Convertire HTML in immagini: Guida completa per sviluppatori e principianti
Indice dei Contenuti
- HTML vs. Formati Immagine: Differenze Chiave e Quando la Conversione ha Senso
- Metodo 1. Salvare i File HTML in PDF e poi in Immagine
- Metodo 2. Convertire HTML in Immagine Online Usando CloudXDocs
- Metodo 3. Come Convertire HTML in Immagine in Java con Spire.Doc
- Considerazioni Finali
- Domande Frequenti

In Questo Post:
- HTML vs. Formati Immagine: Differenze Chiave e Quando la Conversione ha Senso
- Metodo 1. Salvare i File HTML in PDF e poi in Immagine
- Metodo 2. Convertire HTML in Immagine Online Usando CloudXDocs
- Metodo 3. Come Convertire HTML in Immagine in Java con Spire.Doc
- Considerazioni Finali
- Domande Frequenti
La conversione di file HTML in immagini è un requisito comune in molti scenari reali, come la generazione di anteprime, l'archiviazione di report basati sul web o l'incorporamento di contenuti in PDF. Sebbene l'HTML sia flessibile e dinamico, le differenze tra browser, caratteri e ambienti di rendering possono portare a risultati di visualizzazione incoerenti. Convertendo l'HTML in immagini statiche, è possibile preservare l'aspetto visivo originale e garantire un rendering coerente su tutte le piattaforme.
In questo articolo, esploreremo diversi modi per convertire HTML in immagini. Tratteremo un metodo basato su browser, uno strumento online come CloudXDocs e una soluzione Java che utilizza Spire.Doc. Ogni metodo serve a scenari diversi, quindi puoi scegliere quello che funziona meglio per te.
HTML vs. Formati Immagine: Differenze Chiave e Quando la Conversione ha Senso
Sebbene sia i formati HTML che quelli immagine siano ampiamente utilizzati per presentare contenuti visivi, sono progettati per obiettivi fondamentalmente diversi. Comprendere queste differenze è essenziale per scegliere il formato di output corretto nelle applicazioni del mondo reale.
Differenze Chiave tra Formati HTML e Immagine
| HTML | Immagine (PNG, JPG, ecc.) | |
|---|---|---|
| Rendering | Dipende dal browser e dal motore di rendering | Output visivo fisso |
| Layout | Responsivo e dinamico | Statico e fisso |
| Interattività | Supporta script, link e azioni dell'utente | Non interattivo |
| Coerenza Visiva | Può variare tra browser e dispositivi | Identico ovunque |
| Dipendenza a Runtime | Richiede un ambiente di rendering HTML/CSS | Autonomo |
| Stabilità dell'Output | Influenzato da CSS, caratteri e viewport | Immune ai cambiamenti ambientali |
L'HTML è adatto per visualizzare contenuti dinamici e interattivi in un browser. Tuttavia, questa flessibilità introduce anche incertezza: lo stesso HTML può essere reso in modo diverso a seconda dei motori del browser, delle dimensioni dello schermo, della disponibilità dei caratteri o delle impostazioni dell'utente. Al contrario, un'immagine rappresenta uno stato visivo finalizzato che non dipende più da condizioni di rendering esterne.
Perché Convertire HTML in Immagine
Convertire l'HTML in un'immagine non è semplicemente un cambio di formato; è un modo per "congelare" il risultato visivo dei contenuti web ed eliminare la variabilità introdotta dagli ambienti di runtime. Questo approccio diventa particolarmente prezioso in situazioni in cui la prevedibilità, la ripetibilità e la compatibilità a valle sono critiche.
Nello specifico, la conversione da HTML a immagine è la scelta giusta quando:
- È richiesta un'esatta fedeltà visiva: Quando layout, tipografia e stile devono apparire esattamente uguali per tutti gli utenti, le immagini eliminano le differenze legate al browser e al dispositivo.
- Il rendering HTML non è disponibile o indesiderabile: I servizi di backend, le pipeline di documenti o i sistemi di terze parti spesso non possono rendere l'HTML in modo affidabile, ma possono gestire facilmente i file di immagine.
- Il contenuto deve essere incorporato o riutilizzato: Le immagini possono essere inserite direttamente in PDF, documenti Word, presentazioni, email o report senza logica di rendering aggiuntiva.
- Il contenuto dinamico o stilizzato deve essere catturato come un'istantanea: Dashboard, grafici o pagine generate possono essere convertiti in immagini per preservare uno stato specifico nel tempo.
- È richiesta l'archiviazione a lungo termine o la conformità: Le immagini assicurano che il contenuto archiviato rimanga visivamente intatto anche se CSS, script o risorse esterne cambiano in futuro.
- È coinvolta l'elaborazione automatizzata o batch: La conversione lato server consente la generazione scalabile di anteprime, miniature e risorse visive senza intervento manuale.
In questi scenari, la conversione di HTML in formati di immagine come PNG o JPG fornisce un output stabile e prevedibile, rendendo più facile integrare i contenuti basati sul web in flussi di lavoro applicativi più ampi.
Metodo 1. Salvare i File HTML in PDF e poi in Immagine
Pro:
- Utilizza la funzionalità integrata del browser
- Alta precisione di rendering per HTML statico e CSS
- Funziona offline una volta installato il browser
Contro:
- Processo manuale, non adatto all'automazione
- Controllo limitato sulla risoluzione e sulle dimensioni dell'output
- Non ideale per pagine dinamiche o pesanti di JavaScript
Ideale per: conversioni una tantum, pagine HTML statiche, anteprime rapide o istantanee di documentazione e ambienti con rigide politiche di installazione del software
Se il tuo obiettivo è convertire HTML in un'immagine senza fare affidamento su Internet e solo per una conversione una tantum, una soluzione pratica è introdurre un formato di documento come passaggio intermedio. I browser moderni forniscono già funzionalità integrate per rendere l'HTML in modo accurato ed esportarlo come PDF. Salvando prima il file HTML come PDF e poi convertendo quel PDF in un'immagine, puoi ottenere risultati visivi affidabili mantenendo il flusso di lavoro semplice. Questo approccio è particolarmente adatto per pagine statiche, anteprime rapide o ambienti in cui l'installazione di software aggiuntivo non è un'opzione.
I passaggi specifici sono elencati di seguito:
Passaggio 1. Apri il file HTML in un browser moderno come Chrome o Edge. Premi Ctrl + P (o Cmd + P su macOS) per aprire la finestra di dialogo di stampa.
Passaggio 2. Seleziona "Salva come PDF" come destinazione e regola le impostazioni di layout se necessario.
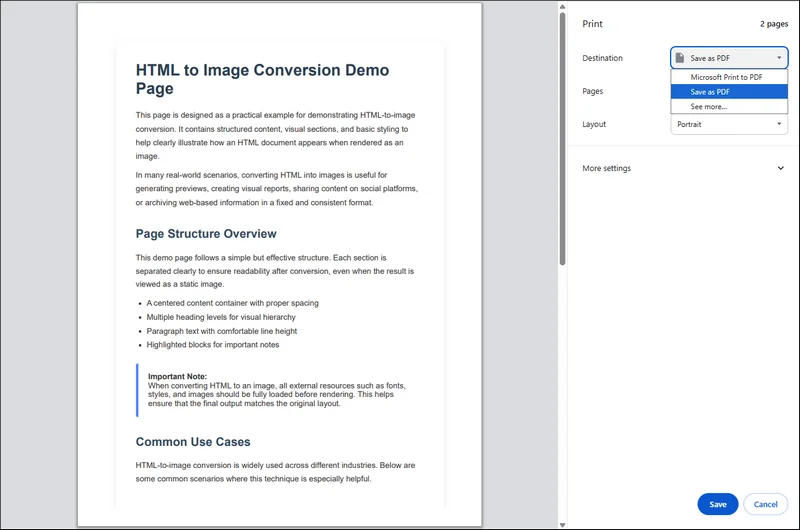
Passaggio 3. Fai clic sul pulsante "Salva" in basso per esportare il file HTML come PDF.
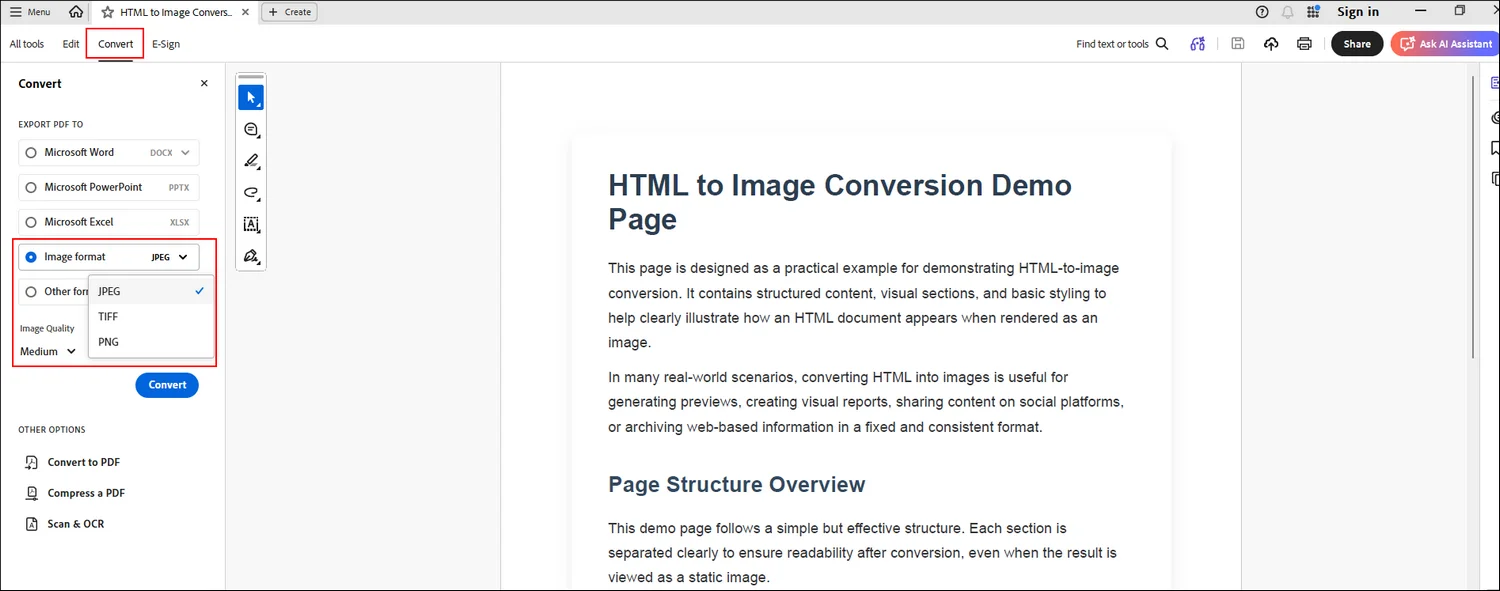
Passaggio 4. Apri il file PDF convertito con Adobe Acrobat. Vai allo strumento "Converti" per scegliere il formato immagine specifico in cui desideri convertire.
Metodo 2. Convertire HTML in Immagine Online Usando CloudXDocs
Pro:
- Nessuna codifica richiesta
- Veloce e facile da usare
- Accessibile da qualsiasi dispositivo con un browser
- Nessuna installazione locale necessaria
Contro:
- Richiede una connessione a Internet
- Non adatto per dati sensibili o confidenziali
Ideale per: utenti non tecnici, conversioni occasionali da HTML a immagine, marketing, design, attività di documentazione e test dell'output di conversione prima dell'automazione
Dopo aver esplorato l'approccio di convertire prima l'HTML in PDF e poi esportare il PDF come immagine, vale la pena notare che questo flusso di lavoro non è sempre necessario, specialmente quando non hai bisogno del pieno controllo tramite codice o quando l'attività di conversione è relativamente semplice. Per gli utenti che preferiscono una soluzione più rapida e leggera, gli strumenti online da HTML a immagine offrono un'alternativa pratica.
Il Convertitore Online da HTML a Immagine di CloudXDocs fornisce una soluzione basata su browser che ti consente di caricare file HTML e convertirli direttamente in formati immagine con pochi clic. Ciò lo rende particolarmente utile per gli utenti non tecnici, così come per gli sviluppatori che desiderano visualizzare in anteprima o convalidare rapidamente i risultati della conversione prima di implementare un flusso di lavoro automatizzato.
Passaggi specifici per utilizzare il Convertitore da HTML a Immagine di CloudXDocs:
Passaggio 1. Vai prima al sito web ufficiale del Convertitore Online da HTML a Immagine di CloudxDocs. Puoi trascinare o fare clic dall'interfaccia principale per caricare il file HTML originale.
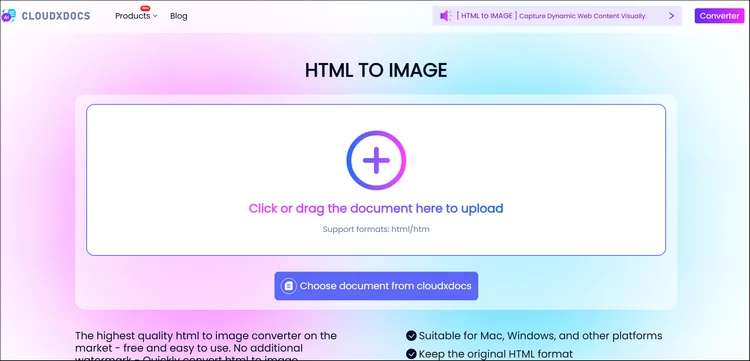
Passaggio 2. Attendi qualche secondo mentre CloudXDocs analizza automaticamente il file HTML caricato e avvia il processo di conversione.
Passaggio 3. Dopo la conversione, puoi scaricare il file compresso che include i file immagine convertiti dalla pagina dei risultati. Scaricalo e decomprimilo per salvare tutte le immagini sul tuo computer locale.
Metodo 3. Come Convertire HTML in Immagine in Java con Spire.Doc
Pro:
- Completamente automatizzato e scalabile
- Alta precisione per layout complessi
- Nessuna dipendenza da Microsoft Word
- Adatto per l'uso lato server e aziendale
Contro:
- Richiede esperienza di sviluppo Java
- Necessita di integrazione e configurazione della libreria
- Licenza richiesta per l'uso in produzione
Ideale per: sviluppatori, applicazioni di backend o lato server, conversioni batch o su larga scala da HTML a immagine e sistemi di elaborazione di documenti aziendali
Sebbene gli strumenti online siano convenienti per conversioni rapide o occasionali, potrebbero non essere la scelta migliore quando hai bisogno di automazione, scalabilità o pieno controllo sul processo di conversione. Negli ambienti di produzione o nei flussi di lavoro di backend, gli sviluppatori richiedono spesso una soluzione programmatica che possa essere integrata direttamente nelle applicazioni Java.
In tali casi, utilizzare il codice Java per convertire HTML in immagini diventa un approccio più affidabile e flessibile. Spire.Doc for Java fornisce una potente API che consente di caricare contenuti HTML, convertirli in documenti ed esportare il risultato come immagini ad alta fedeltà. Questo metodo è particolarmente adatto per gli sviluppatori che necessitano di elaborazione batch, output coerente o integrazione perfetta nei sistemi esistenti senza fare affidamento su servizi esterni.
Perché Scegliere Spire.Doc?
Spire.Doc è una libreria di elaborazione di documenti che supporta l'importazione di HTML e l'esportazione di immagini senza richiedere Microsoft Word o dipendenze di terze parti. È adatto per ambienti lato server e applicazioni aziendali.
I vantaggi principali includono:
- Supporto per contenuti HTML complessi
- Layout e formattazione accurati
- Formati di immagine di output multipli
- API semplice e intuitiva
Per scenari che richiedono automazione e alta precisione di conversione, Spire.Doc offre una soluzione robusta per convertire contenuti HTML in immagini. Come libreria professionale di elaborazione di documenti, Spire.Doc supporta l'importazione di HTML e l'esportazione in vari formati di immagine senza fare affidamento su applicazioni esterne.
Per Convertire HTML in immagini con Spire.Doc for Java:
Passaggio 1. Installa Spire.Doc for Java
Innanzitutto, aggiungi il file Spire.Doc.jar come dipendenza nel tuo programma Java. Puoi scaricare il file .jar dal link di download ufficiale.
Se stai usando Maven, puoi aggiungere il seguente codice al file pom.xml del tuo progetto per aggiungere facilmente la dipendenza:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.7.0</version>
</dependency>
</dependencies>
Usa il seguente codice di esempio per convertire HTML in immagine:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.ImageType;
import com.spire.doc.documents.XHTMLValidationType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertHtmlToImage {
public static void main(String[] args) throws IOException {
// Create a Document object
Document document = new Document();
// Load an HTML file
document.loadFromFile("src\\main\\resources\\sample.html", FileFormat.Html, XHTMLValidationType.None);
// Get the first section
Section section = document.getSections().get(0);
// Set the page margins
section.getPageSetup().getMargins().setAll(2);
// Convert the document to an array of BufferedImage
BufferedImage[] images = document.saveToImages(ImageType.Bitmap);
// Iterate through the images
for (int index = 0; index < images.length; index++)
{
// Specify the output file name
String fileName = String.format("output\\sample-html-to-image_%d.png", index);
// Save each image as a PNG file
File file= new File(fileName);
ImageIO.write(images[index], "PNG", file);
}
// Dispose resources
document.dispose();
}
}
RISULTATO:
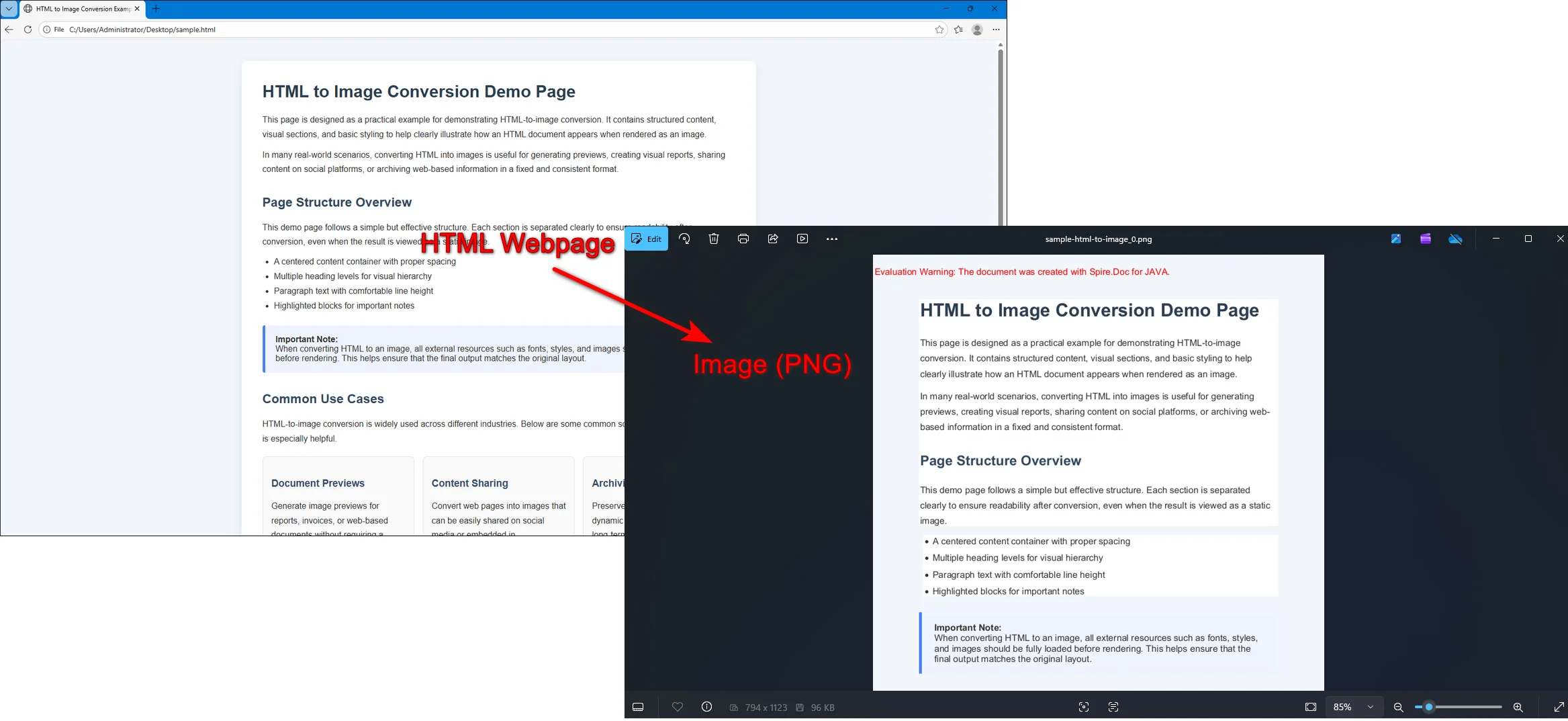
Internamente, Spire.Doc converte l'HTML in un modello di documento Word prima di renderlo in immagini. Ciò consente agli sviluppatori di regolare le impostazioni della pagina come margini, dimensioni della carta e layout prima dell'esportazione, garantendo un migliore controllo sull'output dell'immagine finale.
