Как конвертировать ODP в PPTX (4 простых способа)
Содержание

Если вы когда-либо работали с презентациями, вы, вероятно, сталкивались с файлами ODP — форматом OpenDocument Presentation, который обычно используется в офисных пакетах с открытым исходным кодом, таких как LibreOffice и OpenOffice. Хотя файлы ODP идеально подходят для редактирования в этих программах, они не всегда совместимы с Microsoft PowerPoint, который использует формат PPTX. Конвертирование ODP в PPTX гарантирует, что ваши слайды сохранят свое форматирование, при этом они будут полностью совместимы с PowerPoint для беспрепятственного сотрудничества и профессиональной подачи презентаций.
В этом пошаговом руководстве мы покажем вам 4 простых способа конвертировать ODP в PPTX, от офлайн-программ до онлайн-инструментов и автоматизации с помощью Python, чтобы вы могли выбрать лучший метод для своей рабочей среды.
Обзор методов
- Способ 1: Конвертирование ODP в PPTX с помощью LibreOffice Impress
- Способ 2: Преобразование ODP в PPTX с помощью Microsoft PowerPoint
- Способ 3: Использование онлайн-конвертеров ODP в PPTX
- Способ 4: Использование Python для пакетного преобразования ODP в PPTX
Понимание форматов: ODP против PPTX
Перед конвертацией полезно знать ключевые различия между ODP и PPTX:
- ODP (OpenDocument Presentation): Открытый стандартный формат, используемый в основном в LibreOffice Impress и OpenOffice. Поддерживает слайды, текст, изображения, диаграммы, таблицы и базовую анимацию.
- PPTX (PowerPoint Presentation): Стандартный формат Microsoft PowerPoint. Широко поддерживается и предлагает расширенные функции, такие как SmartArt, переходы, мультимедиа и полную совместимость с экосистемой Microsoft 365.
Конвертирование ODP в PPTX необходимо при совместной работе в средах, где PowerPoint является стандартом, гарантируя, что презентации останутся доступными при сохранении форматирования и функциональности.
Способ 1: Конвертирование ODP в PPTX с помощью LibreOffice Impress
LibreOffice Impress нативно поддерживает файлы ODP и включает встроенную функцию «Сохранить как», которая позволяет конвертировать ODP в PPTX. Этот метод идеально подходит для пользователей, которые предпочитают офлайн-решения, не полагаясь на Microsoft Office.
Пошаговые инструкции:
-
Запустите LibreOffice Impress.
-
Нажмите Файл > Открыть и выберите ваш файл .odp.
-
Перейдите в меню Файл > Сохранить как… или нажмите Ctrl + Shift + S.
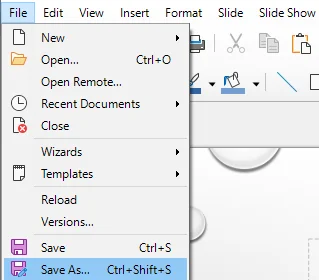
-
В выпадающем меню Тип файла выберите PowerPoint 2007-365 (.pptx).
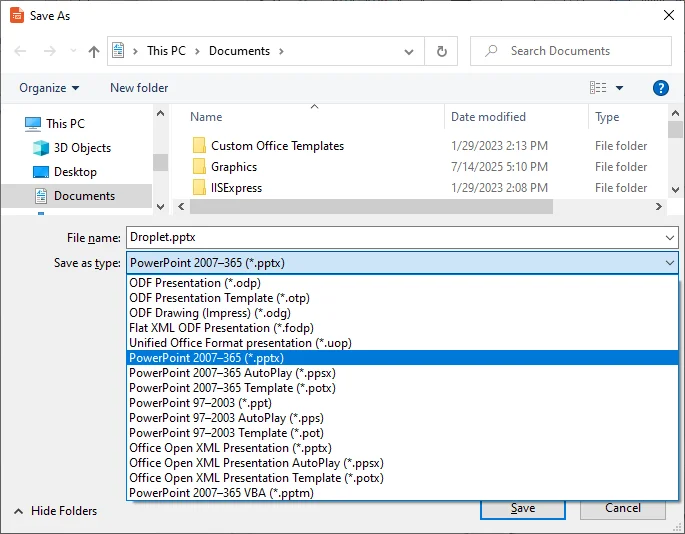
-
Выберите папку назначения, назовите файл и нажмите Сохранить.
-
LibreOffice может предупредить вас, что некоторое форматирование или содержимое может быть не полностью совместимо в выбранном формате. Нажмите Использовать PowerPoint 2007-365 (.pptx), чтобы продолжить.
Преимущества:
- Бесплатно и офлайн, интернет не требуется.
- Сохраняет большую часть форматирования, включая изображения, таблицы и макет слайдов.
Недостатки:
- Сложная анимация или SmartArt могут не передаваться идеально.
- Пакетное преобразование требует написания скриптов или ручных действий.
Способ 2: Преобразование ODP в PPTX с помощью Microsoft PowerPoint
Современные версии Microsoft PowerPoint (2013+) могут открывать файлы ODP напрямую и сохранять их в формате PPTX. Этот метод идеально подходит для пользователей, которые уже используют PowerPoint для редактирования и показа слайдов.
Пошаговые инструкции:
-
Откройте Microsoft PowerPoint.
-
Нажмите Файл > Открыть, затем выберите ваш файл .odp. PowerPoint автоматически загрузит ваши слайды.
-
Просмотрите ваши слайды на наличие проблем с форматированием или мультимедиа.
-
Нажмите Файл > Сохранить как, выберите Презентация PowerPoint (*.pptx) и сохраните.
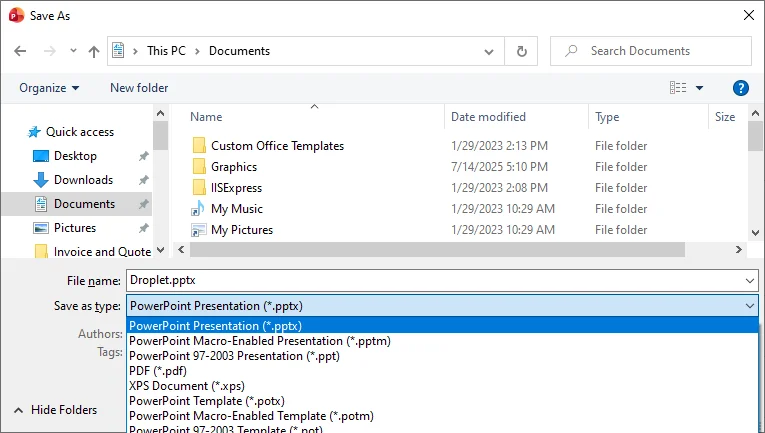
Преимущества:
- Нативная поддержка PowerPoint обеспечивает высокую совместимость.
- Позволяет немедленно редактировать перед сохранением.
Недостатки:
- Требуется лицензионная версия Microsoft PowerPoint.
- Некоторые функции ODP могут некорректно отображаться в PowerPoint.
Способ 3: Использование онлайн-конвертеров ODP в PPTX
Для пользователей, ищущих быстрое, не зависящее от платформы решение без хлопот с установкой программного обеспечения, онлайн-конвертеры ODP в PPTX предлагают бесплатную и эффективную альтернативу. Эти инструменты особенно полезны для разовых конвертаций на общих компьютерах или мобильных устройствах.
Авторитетные сервисы в этой области включают Convertio, Zamzar и OnlineConvert, которые известны своей надежностью и широкой поддержкой форматов.
Шаги по конвертации ODP в PPTX онлайн:
-
Откройте выбранный вами сайт онлайн-конвертера ODP в PPTX, например, Convertio.
-
Загрузите ваш файл .odp.
-
Выберите PPTX в качестве целевого формата.
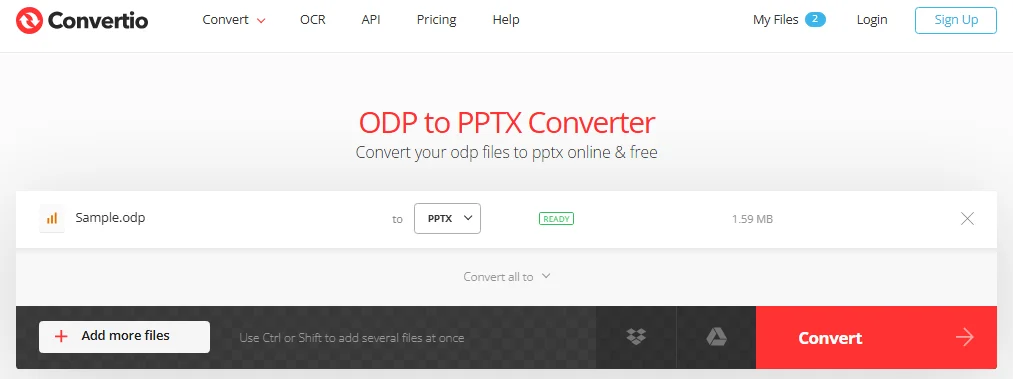
-
Нажмите Конвертировать, затем скачайте полученный файл .pptx.
Примечание: Всегда проверяйте политику конфиденциальности сайта. Для конфиденциальных деловых презентаций безопаснее использовать офлайн-настольное программное обеспечение (например, LibreOffice или Microsoft PowerPoint), чтобы гарантировать, что данные останутся на вашем локальном компьютере.
Преимущества:
- Установка не требуется, работает на разных устройствах.
- Быстро для конвертации одного файла.
Недостатки:
- Для работы требуется стабильное подключение к Интернету.
- Бесплатные тарифы часто ограничивают размер файла (например, максимум 50 МБ) или ежедневное использование.
- Конфиденциальные файлы могут вызывать опасения по поводу конфиденциальности.
Способ 4: Использование Python для пакетного преобразования ODP в PPTX
Для разработчиков или команд, работающих с несколькими презентациями, Python предоставляет мощное и автоматизированное решение. Используя такие библиотеки, как Spire.Presentation для Python, вы можете эффективно выполнять пакетное преобразование из ODP в PPTX, экономя часы ручной работы. Этот метод идеально подходит для корпоративных рабочих процессов или повторяющихся задач конвертации.
Что такое Spire.Presentation и почему стоит его выбрать?
Spire.Presentation — это библиотека Python, которая позволяет разработчикам создавать, читать и программно конвертировать файлы презентаций. Его преимущества для конвертации ODP в PPTX включают:
- Пакетная обработка: Конвертируйте несколько файлов ODP одновременно с минимальным количеством кода.
- Сохраняет форматирование: Сохраняет слайды, изображения, таблицы и базовую анимацию.
- Кроссплатформенность: Работает на Windows, Linux или macOS.
- Подходит для автоматизации: Может быть интегрирован в скрипты, запланированные задачи или конвейеры CI/CD.
- Без зависимостей: Работает независимо, не требуя установки MS Office, LibreOffice или аналогичного программного обеспечения.

Требования к установке
Чтобы использовать Spire.Presentation в Python, установите его через pip:
pip install spire-presentation
Убедитесь, что на вашей системе установлен Python 3.7+.
Пример Python для пакетного конвертирования ODP в PPTX
После установки библиотеки добавьте следующий код для пакетного преобразования нескольких файлов ODP в PPTX:
from spire.presentation import *
import os
def BatchConvertOdpToPptx(InputFolder, OutputFolder):
"""
Пакетно конвертирует все файлы ODP в папке InputFolder в формат PPTX в папке OutputFolder.
Использует Spire.Presentation для Python.
"""
# Создать выходную папку, если она не существует
if not os.path.exists(OutputFolder):
os.makedirs(OutputFolder)
# Перебрать все файлы во входной папке
for file in os.listdir(InputFolder):
# Проверить, имеет ли файл расширение ODP (без учета регистра)
if file.lower().endswith(".odp"):
# Сформировать полный путь к входному файлу
InputPath = os.path.join(InputFolder, file)
# Сформировать путь к выходному файлу, заменив расширение файла на .pptx
OutputPath = os.path.join(OutputFolder, os.path.splitext(file)[0] + ".pptx")
# Создать экземпляр Presentation
presentation = Presentation()
# Загрузить файл ODP
presentation.LoadFromFile(InputPath, FileFormat.ODP)
# Конвертировать и сохранить как PPTX
presentation.SaveToFile(OutputPath, FileFormat.PPTX)
print(f"Файл '{file}' успешно сконвертирован в PPTX.")
# Пример использования
BatchConvertOdpToPptx("C:/ODP_Files", "C:/PPTX_Output")
Совет: После конвертации вы можете дополнительно настроить выходные файлы PPTX, например, изменив размер слайда и применив анимацию.
Преимущества:
- Идеально подходит для пакетных конвертаций.
- Полностью автоматизирован, сокращает ручной труд.
Недостатки:
- Требует настройки Python и некоторых знаний в области написания скриптов.
- Первоначальная настройка может быть технически сложной для новичков.
Сравнение: Какой метод конвертации ODP в PPTX выбрать
Вот краткое сравнение 4 методов конвертации ODP в PPTX:
| Метод | Качество | Скорость | Конфиденциальность | Лучше всего подходит для |
|---|---|---|---|---|
| LibreOffice Impress | Отличное | Быстро | Высокое | Бесплатная офлайн-конвертация |
| Microsoft PowerPoint | Отличное | Быстро | Высокое | Редактирование и нативная конвертация |
| Онлайн-конвертеры | Хорошее | Зависит от Интернета | Низкое | Быстрая конвертация одного файла |
| Скрипт Python | Отличное | Очень быстро (пакетное) | Высокое | Пакетная конвертация и автоматизация |
Устранение распространенных проблем с ODP в PPTX
Хотя конвертация ODP в PPTX обычно проста, некоторые сложные файлы все же могут вызывать проблемы. Вот наиболее распространенные проблемы и способы их решения:
- Потеря форматирования: Сложная анимация, диаграммы или SmartArt могут конвертироваться не идеально. Просмотрите свои слайды и при необходимости скорректируйте содержимое.
- Отсутствующие шрифты: Убедитесь, что все шрифты, используемые в файле ODP, установлены на вашем компьютере, чтобы избежать изменений макета.
- Поврежденные файлы: Перед конвертацией убедитесь, что файлы ODP не повреждены или не загружены частично.
- Неподдерживаемые медиа: Видео или аудио могут не передаваться. При необходимости вставьте или добавьте медиа напрямую в PowerPoint.
Заключение
Теперь у вас есть полный набор инструментов для конвертации ODP в PPTX. Лучший метод зависит от ваших потребностей:
- Для периодических офлайн-конвертаций: Используйте LibreOffice или Microsoft PowerPoint для надежных результатов, сохраняющих большую часть форматирования.
- Для быстрых разовых конвертаций: Онлайн-конвертеры удобны, когда вы не хотите устанавливать какое-либо программное обеспечение.
- Для пакетных или корпоративных рабочих процессов: Автоматизация с помощью Python — самое быстрое и масштабируемое решение для последовательной обработки нескольких файлов.
Выберите метод, который подходит для вашего рабочего процесса, и убедитесь, что ваши презентации остаются профессиональными, совместимыми и готовыми к обмену.
Часто задаваемые вопросы об ODP в PPTX
В1: Могу ли я конвертировать ODP в PPTX без потери анимации?
О1: Простая анимация обычно передается, но сложная или пользовательская анимация может потребовать ручной корректировки.
В2: Безопасны ли онлайн-конвертеры ODP в PPTX для конфиденциальных презентаций?
О2: Не всегда. Для конфиденциальных файлов рекомендуется использовать офлайн-инструменты, такие как LibreOffice или PowerPoint.
В3: Могу ли я пакетно конвертировать несколько файлов ODP в PPTX?
О3: Да, Python с Spire.Presentation позволяет автоматизировать пакетное преобразование.
В4: Будет ли сконвертированный PPTX открываться во всех версиях PowerPoint?
О4: Файлы PPTX совместимы с PowerPoint 2007 и более поздними версиями, хотя некоторые расширенные функции могут отличаться в более старых версиях.
См. также
Ordenar dados no Excel: 5 métodos simples e avançados explicados
Índice
- Antes de começar
- Método 1: Classificar dados por uma única coluna no Excel (Rápido e essencial)
- Método 2: Classificar dados por várias colunas no Excel (Classificação personalizada)
- Método 3: Classificar dados no Excel usando fórmulas (SORT e SORTBY)
- Método 4: Classificar dados filtrados no Excel (Exploração flexível)
- Método 5: Classificar dados do Excel usando Python (Automação e escalabilidade)
- Tabela comparativa: Qual método escolher
- Considerações finais
- Perguntas frequentes (FAQs)

Classificar dados no Excel é uma habilidade essencial para organizar, analisar e compreender informações. Esteja você trabalhando com listas de clientes, relatórios financeiros ou grandes conjuntos de dados, a classificação ajuda a identificar rapidamente padrões, tendências e valores discrepantes.
