichtbare Formatierungsgrenze, die die aktuelle Zeile vorzeitig beendet und jeden folgenden Text direkt an den Anfang der nächsten Seite schiebt. Das Einfügen von zwei Seitenumbrüchen kann jedoch auch eine leere Seite in Word erzeugen.
F3: Warum stimmt meine Seitennummerierung nicht mehr, nachdem ich ein Deckblatt eingefügt habe?
Die integrierten Layouts von Word sind so programmiert, dass die Nummerierung auf Titelseiten ausgeblendet wird. Wenn jedoch trotzdem Nummern auf Ihrem Deckblatt erscheinen, doppelklicken Sie auf den Kopf- oder Fußzeilenbereich, um die Layout-Optionen anzuzeigen. Aktivieren Sie auf der Registerkarte Kopf- und Fußzeile im Menüband das Kontrollkästchen Erste Seite anders, damit Ihre sichtbare Nummerierung sauber ab Seite zwei beginnt.
Lesen Sie auch
5 способов вставки страницы в Word (вручную и с помощью автоматизации Python)
Оглавление
- Вставка пустой страницы в Word с помощью панели инструментов
- Мгновенная вставка страницы в Word с помощью разрыва страницы
- Вставка титульной страницы в документы Word
- Автоматическая вставка страницы с помощью функции «Разрыв страницы перед»
- Программная вставка страницы в Word через Free Spire.Doc
- Часто задаваемые вопросы
При написании или редактировании документа Word нам часто требуется начать новую страницу — будь то прямо между двумя существующими абзацами или в самом конце раздела. Однако многократное нажатие клавиши Enter — это лишь временное решение; как только вы отредактируете текст выше, верстка может легко «поехать».
Чтобы избежать беспорядка в макете, необходимо знать, как правильно вставлять страницу в Word. В этом руководстве мы расскажем обо всех профессиональных методах добавления страницы в документ, включая быстрые клавиши, правила автоматической верстки и приемы программирования, которые гарантируют, что страницы будут разделены именно там, где вам нужно, без неожиданных изменений форматирования.
- Вставка пустой страницы в Word с помощью панели инструментов
- Мгновенная вставка страницы в Word с помощью разрыва страницы
- Вставка титульной страницы в документы Word
- Автоматическая вставка страницы с помощью функции «Разрыв страницы перед»
- Программная вставка страницы в Word через Free Spire.Doc
- Часто задаваемые вопросы
Как вставить пустую страницу в Word с помощью панели инструментов
Если вы предпочитаете редактировать документы с помощью главного меню, лента (Ribbon) — лучший способ добавить страницу в файл Word. Этот подход позволяет разделить текст именно там, где вы хотите, обеспечивая плавный и аккуратный переход на следующую страницу.
Используйте этот вариант, если хотите вставить пустую страницу в документ Word прямо посреди существующего контента, например, чтобы создать чистое пространство для нового раздела или галереи.
- Шаг 1. Установите курсор именно в то место, где должно появиться новое пустое пространство.
- Шаг 2. Перейдите на вкладку Вставка (Insert) на верхней ленте.
- Шаг 3. Нажмите кнопку Пустая страница (Blank Page) в группе Страницы (Pages).
Microsoft Word мгновенно вставит чистую пустую страницу в документ в указанном месте, переместив существующий текст на следующую страницу.
Как мгновенно вставить страницу в Word с помощью разрыва страницы
Как правило, один разрыв страницы используется для разделения контента и переноса определенного заголовка или абзаца в начало следующей страницы. Два последовательных разрыва страницы обычно создают пустую страницу между разделами документа. Независимо от того, предпочитаете ли вы панель инструментов или сочетания клавиш, освоение этого метода поможет вам быстро создавать пустые страницы в Word.
Метод 1: Сочетание клавиш для вставки разрыва страницы
Когда сроки поджимают, использование сочетания клавиш — самый быстрый способ добавить разрыв страницы в документ Word.
- Шаг 1. Установите курсор прямо перед текстом, который нужно перенести вниз.
- Шаг 2. Нажмите Ctrl + Enter (в Windows) или Cmd + Return (на Mac) один раз, чтобы перенести текст, или дважды, если хотите вставить пустую страницу прямо в этом месте.
Метод 2: Вставка разрыва страницы через ленту меню
Если вы предпочитаете визуальные меню, вы можете добиться того же результата, используя главную панель навигации Microsoft Word:
- Шаг 1. Установите курсор прямо перед текстом или заголовком, который нужно переместить.
- Шаг 2. Перейдите на вкладку Вставка (Insert) на ленте.
- Шаг 3. Нажмите Разрыв страницы (Page Break) в группе Страницы (нажмите дважды, если хотите создать полноценную пустую страницу).
Вам может быть интересно: Как удалить разрывы страниц в Word (4 простых метода)
Как вставить титульную страницу в документы Word
Любой профессиональный отчет, бизнес-предложение или академическая работа нуждаются в качественной обложке. Вместо ручного форматирования позвольте Word взять на себя дизайн и структурную работу.
Если вы ищете способ вставки титульной страницы в Word, программа предоставляет встроенную функцию, которая создаст для вас вводный макет.
- Шаг 1. Щелкните в любом месте вашего документа.
- Шаг 2. Перейдите на вкладку Вставка (Insert) на ленте.
- Шаг 3. Нажмите Титульная страница (Cover Page) и выберите понравившийся макет из встроенной галереи.
Word обрабатывает титульные страницы иначе, чем остальной контент документа. Когда вы вставляете встроенную титульную страницу, Word автоматически помещает ее в начало документа и позволяет скрыть нумерацию страниц на титульном листе.
Автоматическая вставка страницы с помощью функции «Разрыв страницы перед»
Эта функция особенно полезна в длинных отчетах, руководствах и книгах, где каждая глава должна начинаться с новой страницы. Вместо того чтобы вставлять разрывы страниц вручную, вы можете использовать настройку Word Разрыв страницы перед (Page break before), чтобы определенные заголовки всегда начинались с новой страницы.
- Шаг 1. Щелкните правой кнопкой мыши по нужному заголовку или стилю «Заголовок 1» на вкладке «Главная» и выберите Абзац (Paragraph).
- Шаг 2. Перейдите на вкладку Положение на странице (Line and Page Breaks) в открывшемся окне.
- Шаг 3. Установите флажок рядом с пунктом С новой страницы (Page break before) и нажмите ОК.
Теперь каждый раз, когда вы применяете этот стиль заголовка, Word будет автоматически создавать для него новую страницу. Даже если вы удалите абзацы в предыдущих разделах, ваши главы никогда не «съедут» и не сместятся.
Как программно вставить страницу в Word через Free Spire.Doc
При создании счетов, формировании ежемесячных отчетов для клиентов или подготовке динамических контрактов настоятельно рекомендуется автоматизировать вставку страниц в документы Word, чтобы сэкономить время и силы. Использование Free Spire.Doc for Python позволяет легко оптимизировать весь этот процесс. Повторяя технику двойного разрыва, которую мы изучили в предыдущем разделе, эта библиотека позволяет добавлять разрывы страниц с помощью метода AppendBreak. Вставляя два последовательных объекта разрыва страницы прямо в абзац или диапазон текста, вы можете легко добавить пустую страницу в выходной файл, не открывая Microsoft Word.
Вот пример кода, показывающий, как вставить новую страницу после первого абзаца:
from spire.doc import *
from spire.doc.common import *
# Создаем объект класса Document
document = Document()
# Загружаем образец файла с диска
document.LoadFromFile("/input/sample.docx")
# Получаем первый раздел документа
section = document.Sections[0]
# Получаем первый абзац
paragraph = section.Paragraphs[0]
# Добавляем первый разрыв страницы, чтобы завершить текущую страницу
paragraph.AppendBreak(BreakType.PageBreak)
# Добавляем второй разрыв страницы, чтобы создать пустую страницу
paragraph.AppendBreak(BreakType.PageBreak)
# Сохраняем результат
document.SaveToFile("/output/InsertBlankPage.docx", FileFormat.Docx2013)
document.Close()
Ниже представлен предварительный просмотр результирующего документа, где видно, что после первого абзаца появилась новая страница:
Заключение
В этом руководстве рассмотрены пять эффективных способов вставки страницы в документы Word, от быстрых ручных исправлений в Microsoft Word до программной автоматизации с использованием Free Spire.Doc for Python. Каждый метод хорош в своих сценариях: ручные варианты, такие как вставка пустой страницы или разрыва, идеально подходят для разовых правок, в то время как Free Spire.Doc — идеальный выбор для интеграции в рабочие процессы и обработки большого объема файлов. Выбирая подходящий метод, вы сможете эффективно вставлять страницы, сохраняя при этом целостность макета документа.
Часто задаваемые вопросы о вставке страниц в Word
В1: Как вставить страницу с альбомной ориентацией в Word?
Чтобы вставить страницу с альбомной ориентацией в Word, вам просто нужно изолировать этот конкретный раздел с помощью разрыва раздела и изменить его ориентацию.
Сначала установите курсор прямо перед контентом, который нужно повернуть, перейдите в Макет > Разрывы > Следующая страница, а затем перейдите в Макет > Ориентация > Альбомная. Это позволит вам напрямую повернуть страницу в Word из книжной в альбомную, не меняя форматирование остальной части документа.
В2: В чем разница между вставкой пустой страницы и разрывом страницы?
Пустая страница добавляет нетронутую пустую страницу между разделами. Разрыв страницы не создает пустого пространства; это просто невидимая граница форматирования, которая обрывает текущую строку и переносит весь последующий текст в начало следующей страницы. Однако вставка двух разрывов страниц подряд также может создать пустую страницу в Word.
В3: Почему нумерация страниц сбивается после вставки титульной страницы?
Встроенные макеты Word запрограммированы так, чтобы скрывать нумерацию на титульных листах. Но если номера все же отображаются на обложке, дважды щелкните область верхнего или нижнего колонтитула, чтобы открыть параметры макета. На вкладке Конструктор (Header & Footer) на ленте установите флажок Особый колонтитул для первой страницы (Different First Page), чтобы нумерация начиналась со второй страницы.
Читайте также
Como imprimir vários documentos do Word de uma só vez: 6 maneiras
Índice
- Método 1: Clicar com o botão direito e imprimir no Explorador de Arquivos
- Método 2: Arrastar e soltar vários arquivos do Word via janela da fila de impressão
- Método 3: Mesclar arquivos do Word primeiro para um trabalho de impressão unificado
- Método 4: Usar uma macro do Word (VBA) para imprimir todos os documentos em uma pasta
- Método 5: Impressão em lote silenciosa com um script PowerShell
- Método 6: Imprimir documentos do Word em C# usando Spire.Doc
- Comparação rápida: Qual método de impressão em lote é o melhor para você?
- Considerações finais
- Perguntas frequentes

Imprimir dezenas de contratos, relatórios ou faturas um por um é uma perda de tempo entediante. Esteja você preparando folhetos para uma reunião, produzindo documentos legais ou simplesmente organizando a papelada do seu escritório, a capacidade de enviar uma pasta inteira de arquivos do Word para a impressora de uma só vez pode economizar horas.
Este artigo apresenta seis métodos práticos para imprimir em lote arquivos .doc e .docx — desde truques simples com o botão direito até uma solução poderosa orientada para desenvolvedores usando o Spire.Doc em C#. Escolha o que melhor se adapta ao seu fluxo de trabalho e comece a imprimir de forma mais inteligente hoje mesmo.
Visão geral dos métodos abordados:
- Método 1: Clicar com o botão direito e imprimir no Explorador de Arquivos
- Método 2: Arrastar e soltar vários arquivos do Word via janela da fila de impressão
- Método 3: Mesclar arquivos do Word primeiro para um trabalho de impressão unificado
- Método 4: Usar uma macro do Word (VBA) para imprimir todos os documentos em uma pasta
- Método 5: Impressão em lote silenciosa com um script PowerShell
- Método 6: Imprimir documentos do Word em C# usando Spire.Doc
Método 1: Clicar com o botão direito e imprimir no Explorador de Arquivos
O método mais simples não requer ferramentas extras e funciona instantaneamente em qualquer PC com Windows. É perfeito para imprimir rapidamente alguns documentos sem instalar nenhum software. Basta selecionar seus arquivos e deixar o Windows cuidar do resto.
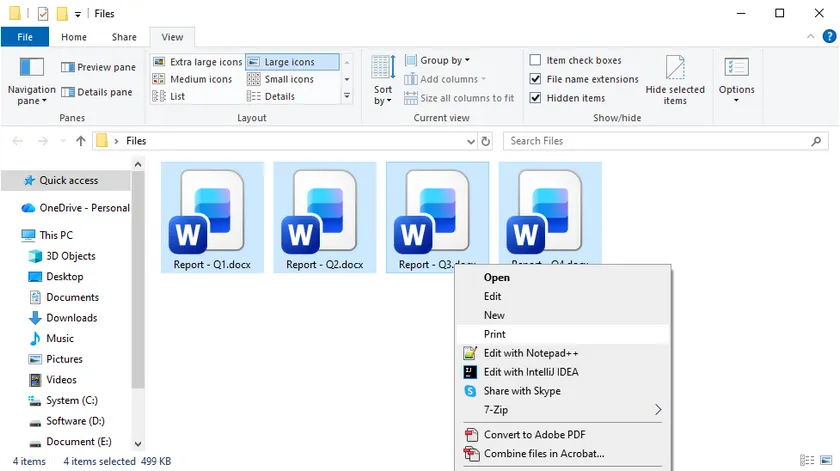
Passos:
- Abra o Explorador de Arquivos e navegue até a pasta que contém seus documentos do Word.
- Selecione os arquivos que deseja imprimir: mantenha pressionada a tecla Ctrl e clique em cada um individualmente, ou pressione Ctrl + A para selecionar todos.
- Clique com o botão direito em qualquer arquivo destacado e escolha Imprimir no menu de contexto.
O Windows abrirá automaticamente cada documento no Microsoft Word, enviará para a impressora padrão e fechará o Word ao terminar. Lembre-se de que, se as configurações de segurança do Word exibirem avisos de macro ou avisos de Modo de Exibição Protegido, o processo poderá pausar até que você os confirme manualmente. Ainda assim, para trabalhos rápidos e ocasionais, este método é imbatível.
Método 2: Arrastar e soltar vários arquivos do Word via janela da fila de impressão
Este fluxo de trabalho nativo de arrastar e soltar do Windows permite a impressão em lote de vários documentos do Word — basta arrastar seus arquivos para um atalho da impressora na área de trabalho. Essa abordagem facilita a alternância entre diferentes impressoras, tornando-a ideal para ambientes de escritório equipados com vários dispositivos de impressão.
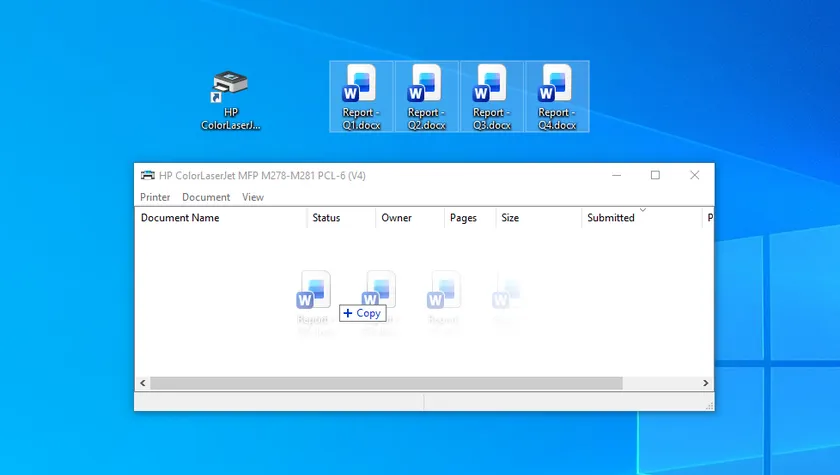
Passos:
- Pressione Win + R, digite control printers e pressione Enter para abrir a janela Dispositivos e Impressoras.