Considerazioni Finali
La conversione di HTML in immagini garantisce un output visivo coerente, riduce la variabilità del rendering e rende i contenuti più facili da condividere, archiviare o incorporare su diverse piattaforme e documenti. Trasformando le pagine web dinamiche in immagini statiche, è possibile preservare l'esatto layout, lo stile e la tipografia senza preoccuparsi delle differenze tra i browser o delle risorse mancanti.
- Per attività rapide e una tantum, salvare l'HTML come PDF e poi esportarlo in un'immagine funziona bene.
- Per conversioni veloci e senza codice, CloudXDocs fornisce una comoda soluzione online.
- Per flussi di lavoro automatizzati e scalabili, Spire.Doc for Java offre un controllo preciso e risultati affidabili.
Considera il tuo flusso di lavoro, i requisiti tecnici e la qualità di output desiderata per scegliere il metodo che meglio si adatta alle tue esigenze, assicurando che il tuo contenuto HTML sia preservato esattamente come previsto e appaia coerente ovunque venga utilizzato.
Domande Frequenti:
D1. La conversione da HTML a immagine è gratuita?
R: Sì, la conversione da HTML a immagine può essere gratuita, a seconda dello strumento che utilizzi. Molti convertitori online e librerie open source offrono opzioni gratuite per un uso di base o occasionale.
D2. Quali formati di immagine sono supportati durante la conversione di HTML?
R: I formati comuni includono PNG, JPG e BMP. Il PNG è generalmente preferito per immagini di alta qualità e senza perdita, mentre il JPG può essere utilizzato per file di dimensioni inferiori.
D3. L'immagine convertita sarà esattamente come la pagina HTML originale?
R: Per l'HTML statico con CSS standard, le immagini di solito preservano accuratamente il layout e lo stile. Tuttavia, contenuti dinamici, animazioni o script potrebbero non apparire nell'immagine convertita a meno che non vengano catturati al momento giusto.
Leggi Anche:
Convertir HTML en images : Guide complet pour développeurs et débutants
Table des matières
Dans cet article :
- HTML vs formats d'image : principales différences et quand la conversion est judicieuse
- Méthode 1. Enregistrer les fichiers HTML en PDF puis en image
- Méthode 2. Convertir HTML en image en ligne avec CloudXDocs
- Méthode 3. Comment convertir HTML en image en Java avec Spire.Doc
- Réflexions finales
- FAQ
La conversion de fichiers HTML en images est une exigence courante dans de nombreux scénarios réels, tels que la génération d'aperçus, l'archivage de rapports Web ou l'intégration de contenu dans des PDF. Bien que le HTML soit flexible et dynamique, les différences entre les navigateurs, les polices et les environnements de rendu peuvent entraîner des résultats d'affichage incohérents. En convertissant le HTML en images statiques, vous pouvez préserver l'apparence visuelle d'origine et garantir un rendu cohérent sur toutes les plateformes.
Dans cet article, nous explorerons plusieurs façons de convertir du HTML en images. Nous couvrirons une méthode basée sur le navigateur, un outil en ligne comme CloudXDocs et une solution Java utilisant Spire.Doc. Chaque méthode sert des scénarios différents, vous pouvez donc choisir celle qui vous convient le mieux.
HTML vs formats d'image : principales différences et quand la conversion est judicieuse
Bien que les formats HTML et image soient largement utilisés pour présenter du contenu visuel, ils sont conçus pour des objectifs fondamentalement différents. Comprendre ces différences est essentiel pour choisir le format de sortie correct dans les applications du monde réel.
Principales différences entre les formats HTML et image
| HTML | Image (PNG, JPG, etc.) | |
|---|---|---|
| Rendu | Dépend du navigateur et du moteur de rendu | Sortie visuelle fixe |
| Mise en page | Réactif et dynamique | Statique et fixe |
| Interactivité | Prend en charge les scripts, les liens et les actions de l'utilisateur | Non interactif |
| Cohérence visuelle | Peut varier selon les navigateurs et les appareils | Identique partout |
| Dépendance d'exécution | Nécessite un environnement de rendu HTML/CSS | Autonome |
| Stabilité de la sortie | Affecté par le CSS, les polices et la fenêtre d'affichage | Insensible aux changements environnementaux |
Le HTML est bien adapté à l'affichage de contenu dynamique et interactif dans un navigateur. Cependant, cette flexibilité introduit également une incertitude : le même HTML peut s'afficher différemment en fonction des moteurs de navigateur, de la taille des écrans, de la disponibilité des polices ou des paramètres de l'utilisateur. En revanche, une image représente un état visuel finalisé qui ne dépend plus des conditions de rendu externes.
Pourquoi convertir du HTML en image
La conversion de HTML en image n'est pas simplement un changement de format ; c'est un moyen de figer le résultat visuel du contenu Web et d'éliminer la variabilité introduite par les environnements d'exécution. Cette approche devient particulièrement précieuse dans les situations où la prévisibilité, la répétabilité et la compatibilité en aval sont essentielles.
Plus précisément, la conversion HTML en image est le bon choix lorsque :
- Une fidélité visuelle exacte est requise : lorsque la mise en page, la typographie et le style doivent apparaître exactement de la même manière pour tous les utilisateurs, les images suppriment les différences liées au navigateur et à l'appareil.
- Le rendu HTML n'est pas disponible ou n'est pas souhaitable : les services backend, les pipelines de documents ou les systèmes tiers ne peuvent souvent pas rendre le HTML de manière fiable, mais peuvent facilement gérer les fichiers image.
- Le contenu doit être intégré ou réutilisé : les images peuvent être directement insérées dans des PDF, des documents Word, des présentations, des e-mails ou des rapports sans logique de rendu supplémentaire.
- Le contenu dynamique ou stylisé doit être capturé sous forme d'instantané : les tableaux de bord, les graphiques ou les pages générées peuvent être convertis en images pour préserver un état spécifique dans le temps.
- Un stockage à long terme ou une conformité est requis : les images garantissent que le contenu archivé reste visuellement intact même si le CSS, les scripts ou les ressources externes changent à l'avenir.
- Un traitement automatisé ou par lots est impliqué : la conversion côté serveur permet la génération évolutive d'aperçus, de vignettes et d'actifs visuels sans intervention manuelle.
Dans ces scénarios, la conversion de HTML en formats d'image tels que PNG ou JPG fournit une sortie stable et prévisible, ce qui facilite l'intégration de contenu Web dans des flux de travail d'application plus larges.
Méthode 1. Enregistrer les fichiers HTML en PDF puis en image
Avantages :
- Utilise la fonctionnalité intégrée du navigateur
- Haute précision de rendu pour le HTML et le CSS statiques
- Fonctionne hors ligne une fois le navigateur installé
Inconvénients :
- Processus manuel, ne convient pas à l'automatisation
- Contrôle limité sur la résolution et la taille de sortie
- Pas idéal pour les pages dynamiques ou riches en JavaScript
Idéal pour : les conversions uniques, les pages HTML statiques, les aperçus rapides ou les instantanés de documentation, et les environnements avec des politiques d'installation de logiciels strictes
Si votre objectif est de convertir du HTML en image sans dépendre d'Internet et pour une conversion unique uniquement, une solution de contournement pratique consiste à introduire un format de document comme étape intermédiaire. Les navigateurs modernes offrent déjà des fonctionnalités intégrées pour rendre le HTML avec précision et l'exporter au format PDF. En enregistrant d'abord le fichier HTML au format PDF, puis en convertissant ce PDF en image, vous pouvez obtenir des résultats visuels fiables tout en gardant le flux de travail simple. Cette approche est particulièrement adaptée aux pages statiques, aux aperçus rapides ou aux environnements où l'installation de logiciels supplémentaires n'est pas une option.
Les étapes spécifiques sont répertoriées ci-dessous :
Étape 1. Ouvrez le fichier HTML dans un navigateur moderne tel que Chrome ou Edge. Appuyez sur Ctrl + P (ou Cmd + P sur macOS) pour ouvrir la boîte de dialogue d'impression.
Étape 2. Sélectionnez "Enregistrer au format PDF" comme destination et ajustez les paramètres de mise en page si nécessaire.
Étape 3. Cliquez sur le bouton "Enregistrer" ci-dessous pour exporter le fichier HTML au format PDF.
Étape 4. Ouvrez le fichier PDF converti avec Adobe Acrobat. Allez dans l'outil "Convertir" pour choisir le format d'image spécifique avec lequel vous souhaitez convertir.
Méthode 2. Convertir HTML en image en ligne avec CloudXDocs
Avantages :
- Aucun codage requis
- Rapide et facile à utiliser
- Accessible depuis n'importe quel appareil avec un navigateur
- Aucune installation locale requise
Inconvénients :
- Nécessite une connexion Internet
- Ne convient pas aux données sensibles ou confidentielles
Idéal pour : les utilisateurs non techniques, les conversions occasionnelles de HTML en image, les tâches de marketing, de conception, de documentation et le test de la sortie de conversion avant l'automatisation
Après avoir exploré l'approche consistant à convertir d'abord le HTML en PDF, puis à exporter le PDF en tant qu'image, il convient de noter que ce flux de travail n'est pas toujours nécessaire, en particulier lorsque vous n'avez pas besoin d'un contrôle total via le code ou lorsque la tâche de conversion est relativement simple. Pour les utilisateurs qui préfèrent une solution plus rapide et plus légère, les outils de conversion HTML en image en ligne offrent une alternative pratique.
Le convertisseur en ligne de HTML en image CloudXDocs fournit une solution basée sur un navigateur qui vous permet de télécharger des fichiers HTML et de les convertir directement en formats d'image en quelques clics. Cela le rend particulièrement utile pour les utilisateurs non techniques, ainsi que pour les développeurs qui souhaitent prévisualiser ou valider rapidement les résultats de la conversion avant de mettre en œuvre un flux de travail automatisé.
Étapes spécifiques pour utiliser le convertisseur HTML en image CloudXDocs :
Étape 1. Rendez-vous d'abord sur le site officiel du convertisseur en ligne de HTML en image CloudxDocs. Vous pouvez faire glisser ou cliquer depuis l'interface principale pour télécharger le fichier HTML d'origine.
Étape 2. Attendez quelques secondes pendant que CloudXDocs analyse automatiquement le fichier HTML téléchargé et commence le processus de conversion.
Étape 3. Après la conversion, vous pouvez télécharger le fichier zippé qui comprend les fichiers image convertis à partir de la page de résultats. Téléchargez-le et décompressez-le pour enregistrer toutes les images sur votre ordinateur local.
Méthode 3. Comment convertir HTML en image en Java avec Spire.Doc
Avantages :
- Entièrement automatisé et évolutif
- Haute précision pour les mises en page complexes
- Aucune dépendance à Microsoft Word
- Convient pour une utilisation côté serveur et en entreprise
Inconvénients :
- Nécessite une expérience de développement Java
- Nécessite l'intégration et la configuration de la bibliothèque
- Licence requise pour une utilisation en production
Idéal pour : les développeurs, les applications backend ou côté serveur, les conversions par lots ou à grande échelle de HTML en image et les systèmes de traitement de documents d'entreprise
Bien que les outils en ligne soient pratiques pour les conversions rapides ou occasionnelles, ils peuvent ne pas être le meilleur choix lorsque vous avez besoin d'automatisation, d'évolutivité ou d'un contrôle total sur le processus de conversion. Dans les environnements de production ou les flux de travail backend, les développeurs ont souvent besoin d'une solution programmatique pouvant être intégrée directement dans les applications Java.
Dans de tels cas, l'utilisation de code Java pour convertir du HTML en images devient une approche plus fiable et flexible. Spire.Doc pour Java fournit une API puissante qui vous permet de charger du contenu HTML, de le convertir en documents et d'exporter le résultat sous forme d'images avec une haute fidélité. Cette méthode est particulièrement adaptée aux développeurs qui ont besoin d'un traitement par lots, d'une sortie cohérente ou d'une intégration transparente dans les systèmes existants sans dépendre de services externes.
Pourquoi choisir Spire.Doc ?
Spire.Doc est une bibliothèque de traitement de documents qui prend en charge l'importation HTML et l'exportation d'images sans nécessiter Microsoft Word ou toute autre dépendance tierce. Il est bien adapté aux environnements côté serveur et aux applications d'entreprise.
Les principaux avantages incluent :
- Prise en charge du contenu HTML complexe
- Mise en page et formatage précis
- Plusieurs formats d'image de sortie
- API simple et intuitive
Pour les scénarios qui nécessitent une automatisation et une grande précision de conversion, Spire.Doc offre une solution robuste pour convertir le contenu HTML en images. En tant que bibliothèque de traitement de documents professionnelle, Spire.Doc prend en charge l'importation de HTML et son exportation vers divers formats d'image sans dépendre d'applications externes.
Pour convertir du HTML en images avec Spire.Doc pour Java :
Étape 1. Installer Spire.Doc pour Java
Tout d'abord, ajoutez le fichier Spire.Doc.jar comme dépendance dans votre programme Java. Vous pouvez télécharger le fichier .jar à partir du lien de téléchargement officiel.
Si vous utilisez Maven, vous pouvez ajouter le code suivant au fichier pom.xml de votre projet pour ajouter facilement la dépendance :
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.7.0</version>
</dependency>
</dependencies>
Utilisez l'exemple de code suivant pour convertir du HTML en image :
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.ImageType;
import com.spire.doc.documents.XHTMLValidationType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertHtmlToImage {
public static void main(String[] args) throws IOException {
// Create a Document object
Document document = new Document();
// Load an HTML file
document.loadFromFile("src\\main\\resources\\sample.html", FileFormat.Html, XHTMLValidationType.None);
// Get the first section
Section section = document.getSections().get(0);
// Set the page margins
section.getPageSetup().getMargins().setAll(2);
// Convert the document to an array of BufferedImage
BufferedImage[] images = document.saveToImages(ImageType.Bitmap);
// Iterate through the images
for (int index = 0; index < images.length; index++)
{
// Specify the output file name
String fileName = String.format("output\\sample-html-to-image_%d.png", index);
// Save each image as a PNG file
File file= new File(fileName);
ImageIO.write(images[index], "PNG", file);
}
// Dispose resources
document.dispose();
}
}
RÉSULTAT :
En interne, Spire.Doc convertit le HTML en un modèle de document Word avant de le rendre en images. Cela permet aux développeurs d'ajuster les paramètres de la page tels que les marges, la taille du papier et la mise en page avant l'exportation, garantissant un meilleur contrôle sur la sortie d'image finale.
Réflexions finales
La conversion de HTML en images garantit une sortie visuelle cohérente, réduit la variabilité du rendu et facilite le partage, le stockage ou l'intégration de contenu sur différentes plateformes et documents. En transformant des pages Web dynamiques en images statiques, vous can préserver la mise en page, le style et la typographie exacts sans vous soucier des différences de navigateur ou des ressources manquantes.
- Pour les tâches rapides et uniques, l'enregistrement de HTML au format PDF, puis l'exportation vers une image fonctionne bien.
- Pour des conversions rapides et sans code, CloudXDocs fournit une solution en ligne pratique.
- Pour les flux de travail automatisés et évolutifs, Spire.Doc pour Java offre un contrôle précis et des résultats fiables.
Tenez compte de votre flux de travail, de vos exigences techniques et de la qualité de sortie souhaitée pour choisir la méthode qui correspond le mieux à vos besoins, en vous assurant que votre contenu HTML est préservé exactement comme prévu et qu'il a un aspect cohérent où qu'il soit utilisé.
FAQ :
Q1. La conversion de HTML en image est-elle gratuite ?
R : Oui, la conversion de HTML en image peut être gratuite, selon l'outil que vous utilisez. De nombreux convertisseurs en ligne et bibliothèques open source offrent des options gratuites pour une utilisation de base ou occasionnelle.
Q2. Quels formats d'image sont pris en charge lors de la conversion de HTML ?
R : Les formats courants incluent PNG, JPG et BMP. Le PNG est généralement préféré pour les images de haute qualité sans perte, tandis que le JPG peut être utilisé pour des fichiers de plus petite taille.
Q3. L'image convertie ressemblera-t-elle exactement à la page HTML d'origine ?
R : Pour le HTML statique avec CSS standard, les images préservent généralement la mise en page et le style avec précision. Cependant, le contenu dynamique, les animations ou les scripts peuvent ne pas apparaître dans l'image convertie à moins d'être capturés au bon moment.
À lire également :
Convertir HTML a imágenes: Guía completa para desarrolladores y principiantes
Tabla de Contenidos
- HTML vs. Formatos de Imagen: Diferencias Clave y Cuándo Tiene Sentido la Conversión
- Método 1. Guardar Archivos HTML a PDF y Luego a Imagen
- Método 2. Convertir HTML a Imagen en Línea Usando CloudXDocs
- Método 3. Cómo Convertir HTML a Imagen en Java con Spire.Doc
- Conclusiones Finales
- Preguntas Frecuentes
En Esta Publicación:
- HTML vs. Formatos de Imagen: Diferencias Clave y Cuándo Tiene Sentido la Conversión
- Método 1. Guardar Archivos HTML a PDF y Luego a Imagen
- Método 2. Convertir HTML a Imagen en Línea Usando CloudXDocs
- Método 3. Cómo Convertir HTML a Imagen en Java con Spire.Doc
- Conclusiones Finales
- Preguntas Frecuentes
Convertir archivos HTML en imágenes es un requisito común en muchos escenarios del mundo real, como generar vistas previas, archivar informes basados en la web o incrustar contenido en archivos PDF. Aunque el HTML es flexible y dinámico, las diferencias en los navegadores, las fuentes y los entornos de renderizado pueden dar lugar a resultados de visualización incoherentes. Al convertir HTML en imágenes estáticas, puede preservar la apariencia visual original y garantizar una renderización coherente en todas las plataformas.