Neste guia, você aprenderá 5 maneiras práticas de classificar dados no Excel, incluindo classificação por coluna única, classificação por várias colunas, classificação dinâmica baseada em fórmulas e automação usando Python.
Navegação rápida
- Método 1: Classificar dados por uma única coluna no Excel (Rápido e essencial)
- Método 2: Classificar dados por várias colunas no Excel (Classificação personalizada)
- Método 3: Classificar dados no Excel usando fórmulas (SORT e SORTBY)
- Método 4: Classificar dados filtrados no Excel (Exploração flexível)
- Método 5: Classificar dados do Excel usando Python (Automação e escalabilidade)
Antes de começar
Antes de classificar dados no Excel, certifique-se de que:
- Seu conjunto de dados inclui uma linha de cabeçalho
- Não há linhas ou colunas completamente em branco no meio
- Cada coluna contém tipos de dados consistentes (por exemplo, números, datas, texto)
Essas verificações ajudam a evitar erros de classificação e desalinhamento de dados.
Método 1: Classificar dados por uma única coluna no Excel (Rápido e essencial)
A ferramenta de classificação integrada é a maneira mais rápida de classificar dados por uma única coluna. É ideal para tarefas simples, como classificar nomes em ordem alfabética ou números do menor para o maior.
Instruções passo a passo:
- Selecione a única coluna que deseja classificar.
- Vá para a guia Dados na faixa de opções do Excel.
- Clique em Classificar de A a Z (ordem crescente: A→Z, 1→100) ou Classificar de Z a A (ordem decrescente: Z→A, 100→1).
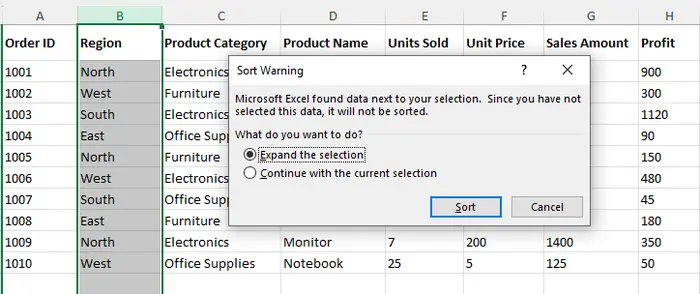
- Uma janela pop-up aparecerá: Expandir a seleção. Mantenha esta opção marcada.
- Clique em Classificar para concluir o processo.
Dica profissional:
- A opção Expandir a seleção garante que todos os dados relacionados nas colunas adjacentes sejam classificados junto com a coluna selecionada. Na maioria dos casos, você deve manter essa opção marcada para evitar quebrar as relações dos dados.
- Se seus dados tiverem uma linha de cabeçalho (por exemplo, "Nome", "E-mail"), marque a caixa Meus dados contêm cabeçalhos na janela pop-up. Isso evita que o Excel classifique o próprio cabeçalho (por exemplo, "Nome" não irá parar no final da coluna).
Método 2: Classificar dados por várias colunas no Excel (Classificação personalizada)
Para conjuntos de dados mais complexos, classificar por uma única coluna não é suficiente. Por exemplo, você pode querer classificar os dados de vendas primeiro por "Região" (crescente) e depois por "Valor da Venda" (decrescente) para ver os melhores desempenhos em cada região. É aqui que entra a Classificação Personalizada.
Instruções passo a passo:
- Selecione qualquer célula dentro do seu conjunto de dados (isso garante que o Excel reconheça a tabela inteira).
- Vá para a guia Dados e clique em Classificar (não nos botões A→Z/Z→A).
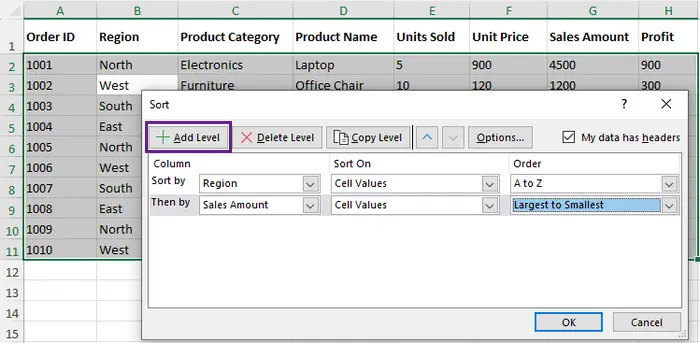
- Na janela Classificação Personalizada:
- Escolha a primeira coluna (por exemplo, "Região") e defina a ordem como De A a Z.
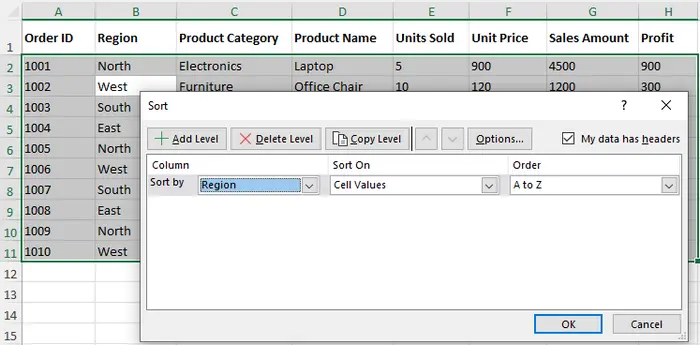
- Clique em Adicionar Nível para adicionar outra coluna (por exemplo, "Valor da Venda") e defina a ordem como Do Maior para o Menor.
- Escolha a primeira coluna (por exemplo, "Região") e defina a ordem como De A a Z.
- Clique em OK para aplicar a classificação. Seus dados agora estarão organizados pela coluna "Região", com empates resolvidos pela coluna "Valor da Venda".
Insight principal:
O Excel aplica a classificação hierarquicamente — ele classifica pela primeira coluna e, em seguida, resolve os empates usando a próxima coluna.
Caso de uso:
- Relatórios de vendas (Região → Receita)
- Listas de funcionários (Departamento → Cargo)
- Inventário (Categoria → Nível de estoque)
Método 3: Classificar dados no Excel usando fórmulas (SORT e SORTBY)
Se seus dados são atualizados com frequência, a classificação manual torna-se ineficiente. Fórmulas do Excel como SORT (CLASSIFICAR) e SORTBY (CLASSIFICARPOR) permitem criar listas classificadas dinâmicas e de atualização automática.
Ao contrário da classificação tradicional, essas funções não modificam os dados originais. Em vez disso, elas geram uma cópia classificada dinamicamente que é atualizada automaticamente.
Usando a função SORT (Mais simples para o Excel moderno)
A função SORT classifica um intervalo de dados e retorna uma nova matriz classificada. Sintaxe: =SORT(matriz, [índice_classificação], [ordem_classificação], [por_coluna])
- Em uma célula vazia (por exemplo, J1), insira a fórmula: =SORT(A1:H11, 1, -1, FALSE)
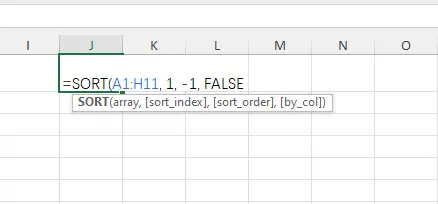
- A1:H11: O conjunto de dados inteiro que você deseja classificar.
- 1: A coluna pela qual classificar.
- -1: Ordem de classificação (1 = crescente, -1 = decrescente).
- FALSE: Classificar por linhas (padrão; use TRUE para classificar por colunas).
- Pressione Enter. O Excel gerará uma lista classificada dinâmica no intervalo começando em J1. Se você atualizar os dados originais (por exemplo, alterar um valor de venda), a lista classificada será atualizada automaticamente.
Usando a função SORTBY (Mais flexível)
=SORTBY(A1:H11, G1:G11, -1)
A função SORTBY classifica um conjunto de dados com base nos valores em um ou mais intervalos separados. Ao contrário da função SORT, que depende das posições das colunas, a SORTBY permite definir exatamente qual intervalo controla a ordem de classificação.
Como funciona:
- A1:H11 → O conjunto de dados a ser retornado (a tabela completa)
- G1:G11 → O intervalo usado como chave de classificação (por exemplo, "Valor da Venda")
- -1 → Ordem de classificação (1 = crescente, -1 = decrescente)
Exemplo de caso de uso:
Classificar uma tabela de vendas por receita sem alterar o conjunto de dados original.
Método 4: Classificar dados filtrados no Excel (Exploração flexível)
Os filtros permitem explorar e classificar rapidamente subconjuntos específicos de seus dados sem alterar permanentemente o conjunto de dados original. Isso é especialmente útil ao trabalhar com grandes conjuntos de dados, como analisar vendas de uma região ou período específico.
Instruções passo a passo:
- Selecione seu conjunto de dados, incluindo a linha de cabeçalho.
- Vá para a guia Dados e clique em Filtro (ou use o atalho: Ctrl+Shift+L). Pequenas setas suspensas aparecerão em cada célula de cabeçalho.
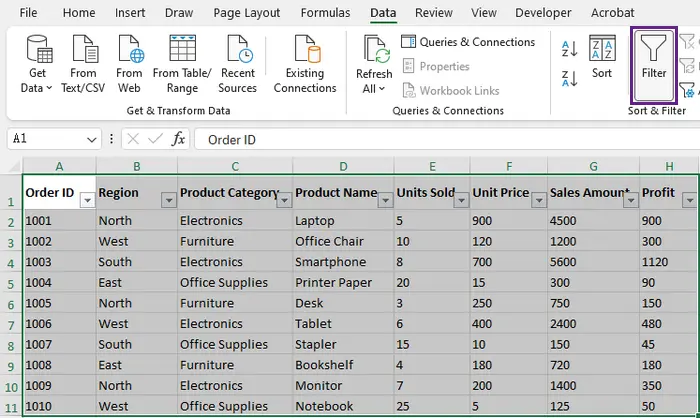
- Clique na seta suspensa na coluna que deseja classificar (por exemplo, "Região"), desmarque as regiões que não precisa (por exemplo, "Leste", "Norte", "Sul") e clique em OK.
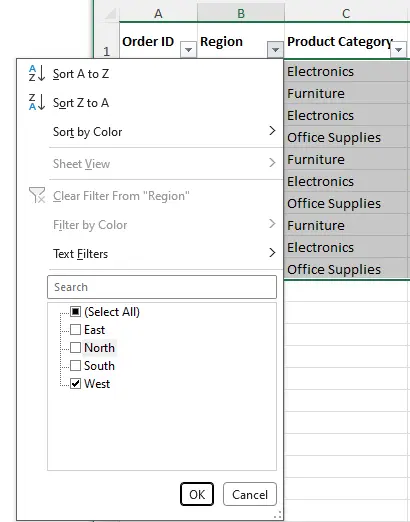
- Clique na seta suspensa na coluna Valor da Venda e escolha Classificar do Menor para o Maior (crescente) ou Classificar do Maior para o Menor (decrescente). Isso classificará apenas as linhas filtradas (visíveis).
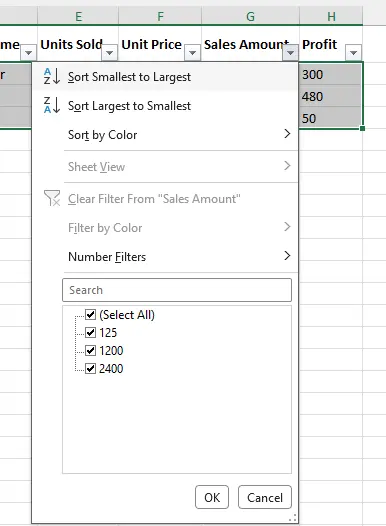
- Para remover o filtro e retornar ao conjunto de dados original, clique em Filtro novamente (ou Ctrl+Shift+L).
Vantagem principal:
Os filtros permitem combinar a classificação com a filtragem de dados, facilitando a exploração de subconjuntos específicos (por exemplo, classificar vendas de alto valor apenas na região específica) sem alterar a estrutura original dos dados.
Método 5: Classificar dados do Excel usando Python (Automação e escalabilidade)
Para grandes conjuntos de dados (mais de 10.000 linhas) ou tarefas de classificação repetitivas (por exemplo, classificar relatórios diários do Excel), a automação com Python é um divisor de águas. Usaremos o Spire.XLS for Python — uma biblioteca poderosa que simplifica a manipulação de arquivos do Excel, incluindo a classificação, sem a necessidade de ter o Excel instalado em sua máquina.
Pré-requisitos:
- Instale o Spire.XLS for Python: Execute pip install Spire.XLS no seu terminal/prompt de comando.
- Prepare seu arquivo Excel de entrada (por exemplo, "Input.xlsx") com os dados que deseja classificar.
Código Python passo a passo (com explicações):
from spire.xls.common import *
from spire.xls import *
# Criar uma instância de Workbook
workbook = Workbook()
# Carregar o arquivo Excel de entrada
workbook.LoadFromFile("Input.xlsx")
# Obter a primeira planilha
worksheet = workbook.Worksheets[0]
# Definir a regra de classificação: Classificar a Coluna B (índice 1) pelos valores em ordem crescente
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Especificar o intervalo de células a ser classificado
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Salvar os dados classificados em um novo arquivo Excel
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Como personalizar o código:
- Classificar uma coluna diferente: Altere o primeiro parâmetro em Add() (por exemplo, 0 para a Coluna A, 1 para a Coluna B).
- Classificação decrescente: Substitua OrderBy.Ascending por OrderBy.Descending.
- Classificar um intervalo maior: Modifique worksheet["A1:H11"] (por exemplo, worksheet["A1:G1000"] para 1000 linhas, 7 colunas).
- Várias colunas: Adicione uma segunda regra de classificação com workbook.DataSorter.SortColumns.Add() (por exemplo, classificar a Coluna A de forma crescente e, em seguida, a Coluna B de forma decrescente).
Caso de uso:
Este método é perfeito para automatizar tarefas repetitivas — por exemplo, classificar mais de 50 arquivos do Excel diariamente ou classificar conjuntos de dados grandes demais para o Excel lidar sem problemas.
Além de classificar dados, você também pode usar Python para automatizar outras tarefas do Excel, como formatar planilhas, aplicar estilos e exportar arquivos do Excel para PDF. Esses recursos facilitam a criação de fluxos de trabalho completos de processamento de documentos.
Tabela comparativa: Qual método escolher
| Método | Melhor para | Prós | Contras |
|---|---|---|---|
| Classificação integrada | Classificação rápida de coluna única | Fácil de usar, sem necessidade de configuração | Limitado à classificação básica; manual |
| Classificação personalizada | Classificação hierárquica de várias colunas | Flexível, lida com conjuntos de dados complexos | Requer alguns passos extras |
| Fórmulas do Excel | Listas classificadas dinâmicas e de atualização automática | Sem reclassificação manual; atualiza com os dados | Função SORT disponível apenas no Excel moderno |
| Filtros | Classificação temporária/exploração de subconjuntos | Não destrutivo; combina com filtragem | Não é ideal para classificação permanente |
| Python (Spire.XLS) | Grandes conjuntos de dados, automação | Escalável, tarefas repetitivas, sem necessidade de Excel | Requer conhecimento básico de Python |
Considerações finais
Classificar no Excel é mais do que apenas organizar dados — trata-se de tornar as informações utilizáveis e significativas.
- Use a classificação integrada para tarefas rápidas
- Use a classificação personalizada para análises estruturadas
- Use fórmulas para resultados dinâmicos
- Use filtros para exploração flexível
- Use Python para automação em escala
Dominar esses métodos permitirá que você lide com tudo, desde planilhas simples até fluxos de trabalho de dados complexos com facilidade.
Perguntas frequentes (FAQs)
P1: Por que meus dados do Excel ficam desalinhados após a classificação?
Isso geralmente acontece quando a opção Expandir a seleção não é selecionada. Sempre certifique-se de que as colunas relacionadas estejam incluídas ao classificar.
P2: Posso classificar por cor de célula ou cor de fonte?
Sim. Na caixa de diálogo Classificar, escolha Cor da Célula ou Cor da Fonte em "Classificar por".
P3: Posso classificar dados com células em branco?
Sim. O Excel coloca os espaços em branco na parte inferior (crescente) ou superior (decrescente). Você pode filtrá-los, se necessário.
P4: Como desfaço uma classificação?
