Excel-Dateien in Python erstellen: Von den Grundlagen bis zur Automatisierung
Inhaltsverzeichnis

Das Erstellen von Excel-Dateien in Python ist eine häufige Anforderung in datengesteuerten Anwendungen. Wenn Anwendungsdaten in einem Format bereitgestellt werden müssen, das von Geschäftsanwendern leicht überprüft und geteilt werden kann, bleibt Excel eine der praktischsten und am weitesten verbreiteten Optionen.
In realen Projekten ist das Erstellen einer Excel-Datei mit Python oft der Ausgangspunkt eines automatisierten Prozesses. Die Daten können aus Datenbanken, APIs oder internen Diensten stammen, und Python ist dafür verantwortlich, diese Daten in eine strukturierte Excel-Datei umzuwandeln, die einem einheitlichen Layout und einer einheitlichen Namenskonvention folgt.
Dieser Artikel zeigt, wie man Excel-Dateien in Python erstellt, vom Erstellen einer Arbeitsmappe von Grund auf über das Schreiben von Daten und das Anwenden grundlegender Formatierungen bis hin zum Aktualisieren vorhandener Dateien bei Bedarf. Alle Beispiele werden aus praktischer Sicht vorgestellt und konzentrieren sich darauf, wie Excel-Dateien in realen Automatisierungsszenarien erstellt und verwendet werden.
Inhaltsverzeichnis
- Typische Szenarien zum Erstellen von Excel-Dateien in Python
- Umgebungseinrichtung
- Erstellen einer neuen Excel-Datei von Grund auf in Python
- Schreiben strukturierter Daten in eine XLSX-Datei mit Python
- Formatieren von Excel-Daten für praxisnahe Berichte in Python
- Lesen und Aktualisieren vorhandener Excel-Dateien in Python
- Kombinieren von Lese- und Schreibvorgängen in einem einzigen Arbeitsablauf
- Auswahl des richtigen Python-Ansatzes zur Erstellung von Excel-Dateien
- Häufige Probleme und Lösungen
- Häufig gestellte Fragen
1. Typische Szenarien zum Erstellen von Excel-Dateien mit Python
Das Erstellen von Excel-Dateien mit Python geschieht in der Regel als Teil eines größeren Systems und nicht als eigenständige Aufgabe. Häufige Szenarien sind:
- Erstellen von täglichen, wöchentlichen oder monatlichen Geschäftsberichten
- Exportieren von Datenbankabfrageergebnissen zur Analyse oder Prüfung
- Erstellen von Excel-Dateien aus Backend-Diensten oder Batch-Jobs
- Automatisierung des Datenaustauschs zwischen internen Systemen oder externen Partnern
In diesen Situationen wird Python oft verwendet, um Excel-Dateien automatisch zu erstellen, was Teams hilft, den manuellen Aufwand zu reduzieren und gleichzeitig die Datenkonsistenz und Wiederholbarkeit zu gewährleisten.
2. Umgebungseinrichtung: Vorbereitung zum Erstellen von Excel-Dateien in Python
In diesem Tutorial verwenden wir Free Spire.XLS for Python, um Excel-Dateivorgänge zu demonstrieren. Bevor Sie Excel-Dateien mit Python erstellen, stellen Sie sicher, dass die Entwicklungsumgebung bereit ist.
Python-Version
Jede moderne Python 3.x-Version ist für Excel-Automatisierungsaufgaben ausreichend.
Free Spire.XLS for Python kann über pip installiert werden:
pip install spire.xls.freeSie können auch Free Spire.XLS for Python herunterladen und manuell in Ihr Projekt einbinden.
Die Bibliothek funktioniert unabhängig von Microsoft Excel, was sie für Serverumgebungen, geplante Aufträge und automatisierte Arbeitsabläufe geeignet macht, in denen Excel nicht installiert ist.
3. Erstellen einer neuen Excel-Datei von Grund auf in Python
Dieser Abschnitt konzentriert sich auf das Erstellen einer Excel-Datei von Grund auf mit Python. Das Ziel ist es, eine grundlegende Arbeitsmappenstruktur zu definieren, einschließlich Arbeitsblättern und Kopfzeilen, bevor Daten geschrieben werden.
Durch das programmgesteuerte Erstellen des anfänglichen Layouts können Sie sicherstellen, dass alle Ausgabedateien die gleiche Struktur haben und für die spätere Datenbefüllung bereit sind.
Beispiel: Erstellen einer leeren Excel-Vorlage
from spire.xls import Workbook, FileFormat
# Initialize a new workbook
workbook = Workbook()
# Access the default worksheet
sheet = workbook.Worksheets[0]
sheet.Name = "Template"
# Add a placeholder title
sheet.Range["B2"].Text = "Monthly Report Template"
# Save the Excel file
workbook.SaveToFile("template.xlsx", FileFormat.Version2016)
workbook.Dispose()
Die Vorschau der Vorlagendatei:
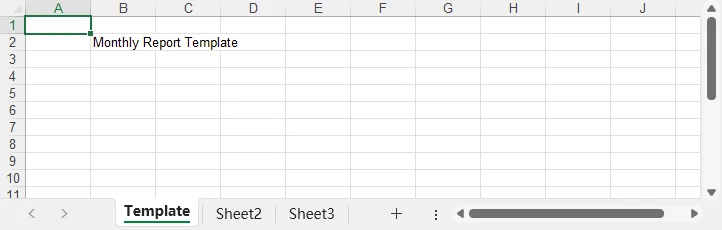
In diesem Beispiel:
- Workbook() erstellt eine neue Excel-Arbeitsmappe, die bereits drei Standardarbeitsblätter enthält.
- Auf das erste Arbeitsblatt wird über Worksheets[0] zugegriffen und es wird umbenannt, um die Grundstruktur zu definieren.
- Die Eigenschaft Range[].Text schreibt Text in eine bestimmte Zelle, sodass Sie Titel oder Platzhalter festlegen können, bevor echte Daten hinzugefügt werden.
- Die Methode SaveToFile() speichert die Arbeitsmappe in einer Excel-Datei. Und FileFormat.Version2016 gibt die zu verwendende Excel-Version oder das Format an.
Erstellen von Excel-Dateien mit mehreren Arbeitsblättern in Python
Bei der Python-basierten Excel-Erstellung kann eine einzelne Arbeitsmappe mehrere Arbeitsblätter enthalten, um zusammengehörige Daten logisch zu organisieren. Jedes Arbeitsblatt kann einen anderen Datensatz, eine Zusammenfassung oder ein Verarbeitungsergebnis innerhalb derselben Datei speichern.
Das folgende Beispiel zeigt, wie man eine Excel-Datei mit mehreren Arbeitsblättern erstellt und Daten in jedes schreibt.
from spire.xls import Workbook, FileFormat
workbook = Workbook()
# Default worksheet
data_sheet = workbook.Worksheets[0]
data_sheet.Name = "Raw Data"
# Remove the second default worksheet
workbook.Worksheets.RemoveAt(1)
# Add a summary worksheet
summary_sheet = workbook.Worksheets.Add("Summary")
summary_sheet.Range["A1"].Text = "Summary Report"
workbook.SaveToFile("multi_sheet_report.xlsx", FileFormat.Version2016)
workbook.Dispose()
Dieses Muster wird häufig mit Lese-/Schreib-Workflows kombiniert, bei denen Rohdaten in ein Arbeitsblatt importiert und verarbeitete Ergebnisse in ein anderes geschrieben werden.
Excel-Dateiformate in der Python-Automatisierung
Beim programmgesteuerten Erstellen von Excel-Dateien in Python ist XLSX das am häufigsten verwendete Format und wird von modernen Versionen von Microsoft Excel vollständig unterstützt. Es unterstützt Arbeitsblätter, Formeln, Stile und ist für die meisten Automatisierungsszenarien geeignet.
Zusätzlich zu XLSX unterstützt Spire.XLS for Python das Erstellen mehrerer gängiger Excel-Formate, darunter:
- XLSX – das Standardformat für die moderne Excel-Automatisierung
- XLS – altes Excel-Format zur Kompatibilität mit älteren Systemen
- CSV – reines Textformat, das häufig für den Datenaustausch und Importe verwendet wird
In diesem Artikel verwenden alle Beispiele das XLSX-Format, das für die Berichterstellung, strukturierte Datenexporte und vorlagenbasierte Excel-Dateien empfohlen wird. Eine vollständige Liste der unterstützten Formate finden Sie in der FileFormat-Enumeration.
4. Schreiben strukturierter Daten in eine XLSX-Datei mit Python
In realen Anwendungen stammen die in Excel geschriebenen Daten selten aus fest codierten Listen. Sie werden häufiger aus Datenbankabfragen, API-Antworten oder Zwischenverarbeitungsergebnissen generiert.
Ein typisches Muster besteht darin, Excel als endgültiges Lieferformat für bereits strukturierte Daten zu behandeln.
Python-Beispiel: Erstellen eines monatlichen Verkaufsberichts aus Anwendungsdaten
Angenommen, Ihre Anwendung hat bereits eine Liste von Verkaufsdatensätzen erstellt, wobei jeder Datensatz Produktinformationen und berechnete Summen enthält. In diesem Beispiel werden die Verkaufsdaten als eine Liste von Wörterbüchern dargestellt, die von einer Anwendungs- oder Dienstschicht zurückgegebene Datensätze simulieren.
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "Sales Report"
headers = ["Product", "Quantity", "Unit Price", "Total Amount"]
for col, header in enumerate(headers, start=1):
sheet.Range[1, col].Text = header
# Data typically comes from a database or service layer
sales_data = [
{"product": "Laptop", "qty": 15, "price": 1200},
{"product": "Monitor", "qty": 30, "price": 250},
{"product": "Keyboard", "qty": 50, "price": 40},
{"product": "Mouse", "qty": 80, "price": 20},
{"product": "Headset", "qty": 100, "price": 10}
]
row = 2
for item in sales_data:
sheet.Range[row, 1].Text = item["product"]
sheet.Range[row, 2].NumberValue = item["qty"]
sheet.Range[row, 3].NumberValue = item["price"]
sheet.Range[row, 4].NumberValue = item["qty"] * item["price"]
row += 1
workbook.SaveToFile("monthly_sales_report.xlsx")
workbook.Dispose()
Die Vorschau des monatlichen Verkaufsberichts:

In diesem Beispiel werden Textwerte wie Produktnamen mit der Eigenschaft CellRange.Text geschrieben, während numerische Felder CellRange.NumberValue verwenden. Dadurch wird sichergestellt, dass Mengen und Preise als Zahlen in Excel gespeichert werden, was eine korrekte Berechnung, Sortierung und Formatierung ermöglicht.
Dieser Ansatz skaliert auf natürliche Weise mit wachsendem Datensatz und hält die Geschäftslogik von der Excel-Ausgabelogik getrennt. Weitere Beispiele zum Schreiben in Excel finden Sie unter Wie man das Schreiben in Excel in Python automatisiert.
5. Formatieren von Excel-Daten für praxisnahe Berichte in Python
In der realen Berichterstattung werden Excel-Dateien oft direkt an die Beteiligten geliefert. Rohdaten ohne Formatierung können schwer zu lesen oder zu interpretieren sein.
Häufige Formatierungsaufgaben sind:
- Kopfzeilen visuell hervorheben
- Anwenden von Hintergrundfarben oder Rahmen
- Formatieren von Zahlen und Währungen
- Automatisches Anpassen der Spaltenbreiten
Das folgende Beispiel zeigt, wie diese gängigen Formatierungsoperationen zusammen angewendet werden können, um die allgemeine Lesbarkeit eines generierten Excel-Berichts zu verbessern.
Python-Beispiel: Verbesserung der Lesbarkeit von Excel-Berichten
from spire.xls import Workbook, Color, LineStyleType
# Load the created Excel file
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Format header row
header_range = sheet.Range.Rows[0] # Get the first used row
header_range.Style.Font.IsBold = True
header_range.Style.Color = Color.get_LightBlue()
# Apply currency format
sheet.Range["C2:D6"].NumberFormat = "$#,##0.00"
# Format data rows
for i in range(1, sheet.Range.Rows.Count):
if i % 2 == 0:
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
row_range.Style.Color = Color.get_LightGreen()
else:
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
row_range.Style.Color = Color.get_LightYellow()
# Add borders to data rows
sheet.Range["A2:D6"].BorderAround(LineStyleType.Medium, Color.get_LightBlue())
# Auto-fit column widths
sheet.AllocatedRange.AutoFitColumns()
# Save the formatted Excel file
workbook.SaveToFile("monthly_sales_report_formatted.xlsx")
workbook.Dispose()
Die Vorschau des formatierten monatlichen Verkaufsberichts:

Obwohl die Formatierung für die Datenkorrektheit nicht zwingend erforderlich ist, wird sie in Geschäftsberichten, die geteilt oder archiviert werden, oft erwartet. Weitere fortgeschrittene Formatierungstechniken finden Sie unter Wie man Excel-Arbeitsblätter mit Python formatiert.
6. Lesen und Aktualisieren vorhandener Excel-Dateien in der Python-Automatisierung
Das Aktualisieren einer vorhandenen Excel-Datei beinhaltet normalerweise das Auffinden der richtigen Zeile, bevor neue Werte geschrieben werden. Anstatt eine feste Zelle zu aktualisieren, durchsuchen Automatisierungsskripte oft Zeilen, um übereinstimmende Datensätze zu finden und Aktualisierungen bedingt anzuwenden.
Python-Beispiel: Aktualisieren einer Excel-Datei
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
sheet = workbook.Worksheets[0]
# Locate the target row by product name
for row in range(2, sheet.LastRow + 1):
product_name = sheet.Range[row, 1].Text
if product_name == "Laptop":
sheet.Range[row, 5].Text = "Reviewed"
break
sheet.Range["E1"].Text = "Status"
workbook.SaveToFile("monthly_sales_report_updated.xlsx")
workbook.Dispose()
Die Vorschau des aktualisierten monatlichen Verkaufsberichts:

7. Kombinieren von Lese- und Schreibvorgängen in einem einzigen Arbeitsablauf
Bei der Arbeit mit importierten Excel-Dateien sind Rohdaten oft nicht sofort für die Berichterstellung oder weitere Analyse geeignet. Häufige Probleme sind doppelte Datensätze, inkonsistente Werte oder unvollständige Zeilen.
Dieser Abschnitt zeigt, wie man vorhandene Excel-Daten liest, normalisiert und das verarbeitete Ergebnis mit Python in eine neue Datei schreibt.
In realen Automatisierungssystemen werden Excel-Dateien oft als Zwischendatenträger und nicht als endgültige Liefergegenstände verwendet.
Sie können von externen Plattformen importiert, von verschiedenen Teams manuell bearbeitet oder von Altsystemen generiert werden, bevor sie weiterverarbeitet werden.
Infolgedessen enthalten rohe Excel-Daten häufig Probleme wie:
- Mehrere Zeilen für dieselbe Geschäftseinheit
- Inkonsistente oder nicht-numerische Werte
- Leere oder unvollständige Datensätze
- Datenstrukturen, die für die Berichterstellung oder Analyse nicht geeignet sind
Eine häufige Anforderung ist es, unbereinigte Excel-Daten zu lesen, Normalisierungsregeln in Python anzuwenden und die bereinigten Ergebnisse in ein neues Arbeitsblatt zu schreiben, auf das sich nachgelagerte Benutzer verlassen können.
Python-Beispiel: Normalisieren und Aggregieren importierter Verkaufsdaten
In diesem Beispiel enthält eine rohe Verkaufs-Excel-Datei mehrere Zeilen pro Produkt.