- Clique duas vezes no ícone da impressora desejada para abrir a janela da fila de impressão.
- Selecione todos os arquivos do Word desejados e arraste-os diretamente para a área em branco da janela da fila de impressão aberta.
Os arquivos preencherão a lista de trabalhos de impressão automaticamente. O Windows abrirá, imprimirá e fechará cada documento sequencialmente.
Dica profissional: Você também pode criar um atalho de impressora na área de trabalho para acesso rápido, embora arrastar para a janela da fila de impressão ofereça resultados mais confiáveis para tarefas em lote.
Método 3: Mesclar arquivos do Word primeiro para um trabalho de impressão unificado
Se você deseja que todos os arquivos separados do Word sejam impressos como um documento contínuo e ordenado, este fluxo de trabalho de mesclagem é a sua solução ideal. Ele funciona excepcionalmente bem para folhetos, relatórios formais e livretos que exigem uma sequência de páginas consistente. Mesclar arquivos antes da impressão elimina a tediosa classificação manual de páginas após a saída.
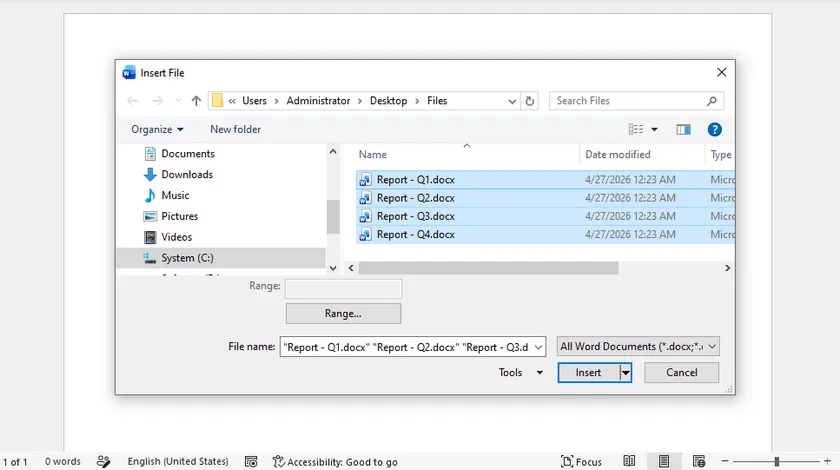
Passos:
- Abra o Microsoft Word e crie um novo documento em branco.
- Navegue até Inserir > Objeto > Texto do Arquivo (caminhos alternativos: Inserir > Arquivo ou expanda o menu suspenso Objeto em certas edições do Word).
- Destaque todos os arquivos DOCX a serem mesclados e clique em Inserir. Os arquivos serão montados seguindo a ordem selecionada.
- Pressione Ctrl + P para abrir o painel de impressão. Selecione sua impressora física ou Microsoft Print to PDF e confirme a impressão.
Você receberá um documento coeso com fluxo de página ininterrupto. Embora a mesclagem leve um pouco mais de tempo, ela evita páginas fora de ordem e elimina a colação manual — ideal para documentos encadernados e folhetos impressos.
Método 4: Usar uma macro do Word (VBA) para imprimir todos os documentos em uma pasta
Se você imprime frequentemente lotes de documentos da mesma pasta, uma simples macro VBA pode automatizar totalmente o processo. Este método é executado diretamente no Microsoft Word, não requer software extra e pode ser configurado para impressão com um clique. É uma ferramenta de automação integrada ideal para tarefas de impressão regulares e repetidas.
Passos:
- Abra o Microsoft Word e pressione Alt + F11 para abrir o editor VBA.
- Vá para Inserir > Módulo e cole o código VBA pronto para uso fornecido abaixo.
- Substitua o caminho da pasta no código pelo seu próprio diretório.
- Pressione F5 para executar a macro ou atribua-a à Barra de Ferramentas de Acesso Rápido para impressão com um clique.
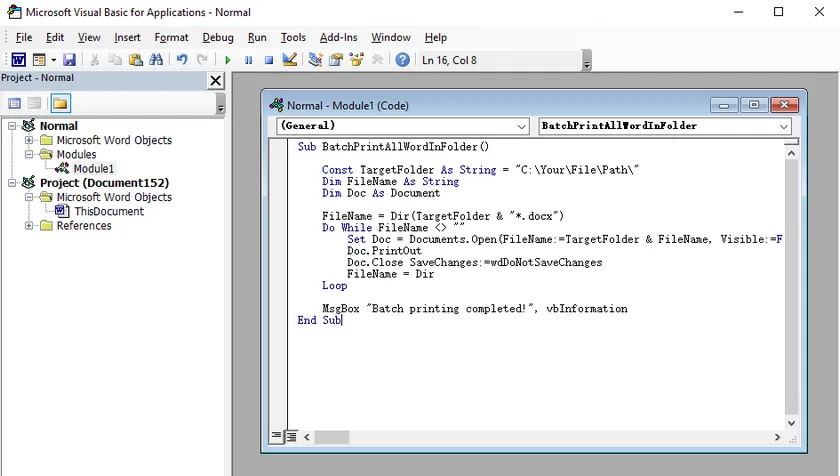
Código VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Seu\Caminho\De\Arquivo\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Impressão em lote concluída!", vbInformation
End Sub
Este método imprime arquivos silenciosamente em segundo plano sem abrir janelas. Os únicos requisitos são habilitar macros e ter o Word instalado — perfeito para uso pessoal ou de escritório confiável.
Método 5: Impressão em lote silenciosa com um script PowerShell
PowerShell oferece uma maneira rápida, leve e baseada em script para imprimir vários documentos do Word em segundo plano — sem janelas, sem pop-ups e sem interação manual. Este método é ideal para usuários que desejam impressão totalmente automatizada e pode até ser agendado com o Agendador de Tarefas do Windows para trabalhos cronometrados automaticamente.
Passos:
- Abra o PowerShell no Menu Iniciar (não são necessários direitos de administrador para impressão básica).
- Copie e cole o script de impressão em lote simples fornecido abaixo.
- Altere o valor
$folderPathpara a pasta de documentos de destino. - Execute o script. O Word será executado silenciosamente em segundo plano, imprimirá todos os seus documentos automaticamente e fechará corretamente ao terminar.
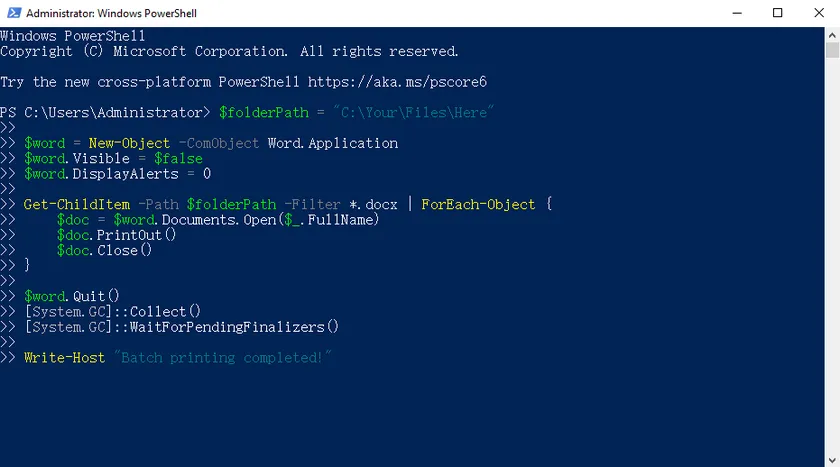
Script PowerShell:
$folderPath = "C:\Seus\Arquivos\Aqui"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Impressão em lote concluída!"
Este método funciona sem software extra, suporta todos os formatos do Word e oferece impressão em lote silenciosa e confiável para uso pessoal e de escritório.
Método 6: Imprimir documentos do Word em C# usando Spire.Doc
Quando você precisa de uma solução de impressão em lote de alto desempenho e totalmente automatizada que seja executada em um servidor sem o Microsoft Office, o Spire.Doc for .NET é a biblioteca ideal. Ele oferece controle programático completo sobre a impressão de documentos, tornando-o ideal para aplicativos da web, serviços em segundo plano ou sistemas de gerenciamento de documentos.
Por que usar o Spire.Doc para impressão em lote?
O Spire.Doc é uma biblioteca .NET independente que lê, cria e manipula arquivos do Word sem qualquer dependência do próprio Word. Para impressão em lote, isso significa que você pode processar milhares de documentos de forma confiável em um servidor, selecionar uma impressora específica, definir intervalos de páginas e até mesmo lidar com impressão duplex — tudo através de código C# limpo.
Configurando o Spire.Doc em seu projeto .NET
Instale o pacote via NuGet Package Manager:
Install-Package Spire.Doc
Ou use a CLI do .NET: dotnet add package Spire.Doc. É isso — sem licenças ou instalações adicionais do Office.
Exemplo de código C#: Imprimir todos os arquivos do Word de um diretório
Abaixo está um aplicativo de console completo que lê todos os arquivos .docx e .doc de uma pasta e os imprime silenciosamente com um controlador de impressão padrão (sem caixa de diálogo pop-up). O código também mostra como lidar com possíveis exceções com elegância.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentosParaImprimir";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtrar apenas para .docx e .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Imprimindo: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Suprimir a caixa de diálogo de impressão para impressão silenciosa
printDoc.PrintController = new StandardPrintController();
// Opcionalmente, defina o nome da impressora e as cópias
// printDoc.PrinterSettings.PrinterName = "Minha Impressora Específica";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Falha ao imprimir {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Impressão em lote concluída.");
}
}
A lógica é direta: obtenha todos os arquivos do diretório, verifique a extensão, carregue cada um em um objeto Document do Spire.Doc, acesse seu PrintDocument, defina StandardPrintController para evitar a caixa de diálogo de impressão do Windows e chame Print(). O loop garante que cada documento do Word válido seja impresso sequencialmente.
A propriedade PrintDocument.PrinterSettings abre as portas para um controle refinado. Você pode especificar a impressora exata com PrinterName, definir o número de cópias, escolher um intervalo de páginas ou habilitar a impressão duplex. Para uma introdução mais detalhada, consulte Como imprimir documentos do Word em C#.
Comparação rápida: Qual método de impressão em lote é o melhor para você?
| Método | Requer Word? | Silencioso / Sem pop-ups | Melhor para |
|---|---|---|---|
| Clicar com o botão direito e imprimir | Sim | Possíveis interrupções | Tarefas ocasionais |
| Arrastar para atalho da impressora | Sim | Possíveis interrupções | Uso diário visual e rápido |
| Mesclar e imprimir em PDF | Sim | Sim (após mesclado) | Produzir uma única impressão ordenada |
| Macro VBA | Sim | Sim, se configurado | Pastas pessoais repetitivas |
| Script PowerShell | Sim (COM) | Sim | Tarefas agendadas no servidor |
| Spire.Doc com C# | Não | Sim, totalmente silencioso | Automação de servidor e integração |
Considerações finais
A impressão em lote de documentos do Word não precisa ser uma tarefa árdua. Comece com os truques integrados rápidos, adote um script quando precisar de repetibilidade e mude para uma biblioteca dedicada como o Spire.Doc quando seu projeto exigir uma solução robusta e sem Office. Qualquer que seja o caminho escolhido, os minutos que você economizar se somarão rapidamente a horas de produtividade recuperada. Agora escolha um método, carregue sua pasta e deixe a impressora fazer o trabalho pesado.
Perguntas frequentes
Posso imprimir documentos do Word sem abrir cada um?
Sim. Os métodos 4, 5 e 6 suprimem a interface do Word ou funcionam sem ela inteiramente. O script PowerShell e o Spire.Doc imprimem silenciosamente em segundo plano, enquanto a macro VBA pode ocultar a janela do aplicativo.
A impressão em lote funciona com arquivos .doc e .docx?
Com certeza. Todos os métodos descritos aqui lidam com formatos .doc legados e .docx modernos. Ao usar o Spire.Doc, a biblioteca lê perfeitamente ambos os formatos sem qualquer conversão.
Como seleciono uma impressora específica ao imprimir vários arquivos?
Para os métodos manuais, defina a impressora desejada como padrão antes de começar. Com o script PowerShell e o exemplo C# do Spire.Doc, você pode definir programaticamente o nome da impressora no código, dando a você controle preciso sem alterar os padrões do sistema.
Veja também
한 번에 여러 Word 문서를 인쇄하는 방법: 6가지 방법
수십 개의 계약서, 보고서 또는 청구서를 하나씩 인쇄하는 것은 매우 번거롭고 시간 낭비입니다. 회의용 유인물을 준비하든, 법률 문서를 작성하든, 단순히 사무실 서류를 정리하든, 폴더 전체의 Word 파일을 한 번에 프린터로 보낼 수 있다면 몇 시간을 절약할 수 있습니다.
이 기사에서는 .doc 및 .docx 파일을 일괄 인쇄하는 6가지 실용적인 방법을 안내합니다. 간단한 우클릭 방식부터 C#에서 Spire.Doc을 사용하는 강력한 개발자용 솔루션까지 다룹니다. 워크플로에 맞는 방법을 선택하여 오늘부터 더 스마트하게 인쇄해 보세요.
다루는 방법 개요:
- 방법 1: 파일 탐색기에서 우클릭 후 인쇄
- 방법 2: 인쇄 대기열 창을 통해 여러 Word 파일 드래그 앤 드롭
- 방법 3: Word 파일을 먼저 병합하여 통합 인쇄 작업 수행
- 방법 4: Word 매크로(VBA)를 사용하여 폴더 내 모든 문서 인쇄
- 방법 5: PowerShell 스크립트로 자동 일괄 인쇄
- 방법 6: Spire.Doc을 사용하여 C#에서 Word 문서 인쇄
방법 1: 파일 탐색기에서 우클릭 후 인쇄
가장 간단한 방법으로 별도의 도구가 필요 없으며 모든 Windows PC에서 즉시 작동합니다. 소프트웨어를 설치하지 않고 소량의 문서를 빠르게 인쇄할 때 적합합니다. 파일을 선택하기만 하면 Windows가 나머지를 처리합니다.
단계:
- 파일 탐색기를 열고 Word 문서가 있는 폴더로 이동합니다.
- 인쇄할 파일을 선택합니다. Ctrl 키를 누른 상태에서 각 파일을 개별적으로 클릭하거나, Ctrl + A를 눌러 전체를 선택합니다.
- 강조 표시된 파일 중 하나를 우클릭하고 컨텍스트 메뉴에서 인쇄를 선택합니다.
Windows가 자동으로 각 문서를 Microsoft Word에서 열고 기본 프린터로 보낸 뒤 완료되면 Word를 닫습니다. Word 보안 설정에 따라 매크로 경고나 보호된 보기 메시지가 표시되면 수동으로 확인해야 할 수도 있습니다. 하지만 가끔씩 빠르게 인쇄해야 할 때 이보다 좋은 방법은 없습니다.