Pressione Ctrl + Z imediatamente após classificar. Se você fez outras alterações, o desfazer pode não estar disponível.
P5: Por que a classificação do Excel não está funcionando?
As causas comuns incluem:
- Tipos de dados mistos
- Linhas ou colunas ocultas
- Intervalo de seleção incorreto
Veja também
Excel에서 데이터 정렬: 5가지 간단하고 고급화된 방법 설명
Excel에서 데이터를 정렬하는 것은 정보를 정리, 분석 및 이해하는 데 필수적인 기술입니다. 고객 목록, 재무 보고서 또는 대규모 데이터 세트를 다룰 때 정렬을 사용하면 패턴, 추세 및 이상치를 빠르게 파악할 수 있습니다.
이 가이드에서는 단일 열 정렬, 다중 열 정렬, 동적 수식 기반 정렬, Python을 사용한 자동화를 포함하여 Excel에서 데이터를 정렬하는 5가지 실용적인 방법을 배웁니다.
빠른 탐색
- 방법 1: Excel에서 단일 열로 데이터 정렬 (빠르고 필수적인 방법)
- 방법 2: Excel에서 여러 열로 데이터 정렬 (사용자 지정 정렬)
- 방법 3: 수식을 사용하여 Excel 데이터 정렬 (SORT 및 SORTBY)
- 방법 4: Excel에서 필터링된 데이터 정렬 (유연한 탐색)
- 방법 5: Python을 사용하여 Excel 데이터 정렬 (자동화 및 확장성)
시작하기 전에
Excel에서 데이터를 정렬하기 전에 다음 사항을 확인하세요:
- 데이터 세트에 머리글 행이 포함되어 있는지 확인합니다.
- 중간에 완전히 비어 있는 행이나 열이 없어야 합니다.
- 각 열에는 일관된 데이터 형식(예: 숫자, 날짜, 텍스트)이 포함되어야 합니다.
이러한 확인 작업은 정렬 오류와 데이터 불일치를 방지하는 데 도움이 됩니다.
방법 1: Excel에서 단일 열로 데이터 정렬 (빠르고 필수적인 방법)
내장된 정렬 도구는 단일 열을 기준으로 데이터를 정렬하는 가장 빠른 방법입니다. 이름을 가나다순으로 정렬하거나 숫자를 오름차순/내림차순으로 정렬하는 등의 간단한 작업에 이상적입니다.
단계별 지침:
- 정렬하려는 단일 열을 선택합니다.
- Excel 리본 메뉴의 데이터 탭으로 이동합니다.
- 텍스트 오름차순 정렬(A→Z, 1→100) 또는 텍스트 내림차순 정렬(Z→A, 100→1)을 클릭합니다.
- 팝업 창이 나타나면 선택 영역 확장을 선택합니다. 이 옵션을 체크 상태로 유지하세요.
- 정렬을 클릭하여 프로세스를 완료합니다.
전문가 팁:
- 선택 영역 확장 옵션을 사용하면 인접한 열의 모든 관련 데이터가 선택한 열과 함께 정렬됩니다. 대부분의 경우 데이터 관계가 깨지지 않도록 이 옵션을 체크 상태로 유지해야 합니다.
- 데이터에 머리글 행(예: "이름", "이메일")이 있는 경우 팝업 창에서 내 데이터에 머리글 포함 상자를 체크하세요. 이렇게 하면 Excel이 머리글 자체를 정렬하는 것을 방지할 수 있습니다(예: "이름"이 열의 맨 아래로 이동하지 않음).
방법 2: Excel에서 여러 열로 데이터 정렬 (사용자 지정 정렬)
더 복잡한 데이터 세트의 경우 단일 열 정렬로는 충분하지 않습니다. 예를 들어, 판매 데이터를 먼저 "지역"(오름차순)별로 정렬한 다음 "판매 금액"(내림차순)별로 정렬하여 각 지역의 상위 실적자를 확인하고 싶을 수 있습니다. 이때 '사용자 지정 정렬'이 필요합니다.
단계별 지침:
- 데이터 세트 내의 아무 셀이나 선택합니다(이렇게 하면 Excel이 전체 표를 인식합니다).
- 데이터 탭으로 이동하여 정렬을 클릭합니다(A→Z/Z→A 버튼이 아님).
- 사용자 지정 정렬 창에서:
- 첫 번째 열(예: "지역")을 선택하고 정렬 기준을 텍스트 오름차순으로 설정합니다.
- 기준 추가를 클릭하여 다른 열(예: "판매 금액")을 추가하고 정렬 기준을 숫자 내림차순으로 설정합니다.
- 첫 번째 열(예: "지역")을 선택하고 정렬 기준을 텍스트 오름차순으로 설정합니다.
- 확인을 클릭하여 정렬을 적용합니다. 이제 데이터가 "지역" 열을 기준으로 정리되며, 값이 같을 경우 "판매 금액" 열을 기준으로 정렬됩니다.
핵심 통찰:
Excel은 계층적으로 정렬을 적용합니다. 즉, 첫 번째 열을 기준으로 정렬한 다음, 다음 열을 사용하여 동일한 값을 해결합니다.
사용 사례:
- 판매 보고서 (지역 → 수익)
- 직원 목록 (부서 → 직책)
- 재고 (카테고리 → 재고 수준)
방법 3: 수식을 사용하여 Excel 데이터 정렬 (SORT 및 SORTBY)
데이터가 자주 업데이트되는 경우 수동 정렬은 비효율적입니다. SORT 및 SORTBY와 같은 Excel 수식을 사용하면 동적으로 자동 업데이트되는 정렬된 목록을 만들 수 있습니다.
기존 정렬과 달리 이러한 함수는 원본 데이터를 수정하지 않습니다. 대신 자동으로 업데이트되는 동적으로 정렬된 복사본을 생성합니다.
SORT 함수 사용 (최신 Excel에서 가장 간단함)
SORT 함수는 데이터 범위를 정렬하고 새로운 정렬된 배열을 반환합니다. 구문: =SORT(범위, [정렬_열], [정렬_순서], [열_기준])
- 빈 셀(예: J1)에 다음 수식을 입력합니다: =SORT(A1:H11, 1, -1, FALSE)
- A1:H11: 정렬하려는 전체 데이터 세트.
- 1: 정렬할 열 번호.
- -1: 정렬 순서 (1 = 오름차순, -1 = 내림차순).
- FALSE: 행 기준 정렬 (기본값; 열 기준으로 정렬하려면 TRUE 사용).
- Enter 키를 누릅니다. Excel이 J1부터 시작하는 범위에 동적으로 정렬된 목록을 생성합니다. 원본 데이터를 업데이트하면(예: 판매 금액 변경) 정렬된 목록도 자동으로 업데이트됩니다.
SORTBY 함수 사용 (더 유연함)
=SORTBY(A1:H11, G1:G11, -1)
SORTBY 함수는 하나 이상의 별도 범위에 있는 값을 기준으로 데이터 세트를 정렬합니다. 열 위치에 의존하는 SORT 함수와 달리, SORTBY를 사용하면 정렬 순서를 제어할 범위를 정확하게 정의할 수 있습니다.
작동 방식:
- A1:H11 → 반환할 데이터 세트 (전체 표)
- G1:G11 → 정렬 키로 사용되는 범위 (예: "판매 금액")
- -1 → 정렬 순서 (1 = 오름차순, -1 = 내림차순)
예시 사용 사례:
원본 데이터 세트를 변경하지 않고 수익별로 판매 표를 정렬합니다.
방법 4: Excel에서 필터링된 데이터 정렬 (유연한 탐색)
필터를 사용하면 원본 데이터 세트를 영구적으로 변경하지 않고도 특정 데이터 하위 집합을 빠르게 탐색하고 정렬할 수 있습니다. 이는 특정 지역이나 기간의 판매 분석과 같은 대규모 데이터 세트를 다룰 때 특히 유용합니다.
단계별 지침:
- 머리글 행을 포함하여 데이터 세트를 선택합니다.
- 데이터 탭으로 이동하여 필터를 클릭합니다(또는 단축키 Ctrl+Shift+L 사용). 각 머리글 셀에 작은 드롭다운 화살표가 나타납니다.
- 정렬하려는 열(예: "지역")의 드롭다운 화살표를 클릭하고 필요 없는 지역(예: "East", "North", "South")의 체크를 해제한 다음 확인을 클릭합니다.
- 판매 금액 열의 드롭다운 화살표를 클릭하고 숫자 오름차순 정렬 또는 숫자 내림차순 정렬을 선택합니다. 이렇게 하면 필터링된(표시된) 행만 정렬됩니다.
- 필터를 제거하고 원본 데이터 세트로 돌아가려면 필터를 다시 클릭합니다(또는 Ctrl+Shift+L).
주요 장점:
필터를 사용하면 정렬과 데이터 필터링을 결합할 수 있어 원본 데이터 구조를 변경하지 않고도 특정 하위 집합(예: 특정 지역의 고가 판매 건만 정렬)을 쉽게 탐색할 수 있습니다.
방법 5: Python을 사용하여 Excel 데이터 정렬 (자동화 및 확장성)
대규모 데이터 세트(10,000행 이상)나 반복적인 정렬 작업(예: 일일 Excel 보고서 정렬)의 경우 Python 자동화가 매우 효과적입니다. 여기서는 Excel이 설치되어 있지 않아도 정렬을 포함한 Excel 파일 조작을 간소화하는 강력한 라이브러리인 Spire.XLS for Python을 사용합니다.
전제 조건:
- Spire.XLS for Python 설치: 터미널/명령 프롬프트에서 pip install Spire.XLS를 실행합니다.
- 정렬하려는 데이터가 포함된 입력 Excel 파일(예: "Input.xlsx")을 준비합니다.
단계별 Python 코드 (설명 포함):
from spire.xls.common import *
from spire.xls import *
# Workbook 인스턴스 생성
workbook = Workbook()
# 입력 Excel 파일 로드
workbook.LoadFromFile("Input.xlsx")
# 첫 번째 워크시트 가져오기
worksheet = workbook.Worksheets[0]
# 정렬 규칙 정의: B열(인덱스 1)을 값 기준으로 오름차순 정렬
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# 정렬할 셀 범위 지정
workbook.DataSorter.Sort(worksheet["A1:H11"])
# 정렬된 데이터를 새 Excel 파일로 저장
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
코드 사용자 지정 방법:
- 다른 열 정렬: Add()의 첫 번째 매개변수를 변경합니다(예: A열은 0, B열은 1).
- 내림차순 정렬: OrderBy.Ascending을 OrderBy.Descending으로 바꿉니다.
- 더 큰 범위 정렬: worksheet["A1:H11"]을 수정합니다(예: 1000행, 7열의 경우 worksheet["A1:G1000"]).
- 여러 열 정렬: workbook.DataSorter.SortColumns.Add()로 두 번째 정렬 규칙을 추가합니다(예: A열 오름차순 정렬 후 B열 내림차순 정렬).
사용 사례:
이 방법은 매일 50개 이상의 Excel 파일을 정렬하거나 Excel에서 원활하게 처리할 수 없는 대규모 데이터 세트를 정렬하는 등 반복적인 작업을 자동화하는 데 완벽합니다.
데이터 정렬 외에도 Python을 사용하여 워크시트 서식 지정, 스타일 적용, Excel 파일을 PDF로 변환과 같은 다른 Excel 작업을 자동화할 수 있습니다. 이러한 기능을 통해 전체 문서 처리 워크플로를 쉽게 구축할 수 있습니다.
비교 표: 어떤 방법을 선택해야 할까요?
| 방법 | 최적 대상 | 장점 | 단점 |
|---|---|---|---|
| 내장 정렬 | 빠른 단일 열 정렬 | 사용하기 쉬움, 설정 불필요 | 기본 정렬로 제한됨, 수동 작업 |
| 사용자 지정 정렬 | 다중 열, 계층적 정렬 | 유연함, 복잡한 데이터 세트 처리 | 몇 가지 추가 단계 필요 |
| Excel 수식 | 동적, 자동 업데이트 정렬 목록 | 수동 재정렬 불필요, 데이터와 함께 업데이트 | SORT 함수는 최신 Excel에서만 사용 가능 |
| 필터 | 임시 정렬/하위 집합 탐색 | 비파괴적, 필터링과 결합 가능 | 영구적인 정렬에는 적합하지 않음 |
| Python (Spire.XLS) | 대규모 데이터 세트, 자동화 | 확장성, 반복 작업, Excel 불필요 | 기본적인 Python 지식 필요 |
마치며
Excel에서의 정렬은 단순히 데이터를 배열하는 것 이상으로, 정보를 유용하고 의미 있게 만드는 과정입니다.
- 빠른 작업에는 내장 정렬을 사용하세요.
- 구조화된 분석에는 사용자 지정 정렬을 사용하세요.
- 동적 결과에는 수식을 사용하세요.
- 유연한 탐색에는 필터를 사용하세요.
- 대규모 자동화에는 Python을 사용하세요.
이러한 방법을 마스터하면 간단한 스프레드시트부터 복잡한 데이터 워크플로까지 모든 것을 쉽게 처리할 수 있습니다.
자주 묻는 질문(FAQ)
Q1: 정렬 후 Excel 데이터가 어긋나는 이유는 무엇인가요?
이는 보통 선택 영역 확장이 선택되지 않았을 때 발생합니다. 정렬할 때는 항상 관련 열이 포함되어 있는지 확인하세요.
Q2: 셀 색상이나 글꼴 색상으로 정렬할 수 있나요?
네. 정렬 대화 상자의 "정렬 기준"에서 셀 색상 또는 글꼴 색상을 선택하세요.
Q3: 빈 셀이 있는 데이터를 정렬할 수 있나요?
네. Excel은 빈 셀을 맨 아래(오름차순) 또는 맨 위(내림차순)에 배치합니다. 필요에 따라 필터링하여 제외할 수 있습니다.
Q4: 정렬을 취소하려면 어떻게 하나요?
정렬 직후 Ctrl + Z를 누르세요. 다른 변경 사항을 이미 적용했다면 취소가 불가능할 수 있습니다.
Q5: Excel 정렬이 작동하지 않는 이유는 무엇인가요?
일반적인 원인은 다음과 같습니다:
- 혼합된 데이터 형식
- 숨겨진 행 또는 열
- 잘못된 선택 범위
참고 항목
Ordinare i dati in Excel: spiegazione di 5 metodi semplici e avanzati
Indice
- Prima di iniziare
- Metodo 1: Ordinare i dati per una singola colonna in Excel (Rapido ed essenziale)
- Metodo 2: Ordinare i dati per più colonne in Excel (Ordinamento personalizzato)
- Metodo 3: Ordinare i dati in Excel usando le formule (SORT e SORTBY)
- Metodo 4: Ordinare dati filtrati in Excel (Esplorazione flessibile)
- Metodo 5: Ordinare i dati di Excel usando Python (Automazione e scalabilità)
- Tabella comparativa: quale metodo scegliere
- Considerazioni finali
- Domande frequenti (FAQ)
Ordinare i dati in Excel è una competenza fondamentale per organizzare, analizzare e comprendere le informazioni. Che tu stia lavorando con elenchi di clienti, report finanziari o grandi set di dati, l'ordinamento ti aiuta a identificare rapidamente modelli, tendenze e anomalie.
In questa guida, imparerai 5 modi pratici per ordinare i dati in Excel, inclusi l'ordinamento per singola colonna, l'ordinamento per più colonne, l'ordinamento dinamico basato su formule e l'automazione tramite Python.
Navigazione rapida
- Metodo 1: Ordinare i dati per una singola colonna in Excel (Rapido ed essenziale)
- Metodo 2: Ordinare i dati per più colonne in Excel (Ordinamento personalizzato)
- Metodo 3: Ordinare i dati in Excel usando le formule (SORT e SORTBY)
- Metodo 4: Ordinare dati filtrati in Excel (Esplorazione flessibile)
- Metodo 5: Ordinare i dati di Excel usando Python (Automazione e scalabilità)
Prima di iniziare
Prima di ordinare i dati in Excel, assicurati che:
- Il tuo set di dati includa una riga di intestazione
- Non ci siano righe o colonne completamente vuote nel mezzo
- Ogni colonna contenga tipi di dati coerenti (ad esempio, numeri, date, testo)
Questi controlli aiutano a prevenire errori di ordinamento e disallineamento dei dati.
Metodo 1: Ordinare i dati per una singola colonna in Excel (Rapido ed essenziale)
Lo strumento di ordinamento integrato è il modo più veloce per ordinare i dati per una singola colonna. È ideale per attività semplici come ordinare i nomi in ordine alfabetico o i numeri dal più piccolo al più grande.