En este artículo, exploraremos varias formas de convertir HTML a imágenes. Cubriremos un método basado en el navegador, una herramienta en línea como CloudXDocs y una solución en Java usando Spire.Doc. Cada método sirve para diferentes escenarios, por lo que puede elegir el que mejor se adapte a sus necesidades.
HTML vs. Formatos de Imagen: Diferencias Clave y Cuándo Tiene Sentido la Conversión
Aunque tanto los formatos HTML como los de imagen se utilizan ampliamente para presentar contenido visual, están diseñados para objetivos fundamentalmente diferentes. Comprender estas diferencias es esencial para elegir el formato de salida correcto en aplicaciones del mundo real.
Diferencias Clave Entre los Formatos HTML y de Imagen
| HTML | Imagen (PNG, JPG, etc.) | |
|---|---|---|
| Renderizado | Depende del navegador y del motor de renderizado | Salida visual fija |
| Diseño | Adaptable y dinámico | Estático y fijo |
| Interactividad | Admite scripts, enlaces y acciones del usuario | No interactivo |
| Consistencia Visual | Puede variar entre navegadores y dispositivos | Idéntico en todas partes |
| Dependencia en Tiempo de Ejecución | Requiere un entorno de renderizado HTML/CSS | Autónomo |
| Estabilidad de la Salida | Afectado por CSS, fuentes y viewport | Inmune a los cambios del entorno |
El HTML es muy adecuado para mostrar contenido dinámico e interactivo en un navegador. Sin embargo, esta flexibilidad también introduce incertidumbre: el mismo HTML puede renderizarse de manera diferente dependiendo de los motores del navegador, los tamaños de pantalla, la disponibilidad de fuentes o la configuración del usuario. En contraste, una imagen representa un estado visual finalizado que ya no depende de las condiciones de renderizado externas.
Por Qué Convertir HTML a Imagen
Convertir HTML a una imagen no es simplemente un cambio de formato; es una forma de congelar el resultado visual del contenido web y eliminar la variabilidad introducida por los entornos de ejecución. Este enfoque se vuelve especialmente valioso en situaciones donde la previsibilidad, la repetibilidad y la compatibilidad descendente son críticas.
Específicamente, la conversión de HTML a imagen es la elección correcta cuando:
- Se requiere una fidelidad visual exacta: cuando el diseño, la tipografía y el estilo deben aparecer exactamente iguales para todos los usuarios, las imágenes eliminan las diferencias relacionadas con el navegador y el dispositivo.
- El renderizado de HTML no está disponible o no es deseable: los servicios de backend, las canalizaciones de documentos o los sistemas de terceros a menudo no pueden renderizar HTML de manera fiable, pero pueden manejar fácilmente archivos de imagen.
- El contenido necesita ser incrustado o reutilizado: las imágenes se pueden insertar directamente en archivos PDF, documentos de Word, presentaciones, correos electrónicos o informes sin lógica de renderizado adicional.
- El contenido dinámico o con estilo debe capturarse como una instantánea: los paneles, gráficos o páginas generadas se pueden convertir en imágenes para preservar un estado específico en el tiempo.
- Se requiere almacenamiento a largo plazo o cumplimiento: las imágenes garantizan que el contenido archivado permanezca visualmente intacto incluso si CSS, scripts o recursos externos cambian en el futuro.
- Se involucra el procesamiento automatizado o por lotes: la conversión del lado del servidor permite la generación escalable de vistas previas, miniaturas y activos visuales sin intervención manual.
En estos escenarios, convertir HTML a formatos de imagen como PNG o JPG proporciona una salida estable y predecible, lo que facilita la integración de contenido basado en la web en flujos de trabajo de aplicaciones más amplios.
Método 1. Guardar Archivos HTML a PDF y Luego a Imagen
Pros:
- Utiliza la funcionalidad integrada del navegador
- Alta precisión de renderizado para HTML estático y CSS
- Funciona sin conexión una vez que el navegador está instalado
Contras:
- Proceso manual, no apto para la automatización
- Control limitado sobre la resolución y el tamaño de salida
- No es ideal para páginas dinámicas o con mucho JavaScript
Ideal para: conversiones únicas, páginas HTML estáticas, vistas previas rápidas o instantáneas de documentación, y entornos con políticas estrictas de instalación de software
Si su objetivo es convertir HTML a una imagen sin depender de Internet y solo para una conversión única, una solución práctica es introducir un formato de documento como paso intermedio. Los navegadores modernos ya proporcionan capacidades integradas para renderizar HTML con precisión y exportarlo como PDF. Al guardar primero el archivo HTML como PDF y luego convertir ese PDF en una imagen, puede lograr resultados visuales fiables manteniendo el flujo de trabajo simple. Este enfoque es especialmente adecuado para páginas estáticas, vistas previas rápidas o entornos donde no es una opción instalar software adicional.
Los pasos específicos se enumeran a continuación:
Paso 1. Abra el archivo HTML en un navegador moderno como Chrome o Edge. Presione Ctrl + P (o Cmd + P en macOS) para abrir el diálogo de impresión.
Paso 2. Seleccione "Guardar como PDF" como destino y ajuste la configuración de diseño si es necesario.
Paso 3. Haga clic en el botón "Guardar" a continuación para exportar el archivo HTML como PDF.
Paso 4. Abra el archivo PDF convertido con Adobe Acrobat. Vaya a la herramienta "Convertir" para elegir el formato de imagen específico al que desea convertir.
Método 2. Convertir HTML a Imagen en Línea Usando CloudXDocs
Pros:
- No se requiere codificación
- Rápido y fácil de usar
- Accesible desde cualquier dispositivo con un navegador
- No se necesita instalación local
Contras:
- Requiere una conexión a internet
- No apto para datos sensibles o confidenciales
Ideal para: usuarios no técnicos, conversiones ocasionales de HTML a imagen, tareas de marketing, diseño, documentación y prueba de la salida de conversión antes de la automatización
Después de explorar el enfoque de convertir primero HTML a PDF y luego exportar el PDF como una imagen, vale la pena señalar que este flujo de trabajo no siempre es necesario, especialmente cuando no necesita un control total a través del código o cuando la tarea de conversión es relativamente simple. Para los usuarios que prefieren una solución más rápida y ligera, las herramientas en línea de HTML a imagen ofrecen una alternativa práctica.
El Convertidor de HTML a Imagen en Línea de CloudXDocs proporciona una solución basada en el navegador que le permite cargar archivos HTML y convertirlos directamente en formatos de imagen con solo unos pocos clics. Esto lo hace particularmente útil para usuarios no técnicos, así como para desarrolladores que desean previsualizar o validar rápidamente los resultados de la conversión antes de implementar un flujo de trabajo automatizado.
Pasos específicos para usar el Convertidor de HTML a Imagen de CloudXDocs:
Paso 1. Vaya primero al sitio web oficial del Convertidor de HTML a Imagen en Línea de CloudxDocs. Puede arrastrar o hacer clic desde la interfaz principal para cargar el archivo HTML original.
Paso 2. Espere unos segundos mientras CloudXDocs analiza automáticamente el archivo HTML cargado y comienza el proceso de conversión.
Paso 3. Después de la conversión, puede descargar el archivo comprimido que incluye los archivos de imagen convertidos desde la página de resultados. Descárguelo y descomprímalo para guardar todas las imágenes en su computadora local.
Método 3. Cómo Convertir HTML a Imagen en Java con Spire.Doc
Pros:
- Totalmente automatizado y escalable
- Alta precisión para diseños complejos
- Sin dependencia de Microsoft Word
- Adecuado para uso en el lado del servidor y empresarial
Contras:
- Requiere experiencia en desarrollo de Java
- Necesita integración y configuración de la biblioteca
- Se requiere licencia para uso en producción
Ideal para: desarrolladores, aplicaciones de backend o del lado del servidor, conversiones de HTML a imagen por lotes o a gran escala, y sistemas de procesamiento de documentos empresariales
Si bien las herramientas en línea son convenientes para conversiones rápidas u ocasionales, es posible que no sean la mejor opción cuando necesita automatización, escalabilidad o control total sobre el proceso de conversión. En entornos de producción o flujos de trabajo de backend, los desarrolladores a menudo requieren una solución programática que se pueda integrar directamente en las aplicaciones de Java.
En tales casos, usar código Java para convertir HTML a imágenes se convierte en un enfoque más fiable y flexible. Spire.Doc para Java proporciona una potente API que le permite cargar contenido HTML, convertirlo en documentos y exportar el resultado como imágenes con alta fidelidad. Este método es especialmente adecuado para desarrolladores que necesitan procesamiento por lotes, resultados consistentes o una integración perfecta en los sistemas existentes sin depender de servicios externos.
¿Por Qué Elegir Spire.Doc?
Spire.Doc es una biblioteca de procesamiento de documentos que admite la importación de HTML y la exportación de imágenes sin requerir Microsoft Word ni ninguna dependencia de terceros. Es muy adecuado para entornos del lado del servidor y aplicaciones empresariales.
Las ventajas clave incluyen:
- Soporte para contenido HTML complejo
- Diseño y formato precisos
- Múltiples formatos de imagen de salida
- API simple e intuitiva
Para escenarios que requieren automatización y alta precisión de conversión, Spire.Doc ofrece una solución robusta para convertir contenido HTML en imágenes. Como biblioteca profesional de procesamiento de documentos, Spire.Doc admite la importación de HTML y su exportación a varios formatos de imagen sin depender de aplicaciones externas.
Para Convertir HTML a imágenes con Spire.Doc para Java:
Paso 1. Instale Spire.Doc para Java
Primero, agregue el archivo Spire.Doc.jar como una dependencia en su programa Java. Puede descargar el archivo .jar desde el enlace de descarga oficial.
Si está utilizando Maven, puede agregar el siguiente código al archivo pom.xml de su proyecto para agregar la dependencia fácilmente:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.7.0</version>
</dependency>
</dependencies>
Use el siguiente código de muestra para convertir HTML a imagen:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.ImageType;
import com.spire.doc.documents.XHTMLValidationType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertHtmlToImage {
public static void main(String[] args) throws IOException {
// Create a Document object
Document document = new Document();
// Load an HTML file
document.loadFromFile("src\\main\\resources\\sample.html", FileFormat.Html, XHTMLValidationType.None);
// Get the first section
Section section = document.getSections().get(0);
// Set the page margins
section.getPageSetup().getMargins().setAll(2);
// Convert the document to an array of BufferedImage
BufferedImage[] images = document.saveToImages(ImageType.Bitmap);
// Iterate through the images
for (int index = 0; index < images.length; index++)
{
// Specify the output file name
String fileName = String.format("output\\sample-html-to-image_%d.png", index);
// Save each image as a PNG file
File file= new File(fileName);
ImageIO.write(images[index], "PNG", file);
}
// Dispose resources
document.dispose();
}
}
RESULTADO:
Internamente, Spire.Doc convierte HTML en un modelo de documento de Word antes de renderizarlo en imágenes. Esto permite a los desarrolladores ajustar la configuración de la página, como los márgenes, el tamaño del papel y el diseño antes de exportar, lo que garantiza un mejor control sobre la salida de la imagen final.
Conclusiones Finales
Convertir HTML a imágenes garantiza una salida visual consistente, reduce la variabilidad del renderizado, y facilita compartir, almacenar o incrustar contenido en diferentes plataformas y documentos. Al convertir páginas web dinámicas en imágenes estáticas, puede preservar el diseño, el estilo y la tipografía exactos sin preocuparse por las diferencias del navegador o los recursos faltantes.
- Para tareas rápidas y únicas, guardar HTML como PDF y luego exportarlo a una imagen funciona bien.
- Para conversiones rápidas y sin código, CloudXDocs proporciona una solución en línea conveniente.
- Para flujos de trabajo automatizados y escalables, Spire.Doc para Java ofrece un control preciso y resultados fiables.
Considere su flujo de trabajo, los requisitos técnicos y la calidad de salida deseada para elegir el método que mejor se adapte a sus necesidades, asegurando que su contenido HTML se conserve exactamente como se pretende y se vea consistente donde sea que se use.
Preguntas Frecuentes:
P1. ¿La conversión de HTML a imagen es gratuita?
R: Sí, la conversión de HTML a imagen puede ser gratuita, dependiendo de la herramienta que utilice. Muchos convertidores en línea y bibliotecas de código abierto ofrecen opciones gratuitas para uso básico u ocasional.
P2. ¿Qué formatos de imagen se admiten al convertir HTML?
R: Los formatos comunes incluyen PNG, JPG y BMP. Generalmente se prefiere PNG para imágenes de alta calidad sin pérdidas, mientras que JPG se puede usar para tamaños de archivo más pequeños.
P3. ¿La imagen convertida se verá exactamente como la página HTML original?
R: Para HTML estático con CSS estándar, las imágenes suelen conservar el diseño y el estilo con precisión. Sin embargo, el contenido dinámico, las animaciones o los scripts pueden no aparecer en la imagen convertida a menos que se capturen en el momento adecuado.
Lea También:
HTML in Bilder umwandeln: Der komplette Leitfaden für Entwickler & Anfänger
Inhaltsverzeichnis
- HTML vs. Bildformate: Hauptunterschiede und wann eine Konvertierung sinnvoll ist
- Methode 1. HTML-Dateien als PDF und dann als Bild speichern
- Methode 2. HTML online mit CloudXDocs in ein Bild konvertieren
- Methode 3. Wie man HTML in Java mit Spire.Doc in ein Bild konvertiert
- Abschließende Gedanken
- Häufig gestellte Fragen
In diesem Beitrag:
- HTML vs. Bildformate: Hauptunterschiede und wann eine Konvertierung sinnvoll ist
- Methode 1. HTML-Dateien als PDF und dann als Bild speichern
- Methode 2. HTML online mit CloudXDocs in ein Bild konvertieren
- Methode 3. Wie man HTML in Java mit Spire.Doc in ein Bild konvertiert
- Abschließende Gedanken
- Häufig gestellte Fragen
Das Konvertieren von HTML-Dateien in Bilder ist eine häufige Anforderung in vielen realen Szenarien, wie z. B. das Erstellen von Vorschauen, das Archivieren von webbasierten Berichten oder das Einbetten von Inhalten in PDFs. Obwohl HTML flexibel und dynamisch ist, können Unterschiede in Browsern, Schriftarten und Rendering-Umgebungen zu inkonsistenten Anzeigeergebnissen führen. Durch die Konvertierung von HTML in statische Bilder können Sie das ursprüngliche visuelle Erscheinungsbild bewahren und eine konsistente Darstellung auf allen Plattformen gewährleisten.
In diesem Artikel werden wir verschiedene Möglichkeiten zur Konvertierung von HTML in Bilder untersuchen. Wir werden eine browserbasierte Methode, ein Online-Tool wie CloudXDocs und eine Java-Lösung mit Spire.Doc behandeln. Jede Methode dient unterschiedlichen Szenarien, sodass Sie diejenige auswählen können, die für Sie am besten geeignet ist.
HTML vs. Bildformate: Hauptunterschiede und wann eine Konvertierung sinnvoll ist
Obwohl sowohl HTML- als auch Bildformate weit verbreitet sind, um visuelle Inhalte darzustellen, sind sie für grundlegend unterschiedliche Ziele konzipiert. Das Verständnis dieser Unterschiede ist entscheidend für die Wahl des richtigen Ausgabeformats in realen Anwendungen.
Hauptunterschiede zwischen HTML- und Bildformaten
| HTML | Bild (PNG, JPG, etc.) | |
|---|---|---|
| Darstellung | Abhängig von Browser und Rendering-Engine | Feste visuelle Ausgabe |
| Layout | Responsiv und dynamisch | Statisch und fest |
| Interaktivität | Unterstützt Skripte, Links und Benutzeraktionen | Nicht interaktiv |
| Visuelle Konsistenz | Kann je nach Browser und Gerät variieren | Überall identisch |
| Laufzeitabhängigkeit | Erfordert eine HTML/CSS-Rendering-Umgebung | Eigenständig |
| Ausgabestabilität | Beeinflusst durch CSS, Schriftarten und Ansichtsfenster | Unempfindlich gegenüber Umgebungsänderungen |
HTML eignet sich gut zur Anzeige dynamischer und interaktiver Inhalte in einem Browser. Diese Flexibilität bringt jedoch auch Unsicherheit mit sich: Derselbe HTML-Code kann je nach Browser-Engine, Bildschirmgröße, Schriftverfügbarkeit oder Benutzereinstellungen unterschiedlich dargestellt werden. Im Gegensatz dazu stellt ein Bild einen endgültigen visuellen Zustand dar, der nicht mehr von externen Darstellungsbedingungen abhängt.
Warum HTML in ein Bild konvertieren
Die Konvertierung von HTML in ein Bild ist nicht nur eine Formatänderung; es ist eine Möglichkeit, das visuelle Ergebnis von Webinhalten einzufrieren und die durch Laufzeitumgebungen verursachte Variabilität zu beseitigen. Dieser Ansatz wird besonders wertvoll in Situationen, in denen Vorhersehbarkeit, Wiederholbarkeit und nachgelagerte Kompatibilität entscheidend sind.
Insbesondere ist die Konvertierung von HTML in ein Bild die richtige Wahl, wenn:
- Exakte visuelle Wiedergabetreue erforderlich ist: Wenn Layout, Typografie und Stil für alle Benutzer genau gleich aussehen müssen, beseitigen Bilder browser- und gerätebedingte Unterschiede.
- HTML-Rendering nicht verfügbar oder unerwünscht ist: Backend-Dienste, Dokumenten-Pipelines oder Systeme von Drittanbietern können HTML oft nicht zuverlässig rendern, können aber problemlos Bilddateien verarbeiten.
- Inhalte eingebettet oder wiederverwendet werden müssen: Bilder können direkt in PDFs, Word-Dokumente, Präsentationen, E-Mails oder Berichte eingefügt werden, ohne zusätzliche Rendering-Logik.
- Dynamische oder gestylte Inhalte als Schnappschuss erfasst werden müssen: Dashboards, Diagramme oder generierte Seiten können in Bilder umgewandelt werden, um einen bestimmten Zustand zu einem bestimmten Zeitpunkt zu erhalten.
- Langfristige Speicherung oder Konformität erforderlich ist: Bilder stellen sicher, dass archivierte Inhalte auch dann visuell intakt bleiben, wenn sich CSS, Skripte oder externe Ressourcen in Zukunft ändern.
- Automatisierte oder Stapelverarbeitung beteiligt ist: Die serverseitige Konvertierung ermöglicht die skalierbare Erstellung von Vorschauen, Miniaturansichten und visuellen Assets ohne manuellen Eingriff.
In diesen Szenarien bietet die Konvertierung von HTML in Bildformate wie PNG oder JPG eine stabile und vorhersagbare Ausgabe, was die Integration von webbasierten Inhalten in breitere Anwendungs-Workflows erleichtert.