Das Ziel ist es, ein sauberes Zusammenfassungsarbeitsblatt zu erstellen, in dem jedes Produkt nur einmal erscheint und dessen Gesamtverkaufsbetrag programmgesteuert berechnet wird.
from spire.xls import Workbook, Color
workbook = Workbook()
workbook.LoadFromFile("raw_sales_data.xlsx")
source = workbook.Worksheets[0]
summary = workbook.Worksheets.Add("Summary")
# Define headers for the normalized output
summary.Range["A1"].Text = "Product"
summary.Range["B1"].Text = "Total Sales"
product_totals = {}
# Read raw data and aggregate values by product
for row in range(2, source.LastRow + 1):
product = source.Range[row, 1].Text
value = source.Range[row, 4].Value
# Skip incomplete or invalid rows
if not product or value is None:
continue
try:
amount = float(value)
except ValueError:
continue
if product not in product_totals:
product_totals[product] = 0
product_totals[product] += amount
# Write aggregated results to the summary worksheet
target_row = 2
for product, total in product_totals.items():
summary.Range[target_row, 1].Text = product
summary.Range[target_row, 2].NumberValue = total
target_row += 1
# Create a total row
summary.Range[summary.LastRow, 1].Text = "Total"
summary.Range[summary.LastRow, 2].Formula = "=SUM(B2:B" + str(summary.LastRow - 1) + ")"
# Format the summary worksheet
summary.Range.Style.Font.FontName = "Arial"
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.Size = 12
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.IsBold = True
for row in range(2, summary.LastRow + 1):
for column in range(1, summary.LastColumn + 1):
summary.Range[row, column].Style.Font.Size = 10
summary.Range[summary.LastRow, 1, summary.LastRow, summary.LastColumn].Style.Color = Color.get_LightGray()
summary.Range.AutoFitColumns()
workbook.SaveToFile("normalized_sales_summary.xlsx")
workbook.Dispose()
Die Vorschau der normalisierten Verkaufszusammenfassung:
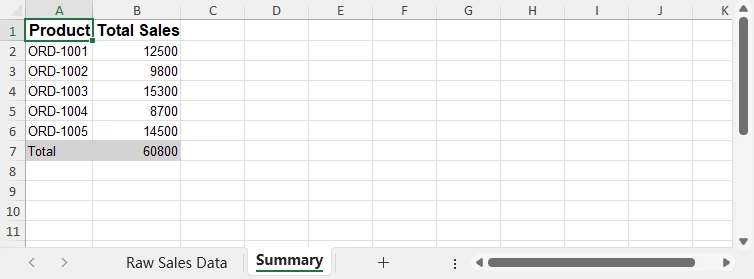
Python übernimmt die Datenvalidierung, Aggregation und Normalisierungslogik, während Excel das endgültige Lieferformat für Geschäftsanwender bleibt – was die Notwendigkeit einer manuellen Bereinigung oder komplexer Tabellenkalkulationsformeln überflüssig macht.
Auswahl des richtigen Python-Ansatzes zur Erstellung von Excel-Dateien
Python bietet mehrere Möglichkeiten, Excel-Dateien zu erstellen, und der beste Ansatz hängt davon ab, wie Excel in Ihrem Arbeitsablauf verwendet wird.
Free Spire.XLS for Python eignet sich besonders gut für Szenarien, in denen:
- Excel-Dateien ohne installiertes Microsoft Excel generiert oder aktualisiert werden
- Dateien von Backend-Diensten, Batch-Jobs oder geplanten Aufgaben erstellt werden
- Sie eine präzise Kontrolle über die Arbeitsblattstruktur, Formatierung und Formeln benötigen
- Excel als Liefer- oder Austauschformat und nicht als interaktives Analysewerkzeug verwendet wird
Für die Datenexploration oder statistische Analyse können Python-Benutzer auf andere Bibliotheken zurückgreifen, während sie Excel-Generierungsbibliotheken wie Free Spire.XLS für die Erstellung strukturierter, präsentationsfertiger Dateien in der Endphase verwenden.
Diese Trennung hält die Datenverarbeitungslogik in Python und die Präsentationslogik in Excel, was die Wartbarkeit und Zuverlässigkeit verbessert.
Weitere detaillierte Anleitungen und Beispiele finden Sie im Spire.XLS for Python Tutorial.
8. Häufige Probleme beim Erstellen und Schreiben von Excel-Dateien in Python
Bei der Automatisierung der Excel-Erstellung treten häufig mehrere praktische Probleme auf.
-
Dateipfad- und Berechtigungsfehler
Überprüfen Sie immer, ob das Zielverzeichnis existiert und der Prozess Schreibzugriff hat, bevor Sie Dateien speichern.
-
Unerwartete Datentypen
Kontrollieren Sie explizit, ob Werte als Text oder Zahlen geschrieben werden, um Berechnungsfehler in Excel zu vermeiden.
-
Versehentliches Überschreiben von Dateien
Verwenden Sie zeitgestempelte Dateinamen oder Ausgabeverzeichnisse, um das Überschreiben vorhandener Berichte zu verhindern.
-
Große Datensätze
Bei der Verarbeitung großer Datenmengen schreiben Sie die Zeilen sequenziell und vermeiden Sie unnötige Formatierungsoperationen innerhalb von Schleifen.
Die frühzeitige Behebung dieser Probleme trägt dazu bei, dass die Excel-Automatisierung auch bei wachsender Datengröße und Komplexität zuverlässig bleibt.
9. Fazit
Das Erstellen von Excel-Dateien in Python ist eine praktische Lösung zur Automatisierung von Berichterstellung, Datenexport und Dokumentenaktualisierungen in realen Geschäftsumgebungen. Durch die Kombination von Dateierstellung, strukturiertem Datenschreiben, Formatierung und Aktualisierungs-Workflows kann die Excel-Automatisierung über einmalige Skripte hinausgehen und Teil eines stabilen Systems werden.
Spire.XLS for Python bietet eine zuverlässige Möglichkeit, diese Operationen in Umgebungen zu implementieren, in denen Automatisierung, Konsistenz und Wartbarkeit unerlässlich sind. Sie können eine temporäre Lizenz beantragen, um das volle Potenzial der Python-Automatisierung bei der Verarbeitung von Excel-Dateien auszuschöpfen.
FAQ: Erstellen von Excel-Dateien in Python
Kann Python Excel-Dateien ohne installiertes Microsoft Excel erstellen?
Ja. Bibliotheken wie Spire.XLS for Python arbeiten unabhängig von Microsoft Excel und eignen sich daher für Server, Cloud-Umgebungen und automatisierte Arbeitsabläufe.
Ist Python für die Erstellung großer Excel-Dateien geeignet?
Python kann große Excel-Dateien effektiv erstellen, vorausgesetzt, die Daten werden sequenziell geschrieben und unnötige Formatierungsoperationen innerhalb von Schleifen werden vermieden.
Wie kann ich das Überschreiben vorhandener Excel-Dateien verhindern?
Ein gängiger Ansatz ist die Verwendung von zeitgestempelten Dateinamen oder dedizierten Ausgabeverzeichnissen beim Speichern generierter Excel-Berichte.
Kann Python Excel-Dateien aktualisieren, die von anderen Systemen erstellt wurden?
Ja. Python kann Excel-Dateien lesen, ändern und erweitern, die von anderen Anwendungen erstellt wurden, solange das Dateiformat unterstützt wird.
Siehe auch
Создание файлов Excel в Python: от основ до автоматизации
Содержание
Создание файлов Excel в Python является частым требованием в приложениях, управляемых данными. Когда данные приложения необходимо предоставить в формате, который бизнес-пользователи могут легко просматривать и совместно использовать, Excel остается одним из самых практичных и широко распространенных вариантов.
В реальных проектах создание файла Excel с помощью Python часто является отправной точкой автоматизированного процесса. Данные могут поступать из баз данных, API или внутренних служб, и Python отвечает за преобразование этих данных в структурированный файл Excel, который соответствует согласованной структуре и соглашению об именах.
В этой статье показано, как создавать файлы Excel в Python, от создания книги с нуля до записи данных, применения базового форматирования и обновления существующих файлов при необходимости. Все примеры представлены с практической точки зрения, с упором на то, как файлы Excel создаются и используются в реальных сценариях автоматизации.
Содержание
- Типичные сценарии создания файлов Excel в Python
- Настройка среды
- Создание нового файла Excel с нуля в Python
- Запись структурированных данных в файл XLSX с помощью Python
- Форматирование данных Excel для реальных отчетов в Python
- Чтение и обновление существующих файлов Excel в Python
- Объединение операций чтения и записи в одном рабочем процессе
- Выбор правильного подхода Python для создания файлов Excel
- Общие проблемы и решения
- Часто задаваемые вопросы
1. Типичные сценарии создания файлов Excel с помощью Python
Создание файлов Excel с помощью Python обычно происходит как часть более крупной системы, а не как отдельная задача. Общие сценарии включают:
- Создание ежедневных, еженедельных или ежемесячных бизнес-отчетов
- Экспорт результатов запросов к базе данных для анализа или аудита
- Создание файлов Excel из серверных служб или пакетных заданий
- Автоматизация обмена данными между внутренними системами или внешними партнерами
В этих ситуациях Python часто используется для автоматического создания файлов Excel, помогая командам сократить ручные усилия, обеспечивая при этом согласованность и повторяемость данных.
2. Настройка среды: подготовка к созданию файлов Excel в Python
В этом руководстве мы используем Free Spire.XLS for Python для демонстрации операций с файлами Excel. Перед созданием файлов Excel с помощью Python убедитесь, что среда разработки готова.
Версия Python
Любая современная версия Python 3.x достаточна для задач автоматизации Excel.
Free Spire.XLS for Python можно установить через pip:
pip install spire.xls.freeВы также можете скачать Free Spire.XLS for Python и включить его в свой проект вручную.
Библиотека работает независимо от Microsoft Excel, что делает ее подходящей для серверных сред, запланированных заданий и автоматизированных рабочих процессов, где Excel не установлен.
3. Создание нового файла Excel с нуля в Python
Этот раздел посвящен созданию файла Excel с нуля с помощью Python. Цель состоит в том, чтобы определить базовую структуру книги, включая рабочие листы и строки заголовков, до записи каких-либо данных.
Создавая начальный макет программно, вы можете гарантировать, что все выходные файлы имеют одинаковую структуру и готовы к последующему заполнению данными.
Пример: создание пустого шаблона Excel
from spire.xls import Workbook, FileFormat
# Initialize a new workbook
workbook = Workbook()
# Access the default worksheet
sheet = workbook.Worksheets[0]
sheet.Name = "Template"
# Add a placeholder title
sheet.Range["B2"].Text = "Monthly Report Template"
# Save the Excel file
workbook.SaveToFile("template.xlsx", FileFormat.Version2016)
workbook.Dispose()
Предварительный просмотр файла шаблона:
В этом примере:
- Workbook() создает новую книгу Excel, которая уже содержит три рабочих листа по умолчанию.
- Доступ к первому рабочему листу осуществляется через Worksheets[0] и он переименовывается для определения базовой структуры.
- Свойство Range[].Text записывает текст в определенную ячейку, позволяя устанавливать заголовки или заполнители до добавления реальных данных.
- Метод SaveToFile() сохраняет книгу в файл Excel. А FileFormat.Version2016 указывает версию или формат Excel для использования.
Создание файлов Excel с несколькими рабочими листами в Python
При создании Excel на основе Python одна книга может содержать несколько рабочих листов для логической организации связанных данных. Каждый рабочий лист может хранить разный набор данных, сводку или результат обработки в одном и том же файле.
В следующем примере показано, как создать файл Excel с несколькими рабочими листами и записать данные в каждый из них.
from spire.xls import Workbook, FileFormat
workbook = Workbook()
# Default worksheet
data_sheet = workbook.Worksheets[0]
data_sheet.Name = "Raw Data"
# Remove the second default worksheet
workbook.Worksheets.RemoveAt(1)
# Add a summary worksheet
summary_sheet = workbook.Worksheets.Add("Summary")
summary_sheet.Range["A1"].Text = "Summary Report"
workbook.SaveToFile("multi_sheet_report.xlsx", FileFormat.Version2016)
workbook.Dispose()
Этот шаблон обычно сочетается с рабочими процессами чтения/записи, где необработанные данные импортируются в один рабочий лист, а обработанные результаты записываются в другой.
Форматы файлов Excel в автоматизации Python
При программном создании файлов Excel в Python XLSX является наиболее часто используемым форматом и полностью поддерживается современными версиями Microsoft Excel. Он поддерживает рабочие листы, формулы, стили и подходит для большинства сценариев автоматизации.
В дополнение к XLSX, Spire.XLS for Python поддерживает создание нескольких распространенных форматов Excel, в том числе:
- XLSX – формат по умолчанию для современной автоматизации Excel
- XLS – устаревший формат Excel для совместимости со старыми системами
- CSV – текстовый формат, часто используемый для обмена и импорта данных
В этой статье все примеры используют формат XLSX, который рекомендуется для создания отчетов, экспорта структурированных данных и файлов Excel на основе шаблонов. Вы можете проверить перечисление FileFormat для получения полного списка поддерживаемых форматов.
4. Запись структурированных данных в файл XLSX с помощью Python
В реальных приложениях данные, записываемые в Excel, редко поступают из жестко закодированных списков. Чаще всего они генерируются из запросов к базе данных, ответов API или промежуточных результатов обработки.
Типичным шаблоном является рассмотрение Excel как окончательного формата доставки для уже структурированных данных.
Пример на Python: создание ежемесячного отчета о продажах из данных приложения
Предположим, ваше приложение уже создало список записей о продажах, где каждая запись содержит информацию о продукте и рассчитанные итоги. В этом примере данные о продажах представлены в виде списка словарей, имитирующих записи, возвращаемые из приложения или сервисного уровня.
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "Sales Report"
headers = ["Product", "Quantity", "Unit Price", "Total Amount"]
for col, header in enumerate(headers, start=1):
sheet.Range[1, col].Text = header
# Data typically comes from a database or service layer
sales_data = [
{"product": "Laptop", "qty": 15, "price": 1200},
{"product": "Monitor", "qty": 30, "price": 250},
{"product": "Keyboard", "qty": 50, "price": 40},
{"product": "Mouse", "qty": 80, "price": 20},
{"product": "Headset", "qty": 100, "price": 10}
]
row = 2
for item in sales_data:
sheet.Range[row, 1].Text = item["product"]
sheet.Range[row, 2].NumberValue = item["qty"]
sheet.Range[row, 3].NumberValue = item["price"]
sheet.Range[row, 4].NumberValue = item["qty"] * item["price"]
row += 1
workbook.SaveToFile("monthly_sales_report.xlsx")
workbook.Dispose()
Предварительный просмотр ежемесячного отчета о продажах:
В этом примере текстовые значения, такие как названия продуктов, записываются с помощью свойства CellRange.Text, а числовые поля используют CellRange.NumberValue. Это гарантирует, что количества и цены хранятся в Excel как числа, что позволяет выполнять правильные вычисления, сортировку и форматирование.
Этот подход естественным образом масштабируется по мере роста набора данных и отделяет бизнес-логику от логики вывода Excel. Для получения дополнительных примеров записи в Excel см. Как автоматизировать запись в Excel в Python.
5. Форматирование данных Excel для реальных отчетов в Python
В реальной отчетности файлы Excel часто доставляются непосредственно заинтересованным сторонам. Необработанные данные без форматирования могут быть трудны для чтения или интерпретации.
Общие задачи форматирования включают:
- Визуальное выделение строк заголовков
- Применение фоновых цветов или границ
- Форматирование чисел и валют
- Автоматическая настройка ширины столбцов
В следующем примере показано, как эти общие операции форматирования могут быть применены вместе для улучшения общей читаемости сгенерированного отчета Excel.