Istruzioni passo dopo passo:
- Seleziona la singola colonna che desideri ordinare.
- Vai alla scheda Dati nella barra multifunzione di Excel.
- Fai clic su Ordina dalla A alla Z (ordine crescente: A→Z, 1→100) o Ordina dalla Z alla A (ordine decrescente: Z→A, 100→1).
- Apparirà una finestra pop-up: Espandi la selezione. Mantieni selezionata questa opzione.
- Fai clic su Ordina per completare il processo.
Suggerimento professionale:
- L'opzione Espandi la selezione assicura che tutti i dati correlati nelle colonne adiacenti vengano ordinati insieme alla colonna selezionata. Nella maggior parte dei casi, dovresti mantenere questa opzione selezionata per evitare di rompere le relazioni tra i dati.
- Se i tuoi dati hanno una riga di intestazione (ad esempio, "Nome", "Email"), seleziona la casella Dati con intestazioni nella finestra pop-up. Questo impedisce a Excel di ordinare l'intestazione stessa (ad esempio, "Nome" non finirà in fondo alla colonna).
Metodo 2: Ordinare i dati per più colonne in Excel (Ordinamento personalizzato)
Per set di dati più complessi, l'ordinamento per una singola colonna non è sufficiente. Ad esempio, potresti voler ordinare i dati di vendita prima per "Regione" (crescente) e poi per "Importo vendite" (decrescente) per vedere i migliori risultati in ogni regione. È qui che entra in gioco l'Ordinamento personalizzato.
Istruzioni passo dopo passo:
- Seleziona qualsiasi cella all'interno del tuo set di dati (questo assicura che Excel riconosca l'intera tabella).
- Vai alla scheda Dati e fai clic su Ordina (non sui pulsanti A→Z/Z→A).
- Nella finestra Ordinamento personalizzato:
- Scegli la prima colonna (ad esempio, "Regione") e imposta l'ordine su Dalla A alla Z.
- Fai clic su Aggiungi livello per aggiungere un'altra colonna (ad esempio, "Importo vendite") e imposta l'ordine su Dal più grande al più piccolo.
- Scegli la prima colonna (ad esempio, "Regione") e imposta l'ordine su Dalla A alla Z.
- Fai clic su OK per applicare l'ordinamento. I tuoi dati saranno ora organizzati per la colonna "Regione", con i pareggi risolti dalla colonna "Importo vendite".
Approfondimento:
Excel applica l'ordinamento gerarchicamente: ordina in base alla prima colonna, quindi risolve i pareggi utilizzando la colonna successiva.
Casi d'uso:
- Report di vendita (Regione → Ricavi)
- Elenchi dipendenti (Dipartimento → Ruolo)
- Inventario (Categoria → Livello scorte)
Metodo 3: Ordinare i dati in Excel usando le formule (SORT e SORTBY)
Se i tuoi dati vengono aggiornati frequentemente, l'ordinamento manuale diventa inefficiente. Le formule di Excel come SORT e SORTBY ti consentono di creare elenchi ordinati dinamici che si aggiornano automaticamente.
A differenza dell'ordinamento tradizionale, queste funzioni non modificano i dati originali. Generano invece una copia ordinata dinamicamente che si aggiorna automaticamente.
Utilizzo della funzione SORT (La più semplice per Excel moderno)
La funzione SORT ordina un intervallo di dati e restituisce una nuova matrice ordinata. Sintassi: =SORT(intervallo, [indice_ordinamento], [ordine_ordinamento], [per_colonna])
- In una cella vuota (ad esempio, J1), inserisci la formula: =SORT(A1:H11, 1, -1, FALSE)
- A1:H11: L'intero set di dati che vuoi ordinare.
- 1: La colonna in base alla quale ordinare.
- -1: Ordine di ordinamento (1 = crescente, -1 = decrescente).
- FALSE: Ordina per righe (predefinito; usa TRUE per ordinare per colonne).
- Premi Invio. Excel genererà un elenco ordinato dinamico nell'intervallo a partire da J1. Se aggiorni i dati originali (ad esempio, modifichi un importo di vendita), l'elenco ordinato si aggiornerà automaticamente.
Utilizzo della funzione SORTBY (Più flessibile)
=SORTBY(A1:H11, G1:G11, -1)
La funzione SORTBY ordina un set di dati in base ai valori in uno o più intervalli separati. A differenza della funzione SORT, che si basa sulle posizioni delle colonne, SORTBY ti consente di definire esattamente quale intervallo controlla l'ordine di ordinamento.
Come funziona:
- A1:H11 → Il set di dati da restituire (la tabella completa)
- G1:G11 → L'intervallo utilizzato come chiave di ordinamento (ad esempio, "Importo vendite")
- -1 → Ordine di ordinamento (1 = crescente, -1 = decrescente)
Esempio di caso d'uso:
Ordinare una tabella di vendita per ricavi senza modificare il set di dati originale.
Metodo 4: Ordinare dati filtrati in Excel (Esplorazione flessibile)
I filtri ti consentono di esplorare e ordinare rapidamente sottoinsiemi specifici dei tuoi dati senza modificare in modo permanente il set di dati originale. Questo è particolarmente utile quando si lavora con grandi set di dati, come l'analisi delle vendite di una regione o di un periodo di tempo specifico.
Istruzioni passo dopo passo:
- Seleziona il tuo set di dati, inclusa la riga di intestazione.
- Vai alla scheda Dati e fai clic su Filtro (o usa la scorciatoia: Ctrl+Shift+L). Piccole frecce a discesa appariranno in ogni cella dell'intestazione.
- Fai clic sulla freccia a discesa nella colonna che desideri ordinare (ad esempio, "Regione"), deseleziona le regioni che non ti servono (ad esempio, "Est", "Nord", "Sud") e quindi fai clic su OK.
- Fai clic sulla freccia a discesa nella colonna Importo vendite e scegli Ordina dal più piccolo al più grande (crescente) o Ordina dal più grande al più piccolo (decrescente). Questo ordinerà solo le righe filtrate (visibili).
- Per rimuovere il filtro e tornare al set di dati originale, fai clic di nuovo su Filtro (o Ctrl+Shift+L).
Vantaggio chiave:
I filtri ti consentono di combinare l'ordinamento con il filtraggio dei dati, rendendo facile esplorare sottoinsiemi specifici (ad esempio, ordinare solo le vendite di alto valore in una regione specifica) senza alterare la struttura originale dei dati.
Metodo 5: Ordinare i dati di Excel usando Python (Automazione e scalabilità)
Per set di dati di grandi dimensioni (oltre 10.000 righe) o attività di ordinamento ripetitive (ad esempio, l'ordinamento di report Excel giornalieri), l'automazione Python cambia le regole del gioco. Utilizzeremo Spire.XLS for Python, una potente libreria che semplifica la manipolazione dei file Excel, incluso l'ordinamento, senza richiedere che Excel sia installato sul tuo computer.
Prerequisiti:
- Installa Spire.XLS for Python: Esegui pip install Spire.XLS nel tuo terminale/prompt dei comandi.
- Prepara il tuo file Excel di input (ad esempio, "Input.xlsx") con i dati che desideri ordinare.
Codice Python passo dopo passo (con spiegazioni):
from spire.xls.common import *
from spire.xls import *
# Crea un'istanza di Workbook
workbook = Workbook()
# Carica il file Excel di input
workbook.LoadFromFile("Input.xlsx")
# Ottieni il primo foglio di lavoro
worksheet = workbook.Worksheets[0]
# Definisci la regola di ordinamento: Ordina la colonna B (indice 1) per valori in ordine crescente
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Specifica l'intervallo di celle da ordinare
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Salva i dati ordinati in un nuovo file Excel
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Come personalizzare il codice:
- Ordinare una colonna diversa: Cambia il primo parametro in Add() (ad esempio, 0 per la Colonna A, 1 per la Colonna B).
- Ordinamento decrescente: Sostituisci OrderBy.Ascending con OrderBy.Descending.
- Ordinare un intervallo più ampio: Modifica worksheet["A1:H11"] (ad esempio, worksheet["A1:G1000"] per 1000 righe, 7 colonne).
- Più colonne: Aggiungi una seconda regola di ordinamento con workbook.DataSorter.SortColumns.Add() (ad esempio, ordina la Colonna A in modo crescente, poi la Colonna B in modo decrescente).
Caso d'uso:
Questo metodo è perfetto per automatizzare attività ripetitive, ad esempio ordinare oltre 50 file Excel al giorno o ordinare set di dati troppo grandi per essere gestiti agevolmente da Excel.
Oltre all'ordinamento dei dati, puoi utilizzare Python per automatizzare altre attività di Excel come la formattazione dei fogli di lavoro, l'applicazione di stili e l'esportazione di file Excel in PDF. Queste funzionalità rendono facile costruire flussi di lavoro completi di elaborazione documenti.
Tabella comparativa: quale metodo scegliere
| Metodo | Ideale per | Pro | Contro |
|---|---|---|---|
| Ordinamento integrato | Ordinamento rapido per singola colonna | Facile da usare, nessuna configurazione richiesta | Limitato all'ordinamento di base; manuale |
| Ordinamento personalizzato | Ordinamento gerarchico per più colonne | Flessibile, gestisce set di dati complessi | Richiede alcuni passaggi extra |
| Formule Excel | Elenchi ordinati dinamici che si aggiornano automaticamente | Nessun riordino manuale; si aggiorna con i dati | Funzione SORT disponibile solo in Excel moderno |
| Filtri | Ordinamento/esplorazione temporanea di sottoinsiemi | Non distruttivo; si combina con il filtraggio | Non ideale per l'ordinamento permanente |
| Python (Spire.XLS) | Grandi set di dati, automazione | Scalabile, attività ripetitive, non richiede Excel | Richiede conoscenze di base di Python |
Considerazioni finali
Ordinare in Excel è molto più che disporre i dati: si tratta di rendere le informazioni utilizzabili e significative.
- Usa l'ordinamento integrato per attività rapide
- Usa l'ordinamento personalizzato per analisi strutturate
- Usa le formule per risultati dinamici
- Usa i filtri per un'esplorazione flessibile
- Usa Python per l'automazione su larga scala
Padroneggiare questi metodi ti permetterà di gestire tutto, dai semplici fogli di calcolo ai flussi di lavoro di dati complessi, con facilità.
Domande frequenti (FAQ)
Q1: Perché i miei dati Excel sono disallineati dopo l'ordinamento?
Questo accade solitamente quando non è selezionato Espandi la selezione. Assicurati sempre che le colonne correlate siano incluse durante l'ordinamento.
Q2: Posso ordinare per colore della cella o colore del carattere?
Sì. Nella finestra di dialogo Ordina, scegli Colore cella o Colore carattere sotto "Ordina per".
Q3: Posso ordinare i dati con celle vuote?
Sì. Excel posiziona le celle vuote in fondo (crescente) o in alto (decrescente). Puoi filtrarle se necessario.
Q4: Come annullo un ordinamento?
Premi Ctrl + Z immediatamente dopo l'ordinamento. Se hai apportato altre modifiche, l'annullamento potrebbe non essere disponibile.
Q5: Perché l'ordinamento di Excel non funziona?
Le cause comuni includono:
- Tipi di dati misti
- Righe o colonne nascoste
- Intervallo di selezione errato
Vedi anche
Trier les données dans Excel : 5 méthodes simples et avancées expliquées
Table des matières
- Avant de commencer
- Méthode 1 : Trier les données par une seule colonne dans Excel (Rapide et essentiel)
- Méthode 2 : Trier les données par plusieurs colonnes dans Excel (Tri personnalisé)
- Méthode 3 : Trier les données dans Excel à l'aide de formules (SORT & SORTBY)
- Méthode 4 : Trier les données filtrées dans Excel (Exploration flexible)
- Méthode 5 : Trier les données Excel à l'aide de Python (Automatisation et évolutivité)
- Tableau comparatif : Quelle méthode choisir ?
- Réflexions finales
- FAQ
Le tri des données dans Excel est une compétence essentielle pour organiser, analyser et donner du sens aux informations. Que vous travailliez avec des listes de clients, des rapports financiers ou de grands ensembles de données, le tri vous aide à identifier rapidement les modèles, les tendances et les anomalies.
Dans ce guide, vous apprendrez 5 méthodes pratiques pour trier des données dans Excel, notamment le tri par colonne unique, le tri multi-colonnes, le tri dynamique par formule et l'automatisation via Python.
Navigation rapide
- Méthode 1 : Trier les données par une seule colonne dans Excel (Rapide et essentiel)
- Méthode 2 : Trier les données par plusieurs colonnes dans Excel (Tri personnalisé)
- Méthode 3 : Trier les données dans Excel à l'aide de formules (SORT & SORTBY)
- Méthode 4 : Trier les données filtrées dans Excel (Exploration flexible)
- Méthode 5 : Trier les données Excel à l'aide de Python (Automatisation et évolutivité)
Avant de commencer
Avant de trier des données dans Excel, assurez-vous que :
- Votre ensemble de données inclut une ligne d'en-tête.
- Il n'y a pas de lignes ou de colonnes entièrement vides au milieu.
- Chaque colonne contient des types de données cohérents (par exemple, nombres, dates, texte).
Ces vérifications permettent d'éviter les erreurs de tri et le désalignement des données.
Méthode 1 : Trier les données par une seule colonne dans Excel (Rapide et essentiel)
L'outil de tri intégré est le moyen le plus rapide de trier des données par une seule colonne. Il est idéal pour des tâches simples telles que le tri alphabétique de noms ou le tri de nombres du plus petit au plus grand.
Instructions étape par étape :
- Sélectionnez la colonne unique que vous souhaitez trier.
- Allez dans l'onglet Données du ruban Excel.
- Cliquez sur Trier du plus petit au plus grand (ordre croissant : A→Z, 1→100) ou Trier du plus grand au plus petit (ordre décroissant : Z→A, 100→1).
- Une fenêtre contextuelle apparaîtra : Étendre la sélection. Gardez cette option cochée.
- Cliquez sur Trier pour terminer le processus.
Conseil d'expert :
- L'option Étendre la sélection garantit que toutes les données associées dans les colonnes adjacentes sont triées en même temps que la colonne sélectionnée. Dans la plupart des cas, vous devez garder cette option cochée pour éviter de rompre les relations entre les données.
- Si vos données comportent une ligne d'en-tête (par exemple, « Nom », « E-mail »), cochez la case Mes données ont des en-têtes dans la fenêtre contextuelle. Cela empêche Excel de trier l'en-tête lui-même (par exemple, « Nom » ne se retrouvera pas en bas de la colonne).
Méthode 2 : Trier les données par plusieurs colonnes dans Excel (Tri personnalisé)
Pour des ensembles de données plus complexes, le tri par une seule colonne ne suffit pas. Par exemple, vous souhaiterez peut-être trier les données de vente d'abord par « Région » (croissant), puis par « Montant des ventes » (décroissant) pour voir les meilleures performances dans chaque région. C'est là qu'intervient le Tri personnalisé.
Instructions étape par étape :
- Sélectionnez n'importe quelle cellule dans votre ensemble de données (cela garantit qu'Excel reconnaît l'intégralité du tableau).
- Allez dans l'onglet Données et cliquez sur Trier (pas sur les boutons A→Z/Z→A).
- Dans la fenêtre Tri personnalisé :
- Choisissez la première colonne (par exemple, « Région ») et définissez l'ordre sur De A à Z.
- Cliquez sur Ajouter un niveau pour ajouter une autre colonne (par exemple, « Montant des ventes ») et définissez l'ordre sur Du plus grand au plus petit.
- Choisissez la première colonne (par exemple, « Région ») et définissez l'ordre sur De A à Z.
- Cliquez sur OK pour appliquer le tri. Vos données seront désormais organisées par la colonne « Région », les égalités étant départagées par la colonne « Montant des ventes ».
Aperçu clé :
Excel applique le tri de manière hiérarchique : il trie selon la première colonne, puis résout les égalités en utilisant la colonne suivante.
Cas d'utilisation :
- Rapports de ventes (Région → Revenu)
- Listes d'employés (Département → Rôle)
- Inventaire (Catégorie → Niveau de stock)
Méthode 3 : Trier les données dans Excel à l'aide de formules (SORT & SORTBY)
Si vos données sont mises à jour fréquemment, le tri manuel devient inefficace. Les formules Excel comme TRIER et TRIERPAR vous permettent de créer des listes triées dynamiques qui se mettent à jour automatiquement.
Contrairement au tri traditionnel, ces fonctions ne modifient pas les données d'origine. Au lieu de cela, elles génèrent une copie triée dynamiquement qui se met à jour automatiquement.