Methode 1. HTML-Dateien als PDF und dann als Bild speichern
Vorteile:
- Verwendet die integrierte Browser-Funktionalität
- Hohe Darstellungsgenauigkeit für statisches HTML und CSS
- Funktioniert offline, sobald der Browser installiert ist
Nachteile:
- Manueller Prozess, nicht für die Automatisierung geeignet
- Begrenzte Kontrolle über Auflösung und Ausgabegröße
- Nicht ideal für dynamische oder JavaScript-lastige Seiten
Am besten für: einmalige Konvertierungen, statische HTML-Seiten, schnelle Vorschauen oder Dokumentations-Schnappschüsse und Umgebungen mit strengen Software-Installationsrichtlinien
Wenn Ihr Ziel darin besteht, HTML in ein Bild zu konvertieren, ohne auf das Internet angewiesen zu sein und nur für eine einmalige Konvertierung, ist ein praktischer Workaround die Einführung eines Dokumentformats als Zwischenschritt. Moderne Browser bieten bereits integrierte Funktionen, um HTML genau zu rendern und als PDF zu exportieren. Indem Sie die HTML-Datei zuerst als PDF speichern und dieses PDF dann in ein Bild konvertieren, können Sie zuverlässige visuelle Ergebnisse erzielen und den Arbeitsablauf einfach halten. Dieser Ansatz eignet sich besonders für statische Seiten, schnelle Vorschauen oder Umgebungen, in denen die Installation zusätzlicher Software keine Option ist.
Die einzelnen Schritte sind unten aufgeführt:
Schritt 1. Öffnen Sie die HTML-Datei in einem modernen Browser wie Chrome oder Edge. Drücken Sie Strg + P (oder Cmd + P auf macOS), um den Druckdialog zu öffnen.
Schritt 2. Wählen Sie "Als PDF speichern" als Ziel aus und passen Sie bei Bedarf die Layouteinstellungen an.
Schritt 3. Klicken Sie auf die Schaltfläche "Speichern" unten, um die HTML-Datei als PDF zu exportieren.
Schritt 4. Öffnen Sie die konvertierte PDF-Datei mit Adobe Acrobat. Gehen Sie zum Werkzeug "Konvertieren", um das spezifische Bildformat auszuwählen, in das Sie konvertieren möchten.
Methode 2. HTML online mit CloudXDocs in ein Bild konvertieren
Vorteile:
- Keine Programmierung erforderlich
- Schnell und einfach zu bedienen
- Von jedem Gerät mit Browser aus zugänglich
- Keine lokale Installation erforderlich
Nachteile:
- Erfordert eine Internetverbindung
- Nicht für sensible oder vertrauliche Daten geeignet
Am besten für: nicht-technische Benutzer, gelegentliche HTML-zu-Bild-Konvertierungen, Marketing-, Design-, Dokumentationsaufgaben und das Testen der Konvertierungsausgabe vor der Automatisierung
Nachdem wir den Ansatz der Konvertierung von HTML zuerst in PDF und des anschließenden Exports des PDFs als Bild untersucht haben, ist es erwähnenswert, dass dieser Arbeitsablauf nicht immer notwendig ist – insbesondere, wenn Sie keine vollständige Kontrolle durch Code benötigen oder wenn die Konvertierungsaufgabe relativ einfach ist. Für Benutzer, die eine schnellere, leichtere Lösung bevorzugen, bieten Online-HTML-zu-Bild-Tools eine praktische Alternative.
Der CloudXDocs Online HTML to Image Converter bietet eine browserbasierte Lösung, mit der Sie HTML-Dateien hochladen und mit nur wenigen Klicks direkt in Bildformate konvertieren können. Dies macht ihn besonders nützlich für nicht-technische Benutzer sowie für Entwickler, die Konvertierungsergebnisse schnell vorab anzeigen oder validieren möchten, bevor sie einen automatisierten Arbeitsablauf implementieren.
Spezifische Schritte zur Verwendung des CloudXDocs HTML to Image Converter:
Schritt 1. Gehen Sie zuerst auf die offizielle Website des CloudxDocs Online HTML to Image Converter. Sie können die ursprüngliche HTML-Datei per Drag & Drop oder durch Klicken auf die Hauptoberfläche hochladen.
Schritt 2. Warten Sie einige Sekunden, während CloudXDocs die hochgeladene HTML-Datei automatisch analysiert und den Konvertierungsprozess startet.
Schritt 3. Nach der Konvertierung können Sie die gezippte Datei, die die konvertierten Bilddateien enthält, von der Ergebnisseite herunterladen. Laden Sie sie herunter und entpacken Sie sie, um alle Bilder auf Ihrem lokalen Computer zu speichern.
Methode 3. Wie man HTML in Java mit Spire.Doc in ein Bild konvertiert
Vorteile:
- Vollautomatisch und skalierbar
- Hohe Genauigkeit bei komplexen Layouts
- Keine Abhängigkeit von Microsoft Word
- Geeignet für serverseitigen und unternehmensweiten Einsatz
Nachteile:
- Erfordert Java-Entwicklungserfahrung
- Benötigt Bibliotheksintegration und -konfiguration
- Lizenzierung für den Produktionseinsatz erforderlich
Am besten für: Entwickler, Backend- oder serverseitige Anwendungen, Stapel- oder groß angelegte HTML-zu-Bild-Konvertierungen und unternehmensweite Dokumentenverarbeitungssysteme
Während Online-Tools für schnelle oder gelegentliche Konvertierungen praktisch sind, sind sie möglicherweise nicht die beste Wahl, wenn Sie Automatisierung, Skalierbarkeit oder vollständige Kontrolle über den Konvertierungsprozess benötigen. In Produktionsumgebungen oder Backend-Workflows benötigen Entwickler oft eine programmatische Lösung, die direkt in Java-Anwendungen integriert werden kann.
In solchen Fällen wird die Verwendung von Java-Code zur Konvertierung von HTML in Bilder zu einem zuverlässigeren und flexibleren Ansatz. Spire.Doc for Java bietet eine leistungsstarke API, mit der Sie HTML-Inhalte laden, in Dokumente konvertieren und das Ergebnis als Bilder mit hoher Wiedergabetreue exportieren können. Diese Methode eignet sich besonders für Entwickler, die Stapelverarbeitung, konsistente Ausgabe oder eine nahtlose Integration in bestehende Systeme ohne Abhängigkeit von externen Diensten benötigen.
Warum Spire.Doc wählen?
Spire.Doc ist eine Dokumentenverarbeitungsbibliothek, die den Import von HTML und den Export von Bildern unterstützt, ohne dass Microsoft Word oder Abhängigkeiten von Drittanbietern erforderlich sind. Es eignet sich gut für serverseitige Umgebungen und Unternehmensanwendungen.
Zu den Hauptvorteilen gehören:
- Unterstützung für komplexe HTML-Inhalte
- Genaues Layout und Formatierung
- Mehrere Ausgabe-Bildformate
- Einfache und intuitive API
Für Szenarien, die Automatisierung und hohe Konvertierungsgenauigkeit erfordern, bietet Spire.Doc eine robuste Lösung zur Konvertierung von HTML-Inhalten in Bilder. Als professionelle Dokumentenverarbeitungsbibliothek unterstützt Spire.Doc den Import von HTML und den Export in verschiedene Bildformate, ohne auf externe Anwendungen angewiesen zu sein.
So konvertieren Sie HTML in Bilder mit Spire.Doc for Java:
Schritt 1. Installieren Sie Spire.Doc for Java
Fügen Sie zuerst die Datei Spire.Doc.jar als Abhängigkeit in Ihrem Java-Programm hinzu. Sie können die .jar-Datei über den offiziellen Download-Link herunterladen.
Wenn Sie Maven verwenden, können Sie den folgenden Code zur pom.xml-Datei Ihres Projekts hinzufügen, um die Abhängigkeit einfach hinzuzufügen:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.7.0</version>
</dependency>
</dependencies>
Verwenden Sie den folgenden Beispielcode, um HTML in ein Bild zu konvertieren:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.ImageType;
import com.spire.doc.documents.XHTMLValidationType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertHtmlToImage {
public static void main(String[] args) throws IOException {
// Erstellen Sie ein Document-Objekt
Document document = new Document();
// Laden Sie eine HTML-Datei
document.loadFromFile("src\\main\\resources\\sample.html", FileFormat.Html, XHTMLValidationType.None);
// Holen Sie sich den ersten Abschnitt
Section section = document.getSections().get(0);
// Stellen Sie die Seitenränder ein
section.getPageSetup().getMargins().setAll(2);
// Konvertieren Sie das Dokument in ein Array von BufferedImage
BufferedImage[] images = document.saveToImages(ImageType.Bitmap);
// Durchlaufen Sie die Bilder
for (int index = 0; index < images.length; index++)
{
// Geben Sie den Namen der Ausgabedatei an
String fileName = String.format("output\\sample-html-to-image_%d.png", index);
// Speichern Sie jedes Bild als PNG-Datei
File file= new File(fileName);
ImageIO.write(images[index], "PNG", file);
}
// Ressourcen freigeben
document.dispose();
}
}
ERGEBNIS:
Intern konvertiert Spire.Doc HTML in ein Word-Dokumentenmodell, bevor es in Bilder gerendert wird. Dies ermöglicht Entwicklern, Seiteneinstellungen wie Ränder, Papiergröße und Layout vor dem Export anzupassen, um eine bessere Kontrolle über die endgültige Bildausgabe zu gewährleisten.
Abschließende Gedanken
Die Konvertierung von HTML in Bilder gewährleistet eine konsistente visuelle Ausgabe, reduziert die Variabilität bei der Darstellung und erleichtert das Teilen, Speichern oder Einbetten von Inhalten auf verschiedenen Plattformen und in Dokumenten. Indem Sie dynamische Webseiten in statische Bilder umwandeln, können Sie das exakte Layout, den Stil und die Typografie bewahren, ohne sich über Browserunterschiede oder fehlende Ressourcen Gedanken machen zu müssen.
- Für schnelle, einmalige Aufgaben funktioniert das Speichern von HTML als PDF und der anschließende Export in ein Bild gut.
- Für schnelle Konvertierungen ohne Code bietet CloudXDocs eine bequeme Online-Lösung.
- Für automatisierte, skalierbare Arbeitsabläufe bietet Spire.Doc for Java präzise Kontrolle und zuverlässige Ergebnisse.
Berücksichtigen Sie Ihren Arbeitsablauf, Ihre technischen Anforderungen und die gewünschte Ausgabequalität, um die Methode zu wählen, die Ihren Bedürfnissen am besten entspricht, und stellen Sie sicher, dass Ihr HTML-Inhalt genau wie beabsichtigt erhalten bleibt und überall konsistent aussieht, wo er verwendet wird.
Häufig gestellte Fragen:
F1. Ist die Konvertierung von HTML in Bilder kostenlos?
A: Ja, die Konvertierung von HTML in Bilder kann kostenlos sein, abhängig vom verwendeten Tool. Viele Online-Konverter und Open-Source-Bibliotheken bieten kostenlose Optionen für die grundlegende oder gelegentliche Nutzung.
F2. Welche Bildformate werden bei der Konvertierung von HTML unterstützt?
A: Gängige Formate sind PNG, JPG und BMP. PNG wird im Allgemeinen für hochwertige, verlustfreie Bilder bevorzugt, während JPG für kleinere Dateigrößen verwendet werden kann.
F3. Wird das konvertierte Bild genau wie die ursprüngliche HTML-Seite aussehen?
A: Bei statischem HTML mit Standard-CSS behalten Bilder in der Regel Layout und Stil genau bei. Dynamische Inhalte, Animationen oder Skripte erscheinen jedoch möglicherweise nicht im konvertierten Bild, es sei denn, sie werden im richtigen Moment erfasst.
Lesen Sie auch:
Конвертация HTML в изображения: Полное руководство для разработчиков и новичков
Содержание
- HTML и форматы изображений: ключевые различия и когда имеет смысл конвертация
- Метод 1. Сохранение HTML-файлов в PDF, а затем в изображение
- Метод 2. Конвертация HTML в изображение онлайн с помощью CloudXDocs
- Метод 3. Как конвертировать HTML в изображение на Java с помощью Spire.Doc
- Заключительные мысли
- Часто задаваемые вопросы
В этом посте:
- HTML и форматы изображений: ключевые различия и когда имеет смысл конвертация
- Метод 1. Сохранение HTML-файлов в PDF, а затем в изображение
- Метод 2. Конвертация HTML в изображение онлайн с помощью CloudXDocs
- Метод 3. Как конвертировать HTML в изображение на Java с помощью Spire.Doc
- Заключительные мысли
- Часто задаваемые вопросы
Преобразование HTML-файлов в изображения является частым требованием во многих реальных сценариях, таких как создание предварительных просмотров, архивирование веб-отчетов или встраивание контента в PDF-файлы. Хотя HTML является гибким и динамичным, различия в браузерах, шрифтах и средах рендеринга могут приводить к несогласованным результатам отображения. Преобразуя HTML в статические изображения, вы можете сохранить исходный внешний вид и обеспечить единообразный рендеринг на разных платформах.
В этой статье мы рассмотрим несколько способов преобразования HTML в изображения. Мы рассмотрим метод на основе браузера, онлайн-инструмент, такой как CloudXDocs, и решение на Java с использованием Spire.Doc. Каждый метод подходит для разных сценариев, поэтому вы можете выбрать тот, который лучше всего подходит именно вам.
HTML и форматы изображений: ключевые различия и когда имеет смысл конвертация
Хотя и HTML, и форматы изображений широко используются для представления визуального контента, они предназначены для принципиально разных целей. Понимание этих различий необходимо для выбора правильного формата вывода в реальных приложениях.
Ключевые различия между форматами HTML и изображений
| HTML | Изображение (PNG, JPG и т.д.) | |
|---|---|---|
| Рендеринг | Зависит от браузера и движка рендеринга | Фиксированный визуальный вывод |
| Макет | Адаптивный и динамичный | Статичный и фиксированный |
| Интерактивность | Поддерживает скрипты, ссылки и действия пользователя | Неинтерактивный |
| Визуальная согласованность | Может отличаться в разных браузерах и на разных устройствах | Идентично везде |
| Зависимость от среды выполнения | Требуется среда рендеринга HTML/CSS | Автономный |
| Стабильность вывода | Зависит от CSS, шрифтов и области просмотра | Невосприимчив к изменениям среды |
HTML хорошо подходит для отображения динамического и интерактивного контента в браузере. Однако эта гибкость также вносит неопределенность: один и тот же HTML может отображаться по-разному в зависимости от движков браузера, размеров экрана, доступности шрифтов или настроек пользователя. В отличие от этого, изображение представляет собой окончательное визуальное состояние, которое больше не зависит от внешних условий рендеринга.
Зачем конвертировать HTML в изображение
Преобразование HTML в изображение — это не просто смена формата; это способ «заморозить» визуальный результат веб-контента и устранить изменчивость, вносимую средами выполнения. Этот подход становится особенно ценным в ситуациях, где критически важны предсказуемость, повторяемость и совместимость с последующими системами.
В частности, преобразование HTML в изображение является правильным выбором, когда:
- Требуется точная визуальная точность: когда макет, типографика и стили должны выглядеть абсолютно одинаково для всех пользователей, изображения устраняют различия, связанные с браузером и устройством.
- Рендеринг HTML недоступен или нежелателен: бэкэнд-сервисы, конвейеры документов или сторонние системы часто не могут надежно отображать HTML, но могут легко обрабатывать файлы изображений.
- Контент необходимо встраивать или повторно использовать: изображения можно напрямую вставлять в PDF-файлы, документы Word, презентации, электронные письма или отчеты без дополнительной логики рендеринга.
- Динамический или стилизованный контент должен быть зафиксирован как снимок: информационные панели, диаграммы или сгенерированные страницы можно преобразовать в изображения, чтобы сохранить определенное состояние во времени.
- Требуется долгосрочное хранение или соответствие требованиям: изображения гарантируют, что архивный контент останется визуально неповрежденным, даже если CSS, скрипты или внешние ресурсы изменятся в будущем.
- Задействована автоматизированная или пакетная обработка: серверное преобразование позволяет масштабируемо генерировать предварительные просмотры, эскизы и визуальные ресурсы без ручного вмешательства.
В этих сценариях преобразование HTML в форматы изображений, такие как PNG или JPG, обеспечивает стабильный и предсказуемый результат, что упрощает интеграцию веб-контента в более широкие рабочие процессы приложений.
Метод 1. Сохранение HTML-файлов в PDF, а затем в изображение
Плюсы:
- Использует встроенную функциональность браузера
- Высокая точность рендеринга для статического HTML и CSS
- Работает в автономном режиме после установки браузера
Минусы:
- Ручной процесс, не подходит для автоматизации
- Ограниченный контроль над разрешением и размером вывода
- Не идеально для динамических или насыщенных JavaScript страниц
Лучше всего подходит для: разовых преобразований, статических HTML-страниц, быстрых предварительных просмотров или снимков документации, а также для сред со строгими политиками установки программного обеспечения
Если ваша цель — преобразовать HTML в изображение, не полагаясь на Интернет и только для одноразового преобразования, практическим обходным путем является введение формата документа в качестве промежуточного шага. Современные браузеры уже предоставляют встроенные возможности для точного рендеринга HTML и его экспорта в PDF. Сначала сохранив HTML-файл как PDF, а затем преобразовав этот PDF в изображение, вы можете достичь надежных визуальных результатов, сохраняя при этом простоту рабочего процесса. Этот подход особенно подходит для статических страниц, быстрых предварительных просмотров или сред, где установка дополнительного программного обеспечения невозможна.
Конкретные шаги перечислены ниже:
Шаг 1. Откройте HTML-файл в современном браузере, таком как Chrome или Edge. Нажмите Ctrl + P (или Cmd + P в macOS), чтобы открыть диалоговое окно печати.
Шаг 2. Выберите "Сохранить как PDF" в качестве места назначения и при необходимости настройте параметры макета.
Шаг 3. Нажмите кнопку "Сохранить" ниже, чтобы экспортировать HTML-файл в формате PDF.
Шаг 4. Откройте преобразованный PDF-файл с помощью Adobe Acrobat. Перейдите к инструменту "Преобразовать", чтобы выбрать конкретный формат изображения, в который вы хотите преобразовать.
Метод 2. Конвертация HTML в изображение онлайн с помощью CloudXDocs
Плюсы:
- Не требует написания кода
- Быстро и легко использовать
- Доступно с любого устройства с браузером
- Не требуется локальная установка
Минусы:
- Требуется подключение к Интернету
- Не подходит для конфиденциальных данных
Лучше всего подходит для: нетехнических пользователей, периодических преобразований HTML в изображение, задач маркетинга, дизайна, документирования и тестирования результатов преобразования перед автоматизацией
После изучения подхода к преобразованию HTML в PDF с последующим экспортом PDF в изображение стоит отметить, что этот рабочий процесс не всегда необходим, особенно когда вам не нужен полный контроль через код или когда задача преобразования относительно проста. Для пользователей, которые предпочитают более быстрое и легкое решение, онлайн-инструменты для преобразования HTML в изображение предлагают практическую альтернативу.
Онлайн-конвертер HTML в изображение CloudXDocs предоставляет браузерное решение, которое позволяет загружать HTML-файлы и преобразовывать их непосредственно в форматы изображений всего за несколько кликов. Это делает его особенно полезным для нетехнических пользователей, а также для разработчиков, которые хотят быстро просмотреть или проверить результаты преобразования перед внедрением автоматизированного рабочего процесса.