Пример на Python: улучшение читаемости отчета Excel
from spire.xls import Workbook, Color, LineStyleType
# Load the created Excel file
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Format header row
header_range = sheet.Range.Rows[0] # Get the first used row
header_range.Style.Font.IsBold = True
header_range.Style.Color = Color.get_LightBlue()
# Apply currency format
sheet.Range["C2:D6"].NumberFormat = "$#,##0.00"
# Format data rows
for i in range(1, sheet.Range.Rows.Count):
if i % 2 == 0:
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
row_range.Style.Color = Color.get_LightGreen()
else:
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
row_range.Style.Color = Color.get_LightYellow()
# Add borders to data rows
sheet.Range["A2:D6"].BorderAround(LineStyleType.Medium, Color.get_LightBlue())
# Auto-fit column widths
sheet.AllocatedRange.AutoFitColumns()
# Save the formatted Excel file
workbook.SaveToFile("monthly_sales_report_formatted.xlsx")
workbook.Dispose()
Предварительный просмотр отформатированного ежемесячного отчета о продажах:
Хотя форматирование не является строго обязательным для правильности данных, оно часто ожидается в бизнес-отчетах, которые передаются или архивируются. Ознакомьтесь с Как форматировать рабочие листы Excel с помощью Python для более продвинутых методов форматирования.
6. Чтение и обновление существующих файлов Excel в автоматизации Python
Обновление существующего файла Excel обычно включает в себя поиск правильной строки перед записью новых значений. Вместо обновления фиксированной ячейки сценарии автоматизации часто сканируют строки для поиска совпадающих записей и применяют обновления условно.
Пример на Python: обновление файла Excel
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
sheet = workbook.Worksheets[0]
# Locate the target row by product name
for row in range(2, sheet.LastRow + 1):
product_name = sheet.Range[row, 1].Text
if product_name == "Laptop":
sheet.Range[row, 5].Text = "Reviewed"
break
sheet.Range["E1"].Text = "Status"
workbook.SaveToFile("monthly_sales_report_updated.xlsx")
workbook.Dispose()
Предварительный просмотр обновленного ежемесячного отчета о продажах:
7. Объединение операций чтения и записи в одном рабочем процессе
При работе с импортированными файлами Excel необработанные данные часто не подходят для отчетности или дальнейшего анализа. Общие проблемы включают дублирующиеся записи, несогласованные значения или неполные строки.
В этом разделе показано, как читать существующие данные Excel, нормализовать их и записывать обработанный результат в новый файл с помощью Python.
В реальных системах автоматизации файлы Excel часто используются как промежуточные носители данных, а не как конечные результаты.
Они могут быть импортированы с внешних платформ, вручную отредактированы разными командами или сгенерированы устаревшими системами перед дальнейшей обработкой.
В результате необработанные данные Excel часто содержат такие проблемы, как:
- Несколько строк для одной и той же бизнес-сущности
- Несогласованные или нечисловые значения
- Пустые или неполные записи
- Структуры данных, которые не подходят для отчетности или анализа
Общим требованием является чтение необработанных данных Excel, применение правил нормализации в Python и запись очищенных результатов в новый рабочий лист, на который могут полагаться последующие пользователи.
Пример на Python: нормализация и агрегирование импортированных данных о продажах
В этом примере необработанный файл Excel с данными о продажах содержит несколько строк для каждого продукта.
Цель состоит в том, чтобы создать чистый сводный рабочий лист, где каждый продукт появляется только один раз, с программно рассчитанной общей суммой продаж.
from spire.xls import Workbook, Color
workbook = Workbook()
workbook.LoadFromFile("raw_sales_data.xlsx")
source = workbook.Worksheets[0]
summary = workbook.Worksheets.Add("Summary")
# Define headers for the normalized output
summary.Range["A1"].Text = "Product"
summary.Range["B1"].Text = "Total Sales"
product_totals = {}
# Read raw data and aggregate values by product
for row in range(2, source.LastRow + 1):
product = source.Range[row, 1].Text
value = source.Range[row, 4].Value
# Skip incomplete or invalid rows
if not product or value is None:
continue
try:
amount = float(value)
except ValueError:
continue
if product not in product_totals:
product_totals[product] = 0
product_totals[product] += amount
# Write aggregated results to the summary worksheet
target_row = 2
for product, total in product_totals.items():
summary.Range[target_row, 1].Text = product
summary.Range[target_row, 2].NumberValue = total
target_row += 1
# Create a total row
summary.Range[summary.LastRow, 1].Text = "Total"
summary.Range[summary.LastRow, 2].Formula = "=SUM(B2:B" + str(summary.LastRow - 1) + ")"
# Format the summary worksheet
summary.Range.Style.Font.FontName = "Arial"
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.Size = 12
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.IsBold = True
for row in range(2, summary.LastRow + 1):
for column in range(1, summary.LastColumn + 1):
summary.Range[row, column].Style.Font.Size = 10
summary.Range[summary.LastRow, 1, summary.LastRow, summary.LastColumn].Style.Color = Color.get_LightGray()
summary.Range.AutoFitColumns()
workbook.SaveToFile("normalized_sales_summary.xlsx")
workbook.Dispose()
Предварительный просмотр нормализованной сводки продаж:
Python обрабатывает логику проверки, агрегирования и нормализации данных, в то время как Excel остается окончательным форматом доставки для бизнес-пользователей, что устраняет необходимость в ручной очистке или сложных формулах в электронных таблицах.
Выбор правильного подхода Python для создания файлов Excel
Python предлагает несколько способов создания файлов Excel, и лучший подход зависит от того, как Excel используется в вашем рабочем процессе.
Free Spire.XLS for Python особенно хорошо подходит для сценариев, где:
- Файлы Excel создаются или обновляются без установленного Microsoft Excel
- Файлы создаются серверными службами, пакетными заданиями или запланированными задачами
- Вам нужен точный контроль над структурой рабочего листа, форматированием и формулами
- Excel используется как формат доставки или обмена, а не как интерактивный инструмент анализа
Для исследования данных или статистического анализа пользователи Python могут использовать другие библиотеки на более ранних этапах, в то время как библиотеки для создания Excel, такие как Free Spire.XLS, используются для создания структурированных, готовых к презентации файлов на заключительном этапе.
Это разделение сохраняет логику обработки данных в Python и логику представления в Excel, улучшая ремонтопригодность и надежность.
Для получения более подробных указаний и примеров см. Руководство по Spire.XLS for Python.
8. Общие проблемы при создании и записи файлов Excel в Python
При автоматизации создания Excel часто возникают несколько практических проблем.
-
Ошибки пути к файлу и разрешений
Всегда проверяйте, что целевой каталог существует и что процесс имеет доступ на запись перед сохранением файлов.
-
Неожиданные типы данных
Явно контролируйте, записываются ли значения как текст или числа, чтобы избежать ошибок вычислений в Excel.
-
Случайная перезапись файлов
Используйте имена файлов с отметками времени или выходные каталоги, чтобы предотвратить перезапись существующих отчетов.
-
Большие наборы данных
При обработке больших объемов данных записывайте строки последовательно и избегайте ненужных операций форматирования внутри циклов.
Раннее решение этих проблем помогает обеспечить надежность автоматизации Excel по мере роста размера и сложности данных.
9. Заключение
Создание файлов Excel в Python является практическим решением для автоматизации отчетности, экспорта данных и обновления документов в реальных бизнес-средах. Объединяя создание файлов, запись структурированных данных, форматирование и рабочие процессы обновления, автоматизация Excel может выйти за рамки одноразовых сценариев и стать частью стабильной системы.
Spire.XLS for Python предоставляет надежный способ реализации этих операций в средах, где важны автоматизация, согласованность и ремонтопригодность. Вы можете подать заявку на временную лицензию, чтобы раскрыть весь потенциал автоматизации Python в обработке файлов Excel.
Часто задаваемые вопросы: создание файлов Excel в Python
Может ли Python создавать файлы Excel без установленного Microsoft Excel?
Да. Библиотеки, такие как Spire.XLS for Python, работают независимо от Microsoft Excel, что делает их подходящими для серверов, облачных сред и автоматизированных рабочих процессов.
Подходит ли Python для создания больших файлов Excel?
Python может эффективно создавать большие файлы Excel при условии, что данные записываются последовательно и избегаются ненужные операции форматирования внутри циклов.
Как я могу предотвратить перезапись существующих файлов Excel?
Общим подходом является использование имен файлов с отметками времени или выделенных выходных каталогов при сохранении сгенерированных отчетов Excel.
Может ли Python обновлять файлы Excel, созданные другими системами?
Да. Python может читать, изменять и расширять файлы Excel, созданные другими приложениями, при условии, что формат файла поддерживается.
Смотрите также
Editar metadados de PDF: quatro maneiras eficazes
Índice
- O Que São Metadados de PDF?
- Método 1: Editar Metadados de PDF Usando o Adobe Acrobat
- Método 2: Editar Metadados de PDF Usando o Sejda (Online)
- Método 3: Editar Metadados de PDF Usando Ferramentas de Linha de Comando
- Método 4: Editar Metadados de PDF Programaticamente Usando o Spire.PDF
- Comparação de Diferentes Métodos
- Considerações Finais
- Perguntas Frequentes

Os metadados de PDF contêm informações descritivas sobre um documento, como título, autor, assunto e palavras-chave. Embora esses dados não sejam visíveis nas próprias páginas do PDF, eles estão incorporados na estrutura do arquivo e podem ser acessados por leitores de PDF, motores de busca e sistemas de gerenciamento de documentos.
Neste artigo, exploraremos quatro maneiras práticas e eficazes de editar metadados de PDF, abrangendo ferramentas de desktop, editores online e soluções orientadas para desenvolvedores. Se você precisa atualizar um único arquivo ou automatizar a edição de metadados para grandes coleções de PDFs, este guia o ajudará a escolher a abordagem certa.
Visão geral dos métodos:
- Método 1: Editar Metadados de PDF Usando o Adobe Acrobat
- Método 2: Editar Metadados de PDF Usando o Sejda (Online)
- Método 3: Editar Metadados de PDF Usando Ferramentas de Linha de Comando
- Método 4: Editar Metadados de PDF Programaticamente Usando o Spire.PDF
O Que São Metadados de PDF?
Metadados de PDF são um conjunto de propriedades armazenadas dentro de um arquivo PDF que descrevem o documento em vez de seu conteúdo visível. Essas propriedades ajudam o software a identificar, categorizar e gerenciar arquivos PDF de forma mais eficiente. Os campos comuns de metadados de PDF incluem:
- Título – O título do documento exibido nos visualizadores de PDF
- Autor – O criador ou proprietário do documento
- Assunto – Uma breve descrição do documento
- Palavras-chave – Tags ou frases pesquisáveis
- Criador – O aplicativo que criou o PDF
- Produtor – O software usado para gerar o PDF final
- Data de Criação / Data de Modificação
Como os metadados são separados do layout e do texto do documento, eles podem ser editados com segurança sem afetar o conteúdo visual.
Método 1: Editar Metadados de PDF Usando o Adobe Acrobat
Adobe Acrobat oferece uma interface confiável e intuitiva para editar metadados de PDF, tornando-o uma escolha popular para usuários comuns. Ele fornece acesso total aos campos de metadados padrão por meio de um fluxo de trabalho gráfico familiar. Para atualizar metadados usando o Adobe Acrobat, siga estes passos:
- Abra o arquivo PDF no Adobe Acrobat.
- Clique em Arquivo → Propriedades para abrir a caixa de diálogo de propriedades do documento.

- Edite campos como Título, Autor, Assunto e Palavras-chave na aba Descrição.
- Clique em OK e salve o PDF para aplicar as alterações.
Prós
- Interface gráfica amigável.
- Suporte completo para campos de metadados de PDF padrão.
- Solução de PDF confiável e amplamente reconhecida.
Contras
- Requer uma licença paga.
- Não é adequado para processamento em lote ou automatizado.
Método 2: Editar Metadados de PDF Usando o Sejda (Online)
O Sejda é uma ferramenta online bem conhecida que permite editar metadados de PDF diretamente no seu navegador. Este método é ideal para edições rápidas e únicas, quando você não quer instalar software de desktop. O processo de edição é simples e requer apenas alguns passos:
- Abra a ferramenta Editar Metadados de PDF do Sejda.
- Carregue seu arquivo PDF do seu computador ou armazenamento em nuvem.

- Escolha Alterar metadados e clique em Continuar.

- Modifique os campos de metadados necessários e clique em Atualizar Metadados do PDF para salvar as alterações.
- Baixe o arquivo PDF atualizado.
Prós
- Nenhuma instalação de software necessária.
- Muito fácil de usar para edições rápidas e únicas.
- Acessível a partir de qualquer navegador moderno.
Contras
- Limitações de tamanho de arquivo e uso diário.
- Preocupações com a privacidade devido ao upload de arquivos.
Método 3: Editar Metadados de PDF Usando Ferramentas de Linha de Comando
As ferramentas de linha de comando fornecem uma maneira confiável e programável de editar metadados de PDF em diferentes sistemas operacionais. Este método é ideal para usuários que preferem fluxos de trabalho baseados em terminal ou precisam processar vários arquivos PDF de forma eficiente. Uma das ferramentas mais utilizadas para esse fim é o ExifTool, que suporta tanto a leitura quanto a escrita de metadados de PDF.
Passos para editar metadados de PDF com o ExifTool (no Windows):
-
Instale o ExifTool no seu sistema.
- Baixe o ExifTool para Windows
- Extraia o exiftool(-k).exe
- Renomeie-o para exiftool.exe
- Copie o .exe e a pasta "exiftool_files" para C:\Windows
-
Abra um terminal ou prompt de comando e verifique se o ExifTool está disponível.
exiftool -ver
-
Navegue até o diretório que contém seu arquivo PDF. Por exemplo, se estiver em D:\Documents, digite:
D: cd Documents
-
Execute um comando para modificar os campos de metadados necessários.
exiftool -Title="Visão Geral da Computação em Nuvem" -Author="Tim Taylor" -Subject="Introdução aos serviços em nuvem" -Keywords="nuvem; negócios; servidor" Input.pdf
-
Verifique as alterações lendo os metadados.
exiftool Input.pdf
Prós
- Funciona de forma confiável no Windows, macOS e Linux.
- Excelente para atualizações em lote e automatizadas.
- Nenhuma interface gráfica necessária.
Contras
- Requer conhecimento de linha de comando.
- Risco de sobrescritas acidentais se mal utilizado.
Nota: Os passos de instalação variam de acordo com o sistema operacional. Usuários de Linux e macOS devem instalar o ExifTool usando um gerenciador de pacotes.
Método 4: Editar Metadados de PDF Programaticamente Usando o Spire.PDF
Ao trabalhar com um grande número de arquivos PDF ou fluxos de trabalho automatizados, a edição programática de metadados é a solução mais eficiente. O Spire.PDF for Python fornece uma API poderosa e amigável para desenvolvedores que permite modificar tanto metadados incorporados quanto personalizados de PDF com o mínimo de código.
Essa abordagem é especialmente útil para serviços de backend, pipelines de documentos e cenários onde os metadados precisam ser padronizados em muitos arquivos.
Abaixo está um exemplo que demonstra como editar metadados de PDF usando o Spire.PDF for Python:
from spire.pdf import *
from spire.pdf.common import *
# Crie um objeto da classe PdfDocument e carregue um documento PDF
pdf = PdfDocument()
pdf.LoadFromFile("Input.pdf")
# Obtenha as propriedades do documento
properties = pdf.DocumentInformation
# Defina as propriedades incorporadas
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "serviço em nuvem; negócios digitais"
properties.Subject = "A introdução do serviço em nuvem e suas vantagens"
properties.Title = "O Poder dos Serviços em Nuvem: Capacitando Empresas na Era Digital"
properties.Producer = "Spire.PDF for Python"
# Defina as propriedades personalizadas
properties.SetCustomProperty("Company", "E-iceblue")
properties.SetCustomProperty("Tags", "Nuvem; Negócios; Servidor")
# Salve o documento
pdf.SaveToFile("output/EditPDFMetadata.pdf")
pdf.Close()
Leia mais: Definir e Recuperar Propriedades de PDF Usando Python
Prós
- Suporta metadados de PDF tanto incorporados quanto personalizados.