Utilisation de la fonction TRIER (La plus simple pour Excel moderne)
La fonction TRIER trie une plage de données et renvoie un nouveau tableau trié. Syntaxe : =TRIER(matrice, [index_tri], [ordre_tri], [par_colonne])
- Dans une cellule vide (par exemple, J1), entrez la formule : =TRIER(A1:H11, 1, -1, FAUX)
- A1:H11 : L'ensemble des données que vous souhaitez trier.
- 1 : La colonne selon laquelle trier.
- -1 : Ordre de tri (1 = croissant, -1 = décroissant).
- FAUX : Trier par lignes (par défaut ; utilisez VRAI pour trier par colonnes).
- Appuyez sur Entrée. Excel générera une liste triée dynamique dans la plage commençant en J1. Si vous mettez à jour les données d'origine (par exemple, modifiez un montant de vente), la liste triée se mettra à jour automatiquement.
Utilisation de la fonction TRIERPAR (Plus flexible)
=TRIERPAR(A1:H11, G1:G11, -1)
La fonction TRIERPAR trie un ensemble de données en fonction des valeurs dans une ou plusieurs plages distinctes. Contrairement à la fonction TRIER, qui repose sur les positions des colonnes, TRIERPAR vous permet de définir exactement quelle plage contrôle l'ordre de tri.
Comment ça fonctionne :
- A1:H11 → L'ensemble de données à renvoyer (le tableau complet)
- G1:G11 → La plage utilisée comme clé de tri (par exemple, « Montant des ventes »)
- -1 → Ordre de tri (1 = croissant, -1 = décroissant)
Exemple de cas d'utilisation :
Trier un tableau de ventes par revenu sans modifier l'ensemble de données d'origine.
Méthode 4 : Trier les données filtrées dans Excel (Exploration flexible)
Les filtres vous permettent d'explorer et de trier rapidement des sous-ensembles spécifiques de vos données sans modifier définitivement l'ensemble de données d'origine. Ceci est particulièrement utile lorsque vous travaillez avec de grands ensembles de données, comme l'analyse des ventes d'une région ou d'une période spécifique.
Instructions étape par étape :
- Sélectionnez votre ensemble de données, y compris la ligne d'en-tête.
- Allez dans l'onglet Données et cliquez sur Filtrer (ou utilisez le raccourci : Ctrl+Maj+L). De petites flèches déroulantes apparaîtront dans chaque cellule d'en-tête.
- Cliquez sur la flèche déroulante de la colonne que vous souhaitez trier (par exemple, « Région »), décochez les régions dont vous n'avez pas besoin (par exemple, « Est », « Nord », « Sud »), puis cliquez sur OK.
- Cliquez sur la flèche déroulante de la colonne Montant des ventes et choisissez Trier du plus petit au plus grand (croissant) ou Trier du plus grand au plus petit (décroissant). Cela triera uniquement les lignes filtrées (visibles).
- Pour supprimer le filtre et revenir à l'ensemble de données d'origine, cliquez à nouveau sur Filtrer (ou Ctrl+Maj+L).
Avantage clé :
Les filtres vous permettent de combiner le tri avec le filtrage des données, ce qui facilite l'exploration de sous-ensembles spécifiques (par exemple, trier les ventes à forte valeur uniquement dans une région spécifique) sans altérer la structure des données d'origine.
Méthode 5 : Trier les données Excel à l'aide de Python (Automatisation et évolutivité)
Pour les grands ensembles de données (plus de 10 000 lignes) ou les tâches de tri répétitives (par exemple, trier des rapports Excel quotidiens), l'automatisation Python change la donne. Nous utiliserons Spire.XLS for Python — une bibliothèque puissante qui simplifie la manipulation des fichiers Excel, y compris le tri, sans nécessiter l'installation d'Excel sur votre machine.
Prérequis :
- Installez Spire.XLS for Python : Exécutez pip install Spire.XLS dans votre terminal/invite de commande.
- Préparez votre fichier Excel d'entrée (par exemple, « Input.xlsx ») avec les données que vous souhaitez trier.
Code Python étape par étape (avec explications) :
from spire.xls.common import *
from spire.xls import *
# Créer une instance de Workbook
workbook = Workbook()
# Charger le fichier Excel d'entrée
workbook.LoadFromFile("Input.xlsx")
# Obtenir la première feuille de calcul
worksheet = workbook.Worksheets[0]
# Définir la règle de tri : Trier la colonne B (index 1) par valeurs dans l'ordre croissant
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Spécifier la plage de cellules à trier
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Enregistrer les données triées dans un nouveau fichier Excel
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Comment personnaliser le code :
- Trier une colonne différente : Modifiez le premier paramètre dans Add() (par exemple, 0 pour la colonne A, 1 pour la colonne B).
- Tri décroissant : Remplacez OrderBy.Ascending par OrderBy.Descending.
- Trier une plage plus large : Modifiez worksheet["A1:H11"] (par exemple, worksheet["A1:G1000"] pour 1000 lignes, 7 colonnes).
- Plusieurs colonnes : Ajoutez une deuxième règle de tri avec workbook.DataSorter.SortColumns.Add() (par exemple, trier la colonne A par ordre croissant, puis la colonne B par ordre décroissant).
Cas d'utilisation :
Cette méthode est parfaite pour automatiser les tâches répétitives — par exemple, trier plus de 50 fichiers Excel quotidiennement, ou trier des ensembles de données trop volumineux pour qu'Excel puisse les gérer facilement.
En plus de trier les données, vous pouvez également utiliser Python pour automatiser d'autres tâches Excel telles que le formatage des feuilles de calcul, l'application de styles et l' exportation de fichiers Excel au format PDF. Ces fonctionnalités facilitent la création de flux de travail complets de traitement de documents.
Tableau comparatif : Quelle méthode choisir ?
| Méthode | Idéal pour | Avantages | Inconvénients |
|---|---|---|---|
| Tri intégré | Tri rapide par colonne unique | Facile à utiliser, aucune configuration requise | Limité au tri de base ; manuel |
| Tri personnalisé | Tri multi-colonnes, hiérarchique | Flexible, gère des ensembles de données complexes | Nécessite quelques étapes supplémentaires |
| Formules Excel | Listes triées dynamiques et auto-mises à jour | Pas de re-tri manuel ; se met à jour avec les données | Fonction TRIER uniquement disponible dans Excel moderne |
| Filtres | Tri temporaire/exploration de sous-ensembles | Non destructif ; se combine avec le filtrage | Pas idéal pour un tri permanent |
| Python (Spire.XLS) | Grands ensembles de données, automatisation | Évolutif, tâches répétitives, pas besoin d'Excel | Nécessite des connaissances de base en Python |
Réflexions finales
Le tri dans Excel est bien plus qu'une simple organisation de données : il s'agit de rendre les informations utilisables et significatives.
- Utilisez le tri intégré pour les tâches rapides.
- Utilisez le tri personnalisé pour une analyse structurée.
- Utilisez les formules pour des résultats dynamiques.
- Utilisez les filtres pour une exploration flexible.
- Utilisez Python pour l'automatisation à grande échelle.
La maîtrise de ces méthodes vous permettra de gérer facilement tout, des simples feuilles de calcul aux flux de travail de données complexes.
FAQ
Q1 : Pourquoi mes données Excel sont-elles désalignées après le tri ?
Cela se produit généralement lorsque l'option Étendre la sélection n'est pas sélectionnée. Assurez-vous toujours que les colonnes associées sont incluses lors du tri.
Q2 : Puis-je trier par couleur de cellule ou couleur de police ?
Oui. Dans la boîte de dialogue Trier, choisissez Couleur de cellule ou Couleur de police sous « Trier sur ».
Q3 : Puis-je trier des données avec des cellules vides ?
Oui. Excel place les cellules vides en bas (croissant) ou en haut (décroissant). Vous pouvez les filtrer si nécessaire.
Q4 : Comment annuler un tri ?
Appuyez sur Ctrl + Z immédiatement après le tri. Si vous avez effectué d'autres modifications, l'annulation peut ne pas être disponible.
Q5 : Pourquoi le tri Excel ne fonctionne-t-il pas ?
Les causes courantes incluent :
- Types de données mixtes
- Lignes ou colonnes masquées
- Plage de sélection incorrecte
Voir aussi
- Comment masquer le quadrillage dans Excel (Affichage, impression et exportation PDF)
- Comment diviser des feuilles Excel en plusieurs fichiers (3 méthodes)
- 5 méthodes simples pour figer les lignes et les colonnes dans Excel
- Comment ajuster automatiquement la largeur des colonnes dans Excel (5 méthodes)
Ordenar datos en Excel: explicación de 5 métodos sencillos y avanzados
Tabla de contenidos
- Antes de empezar
- Método 1: Ordenar datos por una sola columna en Excel (Rápido y esencial)
- Método 2: Ordenar datos por varias columnas en Excel (Orden personalizado)
- Método 3: Ordenar datos en Excel usando fórmulas (SORT y SORTBY)
- Método 4: Ordenar datos filtrados en Excel (Exploración flexible)
- Método 5: Ordenar datos de Excel usando Python (Automatización y escalabilidad)
- Tabla comparativa: ¿Qué método debería elegir?
- Reflexiones finales
- Preguntas frecuentes
Ordenar datos en Excel es una habilidad esencial para organizar, analizar y dar sentido a la información. Ya sea que trabaje con listas de clientes, informes financieros o grandes conjuntos de datos, ordenar le ayuda a identificar rápidamente patrones, tendencias y valores atípicos.
En esta guía, aprenderá 5 formas prácticas de ordenar datos en Excel, incluyendo el orden por una sola columna, el orden por varias columnas, el orden dinámico basado en fórmulas y la automatización mediante Python.
Navegación rápida
- Método 1: Ordenar datos por una sola columna en Excel (Rápido y esencial)
- Método 2: Ordenar datos por varias columnas en Excel (Orden personalizado)
- Método 3: Ordenar datos en Excel usando fórmulas (SORT y SORTBY)
- Método 4: Ordenar datos filtrados en Excel (Exploración flexible)
- Método 5: Ordenar datos de Excel usando Python (Automatización y escalabilidad)
Antes de empezar
Antes de ordenar datos en Excel, asegúrese de que:
- Su conjunto de datos incluya una fila de encabezado.
- No haya filas o columnas completamente vacías en el medio.
- Cada columna contenga tipos de datos consistentes (por ejemplo, números, fechas, texto).
Estas comprobaciones ayudan a prevenir errores de ordenación y desalineación de datos.
Método 1: Ordenar datos por una sola columna en Excel (Rápido y esencial)
La herramienta de ordenación integrada es la forma más rápida de ordenar datos por una sola columna. Es ideal para tareas sencillas como ordenar nombres alfabéticamente o números de menor a mayor.
Instrucciones paso a paso:
- Seleccione la columna única que desea ordenar.
- Vaya a la pestaña Datos en la cinta de opciones de Excel.
- Haga clic en Ordenar de A a Z (orden ascendente: A→Z, 1→100) o Ordenar de Z a A (orden descendente: Z→A, 100→1).
- Aparecerá una ventana emergente: Ampliar la selección. Mantenga esta opción marcada.
- Haga clic en Ordenar para completar el proceso.
Consejo profesional:
- La opción Ampliar la selección garantiza que todos los datos relacionados en las columnas adyacentes se ordenen junto con la columna seleccionada. En la mayoría de los casos, debe mantener esta opción marcada para evitar romper las relaciones de los datos.
- Si sus datos tienen una fila de encabezado (por ejemplo, "Nombre", "Correo electrónico"), marque la casilla Mis datos tienen encabezados en la ventana emergente. Esto evita que Excel ordene el encabezado mismo (por ejemplo, "Nombre" no terminará al final de la columna).
Método 2: Ordenar datos por varias columnas en Excel (Orden personalizado)
Para conjuntos de datos más complejos, ordenar por una sola columna no es suficiente. Por ejemplo, es posible que desee ordenar los datos de ventas primero por "Región" (ascendente) y luego por "Monto de ventas" (descendente) para ver los mejores resultados en cada región. Aquí es donde entra en juego el Orden personalizado.
Instrucciones paso a paso:
- Seleccione cualquier celda dentro de su conjunto de datos (esto asegura que Excel reconozca toda la tabla).
- Vaya a la pestaña Datos y haga clic en Ordenar (no en los botones A→Z/Z→A).
- En la ventana de Orden personalizado:
- Elija la primera columna (por ejemplo, "Región") y establezca el orden en De A a Z.
- Haga clic en Agregar nivel para añadir otra columna (por ejemplo, "Monto de ventas") y establezca el orden en De mayor a menor.
- Elija la primera columna (por ejemplo, "Región") y establezca el orden en De A a Z.
- Haga clic en Aceptar para aplicar el orden. Sus datos ahora estarán organizados por la columna "Región", con los empates resueltos por la columna "Monto de ventas".
Información clave:
Excel aplica el orden de forma jerárquica: ordena por la primera columna y luego resuelve los empates usando la siguiente columna.
Casos de uso:
- Informes de ventas (Región → Ingresos)
- Listas de empleados (Departamento → Puesto)
- Inventario (Categoría → Nivel de existencias)
Método 3: Ordenar datos en Excel usando fórmulas (SORT y SORTBY)
Si sus datos se actualizan con frecuencia, la ordenación manual se vuelve ineficiente. Las fórmulas de Excel como SORT y SORTBY le permiten crear listas ordenadas dinámicas que se actualizan automáticamente.
A diferencia de la ordenación tradicional, estas funciones no modifican los datos originales. En su lugar, generan una copia ordenada dinámicamente que se actualiza automáticamente.
Uso de la función SORT (La más sencilla para Excel moderno)
La función SORT ordena un rango de datos y devuelve una nueva matriz ordenada. Sintaxis: =SORT(rango, [índice_ordenación], [orden], [por_columna])
- En una celda vacía (por ejemplo, J1), introduzca la fórmula: =SORT(A1:H11, 1, -1, FALSE)
- A1:H11: Todo el conjunto de datos que desea ordenar.
- 1: La columna por la cual ordenar.
- -1: Orden de clasificación (1 = ascendente, -1 = descendente).
- FALSE: Ordenar por filas (predeterminado; use TRUE para ordenar por columnas).
- Presione Entrar. Excel generará una lista ordenada dinámica en el rango que comienza en J1. Si actualiza los datos originales (por ejemplo, cambia un monto de ventas), la lista ordenada se actualizará automáticamente.
Uso de la función SORTBY (Más flexible)
=SORTBY(A1:H11, G1:G11, -1)
La función SORTBY ordena un conjunto de datos basado en los valores de uno o más rangos separados. A diferencia de la función SORT, que depende de las posiciones de las columnas, SORTBY le permite definir exactamente qué rango controla el orden de clasificación.
Cómo funciona:
- A1:H11 → El conjunto de datos a devolver (la tabla completa)
- G1:G11 → El rango utilizado como clave de ordenación (por ejemplo, "Monto de ventas")
- -1 → Orden de clasificación (1 = ascendente, -1 = descendente)
Ejemplo de caso de uso:
Ordenar una tabla de ventas por ingresos sin cambiar el conjunto de datos original.
Método 4: Ordenar datos filtrados en Excel (Exploración flexible)
Los filtros le permiten explorar y ordenar rápidamente subconjuntos específicos de sus datos sin cambiar permanentemente el conjunto de datos original. Esto es especialmente útil cuando se trabaja con grandes conjuntos de datos, como al analizar ventas de una región o período de tiempo específico.
Instrucciones paso a paso:
- Seleccione su conjunto de datos, incluyendo la fila de encabezado.
- Vaya a la pestaña Datos y haga clic en Filtro (o use el atajo: Ctrl+Shift+L). Aparecerán pequeñas flechas desplegables en cada celda de encabezado.
- Haga clic en la flecha desplegable en la columna que desea ordenar (por ejemplo, "Región"), desmarque las regiones que no necesita (por ejemplo, "Este", "Norte", "Sur") y luego haga clic en Aceptar.
- Haga clic en la flecha desplegable en la columna Monto de ventas y elija Ordenar de menor a mayor (ascendente) o Ordenar de mayor a menor (descendente). Esto ordenará solo las filas filtradas (visibles).
- Para eliminar el filtro y volver al conjunto de datos original, haga clic en Filtro nuevamente (o Ctrl+Shift+L).
Ventaja clave:
Los filtros le permiten combinar la ordenación con el filtrado de datos, lo que facilita la exploración de subconjuntos específicos (por ejemplo, ordenar solo las ventas de alto valor en una región específica) sin alterar la estructura original de los datos.