Конкретные шаги по использованию конвертера HTML в изображение CloudXDocs:
Шаг 1. Сначала перейдите на официальный сайт онлайн-конвертера HTML в изображение CloudxDocs. Вы можете перетащить или щелкнуть в главном интерфейсе, чтобы загрузить исходный HTML-файл.
Шаг 2. Подождите несколько секунд, пока CloudXDocs автоматически проанализирует загруженный HTML-файл и начнет процесс преобразования.
Шаг 3. После преобразования вы можете загрузить заархивированный файл, содержащий преобразованные файлы изображений, со страницы результатов. Загрузите и разархивируйте его, чтобы сохранить все изображения на свой локальный компьютер.
Метод 3. Как конвертировать HTML в изображение на Java с помощью Spire.Doc
Плюсы:
- Полностью автоматизированный и масштабируемый
- Высокая точность для сложных макетов
- Нет зависимости от Microsoft Word
- Подходит для серверного и корпоративного использования
Минусы:
- Требуется опыт разработки на Java
- Требуется интеграция и настройка библиотеки
- Требуется лицензирование для производственного использования
Лучше всего подходит для: разработчиков, бэкэнд- или серверных приложений, пакетных или крупномасштабных преобразований HTML в изображение, а также для корпоративных систем обработки документов
Хотя онлайн-инструменты удобны для быстрых или периодических преобразований, они могут быть не лучшим выбором, когда вам нужна автоматизация, масштабируемость или полный контроль над процессом преобразования. В производственных средах или бэкэнд-процессах разработчикам часто требуется программное решение, которое можно интегрировать непосредственно в приложения Java.
В таких случаях использование кода Java для преобразования HTML в изображения становится более надежным и гибким подходом. Spire.Doc для Java предоставляет мощный API, который позволяет загружать HTML-контент, преобразовывать его в документы и экспортировать результат в виде изображений с высокой точностью. Этот метод особенно подходит для разработчиков, которым требуется пакетная обработка, согласованный вывод или бесшовная интеграция в существующие системы без الاعتماد на внешние сервисы.
Почему стоит выбрать Spire.Doc?
Spire.Doc — это библиотека для обработки документов, которая поддерживает импорт HTML и экспорт изображений, не требуя Microsoft Word или каких-либо сторонних зависимостей. Она хорошо подходит для серверных сред и корпоративных приложений.
Ключевые преимущества включают:
- Поддержка сложного HTML-контента
- Точный макет и форматирование
- Несколько форматов выходных изображений
- Простой и интуитивно понятный API
Для сценариев, требующих автоматизации и высокой точности преобразования, Spire.Doc предлагает надежное решение для преобразования HTML-контента в изображения. Как профессиональная библиотека для обработки документов, Spire.Doc поддерживает импорт HTML и его экспорт в различные форматы изображений без зависимости от внешних приложений.
Чтобы преобразовать HTML в изображения с помощью Spire.Doc для Java:
Шаг 1. Установите Spire.Doc для Java
Сначала добавьте файл Spire.Doc.jar в качестве зависимости в вашу программу Java. Вы можете скачать файл .jar по официальной ссылке для скачивания.
Если вы используете Maven, вы можете добавить следующий код в файл pom.xml вашего проекта, чтобы легко добавить зависимость:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.7.0</version>
</dependency>
</dependencies>
Используйте следующий пример кода для преобразования HTML в изображение:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.ImageType;
import com.spire.doc.documents.XHTMLValidationType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertHtmlToImage {
public static void main(String[] args) throws IOException {
// Create a Document object
Document document = new Document();
// Load an HTML file
document.loadFromFile("src\\main\\resources\\sample.html", FileFormat.Html, XHTMLValidationType.None);
// Get the first section
Section section = document.getSections().get(0);
// Set the page margins
section.getPageSetup().getMargins().setAll(2);
// Convert the document to an array of BufferedImage
BufferedImage[] images = document.saveToImages(ImageType.Bitmap);
// Iterate through the images
for (int index = 0; index < images.length; index++)
{
// Specify the output file name
String fileName = String.format("output\\sample-html-to-image_%d.png", index);
// Save each image as a PNG file
File file= new File(fileName);
ImageIO.write(images[index], "PNG", file);
}
// Dispose resources
document.dispose();
}
}
РЕЗУЛЬТАТ:
Внутренне, Spire.Doc преобразует HTML в модель документа Word перед его рендерингом в изображения. Это позволяет разработчикам настраивать параметры страницы, такие как поля, размер бумаги и макет, перед экспортом, обеспечивая лучший контроль над конечным выводом изображения.
Заключительные мысли
Преобразование HTML в изображения обеспечивает согласованный визуальный вывод, уменьшает изменчивость рендеринга и упрощает обмен, хранение или встраивание контента на разных платформах и в документах. Превращая динамические веб-страницы в статические изображения, вы можете сохранить точный макет, стили и типографику, не беспокоясь о различиях в браузерах или отсутствующих ресурсах.
- Для быстрых, разовых задач хорошо подходит сохранение HTML в формате PDF с последующим экспортом в изображение.
- Для быстрых преобразований без кода, CloudXDocs предоставляет удобное онлайн-решение.
- Для автоматизированных, масштабируемых рабочих процессов, Spire.Doc для Java предлагает точный контроль и надежные результаты.
Учитывайте свой рабочий процесс, технические требования и желаемое качество вывода, чтобы выбрать метод, который наилучшим образом соответствует вашим потребностям, гарантируя, что ваш HTML-контент сохранится в точности так, как задумано, и будет выглядеть единообразно везде, где он используется.
Часто задаваемые вопросы:
В1. Является ли преобразование HTML в изображение бесплатным?
О: Да, преобразование HTML в изображение может быть бесплатным, в зависимости от используемого инструмента. Многие онлайн-конвертеры и библиотеки с открытым исходным кодом предлагают бесплатные опции для базового или периодического использования.
В2. Какие форматы изображений поддерживаются при преобразовании HTML?
О: Распространенные форматы включают PNG, JPG и BMP. PNG обычно предпочтительнее для высококачественных изображений без потерь, в то время как JPG можно использовать для файлов меньшего размера.
В3. Будет ли преобразованное изображение выглядеть в точности как исходная HTML-страница?
О: Для статического HTML со стандартным CSS изображения обычно точно сохраняют макет и стили. Однако динамический контент, анимация или скрипты могут не отображаться в преобразованном изображении, если они не были захвачены в нужный момент.
Также читайте:
Convert HTML to Images: Developer & Beginner Complete Guide
Table of Contents
In This Post:
- HTML vs. Image Formats: Key Differences and When Conversion Makes Sense
- Method 1. Save HTML Files to PDF and then Image
- Method 2. Convert HTML to Image Online Using CloudXDocs
- Method 3. How to Convert HTML to Image in Java with Spire.Doc
- Final Thoughts
- FAQs
Converting HTML files into images is a common requirement in many real-world scenarios, such as generating previews, archiving web-based reports, or embedding content into PDFs. While HTML is flexible and dynamic, differences in browsers, fonts, and rendering environments can lead to inconsistent display results. By converting HTML into static images, you can preserve the original visual appearance and ensure consistent rendering across platforms.
In this article, we'll explore several ways to convert HTML to images. We'll cover a browser-based method, an online tool like CloudXDocs, and a Java solution using Spire.Doc. Each method serves different scenarios, so you can pick the one that works best for you.
HTML vs. Image Formats: Key Differences and When Conversion Makes Sense
Although both HTML and image formats are widely used to present visual content, they are designed for fundamentally different goals. Understanding these differences is essential for choosing the correct output format in real-world applications.
Key Differences Between HTML and Image Formats
| HTML | Image (PNG, JPG, etc.) | |
|---|---|---|
| Rendering | Depends on browser and rendering engine | Fixed visual output |
| Layout | Responsive and dynamic | Static and fixed |
| Interactivity | Supports scripts, links, and user actions | Non-interactive |
| Visual Consistency | May vary across browsers and devices | Identical everywhere |
| Runtime Dependency | Requires HTML/CSS rendering environment | Self-contained |
| Output Stability | Affected by CSS, fonts, and viewport | Immune to environmental changes |
HTML is well suited for displaying dynamic and interactive content in a browser. However, this flexibility also introduces uncertainty: the same HTML may render differently depending on browser engines, screen sizes, font availability, or user settings. In contrast, an image represents a finalized visual state that no longer depends on external rendering conditions.
Why Convert HTML to Image
Converting HTML to an image is not merely a format change; it is a way to freeze the visual result of web content and eliminate variability introduced by runtime environments. This approach becomes especially valuable in situations where predictability, repeatability, and downstream compatibility are critical.
Specifically, HTML-to-image conversion is the right choice when:
- Exact visual fidelity is required: When layout, typography, and styling must appear exactly the same for all users, images remove browser- and device-related differences.
- HTML rendering is unavailable or undesirable: Backend services, document pipelines, or third-party systems often cannot render HTML reliably, but can easily handle image files.
- Content needs to be embedded or reused: Images can be directly inserted into PDFs, Word documents, presentations, emails, or reports without additional rendering logic.
- Dynamic or styled content must be captured as a snapshot: Dashboards, charts, or generated pages can be converted into images to preserve a specific state in time.
- Long-term storage or compliance is required: Images ensure that archived content remains visually intact even if CSS, scripts, or external resources change in the future.
- Automated or batch processing is involved: Server-side conversion enables scalable generation of previews, thumbnails, and visual assets without manual intervention.
In these scenarios, converting HTML into image formats such as PNG or JPG provides a stable and predictable output, making it easier to integrate web-based content into broader application workflows.
Method 1. Save HTML Files to PDF and then Image
Pros:
- Uses built-in browser functionality
- High rendering accuracy for static HTML and CSS
- Works offline once the browser is installed
Cons:
- Manual process, not suitable for automation
- Limited control over resolution and output size
- Not ideal for dynamic or JavaScript-heavy pages
Best for: one-off conversions, static HTML pages, quick previews or documentation snapshots, and environments with strict software installation policies
If your goal is to convert HTML to an image without relying on the Internet and for one-time conversion only, a practical workaround is to introduce a document format as an intermediate step. Modern browsers already provide built-in capabilities to render HTML accurately and export it as a PDF. By first saving the HTML file as a PDF and then converting that PDF into an image, you can achieve reliable visual results while keeping the workflow simple. This approach is especially suitable for static pages, quick previews, or environments where installing additional software is not an option.
Specific steps are listed below:
Step 1. Open the HTML file in a modern browser such as Chrome or Edge. Press Ctrl + P (or Cmd + P on macOS) to open the print dialog.
Step 2. Select "Save as PDF" as the destination and adjust layout settings if needed.
Step 3. Click the "Save" button below to export the HTML file as a PDF.
Step 4. Open the converted PDF file with Adobe Acrobat. Go to the "Convert" tool to choose the specific image format you want to convert with.
Method 2. Convert HTML to Image Online Using CloudXDocs
Pros:
- No coding required
- Fast and easy to use
- Accessible from any device with a browser
- No local installation needed
Cons:
- Requires an internet connection
- Not suitable for sensitive or confidential data
Best for: non-technical users, occasional HTML-to-image conversions, marketing, design, documentation tasks, and testing conversion output before automation
After exploring the approach of converting HTML to PDF first and then exporting the PDF as an image, it's worth noting that this workflow is not always necessary—especially when you don't need full control through code or when the conversion task is relatively simple. For users who prefer a quicker, more lightweight solution, online HTML-to-image tools offer a practical alternative.
CloudXDocs Online HTML to Image Converter provides a browser-based solution that allows you to upload HTML files and convert them directly into image formats with just a few clicks. This makes it particularly useful for non-technical users, as well as for developers who want to quickly preview or validate conversion results before implementing an automated workflow.
Specific steps to use CloudXDocs HTML to Image Converter:
Step 1. Go to the official website of CloudxDocs Online HTML to Image Converter first. You can drag or click from the main interface to upload the original HTML file.
Step 2. Wait a few seconds as CloudXDocs automatically analyzes the uploaded HTML file and begins the conversion process.
Step 3. After conversion, you can download the zipped file which includes the converted image files from the result page. Download and unzip it to save all the images to your local computer.
Method 3. How to Convert HTML to Image in Java with Spire.Doc
Pros:
- Fully automated and scalable
- High accuracy for complex layouts
- No Microsoft Word dependency
- Suitable for server-side and enterprise use
Cons:
- Requires Java development experience
- Needs library integration and configuration
- Licensing required for production use
Best for: developers, backend or server-side applications, batch or large-scale HTML-to-image conversions, and enterprise document processing systems
While online tools are convenient for quick or occasional conversions, they may not be the best choice when you need automation, scalability, or full control over the conversion process. In production environments or backend workflows, developers often require a programmatic solution that can be integrated directly into Java applications.
In such cases, using Java code to convert HTML to images becomes a more reliable and flexible approach. Spire.Doc for Java provides a powerful API that allows you to load HTML content, convert it into documents, and export the result as images with high fidelity. This method is especially suitable for developers who need batch processing, consistent output, or seamless integration into existing systems without relying on external services.
Why Choose Spire.Doc?
Spire.Doc is a document processing library that supports HTML import and image export without requiring Microsoft Word or any third-party dependencies. It is well-suited for server-side environments and enterprise applications.
Key advantages include:
- Support for complex HTML content
- Accurate layout and formatting
- Multiple output image formats
- Simple and intuitive API
For scenarios that require automation and high conversion accuracy, Spire.Doc offers a robust solution for converting HTML content into images. As a professional document-processing library, Spire.Doc supports importing HTML and exporting it to various image formats without relying on external applications.
To Convert HTML to images with Spire.Doc for Java:
Step 1. Install Spire.Doc for Java
First, add Spire.Doc.jar file as a dependency in your Java program. You can download the .jar file from the official download link.
If you are using Maven, you can add the following code to your project's pom.xml file to add the dependency easily:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.7.0</version>
</dependency>
</dependencies>
Use the following sample code to convert HTML to image:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.ImageType;
import com.spire.doc.documents.XHTMLValidationType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertHtmlToImage {
public static void main(String[] args) throws IOException {
// Create a Document object
Document document = new Document();
// Load an HTML file
document.loadFromFile("src\\main\\resources\\sample.html", FileFormat.Html, XHTMLValidationType.None);
// Get the first section
Section section = document.getSections().get(0);
// Set the page margins
section.getPageSetup().getMargins().setAll(2);
// Convert the document to an array of BufferedImage
BufferedImage[] images = document.saveToImages(ImageType.Bitmap);
// Iterate through the images
for (int index = 0; index < images.length; index++)
{
// Specify the output file name
String fileName = String.format("output\\sample-html-to-image_%d.png", index);
// Save each image as a PNG file
File file= new File(fileName);
ImageIO.write(images[index], "PNG", file);
}
// Dispose resources
document.dispose();
}
}
RESULT:
Internally, Spire.Doc converts HTML into a Word document model before rendering it to images. This allows developers to adjust page settings such as margins, paper size, and layout before exporting, ensuring better control over the final image output.
Final Thoughts
Converting HTML to images ensures consistent visual output, reduces rendering variability, and makes content easier to share, store, or embed across different platforms and documents. By turning dynamic web pages into static images, you can preserve the exact layout, styling, and typography without worrying about browser differences or missing resources.
- For quick, one-off tasks, saving HTML as PDF and then exporting to an image works well.
- For fast, no-code conversions, CloudXDocs provides a convenient online solution.
- For automated, scalable workflows, Spire.Doc for Java offers precise control and reliable results.
Consider your workflow, technical requirements, and desired output quality to choose the method that best fits your needs, ensuring your HTML content is preserved exactly as intended and looks consistent wherever it is used.
FAQs:
Q1. Is HTML-to-image conversion free?
A: Yes, HTML to image conversion can be free, depending on the tool you use. Many online converters and open-source libraries offer free options for basic or occasional use.
Q2. Which image formats are supported when converting HTML?
A: Common formats include PNG, JPG, and BMP. PNG is generally preferred for high-quality, lossless images, while JPG can be used for smaller file sizes.
Q3. Will the converted image look exactly like the original HTML page?
A: For static HTML with standard CSS, images typically preserve layout and styling accurately. However, dynamic content, animations, or scripts may not appear in the converted image unless captured at the right moment.
Also Read:
Como criar um PDF preenchível: 3 maneiras de tornar um PDF editável

No fluxo de trabalho digital de hoje, a capacidade de criar arquivos PDF preenchíveis é mais do que uma conveniência — é uma necessidade. Esteja você distribuindo pesquisas, formulários de inscrição, contratos ou planilhas, os PDFs preenchíveis permitem que os destinatários insiram informações diretamente, reduzam o manuseio manual e proporcionem uma experiência limpa e profissional.
Este guia abrangente o guiará pelas maneiras mais eficazes de criar PDFs editáveis, desde ferramentas gratuitas fáceis de usar e software profissional até scripts automatizados para desenvolvedores. Você aprenderá:
- O que é um PDF preenchível e por que ele é útil
- Crie um PDF editável usando o Adobe Acrobat Pro
- Ferramentas online gratuitas para tornar um PDF preenchível
- Crie programaticamente um PDF preenchível em Python
Ao final deste guia, você poderá escolher o melhor método para suas necessidades e começar a criar formulários PDF profissionais e interativos em minutos.
O que é um PDF preenchível?
Um PDF preenchível (também conhecido como formulário PDF interativo) é um documento que contém campos editáveis — como caixas de texto, caixas de seleção, botões de opção e listas suspensas — que os usuários podem preencher digitalmente sem precisar imprimir nada. Ao contrário de um PDF estático, um formulário preenchível orienta o usuário, garante que todas as informações necessárias sejam coletadas e geralmente inclui recursos como validação de dados e assinaturas digitais.
Por que usar PDFs preenchíveis?
- Profissionalismo: Apresenta uma interface limpa e de marca para uso comercial ou pessoal
- Eficiência: Economiza tempo tanto para o remetente quanto para o destinatário. Os dados podem ser preenchidos automaticamente, exportados ou compartilhados instantaneamente.
- Precisão: Reduz erros de caligrafia ilegível ou entrada de dados incorreta.
- Acessibilidade: Pode ser usado em qualquer dispositivo (desktop, celular, tablet) de qualquer lugar.
1. Crie um PDF editável usando o Adobe Acrobat Pro (o padrão da indústria)
O Adobe Acrobat é o padrão ouro para criar PDFs interativos — é confiável por empresas em todo o mundo por seus recursos robustos, incluindo detecção automática de campos de formulário, integração de assinatura eletrônica e ferramentas de coleta de dados. É ideal se você precisar de funcionalidades avançadas (por exemplo, cálculos, validação de dados).
Etapas para criar um formulário preenchível:
- Abra o Adobe Acrobat e selecione “Ferramentas” > “Preparar formulário” na barra de ferramentas.
- Escolha um documento: você pode começar com um PDF em branco, carregar um PDF existente ou até mesmo digitalizar um formulário em papel. O Acrobat detectará automaticamente os campos estáticos e os converterá em campos de texto preenchíveis.
- Personalize os campos do formulário: use o painel direito para adicionar ou editar campos:
- Campos de texto: para nomes, e-mails, endereços ou texto de formato livre.
- Caixas de seleção/Botões de opção: para perguntas de sim/não ou respostas de múltipla escolha/escolha única.
- Lista suspensa: para apresentar um conjunto de opções predefinidas.