방법 2: 인쇄 대기열 창을 통해 여러 Word 파일 드래그 앤 드롭
이 Windows 기본 드래그 앤 드롭 워크플로를 사용하면 여러 Word 문서를 일괄 인쇄할 수 있습니다. 파일을 특정 프린터 바탕 화면 바로 가기로 드래그하기만 하면 됩니다. 이 방식은 여러 프린터를 사용하는 사무실 환경에서 프린터를 쉽게 전환할 수 있어 매우 유용합니다.
단계:
- Win + R을 누르고 control printers를 입력한 뒤 Enter를 눌러 '장치 및 프린터' 창을 엽니다.
- 대상 프린터 아이콘을 더블 클릭하여 인쇄 대기열 창을 엽니다.
- 대상 Word 파일을 모두 선택한 다음, 열려 있는 인쇄 대기열 창의 빈 영역으로 직접 드래그 앤 드롭합니다.
파일이 자동으로 인쇄 작업 목록에 추가됩니다. Windows가 각 문서를 순차적으로 열고 인쇄한 뒤 닫습니다.
전문가 팁: 바탕 화면에 프린터 바로 가기를 만들어 빠르게 액세스할 수도 있지만, 인쇄 대기열 창으로 드래그하는 것이 일괄 작업 시 더 안정적인 결과를 제공합니다.
방법 3: Word 파일을 먼저 병합하여 통합 인쇄 작업 수행
모든 개별 Word 파일을 하나의 연속된 순서로 인쇄하려면 병합 워크플로가 최적의 솔루션입니다. 일관된 페이지 순서가 필요한 유인물, 공식 보고서 및 소책자에 매우 효과적입니다. 인쇄 전 파일을 병합하면 출력 후 수동으로 페이지를 정리하는 번거로움이 사라집니다.
단계:
- Microsoft Word를 실행하고 새 빈 문서를 만듭니다.
- 삽입 > 개체 > 파일의 텍스트로 이동합니다(Word 버전에 따라 삽입 > 파일 또는 개체 드롭다운 메뉴 확장).
- 병합할 모든 DOCX 파일을 강조 표시한 다음 삽입을 클릭합니다. 파일이 선택한 순서대로 결합됩니다.
- Ctrl + P를 눌러 인쇄 패널을 엽니다. 실제 프린터 또는 Microsoft Print to PDF를 선택하고 인쇄를 확인합니다.
페이지 흐름이 끊기지 않는 하나의 응집력 있는 문서를 얻게 됩니다. 병합하는 데 약간의 시간이 더 걸리지만, 페이지 순서가 뒤바뀌는 것을 방지하고 수동 분류 작업을 없애주므로 제본 문서나 인쇄된 유인물에 이상적입니다.
방법 4: Word 매크로(VBA)를 사용하여 폴더 내 모든 문서 인쇄
같은 폴더에서 문서를 자주 일괄 인쇄하는 경우, 간단한 VBA 매크로를 통해 프로세스를 완전히 자동화할 수 있습니다. 이 방법은 Microsoft Word 내에서 직접 실행되며 추가 소프트웨어가 필요 없고, 원클릭 인쇄로 설정할 수 있습니다. 반복적인 인쇄 작업을 위한 이상적인 내장 자동화 도구입니다.
단계:
- Microsoft Word를 열고 Alt + F11을 눌러 VBA 편집기를 엽니다.
- 삽입 > 모듈로 이동하여 아래 제공된 VBA 코드를 붙여넣습니다.
- 코드의 폴더 경로를 자신의 디렉터리로 바꿉니다.
- F5를 눌러 매크로를 실행하거나, 빠른 실행 도구 모음에 할당하여 원클릭 인쇄를 설정합니다.
VBA 코드:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Your\File\Path\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "일괄 인쇄가 완료되었습니다!", vbInformation
End Sub
이 방법은 창을 열지 않고 백그라운드에서 조용히 파일을 인쇄합니다. 매크로를 활성화하고 Word가 설치되어 있기만 하면 되므로 개인 또는 사무실 데스크톱용으로 매우 안정적입니다.
방법 5: PowerShell 스크립트로 자동 일괄 인쇄
PowerShell은 창이나 팝업, 수동 조작 없이 백그라운드에서 여러 Word 문서를 인쇄할 수 있는 빠르고 가벼운 스크립트 기반 방식을 제공합니다. 이 방법은 완전히 자동화된 인쇄를 원하는 사용자에게 이상적이며, Windows 작업 스케줄러를 사용하여 예약된 시간에 자동으로 인쇄하도록 설정할 수도 있습니다.
단계:
- 시작 메뉴에서 PowerShell을 엽니다(기본 인쇄에는 관리자 권한이 필요하지 않음).
- 아래 제공된 간단한 일괄 인쇄 스크립트를 복사하여 붙여넣습니다.
$folderPath값을 대상 문서 폴더로 변경합니다.- 스크립트를 실행합니다. Word가 백그라운드에서 조용히 실행되어 모든 문서를 자동으로 인쇄하고 완료되면 깔끔하게 종료됩니다.
PowerShell 스크립트:
$folderPath = "C:\Your\Files\Here"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "일괄 인쇄가 완료되었습니다!"
이 방법은 추가 소프트웨어 없이도 모든 Word 형식을 지원하며, 개인 및 사무실 용도로 안정적인 자동 일괄 인쇄를 제공합니다.
방법 6: Spire.Doc을 사용하여 C#에서 Word 문서 인쇄
Microsoft Office가 설치되지 않은 서버에서 실행되는 완전히 자동화된 고성능 일괄 인쇄 솔루션이 필요하다면 Spire.Doc for .NET이 최고의 라이브러리입니다. 문서 인쇄에 대한 완전한 프로그래밍 제어 권한을 제공하므로 웹 애플리케이션, 백그라운드 서비스 또는 문서 관리 시스템에 이상적입니다.
일괄 인쇄에 Spire.Doc을 사용하는 이유
Spire.Doc은 Word 자체에 대한 의존성 없이 Word 파일을 읽고, 만들고, 조작하는 독립형 .NET 라이브러리입니다. 일괄 인쇄의 경우, 서버에서 수천 개의 문서를 안정적으로 처리하고, 특정 프린터를 선택하고, 페이지 범위를 설정하고, 양면 인쇄까지 처리할 수 있습니다. 이 모든 것이 깔끔한 C# 코드로 가능합니다.
.NET 프로젝트에서 Spire.Doc 설정
NuGet 패키지 관리자를 통해 패키지를 설치합니다:
Install-Package Spire.Doc
또는 .NET CLI 사용: dotnet add package Spire.Doc. 추가적인 Office 라이선스나 설치가 필요 없습니다.
C# 코드 예제: 디렉터리의 모든 Word 파일 인쇄
아래는 폴더에서 모든 .docx 및 .doc 파일을 읽어 표준 인쇄 컨트롤러(팝업 대화 상자 없음)를 사용하여 조용히 인쇄하는 전체 콘솔 애플리케이션입니다. 또한 예외 처리를 우아하게 수행하는 방법도 보여줍니다.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentsToPrint";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"인쇄 중: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// 자동 인쇄를 위해 인쇄 대화 상자 표시 안 함
printDoc.PrintController = new StandardPrintController();
// 선택적으로 프린터 이름 및 복사본 설정
// printDoc.PrinterSettings.PrinterName = "My Specific Printer";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"{filePath} 인쇄 실패: {ex.Message}");
}
}
}
Console.WriteLine("일괄 인쇄가 완료되었습니다.");
}
}
논리는 간단합니다. 디렉터리에서 모든 파일을 가져오고, 확장자를 확인하고, 각 파일을 Spire.Doc Document 객체로 로드한 뒤 PrintDocument에 액세스합니다. StandardPrintController를 설정하여 Windows 인쇄 대화 상자를 피하고 Print()를 호출합니다. 루프는 모든 유효한 Word 문서가 순차적으로 인쇄되도록 보장합니다.
PrintDocument.PrinterSettings 속성을 사용하면 세밀한 제어가 가능합니다. PrinterName으로 정확한 프린터를 지정하고, 복사본 수를 설정하고, 페이지 범위를 선택하거나 양면 인쇄를 활성화할 수 있습니다. 자세한 내용은 C#에서 Word 문서 인쇄 방법을 참조하세요.
빠른 비교: 나에게 가장 적합한 일괄 인쇄 방법은?
| 방법 | Word 필요 여부 | 자동/팝업 없음 | 용도 |
|---|---|---|---|
| 우클릭 후 인쇄 | 예 | 중단 가능성 있음 | 가끔 수행하는 일회성 작업 |
| 프린터 바로 가기로 드래그 | 예 | 중단 가능성 있음 | 시각적이고 빠른 일상적 사용 |
| 병합 후 PDF로 인쇄 | 예 | 예 (병합 후) | 단일 순서 인쇄물 생성 |
| VBA 매크로 | 예 | 예 (설정 시) | 개인적인 반복 폴더 작업 |
| PowerShell 스크립트 | 예 (COM) | 예 | 예약된 서버 측 작업 |
| Spire.Doc (C#) | 아니요 | 예, 완전 자동 | 서버 자동화 및 통합 |
결론
Word 문서 일괄 인쇄가 반드시 힘든 작업일 필요는 없습니다. 빠른 내장 기능을 시작으로, 반복성이 필요할 때는 스크립트를 사용하고, 프로젝트에 강력하고 Office가 필요 없는 솔루션이 요구될 때는 Spire.Doc과 같은 전용 라이브러리를 사용하세요. 어떤 방법을 선택하든 절약한 시간은 생산성 향상으로 이어질 것입니다. 이제 방법을 선택하고 폴더를 준비하여 프린터가 힘든 일을 대신하게 하세요.
자주 묻는 질문(FAQ)
각 문서를 열지 않고 Word 문서를 인쇄할 수 있나요?
네. 방법 4, 5, 6은 모두 Word 인터페이스를 숨기거나 아예 사용하지 않습니다. PowerShell 스크립트와 Spire.Doc은 모두 백그라운드에서 조용히 인쇄하며, VBA 매크로는 애플리케이션 창을 숨길 수 있습니다.
일괄 인쇄가 .doc 및 .docx 파일 모두에서 작동하나요?
물론입니다. 여기에 설명된 모든 방법은 레거시 .doc 및 최신 .docx 형식을 모두 처리합니다. Spire.Doc을 사용할 경우 라이브러리가 변환 없이 두 형식을 원활하게 읽습니다.
여러 파일을 인쇄할 때 특정 프린터를 선택하려면 어떻게 하나요?
수동 방법의 경우 시작하기 전에 원하는 프린터를 기본값으로 설정하세요. PowerShell 스크립트와 C# Spire.Doc 예제에서는 코드 내에서 프로그래밍 방식으로 프린터 이름을 설정할 수 있으므로 시스템 기본값을 변경하지 않고도 정밀하게 제어할 수 있습니다.
참고 항목
Come stampare più documenti Word contemporaneamente: 6 metodi
Indice
- Metodo 1: Tasto destro e Stampa da Esplora file
- Metodo 2: Trascinamento di più file Word nella finestra della coda di stampa
- Metodo 3: Unire prima i file Word per un unico processo di stampa
- Metodo 4: Utilizzare una macro di Word (VBA) per stampare tutti i documenti in una cartella
- Metodo 5: Stampa batch silenziosa con uno script PowerShell
- Metodo 6: Stampare documenti Word in C# utilizzando Spire.Doc
- Confronto rapido: Quale metodo di stampa batch è più adatto a te?
- Considerazioni finali
- Domande frequenti (FAQ)
Stampare decine di contratti, report o fatture uno alla volta è una perdita di tempo noiosa. Che tu stia preparando materiale per una riunione, producendo documenti legali o semplicemente organizzando le scartoffie del tuo ufficio, la capacità di inviare un'intera cartella di file Word alla stampante in una sola volta può farti risparmiare ore.
Questo articolo ti guida attraverso sei metodi pratici per stampare in batch file .doc e .docx, dai semplici trucchi con il tasto destro a una potente soluzione orientata agli sviluppatori che utilizza Spire.Doc in C#. Scegli quello più adatto al tuo flusso di lavoro e inizia a stampare in modo più intelligente oggi stesso.
Panoramica dei metodi trattati:
- Metodo 1: Tasto destro e Stampa da Esplora file
- Metodo 2: Trascinamento di più file Word nella finestra della coda di stampa
- Metodo 3: Unire prima i file Word per un unico processo di stampa
- Metodo 4: Utilizzare una macro di Word (VBA) per stampare tutti i documenti in una cartella
- Metodo 5: Stampa batch silenziosa con uno script PowerShell
- Metodo 6: Stampare documenti Word in C# utilizzando Spire.Doc
Metodo 1: Tasto destro e Stampa da Esplora file
Il metodo più semplice non richiede strumenti aggiuntivi e funziona istantaneamente su qualsiasi PC Windows. È perfetto per stampare rapidamente una manciata di documenti senza installare alcun software. Basta selezionare i file e lasciare che Windows faccia il resto.
Passaggi:
- Apri Esplora file e vai alla cartella contenente i tuoi documenti Word.
- Seleziona i file che desideri stampare: tieni premuto il tasto Ctrl e fai clic su ciascuno di essi singolarmente, oppure premi Ctrl + A per selezionarli tutti.
- Fai clic con il tasto destro su uno qualsiasi dei file evidenziati e scegli Stampa dal menu contestuale.
Windows aprirà automaticamente ogni documento in Microsoft Word, lo invierà alla stampante predefinita e chiuderà Word al termine. Tieni presente che se le impostazioni di sicurezza di Word visualizzano avvisi sulle macro o messaggi di Visualizzazione protetta, il processo potrebbe interrompersi finché non li confermi manualmente. Tuttavia, per lavori rapidi e occasionali, questo metodo è difficile da battere.
Metodo 2: Trascinamento di più file Word nella finestra della coda di stampa
Questo flusso di lavoro nativo di Windows basato sul trascinamento consente la stampa batch di più documenti Word: basta trascinare i file su un collegamento desktop della stampante dedicato. Questo approccio rende facile passare da una stampante all'altra a piacimento, rendendolo ideale per ambienti d'ufficio dotati di diversi dispositivi di stampa.
Passaggi:
- Premi Win + R, digita control printers, quindi premi Invio per avviare la finestra Dispositivi e stampanti.
- Fai doppio clic sull'icona della stampante desiderata per aprire la finestra della coda di stampa.
- Seleziona tutti i file Word di destinazione, quindi trascinali direttamente nell'area vuota della finestra della coda di stampa aperta.
I file popoleranno automaticamente l'elenco dei processi di stampa. Windows aprirà, stamperà e chiuderà ogni documento in sequenza.
Consiglio dell'esperto: Puoi anche creare un collegamento alla stampante sul desktop per un accesso rapido, sebbene il trascinamento nella finestra della coda di stampa offra risultati più affidabili per le attività batch.
Metodo 3: Unire prima i file Word per un unico processo di stampa
Se desideri che tutti i file Word separati vengano stampati come un unico documento continuo e ordinato, questo flusso di lavoro di unione è la soluzione ottimale. Funziona eccezionalmente bene per dispense, report formali e opuscoli che richiedono una sequenza di pagine coerente. Unire i file prima della stampa elimina la noiosa operazione manuale di ordinamento delle pagine dopo la stampa.
Passaggi:
- Avvia Microsoft Word e crea un nuovo documento vuoto.
- Vai su Inserisci > Oggetto > Testo da file (percorsi alternativi: Inserisci > File o espandi il menu a discesa Oggetto in alcune versioni di Word).