Método 5: Ordenar datos de Excel usando Python (Automatización y escalabilidad)
Para grandes conjuntos de datos (más de 10,000 filas) o tareas de ordenación repetitivas (por ejemplo, ordenar informes diarios de Excel), la automatización con Python cambia las reglas del juego. Usaremos Spire.XLS for Python, una potente biblioteca que simplifica la manipulación de archivos de Excel, incluida la ordenación, sin necesidad de tener Excel instalado en su máquina.
Requisitos previos:
- Instalar Spire.XLS for Python: Ejecute pip install Spire.XLS en su terminal o símbolo del sistema.
- Prepare su archivo de Excel de entrada (por ejemplo, "Input.xlsx") con los datos que desea ordenar.
Código de Python paso a paso (con explicaciones):
from spire.xls.common import *
from spire.xls import *
# Crear una instancia de libro de trabajo
workbook = Workbook()
# Cargar el archivo de Excel de entrada
workbook.LoadFromFile("Input.xlsx")
# Obtener la primera hoja de cálculo
worksheet = workbook.Worksheets[0]
# Definir la regla de ordenación: Ordenar la columna B (índice 1) por valores en orden ascendente
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Especificar el rango de celdas a ordenar
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Guardar los datos ordenados en un nuevo archivo de Excel
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Cómo personalizar el código:
- Ordenar una columna diferente: Cambie el primer parámetro en Add() (por ejemplo, 0 para la columna A, 1 para la columna B).
- Orden descendente: Reemplace OrderBy.Ascending con OrderBy.Descending.
- Ordenar un rango más grande: Modifique worksheet["A1:H11"] (por ejemplo, worksheet["A1:G1000"] para 1000 filas y 7 columnas).
- Varias columnas: Agregue una segunda regla de ordenación con workbook.DataSorter.SortColumns.Add() (por ejemplo, ordenar la columna A de forma ascendente y luego la columna B de forma descendente).
Caso de uso:
Este método es perfecto para automatizar tareas repetitivas, por ejemplo, ordenar más de 50 archivos de Excel diariamente o procesar conjuntos de datos demasiado grandes para que Excel los maneje sin problemas.
Además de ordenar datos, también puede usar Python para automatizar otras tareas de Excel, como dar formato a hojas de cálculo, aplicar estilos y exportar archivos de Excel a PDF. Estas capacidades facilitan la creación de flujos de trabajo completos de procesamiento de documentos.
Tabla comparativa: ¿Qué método debería elegir?
| Método | Mejor para | Pros | Contras |
|---|---|---|---|
| Ordenación integrada | Ordenación rápida de una sola columna | Fácil de usar, sin configuración | Limitado a ordenación básica; manual |
| Orden personalizado | Ordenación jerárquica de varias columnas | Flexible, maneja conjuntos de datos complejos | Requiere algunos pasos adicionales |
| Fórmulas de Excel | Listas ordenadas dinámicas y autoactualizables | Sin reordenación manual; se actualiza con los datos | La función SORT solo está disponible en Excel moderno |
| Filtros | Ordenación temporal/exploración de subconjuntos | No destructivo; se combina con el filtrado | No es ideal para ordenación permanente |
| Python (Spire.XLS) | Grandes conjuntos de datos, automatización | Escalable, tareas repetitivas, no requiere Excel | Requiere conocimientos básicos de Python |
Reflexiones finales
Ordenar en Excel es más que simplemente organizar datos: se trata de hacer que la información sea utilizable y significativa.
- Use la ordenación integrada para tareas rápidas.
- Use el orden personalizado para análisis estructurados.
- Use fórmulas para resultados dinámicos.
- Use filtros para una exploración flexible.
- Use Python para la automatización a escala.
Dominar estos métodos le permitirá manejar todo, desde hojas de cálculo simples hasta flujos de trabajo de datos complejos con facilidad.
Preguntas frecuentes
P1: ¿Por qué mis datos de Excel están desalineados después de ordenarlos?
Esto suele ocurrir cuando no se selecciona Ampliar la selección. Asegúrese siempre de incluir las columnas relacionadas al ordenar.
P2: ¿Puedo ordenar por color de celda o color de fuente?
Sí. En el cuadro de diálogo Ordenar, elija Color de celda o Color de fuente en "Ordenar según".
P3: ¿Puedo ordenar datos con celdas en blanco?
Sí. Excel coloca los espacios en blanco al final (ascendente) o al principio (descendente). Puede filtrarlos si es necesario.
P4: ¿Cómo deshago una ordenación?
Presione Ctrl + Z inmediatamente después de ordenar. Si ha realizado otros cambios, es posible que la opción de deshacer no esté disponible.
P5: ¿Por qué no funciona la ordenación de Excel?
Las causas comunes incluyen:
- Tipos de datos mixtos.
- Filas o columnas ocultas.
- Rango de selección incorrecto.
Ver también
Daten in Excel sortieren: 5 einfache und fortgeschrittene Methoden erklärt
Inhaltsverzeichnis
- Bevor Sie beginnen
- Methode 1: Daten in Excel nach einer einzelnen Spalte sortieren (Schnell & Grundlegend)
- Methode 2: Daten in Excel nach mehreren Spalten sortieren (Benutzerdefiniertes Sortieren)
- Methode 3: Daten in Excel mit Formeln sortieren (SORT & SORTBY)
- Methode 4: Gefilterte Daten in Excel sortieren (Flexible Analyse)
- Methode 5: Excel-Daten mit Python sortieren (Automatisierung & Skalierbarkeit)
- Vergleichstabelle: Welche Methode sollten Sie wählen?
- Fazit
- FAQs
Das Sortieren von Daten in Excel ist eine grundlegende Fähigkeit, um Informationen zu organisieren, zu analysieren und verständlich zu machen. Egal, ob Sie mit Kundenlisten, Finanzberichten oder großen Datensätzen arbeiten – durch Sortieren können Sie Muster, Trends und Ausreißer schnell erkennen.
In diesem Leitfaden lernen Sie 5 praktische Möglichkeiten zum Sortieren von Daten in Excel kennen, einschließlich der Sortierung nach einer Spalte, der Sortierung nach mehreren Spalten, der dynamischen Sortierung mittels Formeln sowie der Automatisierung mit Python.
Schnellnavigation
- Methode 1: Daten in Excel nach einer einzelnen Spalte sortieren (Schnell & Grundlegend)
- Methode 2: Daten in Excel nach mehreren Spalten sortieren (Benutzerdefiniertes Sortieren)
- Methode 3: Daten in Excel mit Formeln sortieren (SORT & SORTBY)
- Methode 4: Gefilterte Daten in Excel sortieren (Flexible Analyse)
- Methode 5: Excel-Daten mit Python sortieren (Automatisierung & Skalierbarkeit)
Bevor Sie beginnen
Bevor Sie Daten in Excel sortieren, stellen Sie sicher, dass:
- Ihr Datensatz eine Kopfzeile enthält.
- Sich keine komplett leeren Zeilen oder Spalten innerhalb des Bereichs befinden.
- Jede Spalte einheitliche Datentypen enthält (z. B. Zahlen, Datumsangaben, Text).
Diese Überprüfungen helfen, Sortierfehler und Datenverschiebungen zu vermeiden.
Methode 1: Daten in Excel nach einer einzelnen Spalte sortieren (Schnell & Grundlegend)
Das integrierte Sortierwerkzeug ist der schnellste Weg, um Daten nach einer einzelnen Spalte zu sortieren. Es ist ideal für einfache Aufgaben, wie das alphabetische Sortieren von Namen oder das Sortieren von Zahlen von klein nach groß.
Schritt-für-Schritt-Anleitung:
- Markieren Sie die einzelne Spalte, die Sie sortieren möchten.
- Gehen Sie im Excel-Menüband auf die Registerkarte Daten.
- Klicken Sie entweder auf Von A bis Z sortieren (aufsteigende Reihenfolge: A→Z, 1→100) oder Von Z bis A sortieren (absteigende Reihenfolge: Z→A, 100→1).
- Ein Popup-Fenster erscheint: Auswahl erweitern. Lassen Sie diese Option aktiviert.
- Klicken Sie auf Sortieren, um den Vorgang abzuschließen.
Profi-Tipp:
- Die Option Auswahl erweitern stellt sicher, dass alle zugehörigen Daten in benachbarten Spalten zusammen mit der ausgewählten Spalte sortiert werden. In den meisten Fällen sollten Sie diese Option aktiviert lassen, um Datenbeziehungen nicht zu zerstören.
- Wenn Ihre Daten eine Kopfzeile haben (z. B. „Name“, „E-Mail“), aktivieren Sie das Kontrollkästchen Daten haben Überschriften im Popup-Fenster. Dies verhindert, dass Excel die Kopfzeile selbst mit sortiert (z. B. landet „Name“ dann nicht am Ende der Spalte).
Methode 2: Daten in Excel nach mehreren Spalten sortieren (Benutzerdefiniertes Sortieren)
Bei komplexeren Datensätzen reicht das Sortieren nach einer Spalte oft nicht aus. Sie möchten beispielsweise Verkaufsdaten zuerst nach „Region“ (aufsteigend) und dann nach „Verkaufsbetrag“ (absteigend) sortieren, um die leistungsstärksten Einträge in jeder Region zu sehen. Hier kommt das benutzerdefinierte Sortieren ins Spiel.
Schritt-für-Schritt-Anleitung:
- Wählen Sie eine beliebige Zelle innerhalb Ihres Datensatzes aus (damit erkennt Excel die gesamte Tabelle).
- Gehen Sie auf die Registerkarte Daten und klicken Sie auf Sortieren (nicht auf die A→Z/Z→A-Schaltflächen).
- Im Fenster „Sortieren“:
- Wählen Sie die erste Spalte (z. B. „Region“) und setzen Sie die Reihenfolge auf A bis Z.
- Klicken Sie auf Ebene hinzufügen, um eine weitere Spalte (z. B. „Verkaufsbetrag“) auszuwählen, und setzen Sie die Reihenfolge auf Größte nach Kleinste.
- Wählen Sie die erste Spalte (z. B. „Region“) und setzen Sie die Reihenfolge auf A bis Z.
- Klicken Sie auf OK, um die Sortierung anzuwenden. Ihre Daten werden nun nach der Spalte „Region“ organisiert, wobei Gleichstände durch die Spalte „Verkaufsbetrag“ aufgelöst werden.
Wichtige Erkenntnis:
Excel sortiert hierarchisch – es sortiert zuerst nach der ersten Spalte und löst dann Gleichstände anhand der nächsten Spalte auf.
Anwendungsbeispiele:
- Verkaufsberichte (Region → Umsatz)
- Mitarbeiterlisten (Abteilung → Rolle)
- Inventar (Kategorie → Lagerbestand)
Methode 3: Daten in Excel mit Formeln sortieren (SORT & SORTBY)
Wenn Ihre Daten häufig aktualisiert werden, ist manuelles Sortieren ineffizient. Excel-Formeln wie SORT und SORTBY ermöglichen es Ihnen, dynamische, automatisch aktualisierende sortierte Listen zu erstellen.
Im Gegensatz zur herkömmlichen Sortierung verändern diese Funktionen die Originaldaten nicht. Stattdessen generieren sie eine dynamisch sortierte Kopie, die sich automatisch aktualisiert.
Die SORT-Funktion verwenden (Am einfachsten für modernes Excel)
Die SORT-Funktion sortiert einen Datenbereich und gibt ein neues sortiertes Array zurück. Syntax: =SORT(Bereich; [Sortierindex]; [Sortierreihenfolge]; [Nach_Spalte])
- Geben Sie in eine leere Zelle (z. B. J1) die Formel ein: =SORT(A1:H11; 1; -1; FALSCH)
- A1:H11: Der gesamte Datensatz, den Sie sortieren möchten.
- 1: Die Spalte, nach der sortiert werden soll.
- -1: Sortierreihenfolge (1 = aufsteigend, -1 = absteigend).
- FALSCH: Sortierung nach Zeilen (Standard; verwenden Sie WAHR, um nach Spalten zu sortieren).
- Drücken Sie die Eingabetaste. Excel generiert eine dynamische sortierte Liste im Bereich ab J1. Wenn Sie die Originaldaten ändern (z. B. einen Verkaufsbetrag anpassen), aktualisiert sich die sortierte Liste automatisch.
Die SORTBY-Funktion verwenden (Flexibler)
=SORTBY(A1:H11; G1:G11; -1)
Die SORTBY-Funktion sortiert einen Datensatz basierend auf Werten in einem oder mehreren separaten Bereichen. Im Gegensatz zur SORT-Funktion, die auf Spaltenpositionen basiert, können Sie mit SORTBY genau definieren, welcher Bereich die Sortierreihenfolge bestimmt.
Funktionsweise:
- A1:H11 → Der zurückzugebende Datensatz (die vollständige Tabelle)
- G1:G11 → Der Bereich, der als Sortierschlüssel dient (z. B. „Verkaufsbetrag“)
- -1 → Sortierreihenfolge (1 = aufsteigend, -1 = absteigend)
Beispielanwendung:
Sortieren einer Verkaufstabelle nach Umsatz, ohne den ursprünglichen Datensatz zu verändern.
Methode 4: Gefilterte Daten in Excel sortieren (Flexible Analyse)
Filter ermöglichen es Ihnen, bestimmte Teilmengen Ihrer Daten schnell zu untersuchen und zu sortieren, ohne den ursprünglichen Datensatz dauerhaft zu verändern. Dies ist besonders nützlich bei großen Datensätzen, etwa bei der Analyse von Verkäufen aus einer bestimmten Region oder einem bestimmten Zeitraum.
Schritt-für-Schritt-Anleitung:
- Wählen Sie Ihren Datensatz inklusive Kopfzeile aus.
- Gehen Sie auf die Registerkarte Daten und klicken Sie auf Filtern (oder verwenden Sie das Tastenkürzel: Strg+Umschalt+L). In jeder Kopfzeilenzelle erscheinen kleine Dropdown-Pfeile.
- Klicken Sie auf den Dropdown-Pfeil in der Spalte, die Sie sortieren möchten (z. B. „Region“), deaktivieren Sie die Regionen, die Sie nicht benötigen (z. B. „Ost“, „Nord“, „Süd“), und klicken Sie auf OK.
- Klicken Sie auf den Dropdown-Pfeil in der Spalte „Verkaufsbetrag“ und wählen Sie Von Klein nach Groß sortieren (aufsteigend) oder Von Groß nach Klein sortieren (absteigend). Dies sortiert nur die gefilterten (sichtbaren) Zeilen.
- Um den Filter zu entfernen und zum ursprünglichen Datensatz zurückzukehren, klicken Sie erneut auf Filtern (oder Strg+Umschalt+L).
Hauptvorteil:
Filter erlauben es Ihnen, Sortierung mit Datenfilterung zu kombinieren, was die Untersuchung spezifischer Teilmengen erleichtert (z. B. Sortieren von hochwertigen Verkäufen nur in einer bestimmten Region), ohne die ursprüngliche Datenstruktur zu verändern.
Methode 5: Excel-Daten mit Python sortieren (Automatisierung & Skalierbarkeit)
Für große Datensätze (10.000+ Zeilen) oder wiederkehrende Sortieraufgaben (z. B. Sortieren täglicher Excel-Berichte) ist Python-Automatisierung ein echter Game-Changer. Wir verwenden Spire.XLS for Python – eine leistungsstarke Bibliothek, die die Bearbeitung von Excel-Dateien, einschließlich Sortieren, vereinfacht, ohne dass Excel auf Ihrem Computer installiert sein muss.
Voraussetzungen:
- Installieren Sie Spire.XLS for Python: Führen Sie pip install Spire.XLS in Ihrem Terminal/Eingabeaufforderung aus.
- Bereiten Sie Ihre Excel-Eingabedatei (z. B. „Input.xlsx“) mit den Daten vor, die Sie sortieren möchten.
Python-Code (Schritt für Schritt):
from spire.xls.common import *
from spire.xls import *
# Erstellen einer Workbook-Instanz
workbook = Workbook()
# Laden der Excel-Eingabedatei
workbook.LoadFromFile("Input.xlsx")
# Abrufen des ersten Arbeitsblatts
worksheet = workbook.Worksheets[0]
# Definieren der Sortierregel: Sortiere Spalte B (Index 1) nach Werten in aufsteigender Reihenfolge
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Festlegen des zu sortierenden Zellbereichs
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Speichern der sortierten Daten in einer neuen Excel-Datei
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Anpassen des Codes:
- Andere Spalte sortieren: Ändern Sie den ersten Parameter in Add() (z. B. 0 für Spalte A, 1 für Spalte B).