- Campos de assinatura: permitem que os usuários adicionem assinaturas digitais.
- Botão: para ações de envio, redefinição do formulário ou hiperlinks.
- Visualizar e testar: clique em “Visualizar” para testar o formulário — verifique se os campos estão dimensionados, rotulados e funcionais corretamente.
- Salvar e distribuir: salve o PDF e use o recurso “Distribuir” do Acrobat para enviá-lo por e-mail, compartilhar um link ou coletar respostas em uma planilha.
Dica profissional: Depois que seu PDF preenchível for criado e preenchido, achatar o PDF torna-se essencial. O achatamento transforma todas as partes editáveis em texto e imagens estáticos. Isso impede que qualquer pessoa altere o conteúdo por acidente.
2. Ferramentas online gratuitas para tornar um PDF preenchível (não é necessária instalação)
Se você não quer pagar por software, alguns editores de PDF online permitem que você crie um PDF preenchível gratuitamente — sem downloads, sem necessidade de habilidades técnicas. Ferramentas como Sejda, PDFescape e Formize fornecem interfaces baseadas na web para adicionar campos de formulário PDF. Elas são fáceis de usar, mas podem ter limitações de tamanho de arquivo ou de privacidade.
Etapas para criar um PDF preenchível online:
Aqui usamos o Sejda como exemplo para adicionar campos preenchíveis. Ele funciona em todos os navegadores e permite editar PDFs existentes ou começar do zero.
- Acesse o Editor de PDF do Sejda e carregue seu PDF.
- Selecione “Campos de formulário” na barra de ferramentas e adicione os campos desejados.
- Personalize o layout e as propriedades do campo (por exemplo, nome do campo, status obrigatório).
- Clique em “Aplicar alterações” e baixe o PDF preenchível.
Importante: Tenha cuidado com dados confidenciais. Leia a política de privacidade de ferramentas online gratuitas antes de carregar informações confidenciais.
3. Crie programaticamente um PDF preenchível em Python (avançado, para desenvolvedores)
Se você é um desenvolvedor, pode criar PDFs editáveis por meio de código usando a biblioteca Free Spire.PDF. Isso é ideal para integrar a criação de formulários em aplicativos ou automatizar fluxos de trabalho.
O Free Spire.PDF para Python é uma biblioteca robusta e gratuita que oferece suporte à criação, edição e manipulação de PDFs. Ao contrário de algumas alternativas em Python, ele oferece:
- Sem custo para uso pessoal e comercial (com certas limitações de página).
- Suporte abrangente a campos de formulário (campos de texto, botões, caixas de combinação, etc.).
- Fácil integração com scripts Python.
Código Python para adicionar formulários PDF preenchíveis
O código abaixo cria um PDF preenchível com 5 campos de formulário comuns:
- Caixa de texto (para entrada de nome)
- Caixas de seleção (para seleção de gênero)
- Caixa de listagem (para seleção de país)
- Botões de opção (para seleção de hobby)
- Caixa de combinação/lista suspensa (para seleção de grau de escolaridade)
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object (blank PDF)
doc = PdfDocument()
# Add a blank page to the document (default A4 size)
page = doc.Pages.Add()
# Initialize x and y coordinates to position form fields
baseX = 100.0
baseY = 30.0
# Create brush objects for text color (blue for labels, black for options)
brush1 = PdfSolidBrush(PdfRGBColor(Color.get_Blue()))
brush2 = PdfSolidBrush(PdfRGBColor(Color.get_Black()))
# Create a font object (Times Roman, 12pt, regular style)
font = PdfFont(PdfFontFamily.TimesRoman, 12.0, PdfFontStyle.Regular)
# --------------------------
# 1. Add a Text Box (Name)
# --------------------------
# Draw label for the text box (blue color)
page.Canvas.DrawString("Name:", font, brush1, PointF(10.0, baseY))
# Define bounds (position + size) for the text box
tbxBounds = RectangleF(baseX, baseY, 150.0, 15.0)
# Create text box field with unique name "name"
textBox = PdfTextBoxField(page, "name")
textBox.Bounds = tbxBounds
textBox.Font = font
# Add text box to the PDF form
doc.Form.Fields.Add(textBox)
# Move y-coordinate down to avoid overlapping fields
baseY += 30.0
# --------------------------
# 2. Add Checkboxes (Gender)
# --------------------------
# Draw label for gender selection
page.Canvas.DrawString("Gender:", font, brush1, PointF(10.0, baseY))
# Checkbox 1: Male
checkboxBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
checkBoxField1 = PdfCheckBoxField(page, "male")
checkBoxField1.Bounds = checkboxBound1
checkBoxField1.Checked = False # Unchecked by default
page.Canvas.DrawString("Male", font, brush2, PointF(baseX + 20.0, baseY))
# Checkbox 2: Female
checkboxBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
checkBoxField2 = PdfCheckBoxField(page, "female")
checkBoxField2.Bounds = checkboxBound2
checkBoxField2.Checked = False
page.Canvas.DrawString("Female", font, brush2, PointF(baseX + 90.0, baseY))
# Add checkboxes to the form
doc.Form.Fields.Add(checkBoxField1)
doc.Form.Fields.Add(checkBoxField2)
baseY += 30.0
# --------------------------
# 3. Add a List Box (Country)
# --------------------------
# Draw label for country selection
page.Canvas.DrawString("Country:", font, brush1, PointF(10.0, baseY))
# Define bounds for the list box
listboxBound = RectangleF(baseX, baseY, 150.0, 50.0)
# Create list box field with unique name "country"
listBoxField = PdfListBoxField(page, "country")
# Add options (display text + internal value)
listBoxField.Items.Add(PdfListFieldItem("USA", "usa"))
listBoxField.Items.Add(PdfListFieldItem("Canada", "canada"))
listBoxField.Items.Add(PdfListFieldItem("Mexico", "mexico"))
listBoxField.Bounds = listboxBound
listBoxField.Font = font
# Add list box to the form
doc.Form.Fields.Add(listBoxField)
baseY += 60.0
# --------------------------
# 4. Add Radio Buttons (Hobbies)
# --------------------------
# Draw label for hobby selection
page.Canvas.DrawString("Hobbies:", font, brush1, PointF(10.0, baseY))
# Create radio button group (unique name "hobbies" ensures mutual exclusivity)
radioButtonListField = PdfRadioButtonListField(page, "hobbies")
# Radio button 1: Travel
radioItem1 = PdfRadioButtonListItem("travel")
radioBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
radioItem1.Bounds = radioBound1
page.Canvas.DrawString("Travel", font, brush2, PointF(baseX + 20.0, baseY))
# Radio button 2: Movie
radioItem2 = PdfRadioButtonListItem("movie")
radioBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
radioItem2.Bounds = radioBound2
page.Canvas.DrawString("Movie", font, brush2, PointF(baseX + 90.0, baseY))
# Add radio buttons to the group and group to the form
radioButtonListField.Items.Add(radioItem1)
radioButtonListField.Items.Add(radioItem2)
doc.Form.Fields.Add(radioButtonListField)
baseY += 30.0
# --------------------------
# 5. Add a Combobox (Degree)
# --------------------------
# Draw label for education degree
page.Canvas.DrawString("Degree:", font, brush1, PointF(10.0, baseY))
# Define bounds for the combobox
cmbBounds = RectangleF(baseX, baseY, 150.0, 15.0)
comboBoxField = PdfComboBoxField(page, "degree")
comboBoxField.Bounds = cmbBounds
# Add degree options (display text + internal value)
comboBoxField.Items.Add(PdfListFieldItem("Bachelor", "bachelor"))
comboBoxField.Items.Add(PdfListFieldItem("Master", "master"))
comboBoxField.Items.Add(PdfListFieldItem("Doctor", "doctor"))
comboBoxField.Font = font
# Add combobox to the form
doc.Form.Fields.Add(comboBoxField)
baseY += 30.0
# --------------------------
# Save the fillable PDF
# --------------------------
doc.SaveToFile("PdfForm.pdf", FileFormat.PDF)
Explicações do código principal
- Configuração do documento PDF: PdfDocument() cria um PDF em branco e Pages.Add() adiciona uma página A4 padrão (não há necessidade de definir o tamanho explicitamente).
- Layout e estilo:
- baseX/baseY: Coordenadas para controlar o posicionamento do campo (evita sobreposição e garante um layout limpo).
- PdfSolidBrush: Define as cores do texto (azul para rótulos, preto para opções) para melhorar a legibilidade do formulário.
- PdfFont: Define uma fonte padrão Times Roman 12pt para um estilo de texto consistente em todos os campos.
- Tipos de campo de formulário:
- PdfTextBoxField: Entrada de texto de linha única com alinhamento da fonte ao texto de entrada.
- PdfCheckBoxField: Seleção binária com estado padrão desmarcado.
- PdfListBoxField: Lista selecionável de várias linhas com limites mais altos para mostrar várias opções.
- PdfRadioButtonListField: Seleção mutuamente exclusiva – o agrupamento sob um nome garante que apenas um possa ser selecionado.
- PdfComboBoxField: Seleção suspensa com rótulos legíveis por humanos e valores internos amigáveis à máquina.
- Salvando arquivo: O PDF é salvo no caminho especificado com o FileFormat.PDF explícito para compatibilidade.
O PDF preenchível gerado tem a seguinte aparência:
Além de criar PDFs preenchíveis, um requisito crítico do mundo real para desenvolvedores que criam fluxos de trabalho automatizados é a capacidade de ler os valores dos campos do formulário e exportar os dados do formulário PDF coletados para formatos padrão para análise posterior.
Perguntas Frequentes (FAQ)
Q1: Posso criar um PDF preenchível gratuitamente?
Sim. Ferramentas online gratuitas como PDFescape ou Sejda permitem a criação básica de formulários sem pagamento ou instalação. Bibliotecas Python como o Free Spire.PDF também oferecem uma abordagem programática e gratuita para desenvolvedores.
Q2: Os PDFs preenchíveis são compatíveis com todos os dispositivos e leitores de PDF?
A maioria dos leitores de PDF modernos (Adobe Acrobat Reader, Preview no Mac, Chrome, Edge) oferece suporte ao preenchimento de formulários. No entanto, criar ou editar campos de formulário normalmente requer ferramentas especializadas.
Q3: Os PDFs preenchíveis podem incluir assinaturas digitais?
Sim. Muitas ferramentas, incluindo o Adobe Acrobat e vários editores online, permitem adicionar campos de assinatura onde os usuários podem desenhar, digitar ou carregar uma assinatura digital.
Q4: Qual método é o melhor para criar PDFs preenchíveis em lote?
Para geração em lote, uma abordagem programática usando Python é mais eficiente. Você pode automatizar a criação de centenas de formulários com layouts semelhantes, mas dados exclusivos.
Considerações Finais
Criar um PDF preenchível não precisa ser complicado — seja você um iniciante ou um desenvolvedor, existe uma ferramenta que se adapta ao seu fluxo de trabalho. Para uso casual, ferramentas online gratuitas como PDFescape ou Sejda são perfeitas. Para formulários profissionais (por exemplo, contratos, faturas), invista no Adobe Acrobat para recursos avançados. E para soluções automatizadas e escaláveis, o Python com Free Spire.PDF oferece uma alternativa poderosa e gratuita.
Seguindo as etapas deste guia, você criará PDFs preenchíveis que economizam tempo, reduzem erros e melhoram a experiência do usuário
Veja também
작성 가능한 PDF 만들기: PDF를 편집 가능하게 만드는 3가지 방법
오늘날의 디지털 워크플로우에서 채울 수 있는 PDF 파일을 만드는 기능은 편의성 그 이상이며 필수입니다. 설문조사, 신청서, 계약서 또는 워크시트를 배포할 때 채울 수 있는 PDF를 사용하면 수신자가 정보를 직접 입력하고 수동 처리를 줄이며 깔끔하고 전문적인 경험을 제공할 수 있습니다.
이 포괄적인 가이드에서는 사용자 친화적인 무료 도구와 전문 소프트웨어부터 개발자를 위한 자동화된 스크립팅에 이르기까지 편집 가능한 PDF를 만드는 가장 효과적인 방법을 안내합니다. 다음을 배우게 됩니다.
- 채울 수 있는 PDF란 무엇이며 유용한 이유
- Adobe Acrobat Pro를 사용하여 편집 가능한 PDF 만들기
- PDF를 채울 수 있게 만드는 무료 온라인 도구
- Python에서 프로그래밍 방식으로 채울 수 있는 PDF 만들기
이 가이드를 마치면 필요에 가장 적합한 방법을 선택하고 몇 분 안에 전문적인 대화형 PDF 양식을 만들 수 있습니다.
채울 수 있는 PDF란 무엇입니까?
채울 수 있는 PDF(대화형 PDF 양식이라고도 함)는 사용자가 아무것도 인쇄할 필요 없이 디지털 방식으로 완료할 수 있는 텍스트 상자, 확인란, 라디오 버튼 및 드롭다운 목록과 같은 편집 가능한 필드가 포함된 문서입니다. 정적 PDF와 달리 채울 수 있는 양식은 사용자를 안내하고 필요한 모든 정보가 수집되도록 보장하며 종종 데이터 유효성 검사 및 디지털 서명과 같은 기능을 포함합니다.
채울 수 있는 PDF를 사용하는 이유는 무엇입니까?
- 전문성: 비즈니스 또는 개인용으로 깔끔하고 브랜드화된 인터페이스를 제공합니다.
- 효율성: 발신자와 수신자 모두의 시간을 절약합니다. 데이터를 자동으로 채우거나 내보내거나 즉시 공유할 수 있습니다.
- 정확성: 읽기 어려운 필기나 잘못된 데이터 입력으로 인한 오류를 줄입니다.
- 접근성: 어디서나 모든 장치(데스크톱, 모바일, 태블릿)에서 사용할 수 있습니다.
1. Adobe Acrobat Pro를 사용하여 편집 가능한 PDF 만들기(업계 표준)
Adobe Acrobat은 대화형 PDF를 만들기 위한 최고의 표준이며 자동 양식 필드 감지, 전자 서명 통합 및 데이터 수집 도구를 포함한 강력한 기능으로 전 세계 기업의 신뢰를 받고 있습니다. 고급 기능(예: 계산, 데이터 유효성 검사)이 필요한 경우 이상적입니다.
채울 수 있는 양식을 만드는 단계:
- Adobe Acrobat을 열고 도구 모음에서 "도구" > "양식 준비"를 선택합니다.
- 문서 선택: 빈 PDF에서 시작하거나 기존 PDF를 업로드하거나 종이 양식을 스캔할 수도 있습니다. Acrobat은 정적 필드를 자동으로 감지하여 채울 수 있는 텍스트 필드로 변환합니다.
- 양식 필드 사용자 지정: 오른쪽 창을 사용하여 필드를 추가하거나 편집합니다.
- 텍스트 필드: 이름, 이메일, 주소 또는 자유 형식 텍스트용.
- 확인란/라디오 버튼: 예/아니요 질문 또는 단일/객관식 답변용.
- 드롭다운 목록: 미리 정의된 옵션 집합을 표시하기 위한 것입니다.
- 서명 필드: 사용자가 디지털 서명을 추가할 수 있도록 합니다.
- 버튼: 제출 작업, 양식 재설정 또는 하이퍼링크용.
- 미리보기 및 테스트: "미리보기"를 클릭하여 양식을 테스트하고 필드 크기가 올바르게 지정되고 레이블이 지정되었으며 작동하는지 확인합니다.
- 저장 및 배포: PDF를 저장한 다음 Acrobat의 "배포" 기능을 사용하여 이메일로 보내거나 링크를 공유하거나 스프레드시트에서 응답을 수집합니다.
전문가 팁: 채울 수 있는 PDF를 만들고 채우면 PDF 병합이 필수적입니다. 병합하면 편집 가능한 모든 부분이 정적 텍스트와 이미지로 바뀝니다. 이렇게 하면 다른 사람이 실수로 내용을 변경하는 것을 방지할 수 있습니다.
2. PDF를 채울 수 있게 만드는 무료 온라인 도구(설치 필요 없음)
소프트웨어 비용을 지불하고 싶지 않다면 일부 온라인 PDF 편집기를 사용하여 무료로 채울 수 있는 PDF를 만들 수 있습니다. 다운로드나 기술적인 기술이 필요하지 않습니다. Sejda, PDFescape 및 Formize와 같은 도구는 PDF 양식 필드를 추가하기 위한 웹 기반 인터페이스를 제공합니다. 사용자 친화적이지만 파일 크기나 개인 정보 보호에 제한이 있을 수 있습니다.
온라인에서 채울 수 있는 PDF를 만드는 단계:
여기서는 Sejda를 예로 들어 채울 수 있는 필드를 추가합니다. 모든 브라우저에서 작동하며 기존 PDF를 편집하거나 처음부터 시작할 수 있습니다.
- Sejda의 PDF 편집기로 이동하여 PDF를 업로드하세요.
- 도구 모음에서 "양식 필드"를 선택하고 원하는 필드를 추가합니다.
- 필드 레이아웃 및 속성(예: 필드 이름, 필수 상태)을 사용자 지정합니다.
- "변경 사항 적용"을 클릭하고 채울 수 있는 PDF를 다운로드합니다.
중요: 민감한 데이터에 유의하십시오. 기밀 정보를 업로드하기 전에 무료 온라인 도구의 개인 정보 보호 정책을 읽어보십시오.
3. Python에서 프로그래밍 방식으로 채울 수 있는 PDF 만들기(고급, 개발자용)
개발자라면 Free Spire.PDF 라이브러리를 사용하여 코드를 통해 편집 가능한 PDF를 만들 수 있습니다. 이는 양식 생성을 앱에 통합하거나 워크플로우를 자동화하는 데 이상적입니다.
Free Spire.PDF for Python은 PDF 생성, 편집 및 조작을 지원하는 강력한 무료 라이브러리입니다. 일부 Python 대안과 달리 다음을 제공합니다.
- 개인 및 상업적 용도로 모두 무료입니다(특정 페이지 제한 있음).
- 포괄적인 양식 필드 지원(텍스트 필드, 버튼, 콤보 상자 등).
- Python 스크립트와의 손쉬운 통합.
PDF 채울 수 있는 양식을 추가하는 Python 코드
아래 코드는 5개의 공통 양식 필드가 있는 채울 수 있는 PDF를 만듭니다.