- Ideal para processamento em lote e fluxos de trabalho de automação.
Contras
- Requer conhecimento básico de programação em Python.
- A configuração inicial da biblioteca é necessária.
- Menos conveniente para edições manuais únicas.
Além da edição de metadados, o Spire.PDF for Python fornece APIs para processamento em lote, geração de PDF e modificação de conteúdo, que podem ser combinadas para tarefas de automação de documentos mais complexas.
Comparação de Diferentes Métodos
| Método | Facilidade de Uso | Edição em Lote | Automação | Privacidade |
|---|---|---|---|---|
| Adobe Acrobat | Alta | Não | Não | Alta |
| Sejda (Online) | Muito Alta | Não | Não | Baixa |
| Ferramentas de Linha de Comando | Baixa | Sim | Sim | Alta |
| Spire.PDF for Python | Média | Sim | Sim | Alta |
Considerações Finais
A edição de metadados de PDF é uma maneira prática de manter os documentos bem organizados, pesquisáveis e consistentes em diferentes fluxos de trabalho. Dependendo do seu conhecimento técnico e cenário de uso, existem várias maneiras eficazes de atualizar as propriedades do PDF sem modificar o conteúdo visível do documento.
Para usuários que preferem uma interface gráfica, o Adobe Acrobat fornece uma solução de desktop confiável, enquanto o Sejda PDF Editor é conveniente para edições rápidas baseadas em navegador. Se você precisa de maior controle ou deseja processar vários arquivos de forma eficiente, ferramentas de linha de comando como o ExifTool oferecem uma abordagem poderosa e multiplataforma. Para desenvolvedores e sistemas automatizados, o Spire.PDF for Python se destaca como a opção mais flexível, suportando metadados incorporados e personalizados com o mínimo de código.
Ao escolher o método que melhor se adapta ao seu fluxo de trabalho — manual, online, linha de comando ou programático — você pode garantir que seus metadados de PDF permaneçam precisos, padronizados e fáceis de gerenciar em qualquer escala.
Perguntas Frequentes
P1. Os metadados de PDF podem ser editados sem alterar o conteúdo do documento?
Sim. As atualizações de metadados não afetam o texto visível ou o layout de um PDF.
P2. Os metadados de PDF são visíveis para os leitores?
Os metadados ficam ocultos por padrão, mas podem ser visualizados nas propriedades do documento.
P3. Posso editar metadados em lote para vários PDFs?
Sim. Métodos programáticos e de linha de comando são os melhores para operações em lote.
P4. A edição de metadados afeta as assinaturas digitais?
Sim. Qualquer modificação, incluindo alterações de metadados, pode invalidar uma assinatura digital.
Você Também Pode se Interessar Por
PDF 메타데이터 편집: 네 가지 효과적인 방법
PDF 메타데이터는 문서의 제목, 작성자, 주제 및 키워드와 같은 설명 정보를 포함합니다. 이 데이터는 PDF 페이지 자체에는 표시되지 않지만 파일 구조에 포함되어 있으며 PDF 리더, 검색 엔진 및 문서 관리 시스템에서 액세스할 수 있습니다.
이 기사에서는 데스크톱 도구, 온라인 편집기 및 개발자 중심 솔루션을 다루면서 PDF 메타데이터를 편집하는 네 가지 실용적이고 효과적인 방법을 살펴보겠습니다. 단일 파일을 업데이트해야 하든 대규모 PDF 컬렉션에 대한 메타데이터 편집을 자동화해야 하든 이 가이드는 올바른 접근 방식을 선택하는 데 도움이 될 것입니다.
방법 개요:
- 방법 1: Adobe Acrobat을 사용하여 PDF 메타데이터 편집
- 방법 2: Sejda(온라인)를 사용하여 PDF 메타데이터 편집
- 방법 3: 명령줄 도구를 사용하여 PDF 메타데이터 편집
- 방법 4: Spire.PDF를 사용하여 프로그래밍 방식으로 PDF 메타데이터 편집
PDF 메타데이터란 무엇인가?
PDF 메타데이터는 보이는 콘텐츠가 아닌 문서를 설명하는 PDF 파일 내에 저장된 속성 집합입니다. 이러한 속성은 소프트웨어가 PDF 파일을 보다 효율적으로 식별, 분류 및 관리하는 데 도움이 됩니다. 일반적인 PDF 메타데이터 필드는 다음과 같습니다.
- 제목 – PDF 뷰어에 표시되는 문서 제목
- 작성자 – 문서의 작성자 또는 소유자
- 주제 – 문서에 대한 간략한 설명
- 키워드 – 검색 가능한 태그 또는 구문
- 만든 이 – PDF를 만든 응용 프로그램
- 프로듀서 – 최종 PDF를 생성하는 데 사용된 소프트웨어
- 생성 날짜 / 수정 날짜
메타데이터는 문서의 레이아웃 및 텍스트와 별개이므로 시각적 콘텐츠에 영향을 주지 않고 안전하게 편집할 수 있습니다.
방법 1: Adobe Acrobat을 사용하여 PDF 메타데이터 편집
Adobe Acrobat은(는) PDF 메타데이터 편집을 위한 신뢰할 수 있고 직관적인 인터페이스를 제공하여 일반 사용자에게 인기 있는 선택입니다. 익숙한 그래픽 워크플로를 통해 표준 메타데이터 필드에 대한 전체 액세스를 제공합니다. Adobe Acrobat을 사용하여 메타데이터를 업데이트하려면 다음 단계를 따르십시오.
- Adobe Acrobat에서 PDF 파일을 엽니다.
- 파일 → 속성을(를) 클릭하여 문서 속성 대화 상자를 엽니다.
- 설명 탭 아래의 제목, 작성자, 주제 및 키워드와(과) 같은 필드를 편집합니다.
- 확인을(를) 클릭하고 PDF를 저장하여 변경 사항을 적용합니다.
장점
- 사용자 친화적인 그래픽 인터페이스.
- 표준 PDF 메타데이터 필드에 대한 완벽한 지원.
- 신뢰할 수 있고 널리 알려진 PDF 솔루션.
단점
- 유료 라이선스가 필요합니다.
- 일괄 또는 자동화된 처리에 적합하지 않습니다.
방법 2: Sejda(온라인)를 사용하여 PDF 메타데이터 편집
Sejda는 브라우저에서 직접 PDF 메타데이터를 편집할 수 있는 잘 알려진 온라인 도구입니다. 이 방법은 데스크톱 소프트웨어를 설치하고 싶지 않을 때 빠른 일회성 편집에 이상적입니다. 편집 과정은 간단하며 몇 단계만 거치면 됩니다.
- Sejda의 PDF 메타데이터 편집 도구를 엽니다.
- 컴퓨터 또는 클라우드 저장소에서 PDF 파일을 업로드합니다.
- 메타데이터 변경을(를) 선택하고, 그런 다음 계속을(를) 클릭합니다.
- 필요한 메타데이터 필드를 수정하고 PDF 메타데이터 업데이트을(를) 클릭하여 변경 사항을 저장합니다.
- 업데이트된 PDF 파일을 다운로드합니다.
장점
- 소프트웨어 설치가 필요하지 않습니다.
- 빠른 일회성 편집에 매우 사용하기 쉽습니다.
- 모든 최신 브라우저에서 액세스할 수 있습니다.
단점
- 파일 크기 및 일일 사용량 제한.
- 파일 업로드로 인한 개인 정보 보호 문제.
방법 3: 명령줄 도구를 사용하여 PDF 메타데이터 편집
명령줄 도구는 여러 운영 체제에서 PDF 메타데이터를 편집할 수 있는 신뢰할 수 있고 스크립트 가능한 방법을 제공합니다. 이 방법은 터미널 기반 워크플로를 선호하거나 여러 PDF 파일을 효율적으로 처리해야 하는 사용자에게 이상적입니다. 이 목적을 위해 가장 널리 사용되는 도구 중 하나는 ExifTool이며, PDF 메타데이터 읽기 및 쓰기를 모두 지원합니다.
ExifTool로 PDF 메타데이터를 편집하는 단계(Windows에서):
-
시스템에 ExifTool을 설치합니다.
- Windows용 ExifTool 다운로드
- exiftool(-k).exe 압축 풀기
- 이름을 exiftool.exe로 변경
- .exe와 "exiftool_files" 폴더를 C:\Windows에 복사
-
터미널 또는 명령 프롬프트를 열고 ExifTool을 사용할 수 있는지 확인합니다.
exiftool -ver -
PDF 파일이 포함된 디렉터리로 이동합니다. 예를 들어 D:\Documents에 있는 경우 다음을 입력합니다.
D: cd Documents -
명령을 실행하여 필요한 메타데이터 필드를 수정합니다.
exiftool -Title="Cloud Computing Overview" -Author="Tim Taylor" -Subject="Introduction to cloud services" -Keywords="cloud; business; server" Input.pdf -
메타데이터를 읽어 변경 사항을 확인합니다.
exiftool Input.pdf
장점
- Windows, macOS 및 Linux에서 안정적으로 작동합니다.
- 일괄 및 자동화된 업데이트에 탁월합니다.
- 그래픽 인터페이스가 필요하지 않습니다.
단점
- 명령줄 지식이 필요합니다.
- 잘못 사용하면 실수로 덮어쓸 위험이 있습니다.
참고: 설치 단계는 운영 체제에 따라 다릅니다. Linux 및 macOS 사용자는 패키지 관리자를 사용하여 ExifTool을 설치해야 합니다.
방법 4: Spire.PDF를 사용하여 프로그래밍 방식으로 PDF 메타데이터 편집
많은 수의 PDF 파일을 사용하거나 자동화된 워크플로로 작업할 때 프로그래밍 방식의 메타데이터 편집이 가장 효율적인 솔루션입니다. Spire.PDF for Python은(는) 최소한의 코드로 내장 및 사용자 지정 PDF 메타데이터을(를) 모두 수정할 수 있는 강력하고 개발자 친화적인 API를 제공합니다.
이 접근 방식은 백엔드 서비스, 문서 파이프라인 및 많은 파일에서 메타데이터를 표준화해야 하는 시나리오에 특히 유용합니다.
다음은 Spire.PDF for Python을 사용하여 PDF 메타데이터를 편집하는 방법을 보여주는 예입니다.
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Input.pdf")
# Get the properties of the document
properties = pdf.DocumentInformation
# Set built-in properties
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "cloud service; digital business"
properties.Subject = "The introduction of cloud service and its advantages"
properties.Title = "The Power of Cloud Services: Empowering Businesses in the Digital Age"
properties.Producer = "Spire.PDF for Python"
# Set custom properties
properties.SetCustomProperty("Company", "E-iceblue")
properties.SetCustomProperty("Tags", "Cloud; Business; Server")
# Save the document
pdf.SaveToFile("output/EditPDFMetadata.pdf")
pdf.Close()
추가 정보: Python을 사용하여 PDF 속성 설정 및 검색
장점
- 내장 및 사용자 지정 PDF 메타데이터를 모두 지원합니다.
- 일괄 처리 및 자동화 워크플로에 이상적입니다.
단점
- 기본적인 Python 프로그래밍 지식이 필요합니다.
- 초기 라이브러리 설정이 필요합니다.
- 단일 수동 편집에는 덜 편리합니다.
메타데이터 편집 외에도 Spire.PDF for Python은 일괄 처리, PDF 생성 및 콘텐츠 수정을(를) 위한 API를 제공하며, 이를 결합하여 더 복잡한 문서 자동화 작업을 수행할 수 있습니다.
다양한 방법 비교
| 방법 | 사용 용이성 | 일괄 편집 | 자동화 | 개인 정보 보호 |
|---|---|---|---|---|
| Adobe Acrobat | 높음 | 아니요 | 아니요 | 높음 |
| Sejda (온라인) | 매우 높음 | 아니요 | 아니요 | 낮음 |
| 명령줄 도구 | 낮음 | 예 | 예 | 높음 |
| Spire.PDF for Python | 중간 | 예 | 예 | 높음 |
마지막 생각들
PDF 메타데이터를 편집하는 것은 문서를 잘 정리하고 검색 가능하며 다양한 워크플로에서 일관성을 유지하는 실용적인 방법입니다. 기술적 배경과 사용 시나리오에 따라 문서의 보이는 콘텐츠를 수정하지 않고 PDF 속성을 업데이트하는 여러 가지 효과적인 방법이 있습니다.
그래픽 인터페이스를 선호하는 사용자의 경우 Adobe Acrobat은(는) 신뢰할 수 있는 데스크톱 솔루션을 제공하는 반면 Sejda PDF 편집기는 빠른 브라우저 기반 편집에 편리합니다. 더 많은 제어가 필요하거나 여러 파일을 효율적으로 처리하려면 ExifTool과(와) 같은 명령줄 도구은(는) 강력한 크로스 플랫폼 접근 방식을 제공합니다. 개발자 및 자동화된 시스템의 경우 Spire.PDF for Python은(는) 최소한의 코드로 내장 및 사용자 지정 메타데이터를 모두 지원하는 가장 유연한 옵션으로 두드러집니다.
워크플로(수동, 온라인, 명령줄 또는 프로그래밍 방식)에 가장 적합한 방법을 선택하면 PDF 메타데이터가 모든 규모에서 정확하고 표준화되며 관리하기 쉬운 상태로 유지되도록 할 수 있습니다.
자주 묻는 질문
Q1. 문서 내용을 변경하지 않고 PDF 메타데이터를 편집할 수 있습니까?
예. 메타데이터 업데이트는 PDF의 보이는 텍스트나 레이아웃에 영향을 주지 않습니다.
Q2. PDF 메타데이터가 독자에게 보입니까?
메타데이터는 기본적으로 숨겨져 있지만 문서 속성에서 볼 수 있습니다.
Q3. 여러 PDF의 메타데이터를 일괄 편집할 수 있습니까?
예. 프로그래밍 방식 및 명령줄 방법은 일괄 작업에 가장 적합합니다.
Q4. 메타데이터 편집이 디지털 서명에 영향을 줍니까?
예. 메타데이터 변경을 포함한 모든 수정은 디지털 서명을 무효화할 수 있습니다.
관심 있을 만한 다른 항목
Modificare i metadati del PDF: quattro modi efficaci
Indice
- Cosa sono i metadati PDF?
- Metodo 1: Modificare i metadati PDF con Adobe Acrobat
- Metodo 2: Modificare i metadati PDF con Sejda (Online)
- Metodo 3: Modificare i metadati PDF con strumenti da riga di comando
- Metodo 4: Modificare i metadati PDF programmaticamente con Spire.PDF
- Confronto dei diversi metodi
- Considerazioni finali
- Domande frequenti
I metadati PDF contengono informazioni descrittive su un documento, come titolo, autore, oggetto e parole chiave. Sebbene questi dati non siano visibili all'interno delle pagine del PDF stesso, sono incorporati nella struttura del file e possono essere consultati da lettori PDF, motori di ricerca e sistemi di gestione documentale.
In questo articolo, esploreremo quattro modi pratici ed efficaci per modificare i metadati PDF, coprendo strumenti desktop, editor online e soluzioni orientate agli sviluppatori. Che tu debba aggiornare un singolo file o automatizzare la modifica dei metadati per grandi raccolte di PDF, questa guida ti aiuterà a scegliere l'approccio giusto.