- Evidenzia tutti i file DOCX da unire, quindi fai clic su Inserisci. I file verranno assemblati seguendo l'ordine selezionato.
- Premi Ctrl + P per aprire il pannello di stampa. Seleziona la tua stampante fisica o Microsoft Print to PDF, quindi conferma la stampa.
Riceverai un documento coeso con un flusso di pagine ininterrotto. Sebbene l'unione richieda un po' di tempo extra, previene l'ordine errato delle pagine ed elimina l'assemblaggio manuale: ideale per documenti rilegati e dispense stampate.
Metodo 4: Utilizzare una macro di Word (VBA) per stampare tutti i documenti in una cartella
Se stampi spesso batch di documenti dalla stessa cartella, una semplice macro VBA può automatizzare completamente il processo. Questo metodo viene eseguito direttamente all'interno di Microsoft Word, non richiede software aggiuntivo e può essere configurato per la stampa con un solo clic. È uno strumento di automazione integrato ideale per attività di stampa regolari e ripetute.
Passaggi:
- Apri Microsoft Word e premi Alt + F11 per aprire l'editor VBA.
- Vai su Inserisci > Modulo e incolla il codice VBA pronto all'uso fornito di seguito.
- Sostituisci il percorso della cartella nel codice con la tua directory.
- Premi F5 per eseguire la macro, oppure assegnala alla barra di accesso rapido per la stampa con un clic.
Codice VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Il\Tuo\Percorso\File\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Stampa batch completata!", vbInformation
End Sub
Questo metodo stampa i file silenziosamente in background senza aprire finestre. Gli unici requisiti sono abilitare le macro e avere Word installato: perfetto per un uso affidabile su desktop personale o in ufficio.
Metodo 5: Stampa batch silenziosa con uno script PowerShell
PowerShell offre un modo veloce, leggero e basato su script per stampare più documenti Word in background: nessuna finestra, nessun pop-up e nessuna interazione manuale. Questo metodo è ideale per gli utenti che desiderano una stampa completamente automatizzata e può persino essere pianificato con l'Utilità di pianificazione di Windows per attività automatiche e programmate.
Passaggi:
- Apri PowerShell dal menu Start (non sono necessari diritti di amministratore per la stampa di base).
- Copia e incolla il semplice script di stampa batch fornito di seguito.
- Modifica il valore
$folderPathcon la cartella dei documenti di destinazione. - Esegui lo script. Word verrà eseguito silenziosamente in background, stamperà automaticamente tutti i documenti e si chiuderà correttamente al termine.
Script PowerShell:
$folderPath = "C:\I\Tuoi\File\Qui"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Stampa batch completata!"
Questo metodo funziona senza software aggiuntivo, supporta tutti i formati Word e offre una stampa batch silenziosa e affidabile sia per uso personale che in ufficio.
Metodo 6: Stampare documenti Word in C# utilizzando Spire.Doc
Quando hai bisogno di una soluzione di stampa batch completamente automatizzata e ad alte prestazioni che funzioni su un server senza Microsoft Office, Spire.Doc for .NET è la libreria di riferimento. Ti offre un controllo programmatico completo sulla stampa dei documenti, rendendola ideale per applicazioni web, servizi in background o sistemi di gestione documentale.
Perché utilizzare Spire.Doc per la stampa batch?
Spire.Doc è una libreria .NET autonoma che legge, crea e manipola file Word senza alcuna dipendenza da Word stesso. Per la stampa batch, ciò significa che puoi elaborare migliaia di documenti in modo affidabile su un server, selezionare una stampante specifica, impostare intervalli di pagine e persino gestire la stampa fronte-retro, tutto tramite un codice C# pulito.
Configurazione di Spire.Doc nel tuo progetto .NET
Installa il pacchetto tramite NuGet Package Manager:
Install-Package Spire.Doc
Oppure usa la CLI .NET: dotnet add package Spire.Doc. Tutto qui: nessuna licenza o installazione di Office aggiuntiva.
Esempio di codice C#: Stampare tutti i file Word da una directory
Di seguito è riportata un'applicazione console completa che legge tutti i file .docx e .doc da una cartella e li stampa silenziosamente con un controller di stampa standard (nessuna finestra di dialogo pop-up). Il codice mostra anche come gestire correttamente le possibili eccezioni.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentiDaStampare";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtra solo per .docx e .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Stampa in corso: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Sopprime la finestra di dialogo di stampa per una stampa silenziosa
printDoc.PrintController = new StandardPrintController();
// Opzionalmente imposta il nome della stampante e le copie
// printDoc.PrinterSettings.PrinterName = "La Mia Stampante";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Impossibile stampare {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Stampa batch completata.");
}
}
La logica è semplice: ottieni tutti i file dalla directory, controlla l'estensione, carica ciascuno in un oggetto Document di Spire.Doc, accedi al suo PrintDocument, imposta StandardPrintController per evitare la finestra di dialogo di stampa di Windows e chiama Print(). Il ciclo garantisce che ogni documento Word valido venga stampato in sequenza.
La proprietà PrintDocument.PrinterSettings apre la porta a un controllo granulare. Puoi specificare la stampante esatta con PrinterName, impostare il numero di copie, scegliere un intervallo di pagine o abilitare la stampa fronte-retro. Per un'introduzione più dettagliata, fai riferimento a Come stampare documenti Word in C#.
Confronto rapido: Quale metodo di stampa batch è più adatto a te?
| Metodo | Richiede Word? | Silenzioso / Nessun pop-up | Ideale per |
|---|---|---|---|
| Tasto destro e Stampa | Sì | Possibili interruzioni | Attività occasionali |
| Trascina su collegamento stampante | Sì | Possibili interruzioni | Uso quotidiano rapido e visivo |
| Unisci e stampa in PDF | Sì | Sì (una volta uniti) | Produrre un unico stampato ordinato |
| Macro VBA | Sì | Sì, se configurato | Cartelle personali ripetitive |
| Script PowerShell | Sì (COM) | Sì | Attività pianificate lato server |
| Spire.Doc con C# | No | Sì, completamente silenzioso | Automazione server e integrazione |
Considerazioni finali
La stampa batch di documenti Word non deve essere un lavoro gravoso. Inizia con i rapidi trucchi integrati, adotta uno script quando hai bisogno di ripetibilità e passa a una libreria dedicata come Spire.Doc quando il tuo progetto richiede una soluzione robusta e priva di Office. Qualunque strada tu scelga, i minuti risparmiati si sommeranno rapidamente in ore di produttività recuperata. Ora scegli un metodo, carica la tua cartella e lascia che la stampante faccia il lavoro pesante.
Domande frequenti (FAQ)
Posso stampare documenti Word senza aprirli uno per uno?
Sì. I metodi 4, 5 e 6 sopprimono l'interfaccia di Word o funzionano senza di essa. Lo script PowerShell e Spire.Doc stampano entrambi silenziosamente in background, mentre la macro VBA può nascondere la finestra dell'applicazione.
La stampa batch funziona con file .doc e .docx?
Assolutamente sì. Ogni metodo descritto qui gestisce sia i formati legacy .doc che quelli moderni .docx. Quando si utilizza Spire.Doc, la libreria legge perfettamente entrambi i formati senza alcuna conversione.
Come seleziono una stampante specifica durante la stampa di più file?
Per i metodi manuali, imposta la stampante desiderata come predefinita prima di iniziare. Con lo script PowerShell e l'esempio C# di Spire.Doc, puoi impostare programmaticamente il nome della stampante all'interno del codice, offrendoti un controllo preciso senza modificare le impostazioni predefinite del sistema.
Vedi anche
Comment imprimer plusieurs documents Word à la fois : 6 méthodes
Table des matières
- Méthode 1 : Clic droit et imprimer depuis l'Explorateur de fichiers
- Méthode 2 : Glisser-déposer plusieurs fichiers Word via la fenêtre de file d'attente d'impression
- Méthode 3 : Fusionner d'abord les fichiers Word pour une impression unifiée
- Méthode 4 : Utiliser une macro Word (VBA) pour imprimer tous les documents d'un dossier
- Méthode 5 : Impression par lots silencieuse avec un script PowerShell
- Méthode 6 : Imprimer des documents Word en C# avec Spire.Doc
- Comparaison rapide : quelle méthode d'impression par lots vous convient le mieux ?
- Réflexions finales
- FAQ
Imprimer des dizaines de contrats, rapports ou factures un par un est une perte de temps fastidieuse. Que vous prépariez des documents pour une réunion, produisiez des documents juridiques ou organisiez simplement vos dossiers de bureau, la capacité d'envoyer tout un dossier de fichiers Word à l'imprimante en une seule fois peut vous faire gagner des heures.
Cet article vous présente six méthodes pratiques pour imprimer par lots des fichiers .doc et .docx, allant d'astuces simples par clic droit à une solution puissante destinée aux développeurs utilisant Spire.Doc en C#. Choisissez celle qui correspond à votre flux de travail et commencez à imprimer plus intelligemment dès aujourd'hui.
Aperçu des méthodes couvertes :
- Méthode 1 : Clic droit et imprimer depuis l'Explorateur de fichiers
- Méthode 2 : Glisser-déposer plusieurs fichiers Word via la fenêtre de file d'attente d'impression
- Méthode 3 : Fusionner d'abord les fichiers Word pour une impression unifiée
- Méthode 4 : Utiliser une macro Word (VBA) pour imprimer tous les documents d'un dossier
- Méthode 5 : Impression par lots silencieuse avec un script PowerShell
- Méthode 6 : Imprimer des documents Word en C# avec Spire.Doc
Méthode 1 : Clic droit et imprimer depuis l'Explorateur de fichiers
La méthode la plus simple ne nécessite aucun outil supplémentaire et fonctionne instantanément sur n'importe quel PC Windows. Elle est parfaite pour imprimer rapidement quelques documents sans installer de logiciel. Sélectionnez simplement vos fichiers et laissez Windows gérer le reste.
Étapes :
- Ouvrez l'Explorateur de fichiers et accédez au dossier contenant vos documents Word.
- Sélectionnez les fichiers que vous souhaitez imprimer : maintenez la touche Ctrl enfoncée et cliquez sur chaque fichier individuellement, ou appuyez sur Ctrl + A pour tout sélectionner.
- Faites un clic droit sur n'importe quel fichier sélectionné et choisissez Imprimer dans le menu contextuel.
Windows ouvrira automatiquement chaque document dans Microsoft Word, l'enverra à votre imprimante par défaut et fermera Word une fois terminé. Gardez à l'esprit que si vos paramètres de sécurité Word affichent des avertissements de macro ou des invites de mode protégé, le processus peut s'interrompre jusqu'à ce que vous les confirmiez manuellement. Néanmoins, pour des tâches rapides et occasionnelles, cette méthode est difficile à battre.
Méthode 2 : Glisser-déposer plusieurs fichiers Word via la fenêtre de file d'attente d'impression
Ce flux de travail natif de Windows permet l'impression par lots de plusieurs documents Word : il suffit de faire glisser vos fichiers sur un raccourci de bureau dédié à l'imprimante. Cette approche facilite le basculement entre différentes imprimantes, ce qui la rend idéale pour les environnements de bureau équipés de plusieurs périphériques d'impression.
Étapes :
- Appuyez sur Win + R, tapez control printers, puis appuyez sur Entrée pour lancer la fenêtre Périphériques et imprimantes.
- Double-cliquez sur l'icône de votre imprimante cible pour afficher sa fenêtre de file d'attente d'impression.
- Sélectionnez tous les fichiers Word cibles, puis faites-les glisser directement dans la zone vide de la fenêtre de file d'attente d'impression ouverte.
Les fichiers seront automatiquement ajoutés à la liste des travaux d'impression. Windows ouvrira, imprimera et fermera chaque document séquentiellement.
Conseil d'expert : Vous pouvez également créer un raccourci d'imprimante sur le bureau pour un accès rapide, bien que le glisser-déposer dans la fenêtre de file d'attente d'impression donne des résultats plus fiables pour les tâches par lots.
Méthode 3 : Fusionner d'abord les fichiers Word pour une impression unifiée
Si vous souhaitez que tous les fichiers Word séparés soient imprimés sous forme d'un seul document continu et ordonné, ce flux de travail de fusion est votre solution optimale. Il fonctionne exceptionnellement bien pour les documents distribués, les rapports officiels et les livrets qui nécessitent une séquence de pages cohérente. Fusionner les fichiers avant l'impression évite le tri manuel fastidieux des pages après la sortie.
Étapes :
- Lancez Microsoft Word et créez un nouveau document vierge.
- Accédez à Insertion > Objet > Texte d'un fichier (chemins alternatifs : Insertion > Fichier ou développez le menu déroulant Objet sur certaines éditions de Word).
- Mettez en surbrillance tous les fichiers DOCX à fusionner, puis cliquez sur Insérer. Les fichiers s'assembleront selon l'ordre sélectionné.
- Appuyez sur Ctrl + P pour ouvrir le panneau d'impression. Sélectionnez votre imprimante physique ou Microsoft Print to PDF, puis confirmez l'impression.
Vous obtiendrez un document cohérent avec un flux de pages ininterrompu. Bien que la fusion prenne un peu plus de temps, elle évite les pages mal ordonnées et élimine le tri manuel, ce qui est idéal pour les documents reliés et les supports imprimés.
Méthode 4 : Utiliser une macro Word (VBA) pour imprimer tous les documents d'un dossier
Si vous imprimez fréquemment des lots de documents à partir du même dossier, une simple macro VBA peut automatiser entièrement le processus. Cette méthode s'exécute directement dans Microsoft Word, ne nécessite aucun logiciel supplémentaire et peut être configurée pour une impression en un clic. C'est un outil d'automatisation intégré idéal pour les tâches d'impression répétitives.
Étapes :
- Ouvrez Microsoft Word et appuyez sur Alt + F11 pour ouvrir l'éditeur VBA.
- Allez dans Insertion > Module et collez le code VBA prêt à l'emploi fourni ci-dessous.
- Remplacez le chemin du dossier dans le code par votre propre répertoire.
- Appuyez sur F5 pour exécuter la macro, ou assignez-la à la barre d'outils Accès rapide pour une impression en un clic.
Code VBA :
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Votre\Chemin\De\Fichier\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Impression par lots terminée !", vbInformation
End Sub
Cette méthode imprime les fichiers silencieusement en arrière-plan sans ouvrir de fenêtres. Les seules exigences sont l'activation des macros et l'installation de Word — parfait pour une utilisation fiable sur un ordinateur personnel ou de bureau.
Méthode 5 : Impression par lots silencieuse avec un script PowerShell
PowerShell offre un moyen rapide, léger et basé sur des scripts pour imprimer plusieurs documents Word en arrière-plan — sans fenêtres, sans pop-ups et sans interaction manuelle. Cette méthode est idéale pour les utilisateurs qui souhaitent une impression entièrement automatisée, et elle peut même être planifiée avec le Planificateur de tâches Windows pour des travaux automatiques et programmés.
Étapes :
- Ouvrez PowerShell depuis le menu Démarrer (aucun droit d'administrateur requis pour l'impression de base).
- Copiez et collez le script d'impression par lots simple fourni ci-dessous.
- Modifiez la valeur
$folderPathpar le dossier contenant vos documents cibles. - Exécutez le script. Word s'exécutera silencieusement en arrière-plan, imprimera tous vos documents automatiquement et se fermera proprement une fois terminé.
Script PowerShell :
$folderPath = "C:\Vos\Fichiers\Ici"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Impression par lots terminée !"