- 텍스트 상자(이름 입력용)
- 확인란(성별 선택용)
- 목록 상자(국가 선택용)
- 라디오 버튼(취미 선택용)
- 콤보박스/드롭다운(학위 선택용)
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument 개체 만들기(빈 PDF)
doc = PdfDocument()
# 문서에 빈 페이지 추가(기본 A4 크기)
page = doc.Pages.Add()
# 양식 필드 위치를 지정하기 위해 x 및 y 좌표 초기화
baseX = 100.0
baseY = 30.0
# 텍스트 색상에 대한 브러시 개체 만들기(레이블은 파란색, 옵션은 검은색)
brush1 = PdfSolidBrush(PdfRGBColor(Color.get_Blue()))
brush2 = PdfSolidBrush(PdfRGBColor(Color.get_Black()))
# 글꼴 개체 만들기(Times Roman, 12pt, 일반 스타일)
font = PdfFont(PdfFontFamily.TimesRoman, 12.0, PdfFontStyle.Regular)
# --------------------------
# 1. 텍스트 상자 추가(이름)
# --------------------------
# 텍스트 상자에 대한 레이블 그리기(파란색)
page.Canvas.DrawString("Name:", font, brush1, PointF(10.0, baseY))
# 텍스트 상자에 대한 경계(위치 + 크기) 정의
tbxBounds = RectangleF(baseX, baseY, 150.0, 15.0)
# 고유한 이름 "name"으로 텍스트 상자 필드 만들기
textBox = PdfTextBoxField(page, "name")
textBox.Bounds = tbxBounds
textBox.Font = font
# PDF 양식에 텍스트 상자 추가
doc.Form.Fields.Add(textBox)
# 필드가 겹치지 않도록 y 좌표를 아래로 이동
baseY += 30.0
# --------------------------
# 2. 확인란 추가(성별)
# --------------------------
# 성별 선택에 대한 레이블 그리기
page.Canvas.DrawString("Gender:", font, brush1, PointF(10.0, baseY))
# 확인란 1: 남성
checkboxBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
checkBoxField1 = PdfCheckBoxField(page, "male")
checkBoxField1.Bounds = checkboxBound1
checkBoxField1.Checked = False # 기본적으로 선택 취소됨
page.Canvas.DrawString("Male", font, brush2, PointF(baseX + 20.0, baseY))
# 확인란 2: 여성
checkboxBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
checkBoxField2 = PdfCheckBoxField(page, "female")
checkBoxField2.Bounds = checkboxBound2
checkBoxField2.Checked = False
page.Canvas.DrawString("Female", font, brush2, PointF(baseX + 90.0, baseY))
# 양식에 확인란 추가
doc.Form.Fields.Add(checkBoxField1)
doc.Form.Fields.Add(checkBoxField2)
baseY += 30.0
# --------------------------
# 3. 목록 상자 추가(국가)
# --------------------------
# 국가 선택에 대한 레이블 그리기
page.Canvas.DrawString("Country:", font, brush1, PointF(10.0, baseY))
# 목록 상자에 대한 경계 정의
listboxBound = RectangleF(baseX, baseY, 150.0, 50.0)
# 고유한 이름 "country"로 목록 상자 필드 만들기
listBoxField = PdfListBoxField(page, "country")
# 옵션 추가(표시 텍스트 + 내부 값)
listBoxField.Items.Add(PdfListFieldItem("USA", "usa"))
listBoxField.Items.Add(PdfListFieldItem("Canada", "canada"))
listBoxField.Items.Add(PdfListFieldItem("Mexico", "mexico"))
listBoxField.Bounds = listboxBound
listBoxField.Font = font
# 양식에 목록 상자 추가
doc.Form.Fields.Add(listBoxField)
baseY += 60.0
# --------------------------
# 4. 라디오 버튼 추가(취미)
# --------------------------
# 취미 선택에 대한 레이블 그리기
page.Canvas.DrawString("Hobbies:", font, brush1, PointF(10.0, baseY))
# 라디오 버튼 그룹 만들기(고유한 이름 "hobbies"는 상호 배타성을 보장)
radioButtonListField = PdfRadioButtonListField(page, "hobbies")
# 라디오 버튼 1: 여행
radioItem1 = PdfRadioButtonListItem("travel")
radioBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
radioItem1.Bounds = radioBound1
page.Canvas.DrawString("Travel", font, brush2, PointF(baseX + 20.0, baseY))
# 라디오 버튼 2: 영화
radioItem2 = PdfRadioButtonListItem("movie")
radioBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
radioItem2.Bounds = radioBound2
page.Canvas.DrawString("Movie", font, brush2, PointF(baseX + 90.0, baseY))
# 그룹에 라디오 버튼 추가 및 양식에 그룹 추가
radioButtonListField.Items.Add(radioItem1)
radioButtonListField.Items.Add(radioItem2)
doc.Form.Fields.Add(radioButtonListField)
baseY += 30.0
# --------------------------
# 5. 콤보박스 추가(학위)
# --------------------------
# 학위에 대한 레이블 그리기
page.Canvas.DrawString("Degree:", font, brush1, PointF(10.0, baseY))
# 콤보박스에 대한 경계 정의
cmbBounds = RectangleF(baseX, baseY, 150.0, 15.0)
comboBoxField = PdfComboBoxField(page, "degree")
comboBoxField.Bounds = cmbBounds
# 학위 옵션 추가(표시 텍스트 + 내부 값)
comboBoxField.Items.Add(PdfListFieldItem("Bachelor", "bachelor"))
comboBoxField.Items.Add(PdfListFieldItem("Master", "master"))
comboBoxField.Items.Add(PdfListFieldItem("Doctor", "doctor"))
comboBoxField.Font = font
# 양식에 콤보박스 추가
doc.Form.Fields.Add(comboBoxField)
baseY += 30.0
# --------------------------
# 채울 수 있는 PDF 저장
# --------------------------
doc.SaveToFile("PdfForm.pdf", FileFormat.PDF)
주요 코드 설명
- PDF 문서 설정: PdfDocument()는 빈 PDF를 만들고 Pages.Add()는 기본 A4 페이지를 추가합니다(크기를 명시적으로 정의할 필요 없음).
- 레이아웃 및 스타일링:
- baseX/baseY: 필드 위치를 제어하는 좌표(겹침을 방지하고 깔끔한 레이아웃 보장).
- PdfSolidBrush: 양식 가독성을 높이기 위해 텍스트 색상(레이블은 파란색, 옵션은 검은색)을 정의합니다.
- PdfFont: 모든 필드에서 일관된 텍스트 스타일을 위해 표준 Times Roman 12pt 글꼴을 설정합니다.
- 양식 필드 유형:
- PdfTextBoxField: 입력 텍스트에 글꼴이 정렬된 한 줄 텍스트 입력.
- PdfCheckBoxField: 선택되지 않은 기본 상태의 이진 선택.
- PdfListBoxField: 여러 옵션을 표시하기 위해 더 높은 경계를 가진 여러 줄 선택 가능 목록.
- PdfRadioButtonListField: 상호 배타적인 선택 – 하나의 이름으로 그룹화하면 하나만 선택할 수 있습니다.
- PdfComboBoxField: 사람이 읽을 수 있는 레이블과 기계 친화적인 내부 값을 사용한 드롭다운 선택.
- 파일 저장: 호환성을 위해 명시적인 FileFormat.PDF를 사용하여 지정된 경로에 PDF가 저장됩니다.
생성된 채울 수 있는 PDF는 다음과 같습니다.
채울 수 있는 PDF를 만드는 것 외에도 자동화된 워크플로우를 구축하는 개발자에게 중요한 실제 요구 사항은 양식 필드 값을 읽고 수집된 PDF 양식 데이터를 추가 분석을 위해 표준 형식으로 내보내는 기능입니다.
자주 묻는 질문(FAQ)
Q1: 채울 수 있는 PDF를 무료로 만들 수 있나요?
예. PDFescape 또는 Sejda와 같은 무료 온라인 도구를 사용하면 결제나 설치 없이 기본 양식을 만들 수 있습니다. Free Spire.PDF와 같은 Python 라이브러리는 개발자를 위한 무료 프로그래밍 방식 접근 방식도 제공합니다.
Q2: 채울 수 있는 PDF는 모든 장치 및 PDF 리더와 호환됩니까?
대부분의 최신 PDF 리더(Adobe Acrobat Reader, Mac의 미리보기, Chrome, Edge)는 양식 작성을 지원합니다. 그러나 양식 필드를 만들거나 편집하려면 일반적으로 특수 도구가 필요합니다.
Q3: 채울 수 있는 PDF에 디지털 서명을 포함할 수 있나요?
예. Adobe Acrobat 및 여러 온라인 편집기를 포함한 많은 도구를 사용하면 사용자가 디지털 서명을 그리거나 입력하거나 업로드할 수 있는 서명 필드를 추가할 수 있습니다.
Q4: 채울 수 있는 PDF를 일괄 생성하는 데 가장 좋은 방법은 무엇입니까?
일괄 생성을 위해서는 Python을 사용하는 프로그래밍 방식이 가장 효율적입니다. 레이아웃은 비슷하지만 데이터는 고유한 수백 개의 양식 생성을 자동화할 수 있습니다.
마지막 생각들
채울 수 있는 PDF를 만드는 것은 복잡할 필요가 없습니다. 초보자이든 개발자이든 워크플로우에 맞는 도구가 있습니다. 일상적인 사용에는 PDFescape 또는 Sejda와 같은 무료 온라인 도구가 적합합니다. 전문적인 양식(예: 계약서, 송장)의 경우 고급 기능을 위해 Adobe Acrobat에 투자하십시오. 그리고 자동화되고 확장 가능한 솔루션을 위해 Free Spire.PDF가 포함된 Python은 강력하고 무료인 대안을 제공합니다.
이 가이드의 단계를 따르면 시간을 절약하고 오류를 줄이며 사용자 경험을 개선하는 채울 수 있는 PDF를 만들 수 있습니다.
더 보기
Come creare un PDF compilabile: 3 modi per rendere un PDF modificabile
Nel flusso di lavoro digitale di oggi, la capacità di creare file PDF compilabili è più di una comodità: è una necessità. Che si tratti di distribuire sondaggi, moduli di domanda, contratti o fogli di lavoro, i PDF compilabili consentono ai destinatari di inserire le informazioni direttamente, riducono la gestione manuale e offrono un'esperienza pulita e professionale.
Questa guida completa ti illustrerà i modi più efficaci per creare PDF modificabili, da strumenti gratuiti di facile utilizzo e software professionali a script automatizzati per sviluppatori. Imparerai:
- Cos'è un PDF compilabile e perché è utile
- Creare un PDF modificabile utilizzando Adobe Acrobat Pro
- Strumenti online gratuiti per rendere i PDF compilabili
- Creare programmaticamente un PDF compilabile in Python
Alla fine di questa guida, sarai in grado di scegliere il metodo migliore per le tue esigenze e iniziare a creare moduli PDF professionali e interattivi in pochi minuti.
Cos'è un PDF compilabile?
Un PDF compilabile (noto anche come modulo PDF interattivo) è un documento che contiene campi modificabili, come caselle di testo, caselle di controllo, pulsanti di opzione ed elenchi a discesa, che gli utenti possono compilare digitalmente senza bisogno di stampare nulla. A differenza di un PDF statico, un modulo compilabile guida l'utente, garantisce la raccolta di tutte le informazioni necessarie e spesso include funzionalità come la convalida dei dati e le firme digitali.
Perché usare i PDF compilabili?
- Professionalità: presenta un'interfaccia pulita e brandizzata per uso aziendale o personale
- Efficienza: fa risparmiare tempo sia al mittente che al destinatario. I dati possono essere compilati automaticamente, esportati o condivisi istantaneamente.
- Precisione: riduce gli errori dovuti a grafia illeggibile o all'inserimento errato dei dati.
- Accessibilità: può essere utilizzato su qualsiasi dispositivo (desktop, mobile, tablet) da qualsiasi luogo.
1. Creare un PDF modificabile utilizzando Adobe Acrobat Pro (lo standard del settore)
Adobe Acrobat è il gold standard per la creazione di PDF interattivi: è considerato affidabile dalle aziende di tutto il mondo per le sue robuste funzionalità, tra cui il rilevamento automatico dei campi modulo, l'integrazione della firma elettronica e gli strumenti di raccolta dati. È ideale se hai bisogno di funzionalità avanzate (ad es. calcoli, convalida dei dati).
Passaggi per creare un modulo compilabile:
- Apri Adobe Acrobat e seleziona “Strumenti” > “Prepara modulo” dalla barra degli strumenti.
- Scegli un documento: puoi iniziare da un PDF vuoto, caricare un PDF esistente o persino scansionare un modulo cartaceo. Acrobat rileverà automaticamente i campi statici e li convertirà in campi di testo compilabili.
- Personalizza i campi del modulo: utilizza il riquadro di destra per aggiungere o modificare i campi:
- Campi di testo: per nomi, e-mail, indirizzi o testo libero.
- Caselle di controllo/Pulsanti di opzione: per domande sì/no o risposte a scelta singola/multipla.
- Elenco a discesa: per presentare una serie di opzioni predefinite.
- Campi firma: consente agli utenti di aggiungere firme digitali.
- Pulsante: per azioni di invio, reimpostazione del modulo o collegamenti ipertestuali.
- Anteprima e test: fai clic su “Anteprima” per testare il modulo: assicurati che i campi siano dimensionati, etichettati e funzionanti correttamente.
- Salva e distribuisci: salva il PDF, quindi utilizza la funzione “Distribuisci” di Acrobat per inviarlo via e-mail, condividere un collegamento o raccogliere le risposte in un foglio di calcolo.
Suggerimento professionale: una volta creato e compilato il PDF compilabile, l'appiattimento del PDF diventa essenziale. L'appiattimento trasforma tutte le parti modificabili in testo e immagini statici. Ciò impedisce a chiunque di modificare accidentalmente il contenuto.
2. Strumenti online gratuiti per rendere i PDF compilabili (nessuna installazione richiesta)
Se non vuoi pagare per il software, alcuni editor di PDF online ti consentono di creare un PDF compilabile gratuitamente, senza download e senza competenze tecniche. Strumenti come Sejda, PDFescape, e Formize forniscono interfacce basate sul Web per l'aggiunta di campi modulo PDF. Questi sono facili da usare ma possono avere limitazioni di dimensione del file o di privacy.
Passaggi per creare un PDF compilabile online:
Qui usiamo Sejda come esempio per aggiungere campi compilabili. Funziona su tutti i browser e ti consente di modificare i PDF esistenti o di iniziare da zero.
- Vai all'editor PDF di Sejda e carica il tuo PDF.
- Seleziona “Campi modulo” dalla barra degli strumenti e aggiungi i campi desiderati.
- Personalizza il layout e le proprietà dei campi (ad es. nome del campo, stato richiesto).
- Fai clic su “Applica modifiche” e scarica il PDF compilabile.
Importante: prestare attenzione ai dati sensibili. Leggere l'informativa sulla privacy degli strumenti online gratuiti prima di caricare informazioni riservate.
3. Creare programmaticamente un PDF compilabile in Python (avanzato, per sviluppatori)
Se sei uno sviluppatore, puoi creare PDF modificabili tramite codice utilizzando la libreria Free Spire.PDF. Questo è l'ideale per integrare la creazione di moduli nelle app o per automatizzare i flussi di lavoro.
Free Spire.PDF per Python è una libreria robusta e gratuita che supporta la creazione, la modifica e la manipolazione di PDF. A differenza di alcune alternative Python, fornisce:
- Nessun costo per uso personale e commerciale (con alcune limitazioni di pagina).
- Supporto completo per i campi modulo (campi di testo, pulsanti, caselle combinate, ecc.).
- Facile integrazione con gli script Python.
Codice Python per aggiungere moduli compilabili PDF
Il codice seguente crea un PDF compilabile con 5 campi modulo comuni:
- Casella di testo (per l'inserimento del nome)
- Caselle di controllo (per la selezione del sesso)
- Casella di riepilogo (per la selezione del paese)
- Pulsanti di opzione (per la selezione dell'hobby)
- Casella combinata/menu a discesa (per la selezione del titolo di studio)
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object (blank PDF)
doc = PdfDocument()
# Add a blank page to the document (default A4 size)
page = doc.Pages.Add()
# Initialize x and y coordinates to position form fields
baseX = 100.0
baseY = 30.0
# Create brush objects for text color (blue for labels, black for options)
brush1 = PdfSolidBrush(PdfRGBColor(Color.get_Blue()))
brush2 = PdfSolidBrush(PdfRGBColor(Color.get_Black()))
# Create a font object (Times Roman, 12pt, regular style)
font = PdfFont(PdfFontFamily.TimesRoman, 12.0, PdfFontStyle.Regular)
# --------------------------
# 1. Add a Text Box (Name)
# --------------------------
# Draw label for the text box (blue color)
page.Canvas.DrawString("Name:", font, brush1, PointF(10.0, baseY))
# Define bounds (position + size) for the text box
tbxBounds = RectangleF(baseX, baseY, 150.0, 15.0)
# Create text box field with unique name "name"
textBox = PdfTextBoxField(page, "name")
textBox.Bounds = tbxBounds
textBox.Font = font
# Add text box to the PDF form
doc.Form.Fields.Add(textBox)
# Move y-coordinate down to avoid overlapping fields
baseY += 30.0
# --------------------------
# 2. Add Checkboxes (Gender)
# --------------------------
# Draw label for gender selection
page.Canvas.DrawString("Gender:", font, brush1, PointF(10.0, baseY))
# Checkbox 1: Male
checkboxBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
checkBoxField1 = PdfCheckBoxField(page, "male")
checkBoxField1.Bounds = checkboxBound1
checkBoxField1.Checked = False # Unchecked by default
page.Canvas.DrawString("Male", font, brush2, PointF(baseX + 20.0, baseY))
# Checkbox 2: Female
checkboxBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
checkBoxField2 = PdfCheckBoxField(page, "female")
checkBoxField2.Bounds = checkboxBound2
checkBoxField2.Checked = False
page.Canvas.DrawString("Female", font, brush2, PointF(baseX + 90.0, baseY))
# Add checkboxes to the form
doc.Form.Fields.Add(checkBoxField1)
doc.Form.Fields.Add(checkBoxField2)
baseY += 30.0
# --------------------------
# 3. Add a List Box (Country)
# --------------------------
# Draw label for country selection
page.Canvas.DrawString("Country:", font, brush1, PointF(10.0, baseY))
# Define bounds for the list box
listboxBound = RectangleF(baseX, baseY, 150.0, 50.0)
# Create list box field with unique name "country"
listBoxField = PdfListBoxField(page, "country")
# Add options (display text + internal value)
listBoxField.Items.Add(PdfListFieldItem("USA", "usa"))
listBoxField.Items.Add(PdfListFieldItem("Canada", "canada"))
listBoxField.Items.Add(PdfListFieldItem("Mexico", "mexico"))
listBoxField.Bounds = listboxBound
listBoxField.Font = font
# Add list box to the form
doc.Form.Fields.Add(listBoxField)
baseY += 60.0
# --------------------------
# 4. Add Radio Buttons (Hobbies)
# --------------------------
# Draw label for hobby selection
page.Canvas.DrawString("Hobbies:", font, brush1, PointF(10.0, baseY))
# Create radio button group (unique name "hobbies" ensures mutual exclusivity)
radioButtonListField = PdfRadioButtonListField(page, "hobbies")
# Radio button 1: Travel
radioItem1 = PdfRadioButtonListItem("travel")
radioBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
radioItem1.Bounds = radioBound1
page.Canvas.DrawString("Travel", font, brush2, PointF(baseX + 20.0, baseY))
# Radio button 2: Movie
radioItem2 = PdfRadioButtonListItem("movie")
radioBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
radioItem2.Bounds = radioBound2
page.Canvas.DrawString("Movie", font, brush2, PointF(baseX + 90.0, baseY))
# Add radio buttons to the group and group to the form
radioButtonListField.Items.Add(radioItem1)
radioButtonListField.Items.Add(radioItem2)
doc.Form.Fields.Add(radioButtonListField)
baseY += 30.0
# --------------------------
# 5. Add a Combobox (Degree)
# --------------------------
# Draw label for education degree
page.Canvas.DrawString("Degree:", font, brush1, PointF(10.0, baseY))
# Define bounds for the combobox
cmbBounds = RectangleF(baseX, baseY, 150.0, 15.0)
comboBoxField = PdfComboBoxField(page, "degree")
comboBoxField.Bounds = cmbBounds
# Add degree options (display text + internal value)
comboBoxField.Items.Add(PdfListFieldItem("Bachelor", "bachelor"))
comboBoxField.Items.Add(PdfListFieldItem("Master", "master"))
comboBoxField.Items.Add(PdfListFieldItem("Doctor", "doctor"))
comboBoxField.Font = font
# Add combobox to the form
doc.Form.Fields.Add(comboBoxField)
baseY += 30.0
# --------------------------
# Save the fillable PDF
# --------------------------
doc.SaveToFile("PdfForm.pdf", FileFormat.PDF)
Spiegazioni del codice chiave
- Impostazione del documento PDF: PdfDocument() crea un PDF vuoto e Pages.Add() aggiunge una pagina A4 predefinita (non è necessario definire esplicitamente le dimensioni).