Panoramica dei metodi:
- Metodo 1: Modificare i metadati PDF con Adobe Acrobat
- Metodo 2: Modificare i metadati PDF con Sejda (Online)
- Metodo 3: Modificare i metadati PDF con strumenti da riga di comando
- Metodo 4: Modificare i metadati PDF programmaticamente con Spire.PDF
Cosa sono i metadati PDF?
I metadati PDF sono un insieme di proprietà memorizzate all'interno di un file PDF che descrivono il documento piuttosto che il suo contenuto visibile. Queste proprietà aiutano il software a identificare, classificare e gestire i file PDF in modo più efficiente. I campi comuni dei metadati PDF includono:
- Titolo – Il titolo del documento mostrato nei visualizzatori PDF
- Autore – Il creatore o proprietario del documento
- Oggetto – Una breve descrizione del documento
- Parole chiave – Tag o frasi ricercabili
- Creatore – L'applicazione che ha creato il PDF
- Produttore – Il software utilizzato per generare il PDF finale
- Data di creazione / Data di modifica
Poiché i metadati sono separati dal layout e dal testo del documento, possono essere modificati in sicurezza senza alterare il contenuto visivo.
Metodo 1: Modificare i metadati PDF con Adobe Acrobat
Adobe Acrobat offre un'interfaccia affidabile e intuitiva per la modifica dei metadati PDF, rendendolo una scelta popolare per gli utenti di tutti i giorni. Fornisce pieno accesso ai campi di metadati standard attraverso un flusso di lavoro grafico familiare. Per aggiornare i metadati con Adobe Acrobat, segui questi passaggi:
- Apri il file PDF in Adobe Acrobat.
- Fai clic su File → Proprietà per aprire la finestra di dialogo delle proprietà del documento.
- Modifica campi come Titolo, Autore, Oggetto e Parole chiave nella scheda Descrizione.
- Fai clic su OK e salva il PDF per applicare le modifiche.
Vantaggi
- Interfaccia grafica intuitiva.
- Supporto completo per i campi di metadati PDF standard.
- Soluzione PDF affidabile e ampiamente riconosciuta.
Svantaggi
- Richiede una licenza a pagamento.
- Non adatto per l'elaborazione batch o automatizzata.
Metodo 2: Modificare i metadati PDF con Sejda (Online)
Sejda è un noto strumento online che consente di modificare i metadati PDF direttamente nel browser. Questo metodo è ideale per modifiche rapide e occasionali quando non si desidera installare software desktop. Il processo di modifica è semplice e richiede solo pochi passaggi:
- Apri lo strumento Modifica metadati PDF di Sejda.
- Carica il tuo file PDF dal tuo computer o da un archivio cloud.
- Scegli Cambia metadati, quindi fai clic su Continua.
- Modifica i campi di metadati richiesti e fai clic su Aggiorna metadati PDF per salvare le modifiche.
- Scarica il file PDF aggiornato.
Vantaggi
- Nessuna installazione di software richiesta.
- Molto facile da usare per modifiche rapide e occasionali.
- Accessibile da qualsiasi browser moderno.
Svantaggi
- Limitazioni sulla dimensione dei file e sull'utilizzo giornaliero.
- Preoccupazioni sulla privacy a causa del caricamento di file.
Metodo 3: Modificare i metadati PDF con strumenti da riga di comando
Gli strumenti da riga di comando forniscono un modo affidabile e scriptabile per modificare i metadati PDF su diversi sistemi operativi. Questo metodo è ideale per gli utenti che preferiscono flussi di lavoro basati su terminale o che necessitano di elaborare più file PDF in modo efficiente. Uno degli strumenti più utilizzati a questo scopo è ExifTool, che supporta sia la lettura che la scrittura dei metadati PDF.
Passaggi per modificare i metadati PDF con ExifTool (su Windows):
-
Installa ExifTool sul tuo sistema.
- Scarica ExifTool per Windows
- Estrai exiftool(-k).exe
- Rinominalo in exiftool.exe
- Copia il file .exe e la cartella "exiftool_files" in C:\Windows
-
Apri un terminale o un prompt dei comandi e verifica se ExifTool è disponibile.
exiftool -ver -
Naviga nella directory contenente il tuo file PDF. Ad esempio, se si trova in D:\Documents, digita:
D: cd Documents -
Esegui un comando per modificare i campi di metadati richiesti.
exiftool -Title="Panoramica del Cloud Computing" -Author="Tim Taylor" -Subject="Introduzione ai servizi cloud" -Keywords="cloud; business; server" Input.pdf -
Verifica le modifiche leggendo i metadati.
exiftool Input.pdf
Vantaggi
- Funziona in modo affidabile su Windows, macOS e Linux.
- Eccellente per aggiornamenti batch e automatizzati.
- Nessuna interfaccia grafica richiesta.
Svantaggi
- Richiede conoscenza della riga di comando.
- Rischio di sovrascritture accidentali in caso di uso improprio.
Nota: i passaggi di installazione variano a seconda del sistema operativo. Gli utenti di Linux e macOS dovrebbero installare ExifTool utilizzando un gestore di pacchetti.
Metodo 4: Modificare i metadati PDF programmaticamente con Spire.PDF
Quando si lavora con un gran numero di file PDF o flussi di lavoro automatizzati, la modifica programmatica dei metadati è la soluzione più efficiente. Spire.PDF per Python fornisce un'API potente e intuitiva per gli sviluppatori che consente di modificare sia i metadati PDF integrati che quelli personalizzati con un codice minimo.
Questo approccio è particolarmente utile per i servizi di backend, le pipeline di documenti e gli scenari in cui i metadati devono essere standardizzati su molti file.
Di seguito è riportato un esempio che dimostra come modificare i metadati PDF utilizzando Spire.PDF per Python:
from spire.pdf import *
from spire.pdf.common import *
# Crea un oggetto della classe PdfDocument e carica un documento PDF
pdf = PdfDocument()
pdf.LoadFromFile("Input.pdf")
# Ottieni le proprietà del documento
properties = pdf.DocumentInformation
# Imposta le proprietà integrate
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "servizio cloud; business digitale"
properties.Subject = "L'introduzione del servizio cloud e i suoi vantaggi"
properties.Title = "Il potere dei servizi cloud: potenziare le aziende nell'era digitale"
properties.Producer = "Spire.PDF per Python"
# Imposta le proprietà personalizzate
properties.SetCustomProperty("Azienda", "E-iceblue")
properties.SetCustomProperty("Tag", "Cloud; Business; Server")
# Salva il documento
pdf.SaveToFile("output/EditPDFMetadata.pdf")
pdf.Close()
Leggi di più: Impostare e recuperare le proprietà PDF utilizzando Python
Vantaggi
- Supporta sia i metadati PDF integrati che quelli personalizzati.
- Ideale per l'elaborazione batch e i flussi di lavoro di automazione.
Svantaggi
- Richiede una conoscenza di base della programmazione Python.
- È richiesta la configurazione iniziale della libreria.
- Meno comodo per modifiche singole e manuali.
Oltre alla modifica dei metadati, Spire.PDF per Python fornisce API per l'elaborazione batch, la generazione di PDF e la modifica dei contenuti, che possono essere combinate per attività di automazione dei documenti più complesse.
Confronto dei diversi metodi
| Metodo | Facilità d'uso | Modifica batch | Automazione | Privacy |
|---|---|---|---|---|
| Adobe Acrobat | Alta | No | No | Alta |
| Sejda (Online) | Molto alta | No | No | Bassa |
| Strumenti da riga di comando | Bassa | Sì | Sì | Alta |
| Spire.PDF per Python | Media | Sì | Sì | Alta |
Considerazioni finali
La modifica dei metadati PDF è un modo pratico per mantenere i documenti ben organizzati, ricercabili e coerenti tra diversi flussi di lavoro. A seconda del tuo background tecnico e dello scenario di utilizzo, esistono diversi modi efficaci per aggiornare le proprietà del PDF senza modificare il contenuto visibile del documento.
Per gli utenti che preferiscono un'interfaccia grafica, Adobe Acrobat fornisce una soluzione desktop affidabile, mentre Sejda PDF Editor è comodo per modifiche rapide basate su browser. Se hai bisogno di un maggiore controllo o desideri elaborare più file in modo efficiente, strumenti da riga di comando come ExifTool offrono un approccio potente e multipiattaforma. Per gli sviluppatori e i sistemi automatizzati, Spire.PDF per Python si distingue come l'opzione più flessibile, supportando sia i metadati integrati che quelli personalizzati con un codice minimo.
Scegliendo il metodo che meglio si adatta al tuo flusso di lavoro—manuale, online, da riga di comando o programmatico—puoi garantire che i tuoi metadati PDF rimangano accurati, standardizzati e facili da gestire su qualsiasi scala.
Domande frequenti
D1. È possibile modificare i metadati PDF senza modificare il contenuto del documento?
Sì. Gli aggiornamenti dei metadati non influiscono sul testo visibile o sul layout di un PDF.
D2. I metadati PDF sono visibili ai lettori?
I metadati sono nascosti per impostazione predefinita ma possono essere visualizzati nelle proprietà del documento.
D3. Posso modificare in batch i metadati di più PDF?
Sì. I metodi programmatici e da riga di comando sono i migliori per le operazioni batch.
D4. La modifica dei metadati influisce sulle firme digitali?
Sì. Qualsiasi modifica, incluse le modifiche ai metadati, può invalidare una firma digitale.
Potrebbe interessarti anche
Modifier les métadonnées d'un PDF : quatre méthodes efficaces
Table des matières
- Qu'est-ce que les métadonnées PDF ?
- Méthode 1 : Modifier les métadonnées PDF avec Adobe Acrobat
- Méthode 2 : Modifier les métadonnées PDF avec Sejda (en ligne)
- Méthode 3 : Modifier les métadonnées PDF avec des outils en ligne de commande
- Méthode 4 : Modifier les métadonnées PDF par programmation avec Spire.PDF
- Comparaison des différentes méthodes
- Réflexions finales
- FAQ
Les métadonnées PDF contiennent des informations descriptives sur un document, telles que son titre, son auteur, son sujet et ses mots-clés. Bien que ces données ne soient pas visibles dans les pages PDF elles-mêmes, elles sont intégrées dans la structure du fichier et peuvent être consultées par les lecteurs PDF, les moteurs de recherche et les systèmes de gestion de documents.
Dans cet article, nous explorerons quatre manières pratiques et efficaces de modifier les métadonnées PDF, couvrant les outils de bureau, les éditeurs en ligne et les solutions orientées développeur. Que vous ayez besoin de mettre à jour un seul fichier ou d'automatiser la modification des métadonnées pour de grandes collections de PDF, ce guide vous aidera à choisir la bonne approche.
Aperçu des méthodes :
- Méthode 1 : Modifier les métadonnées PDF avec Adobe Acrobat
- Méthode 2 : Modifier les métadonnées PDF avec Sejda (en ligne)
- Méthode 3 : Modifier les métadonnées PDF avec des outils en ligne de commande
- Méthode 4 : Modifier les métadonnées PDF par programmation avec Spire.PDF
Qu'est-ce que les métadonnées PDF ?
Les métadonnées PDF sont un ensemble de propriétés stockées dans un fichier PDF qui décrivent le document plutôt que son contenu visible. Ces propriétés aident les logiciels à identifier, classer et gérer plus efficacement les fichiers PDF. Les champs de métadonnées PDF courants incluent :
- Titre – Le titre du document affiché dans les visionneuses PDF
- Auteur – Le créateur ou le propriétaire du document
- Sujet – Une brève description du document
- Mots-clés – Balises ou expressions consultables
- Créateur – L'application qui a créé le PDF
- Producteur – Le logiciel utilisé pour générer le PDF final
- Date de création / Date de modification
Étant donné que les métadonnées sont distinctes de la mise en page et du texte du document, elles peuvent être modifiées en toute sécurité sans affecter le contenu visuel.
Méthode 1 : Modifier les métadonnées PDF avec Adobe Acrobat
Adobe Acrobat offre une interface fiable et intuitive pour la modification des métadonnées PDF, ce qui en fait un choix populaire pour les utilisateurs quotidiens. Il offre un accès complet aux champs de métadonnées standard via un flux de travail graphique familier. Pour mettre à jour les métadonnées à l'aide d'Adobe Acrobat, procédez comme suit :
- Ouvrez le fichier PDF dans Adobe Acrobat.
- Cliquez sur Fichier → Propriétés pour ouvrir la boîte de dialogue des propriétés du document.
- Modifiez des champs tels que Titre, Auteur, Sujet et Mots-clés sous l'onglet Description.
- Cliquez sur OK et enregistrez le PDF pour appliquer les modifications.
Avantages
- Interface graphique conviviale.
- Prise en charge complète des champs de métadonnées PDF standard.
- Solution PDF fiable et largement reconnue.
Inconvénients
- Nécessite une licence payante.
- Ne convient pas au traitement par lots ou automatisé.
Méthode 2 : Modifier les métadonnées PDF avec Sejda (en ligne)
Sejda est un outil en ligne bien connu qui vous permet de modifier les métadonnées PDF directement dans votre navigateur. Cette méthode est idéale pour des modifications rapides et ponctuelles lorsque vous ne souhaitez pas installer de logiciel de bureau. Le processus d'édition est simple et ne nécessite que quelques étapes :
- Ouvrez l'outil Modifier les métadonnées PDF de Sejda.
- Téléchargez votre fichier PDF depuis votre ordinateur ou votre stockage cloud.
- Choisissez Modifier les métadonnées, puis cliquez sur Continuer.
- Modifiez les champs de métadonnées requis, et cliquez sur Mettre à jour les métadonnées PDF pour enregistrer les modifications.
- Téléchargez le fichier PDF mis à jour.
Avantages
- Aucune installation de logiciel requise.
- Très facile à utiliser pour des modifications rapides et ponctuelles.
- Accessible depuis n'importe quel navigateur moderne.
Inconvénients
- Limitations de taille de fichier et d'utilisation quotidienne.
- Problèmes de confidentialité dus aux téléchargements de fichiers.
Méthode 3 : Modifier les métadonnées PDF avec des outils en ligne de commande
Les outils en ligne de commande offrent un moyen fiable et scriptable de modifier les métadonnées PDF sur différents systèmes d'exploitation. Cette méthode est idéale pour les utilisateurs qui préfèrent les flux de travail basés sur un terminal ou qui ont besoin de traiter efficacement plusieurs fichiers PDF. L'un des outils les plus utilisés à cette fin est ExifTool, qui prend en charge à la fois la lecture et l'écriture des métadonnées PDF.
Étapes pour modifier les métadonnées PDF avec ExifTool (sous Windows) :
-
Installez ExifTool sur votre système.
- Télécharger ExifTool pour Windows
- Extraire exiftool(-k).exe
- Renommez-le en exiftool.exe
- Copiez le .exe et le dossier "exiftool_files" dans C:\Windows
-
Ouvrez un terminal ou une invite de commande et vérifiez si ExifTool est disponible.
exiftool -ver -
Accédez au répertoire contenant votre fichier PDF. Par exemple, s'il se trouve dans D:\Documents, tapez :
D: cd Documents -
Exécutez une commande pour modifier les champs de métadonnées requis.
exiftool -Title="Cloud Computing Overview" -Author="Tim Taylor" -Subject="Introduction to cloud services" -Keywords="cloud; business; server" Input.pdf -
Vérifiez les modifications en lisant les métadonnées.
exiftool Input.pdf
Avantages
- Fonctionne de manière fiable sur Windows, macOS et Linux.
- Excellent pour les mises à jour par lots et automatisées.
- Aucune interface graphique requise.
Inconvénients
- Nécessite des connaissances en ligne de commande.
- Risque d'écrasements accidentels en cas de mauvaise utilisation.
Remarque : les étapes d'installation varient selon le système d'exploitation. Les utilisateurs de Linux et de macOS doivent installer ExifTool à l'aide d'un gestionnaire de paquets.