Cette méthode fonctionne sans logiciel supplémentaire, prend en charge tous les formats Word et offre une impression par lots silencieuse et fiable pour un usage personnel et professionnel.
Méthode 6 : Imprimer des documents Word en C# avec Spire.Doc
Lorsque vous avez besoin d'une solution d'impression par lots entièrement automatisée et haute performance qui s'exécute sur un serveur sans Microsoft Office, Spire.Doc for .NET est la bibliothèque de référence. Elle vous donne un contrôle programmatique complet sur l'impression de documents, ce qui la rend idéale pour les applications web, les services en arrière-plan ou les systèmes de gestion documentaire.
Pourquoi utiliser Spire.Doc pour l'impression par lots ?
Spire.Doc est une bibliothèque .NET autonome qui lit, crée et manipule des fichiers Word sans aucune dépendance à Word lui-même. Pour l'impression par lots, cela signifie que vous pouvez traiter des milliers de documents de manière fiable sur un serveur, sélectionner une imprimante spécifique, définir des plages de pages et même gérer l'impression recto verso — le tout via un code C# propre.
Configuration de Spire.Doc dans votre projet .NET
Installez le package via le gestionnaire de packages NuGet :
Install-Package Spire.Doc
Ou utilisez l'interface de ligne de commande .NET : dotnet add package Spire.Doc. C'est tout — aucune licence ou installation Office supplémentaire n'est requise.
Exemple de code C# : Imprimer tous les fichiers Word d'un répertoire
Voici une application console complète qui lit tous les fichiers .docx et .doc d'un dossier et les imprime silencieusement avec un contrôleur d'impression standard (sans boîte de dialogue contextuelle). Le code montre également comment gérer les exceptions potentielles avec élégance.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentsAImprimer";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtrer uniquement pour .docx et .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Impression : {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Supprimer la boîte de dialogue d'impression pour une impression silencieuse
printDoc.PrintController = new StandardPrintController();
// Optionnellement définir le nom de l'imprimante et le nombre de copies
// printDoc.PrinterSettings.PrinterName = "Mon imprimante spécifique";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Échec de l'impression de {filePath} : {ex.Message}");
}
}
}
Console.WriteLine("Impression par lots terminée.");
}
}
La logique est simple : obtenir tous les fichiers du répertoire, vérifier l'extension, charger chacun dans un objet Document de Spire.Doc, accéder à son PrintDocument, définir StandardPrintController pour éviter la boîte de dialogue d'impression Windows, et appeler Print(). La boucle garantit que chaque document Word valide est imprimé séquentiellement.
La propriété PrintDocument.PrinterSettings ouvre la porte à un contrôle précis. Vous pouvez spécifier l'imprimante exacte avec PrinterName, définir le nombre de copies, choisir une plage de pages ou activer l'impression recto verso. Pour une introduction plus détaillée, reportez-vous à Comment imprimer des documents Word en C#.
Comparaison rapide : quelle méthode d'impression par lots vous convient le mieux ?
| Méthode | Nécessite Word ? | Silencieux / Sans pop-ups | Idéal pour |
|---|---|---|---|
| Clic droit & Imprimer | Oui | Interruptions possibles | Tâches occasionnelles |
| Glisser vers raccourci imprimante | Oui | Interruptions possibles | Usage quotidien rapide et visuel |
| Fusionner & Imprimer en PDF | Oui | Oui (une fois fusionné) | Produire une seule impression ordonnée |
| Macro VBA | Oui | Oui, si configuré | Dossiers répétitifs personnels |
| Script PowerShell | Oui (COM) | Oui | Tâches planifiées côté serveur |
| Spire.Doc avec C# | Non | Oui, totalement silencieux | Automatisation serveur & intégration |
Réflexions finales
L'impression par lots de documents Word ne doit pas être une corvée. Commencez par les astuces intégrées rapides, adoptez un script lorsque vous avez besoin de répétabilité, et passez à une bibliothèque dédiée comme Spire.Doc lorsque votre projet exige une solution robuste et sans Office. Quelle que soit la voie choisie, les minutes que vous économiserez s'additionneront rapidement pour devenir des heures de productivité retrouvée. Choisissez maintenant une méthode, chargez votre dossier et laissez l'imprimante faire le gros du travail.
FAQ
Puis-je imprimer des documents Word sans ouvrir chacun d'eux ?
Oui. Les méthodes 4, 5 et 6 suppriment toutes l'interface Word ou fonctionnent sans elle. Le script PowerShell et Spire.Doc impriment tous deux silencieusement en arrière-plan, tandis que la macro VBA peut masquer la fenêtre de l'application.
L'impression par lots fonctionne-t-elle avec les fichiers .doc et .docx ?
Absolument. Chaque méthode décrite ici gère à la fois les anciens formats .doc et les formats modernes .docx. Lors de l'utilisation de Spire.Doc, la bibliothèque lit de manière transparente les deux formats sans aucune conversion.
Comment sélectionner une imprimante spécifique lors de l'impression de plusieurs fichiers ?
Pour les méthodes manuelles, définissez l'imprimante souhaitée comme imprimante par défaut avant de commencer. Avec le script PowerShell et l'exemple C# Spire.Doc, vous pouvez définir par programmation le nom de l'imprimante dans le code, vous offrant un contrôle précis sans modifier les paramètres par défaut du système.
Voir aussi
Cómo imprimir varios documentos de Word a la vez: 6 formas
Tabla de contenidos
- Método 1: Clic derecho e imprimir desde el Explorador de archivos
- Método 2: Arrastrar y soltar múltiples archivos de Word a través de la ventana de cola de impresión
- Método 3: Combinar archivos de Word primero para un trabajo de impresión unificado
- Método 4: Usar una macro de Word (VBA) para imprimir todos los documentos de una carpeta
- Método 5: Impresión por lotes silenciosa con un script de PowerShell
- Método 6: Imprimir documentos de Word en C# usando Spire.Doc
- Comparación rápida: ¿Qué método de impresión por lotes se adapta mejor a usted?
- Reflexiones finales
- Preguntas frecuentes
Imprimir docenas de contratos, informes o facturas uno por uno es una pérdida de tiempo tediosa. Ya sea que esté preparando folletos para una reunión, produciendo documentos legales o simplemente organizando el papeleo de su oficina, la capacidad de enviar una carpeta completa de archivos de Word a la impresora de una sola vez puede ahorrarle horas.
Este artículo le guía a través de seis métodos prácticos para imprimir por lotes archivos .doc y .docx, desde trucos sencillos de clic derecho hasta una potente solución orientada a desarrolladores utilizando Spire.Doc en C#. Elija el que mejor se adapte a su flujo de trabajo y comience a imprimir de forma más inteligente hoy mismo.
Resumen de los métodos cubiertos:
- Método 1: Clic derecho e imprimir desde el Explorador de archivos
- Método 2: Arrastrar y soltar múltiples archivos de Word a través de la ventana de cola de impresión
- Método 3: Combinar archivos de Word primero para un trabajo de impresión unificado
- Método 4: Usar una macro de Word (VBA) para imprimir todos los documentos de una carpeta
- Método 5: Impresión por lotes silenciosa con un script de PowerShell
- Método 6: Imprimir documentos de Word en C# usando Spire.Doc
Método 1: Clic derecho e imprimir desde el Explorador de archivos
El método más sencillo no requiere herramientas adicionales y funciona al instante en cualquier PC con Windows. Es perfecto para imprimir rápidamente un puñado de documentos sin instalar ningún software. Simplemente seleccione sus archivos y deje que Windows haga el resto.
Pasos:
- Abra el Explorador de archivos y navegue hasta la carpeta que contiene sus documentos de Word.
- Seleccione los archivos que desea imprimir: mantenga presionada la tecla Ctrl y haga clic en cada uno individualmente, o presione Ctrl + A para seleccionarlos todos.
- Haga clic derecho en cualquier archivo resaltado y elija Imprimir en el menú contextual.
Windows abrirá automáticamente cada documento en Microsoft Word, lo enviará a su impresora predeterminada y cerrará Word al finalizar. Tenga en cuenta que si la configuración de seguridad de Word muestra advertencias de macros o avisos de Vista protegida, el proceso puede pausarse hasta que los confirme manualmente. Aun así, para trabajos rápidos y ocasionales, este método es difícil de superar.
Método 2: Arrastrar y soltar múltiples archivos de Word a través de la ventana de cola de impresión
Este flujo de trabajo nativo de arrastrar y soltar de Windows permite la impresión por lotes de múltiples documentos de Word; simplemente arrastre sus archivos a un acceso directo de escritorio de la impresora. Este enfoque facilita el cambio entre diferentes impresoras a voluntad, lo que lo hace ideal para entornos de oficina equipados con varios dispositivos de impresión.
Pasos:
- Presione Win + R, escriba control printers y luego presione Enter para abrir la ventana de Dispositivos e impresoras.
- Haga doble clic en el icono de su impresora de destino para abrir su ventana de cola de impresión.
- Seleccione todos los archivos de Word de destino y luego arrástrelos y suéltelos directamente en el área en blanco de la ventana de cola de impresión abierta.
Los archivos se añadirán a la lista de trabajos de impresión automáticamente. Windows abrirá, imprimirá y cerrará cada documento secuencialmente.
Consejo profesional: También puede crear un acceso directo de impresora en el escritorio para un acceso rápido, aunque arrastrar a la ventana de cola de impresión ofrece resultados más fiables para tareas por lotes.
Método 3: Combinar archivos de Word primero para un trabajo de impresión unificado
Si desea que todos los archivos de Word separados se impriman como un documento continuo y ordenado, este flujo de trabajo de combinación es su solución óptima. Funciona excepcionalmente bien para folletos, informes formales y cuadernillos que requieren una secuencia de páginas coherente. Combinar archivos antes de imprimir elimina la tediosa clasificación manual de páginas después de la salida.
Pasos:
- Inicie Microsoft Word y cree un nuevo documento en blanco.
- Navegue a Insertar > Objeto > Texto de archivo (rutas alternativas: Insertar > Archivo o expanda el menú desplegable Objeto en ciertas ediciones de Word).
- Resalte todos los archivos DOCX que se van a combinar y luego haga clic en Insertar. Los archivos se ensamblarán siguiendo el orden seleccionado.
- Presione Ctrl + P para abrir el panel de impresión. Seleccione su impresora física o Microsoft Print to PDF y luego confirme la impresión.
Recibirá un documento cohesivo con un flujo de páginas ininterrumpido. Aunque la combinación requiere un poco de tiempo adicional, evita el desorden de páginas y elimina la clasificación manual, ideal para documentos encuadernados y folletos impresos.
Método 4: Usar una macro de Word (VBA) para imprimir todos los documentos de una carpeta
Si imprime frecuentemente lotes de documentos de la misma carpeta, una sencilla macro de VBA puede automatizar completamente el proceso. Este método se ejecuta directamente dentro de Microsoft Word, no requiere software adicional y se puede configurar para imprimir con un solo clic. Es una herramienta de automatización integrada ideal para tareas de impresión regulares y repetitivas.
Pasos:
- Abra Microsoft Word y presione Alt + F11 para abrir el editor de VBA.
- Vaya a Insertar > Módulo y pegue el código VBA listo para usar que se proporciona a continuación.
- Reemplace la ruta de la carpeta en el código con su propio directorio.
- Presione F5 para ejecutar la macro, o asígnela a la Barra de herramientas de acceso rápido para imprimir con un solo clic.
Código VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Tu\Ruta\De\Archivo\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "¡Impresión por lotes completada!", vbInformation
End Sub
Este método imprime archivos silenciosamente en segundo plano sin abrir ventanas. Los únicos requisitos son habilitar las macros y tener Word instalado; perfecto para un uso fiable en escritorio personal o de oficina.
Método 5: Impresión por lotes silenciosa con un script de PowerShell
PowerShell ofrece una forma rápida, ligera y basada en scripts para imprimir múltiples documentos de Word en segundo plano: sin ventanas, sin ventanas emergentes y sin interacción manual. Este método es ideal para usuarios que desean una impresión totalmente automatizada, e incluso se puede programar con el Programador de tareas de Windows para trabajos automáticos y programados.
Pasos:
- Abra PowerShell desde el menú Inicio (no se requieren derechos de administrador para la impresión básica).
- Copie y pegue el sencillo script de impresión por lotes que se proporciona a continuación.
- Cambie el valor de
$folderPatha su carpeta de documentos de destino. - Ejecute el script. Word se ejecutará silenciosamente en segundo plano, imprimirá todos sus documentos automáticamente y se cerrará limpiamente al finalizar.
Script de PowerShell:
$folderPath = "C:\Sus\Archivos\Aqui"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "¡Impresión por lotes completada!"
Este método funciona sin software adicional, admite todos los formatos de Word y ofrece una impresión por lotes silenciosa y fiable tanto para uso personal como de oficina.
Método 6: Imprimir documentos de Word en C# usando Spire.Doc
Cuando necesita una solución de impresión por lotes de alto rendimiento y totalmente automatizada que se ejecute en un servidor sin Microsoft Office, Spire.Doc for .NET es la biblioteca de referencia. Le brinda un control programático completo sobre la impresión de documentos, lo que la hace ideal para aplicaciones web, servicios en segundo plano o sistemas de gestión de documentos.
¿Por qué usar Spire.Doc para la impresión por lotes?
Spire.Doc es una biblioteca .NET independiente que lee, crea y manipula archivos de Word sin ninguna dependencia de Word en sí. Para la impresión por lotes, esto significa que puede procesar miles de documentos de forma fiable en un servidor, seleccionar una impresora específica, establecer rangos de páginas e incluso manejar la impresión a doble cara, todo a través de código C# limpio.
Configuración de Spire.Doc en su proyecto .NET
Instale el paquete a través del Administrador de paquetes NuGet:
Install-Package Spire.Doc
O use la CLI de .NET: dotnet add package Spire.Doc. Eso es todo: no se requieren licencias ni instalaciones adicionales de Office.
Ejemplo de código C#: Imprimir todos los archivos de Word de un directorio
A continuación se muestra una aplicación de consola completa que lee todos los archivos .docx y .doc de una carpeta y los imprime silenciosamente con un controlador de impresión estándar (sin cuadro de diálogo emergente). El código también muestra cómo manejar posibles excepciones con elegancia.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\DocumentosParaImprimir";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Filtrar solo a .docx y .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Imprimiendo: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Suprimir el cuadro de diálogo de impresión para una impresión silenciosa
printDoc.PrintController = new StandardPrintController();
// Opcionalmente establecer el nombre de la impresora y las copias
// printDoc.PrinterSettings.PrinterName = "Mi Impresora Especifica";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Error al imprimir {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Impresión por lotes completada.");
}
}
La lógica es sencilla: obtener todos los archivos del directorio, verificar la extensión, cargar cada uno en un objeto Document de Spire.Doc, acceder a su PrintDocument, establecer StandardPrintController para evitar el cuadro de diálogo de impresión de Windows y llamar a Print(). El bucle asegura que cada documento de Word válido se imprima secuencialmente.
La propiedad PrintDocument.PrinterSettings abre la puerta a un control detallado. Puede especificar la impresora exacta con PrinterName, establecer el número de copias, elegir un rango de páginas o habilitar la impresión a doble cara. Para una introducción más detallada, consulte Cómo imprimir documentos de Word en C#.