- Layout e stile:
- baseX/baseY: coordinate per controllare il posizionamento dei campi (evita la sovrapposizione e garantisce un layout pulito).
- PdfSolidBrush: definisce i colori del testo (blu per le etichette, nero per le opzioni) per migliorare la leggibilità del modulo.
- PdfFont: imposta un carattere Times Roman standard da 12 pt per uno stile di testo coerente in tutti i campi.
- Tipi di campo modulo:
- PdfTextBoxField: immissione di testo a riga singola con allineamento del carattere al testo di immissione.
- PdfCheckBoxField: selezione binaria con stato predefinito non selezionato.
- PdfListBoxField: elenco selezionabile su più righe con limiti più alti per mostrare più opzioni.
- PdfRadioButtonListField: selezione che si esclude a vicenda: il raggruppamento sotto un unico nome garantisce che ne possa essere selezionato solo uno.
- PdfComboBoxField: selezione a discesa con etichette leggibili dall'uomo e valori interni compatibili con la macchina.
- Salvataggio file: il PDF viene salvato nel percorso specificato con FileFormat.PDF esplicito per la compatibilità.
Il PDF compilabile generato ha il seguente aspetto:
Oltre alla creazione di PDF compilabili, un requisito critico del mondo reale per gli sviluppatori che creano flussi di lavoro automatizzati è la capacità di leggere i valori dei campi del modulo e esportare i dati del modulo PDF raccolti in formati standard per ulteriori analisi.
Domande frequenti (FAQ)
D1: Posso creare un PDF compilabile gratuitamente?
Sì. Strumenti online gratuiti come PDFescape o Sejda consentono la creazione di moduli di base senza pagamento o installazione. Anche le librerie Python come Free Spire.PDF offrono un approccio programmatico gratuito per gli sviluppatori.
D2: I PDF compilabili sono compatibili con tutti i dispositivi e lettori PDF?
La maggior parte dei lettori PDF moderni (Adobe Acrobat Reader, Anteprima su Mac, Chrome, Edge) supporta la compilazione di moduli. Tuttavia, la creazione o la modifica di campi modulo richiede in genere strumenti specializzati.
D3: I PDF compilabili possono includere firme digitali?
Sì. Molti strumenti, tra cui Adobe Acrobat e diversi editor online, consentono di aggiungere campi firma in cui gli utenti possono disegnare, digitare o caricare una firma digitale.
D4: Qual è il metodo migliore per la creazione in batch di PDF compilabili?
Per la generazione in batch, un approccio programmatico che utilizza Python è più efficiente. È possibile automatizzare la creazione di centinaia di moduli con layout simili ma dati univoci.
Considerazioni finali
La creazione di un PDF compilabile non deve essere complicata: che tu sia un principiante o uno sviluppatore, c'è uno strumento che si adatta al tuo flusso di lavoro. Per un uso occasionale, strumenti online gratuiti come PDFescape o Sejda sono perfetti. Per i moduli professionali (ad es. contratti, fatture), investi in Adobe Acrobat per funzionalità avanzate. E per soluzioni automatizzate e scalabili, Python con Free Spire.PDF offre un'alternativa potente e gratuita.
Seguendo i passaggi di questa guida, creerai PDF compilabili che fanno risparmiare tempo, riducono gli errori e migliorano l'esperienza dell'utente
Vedi anche
Comment créer un PDF remplissable : 3 façons de rendre un PDF modifiable
Table des matières
Dans le flux de travail numérique d'aujourd'hui, la capacité de créer des fichiers PDF remplissables est plus qu'une commodité, c'est une nécessité. Que vous distribuiez des enquêtes, des formulaires de candidature, des contrats ou des feuilles de travail, les PDF remplissables permettent aux destinataires de saisir des informations directement, de réduire la manipulation manuelle et d'offrir une expérience propre et professionnelle.
Ce guide complet vous présentera les moyens les plus efficaces de créer des PDF modifiables, des outils gratuits conviviaux et des logiciels professionnels aux scripts automatisés pour les développeurs. Vous apprendrez :
- Qu'est-ce qu'un PDF remplissable et pourquoi est-ce utile
- Créer un PDF modifiable avec Adobe Acrobat Pro
- Outils en ligne gratuits pour rendre un PDF remplissable
- Créer un PDF remplissable par programmation en Python
À la fin de ce guide, vous serez en mesure de choisir la meilleure méthode pour vos besoins et de commencer à créer des formulaires PDF professionnels et interactifs en quelques minutes.
Qu'est-ce qu'un PDF remplissable ?
Un PDF remplissable (également appelé formulaire PDF interactif) est un document qui contient des champs modifiables, tels que des zones de texte, des cases à cocher, des boutons radio et des listes déroulantes, que les utilisateurs peuvent remplir numériquement sans avoir à imprimer quoi que ce soit. Contrairement à un PDF statique, un formulaire remplissable guide l'utilisateur, garantit que toutes les informations nécessaires sont collectées et inclut souvent des fonctionnalités telles que la validation des données et les signatures numériques.
Pourquoi utiliser des PDF remplissables ?
- Professionnalisme : Présente une interface propre et de marque pour un usage professionnel ou personnel
- Efficacité : Fait gagner du temps à l'expéditeur et au destinataire. Les données peuvent être remplies automatiquement, exportées ou partagées instantanément.
- Précision : Réduit les erreurs dues à une écriture illisible ou à une saisie de données incorrecte.
- Accessibilité : Peut être utilisé sur n'importe quel appareil (ordinateur de bureau, mobile, tablette) de n'importe où.
1. Créer un PDF modifiable avec Adobe Acrobat Pro (la norme de l'industrie)
Adobe Acrobat est la référence pour la création de PDF interactifs. Il est approuvé par les entreprises du monde entier pour ses fonctionnalités robustes, notamment la détection automatique des champs de formulaire, l'intégration de la signature électronique et les outils de collecte de données. Il est idéal si vous avez besoin de fonctionnalités avancées (par exemple, des calculs, la validation des données).
Étapes pour créer un formulaire remplissable :
- Ouvrez Adobe Acrobat et sélectionnez « Outils » > « Préparer le formulaire » dans la barre d'outils.
- Choisissez un document : vous pouvez partir d'un PDF vierge, télécharger un PDF existant ou même numériser un formulaire papier. Acrobat détectera automatiquement les champs statiques et les convertira en champs de texte remplissables.
- Personnaliser les champs de formulaire : utilisez le volet de droite pour ajouter ou modifier des champs :
- Champs de texte : pour les noms, les e-mails, les adresses ou le texte libre.
- Cases à cocher/Boutons radio : pour les questions oui/non ou les réponses à choix unique/multiple.
- Liste déroulante : pour présenter un ensemble d'options prédéfinies.
- Champs de signature : permettent aux utilisateurs d'ajouter des signatures numériques.
- Bouton : pour les actions de soumission, la réinitialisation du formulaire ou les hyperliens.
- Aperçu & test : cliquez sur « Aperçu » pour tester le formulaire — assurez-vous que les champs sont correctement dimensionnés, étiquetés et fonctionnels.
- Enregistrer & distribuer : enregistrez le PDF, puis utilisez la fonction « Distribuer » d'Acrobat pour l'envoyer par e-mail, partager un lien ou collecter des réponses dans une feuille de calcul.
Conseil de pro : une fois votre PDF remplissable créé et rempli, l'aplatissement du PDF devient essentiel. L'aplatissement transforme toutes les parties modifiables en texte et images statiques. Cela empêche quiconque de modifier le contenu par accident.
2. Outils en ligne gratuits pour rendre un PDF remplissable (aucune installation requise)
Si vous ne voulez pas payer pour un logiciel, certains éditeurs de PDF en ligne vous permettent de créer un PDF remplissable gratuitement — sans téléchargement, sans compétences techniques requises. Des outils comme Sejda, PDFescape, et Formize fournissent des interfaces Web pour ajouter des champs de formulaire PDF. Ils sont conviviaux mais peuvent avoir des limitations de taille de fichier ou de confidentialité.
Étapes pour créer un PDF remplissable en ligne :
Ici, nous utilisons Sejda comme exemple pour ajouter des champs remplissables. Il fonctionne sur tous les navigateurs et vous permet de modifier des PDF existants ou de partir de zéro.
- Allez sur l'éditeur PDF de Sejda et téléchargez votre PDF.
- Sélectionnez « Champs de formulaire » dans la barre d'outils et ajoutez les champs souhaités.
- Personnalisez la disposition et les propriétés des champs (par exemple, le nom du champ, le statut requis).
- Cliquez sur « Appliquer les modifications » et téléchargez le PDF remplissable.
Important : Soyez attentif aux données sensibles. Lisez la politique de confidentialité des outils en ligne gratuits avant de télécharger des informations confidentielles.
3. Créer un PDF remplissable par programmation en Python (avancé, pour les développeurs)
Si vous êtes développeur, vous pouvez créer des PDF modifiables via du code à l'aide de la bibliothèque Free Spire.PDF. C'est idéal pour intégrer la création de formulaires dans des applications ou pour automatiser des flux de travail.
Free Spire.PDF for Python est une bibliothèque gratuite et robuste qui prend en charge la création, la modification et la manipulation de PDF. Contrairement à certaines alternatives Python, il offre :
- Aucun coût pour un usage personnel et commercial (avec certaines limitations de pages).
- Prise en charge complète des champs de formulaire (champs de texte, boutons, boîtes combinées, etc.).
- Intégration facile avec les scripts Python.
Code Python pour ajouter des formulaires PDF remplissables
Le code ci-dessous crée un PDF remplissable avec 5 champs de formulaire courants :
- Zone de texte (pour la saisie du nom)
- Cases à cocher (pour la sélection du sexe)
- Zone de liste (pour la sélection du pays)
- Boutons radio (pour la sélection du passe-temps)
- Boîte combinée/liste déroulante (pour la sélection du diplôme)
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object (blank PDF)
doc = PdfDocument()
# Add a blank page to the document (default A4 size)
page = doc.Pages.Add()
# Initialize x and y coordinates to position form fields
baseX = 100.0
baseY = 30.0
# Create brush objects for text color (blue for labels, black for options)
brush1 = PdfSolidBrush(PdfRGBColor(Color.get_Blue()))
brush2 = PdfSolidBrush(PdfRGBColor(Color.get_Black()))
# Create a font object (Times Roman, 12pt, regular style)
font = PdfFont(PdfFontFamily.TimesRoman, 12.0, PdfFontStyle.Regular)
# --------------------------
# 1. Add a Text Box (Name)
# --------------------------
# Draw label for the text box (blue color)
page.Canvas.DrawString("Name:", font, brush1, PointF(10.0, baseY))
# Define bounds (position + size) for the text box
tbxBounds = RectangleF(baseX, baseY, 150.0, 15.0)
# Create text box field with unique name "name"
textBox = PdfTextBoxField(page, "name")
textBox.Bounds = tbxBounds
textBox.Font = font
# Add text box to the PDF form
doc.Form.Fields.Add(textBox)
# Move y-coordinate down to avoid overlapping fields
baseY += 30.0
# --------------------------
# 2. Add Checkboxes (Gender)
# --------------------------
# Draw label for gender selection
page.Canvas.DrawString("Gender:", font, brush1, PointF(10.0, baseY))
# Checkbox 1: Male
checkboxBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
checkBoxField1 = PdfCheckBoxField(page, "male")
checkBoxField1.Bounds = checkboxBound1
checkBoxField1.Checked = False # Unchecked by default
page.Canvas.DrawString("Male", font, brush2, PointF(baseX + 20.0, baseY))
# Checkbox 2: Female
checkboxBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
checkBoxField2 = PdfCheckBoxField(page, "female")
checkBoxField2.Bounds = checkboxBound2
checkBoxField2.Checked = False
page.Canvas.DrawString("Female", font, brush2, PointF(baseX + 90.0, baseY))
# Add checkboxes to the form
doc.Form.Fields.Add(checkBoxField1)
doc.Form.Fields.Add(checkBoxField2)
baseY += 30.0
# --------------------------
# 3. Add a List Box (Country)
# --------------------------
# Draw label for country selection
page.Canvas.DrawString("Country:", font, brush1, PointF(10.0, baseY))
# Define bounds for the list box
listboxBound = RectangleF(baseX, baseY, 150.0, 50.0)
# Create list box field with unique name "country"
listBoxField = PdfListBoxField(page, "country")
# Add options (display text + internal value)
listBoxField.Items.Add(PdfListFieldItem("USA", "usa"))
listBoxField.Items.Add(PdfListFieldItem("Canada", "canada"))
listBoxField.Items.Add(PdfListFieldItem("Mexico", "mexico"))
listBoxField.Bounds = listboxBound
listBoxField.Font = font
# Add list box to the form
doc.Form.Fields.Add(listBoxField)
baseY += 60.0
# --------------------------
# 4. Add Radio Buttons (Hobbies)
# --------------------------
# Draw label for hobby selection
page.Canvas.DrawString("Hobbies:", font, brush1, PointF(10.0, baseY))
# Create radio button group (unique name "hobbies" ensures mutual exclusivity)
radioButtonListField = PdfRadioButtonListField(page, "hobbies")
# Radio button 1: Travel
radioItem1 = PdfRadioButtonListItem("travel")
radioBound1 = RectangleF(baseX, baseY, 15.0, 15.0)
radioItem1.Bounds = radioBound1
page.Canvas.DrawString("Travel", font, brush2, PointF(baseX + 20.0, baseY))
# Radio button 2: Movie
radioItem2 = PdfRadioButtonListItem("movie")
radioBound2 = RectangleF(baseX + 70.0, baseY, 15.0, 15.0)
radioItem2.Bounds = radioBound2
page.Canvas.DrawString("Movie", font, brush2, PointF(baseX + 90.0, baseY))
# Add radio buttons to the group and group to the form
radioButtonListField.Items.Add(radioItem1)
radioButtonListField.Items.Add(radioItem2)
doc.Form.Fields.Add(radioButtonListField)
baseY += 30.0
# --------------------------
# 5. Add a Combobox (Degree)
# --------------------------
# Draw label for education degree
page.Canvas.DrawString("Degree:", font, brush1, PointF(10.0, baseY))
# Define bounds for the combobox
cmbBounds = RectangleF(baseX, baseY, 150.0, 15.0)
comboBoxField = PdfComboBoxField(page, "degree")
comboBoxField.Bounds = cmbBounds
# Add degree options (display text + internal value)
comboBoxField.Items.Add(PdfListFieldItem("Bachelor", "bachelor"))
comboBoxField.Items.Add(PdfListFieldItem("Master", "master"))
comboBoxField.Items.Add(PdfListFieldItem("Doctor", "doctor"))
comboBoxField.Font = font
# Add combobox to the form
doc.Form.Fields.Add(comboBoxField)
baseY += 30.0
# --------------------------
# Save the fillable PDF
# --------------------------
doc.SaveToFile("PdfForm.pdf", FileFormat.PDF)
Explications clés du code
- Configuration du document PDF : PdfDocument() crée un PDF vierge, et Pages.Add() ajoute une page A4 par défaut (pas besoin de définir explicitement la taille).
- Mise en page & Style :
- baseX/baseY : Coordonnées pour contrôler le positionnement des champs (évite les chevauchements et assure une mise en page propre).
- PdfSolidBrush : Définit les couleurs du texte (bleu pour les étiquettes, noir pour les options) pour améliorer la lisibilité du formulaire.
- PdfFont : Définit une police standard Times Roman 12pt pour un style de texte cohérent sur tous les champs.
- Types de champs de formulaire :
- PdfTextBoxField : Saisie de texte sur une seule ligne avec alignement de la police sur le texte d'entrée.
- PdfCheckBoxField : Sélection binaire avec état non coché par défaut.
- PdfListBoxField : Liste sélectionnable multiligne avec des limites plus hautes pour afficher plusieurs options.
- PdfRadioButtonListField : Sélection mutuellement exclusive – le regroupement sous un seul nom garantit qu'un seul peut être sélectionné.
- PdfComboBoxField : Sélection déroulante avec des étiquettes lisibles par l'homme et des valeurs internes conviviales pour la machine.
- Enregistrement du fichier : le PDF est enregistré dans le chemin spécifié avec le format de fichier explicite FileFormat.PDF pour la compatibilité.
Le PDF remplissable généré ressemble à :
Au-delà de la création de PDF remplissables, une exigence essentielle du monde réel pour les développeurs qui créent des flux de travail automatisés est la capacité de lire les valeurs des champs de formulaire et d'exporter les données de formulaire PDF collectées dans des formats standard pour une analyse plus approfondie.
Foire aux questions (FAQ)
Q1 : Puis-je créer un PDF remplissable gratuitement ?
Oui. Des outils en ligne gratuits comme PDFescape ou Sejda permettent la création de formulaires de base sans paiement ni installation. Des bibliothèques Python comme Free Spire.PDF offrent également une approche programmatique gratuite pour les développeurs.
Q2 : Les PDF remplissables sont-ils compatibles avec tous les appareils et lecteurs de PDF ?
La plupart des lecteurs de PDF modernes (Adobe Acrobat Reader, Aperçu sur Mac, Chrome, Edge) prennent en charge le remplissage de formulaires. Cependant, la création ou la modification de champs de formulaire nécessite généralement des outils spécialisés.
Q3 : Les PDF remplissables peuvent-ils inclure des signatures numériques ?
Oui. De nombreux outils, y compris Adobe Acrobat et plusieurs éditeurs en ligne, vous permettent d'ajouter des champs de signature où les utilisateurs peuvent dessiner, taper ou télécharger une signature numérique.
Q4 : Quelle est la meilleure méthode pour créer des PDF remplissables en masse ?
Pour la génération en masse, une approche programmatique utilisant Python est la plus efficace. Vous pouvez automatiser la création de centaines de formulaires avec des mises en page similaires mais des données uniques.
Réflexions finales
La création d'un PDF remplissable n'a pas à être compliquée — que vous soyez un débutant ou un développeur, il existe un outil qui correspond à votre flux de travail. Pour une utilisation occasionnelle, des outils en ligne gratuits comme PDFescape ou Sejda sont parfaits. Pour les formulaires professionnels (par exemple, les contrats, les factures), investissez dans Adobe Acrobat pour des fonctionnalités avancées. Et pour des solutions automatisées et évolutives, Python avec Free Spire.PDF offre une alternative puissante et gratuite.
En suivant les étapes de ce guide, vous créerez des PDF remplissables qui vous feront gagner du temps, réduiront les erreurs et amélioreront l'expérience utilisateur