Méthode 4 : Modifier les métadonnées PDF par programmation avec Spire.PDF
Lorsque vous travaillez avec un grand nombre de fichiers PDF ou des flux de travail automatisés, la modification programmatique des métadonnées est la solution la plus efficace. Spire.PDF for Python fournit une API puissante et conviviale pour les développeurs qui vous permet de modifier les métadonnées PDF intégrées et personnalisées avec un minimum de code.
Cette approche est particulièrement utile pour les services backend, les pipelines de documents et les scénarios où les métadonnées doivent être normalisées sur de nombreux fichiers.
Vous trouverez ci-dessous un exemple illustrant comment modifier les métadonnées PDF à l'aide de Spire.PDF for Python :
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Input.pdf")
# Get the properties of the document
properties = pdf.DocumentInformation
# Set built-in properties
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "cloud service; digital business"
properties.Subject = "The introduction of cloud service and its advantages"
properties.Title = "The Power of Cloud Services: Empowering Businesses in the Digital Age"
properties.Producer = "Spire.PDF for Python"
# Set custom properties
properties.SetCustomProperty("Company", "E-iceblue")
properties.SetCustomProperty("Tags", "Cloud; Business; Server")
# Save the document
pdf.SaveToFile("output/EditPDFMetadata.pdf")
pdf.Close()
Lire la suite : Définir et récupérer les propriétés PDF à l'aide de Python
Avantages
- Prend en charge les métadonnées PDF intégrées et personnalisées.
- Idéal pour le traitement par lots et les flux de travail d'automatisation.
Inconvénients
- Nécessite des connaissances de base en programmation Python.
- Une configuration initiale de la bibliothèque est requise.
- Moins pratique pour les modifications manuelles uniques.
En plus de la modification des métadonnées, Spire.PDF for Python fournit des API pour le traitement par lots, la génération de PDF et la modification de contenu, qui peuvent être combinées pour des tâches d'automatisation de documents plus complexes.
Comparaison des différentes méthodes
| Méthode | Facilité d'utilisation | Édition par lots | Automatisation | Confidentialité |
|---|---|---|---|---|
| Adobe Acrobat | Élevée | Non | Non | Élevée |
| Sejda (en ligne) | Très élevée | Non | Non | Faible |
| Outils en ligne de commande | Faible | Oui | Oui | Élevée |
| Spire.PDF for Python | Moyenne | Oui | Oui | Élevée |
Réflexions finales
La modification des métadonnées PDF est un moyen pratique de garder les documents bien organisés, consultables et cohérents dans différents flux de travail. En fonction de votre bagage technique et de votre scénario d'utilisation, il existe plusieurs moyens efficaces de mettre à jour les propriétés PDF sans modifier le contenu visible du document.
Pour les utilisateurs qui préfèrent une interface graphique, Adobe Acrobat fournit une solution de bureau fiable, tandis que Sejda PDF Editor est pratique pour des modifications rapides basées sur un navigateur. Si vous avez besoin d'un plus grand contrôle ou si vous souhaitez traiter efficacement plusieurs fichiers, des outils en ligne de commande tels qu'ExifTool offrent une approche puissante et multiplateforme. Pour les développeurs et les systèmes automatisés, Spire.PDF for Python se distingue comme l'option la plus flexible, prenant en charge les métadonnées intégrées et personnalisées avec un minimum de code.
En choisissant la méthode qui correspond le mieux à votre flux de travail—manuelle, en ligne, en ligne de commande ou programmatique—vous pouvez vous assurer que vos métadonnées PDF restent exactes, standardisées et faciles à gérer à n'importe quelle échelle.
FAQ
Q1. Les métadonnées PDF peuvent-elles être modifiées sans changer le contenu du document ?
Oui. Les mises à jour des métadonnées n'affectent pas le texte visible ou la mise en page d'un PDF.
Q2. Les métadonnées PDF sont-elles visibles pour les lecteurs ?
Les métadonnées sont masquées par défaut mais peuvent être consultées dans les propriétés du document.
Q3. Puis-je modifier par lots les métadonnées de plusieurs PDF ?
Oui. Les méthodes programmatiques et en ligne de commande sont les meilleures pour les opérations par lots.
Q4. La modification des métadonnées affecte-t-elle les signatures numériques ?
Oui. Toute modification, y compris les modifications de métadonnées, peut invalider une signature numérique.
Vous pourriez aussi être intéressé par
Editar metadatos de PDF: cuatro formas efectivas
Tabla de Contenidos
- ¿Qué son los metadatos de PDF?
- Método 1: Editar metadatos de PDF usando Adobe Acrobat
- Método 2: Editar metadatos de PDF usando Sejda (en línea)
- Método 3: Editar metadatos de PDF usando herramientas de línea de comandos
- Método 4: Editar metadatos de PDF programáticamente usando Spire.PDF
- Comparación de diferentes métodos
- Conclusiones
- Preguntas frecuentes
Los metadatos de PDF contienen información descriptiva sobre un documento, como su título, autor, asunto y palabras clave. Aunque estos datos no son visibles dentro de las propias páginas del PDF, están incrustados en la estructura del archivo y pueden ser accedidos por lectores de PDF, motores de búsqueda y sistemas de gestión de documentos.
En este artículo, exploraremos cuatro formas prácticas y eficaces de editar metadatos de PDF, abarcando herramientas de escritorio, editores en línea y soluciones orientadas a desarrolladores. Ya sea que necesite actualizar un solo archivo o automatizar la edición de metadatos para grandes colecciones de PDF, esta guía le ayudará a elegir el enfoque adecuado.
Resumen de los métodos:
- Método 1: Editar metadatos de PDF usando Adobe Acrobat
- Método 2: Editar metadatos de PDF usando Sejda (en línea)
- Método 3: Editar metadatos de PDF usando herramientas de línea de comandos
- Método 4: Editar metadatos de PDF programáticamente usando Spire.PDF
¿Qué son los metadatos de PDF?
Los metadatos de PDF son un conjunto de propiedades almacenadas dentro de un archivo PDF que describen el documento en lugar de su contenido visible. Estas propiedades ayudan al software a identificar, categorizar y gestionar los archivos PDF de manera más eficiente. Los campos comunes de metadatos de PDF incluyen:
- Título – El título del documento que se muestra en los visores de PDF
- Autor – El creador o propietario del documento
- Asunto – Una breve descripción del documento
- Palabras clave – Etiquetas o frases de búsqueda
- Creador – La aplicación que creó el PDF
- Productor – El software utilizado para generar el PDF final
- Fecha de creación / Fecha de modificación
Dado que los metadatos están separados del diseño y el texto del documento, se pueden editar de forma segura sin afectar el contenido visual.
Método 1: Editar metadatos de PDF usando Adobe Acrobat
Adobe Acrobat ofrece una interfaz fiable e intuitiva para editar metadatos de PDF, lo que lo convierte en una opción popular para los usuarios cotidianos. Proporciona acceso completo a los campos de metadatos estándar a través de un flujo de trabajo gráfico familiar. Para actualizar los metadatos con Adobe Acrobat, siga estos pasos:
- Abra el archivo PDF en Adobe Acrobat.
- Haga clic en Archivo → Propiedades para abrir el cuadro de diálogo de propiedades del documento.
- Edite campos como Título, Autor, Asunto y Palabras clave en la pestaña Descripción.
- Haga clic en Aceptar y guarde el PDF para aplicar los cambios.
Ventajas
- Interfaz gráfica fácil de usar.
- Soporte completo para los campos de metadatos estándar de PDF.
- Solución de PDF fiable y ampliamente reconocida.
Desventajas
- Requiere una licencia de pago.
- No es adecuado para el procesamiento por lotes o automatizado.
Método 2: Editar metadatos de PDF usando Sejda (en línea)
Sejda es una conocida herramienta en línea que le permite editar metadatos de PDF directamente en su navegador. Este método es ideal para ediciones rápidas y únicas cuando no desea instalar software de escritorio. El proceso de edición es simple y requiere solo unos pocos pasos:
- Abra la herramienta Editar metadatos de PDF de Sejda.
- Suba su archivo PDF desde su ordenador o almacenamiento en la nube.
- Elija Cambiar metadatos y luego haga clic en Continuar.
- Modifique los campos de metadatos requeridos y haga clic en Actualizar metadatos de PDF para guardar los cambios.
- Descargue el archivo PDF actualizado.
Ventajas
- No requiere instalación de software.
- Muy fácil de usar para ediciones rápidas y únicas.
- Accesible desde cualquier navegador moderno.
Desventajas
- Limitaciones de tamaño de archivo y uso diario.
- Preocupaciones de privacidad debido a la subida de archivos.
Método 3: Editar metadatos de PDF usando herramientas de línea de comandos
Las herramientas de línea de comandos proporcionan una forma fiable y programable de editar metadatos de PDF en diferentes sistemas operativos. Este método es ideal para los usuarios que prefieren flujos de trabajo basados en terminal o que necesitan procesar múltiples archivos PDF de manera eficiente. Una de las herramientas más utilizadas para este propósito es ExifTool, que admite tanto la lectura como la escritura de metadatos de PDF.
Pasos para editar metadatos de PDF con ExifTool (en Windows):
-
Instale ExifTool en su sistema.
- Descargar ExifTool para Windows
- Extraer exiftool(-k).exe
- Renombrarlo a exiftool.exe
- Copiar el .exe y la carpeta "exiftool_files" a C:\Windows
-
Abra una terminal o símbolo del sistema y compruebe si ExifTool está disponible.
exiftool -ver -
Navegue al directorio que contiene su archivo PDF. Por ejemplo, si está en D:\Documents, escriba:
D: cd Documents -
Ejecute un comando para modificar los campos de metadatos requeridos.
exiftool -Title="Cloud Computing Overview" -Author="Tim Taylor" -Subject="Introduction to cloud services" -Keywords="cloud; business; server" Input.pdf -
Verifique los cambios leyendo los metadatos.
exiftool Input.pdf
Ventajas
- Funciona de forma fiable en Windows, macOS y Linux.
- Excelente para actualizaciones por lotes y automatizadas.
- No se requiere interfaz gráfica.
Desventajas
- Requiere conocimientos de la línea de comandos.
- Riesgo de sobrescrituras accidentales si se usa incorrectamente.
Nota: Los pasos de instalación varían según el sistema operativo. Los usuarios de Linux y macOS deben instalar ExifTool utilizando un gestor de paquetes.
Método 4: Editar metadatos de PDF programáticamente usando Spire.PDF
Cuando se trabaja con un gran número de archivos PDF o flujos de trabajo automatizados, la edición programática de metadatos es la solución más eficiente. Spire.PDF para Python proporciona una API potente y fácil de usar para desarrolladores que le permite modificar tanto los metadatos de PDF integrados como los personalizados con un código mínimo.
Este enfoque es especialmente útil para servicios de backend, canalizaciones de documentos y escenarios donde los metadatos deben estandarizarse en muchos archivos.
A continuación se muestra un ejemplo que demuestra cómo editar metadatos de PDF utilizando Spire.PDF para Python:
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Input.pdf")
# Get the properties of the document
properties = pdf.DocumentInformation
# Set built-in properties
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "cloud service; digital business"
properties.Subject = "The introduction of cloud service and its advantages"
properties.Title = "The Power of Cloud Services: Empowering Businesses in the Digital Age"
properties.Producer = "Spire.PDF for Python"
# Set custom properties
properties.SetCustomProperty("Company", "E-iceblue")
properties.SetCustomProperty("Tags", "Cloud; Business; Server")
# Save the document
pdf.SaveToFile("output/EditPDFMetadata.pdf")
pdf.Close()
Leer más: Establecer y recuperar propiedades de PDF usando Python
Ventajas
- Admite metadatos de PDF tanto integrados como personalizados.
- Ideal para el procesamiento por lotes y los flujos de trabajo de automatización.
Desventajas
- Requiere conocimientos básicos de programación en Python.
- Se requiere la configuración inicial de la biblioteca.
- Menos conveniente para ediciones manuales únicas.
Además de la edición de metadatos, Spire.PDF para Python proporciona API para el procesamiento por lotes, la generación de PDF y la modificación de contenido, que se pueden combinar para tareas de automatización de documentos más complejas.
Comparación de diferentes métodos
| Método | Facilidad de uso | Edición por lotes | Automatización | Privacidad |
|---|---|---|---|---|
| Adobe Acrobat | Alta | No | No | Alta |
| Sejda (en línea) | Muy alta | No | No | Baja |
| Herramientas de línea de comandos | Baja | Sí | Sí | Alta |
| Spire.PDF para Python | Media | Sí | Sí | Alta |
Conclusiones
La edición de metadatos de PDF es una forma práctica de mantener los documentos bien organizados, con capacidad de búsqueda y coherentes en diferentes flujos de trabajo. Dependiendo de su experiencia técnica y escenario de uso, existen múltiples formas efectivas de actualizar las propiedades de un PDF sin modificar el contenido visible del documento.
Para los usuarios que prefieren una interfaz gráfica, Adobe Acrobat proporciona una solución de escritorio fiable, mientras que el editor de PDF Sejda es conveniente para ediciones rápidas basadas en el navegador. Si necesita un mayor control o desea procesar múltiples archivos de manera eficiente, las herramientas de línea de comandos como ExifTool ofrecen un enfoque potente y multiplataforma. Para desarrolladores y sistemas automatizados, Spire.PDF para Python se destaca como la opción más flexible, admitiendo metadatos tanto integrados como personalizados con un código mínimo.
Al elegir el método que mejor se adapte a su flujo de trabajo (manual, en línea, por línea de comandos o programático), puede asegurarse de que sus metadatos de PDF sigan siendo precisos, estandarizados y fáciles de gestionar a cualquier escala.
Preguntas frecuentes
P1. ¿Se pueden editar los metadatos de un PDF sin cambiar el contenido del documento?
Sí. Las actualizaciones de metadatos no afectan el texto visible ni el diseño de un PDF.
P2. ¿Son visibles los metadatos de un PDF para los lectores?
Los metadatos están ocultos de forma predeterminada, pero se pueden ver en las propiedades del documento.
P3. ¿Puedo editar metadatos por lotes para múltiples archivos PDF?
Sí. Los métodos programáticos y de línea de comandos son los mejores para las operaciones por lotes.
P4. ¿La edición de metadatos afecta a las firmas digitales?
Sí. Cualquier modificación, incluidos los cambios en los metadatos, puede invalidar una firma digital.
También le puede interesar
PDF-Metadaten bearbeiten: Vier effektive Methoden
Inhaltsverzeichnis
- Was sind PDF-Metadaten?
- Methode 1: PDF-Metadaten mit Adobe Acrobat bearbeiten
- Methode 2: PDF-Metadaten mit Sejda (Online) bearbeiten
- Methode 3: PDF-Metadaten mit Befehlszeilen-Tools bearbeiten
- Methode 4: PDF-Metadaten programmgesteuert mit Spire.PDF bearbeiten
- Vergleich verschiedener Methoden
- Abschließende Gedanken
- Häufig gestellte Fragen
PDF-Metadaten enthalten beschreibende Informationen über ein Dokument, wie z. B. Titel, Autor, Betreff und Schlüsselwörter. Obwohl diese Daten nicht auf den PDF-Seiten selbst sichtbar sind, sind sie in der Dateistruktur eingebettet und können von PDF-Readern, Suchmaschinen und Dokumentenmanagementsystemen abgerufen werden.
In diesem Artikel werden wir vier praktische und effektive Möglichkeiten zur Bearbeitung von PDF-Metadaten untersuchen, die Desktop-Tools, Online-Editoren und entwicklerorientierte Lösungen abdecken. Egal, ob Sie eine einzelne Datei aktualisieren oder die Metadatenbearbeitung für große PDF-Sammlungen automatisieren müssen, dieser Leitfaden wird Ihnen helfen, den richtigen Ansatz zu wählen.