Comparación rápida: ¿Qué método de impresión por lotes se adapta mejor a usted?
| Método | ¿Requiere Word? | Silencioso / Sin ventanas emergentes | Mejor para |
|---|---|---|---|
| Clic derecho e imprimir | Sí | Posibles interrupciones | Tareas ocasionales |
| Arrastrar a acceso directo de impresora | Sí | Posibles interrupciones | Uso diario visual y rápido |
| Combinar e imprimir a PDF | Sí | Sí (una vez combinado) | Producir una sola impresión ordenada |
| Macro VBA | Sí | Sí, si está configurado | Carpetas personales repetitivas |
| Script de PowerShell | Sí (COM) | Sí | Tareas programadas del lado del servidor |
| Spire.Doc con C# | No | Sí, totalmente silencioso | Automatización e integración de servidores |
Reflexiones finales
La impresión por lotes de documentos de Word no tiene por qué ser una tarea pesada. Comience con los trucos integrados rápidos, adopte un script cuando necesite repetibilidad y pase a una biblioteca dedicada como Spire.Doc cuando su proyecto exija una solución robusta y sin Office. Cualquiera que sea la ruta que tome, los minutos que ahorre se sumarán rápidamente a horas de productividad recuperada. Ahora elija un método, cargue su carpeta y deje que la impresora haga el trabajo pesado.
Preguntas frecuentes
¿Puedo imprimir documentos de Word sin abrir cada uno?
Sí. Los métodos 4, 5 y 6 suprimen la interfaz de Word o funcionan sin ella por completo. Tanto el script de PowerShell como Spire.Doc imprimen silenciosamente en segundo plano, mientras que la macro VBA puede ocultar la ventana de la aplicación.
¿La impresión por lotes funciona con archivos .doc y .docx?
Absolutamente. Todos los métodos descritos aquí manejan tanto los formatos .doc heredados como los modernos .docx. Al usar Spire.Doc, la biblioteca lee sin problemas ambos formatos sin ninguna conversión.
¿Cómo selecciono una impresora específica al imprimir varios archivos?
Para los métodos manuales, establezca la impresora deseada como predeterminada antes de comenzar. Con el script de PowerShell y el ejemplo de C# de Spire.Doc, puede establecer programáticamente el nombre de la impresora dentro del código, lo que le brinda un control preciso sin cambiar los valores predeterminados del sistema.
Ver también
So drucken Sie mehrere Word-Dokumente gleichzeitig: 6 Methoden
Inhaltsverzeichnis
- Methode 1: Rechtsklick & Drucken über den Datei-Explorer
- Methode 2: Mehrere Word-Dateien per Drag & Drop über das Druckwarteschlangen-Fenster
- Methode 3: Word-Dateien für einen einheitlichen Druckauftrag zusammenführen
- Methode 4: Verwendung eines Word-Makros (VBA) zum Drucken aller Dokumente in einem Ordner
- Methode 5: Silent-Batch-Druck mit einem PowerShell-Skript
- Methode 6: Word-Dokumente in C# mit Spire.Doc drucken
- Kurzer Vergleich: Welche Batch-Druckmethode passt am besten zu Ihnen?
- Fazit
- Häufig gestellte Fragen (FAQs)
Das Drucken von Dutzenden von Verträgen, Berichten oder Rechnungen einzeln ist eine mühsame Zeitverschwendung. Egal, ob Sie Handouts für ein Meeting vorbereiten, juristische Dokumente erstellen oder einfach nur Ihren Büro-Schriftverkehr organisieren – die Möglichkeit, einen ganzen Ordner mit Word-Dateien auf einmal an den Drucker zu senden, kann Ihnen Stunden sparen.
Dieser Artikel führt Sie durch sechs praktische Methoden zum Batch-Druck von .doc- und .docx-Dateien – von mühelosen Rechtsklick-Tricks bis hin zu einer leistungsstarken, entwicklerorientierten Lösung mit Spire.Doc in C#. Wählen Sie die Methode, die zu Ihrem Arbeitsablauf passt, und drucken Sie ab heute intelligenter.
Überblick über die behandelten Methoden:
- Methode 1: Rechtsklick & Drucken über den Datei-Explorer
- Methode 2: Mehrere Word-Dateien per Drag & Drop über das Druckwarteschlangen-Fenster
- Methode 3: Word-Dateien für einen einheitlichen Druckauftrag zusammenführen
- Methode 4: Verwendung eines Word-Makros (VBA) zum Drucken aller Dokumente in einem Ordner
- Methode 5: Silent-Batch-Druck mit einem PowerShell-Skript
- Methode 6: Word-Dokumente in C# mit Spire.Doc drucken
Methode 1: Rechtsklick & Drucken über den Datei-Explorer
Die einfachste Methode erfordert keine zusätzlichen Tools und funktioniert sofort auf jedem Windows-PC. Sie ist perfekt geeignet, um schnell eine Handvoll Dokumente zu drucken, ohne Software installieren zu müssen. Wählen Sie einfach Ihre Dateien aus und lassen Sie Windows den Rest erledigen.
Schritte:
- Öffnen Sie den Datei-Explorer und navigieren Sie zu dem Ordner mit Ihren Word-Dokumenten.
- Wählen Sie die Dateien aus, die Sie drucken möchten: Halten Sie die Strg-Taste gedrückt und klicken Sie jede Datei einzeln an, oder drücken Sie Strg + A, um alle auszuwählen.
- Klicken Sie mit der rechten Maustaste auf eine der markierten Dateien und wählen Sie Drucken aus dem Kontextmenü.
Windows öffnet automatisch jedes Dokument in Microsoft Word, sendet es an Ihren Standarddrucker und schließt Word nach Abschluss des Vorgangs wieder. Beachten Sie, dass der Prozess bei Word-Sicherheitseinstellungen, die Makrowarnungen oder die geschützte Ansicht anzeigen, pausieren kann, bis Sie diese manuell bestätigen. Dennoch ist diese Methode für schnelle, gelegentliche Aufgaben kaum zu schlagen.
Methode 2: Mehrere Word-Dateien per Drag & Drop über das Druckwarteschlangen-Fenster
Dieser native Windows-Workflow per Drag & Drop ermöglicht den Batch-Druck mehrerer Word-Dokumente – ziehen Sie Ihre Dateien einfach auf eine Desktop-Verknüpfung Ihres Druckers. Dieser Ansatz erleichtert den Wechsel zwischen verschiedenen Druckern und ist ideal für Büroumgebungen mit mehreren Druckgeräten.
Schritte:
- Drücken Sie Win + R, geben Sie control printers ein und drücken Sie Enter, um das Fenster „Geräte und Drucker“ zu öffnen.
- Doppelklicken Sie auf das Symbol Ihres Zieldruckers, um dessen Druckwarteschlangen-Fenster zu öffnen.
- Wählen Sie alle gewünschten Word-Dateien aus und ziehen Sie diese per Drag & Drop direkt in den leeren Bereich des geöffneten Druckwarteschlangen-Fensters.
Die Dateien werden automatisch in die Liste der Druckaufträge aufgenommen. Windows öffnet, druckt und schließt jedes Dokument nacheinander.
Profi-Tipp: Sie können auch eine Desktop-Verknüpfung für den Drucker erstellen, um schneller darauf zuzugreifen, wobei das Ziehen in das Druckwarteschlangen-Fenster bei Batch-Aufgaben zuverlässigere Ergebnisse liefert.
Methode 3: Word-Dateien für einen einheitlichen Druckauftrag zusammenführen
Wenn Sie möchten, dass alle separaten Word-Dateien als ein kontinuierliches, geordnetes Dokument gedruckt werden, ist dieser Zusammenführungs-Workflow die optimale Lösung. Er funktioniert hervorragend für Handouts, formelle Berichte und Broschüren, die eine konsistente Seitennummerierung erfordern. Das Zusammenführen der Dateien vor dem Drucken erspart Ihnen das mühsame manuelle Sortieren der Seiten nach dem Druck.
Schritte:
- Starten Sie Microsoft Word und erstellen Sie ein leeres neues Dokument.
- Navigieren Sie zu Einfügen > Objekt > Text aus Datei (alternative Pfade: Einfügen > Datei oder erweitern Sie das Dropdown-Menü „Objekt“ in bestimmten Word-Versionen).
- Markieren Sie alle DOCX-Dateien, die zusammengeführt werden sollen, und klicken Sie auf Einfügen. Die Dateien werden in der von Ihnen gewählten Reihenfolge zusammengefügt.
- Drücken Sie Strg + P, um das Druckmenü zu öffnen. Wählen Sie entweder Ihren physischen Drucker oder Microsoft Print to PDF und bestätigen Sie den Druckvorgang.
Sie erhalten ein zusammenhängendes Dokument mit ununterbrochenem Seitenfluss. Obwohl das Zusammenführen etwas zusätzliche Zeit in Anspruch nimmt, verhindert es falsch sortierte Seiten und macht das manuelle Zusammenstellen überflüssig – ideal für gebundene Dokumente und gedruckte Handouts.
Methode 4: Verwendung eines Word-Makros (VBA) zum Drucken aller Dokumente in einem Ordner
Wenn Sie häufig Stapel von Dokumenten aus demselben Ordner drucken, kann ein einfaches VBA-Makro den Prozess vollständig automatisieren. Diese Methode läuft direkt in Microsoft Word, erfordert keine zusätzliche Software und kann für den Druck mit einem Klick eingerichtet werden. Es ist ein ideales integriertes Automatisierungstool für regelmäßige, wiederkehrende Druckaufgaben.
Schritte:
- Öffnen Sie Microsoft Word und drücken Sie Alt + F11, um den VBA-Editor zu öffnen.
- Gehen Sie zu Einfügen > Modul und fügen Sie den unten bereitgestellten, gebrauchsfertigen VBA-Code ein.
- Ersetzen Sie den Ordnerpfad im Code durch Ihr eigenes Verzeichnis.
- Drücken Sie F5, um das Makro auszuführen, oder weisen Sie es der Symbolleiste für den Schnellzugriff zu, um mit einem Klick zu drucken.
VBA-Code:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Ihr\Datei\Pfad\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Batch-Druck abgeschlossen!", vbInformation
End Sub
Diese Methode druckt Dateien im Hintergrund, ohne Fenster zu öffnen. Die einzigen Voraussetzungen sind das Aktivieren von Makros und die Installation von Word – perfekt für den zuverlässigen Einsatz im persönlichen oder bürointernen Bereich.
Methode 5: Silent-Batch-Druck mit einem PowerShell-Skript
PowerShell bietet eine schnelle, leichtgewichtige und skriptbasierte Möglichkeit, mehrere Word-Dokumente im Hintergrund zu drucken – ohne Fenster, ohne Pop-ups und ohne manuelle Interaktion. Diese Methode ist ideal für Benutzer, die einen vollautomatischen Druck wünschen, und kann sogar mit der Windows-Aufgabenplanung für automatische, zeitgesteuerte Aufträge geplant werden.
Schritte:
- Öffnen Sie PowerShell über das Startmenü (für grundlegendes Drucken sind keine Administratorrechte erforderlich).
- Kopieren Sie das unten bereitgestellte einfache Batch-Druck-Skript und fügen Sie es ein.
- Ändern Sie den Wert
$folderPathin Ihren Ziel-Dokumentenordner. - Führen Sie das Skript aus. Word läuft im Hintergrund, druckt alle Ihre Dokumente automatisch und schließt sich nach Abschluss sauber.
PowerShell-Skript:
$folderPath = "C:\Ihre\Dateien\Hier"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Batch-Druck abgeschlossen!"
Diese Methode funktioniert ohne zusätzliche Software, unterstützt alle Word-Formate und liefert zuverlässigen, lautlosen Batch-Druck für den persönlichen und geschäftlichen Gebrauch.
Methode 6: Word-Dokumente in C# mit Spire.Doc drucken
Wenn Sie eine vollautomatisierte, leistungsstarke Batch-Drucklösung benötigen, die auf einem Server ohne Microsoft Office läuft, ist Spire.Doc for .NET die erste Wahl. Es bietet Ihnen die vollständige programmatische Kontrolle über den Dokumentendruck, was es ideal für Webanwendungen, Hintergrunddienste oder Dokumentenmanagementsysteme macht.
Warum Spire.Doc für den Batch-Druck verwenden?
Spire.Doc ist eine eigenständige .NET-Bibliothek, die Word-Dateien liest, erstellt und manipuliert, ohne von Word selbst abhängig zu sein. Für den Batch-Druck bedeutet dies, dass Sie Tausende von Dokumenten zuverlässig auf einem Server verarbeiten, einen bestimmten Drucker auswählen, Seitenbereiche festlegen und sogar beidseitigen Druck steuern können – alles durch sauberen C#-Code.
Einrichten von Spire.Doc in Ihrem .NET-Projekt
Installieren Sie das Paket über den NuGet Package Manager:
Install-Package Spire.Doc
Oder verwenden Sie die .NET CLI: dotnet add package Spire.Doc. Das ist alles – keine zusätzlichen Office-Lizenzen oder Installationen erforderlich.
C#-Codebeispiel: Alle Word-Dateien aus einem Verzeichnis drucken
Unten sehen Sie eine vollständige Konsolenanwendung, die alle .docx- und .doc-Dateien aus einem Ordner liest und sie lautlos mit einem Standard-Druckcontroller (ohne Pop-up-Dialog) druckt. Der Code zeigt auch, wie man mögliche Ausnahmen elegant behandelt.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\ZuDruckendeDokumente";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Drucke: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Unterdrückt den Druckdialog für lautloses Drucken
printDoc.PrintController = new StandardPrintController();
// Optional: Druckername und Kopien festlegen
// printDoc.PrinterSettings.PrinterName = "Mein Drucker";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Fehler beim Drucken von {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Batch-Druck abgeschlossen.");
}
}
Die Logik ist einfach: Alle Dateien aus dem Verzeichnis abrufen, die Erweiterung prüfen, jede in ein Spire.Doc-Document-Objekt laden, auf dessen PrintDocument zugreifen, den StandardPrintController festlegen, um den Windows-Druckdialog zu vermeiden, und Print() aufrufen. Die Schleife stellt sicher, dass jedes gültige Word-Dokument nacheinander gedruckt wird.
Die Eigenschaft PrintDocument.PrinterSettings ermöglicht eine präzise Steuerung. Sie können den genauen Drucker mit PrinterName angeben, die Anzahl der Kopien festlegen, einen Seitenbereich auswählen oder den beidseitigen Druck aktivieren. Weitere Informationen finden Sie unter Wie man Word-Dokumente in C# druckt.
Kurzer Vergleich: Welche Batch-Druckmethode passt am besten zu Ihnen?
| Methode | Erfordert Word? | Lautlos / Keine Pop-ups | Am besten geeignet für |
|---|---|---|---|
| Rechtsklick & Drucken | Ja | Mögliche Unterbrechungen | Gelegentliche Einzelaufgaben |
| Drag & Drop auf Drucker | Ja | Mögliche Unterbrechungen | Visuelle, schnelle tägliche Nutzung |
| Zusammenführen & als PDF drucken | Ja | Ja (nach Zusammenführung) | Erstellung eines geordneten Ausdrucks |
| VBA-Makro | Ja | Ja, falls konfiguriert | Persönliche, wiederkehrende Ordner |
| PowerShell-Skript | Ja (COM) | Ja | Geplante serverseitige Aufgaben |
| Spire.Doc mit C# | Nein | Ja, vollkommen lautlos | Server-Automatisierung & Integration |
Fazit
Das Stapeldrucken von Word-Dokumenten muss keine lästige Pflicht sein. Beginnen Sie mit den schnellen integrierten Tricks, nutzen Sie ein Skript, wenn Sie Wiederholbarkeit benötigen, und steigen Sie auf eine dedizierte Bibliothek wie Spire.Doc um, wenn Ihr Projekt eine robuste, Office-freie Lösung erfordert. Welchen Weg Sie auch wählen, die Minuten, die Sie sparen, summieren sich schnell zu Stunden gewonnener Produktivität. Wählen Sie jetzt eine Methode, laden Sie Ihren Ordner und lassen Sie den Drucker die Arbeit erledigen.