- Absteigende Sortierung: Ersetzen Sie OrderBy.Ascending durch OrderBy.Descending.
- Größeren Bereich sortieren: Ändern Sie worksheet["A1:H11"] (z. B. worksheet["A1:G1000"] für 1000 Zeilen, 7 Spalten).
- Mehrere Spalten: Fügen Sie eine zweite Sortierregel mit workbook.DataSorter.SortColumns.Add() hinzu (z. B. Spalte A aufsteigend, dann Spalte B absteigend).
Anwendungsfall:
Diese Methode ist perfekt für die Automatisierung wiederkehrender Aufgaben – z. B. das tägliche Sortieren von 50+ Excel-Dateien oder das Sortieren von Datensätzen, die für Excel zu groß sind.
Neben dem Sortieren von Daten können Sie Python auch zur Automatisierung anderer Excel-Aufgaben verwenden, wie z. B. Formatierung von Arbeitsblättern, Anwenden von Stilen und Exportieren von Excel-Dateien in PDF. Diese Funktionen erleichtern den Aufbau vollständiger Dokumentenverarbeitungs-Workflows.
Vergleichstabelle: Welche Methode sollten Sie wählen?
| Methode | Am besten geeignet für | Vorteile | Nachteile |
|---|---|---|---|
| Integrierte Sortierung | Schnelle Sortierung nach einer Spalte | Einfach, keine Einrichtung erforderlich | Begrenzt auf einfache Sortierung; manuell |
| Benutzerdefinierte Sortierung | Mehrspaltige, hierarchische Sortierung | Flexibel, bewältigt komplexe Datensätze | Erfordert einige zusätzliche Schritte |
| Excel-Formeln | Dynamische, automatisch aktualisierende Listen | Kein manuelles Neusortieren; aktualisiert sich mit Daten | SORT-Funktion nur in modernem Excel verfügbar |
| Filter | Temporäres Sortieren/Untersuchen von Teilmengen | Nicht destruktiv; kombinierbar mit Filtern | Nicht ideal für dauerhafte Sortierung |
| Python (Spire.XLS) | Große Datensätze, Automatisierung | Skalierbar, wiederkehrende Aufgaben, kein Excel nötig | Erfordert grundlegende Python-Kenntnisse |
Fazit
Sortieren in Excel ist mehr als nur das Anordnen von Daten – es geht darum, Informationen nutzbar und aussagekräftig zu machen.
- Verwenden Sie die integrierte Sortierung für schnelle Aufgaben.
- Verwenden Sie die benutzerdefinierte Sortierung für strukturierte Analysen.
- Verwenden Sie Formeln für dynamische Ergebnisse.
- Verwenden Sie Filter für flexible Analysen.
- Verwenden Sie Python für die Automatisierung in großem Maßstab.
Die Beherrschung dieser Methoden ermöglicht es Ihnen, alles von einfachen Tabellen bis hin zu komplexen Daten-Workflows mühelos zu bewältigen.
FAQs
F1: Warum sind meine Excel-Daten nach dem Sortieren falsch ausgerichtet?
Dies passiert normalerweise, wenn Auswahl erweitern nicht ausgewählt wurde. Stellen Sie immer sicher, dass zugehörige Spalten beim Sortieren einbezogen werden.
F2: Kann ich nach Zellfarbe oder Schriftfarbe sortieren?
Ja. Wählen Sie im Dialogfeld „Sortieren“ unter „Sortieren nach“ die Option Zellfarbe oder Schriftfarbe.
F3: Kann ich Daten mit leeren Zellen sortieren?
Ja. Excel platziert leere Zellen am Ende (aufsteigend) oder am Anfang (absteigend). Sie können sie bei Bedarf herausfiltern.
F4: Wie mache ich eine Sortierung rückgängig?
Drücken Sie sofort nach dem Sortieren Strg + Z. Wenn Sie bereits andere Änderungen vorgenommen haben, ist das Rückgängigmachen möglicherweise nicht mehr verfügbar.
F5: Warum funktioniert die Excel-Sortierung nicht?
Häufige Ursachen sind:
- Gemischte Datentypen
- Ausgeblendete Zeilen oder Spalten
- Falscher Auswahlbereich
Siehe auch
Сортировка данных в Excel: объяснение 5 простых и продвинутых методов
Оглавление
- Перед началом работы
- Способ 1: Сортировка данных по одному столбцу в Excel (быстро и просто)
- Способ 2: Сортировка данных по нескольким столбцам в Excel (настраиваемая сортировка)
- Способ 3: Сортировка данных в Excel с помощью формул (SORT и SORTBY)
- Способ 4: Сортировка отфильтрованных данных в Excel (гибкий анализ)
- Способ 5: Сортировка данных Excel с помощью Python (автоматизация и масштабируемость)
- Сравнительная таблица: какой метод выбрать
- Заключение
- Часто задаваемые вопросы
Сортировка данных в Excel — это базовый навык, необходимый для организации, анализа и понимания информации. Работаете ли вы со списками клиентов, финансовыми отчетами или большими массивами данных, сортировка поможет вам быстро выявить закономерности, тренды и аномалии.
В этом руководстве вы узнаете 5 практических способов сортировки данных в Excel, включая сортировку по одному и нескольким столбцам, динамическую сортировку с помощью формул и автоматизацию на языке Python.
Быстрая навигация
- Способ 1: Сортировка данных по одному столбцу в Excel (быстро и просто)
- Способ 2: Сортировка данных по нескольким столбцам в Excel (настраиваемая сортировка)
- Способ 3: Сортировка данных в Excel с помощью формул (SORT и SORTBY)
- Способ 4: Сортировка отфильтрованных данных в Excel (гибкий анализ)
- Способ 5: Сортировка данных Excel с помощью Python (автоматизация и масштабируемость)
Перед началом работы
Прежде чем приступать к сортировке данных в Excel, убедитесь, что:
- Ваш набор данных содержит строку заголовков.
- Внутри таблицы нет полностью пустых строк или столбцов.
- Каждый столбец содержит однотипные данные (например, только числа, даты или текст).
Эти проверки помогут избежать ошибок при сортировке и нарушения целостности данных.
Способ 1: Сортировка данных по одному столбцу в Excel (быстро и просто)
Встроенный инструмент сортировки — самый быстрый способ упорядочить данные по одному столбцу. Он идеально подходит для простых задач, таких как сортировка имен в алфавитном порядке или чисел от меньшего к большему.
Пошаговая инструкция:
- Выберите один столбец, по которому хотите выполнить сортировку.
- Перейдите на вкладку Данные на ленте Excel.
- Нажмите Сортировка от А до Я (по возрастанию: А→Я, 1→100) или Сортировка от Я до А (по убыванию: Я→А, 100→1).
- Появится всплывающее окно: Расширить выделенный диапазон. Оставьте этот вариант выбранным.
- Нажмите Сортировка, чтобы завершить процесс.
Совет:
- Опция Расширить выделенный диапазон гарантирует, что все связанные данные в соседних столбцах будут перемещены вместе с выбранным столбцом. В большинстве случаев эту опцию следует оставлять включенной, чтобы не нарушить связи в данных.
- Если в ваших данных есть строка заголовков (например, «Имя», «Email»), установите флажок Мои данные содержат заголовки во всплывающем окне. Это предотвратит сортировку самого заголовка (например, слово «Имя» не окажется в конце списка).
Способ 2: Сортировка данных по нескольким столбцам в Excel (настраиваемая сортировка)
Для сложных наборов данных сортировки по одному столбцу недостаточно. Например, вы можете захотеть отсортировать данные о продажах сначала по «Региону» (по возрастанию), а затем по «Сумме продаж» (по убыванию), чтобы увидеть лучшие показатели в каждом регионе. Здесь на помощь приходит «Настраиваемая сортировка».
Пошаговая инструкция:
- Выберите любую ячейку внутри вашего набора данных (это позволит Excel распознать всю таблицу целиком).
- Перейдите на вкладку Данные и нажмите Сортировка (не кнопки А→Я/Я→А).
- В окне «Сортировка»:
- Выберите первый столбец (например, «Регион») и установите порядок От А до Я.
- Нажмите Добавить уровень, чтобы выбрать следующий столбец (например, «Сумма продаж»), и установите порядок По убыванию.
- Выберите первый столбец (например, «Регион») и установите порядок От А до Я.
- Нажмите ОК, чтобы применить сортировку. Теперь данные будут организованы по столбцу «Регион», а при совпадении регионов — по «Сумме продаж».
Важное замечание:
Excel применяет сортировку иерархически — сначала сортирует по первому столбцу, а затем разрешает совпадения с помощью следующего.
Примеры использования:
- Отчеты о продажах (Регион → Выручка)
- Списки сотрудников (Отдел → Должность)
- Инвентаризация (Категория → Уровень запасов)
Способ 3: Сортировка данных в Excel с помощью формул (SORT и SORTBY)
Если данные часто обновляются, ручная сортировка становится неэффективной. Формулы Excel, такие как SORT и SORTBY, позволяют создавать динамические, автоматически обновляемые списки.
В отличие от традиционной сортировки, эти функции не изменяют исходные данные. Вместо этого они создают динамически отсортированную копию, которая обновляется автоматически.
Использование функции SORT (простой вариант для современного Excel)
Функция SORT сортирует диапазон данных и возвращает новый отсортированный массив. Синтаксис: =SORT(массив; [индекс_сортировки]; [порядок_сортировки]; [по_столбцу])
- В пустой ячейке (например, J1) введите формулу: =SORT(A1:H11; 1; -1; FALSE)
- A1:H11: Весь набор данных, который нужно отсортировать.
- 1: Индекс столбца для сортировки.
- -1: Порядок сортировки (1 = по возрастанию, -1 = по убыванию).
- FALSE: Сортировка по строкам (по умолчанию; используйте TRUE для сортировки по столбцам).
- Нажмите Enter. Excel создаст динамический отсортированный список, начиная с ячейки J1. Если вы измените исходные данные (например, сумму продаж), список обновится автоматически.
Использование функции SORTBY (более гибкий вариант)
=SORTBY(A1:H11; G1:G11; -1)
Функция SORTBY сортирует набор данных на основе значений в одном или нескольких отдельных диапазонах. В отличие от функции SORT, которая опирается на номера столбцов, SORTBY позволяет точно указать диапазон, определяющий порядок сортировки.
Как это работает:
- A1:H11 → Набор данных для вывода (вся таблица).
- G1:G11 → Диапазон, используемый как ключ сортировки (например, «Сумма продаж»).
- -1 → Порядок сортировки (1 = по возрастанию, -1 = по убыванию).
Пример использования:
Отсортировать таблицу продаж по выручке, не меняя исходный набор данных.
Способ 4: Сортировка отфильтрованных данных в Excel (гибкий анализ)
Фильтры позволяют быстро просматривать и сортировать определенные подмножества данных, не меняя исходную таблицу навсегда. Это особенно полезно при работе с большими объемами данных, например, при анализе продаж в конкретном регионе или за определенный период.
Пошаговая инструкция:
- Выберите ваш набор данных, включая строку заголовков.
- Перейдите на вкладку Данные и нажмите Фильтр (или используйте сочетание клавиш: Ctrl+Shift+L). В каждой ячейке заголовка появятся маленькие стрелки раскрывающегося списка.
- Нажмите на стрелку в столбце, который хотите отсортировать (например, «Регион»), снимите флажки с ненужных регионов (например, «Восток», «Север», «Юг») и нажмите ОК.
- Нажмите на стрелку в столбце «Сумма продаж» и выберите Сортировка от минимального к максимальному (по возрастанию) или Сортировка от максимального к минимальному (по убыванию). Это отсортирует только отфильтрованные (видимые) строки.
- Чтобы убрать фильтр и вернуться к исходным данным, снова нажмите Фильтр (или Ctrl+Shift+L).
Ключевое преимущество:
Фильтры позволяют комбинировать сортировку с фильтрацией данных, что упрощает анализ конкретных подмножеств (например, сортировка только крупных сделок в конкретном регионе) без изменения структуры исходных данных.
Способ 5: Сортировка данных Excel с помощью Python (автоматизация и масштабируемость)
Для больших наборов данных (более 10 000 строк) или повторяющихся задач (например, ежедневная сортировка отчетов) автоматизация на Python — это прорыв. Мы будем использовать Spire.XLS for Python — мощную библиотеку, которая упрощает работу с файлами Excel, включая сортировку, без необходимости установки самого Excel на вашем компьютере.
Предварительные требования:
- Установите Spire.XLS for Python: выполните команду pip install Spire.XLS в терминале или командной строке.
- Подготовьте входной файл Excel (например, «Input.xlsx») с данными, которые нужно отсортировать.
Пошаговый код Python (с пояснениями):
from spire.xls.common import *
from spire.xls import *
# Создаем экземпляр рабочей книги
workbook = Workbook()
# Загружаем входной файл Excel
workbook.LoadFromFile("Input.xlsx")
# Получаем первый рабочий лист
worksheet = workbook.Worksheets[0]
# Определяем правило сортировки: сортировать столбец B (индекс 1) по значениям по возрастанию
workbook.DataSorter.SortColumns.Add(1, SortComparsionType.Values, OrderBy.Ascending)
# Указываем диапазон ячеек для сортировки
workbook.DataSorter.Sort(worksheet["A1:H11"])
# Сохраняем отсортированные данные в новый файл Excel
workbook.SaveToFile("SortByColumns.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Как настроить код:
- Сортировка другого столбца: измените первый параметр в Add() (например, 0 для столбца A, 1 для столбца B).
- Сортировка по убыванию: замените OrderBy.Ascending на OrderBy.Descending.
- Сортировка большего диапазона: измените worksheet["A1:H11"] (например, worksheet["A1:G1000"] для 1000 строк и 7 столбцов).
- Несколько столбцов: добавьте второе правило сортировки с помощью workbook.DataSorter.SortColumns.Add() (например, сначала сортировка столбца A по возрастанию, затем столбца B по убыванию).
Пример использования:
Этот метод идеально подходит для автоматизации рутинных задач — например, ежедневной сортировки 50+ файлов Excel или обработки наборов данных, которые слишком велики для плавной работы в самом Excel.
Помимо сортировки, вы можете использовать Python для автоматизации других задач, таких как форматирование листов, применение стилей и экспорт файлов Excel в PDF. Эти возможности позволяют легко создавать полноценные рабочие процессы обработки документов.
Сравнительная таблица: какой метод выбрать
| Метод | Лучше всего подходит для | Плюсы | Минусы |
|---|---|---|---|
| Встроенная сортировка | Быстрой сортировки по одному столбцу | Простота, не требует настройки | Ограничен базовыми задачами; ручной процесс |
| Настраиваемая сортировка | Многоуровневой сортировки по нескольким столбцам | Гибкость, работа со сложными данными | Требует нескольких дополнительных шагов |
| Формулы Excel | Динамических, автоматически обновляемых списков | Нет необходимости в повторной сортировке | Функция SORT доступна только в современном Excel |
| Фильтры | Временной сортировки/анализа подмножеств | Неразрушающий метод; сочетается с фильтрацией | Не подходит для постоянной сортировки |
| Python (Spire.XLS) | Больших наборов данных, автоматизации | Масштабируемость, повторяющиеся задачи, не нужен Excel | Требуются базовые знания Python |
Заключение
Сортировка в Excel — это больше, чем просто упорядочивание данных; это способ сделать информацию полезной и понятной.
- Используйте встроенную сортировку для быстрых задач.
- Используйте настраиваемую сортировку для структурированного анализа.
- Используйте формулы для динамических результатов.
- Используйте фильтры для гибкого исследования данных.
- Используйте Python для автоматизации в больших масштабах.
Освоение этих методов позволит вам с легкостью справляться с любыми задачами: от простых таблиц до сложных рабочих процессов с данными.
Часто задаваемые вопросы
В1: Почему мои данные в Excel смещаются после сортировки?
Обычно это происходит, если не выбрана опция Расширить выделенный диапазон. Всегда следите за тем, чтобы связанные столбцы были включены в сортировку.
В2: Можно ли сортировать по цвету ячейки или шрифта?
Да. В диалоговом окне «Сортировка» выберите Цвет ячейки или Цвет шрифта в поле «Сортировка по».
В3: Можно ли сортировать данные с пустыми ячейками?
Да. Excel помещает пустые ячейки в конец (при сортировке по возрастанию) или в начало (по убыванию). При необходимости их можно отфильтровать.
В4: Как отменить сортировку?
Нажмите Ctrl + Z сразу после сортировки. Если вы уже внесли другие изменения, отмена может быть недоступна.