Methodenübersicht:
- Methode 1: PDF-Metadaten mit Adobe Acrobat bearbeiten
- Methode 2: PDF-Metadaten mit Sejda (Online) bearbeiten
- Methode 3: PDF-Metadaten mit Befehlszeilen-Tools bearbeiten
- Methode 4: PDF-Metadaten programmgesteuert mit Spire.PDF bearbeiten
Was sind PDF-Metadaten?
PDF-Metadaten sind eine Reihe von Eigenschaften, die in einer PDF-Datei gespeichert sind und das Dokument anstelle seines sichtbaren Inhalts beschreiben. Diese Eigenschaften helfen Software dabei, PDF-Dateien effizienter zu identifizieren, zu kategorisieren und zu verwalten. Gängige PDF-Metadatenfelder umfassen:
- Titel – Der Dokumenttitel, der in PDF-Viewern angezeigt wird
- Autor – Der Ersteller oder Besitzer des Dokuments
- Betreff – Eine kurze Beschreibung des Dokuments
- Schlüsselwörter – Durchsuchbare Tags oder Phrasen
- Ersteller – Die Anwendung, die das PDF erstellt hat
- Hersteller – Die Software, die zur Erzeugung des endgültigen PDFs verwendet wurde
- Erstellungsdatum / Änderungsdatum
Da Metadaten vom Layout und Text des Dokuments getrennt sind, können sie sicher bearbeitet werden, ohne den visuellen Inhalt zu beeinträchtigen.
Methode 1: PDF-Metadaten mit Adobe Acrobat bearbeiten
Adobe Acrobat bietet eine zuverlässige und intuitive Benutzeroberfläche zur Bearbeitung von PDF-Metadaten und ist daher eine beliebte Wahl für alltägliche Benutzer. Es bietet vollen Zugriff auf Standard-Metadatenfelder über einen vertrauten grafischen Arbeitsablauf. Um Metadaten mit Adobe Acrobat zu aktualisieren, folgen Sie diesen Schritten:
- Öffnen Sie die PDF-Datei in Adobe Acrobat.
- Klicken Sie auf Datei → Eigenschaften, um das Dialogfeld für die Dokumenteigenschaften zu öffnen.
- Bearbeiten Sie Felder wie Titel, Autor, Betreff und Schlüsselwörter unter dem Reiter Beschreibung.
- Klicken Sie auf OK und speichern Sie das PDF, um die Änderungen zu übernehmen.
Vorteile
- Benutzerfreundliche grafische Oberfläche.
- Volle Unterstützung für Standard-PDF-Metadatenfelder.
- Zuverlässige und weithin anerkannte PDF-Lösung.
Nachteile
- Erfordert eine kostenpflichtige Lizenz.
- Nicht für die Stapel- oder automatisierte Verarbeitung geeignet.
Methode 2: PDF-Metadaten mit Sejda (Online) bearbeiten
Sejda ist ein bekanntes Online-Tool, mit dem Sie PDF-Metadaten direkt in Ihrem Browser bearbeiten können. Diese Methode ist ideal für schnelle, einmalige Bearbeitungen, wenn Sie keine Desktop-Software installieren möchten. Der Bearbeitungsprozess ist einfach und erfordert nur wenige Schritte:
- Öffnen Sie Sejdas PDF-Metadaten bearbeiten Tool.
- Laden Sie Ihre PDF-Datei von Ihrem Computer oder Cloud-Speicher hoch.
- Wählen Sie Metadaten ändern und klicken Sie dann auf Weiter.
- Ändern Sie die erforderlichen Metadatenfelder und klicken Sie auf PDF-Metadaten aktualisieren, um die Änderungen zu speichern.
- Laden Sie die aktualisierte PDF-Datei herunter.
Vorteile
- Keine Softwareinstallation erforderlich.
- Sehr einfach für schnelle, einmalige Bearbeitungen zu verwenden.
- Von jedem modernen Browser aus zugänglich.
Nachteile
- Dateigrößen- und tägliche Nutzungsbeschränkungen.
- Datenschutzbedenken aufgrund von Datei-Uploads.
Methode 3: PDF-Metadaten mit Befehlszeilen-Tools bearbeiten
Befehlszeilen-Tools bieten eine zuverlässige und skriptfähige Möglichkeit, PDF-Metadaten über verschiedene Betriebssysteme hinweg zu bearbeiten. Diese Methode ist ideal für Benutzer, die terminalbasierte Arbeitsabläufe bevorzugen oder mehrere PDF-Dateien effizient verarbeiten müssen. Eines der am weitesten verbreiteten Werkzeuge für diesen Zweck ist ExifTool, das sowohl das Lesen als auch das Schreiben von PDF-Metadaten unterstützt.
Schritte zur Bearbeitung von PDF-Metadaten mit ExifTool (unter Windows):
-
Installieren Sie ExifTool auf Ihrem System.
- Laden Sie ExifTool für Windows herunter
- Extrahieren Sie exiftool(-k).exe
- Benennen Sie es in exiftool.exe um
- Kopieren Sie die .exe-Datei und den "exiftool_files" Ordner nach C:\Windows
-
Öffnen Sie ein Terminal oder eine Eingabeaufforderung und prüfen Sie, ob ExifTool verfügbar ist.
exiftool -ver -
Navigieren Sie zu dem Verzeichnis, das Ihre PDF-Datei enthält. Wenn sie sich beispielsweise in D:\Dokumente befindet, geben Sie ein:
D: cd Documents -
Führen Sie einen Befehl aus, um die erforderlichen Metadatenfelder zu ändern.
exiftool -Title="Cloud Computing Overview" -Author="Tim Taylor" -Subject="Introduction to cloud services" -Keywords="cloud; business; server" Input.pdf -
Überprüfen Sie die Änderungen, indem Sie die Metadaten lesen.
exiftool Input.pdf
Vorteile
- Funktioniert zuverlässig unter Windows, macOS und Linux.
- Hervorragend für Stapel- und automatisierte Updates.
- Keine grafische Oberfläche erforderlich.
Nachteile
- Erfordert Kenntnisse der Befehlszeile.
- Gefahr des versehentlichen Überschreibens bei unsachgemäßer Verwendung.
Hinweis: Die Installationsschritte variieren je nach Betriebssystem. Linux- und macOS-Benutzer sollten ExifTool mit einem Paketmanager installieren.
Methode 4: PDF-Metadaten programmgesteuert mit Spire.PDF bearbeiten
Bei der Arbeit mit einer großen Anzahl von PDF-Dateien oder automatisierten Arbeitsabläufen ist die programmgesteuerte Bearbeitung von Metadaten die effizienteste Lösung. Spire.PDF for Python bietet eine leistungsstarke und entwicklerfreundliche API, mit der Sie sowohl integrierte als auch benutzerdefinierte PDF-Metadaten mit minimalem Code ändern können.
Dieser Ansatz ist besonders nützlich für Backend-Dienste, Dokumenten-Pipelines und Szenarien, in denen Metadaten über viele Dateien hinweg standardisiert werden müssen.
Unten finden Sie ein Beispiel, das zeigt, wie Sie PDF-Metadaten mit Spire.PDF for Python bearbeiten:
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Input.pdf")
# Get the properties of the document
properties = pdf.DocumentInformation
# Set built-in properties
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "cloud service; digital business"
properties.Subject = "The introduction of cloud service and its advantages"
properties.Title = "The Power of Cloud Services: Empowering Businesses in the Digital Age"
properties.Producer = "Spire.PDF for Python"
# Set custom properties
properties.SetCustomProperty("Company", "E-iceblue")
properties.SetCustomProperty("Tags", "Cloud; Business; Server")
# Save the document
pdf.SaveToFile("output/EditPDFMetadata.pdf")
pdf.Close()
Lesen Sie weiter: PDF-Eigenschaften mit Python festlegen und abrufen
Vorteile
- Unterstützt sowohl integrierte als auch benutzerdefinierte PDF-Metadaten.
- Ideal für Stapelverarbeitungs- und Automatisierungs-Workflows.
Nachteile
- Erfordert grundlegende Python-Programmierkenntnisse.
- Eine anfängliche Bibliothekseinrichtung ist erforderlich.
- Weniger praktisch für einzelne, manuelle Bearbeitungen.
Zusätzlich zur Metadatenbearbeitung bietet Spire.PDF for Python APIs für die Stapelverarbeitung, PDF-Erstellung und Inhaltsänderung, die für komplexere Aufgaben der Dokumentenautomatisierung kombiniert werden können.
Vergleich verschiedener Methoden
| Methode | Benutzerfreundlichkeit | Stapelbearbeitung | Automatisierung | Datenschutz |
|---|---|---|---|---|
| Adobe Acrobat | Hoch | Nein | Nein | Hoch |
| Sejda (Online) | Sehr hoch | Nein | Nein | Niedrig |
| Befehlszeilen-Tools | Niedrig | Ja | Ja | Hoch |
| Spire.PDF for Python | Mittel | Ja | Ja | Hoch |
Abschließende Gedanken
Die Bearbeitung von PDF-Metadaten ist eine praktische Möglichkeit, Dokumente gut organisiert, durchsuchbar und über verschiedene Arbeitsabläufe hinweg konsistent zu halten. Abhängig von Ihrem technischen Hintergrund und Ihrem Anwendungsszenario gibt es mehrere effektive Möglichkeiten, PDF-Eigenschaften zu aktualisieren, ohne den sichtbaren Inhalt des Dokuments zu ändern.
Für Benutzer, die eine grafische Benutzeroberfläche bevorzugen, bietet Adobe Acrobat eine zuverlässige Desktop-Lösung, während der Sejda PDF Editor für schnelle, browserbasierte Bearbeitungen praktisch ist. Wenn Sie mehr Kontrolle benötigen oder mehrere Dateien effizient verarbeiten möchten, bieten Befehlszeilen-Tools wie ExifTool einen leistungsstarken und plattformübergreifenden Ansatz. Für Entwickler und automatisierte Systeme ist Spire.PDF for Python die flexibelste Option, die sowohl integrierte als auch benutzerdefinierte Metadaten mit minimalem Code unterstützt.
Indem Sie die Methode wählen, die am besten zu Ihrem Arbeitsablauf passt – manuell, online, per Befehlszeile oder programmgesteuert – können Sie sicherstellen, dass Ihre PDF-Metadaten korrekt, standardisiert und in jedem Maßstab einfach zu verwalten bleiben.
Häufig gestellte Fragen
F1. Können PDF-Metadaten bearbeitet werden, ohne den Dokumentinhalt zu ändern?
Ja. Metadaten-Updates beeinträchtigen nicht den sichtbaren Text oder das Layout eines PDFs.
F2. Sind PDF-Metadaten für Leser sichtbar?
Metadaten sind standardmäßig ausgeblendet, können aber in den Dokumenteigenschaften eingesehen werden.
F3. Kann ich Metadaten für mehrere PDFs im Stapel bearbeiten?
Ja. Programmgesteuerte und Befehlszeilenmethoden eignen sich am besten für Stapeloperationen.
F4. Beeinflusst die Bearbeitung von Metadaten digitale Signaturen?
Ja. Jede Änderung, einschließlich Metadatenänderungen, kann eine digitale Signatur ungültig machen.
Das könnte Sie auch interessieren
Редактирование метаданных PDF: четыре эффективных способа
Содержание
- Что такое метаданные PDF?
- Способ 1: Редактирование метаданных PDF с помощью Adobe Acrobat
- Способ 2: Редактирование метаданных PDF с помощью Sejda (онлайн)
- Способ 3: Редактирование метаданных PDF с помощью инструментов командной строки
- Способ 4: Программное редактирование метаданных PDF с помощью Spire.PDF
- Сравнение различных методов
- Заключительные мысли
- Часто задаваемые вопросы
Метаданные PDF содержат описательную информацию о документе, такую как его заголовок, автор, тема и ключевые слова. Хотя эти данные не видны на самих страницах PDF, они встроены в структуру файла и могут быть доступны для программ чтения PDF, поисковых систем и систем управления документами.
В этой статье мы рассмотрим четыре практичных и эффективных способа редактирования метаданных PDF, охватывая настольные инструменты, онлайн-редакторы и решения, ориентированные на разработчиков. Независимо от того, нужно ли вам обновить один файл или автоматизировать редактирование метаданных для больших коллекций PDF, это руководство поможет вам выбрать правильный подход.
Обзор методов:
- Способ 1: Редактирование метаданных PDF с помощью Adobe Acrobat
- Способ 2: Редактирование метаданных PDF с помощью Sejda (онлайн)
- Способ 3: Редактирование метаданных PDF с помощью инструментов командной строки
- Способ 4: Программное редактирование метаданных PDF с помощью Spire.PDF
Что такое метаданные PDF?
Метаданные PDF — это набор свойств, хранящихся в файле PDF, которые описывают документ, а не его видимое содержимое. Эти свойства помогают программному обеспечению более эффективно идентифицировать, классифицировать и управлять файлами PDF. Общие поля метаданных PDF включают:
- Заголовок – Заголовок документа, отображаемый в программах для просмотра PDF
- Автор – Создатель или владелец документа
- Тема – Краткое описание документа
- Ключевые слова – Теги или фразы для поиска
- Создатель – Приложение, создавшее PDF
- Производитель – Программное обеспечение, использованное для создания окончательного PDF
- Дата создания / Дата изменения
Поскольку метаданные отделены от макета и текста документа, их можно безопасно редактировать, не затрагивая визуальное содержимое.
Способ 1: Редактирование метаданных PDF с помощью Adobe Acrobat
Adobe Acrobat предлагает надежный и интуитивно понятный интерфейс для редактирования метаданных PDF, что делает его популярным выбором для обычных пользователей. Он обеспечивает полный доступ к стандартным полям метаданных через знакомый графический рабочий процесс. Чтобы обновить метаданные с помощью Adobe Acrobat, выполните следующие действия:
- Откройте PDF-файл в Adobe Acrobat.
- Нажмите Файл → Свойства, чтобы открыть диалоговое окно свойств документа.
- Отредактируйте такие поля, как Заголовок, Автор, Тема и Ключевые слова на вкладке Описание.
- Нажмите ОК и сохраните PDF, чтобы применить изменения.
Плюсы
- Удобный графический интерфейс.
- Полная поддержка стандартных полей метаданных PDF.
- Надежное и широко признанное решение для PDF.
Минусы
- Требуется платная лицензия.
- Не подходит для пакетной или автоматизированной обработки.
Способ 2: Редактирование метаданных PDF с помощью Sejda (онлайн)
Sejda — это известный онлайн-инструмент, который позволяет редактировать метаданные PDF прямо в браузере. Этот метод идеально подходит для быстрых одноразовых правок, когда вы не хотите устанавливать настольное программное обеспечение. Процесс редактирования прост и требует всего нескольких шагов:
- Откройте инструмент Sejda Редактировать метаданные PDF.
- Загрузите свой PDF-файл с компьютера или из облачного хранилища.
- Выберите Изменить метаданные, затем нажмите Продолжить.
- Измените необходимые поля метаданных и нажмите Обновить метаданные PDF, чтобы сохранить изменения.
- Загрузите обновленный PDF-файл.
Плюсы
- Не требуется установка программного обеспечения.
- Очень прост в использовании для быстрых одноразовых правок.
- Доступен из любого современного браузера.
Минусы
- Ограничения по размеру файла и ежедневному использованию.
- Проблемы с конфиденциальностью из-за загрузки файлов.
Способ 3: Редактирование метаданных PDF с помощью инструментов командной строки
Инструменты командной строки предоставляют надежный и скриптовый способ редактирования метаданных PDF в различных операционных системах. Этот метод идеально подходит для пользователей, которые предпочитают рабочие процессы на основе терминала или нуждаются в эффективной обработке нескольких файлов PDF. Одним из наиболее широко используемых инструментов для этой цели является ExifTool, который поддерживает как чтение, так и запись метаданных PDF.