Häufig gestellte Fragen (FAQs)
Kann ich Word-Dokumente drucken, ohne jedes einzeln zu öffnen?
Ja. Die Methoden 4, 5 und 6 unterdrücken die Word-Oberfläche oder funktionieren ganz ohne sie. Das PowerShell-Skript und Spire.Doc drucken beide lautlos im Hintergrund, während das VBA-Makro das Anwendungsfenster ausblenden kann.
Funktioniert der Batch-Druck mit .doc- und .docx-Dateien?
Absolut. Jede hier beschriebene Methode verarbeitet sowohl ältere .doc- als auch moderne .docx-Formate. Bei der Verwendung von Spire.Doc liest die Bibliothek beide Formate nahtlos ohne Konvertierung.
Wie wähle ich einen bestimmten Drucker aus, wenn ich mehrere Dateien drucke?
Bei den manuellen Methoden legen Sie vor dem Start Ihren gewünschten Drucker als Standard fest. Beim PowerShell-Skript und dem C#-Spire.Doc-Beispiel können Sie den Druckernamen programmatisch im Code festlegen, was Ihnen eine präzise Kontrolle ermöglicht, ohne die Systemeinstellungen zu ändern.
Siehe auch
Как распечатать несколько документов Word одновременно: 6 способов
Оглавление
- Способ 1: Правая кнопка мыши и печать из Проводника
- Способ 2: Перетаскивание нескольких файлов Word в окно очереди печати
- Способ 3: Объединение файлов Word для единого задания на печать
- Способ 4: Использование макроса Word (VBA) для печати всех документов в папке
- Способ 5: Фоновая пакетная печать с помощью скрипта PowerShell
- Способ 6: Печать документов Word на C# с использованием Spire.Doc
- Краткое сравнение: какой метод пакетной печати подходит вам лучше всего?
- Заключение
- Часто задаваемые вопросы
Печать десятков контрактов, отчетов или счетов по одному — это утомительная трата времени. Готовите ли вы раздаточные материалы для встречи, создаете юридические документы или просто наводите порядок в офисных бумагах, возможность отправить целую папку файлов Word на принтер за один раз может сэкономить вам часы работы.
В этой статье мы рассмотрим шесть практических методов пакетной печати файлов .doc и .docx — от простых приемов с правой кнопкой мыши до мощного решения для разработчиков на C# с использованием Spire.Doc. Выберите тот, который лучше всего подходит для вашего рабочего процесса, и начните печатать эффективнее уже сегодня.
Обзор рассматриваемых методов:
- Способ 1: Правая кнопка мыши и печать из Проводника
- Способ 2: Перетаскивание нескольких файлов Word в окно очереди печати
- Способ 3: Объединение файлов Word для единого задания на печать
- Способ 4: Использование макроса Word (VBA) для печати всех документов в папке
- Способ 5: Фоновая пакетная печать с помощью скрипта PowerShell
- Способ 6: Печать документов Word на C# с использованием Spire.Doc
Способ 1: Правая кнопка мыши и печать из Проводника
Самый простой метод, не требующий дополнительных инструментов и работающий мгновенно на любом ПК с Windows. Он идеально подходит для быстрой печати нескольких документов без установки какого-либо программного обеспечения. Просто выделите файлы, а остальное сделает Windows.
Шаги:
- Откройте Проводник и перейдите в папку с вашими документами Word.
- Выберите файлы, которые хотите распечатать: удерживайте клавишу Ctrl и щелкайте по каждому файлу отдельно или нажмите Ctrl + A, чтобы выбрать все.
- Нажмите правой кнопкой мыши на любой выделенный файл и выберите Печать в контекстном меню.
Windows автоматически откроет каждый документ в Microsoft Word, отправит его на принтер по умолчанию и закроет Word после завершения. Имейте в виду, что если настройки безопасности Word отображают предупреждения о макросах или защищенный просмотр, процесс может приостановиться до вашего подтверждения. Тем не менее, для быстрой разовой печати этот метод незаменим.
Способ 2: Перетаскивание нескольких файлов Word в окно очереди печати
Этот встроенный рабочий процесс Windows позволяет выполнять пакетную печать нескольких документов Word путем перетаскивания файлов на ярлык принтера. Такой подход упрощает переключение между разными принтерами, что идеально подходит для офисов, оснащенных несколькими печатающими устройствами.
Шаги:
- Нажмите Win + R, введите control printers и нажмите Enter, чтобы открыть окно «Устройства и принтеры».
- Дважды щелкните значок нужного принтера, чтобы открыть окно очереди печати.
- Выберите все нужные файлы Word и перетащите их прямо в пустую область открытого окна очереди печати.
Файлы автоматически добавятся в список заданий на печать. Windows будет открывать, печатать и закрывать каждый документ последовательно.
Совет: Вы также можете создать ярлык принтера на рабочем столе для быстрого доступа, хотя перетаскивание непосредственно в окно очереди печати дает более надежные результаты для пакетных задач.
Способ 3: Объединение файлов Word для единого задания на печать
Если вы хотите, чтобы все отдельные файлы Word были напечатаны как один непрерывный документ, этот метод объединения — оптимальное решение. Он отлично подходит для раздаточных материалов, официальных отчетов и брошюр, требующих последовательной нумерации страниц. Объединение файлов перед печатью избавляет от утомительной ручной сортировки страниц после вывода.
Шаги:
- Запустите Microsoft Word и создайте новый пустой документ.
- Перейдите в Вставка > Объект > Текст из файла (альтернативные пути: Вставка > Файл или разверните выпадающее меню «Объект» в некоторых версиях Word).
- Выделите все файлы DOCX для объединения и нажмите Вставка. Файлы соберутся в выбранном вами порядке.
- Нажмите Ctrl + P, чтобы открыть панель печати. Выберите ваш физический принтер или Microsoft Print to PDF, затем подтвердите печать.
Вы получите один связный документ с непрерывной нумерацией страниц. Хотя объединение занимает немного больше времени, оно предотвращает нарушение порядка страниц и исключает ручную сортировку — идеально для сброшюрованных документов и раздаточных материалов.
Способ 4: Использование макроса Word (VBA) для печати всех документов в папке
Если вы часто печатаете пакеты документов из одной и той же папки, простой VBA-макрос может полностью автоматизировать этот процесс. Этот метод работает непосредственно внутри Microsoft Word, не требует дополнительного ПО и может быть настроен для печати в один клик. Это идеальный встроенный инструмент автоматизации для регулярных повторяющихся задач печати.
Шаги:
- Откройте Microsoft Word и нажмите Alt + F11, чтобы открыть редактор VBA.
- Перейдите в Вставка > Модуль и вставьте готовый код VBA, приведенный ниже.
- Замените путь к папке в коде на свой собственный каталог.
- Нажмите F5 для запуска макроса или добавьте его на панель быстрого доступа для печати в один клик.
Код VBA:
Sub BatchPrintAllWordInFolder()
Const TargetFolder As String = "C:\Ваш\Путь\К\Файлу\"
Dim FileName As String
Dim Doc As Document
FileName = Dir(TargetFolder & "*.docx")
Do While FileName <> ""
Set Doc = Documents.Open(FileName:=TargetFolder & FileName, Visible:=False)
Doc.PrintOut
Doc.Close SaveChanges:=wdDoNotSaveChanges
FileName = Dir
Loop
MsgBox "Пакетная печать завершена!", vbInformation
End Sub
Этот метод печатает файлы в фоновом режиме без открытия окон. Единственные требования — включение макросов и установленный Word. Идеально подходит для надежного использования дома или в офисе.
Способ 5: Фоновая пакетная печать с помощью скрипта PowerShell
PowerShell предлагает быстрый и легкий способ печати нескольких документов Word в фоновом режиме — без окон, всплывающих сообщений и ручного взаимодействия. Этот метод идеален для пользователей, которым нужна полная автоматизация, и его даже можно запланировать через «Планировщик заданий Windows» для автоматического выполнения по расписанию.
Шаги:
- Откройте PowerShell из меню «Пуск» (права администратора для базовой печати не требуются).
- Скопируйте и вставьте приведенный ниже простой скрипт пакетной печати.
- Измените значение
$folderPathна путь к вашей папке с документами. - Запустите скрипт. Word будет работать в фоновом режиме, автоматически распечатает все документы и корректно закроется после завершения.
Скрипт PowerShell:
$folderPath = "C:\Ваши\Файлы\Здесь"
$word = New-Object -ComObject Word.Application
$word.Visible = $false
$word.DisplayAlerts = 0
Get-ChildItem -Path $folderPath -Filter *.docx | ForEach-Object {
$doc = $word.Documents.Open($_.FullName)
$doc.PrintOut()
$doc.Close()
}
$word.Quit()
[System.GC]::Collect()
[System.GC]::WaitForPendingFinalizers()
Write-Host "Пакетная печать завершена!"
Этот метод работает без дополнительного ПО, поддерживает все форматы Word и обеспечивает надежную фоновую печать как для личного, так и для офисного использования.
Способ 6: Печать документов Word на C# с использованием Spire.Doc
Когда вам нужно полностью автоматизированное высокопроизводительное решение для пакетной печати, работающее на сервере без установленного Microsoft Office, Spire.Doc for .NET — это идеальная библиотека. Она дает полный программный контроль над печатью документов, что делает ее идеальной для веб-приложений, фоновых служб или систем управления документами.
Почему стоит использовать Spire.Doc для пакетной печати?
Spire.Doc — это автономная библиотека .NET, которая читает, создает и редактирует файлы Word без какой-либо зависимости от самого Word. Для пакетной печати это означает, что вы можете надежно обрабатывать тысячи документов на сервере, выбирать конкретный принтер, задавать диапазоны страниц и даже настраивать двустороннюю печать — и все это с помощью чистого кода C#.
Настройка Spire.Doc в вашем проекте .NET
Установите пакет через NuGet Package Manager:
Install-Package Spire.Doc
Или используйте .NET CLI: dotnet add package Spire.Doc. Это все — никаких дополнительных лицензий или установок Office.
Пример кода на C#: Печать всех файлов Word из каталога
Ниже представлено консольное приложение, которое считывает все файлы .docx и .doc из папки и печатает их в фоновом режиме с использованием стандартного контроллера печати (без всплывающих диалоговых окон). Код также показывает, как корректно обрабатывать возможные исключения.
using Spire.Doc;
using System;
using System.Drawing.Printing;
using System.IO;
class BatchPrint
{
static void Main(string[] args)
{
string folderPath = @"C:\ДокументыДляПечати";
string[] wordFiles = Directory.GetFiles(folderPath, "*.doc*");
// Фильтр только для .docx и .doc
string[] allowedExtensions = { ".docx", ".doc" };
foreach (string filePath in wordFiles)
{
string ext = Path.GetExtension(filePath).ToLower();
if (Array.Exists(allowedExtensions, e => e == ext))
{
try
{
Console.WriteLine($"Печать: {Path.GetFileName(filePath)}");
Document doc = new Document();
doc.LoadFromFile(filePath);
PrintDocument printDoc = doc.PrintDocument;
// Отключение диалогового окна печати для фоновой печати
printDoc.PrintController = new StandardPrintController();
// Опционально: установка имени принтера и количества копий
// printDoc.PrinterSettings.PrinterName = "Мой Принтер";
// printDoc.PrinterSettings.Copies = 2;
printDoc.Print();
doc.Close();
}
catch (Exception ex)
{
Console.WriteLine($"Ошибка печати {filePath}: {ex.Message}");
}
}
}
Console.WriteLine("Пакетная печать завершена.");
}
}
Логика проста: получить все файлы из каталога, проверить расширение, загрузить каждый в объект Document библиотеки Spire.Doc, получить доступ к его PrintDocument, установить StandardPrintController, чтобы избежать появления окна печати Windows, и вызвать Print(). Цикл гарантирует, что каждый корректный документ Word будет напечатан последовательно.
Свойство PrintDocument.PrinterSettings открывает доступ к тонкой настройке. Вы можете указать конкретный принтер через PrinterName, задать количество копий, выбрать диапазон страниц или включить двустороннюю печать. Для более подробного ознакомления обратитесь к руководству Как печатать документы Word на C#.
Краткое сравнение: какой метод пакетной печати подходит вам лучше всего?
| Метод | Требуется Word? | Фоновый режим / Без окон | Лучше всего подходит для |
|---|---|---|---|
| Правая кнопка мыши | Да | Возможны прерывания | Разовые задачи |
| Перетаскивание на ярлык | Да | Возможны прерывания | Визуальное, ежедневное использование |
| Объединение и печать в PDF | Да | Да (после объединения) | Создание одного упорядоченного документа |
| VBA Макрос | Да | Да, если настроено | Личные повторяющиеся задачи |
| Скрипт PowerShell | Да (COM) | Да | Серверные задачи по расписанию |
| Spire.Doc на C# | Нет | Да, полностью фоновый | Серверная автоматизация и интеграция |
Заключение
Пакетная печать документов Word не обязательно должна быть рутиной. Начните с простых встроенных приемов, перейдите к скриптам, когда потребуется повторяемость, и используйте специализированную библиотеку, такую как Spire.Doc, когда ваш проект требует надежного решения без зависимости от Office. Какой бы путь вы ни выбрали, сэкономленные минуты быстро сложатся в часы продуктивной работы. Выберите метод, подготовьте папку и позвольте принтеру сделать всю тяжелую работу.
Часто задаваемые вопросы
Можно ли печатать документы Word, не открывая каждый из них?
Да. Методы 4, 5 и 6 либо подавляют интерфейс Word, либо работают без него вовсе. Скрипт PowerShell и Spire.Doc печатают в фоновом режиме, а макрос VBA может скрыть окно приложения.
Работает ли пакетная печать с файлами .doc и .docx?
Безусловно. Каждый описанный здесь метод поддерживает как старые форматы .doc, так и современные .docx. При использовании Spire.Doc библиотека бесшовно читает оба формата без необходимости конвертации.
Как выбрать конкретный принтер при печати нескольких файлов?
Для ручных методов установите нужный принтер по умолчанию перед началом работы. В скрипте PowerShell и примере на C# со Spire.Doc вы можете программно задать имя принтера внутри кода, что дает точный контроль без изменения системных настроек.
Смотрите также
Como converter tabelas do Word para CSV (DOC/DOCX para CSV)
Índice

CSV (Comma-Separated Values) é um formato leve e universalmente compatível para dados tabulares. Documentos do Word (DOC e DOCX), por outro lado, são documentos de texto rico que contêm parágrafos, imagens, cabeçalhos, formatação e tabelas. Como o CSV suporta apenas linhas e colunas, converter Word para CSV ou DOCX para CSV quase sempre significa extrair dados de tabelas do documento.
As organizações frequentemente precisam converter tabelas do Word ou DOCX para CSV ao mover dados estruturados para planilhas, bancos de dados, sistemas de CRM, ferramentas de análise ou fluxos de trabalho automatizados.
Este guia abrange dois métodos práticos para converter tabelas do Word para CSV, além de contexto importante sobre por que o Word não pode exportar CSV diretamente e quando os conversores online são apropriados.