В5: Почему сортировка в Excel не работает?
Распространенные причины:
- Смешанные типы данных.
- Скрытые строки или столбцы.
- Неверно выбранный диапазон.
Смотрите также
Como remover quebras de página no Word (4 métodos fáceis)
Índice

Você já abriu um documento do Word e encontrou páginas em branco inesperadas ou espaços estranhos? Esses problemas geralmente são causados por quebras de página ocultas ou mal posicionadas. Quer tenham sido adicionadas manualmente ou acionadas por configurações específicas de parágrafo, saber como remover quebras de página no Word é uma habilidade essencial para manter sua formatação limpa e profissional.
Este guia aborda quatro maneiras práticas de remover quebras de página no Word, desde cliques manuais simples até soluções automatizadas.
- Remover quebras de página usando o recurso Mostrar/Ocultar
- Remover quebras de página com Localizar e Substituir
- Remover quebras de página ajustando quebras automáticas
- Remover quebras de página usando código (Free Spire.Doc)
- Perguntas frequentes
Remover uma quebra de página no Microsoft Word com o recurso Mostrar/Ocultar
Se você tem apenas uma ou duas quebras para corrigir, a maneira mais direta de remover uma quebra de página em documentos do Word é encontrar o marcador oculto e excluí-lo. O Word mantém esses marcadores invisíveis por padrão para manter a interface limpa, então você precisa primeiro torná-los visíveis. Aqui estão os passos que você pode seguir:
- Passo 1: Vá para a guia Página Inicial e clique no ícone Mostrar/Ocultar ¶ (ou pressione Ctrl + Shift + 8). Isso revelará todas as marcas de formatação ocultas.
- Passo 2: Encontre as quebras de página no documento. Elas aparecem como uma linha pontilhada com o rótulo "Quebra de Página".
- Passo 3: Clique nessa linha e pressione a tecla Delete ou Backspace no seu teclado.
Dica profissional: Às vezes, espaços indesejados são causados por uma série de parágrafos vazios em vez de uma quebra de página. Se você vir vários símbolos ¶ sem texto, talvez também precise remover linhas em branco para organizar completamente o layout do seu documento.
Remover uma quebra de página no Microsoft Word com Localizar e Substituir
Ao trabalhar com documentos longos ou desorganizados, pode ser necessário remover todas as quebras de página de uma vez. Removê-las uma por uma pode ser demorado. Em vez disso, você pode usar a ferramenta Localizar e Substituir para limpar o documento inteiro em segundos. Além de apenas localizar e substituir texto normal, esse recurso permite que você direcione caracteres especiais e marcadores de formatação, proporcionando um nível profissional de controle sobre o layout.
- Passo 1: Pressione Ctrl + H para abrir a caixa de diálogo Localizar e Substituir.
- Passo 2: Na caixa Localizar, digite
^m(o código especial para uma quebra de página manual).
- Passo 3: Deixe a caixa Substituir por vazia e clique em Substituir Tudo.
Esta é a maneira mais rápida de remover todas as quebras de página em arquivos do Word quando você deseja redefinir completamente o fluxo do seu texto.
Remover uma quebra de página em documentos do Word ajustando quebras automáticas
Às vezes, você pode tentar remover uma quebra de página no Microsoft Word e descobrir que não há marcador para excluir. Essas quebras não aparecerão como uma linha visível de Quebra de Página, mesmo quando as marcas de formatação estiverem ativadas. Isso acontece porque a quebra é uma regra de parágrafo em vez de um caractere. Mesmo assim, ainda existem maneiras eficazes de encontrá-las e removê-las ajustando a formatação do parágrafo.
- Passo 1: Selecione o parágrafo que está pulando para uma nova página inesperadamente.
- Passo 2: Clique com o botão direito no texto e escolha Parágrafo, depois navegue até a guia Quebras de Linha e de Página.
- Passo 3: Desmarque a caixa Quebra de página antes.
Usar este método é a maneira mais eficaz de remover quebras de página no Word que parecem presas ou inamovíveis. Ele aborda a lógica de formatação subjacente do documento em vez de procurar um caractere para excluir, garantindo que seu texto flua naturalmente sem interrupções forçadas.
Remover quebras de página em um documento do Word usando código (Free Spire.Doc)
Para aqueles que gerenciam grandes volumes de documentos, remover manualmente as quebras de página no Word não é prático. Desenvolvedores frequentemente usam bibliotecas como o Free Spire.Doc for Python para automatizar o processo.
O script irá escanear cada seção e parágrafo de um documento para identificar objetos de Quebra (Break) específicos. Uma vez que uma quebra de página é detectada dentro da estrutura do documento, o Free Spire.Doc a removerá diretamente da coleção de objetos.
Este método garante consistência em centenas de arquivos sem abri-los um por um. Abaixo está um exemplo em Python de como remover todas as quebras de página em um arquivo Word usando a biblioteca Free Spire.Doc:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Criar um objeto Document
document = Document()
# Carregar um documento Word
document.LoadFromFile(inputFile)
# Iterar por todas as seções no documento
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# Iterar por todos os parágrafos em cada seção
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# Iterar pelos objetos filhos de trás para frente para evitar erros de índice durante a remoção
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# Verificar se o objeto é uma quebra
if isinstance(child, Break):
break_obj = child
# Remover o objeto se for uma quebra de página
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# Salvar o arquivo resultante
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Aqui está a prévia do documento Word original e do arquivo de saída:

Conclusão
Gerenciar o fluxo do documento torna-se muito mais fácil quando você entende como as quebras de página funcionam. Se você prefere o botão Mostrar/Ocultar, o método Localizar e Substituir ou ajustar as configurações de parágrafo, agora você tem as ferramentas para remover quebras de página em documentos do Word de forma eficaz. Para ainda mais eficiência, usar código com o Free Spire.Doc permite que você lide com tarefas complexas em vários arquivos. Ao dominar essas quatro técnicas, você pode garantir que seus documentos sempre tenham a aparência pretendida, sem interrupções inesperadas.
Perguntas frequentes sobre como remover quebras de página
P1: Como removo todas as quebras de página no Word de uma só vez?
R: A maneira mais rápida é usar a ferramenta Localizar e Substituir. Pressione Ctrl + H, digite ^m na caixa Localizar e clique em Substituir Tudo. Isso limpará instantaneamente todas as quebras de página manuais no seu documento.
P2: Por que não consigo excluir certas quebras de página no meu documento?
R: Se uma quebra não se move, geralmente é devido a uma de duas coisas: ou o Controle de Alterações está ativado ou você está lidando com uma configuração de parágrafo de Quebra de página antes. Além disso, certifique-se de não confundir uma quebra de página com uma quebra de seção; para remover uma quebra de seção, você precisaria pesquisar por ^b em vez disso.
P3: Como remover quebras de página no Word sem excluir texto?
R: Remover uma quebra de página não exclui suas palavras. Basta ativar as marcas de formatação (¶), colocar o cursor diretamente na linha pontilhada da Quebra de Página e pressionar Delete. Seu texto permanecerá intacto, mas simplesmente subirá para preencher a página anterior.
P4: Existe diferença ao remover quebras de página no Word no Mac?
R: A lógica permanece a mesma. Você pode usar Cmd + 8 para alternar as marcas de formatação ou navegar para Editar > Localizar > Localizar e Substituir Avançado para realizar remoções em lote. A principal diferença é simplesmente usar a tecla Command (⌘) em vez de Control (Ctrl) para seus atalhos.
Leia também:
Word에서 페이지 나누기를 제거하는 방법 (4가지 쉬운 방법)
Word 문서를 열었을 때 예상치 못한 빈 페이지나 어색한 간격을 발견한 적이 있으신가요? 이러한 문제는 대개 숨겨져 있거나 잘못 배치된 페이지 나누기로 인해 발생합니다. 수동으로 추가되었든 특정 단락 설정에 의해 트리거되었든, Word에서 페이지 나누기를 제거하는 방법을 아는 것은 문서 서식을 깔끔하고 전문적으로 유지하는 데 필수적인 기술입니다.
이 가이드에서는 간단한 수동 클릭부터 자동화된 솔루션까지, Word에서 페이지 나누기를 제거하는 네 가지 실용적인 방법을 다룹니다.
- 표시/숨기기 기능을 사용하여 페이지 나누기 제거
- 찾기 및 바꾸기로 페이지 나누기 제거
- 자동 페이지 나누기 조정을 통해 페이지 나누기 제거
- 코드를 사용하여 페이지 나누기 제거 (Free Spire.Doc)
- 자주 묻는 질문(FAQs)
표시/숨기기 기능을 사용하여 Microsoft Word에서 페이지 나누기 제거
수정해야 할 나누기가 한두 개뿐이라면, Word 문서에서 페이지 나누기를 제거하는 가장 직접적인 방법은 숨겨진 표시를 찾아 삭제하는 것입니다. Word는 인터페이스를 깔끔하게 유지하기 위해 기본적으로 이러한 표시를 숨기므로, 먼저 이를 보이게 설정해야 합니다. 다음 단계를 따르세요:
- 1단계: 홈 탭으로 이동하여 표시/숨기기 ¶ 아이콘을 클릭합니다(또는 Ctrl + Shift + 8을 누릅니다). 모든 숨겨진 서식 기호가 나타납니다.
- 2단계: 문서에서 페이지 나누기를 찾습니다. "페이지 나누기"라고 표시된 점선으로 나타납니다.
- 3단계: 해당 선을 클릭하고 키보드의 Delete 또는 Backspace 키를 누릅니다.
전문가 팁: 때때로 원치 않는 간격은 페이지 나누기가 아니라 일련의 빈 단락 때문에 발생합니다. 텍스트가 없는 ¶ 기호가 여러 개 보인다면, 문서 레이아웃을 완전히 정리하기 위해 빈 줄 제거가 필요할 수도 있습니다.
찾기 및 바꾸기를 사용하여 Microsoft Word에서 페이지 나누기 제거
길거나 복잡한 문서를 작업할 때는 모든 페이지 나누기를 한 번에 제거해야 할 수도 있습니다. 하나씩 제거하는 것은 시간이 많이 걸릴 수 있습니다. 대신 찾기 및 바꾸기 도구를 사용하여 몇 초 만에 문서 전체를 정리할 수 있습니다. 단순히 일반 텍스트를 찾고 바꾸는 것을 넘어, 이 기능을 사용하면 특수 문자 및 서식 표시를 대상으로 지정하여 레이아웃을 전문적으로 제어할 수 있습니다.
- 1단계: Ctrl + H를 눌러 찾기 및 바꾸기 대화 상자를 엽니다.
- 2단계: 찾을 내용 상자에
^m(수동 페이지 나누기에 대한 특수 코드)을 입력합니다.
- 3단계: 바꿀 내용 상자는 비워두고 모두 바꾸기를 클릭합니다.
이는 텍스트 흐름을 완전히 재설정하고 싶을 때 Word 파일에서 모든 페이지 나누기를 제거하는 가장 빠른 방법입니다.
자동 페이지 나누기 조정을 통해 Word 문서에서 페이지 나누기 제거
때때로 Microsoft Word에서 페이지 나누기를 제거하려고 해도 삭제할 표시가 없는 경우가 있습니다. 이러한 나누기는 서식 기호를 활성화해도 눈에 보이는 '페이지 나누기' 선으로 나타나지 않습니다. 이는 해당 나누기가 문자가 아닌 단락 규칙이기 때문입니다. 그럼에도 불구하고 단락 서식을 조정하여 이를 찾고 제거하는 효과적인 방법이 있습니다.
- 1단계: 예기치 않게 새 페이지로 넘어가는 단락을 선택합니다.
- 2단계: 텍스트를 마우스 오른쪽 버튼으로 클릭하고 단락을 선택한 다음, 줄 및 페이지 나누기 탭으로 이동합니다.
- 3단계: 페이지 나누기 전 확인란의 선택을 취소합니다.
이 방법을 사용하는 것은 고정되어 있거나 삭제할 수 없는 것처럼 느껴지는 Word의 페이지 나누기를 제거하는 가장 효과적인 방법입니다. 삭제할 문자를 찾는 대신 문서의 기본 서식 논리를 해결하므로, 강제적인 중단 없이 텍스트가 자연스럽게 흐르도록 보장합니다.
코드를 사용하여 Word 문서에서 페이지 나누기 제거 (Free Spire.Doc)
대량의 문서를 관리하는 경우 수동으로 Word의 페이지 나누기를 제거하는 것은 실용적이지 않습니다. 개발자들은 종종 Free Spire.Doc for Python과 같은 라이브러리를 사용하여 이 과정을 자동화합니다.
이 스크립트는 문서의 모든 섹션과 단락을 스캔하여 특정 Break 객체를 식별합니다. 문서 구조 내에서 페이지 나누기가 감지되면 Free Spire.Doc이 객체 컬렉션에서 직접 이를 제거합니다.
이 방법을 사용하면 수백 개의 파일을 하나씩 열지 않고도 일관성을 유지할 수 있습니다. 다음은 Free Spire.Doc 라이브러리를 사용하여 Word 파일에서 모든 페이지 나누기를 제거하는 Python 예제입니다:
from spire.doc import *
from spire.doc.common import *
inputFile = "/input/sample.docx"
outputFile = "/output/RemovePageBreaks.docx"
# Document 객체 생성
document = Document()
# Word 문서 로드
document.LoadFromFile(inputFile)
# 문서의 모든 섹션을 반복
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
# 각 섹션의 모든 단락을 반복
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
# 제거 중 인덱스 오류를 방지하기 위해 자식 객체를 역순으로 반복
for k in range(paragraph.ChildObjects.Count - 1, -1, -1):
child = paragraph.ChildObjects.get_Item(k)
# 객체가 Break인지 확인
if isinstance(child, Break):
break_obj = child
# 페이지 나누기인 경우 객체 제거
if break_obj.BreakType == BreakType.PageBreak:
paragraph.ChildObjects.Remove(break_obj)
# 결과 파일 저장
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
다음은 원본 Word 문서와 결과 파일의 미리보기입니다:
결론
페이지 나누기가 어떻게 작동하는지 이해하면 문서 흐름을 관리하기가 훨씬 쉬워집니다. 표시/숨기기 버튼, 찾기 및 바꾸기 방법, 또는 단락 설정 조정 중 무엇을 선호하든, 이제 Word 문서에서 페이지 나누기를 효과적으로 제거할 수 있는 도구를 갖추게 되었습니다. 더 높은 효율성을 위해 Free Spire.Doc을 사용한 코딩은 여러 파일에 걸친 복잡한 작업을 처리할 수 있게 해줍니다. 이 네 가지 기술을 마스터하면 예기치 않은 중단 없이 문서가 항상 의도한 대로 보이도록 할 수 있습니다.
페이지 나누기 제거에 관한 자주 묻는 질문(FAQs)
Q1: Word에서 모든 페이지 나누기를 한 번에 제거하려면 어떻게 하나요?
A: 가장 빠른 방법은 찾기 및 바꾸기 도구를 사용하는 것입니다. Ctrl + H를 누르고 찾을 내용 상자에 ^m을 입력한 다음 모두 바꾸기를 클릭하세요. 이렇게 하면 문서의 모든 수동 페이지 나누기가 즉시 제거됩니다.
Q2: 문서의 특정 페이지 나누기를 삭제할 수 없는 이유는 무엇인가요?
A: 나누기가 제거되지 않는다면 대개 두 가지 이유 중 하나입니다. 변경 내용 추적이 활성화되어 있거나 페이지 나누기 전 단락 설정과 관련된 경우입니다. 또한, 페이지 나누기를 구역 나누기와 혼동하지 않도록 주의하세요. 구역 나누기를 제거하려면 대신 ^b를 검색해야 합니다.
Q3: 텍스트를 삭제하지 않고 Word에서 페이지 나누기를 제거하려면 어떻게 하나요?
A: 페이지 나누기를 제거해도 텍스트는 삭제되지 않습니다. 단순히 서식 기호(¶)를 켜고, 커서를 페이지 나누기 점선 바로 위에 놓은 다음 Delete를 누르세요. 텍스트는 그대로 유지되면서 이전 페이지를 채우기 위해 위로 이동합니다.
Q4: Mac의 Word에서 페이지 나누기를 제거할 때 차이점이 있나요?
A: 논리는 동일합니다. Cmd + 8을 사용하여 서식 기호를 전환하거나 편집 > 찾기 > 고급 찾기 및 바꾸기로 이동하여 일괄 제거를 수행할 수 있습니다. 주요 차이점은 단축키 사용 시 Control (Ctrl) 대신 Command (⌘) 키를 사용하는 것뿐입니다.