Шаги по редактированию метаданных PDF с помощью ExifTool (в Windows):
-
Установите ExifTool в вашей системе.
- Скачайте ExifTool для Windows
- Извлеките exiftool(-k).exe
- Переименуйте его в exiftool.exe
- Скопируйте .exe и папку "exiftool_files" в C:\Windows
-
Откройте терминал или командную строку и проверьте, доступен ли ExifTool.
exiftool -ver -
Перейдите в каталог, содержащий ваш PDF-файл. Например, если он находится в D:\Documents, введите:
D: cd Documents -
Выполните команду для изменения необходимых полей метаданных.
exiftool -Title="Cloud Computing Overview" -Author="Tim Taylor" -Subject="Introduction to cloud services" -Keywords="cloud; business; server" Input.pdf -
Проверьте изменения, прочитав метаданные.
exiftool Input.pdf
Плюсы
- Надежно работает в Windows, macOS и Linux.
- Отлично подходит для пакетных и автоматизированных обновлений.
- Не требуется графический интерфейс.
Минусы
- Требуются знания командной строки.
- Риск случайной перезаписи при неправильном использовании.
Примечание: шаги установки зависят от операционной системы. Пользователи Linux и macOS должны устанавливать ExifTool с помощью менеджера пакетов.
Способ 4: Программное редактирование метаданных PDF с помощью Spire.PDF
При работе с большим количеством PDF-файлов или автоматизированными рабочими процессами программное редактирование метаданных является наиболее эффективным решением. Spire.PDF for Python предоставляет мощный и удобный для разработчиков API, который позволяет изменять как встроенные, так и пользовательские метаданные PDF с минимальным кодом.
Этот подход особенно полезен для бэкэнд-сервисов, конвейеров документов и сценариев, где метаданные необходимо стандартизировать для многих файлов.
Ниже приведен пример, демонстрирующий, как редактировать метаданные PDF с помощью Spire.PDF for Python:
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Input.pdf")
# Get the properties of the document
properties = pdf.DocumentInformation
# Set built-in properties
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "cloud service; digital business"
properties.Subject = "The introduction of cloud service and its advantages"
properties.Title = "The Power of Cloud Services: Empowering Businesses in the Digital Age"
properties.Producer = "Spire.PDF for Python"
# Set custom properties
properties.SetCustomProperty("Company", "E-iceblue")
properties.SetCustomProperty("Tags", "Cloud; Business; Server")
# Save the document
pdf.SaveToFile("output/EditPDFMetadata.pdf")
pdf.Close()
Читать далее: Установка и получение свойств PDF с помощью Python
Плюсы
- Поддерживает как встроенные, так и пользовательские метаданные PDF.
- Идеально подходит для пакетной обработки и автоматизации рабочих процессов.
Минусы
- Требуются базовые знания программирования на Python.
- Требуется начальная настройка библиотеки.
- Менее удобно для единичных ручных правок.
Помимо редактирования метаданных, Spire.PDF for Python предоставляет API для пакетной обработки, создания PDF и изменения содержимого, которые можно комбинировать для более сложных задач автоматизации документов.
Сравнение различных методов
| Метод | Простота использования | Пакетное редактирование | Автоматизация | Конфиденциальность |
|---|---|---|---|---|
| Adobe Acrobat | Высокая | Нет | Нет | Высокая |
| Sejda (Онлайн) | Очень высокая | Нет | Нет | Низкая |
| Инструменты командной строки | Низкая | Да | Да | Высокая |
| Spire.PDF for Python | Средняя | Да | Да | Высокая |
Заключительные мысли
Редактирование метаданных PDF — это практичный способ поддерживать документы в хорошо организованном, доступном для поиска и согласованном виде в различных рабочих процессах. В зависимости от вашего технического опыта и сценария использования существует несколько эффективных способов обновления свойств PDF без изменения видимого содержимого документа.
Для пользователей, предпочитающих графический интерфейс, Adobe Acrobat предоставляет надежное настольное решение, в то время как Sejda PDF Editor удобен для быстрых правок в браузере. Если вам нужен больший контроль или вы хотите эффективно обрабатывать несколько файлов, инструменты командной строки, такие как ExifTool, предлагают мощный и кроссплатформенный подход. Для разработчиков и автоматизированных систем Spire.PDF for Python выделяется как наиболее гибкий вариант, поддерживающий как встроенные, так и пользовательские метаданные с минимальным кодом.
Выбирая метод, который наилучшим образом соответствует вашему рабочему процессу — ручной, онлайн, командная строка или программный — вы можете гарантировать, что ваши метаданные PDF останутся точными, стандартизированными и простыми в управлении в любом масштабе.
Часто задаваемые вопросы
В1. Можно ли редактировать метаданные PDF, не изменяя содержимое документа?
Да. Обновления метаданных не влияют на видимый текст или макет PDF.
В2. Видны ли метаданные PDF читателям?
Метаданные по умолчанию скрыты, но их можно просмотреть в свойствах документа.
В3. Могу ли я пакетно редактировать метаданные для нескольких PDF-файлов?
Да. Программные и командно-строчные методы лучше всего подходят для пакетных операций.
В4. Влияет ли редактирование метаданных на цифровые подписи?
Да. Любое изменение, включая изменения метаданных, может сделать цифровую подпись недействительной.
Вам также может быть интересно
Converter Word para RTF: 4 maneiras fáceis (opções gratuitas e em lote)
Ao compartilhar documentos entre plataformas, os arquivos do Word podem encontrar problemas de compatibilidade, especialmente entre diferentes sistemas operacionais ou aplicativos de escritório. A conversão de documentos do Word para RTF (Rich Text Format) preserva a formatação essencial do texto, garantindo amplo suporte multiplataforma, tornando-o ideal para compartilhamento contínuo. Este guia fornece uma visão geral completa de como converter Word para RTF, explicando o que é RTF, por que é importante e quatro métodos práticos para realizar a conversão de forma eficiente.
- O que é RTF
- Por que converter Word para RTF
- Como converter Word para RTF
- Como evitar problemas de formatação durante a conversão de Word para RTF
Dica: Se precisar reverter o processo, nosso tutorial sobre conversão de RTF para Word mostra maneiras simples de converter de volta.
O que é RTF?
RTF (Rich Text Format) é um formato de documento desenvolvido pela Microsoft na década de 1980 para permitir a troca de texto formatado entre diferentes plataformas e aplicativos.
Diferente do texto simples, o RTF suporta formatação básica, como fontes, tamanhos de fonte, estilos de negrito e itálico, cores de texto e alinhamento de parágrafo. Ao mesmo tempo, evita muitos dos recursos avançados e complexos encontrados nos formatos modernos do Word, tornando-o mais estável e amplamente compatível em diferentes ambientes.
Por que converter Word para RTF?
Em comparação com os formatos DOC ou DOCX, o RTF oferece várias vantagens práticas:
-
Melhor compatibilidade
Os arquivos RTF podem ser abertos por quase todos os aplicativos de processamento de texto, incluindo editores mais antigos ou leves.
-
Tamanho de arquivo menor
Sem elementos complexos, os arquivos RTF costumam ser mais compactos que os documentos DOCX.
-
Estrutura mais simples
Ideal para sistemas que exigem formatação básica, mas não suportam recursos avançados do Word.
-
Formato amigável para e-mail
Muitos sistemas de e-mail e plataformas de documentos lidam com arquivos RTF de forma mais confiável do que com DOCX.
Como converter Word para RTF?
Existem várias maneiras de converter documentos do Word para RTF, desde ferramentas de desktop manuais até serviços online e processamento em lote automatizado. Abaixo estão quatro métodos comumente usados, cada um adequado para diferentes cenários.
Converter Word para RTF usando o Microsoft Word
Usar o próprio Microsoft Word é a maneira mais direta e confiável de converter documentos do Word para RTF. Quase todas as versões do Word - incluindo 2010, 2013, 2016, 2019, 2021 e Microsoft 365 - suportam a exportação de documentos para o formato RTF.
Passos:
-
Abra o arquivo DOC ou DOCX no Microsoft Word.
-
Clique em Arquivo > Salvar como.
-
Escolha uma pasta de destino.
-
No menu suspenso Salvar como tipo, selecione Formato Rich Text (*.rtf).
-
Clique em Salvar.
Prós:
- Alta precisão de formatação
- Nenhum software adicional necessário
- Simples e confiável
Contras:
- Não é adequado para processamento em lote
Ideal para:
- Conversões únicas
- Documentos que exigem alta fidelidade de formatação
Converter Word para RTF usando o LibreOffice
O LibreOffice é uma suíte de escritório gratuita e de código aberto que suporta salvar documentos do Word como RTF no Windows, macOS e Linux. É uma excelente alternativa quando o Microsoft Word não está disponível.
Passos:
-
Baixe e instale o LibreOffice do site oficial.
-
Abra o arquivo do Word no LibreOffice Writer.
-
Vá para Arquivo > Salvar como.
-
Selecione Rich Text (*.rtf) como o formato de saída.
-
Clique em Salvar.
Prós:
- Gratuito e de código aberto
- Suporte multiplataforma
- Nenhuma dependência do Microsoft Word
Contras:
- Pequenas diferenças podem aparecer em layouts complexos
- A interface pode parecer desconhecida para os usuários do Word
Ideal para:
- Usuários sem Microsoft Word
- Ambientes de código aberto ou baseados em Linux
Converter Word para RTF usando ferramentas online gratuitas
Se você prefere não instalar software de desktop ou precisa converter documentos do Word para RTF em serviços móveis, as ferramentas online são uma solução conveniente.
Conversores online populares incluem:
- Convertio - Suporta conversão em lote e importações de armazenamento em nuvem (Google Drive ou Dropbox)
- CloudConvert - Oferece vários formatos e acesso à API
- Zamzar - Permite que os arquivos convertidos sejam entregues por e-mail
Passos (usando o Convertio como exemplo):
- Abra o conversor online de Word para RTF do Convertio.
- Clique em Escolher arquivos para enviar seu arquivo do Word ou arraste-o para a área de upload.
- Selecione RTF como o formato de destino.
- Clique em Converter para iniciar o processo de conversão.
- Baixe o arquivo RTF convertido.
Prós:
- Nenhuma instalação de software necessária
- Acessível de qualquer dispositivo com um navegador
- Fácil de usar
Contras:
- Limites de tamanho de arquivo ou de uso podem ser aplicados
- Preocupações com a privacidade ao enviar documentos confidenciais
- Menos controle sobre a formatação avançada
Ideal para:
- Conversões rápidas e únicas
- Arquivos pequenos sem conteúdo sensível
Converter arquivos do Word em lote para RTF usando C#
Para conversões de documentos em grande escala ou recorrentes, os métodos manuais tornam-se ineficientes. Usando C# e a biblioteca Spire.Doc for .NET, você pode converter automaticamente em lote centenas de arquivos Word DOC/DOCX para RTF ou outros formatos de arquivo como PDF e HTML sem esforço.

Passos para converter em lote Word para RTF:
-
Preparar arquivos do Word
Coloque todos os arquivos DOC ou DOCX que você deseja converter em uma única pasta.
-
Criar um novo projeto C#
Abra o Visual Studio e crie um aplicativo de console.
-
Instalar o Spire.Doc for .NET
Instale a biblioteca via NuGet em seu projeto C# usando o seguinte comando:
Install-Package Spire.Doc -
Adicionar o código para converter em lote arquivos DOC/DOCX para RTF
O código a seguir demonstra como percorrer cada documento do Word na pasta e salvá-lo no formato RTF:
using Spire.Doc; using System; using System.IO; namespace BatchWordToRtf { class Program { static void Main() { // Caminho da pasta de entrada: onde seus arquivos do Word estão armazenados string inputFolder = @"C:\WordFiles\"; // Caminho da pasta de saída: onde os arquivos RTF convertidos serão salvos string outputFolder = @"C:\RtfFiles\"; // Percorrer todos os arquivos na pasta de entrada foreach (string file in Directory.EnumerateFiles(inputFolder)) { // Obter a extensão do arquivo e converter para minúsculas string extension = Path.GetExtension(file).ToLower(); // Processar apenas arquivos .doc e .docx if (extension == ".doc" || extension == ".docx") { // Criar um objeto Document e carregar o arquivo do Word Document doc = new Document(); doc.LoadFromFile(file); // Obter o nome do arquivo sem extensão string fileName = Path.GetFileNameWithoutExtension(file); // Salvar o arquivo como RTF na pasta de saída doc.SaveToFile(Path.Combine(outputFolder, fileName + ".rtf"), FileFormat.Rtf); } } Console.WriteLine("Conversão em lote concluída!"); } } } -
Executar o programa
Execute o programa para realizar a conversão em lote. Após a execução, os arquivos RTF serão gerados automaticamente na pasta de saída especificada no código.
Prós:
- Alta eficiência para conversões em massa
- Nenhuma instalação do Microsoft Word necessária
- Facilmente integrado em fluxos de trabalho automatizados ou ambientes de servidor
Contras:
- Requer conhecimento de programação
- Depende de bibliotecas .NET de terceiros
Ideal para:
- Empresas e desenvolvedores
- Sistemas automatizados de processamento de documentos
Artigo relacionado: C#/VB.NET: Converter RTF para Word Doc/Docx e vice-versa
Como evitar problemas de formatação durante a conversão de Word para RTF
Para minimizar problemas de formatação durante a conversão de Word para RTF, considere as seguintes práticas recomendadas:
-
Evite recursos avançados do Word
Macros, SmartArt, objetos incorporados e tabelas complexas podem não ser convertidos corretamente. Convertê-los em imagens pode ajudar a preservar sua aparência.
-
Use fontes padrão
Escolha fontes amplamente suportadas, como Arial, Times New Roman ou Calibri, para garantir uma exibição de texto consistente em diferentes plataformas.
-
Verifique a compatibilidade entre plataformas
Abra o arquivo RTF convertido em diferentes editores (por exemplo, Word e LibreOffice) para verificar a consistência do layout.
-
Teste antes do processamento em lote
Sempre valide alguns arquivos de amostra antes de executar conversões em grande escala ou automatizadas.
Conclusão
A conversão de Word para RTF é uma maneira eficaz de melhorar a compatibilidade, portabilidade e confiabilidade entre plataformas. Dependendo de suas necessidades, você pode escolher a conversão manual com o Microsoft Word ou LibreOffice, a conversão rápida com ferramentas online ou o processamento em lote automatizado usando C#.
Procurando por mais tutoriais de Word de alta qualidade? Confira nossos recursos gratuitos sobre Word.
Perguntas frequentes: Word para RTF
P1: Qual é a maneira mais fácil de converter Word para RTF?
R1: Usar o recurso "Salvar como" do Microsoft Word é o método mais simples.
P2: A conversão de Word para RTF afetará a formatação?
R2: A formatação básica é preservada, mas recursos avançados como macros ou SmartArt podem não ser totalmente suportados.
P3: Posso converter Word para RTF gratuitamente?
R3: Sim. O LibreOffice e muitos conversores online oferecem opções de conversão gratuitas.
P4: Como posso converter em lote vários arquivos do Word para RTF?
R4: Você pode usar C# com bibliotecas como o Spire.Doc para automatizar conversões em lote.
P5: O RTF é compatível entre plataformas e aplicativos?
R5: Sim. O RTF é amplamente suportado no Windows, macOS, Linux e na maioria dos processadores de texto.
P6: Posso converter Word para RTF online sem instalar software?
R6: Sim. Ferramentas online como o Convertio permitem a conversão baseada em navegador, embora possam ser aplicadas limitações de tamanho de arquivo e privacidade.