Navegação Rápida
- Por que o Word não pode ser salvo diretamente como CSV
- Método 1 – Converter tabelas do Word para CSV usando software de planilha
- Você pode usar um conversor online de Word para CSV?
- Método 2 – Converter tabelas do Word para CSV automaticamente com Python
- FAQ
Qual Método Escolher?
| Método | Facilidade de Uso | Processamento em Lote | Privacidade | Melhor Para |
|---|---|---|---|---|
| Software de Planilha | Alta | Não | Alta | Conversões ocasionais, revisão manual |
| Python (Spire.Doc) | Média | Sim | Alta | Automação, processamento em lote, tarefas recorrentes |
1. Por que o Word não pode ser salvo diretamente como CSV
O Microsoft Word não oferece uma opção de "Salvar como CSV". Isso não é uma falha — reflete uma incompatibilidade fundamental de formato:
- Documentos do Word contêm conteúdo misto: parágrafos, imagens, cabeçalhos, rodapés, texto estilizado e tabelas. Um único documento pode ter várias seções, colunas e elementos aninhados.
- Arquivos CSV contêm apenas dados tabulares planos: linhas e colunas de texto simples separadas por vírgulas.
O Word não consegue determinar automaticamente como achatar um documento de texto rico em um layout tabular. Um documento com três parágrafos, uma imagem e uma tabela não se mapeia claramente em linhas e colunas. A única parte de um documento do Word que tem uma representação CSV natural é dados de tabela estruturados.
É por isso que todas as abordagens práticas para converter Word para CSV se concentram em extrair tabelas do documento — seja por meio de software de planilha, ferramentas online ou métodos programáticos.
2. Método 1 – Converter tabelas do Word para CSV usando software de planilha
A maneira mais direta de converter tabelas do Word para CSV é copiar a tabela para um aplicativo de planilha e exportá-la. Tanto o Microsoft Excel quanto o Google Sheets suportam este fluxo de trabalho.
O Fluxo de Trabalho
- Copie a tabela do Word para uma planilha — Selecione a tabela no Word, copie-a e cole-a em uma nova planilha
- Verifique os dados importados — Verifique se as linhas, colunas e valores das células estão corretamente separados. Observe as células mescladas, que podem causar desalinhamento
- Exporte como CSV — Salve ou baixe a planilha no formato CSV
Opção A – Microsoft Office
- Abra o documento do Word e copie a tabela que deseja exportar.
- Cole a tabela em uma planilha do Excel e verifique se as linhas e colunas foram importadas corretamente.
- Revise células mescladas, quebras de linha ou outros problemas de formatação que possam afetar a estrutura do CSV.
- Escolha Arquivo > Salvar como e salve a planilha como um arquivo CSV.
O Excel preserva bem a estrutura da tabela do Word — linhas e colunas se mapeiam corretamente na maioria dos casos. Se o seu documento contiver várias tabelas, você pode colar cada uma em uma planilha separada e salvar cada uma como um arquivo CSV individual.
Considerações:
- Células mescladas na tabela do Word podem causar desalinhamento após a colagem
- O Excel é executado localmente, portanto seus dados permanecem em sua máquina
- O processo é manual e não é prático para conversões frequentes ou em larga escala
Opção B – Google Sheets
- Copie a tabela do documento do Word (no Google Docs ou outros visualizadores de documentos).
- Cole-a em uma nova planilha do Google Sheets.
- Verifique a estrutura da tabela importada e ajuste quaisquer dados desalinhados.
- Baixe a planilha como um arquivo CSV usando Arquivo > Download > Valores Separados por Vírgula (.csv).
O Google Sheets é gratuito e requer apenas uma conta Google. Ele também facilita o compartilhamento e a revisão de dados com colaboradores antes de exportar para CSV.
Considerações:
- Os dados são armazenados nos servidores do Google durante a edição — considere isso para informações confidenciais
- Nenhuma instalação de software necessária
- Assim como o Excel, este é um processo manual sem suporte de automação
Quando Usar Este Método
A conversão baseada em planilha funciona bem quando você precisa ocasionalmente exportar dados de tabelas do Word para CSV e deseja revisar os dados antes de salvar. Para conversões recorrentes, vários documentos ou fluxos de trabalho automatizados, o método Python abaixo é mais eficiente.
Se você também precisar converter DOCX (documentos do Word) para XLSX, pode consultar nosso guia de conversão de Docx para XLSX para um fluxo de trabalho de planilha estruturado.
3. Você pode usar um conversor online de Word para CSV?
Sim. Vários sites oferecem ferramentas de conversor de Word para CSV que permitem fazer upload de um arquivo DOC ou DOCX e baixar um arquivo CSV. Estes são adequados para conversões rápidas e únicas quando você não quer instalar nenhum software.
No entanto, os conversores online têm limitações notáveis:
- Privacidade — Seu documento é carregado em um servidor de terceiros, o que pode não ser aceitável para dados confidenciais ou proprietários
- Limites de tamanho de arquivo — A maioria das ferramentas gratuitas restringe uploads a 5–10 MB
- Reconhecimento de tabela — Alguns conversores extraem apenas a primeira tabela; outros podem interpretar mal a estrutura do documento
- Sem processamento em lote — Você pode converter apenas um arquivo por vez
Para dados confidenciais, conversões recorrentes ou processamento em lote, métodos locais (software de planilha ou Python) são preferíveis.
4. Método 2 – Converter tabelas do Word para CSV automaticamente com Python
Se você precisar converter arquivos do Word para CSV regularmente, automatizar o processamento de documentos ou lidar com um grande número de arquivos, o Python oferece uma solução mais eficiente. Com o Spire.Doc for Python, você pode ler documentos do Word, extrair dados de tabelas e exportá-los diretamente para o formato CSV — tudo sem o Microsoft Word instalado.
Instalar Spire.Doc for Python
Instale a biblioteca via pip:
pip install spire.doc
Importe as classes necessárias em seu script Python:
from spire.doc import *
from spire.doc.common import *
Alternativamente, você pode baixar Spire.Doc for Python e integrá-lo manualmente.
Converter uma Tabela do Word para CSV
O exemplo a seguir carrega um documento do Word, extrai a primeira tabela, lê suas linhas e células e grava os dados em um arquivo CSV.
import csv
from spire.doc import *
from spire.doc.common import *
document = Document()
document.LoadFromFile("Sample.docx")
section = document.Sections.get_Item(0)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
csv_data = []
for r in range(table.Rows.Count):
row = table.Rows.get_Item(r)
row_data = []
for c in range(row.Cells.Count):
cell = row.Cells.get_Item(c)
paragraphs = []
for p in range(cell.Paragraphs.Count):
text = cell.Paragraphs.get_Item(p).Text.strip()
if text:
paragraphs.append(text)
row_data.append(" ".join(paragraphs))
csv_data.append(row_data)
csv_path = f"table_{t + 1}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
csv.writer(f).writerows(csv_data)
document.Close()
Como Funciona
Document.LoadFromFile()carrega o documento do Word na memória.section.Tables.get_Item(table_index)seleciona a tabela a ser exportada.- O script percorre cada linha e célula da tabela usando as coleções Rows e Cells.
- Cada célula da tabela pode conter um ou mais parágrafos. O script lê todos os parágrafos usando
cell.Paragraphse extrai seu conteúdo de texto. - O texto do parágrafo extraído é limpo com
.strip()e combinado em uma única string para o valor da célula CSV. csv.writer()exporta os dados da tabela coletados para um arquivo CSV padrão que pode ser aberto no Excel, Google Sheets, bancos de dados ou outras ferramentas de processamento de dados.
Resultado da Saída
Abaixo está uma prévia da tabela do Word e do arquivo CSV gerado:
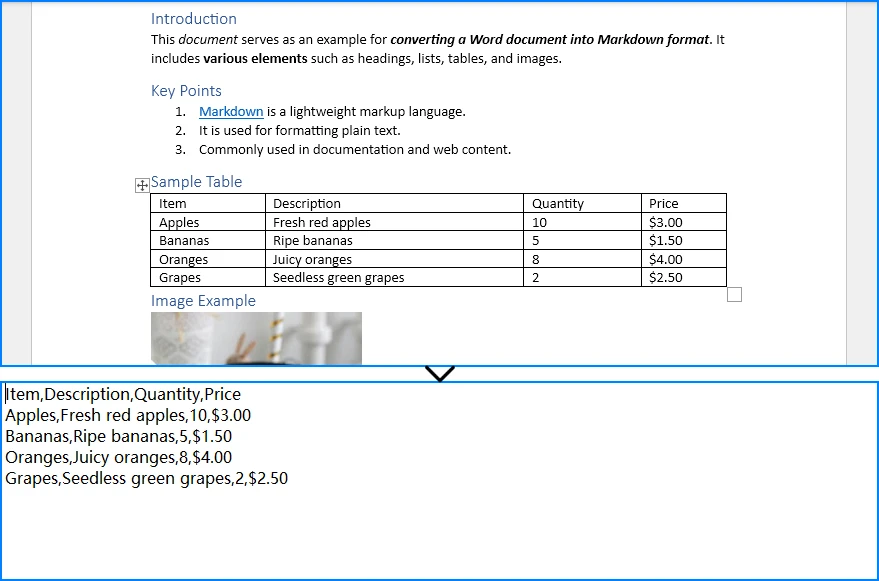
A saída é um arquivo .csv formatado corretamente contendo os dados da tabela do Word, pronto para importação no Excel, bancos de dados ou qualquer sistema que aceite entrada CSV.
Extrair Múltiplas Tabelas de um Documento do Word
Se o seu documento do Word contiver várias tabelas, itere por section.Tables e salve cada uma como um arquivo CSV separado:
for t in range(section.Tables.Count):
word_table_to_csv(
word_path,
f"table_{t + 1}.csv",
table_index=t
)
Converter em Lote Vários Arquivos do Word
Para processar uma pasta inteira de documentos do Word, itere pelos arquivos e extraia a primeira tabela de cada um:
for filename in os.listdir(input_folder):
if filename.lower().endswith((".doc", ".docx")):
word_table_to_csv(
os.path.join(input_folder, filename),
os.path.join(
output_folder,
os.path.splitext(filename)[0] + ".csv"
)
)
Por que Usar Python para Conversão de Word para CSV?
A automação com Python e Spire.Doc for Python oferece vantagens claras quando você precisa converter tabelas do Word para CSV em escala:
| Vantagem | Detalhes |
|---|---|
| Conversão em lote | Processe dezenas ou centenas de arquivos do Word em um único script |
| Automação | Agende conversões para serem executadas automaticamente — diariamente, semanalmente ou sob demanda |
| Grandes conjuntos de dados | Lide com documentos do Word com tabelas grandes que são impraticáveis de converter manualmente |
| Integração de fluxo de trabalho | Integre a conversão de Word para CSV em pipelines de dados, processos ETL ou fluxos de trabalho CI/CD |
| Sem dependência do Microsoft Word | Spire.Doc for Python funciona sem o Microsoft Word instalado |
| Precisão dos dados | A extração programática elimina erros de copiar e colar e garante resultados consistentes |
Para uso mais avançado, você também pode consultar nosso guia sobre extrair tabelas de documentos do Word usando Python.
5. FAQ
Posso converter Word para CSV diretamente?
Não. O Microsoft Word não tem uma opção integrada para salvar ou exportar documentos como CSV. A caixa de diálogo "Salvar como" do Word suporta formatos como DOCX, PDF, RTF, HTML e texto simples — mas não CSV. Para converter Word para CSV, você precisa extrair dados de tabelas do documento e gravá-los em um arquivo CSV usando software de planilha ou automação Python.
Por que o Word não pode salvar diretamente como CSV?
O Word é um formato de documento de texto rico que suporta parágrafos, imagens, cabeçalhos, estilos e conteúdo misto. CSV é um formato tabular plano que armazena apenas linhas e colunas de texto separadas por vírgulas. O Word não consegue determinar automaticamente como achatar uma estrutura de documento complexa em um layout tabular, portanto, não oferece CSV como opção de exportação. Apenas dados estruturados — tipicamente dados em tabelas do Word — podem ser convertidos significativamente para CSV.
Como converto uma tabela do Word para CSV?
Você tem duas opções principais: (1) Software de planilha — Copie a tabela do Word para o Excel ou Google Sheets, verifique os dados e salve ou baixe como CSV. Esta é a abordagem mais comum para uso ocasional. (2) Python — Use Spire.Doc for Python para ler o documento do Word, acessar a tabela programaticamente, extrair valores de células e gravá-los em um arquivo CSV. Isso é ideal para automação, processamento em lote e conversões recorrentes.
Posso converter DOCX para CSV sem o Excel?
Sim. Você pode converter DOCX para CSV sem o Excel usando: (1) Google Sheets — Cole os dados da tabela do Word em uma planilha do Google Sheets e baixe como CSV. (2) Ferramentas online — Faça upload do seu arquivo DOCX para um site conversor de Word para CSV e baixe o resultado. (3) Python — Use Spire.Doc for Python para ler o arquivo DOCX, extrair dados de tabelas e gravá-los em CSV. Isso funciona sem nenhum software do Microsoft Office instalado.
Existe um conversor gratuito de Word para CSV?
Sim. Existem opções gratuitas em duas categorias: (1) Conversores online — Muitos sites oferecem conversão gratuita de Word para CSV, embora geralmente tenham limites de tamanho de arquivo e levantem preocupações de privacidade, pois seus dados são carregados em um servidor de terceiros. (2) Scripts Python — Você pode escrever um script de conversão local e gratuito usando Spire.Doc for Python (que oferece uma versão gratuita) e o módulo csv integrado do Python. Isso mantém seus dados privados e não tem restrições de tamanho de arquivo.
Como extraio dados de um documento do Word para CSV em Python?
Use Spire.Doc for Python para carregar o documento do Word, acessar a tabela através das coleções Sections e Tables, iterar por linhas e células para ler o texto de cada célula e gravar os dados em um arquivo CSV usando o csv.writer padrão do Python. O exemplo de código completo é fornecido no Método 2 acima.
O Spire.Doc for Python requer que o Microsoft Word seja instalado?
Não. Spire.Doc for Python é uma biblioteca independente que cria, lê e manipula documentos do Word de forma independente. Ele não requer que o Microsoft Word ou qualquer componente do Office seja instalado em seu sistema. Isso o torna adequado para ambientes de servidor, fluxos de trabalho automatizados e máquinas onde o Office não está disponível.
Conclusão
Converter Word para CSV significa extrair dados de tabelas estruturadas de documentos DOC ou DOCX e salvá-los em um formato tabular. Software de planilha (Excel ou Google Sheets) fornece uma abordagem manual simples — copie a tabela do Word, verifique os dados e exporte como CSV. Isso funciona bem para conversões ocasionais, mas não escala para processamento em lote ou fluxos de trabalho recorrentes.
Automação com Python com Spire.Doc for Python oferece uma solução confiável para converter tabelas do Word para CSV programaticamente. Ele lê arquivos DOC e DOCX, extrai dados de tabelas com precisão e grava a saída CSV — tudo sem exigir o Microsoft Word. Para desenvolvedores e organizações que convertem regularmente arquivos DOC ou DOCX para CSV, Spire.Doc for Python oferece uma maneira confiável de automatizar todo o processo, preservando os dados da tabela com precisão.
Você pode solicitar uma licença gratuita de 30 dias para avaliar todos os recursos do Spire.Doc for Python.